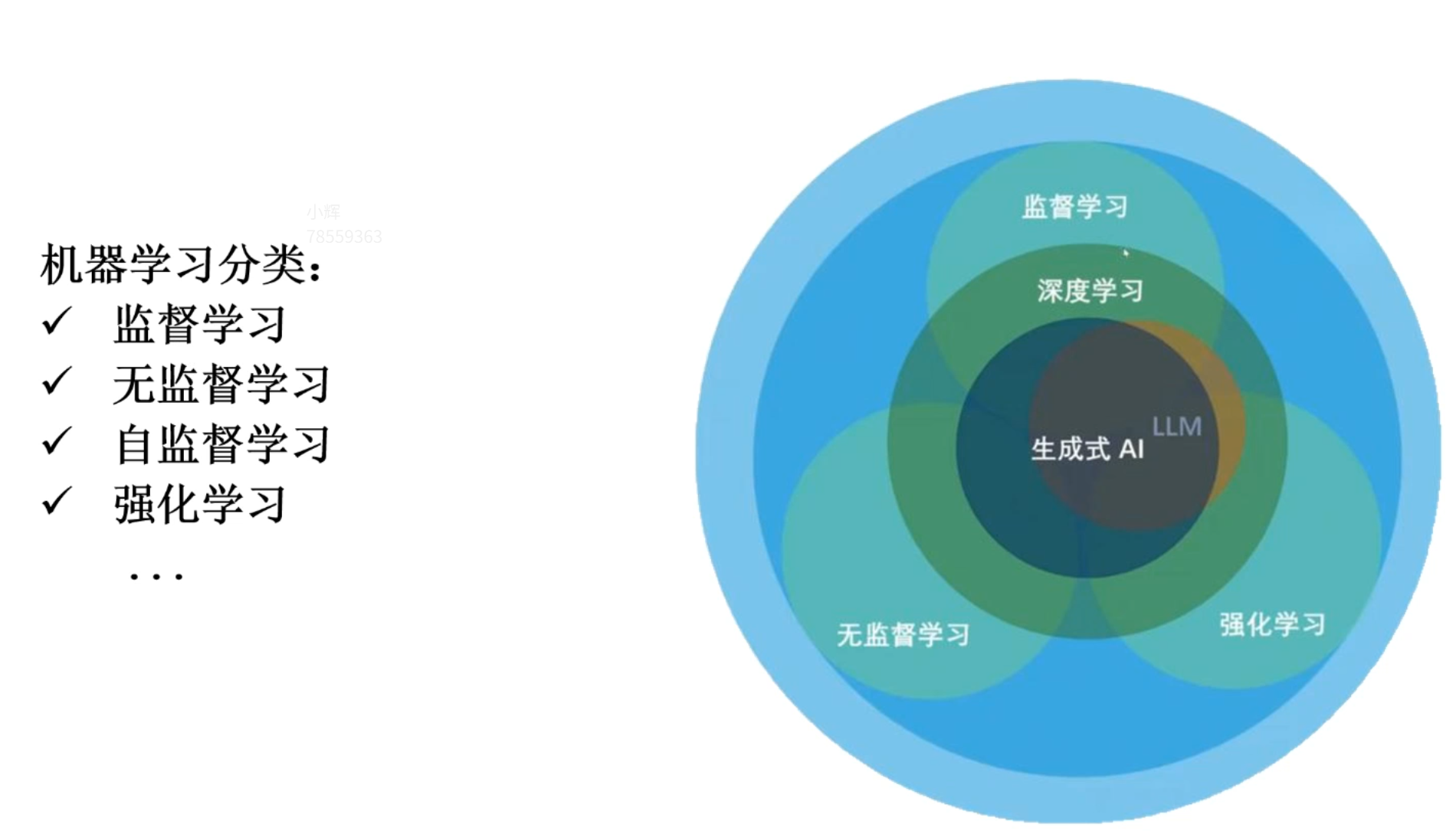
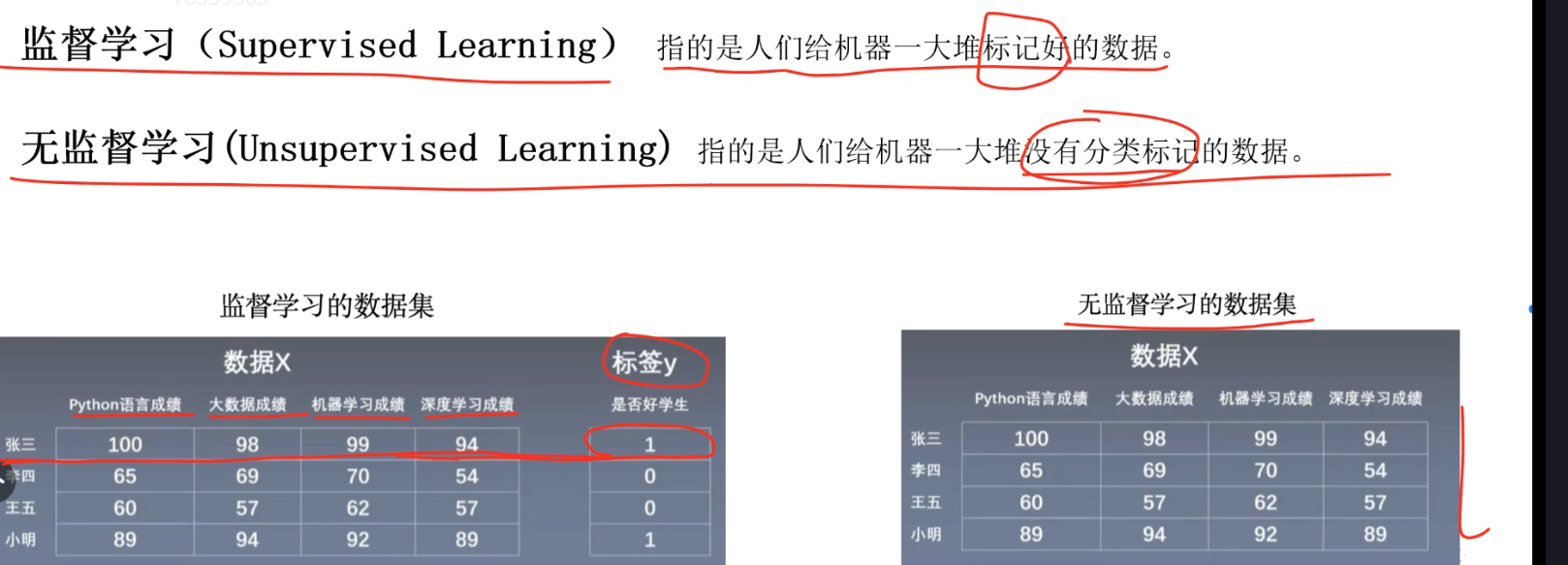
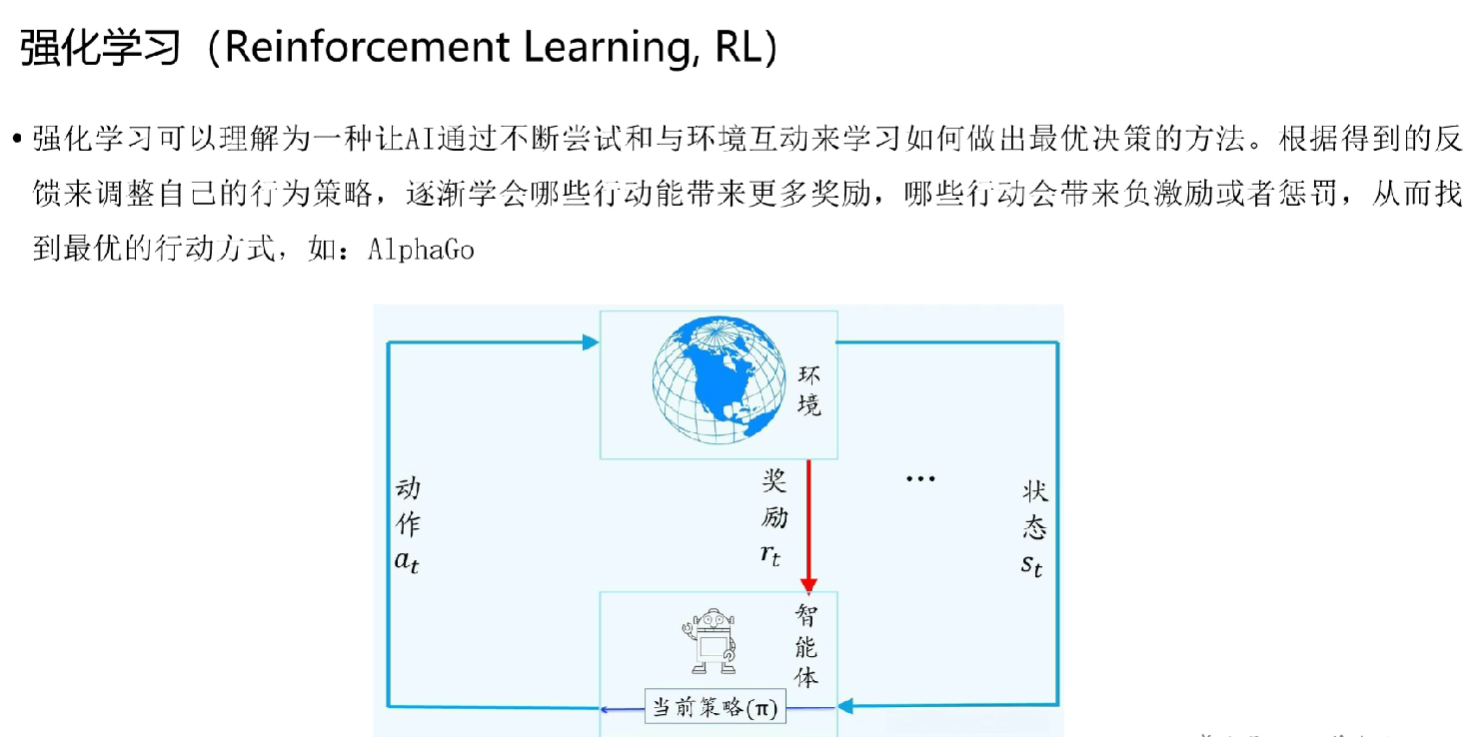
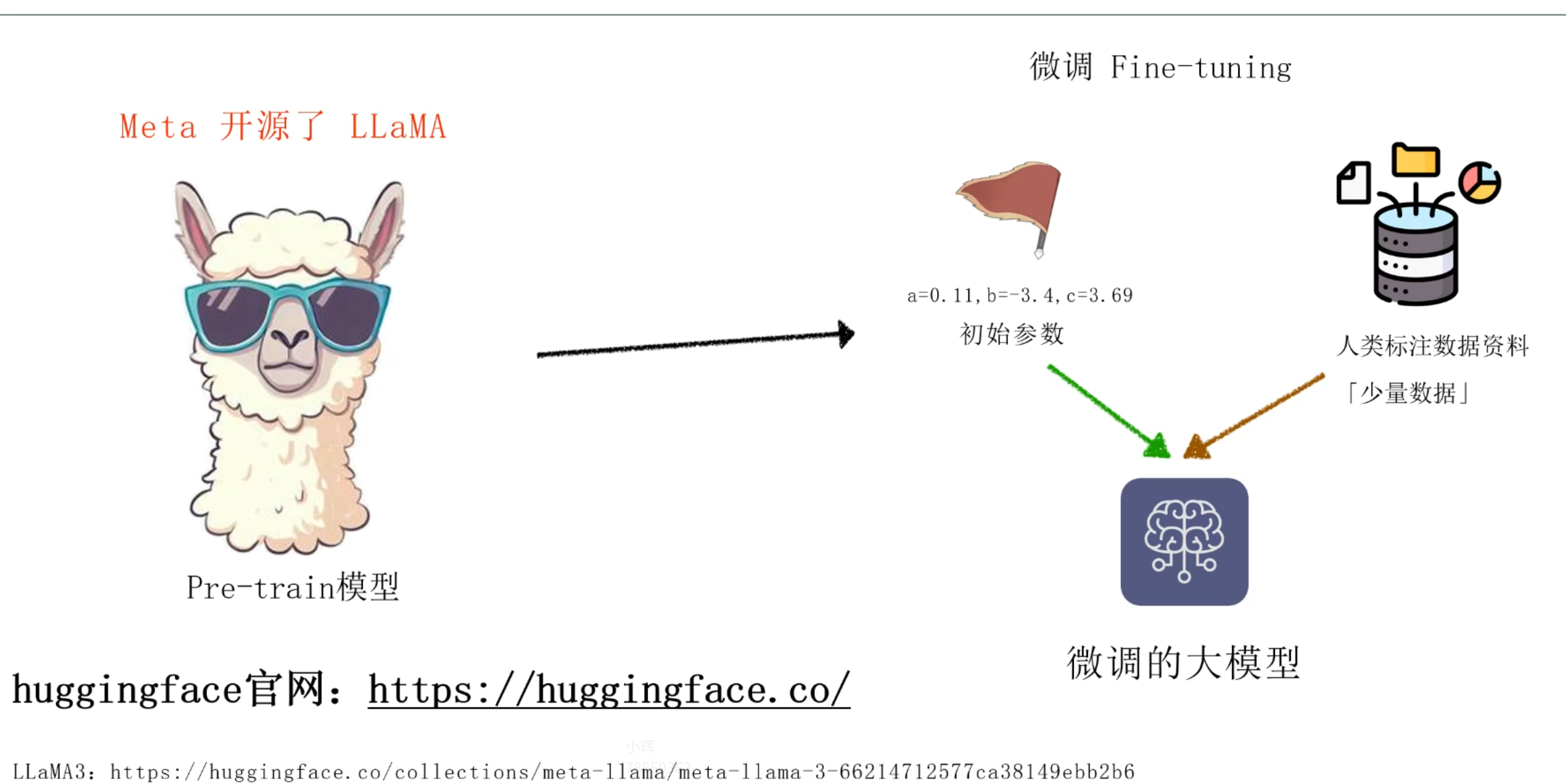
大模型的核心原理
 提示词优化地址:
提示词优化地址:
大模型工作原理:
gpt和chatgpt


Transformer的优势:
1. 并行计算:可以充分利用现代计算硬件进行并行计算,大大提高了训练速度。
2. 捕捉长距离依赖:自注意力机制使得每个位置的输入可以与序列中其他位置的所有信息进行交互,这大大增强了模型捕捉长距离依赖的能力。
3. 可拓展性:transformer架构更容易拓展到更大的模型和更多的书,也更容易提升模型的表达能力。
4. 灵活性和效果,Transformer不仅能搞笑的处理长序列,还能在多种NLP任务中取得良好的效果,无论是机器翻译,文本生成,语义理解,Transformer都能展现出色的性能。





补充:
一.
在大模型交互中,系统提示词(System Prompt)和用户提示词(User Prompt)是两种不同角色的指令,主要差别体现在作用对象、功能定位和使用场景上:
作用对象不同
- 系统提示词:是开发者或平台对模型本身的指令,告诉模型 “你应该以什么身份、什么风格、什么规则来工作”。
- 用户提示词:是用户对模型的具体请求,告诉模型 “现在需要你做什么具体任务”。
功能定位不同
- 系统提示词:相当于给模型设定 “隐形规则”,用于约束模型的整体行为。例如:“你是一个专业的医疗顾问,只回答与健康相关的问题,语气要温和”“你需要用中文口语化表达,避免使用专业术语”。
- 用户提示词:是单次交互的具体任务,决定模型的即时输出内容。例如:“什么是高血压?”“帮我写一封请假邮件”。
使用场景不同
- 系统提示词:通常由开发者在模型初始化时预设,用户看不到但会影响所有交互。比如 ChatGPT 的默认系统提示词可能包含 “遵守伦理规范”“拒绝有害请求” 等规则。
- 用户提示词:是用户在每次对话中输入的内容,随具体需求动态变化。
举个形象的例子:系统提示词像 “剧本大纲”,规定了演员(模型)的角色和表演风格;用户提示词像 “当前台词”,决定了演员在这场戏里具体说什么。
在你提供的代码中,虽然没有显式写出系统提示词,但大模型通常会有默认的系统设定(比如 “帮助用户解答问题”)。如果需要自定义,可以在messages列表中添加一条{"role": "system", "content": "你的系统指令"},放在用户提示词之前,模型就会遵循这个规则处理后续对话。
二.
注意力机制与自注意机制区别:
在深度学习(尤其是 Transformer 架构)中,注意力机制(Attention Mechanism) 是一个广义概念,而自注意力机制(Self-Attention Mechanism) 是注意力机制的一个核心分支,二者是 “包含与被包含” 的关系,核心区别体现在输入来源、关注对象和适用场景上。下面从定义、核心差异、具体案例三个维度展开解析:
一、基础定义:先明确两个概念的本质
要理解区别,首先需要明确二者的核心逻辑 —— 注意力机制的本质是 “从海量信息中筛选出关键信息,给关键信息更高权重,再基于关键信息做决策”,类似人看书时 “重点看标题和关键词,忽略无关段落” 的过程。
| 概念 | 核心定义 | 核心逻辑 |
|---|---|---|
| 注意力机制(Attention) | 广义的 “信息筛选框架”,需指定两个输入:1. 查询(Query, Q):当前需要解决的 “问题”(如 “这句话的主语是什么”);2. 键值对(Key-Value, K-V):用于回答问题的 “信息库”(Key 是信息的 “标签”,Value 是信息的 “内容”)。通过计算 Q 与每个 K 的相似度(权重),再用权重加权求和 V,得到 “聚焦关键信息的结果”。 | 「用 Q 匹配 K,从 V 中选关键信息」(需外部提供 K-V,Q 与 K-V 来源可不同) |
| 自注意力机制(Self-Attention) | 注意力机制的特殊形式:Q、K、V 来自同一输入(即 “自己关注自己”)。无需外部信息库,直接对输入本身的不同部分进行 “内部关联分析”,捕捉输入内部的依赖关系(如句子中 “他” 指代 “小明”)。 | 「用输入自己的 Q,匹配自己的 K,从自己的 V 中选关键信息」(Q/K/V 同源,仅依赖输入本身) |
二、核心差异:3 个关键维度对比
二者的本质区别,可通过 “输入来源”“关注对象”“适用场景” 三个维度清晰区分:
| 对比维度 | 注意力机制(Attention) | 自注意力机制(Self-Attention) |
|---|---|---|
| 1. Q/K/V 的来源 | Q、K、V 可来自不同输入(异源):例 1:机器翻译中,“英文原文” 生成 K-V,“中文译文已生成部分” 生成 Q;例 2:图片描述任务中,“图片特征” 生成 K-V,“已生成的文字” 生成 Q。 | Q、K、V完全来自同一输入(同源):例 1:处理句子 “小明去公园,他喜欢放风筝” 时,Q/K/V 都来自这句话的词向量;例 2:分析图片时,Q/K/V 都来自图片的像素特征或区域特征。 |
| 2. 关注的对象 | 关注 “两个不同序列 / 模态之间的关联”(如 “原文与译文”“图片与文字”),解决 “外部信息匹配” 问题。 | 关注 “同一序列 / 模态内部不同元素的关联”(如 “句子内的代词与先行词”“图片内的物体位置关系”),解决 “内部依赖捕捉” 问题。 |
| 3. 典型适用场景 | 多用于 “跨模态 / 跨序列” 任务,常见于传统 Seq2Seq 模型(如 RNN+Attention):- 机器翻译(原文→译文,跨序列);- 图片描述(图片→文字,跨模态);- 语音识别(语音特征→文字,跨模态)。 | 多用于 “单序列 / 单模态内部分析” 任务,是 Transformer 的核心组件:- 文本理解(如情感分析、阅读理解,需捕捉句子内语义关联);- 文本生成(如 GPT 系列,需关联前文生成后文);- 图像分割(需捕捉图片内像素 / 区域的依赖关系)。 |
三、案例具象化:用 “文本任务” 理解差异
通过两个具体任务,能更直观感受二者的不同:
案例 1:机器翻译(用 “注意力机制”)
假设任务是将英文句子 “I love eating apples” 翻译成中文 “我喜欢吃苹果”,传统 Seq2Seq 模型(RNN+Attention)的工作流程:
- 编码器(Encoder) 处理英文原文,生成每个单词的特征向量,组成 “K-V 库”(K = 英文单词的特征,V = 英文单词的语义信息);
- 解码器(Decoder) 逐词生成中文:
- 生成 “我” 时,Q 是 “我” 的特征向量,计算 Q 与英文 K(I、love、eating、apples)的相似度,发现 “Q 与 I 的相似度最高”,于是给 “I 的 V” 更高权重,基于 “I 的语义” 生成 “我”;
- 生成 “苹果” 时,Q 是 “苹果” 的特征向量,与英文 K 匹配后,给 “apples 的 V” 最高权重,基于 “apples 的语义” 生成 “苹果”。
这里的注意力机制是跨序列的(英文→中文),Q 来自 “译文已生成部分”,K-V 来自 “原文”,属于典型的 “非自注意力”。
案例 2:句子语义理解(用 “自注意力机制”)
假设任务是分析中文句子 “小明昨天去了北京,他说那里的秋天很美” 中 “他” 的指代对象,Transformer 的自注意力流程:
- 将整个句子的每个词(小明、昨天、去、北京、他、说、那里、秋天、很美)转化为词向量,同时生成该句子的 Q、K、V(Q/K/V 都来自这 9 个词的向量,同源);
- 计算每个词的 Q 与所有词的 K 的相似度:
- 当 Q 是 “他” 的向量时,计算 “他的 Q” 与 “小明的 K”“北京的 K”“秋天的 K” 等的相似度,发现 “与小明的 K 相似度最高”;
- 给 “小明的 V” 最高权重,加权求和后得到 “他” 的语义向量 —— 此时 “他的向量” 已融合了 “小明” 的信息,模型明确 “他指代小明”。
这里的自注意力机制是单序列内部的(句子内词与词的关联),Q/K/V 都来自同一个句子,无需外部信息。
四、总结:一句话分清二者关系
- 范围上:自注意力机制是注意力机制的 “子集”,所有自注意力都是注意力,但不是所有注意力都是自注意力;
- 核心上:注意力机制解决 “跨来源信息匹配”(Q 与 K-V 异源),自注意力机制解决 “同来源内部关联”(Q 与 K-V 同源);
- 地位上:自注意力机制是 Transformer 架构的 “灵魂”,正是因为它能高效捕捉长序列内部的依赖关系,才让 Transformer 超越 RNN,成为 NLP、CV 等领域的基础模型。
三. nlp:自然语言处理
四. subword分词词元化:
你提到的 subword(子词)级词元化 是现代大语言模型(比如 Yi、GPT、BERT 等)中非常重要的一步,我给你详细解释一下:
1. 为什么需要 subword 词元化?
传统的 词级(word-level) 分词有两个主要问题:
- 未登录词(OOV, Out-of-Vocabulary):训练语料中没见过的词无法直接表示。
- 词表过大:如果直接用所有单词作为词表,词表会非常大,导致模型参数爆炸。
而 字符级(character-level) 虽然没有 OOV 问题,但语言建模难度高,因为字符本身语义信息弱,需要更多上下文才能理解。
subword 词元化 就是在词和字符之间取一个折中:
- 高频词:整个词作为一个 token
- 低频词:拆成更小的有意义的单元(subword)
- 非常罕见的词:拆到字符级别
这样可以:
- 减少 OOV
- 控制词表大小
- 同时保留语义信息
2. 常见的 subword 算法
大模型常用的 subword 分词算法有:
Byte Pair Encoding (BPE)
- GPT、RoBERTa、GPT-2、Yi 等都用 BPE
- 从单个字符开始,不断合并频率最高的相邻字符 / 子串,直到达到预设词表大小
- 优点:简单高效,压缩率高
WordPiece
- BERT、DistilBERT 等使用
- 与 BPE 类似,但合并时选择能最大化训练数据似然的子串对
SentencePiece
- Google 提出,可同时处理 BPE 和 unigram 语言模型
- 不依赖空格,对中日韩等无空格语言友好
3. 举个例子(BPE)
假设训练语料中有:
low, lower, newest, widest
初始词表(按字符):
l, o, w, e, r, n, e, w, s, t, i, d
合并过程:
- 发现
"e" + "s"出现频率高 → 合并成"es" - 发现
"es" + "t"出现频率高 → 合并成"est" - 发现
"l" + "o"出现频率高 → 合并成"lo" - 发现
"lo" + "w"出现频率高 → 合并成"low"
最终,lower 可能被拆成:
["low", "er"]
newest 拆成:
["new", "est"]
这样高频的 "low" 和 "est" 会作为整体 token,而低频部分被拆成更小单元。
4. 大模型中的流程
在大模型(比如 Yi)中,输入文本会先经过 Tokenizer:
- 预处理:去掉无用符号、统一大小写等
- 分词:用 BPE 或其他 subword 算法拆成 tokens
- 映射 ID:每个 token 对应词表中的一个 ID
- 嵌入层:将 ID 转成向量,进入 Transformer 模型
5. 优点总结
- 降低 OOV 率:罕见词可以拆成已知子词
- 减少词表大小:一般大模型词表在 50k~100k 左右
- 提升泛化能力:相似词根会共享子词表示
- 多语言支持:适合处理不同语言的形态变化
五. PyTorch是什么?
pytorch是一个开源的深度学习框架,一个用python写神经网络和训练AI模型的“工具箱”,提供了大量现成的数学运算,神经网络层,优化器等组件,让你能高效的构建,训练和部署深度学习模型。