STM32 Flash 访问加速器详解(ART Accelerator)
STM32 Flash 访问加速器详解(ART Accelerator)
1. 背景:为什么需要 Flash 加速器?
1.1 问题根源
- Flash 访问速度慢:STM32 的内置 Flash 存储器访问延迟通常为数十纳秒(ns),而 CPU 在高频运行(如 168 MHz、216 MHz 甚至更高)时,每个时钟周期只有几纳秒。
- 等待状态(Wait State):为了正确读取 Flash,CPU 必须插入等待周期。例如:
- 72 MHz 时可能需要 2 个等待周期
- 168 MHz 时可能需要 5 个等待周期
- 216 MHz 时可能需要 7 个等待周期
- 性能损失:每次从 Flash 取指令或读取常量数据都要等待,严重限制了 CPU 的实际性能。
1.2 传统解决方案的局限
- 增加 SRAM:把代码复制到 SRAM 运行(零等待),但 SRAM 容量有限且成本高。
- 降低频率:不现实,违背了使用高性能 MCU 的初衷。
2. ART 加速器的架构与原理
2.1 核心组件(以 STM32F2/F4/F7/H7 为例)
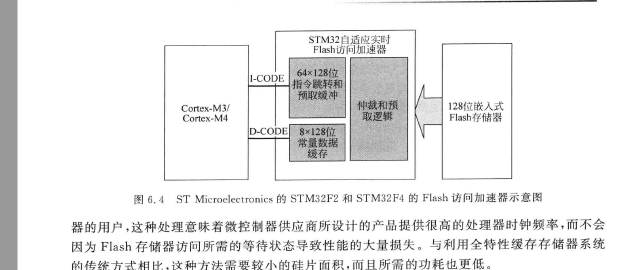
┌─────────────────────────────────────────────────────┐
│ STM32 自适应实时 Flash 访问加速器 │
├──────────────┬──────────────────────┬───────────────┤
│ │ │ │
│ I-CODE │ 64×128位 │ 仲裁和预 │
│ (指令总线) │ 指令缓存和 │ 取逻辑 │───→ 128位嵌入式
│ │ 预取缓冲 │ │ Flash存储器
│ D-CODE │ 8×128位 │ │
│ (数据总线) │ 常量数据缓存 │ │
│ │ │ │
└──────────────┴──────────────────────┴───────────────┘
关键特性:
- 指令缓存(I-Cache):64 行 × 128 位 = 8 KB(STM32F4)或更大(STM32F7/H7)
- 数据缓存(D-Cache):8 行 × 128 位 = 1 KB(仅缓存常量数据,如查找表)
- 预取缓冲(Prefetch Buffer):顺序读取时提前取下一行数据
- 128 位宽接口:一次读取 16 字节(4 条 32 位 Thumb-2 指令),显著减少访问次数
2.2 工作原理
2.2.1 指令缓存命中(I-Cache Hit)
CPU 请求地址 0x08001000↓
ART 检查 I-Cache↓
命中 → 0 等待周期直接返回指令
2.2.2 缓存未命中(Cache Miss)
CPU 请求地址 0x08001100↓
ART 检查 I-Cache:未命中↓
从 Flash 读取 128 位(16 字节)→ 5~7 个等待周期↓
更新缓存行 + 返回指令↓
后续 3 条指令(同一缓存行)→ 0 等待周期
2.2.3 预取机制
- 当 CPU 顺序执行代码时,ART 自动预取下一行到缓冲区。
- 典型场景:循环、顺序函数调用。
2.3 实测性能提升(根据 ST 官方数据)
| CPU 频率 | 无 ART(纯等待状态) | 启用 ART 加速器 | 性能提升 |
|---|---|---|---|
| 168 MHz | ~100 DMIPS | ~210 DMIPS | 110% |
| 216 MHz | ~120 DMIPS | ~270 DMIPS | 125% |
CoreMark 基准测试:在 168 MHz 时,ART 加速器的性能相当于 0 等待状态下的 Flash 执行。
3. 代码优化策略(如何充分利用 ART 加速器)
3.1 硬件配置(必需步骤)
3.1.1 启用 ART 加速器(启动代码中)
STM32F4 示例(使用 HAL 库):
可以看到ART加速是默认开启的。
// filepath: main.c
void SystemClock_Config(void) {// ...时钟配置代码...// 启用指令缓存__HAL_FLASH_INSTRUCTION_CACHE_ENABLE();// 启用数据缓存(如果芯片支持)__HAL_FLASH_DATA_CACHE_ENABLE();// 启用预取缓冲__HAL_FLASH_PREFETCH_BUFFER_ENABLE();// 设置 Flash 等待周期(根据频率,例如 168 MHz → 5 WS)__HAL_FLASH_SET_LATENCY(FLASH_LATENCY_5);
}
STM32F7/H7 示例(使用 HAL 库):
// filepath: main.c
void SystemClock_Config(void) {// STM32F7/H7 还支持 D-Cache(数据缓存)SCB_EnableICache(); // 启用 Cortex-M7 的 I-CacheSCB_EnableDCache(); // 启用 Cortex-M7 的 D-Cache__HAL_FLASH_ART_ENABLE(); // 启用 ART 加速器__HAL_FLASH_PREFETCH_BUFFER_ENABLE();__HAL_FLASH_SET_LATENCY(FLASH_LATENCY_7); // 216 MHz
}
寄存器级操作(不使用 HAL):
// filepath: system_stm32f4xx.c
// STM32F4
FLASH->ACR |= FLASH_ACR_ICEN // 启用指令缓存| FLASH_ACR_DCEN // 启用数据缓存| FLASH_ACR_PRFTEN // 启用预取| FLASH_ACR_LATENCY_5WS; // 设置等待周期
3.2 代码结构优化
3.2.1 保持代码局部性(Locality)
❌ 不好的例子(跳转分散,缓存命中率低):
void task_a(void) { /* 大量代码 */ }
void task_b(void) { /* 大量代码 */ }
void task_c(void) { /* 大量代码 */ }void main_loop(void) {while(1) {task_a(); // 地址 0x08001000task_b(); // 地址 0x08003000(跨多个缓存行)task_c(); // 地址 0x08005000}
}
✅ 好的例子(函数紧密排列,提高缓存命中率):
// 使用链接脚本或 __attribute__ 控制函数顺序
__attribute__((section(".hotfunc")))
void task_a(void) { /* ... */ }__attribute__((section(".hotfunc")))
void task_b(void) { /* ... */ }__attribute__((section(".hotfunc")))
void task_c(void) { /* ... */ }
链接脚本示例(GCC):
SECTIONS {.text : {*(.hotfunc) /* 热点函数放在一起 */*(.text)} > FLASH
}
3.2.2 减少分支预测失败
❌ 不好的例子(大量条件跳转):
void process_data(uint8_t type) {if (type == TYPE_A) {/* 处理 A */} else if (type == TYPE_B) {/* 处理 B */} else if (type == TYPE_C) {/* 处理 C */}// ...更多分支
}
✅ 好的例子(使用函数指针表,减少跳转):
typedef void (*handler_t)(void);const handler_t handlers[] = {handle_type_a,handle_type_b,handle_type_c,
};void process_data(uint8_t type) {if (type < ARRAY_SIZE(handlers)) {handlers[type](); // 间接调用,但更可预测}
}
3.2.3 内联小函数(减少函数调用开销)
❌ 不好的例子:
uint32_t add(uint32_t a, uint32_t b) {return a + b;
}void compute(void) {result = add(x, y); // 函数调用:跳转 + 缓存可能失效
}
✅ 好的例子:
static inline uint32_t add(uint32_t a, uint32_t b) {return a + b;
}void compute(void) {result = add(x, y); // 编译器直接展开,无跳转
}
3.2.4 循环优化(利用预取)
❌ 不好的例子(循环体太大,超出缓存行):
void process_array(uint32_t *data, size_t len) {for (size_t i = 0; i < len; i++) {data[i] = complex_function(data[i]); // 函数调用跳出循环}
}
✅ 好的例子(循环展开 + 内联):
void process_array(uint32_t *data, size_t len) {size_t i;for (i = 0; i + 4 <= len; i += 4) {data[i] = process_inline(data[i]);data[i+1] = process_inline(data[i+1]);data[i+2] = process_inline(data[i+2]);data[i+3] = process_inline(data[i+3]);}for (; i < len; i++) {data[i] = process_inline(data[i]);}
}
3.3 数据访问优化
3.3.1 常量数据放在 Flash(利用 D-Cache)
❌ 不好的例子(查找表在 SRAM,浪费宝贵的 RAM):
uint8_t sin_table[256] = { /* ... */ }; // 默认在 .data 段(SRAM)
✅ 好的例子(查找表在 Flash,由 D-Cache 加速):
const uint8_t sin_table[256] = { /* ... */ }; // .rodata 段(Flash)
3.3.2 对齐数据结构(提高缓存效率)
❌ 不好的例子:
struct sensor_data {uint8_t status; // 1 字节uint32_t value; // 4 字节(未对齐)uint16_t flags; // 2 字节
};
✅ 好的例子:
struct sensor_data {uint32_t value; // 4 字节对齐uint16_t flags;uint8_t status;uint8_t reserved; // 填充到 8 字节边界
} __attribute__((aligned(8)));
3.4 编译器优化选项
GCC 推荐设置(Makefile 或 CMakeLists.txt):
# 优化级别
CFLAGS += -O2 # 平衡优化(或 -O3 激进优化)
CFLAGS += -flto # 链接时优化(跨文件内联)
CFLAGS += -ffunction-sections -fdata-sections
LDFLAGS += -Wl,--gc-sections # 移除未使用代码# Cortex-M4/M7 特定
CFLAGS += -mcpu=cortex-m4
CFLAGS += -mthumb # Thumb-2 指令集(必需)
CFLAGS += -mfloat-abi=hard # 硬件浮点(如果有 FPU)
CFLAGS += -mfpu=fpv4-sp-d16
Keil MDK 设置:
- Optimization Level:
-O2或-O3 - One ELF Section per Function: 勾选
- Link-Time Optimization: 勾选
IAR EWARM 设置:
- Optimization: High (Speed)
- Enable LTO: Yes
4. 性能测试与验证
4.1 测量缓存命中率(仅 STM32F7/H7 支持)
// filepath: perf_test.c
#include "stm32f7xx_hal.h"void measure_cache_performance(void) {uint32_t hits_before, misses_before;uint32_t hits_after, misses_after;// 读取性能计数器(需在调试模式下)hits_before = DWT->CPICNT; // I-Cache 命中次数(示例寄存器)misses_before = /* ... */; // 未命中次数// 执行测试代码test_function();hits_after = DWT->CPICNT;misses_after = /* ... */;float hit_rate = (float)(hits_after - hits_before) / ((hits_after - hits_before) + (misses_after - misses_before));printf("Cache Hit Rate: %.2f%%\n", hit_rate * 100);
}
4.2 对比测试(启用/禁用 ART)

// filepath: benchmark.c
#include "stm32f4xx_hal.h"void run_benchmark(void) {uint32_t start, end;// 禁用 ART__HAL_FLASH_INSTRUCTION_CACHE_DISABLE();__HAL_FLASH_PREFETCH_BUFFER_DISABLE();start = HAL_GetTick();dhrystone_benchmark(); // 或其他基准测试end = HAL_GetTick();printf("Without ART: %lu ms\n", end - start);// 启用 ART__HAL_FLASH_INSTRUCTION_CACHE_ENABLE();__HAL_FLASH_PREFETCH_BUFFER_ENABLE();start = HAL_GetTick();dhrystone_benchmark();end = HAL_GetTick();printf("With ART: %lu ms\n", end - start);
}
5. 注意事项与最佳实践
5.1 必须启用的情况
- 高频运行(>100 MHz):不启用 ART,性能损失超过 50%。
- 实时性要求高:减少指令执行时间的抖动。
5.2 特殊场景处理
5.2.1 中断服务例程(ISR)
// 将 ISR 放在 SRAM(零等待)以获得最快响应
__attribute__((section(".ramfunc")))
void TIM2_IRQHandler(void) {// 快速处理
}
链接脚本:
SECTIONS {.ramfunc : {*(.ramfunc)} > RAM AT > FLASH
}
启动代码中复制到 RAM:
extern uint32_t _ramfunc_start, _ramfunc_end, _ramfunc_load;
memcpy(&_ramfunc_start, &_ramfunc_load, (size_t)(&_ramfunc_end - &_ramfunc_start));
5.2.2 调试时的注意事项
- 单步调试时缓存行为可能异常(每次停止都刷新缓存)。
- 在 Release 模式(优化开启)下验证性能。
5.3 多核系统(STM32H7 双核)
- M7 核心有独立的 I-Cache 和 D-Cache。
- M4 核心通常不支持缓存,但可通过共享 SRAM 协作。
- 注意缓存一致性(使用
SCB_CleanDCache/SCB_InvalidateDCache)。
6. 总结
6.1 关键要点
- ART 加速器 通过指令缓存、数据缓存和预取机制,将 Flash 访问性能提升至接近 0 等待状态。
- 必须在启动代码中启用,否则无法发挥 CPU 全部性能。
- 代码优化:保持局部性、减少跳转、内联小函数、循环展开。
- 数据优化:常量放 Flash、对齐结构体、利用 D-Cache。
- 编译器配置:使用
-O2/-O3+ LTO,生成高效的 Thumb-2 代码。
6.2 性能提升预期
| 场景 | 无 ART | 启用 ART | 提升幅度 |
|---|---|---|---|
| 顺序代码执行 | 基准 | 1.5~2× 更快 | 50~100% |
| 小循环(热点代码) | 基准 | 2~2.5× 更快 | 100~150% |
| 大量分支跳转 | 基准 | 1.2~1.5× 更快 | 20~50% |
6.3 推荐工具
- STM32CubeMX:自动生成启用 ART 的初始化代码。
- STM32CubeIDE:内置性能分析器(需 ST-LINK V3 或 J-Trace)。
- CoreMark:标准基准测试,验证优化效果。
附录:常见问题(FAQ)
Q1:ART 加速器会增加功耗吗?
A:略有增加(约 5~10%),但性能提升带来的执行时间缩短通常能补偿这部分功耗。
Q2:所有 STM32 都有 ART 加速器吗?
A:仅高性能系列(F2/F4/F7/H7/L4+)支持,低功耗系列(L0/L1)和基础系列(F0/F1)不支持。
Q3:缓存大小可以配置吗?
A:硬件固定,无法通过寄存器修改。
Q4:如何清空缓存?
A:
__HAL_FLASH_INSTRUCTION_CACHE_RESET(); // 复位 I-Cache
SCB_InvalidateICache(); // Cortex-M7
Q5:预取缓冲与缓存的区别?
A:预取是线性读取下一行到缓冲区,缓存是存储最近访问的多行数据(支持随机访问)。
参考资料:
- ST AN4839: Level 1 cache on STM32F7 Series and STM32H7 Series
- ST AN4667: STM32F7 Series system architecture and performance
- ARM Cortex-M7 Technical Reference Manual
- STM32 参考手册(RM0090 for F4, RM0433 for H7)