从Excel到AI:机器学习如何重塑数据分析,以及MLquick的破局之道
数据分析这事儿,说新不新,说旧不旧。早个二三十年,企业里管数据分析的可能就是个会用Excel的专员,每天对着销售报表算均值、画折线图,最多加个数据透视表,就算是“高级分析”了。那时候的数据量小,业务也简单,老板问“这个月销量为啥降了”,拉出来上个月的数据比一比,看看哪个区域掉得最狠,基本就能给个说法。
但这十年不一样了。先是移动互联网爆发,用户行为数据像潮水一样涌进来——打开APP的时间、停留多久、点了哪个按钮、退出去又干了啥;再后来是物联网普及,工厂里的机器每秒钟都在传数据,温湿度、转速、能耗,一天下来就是几个G。这时候你再用Excel拉数据,别说分析了,光是打开文件都得卡半天。更麻烦的是,数据里藏的规律越来越复杂:用户买不买东西,可能和他上周看的某个短视频有关,也可能和他所在城市的天气挂钩,这些交叉影响的关系,靠人眼盯着报表根本看不出来。
这时候,机器学习就顺理成章地走进了数据分析的圈子。说穿了,机器学习就是让计算机从数据里自己找规律,而且找得又快又细。比如电商平台想知道哪些用户可能会流失,以前可能靠经验“感觉”——最近没登录的、购物车清空的,可能有风险。但机器学习能把用户的浏览记录、客服聊天内容、甚至是退款频率都揉在一起算,最后给出一个“流失概率”,精确到百分之几。这种精度,靠人工分析几乎不可能做到。

不过,机器学习在数据分析里的普及,可不是一帆风顺的。刚开始那几年,它更像实验室里的“奢侈品”。2010年前后,想做个简单的用户分群,得请数据科学家写好几百行Python代码,先清洗数据,再选算法,最后调参数,一套流程走下来,没个把星期出不来结果。业务人员急着要结论,科学家们却在纠结“这个特征的权重是不是该调大一点”,两边经常不在一个频道上。那时候大家对机器学习的态度也很矛盾:知道它厉害,但觉得离自己太远,就像知道火箭能上天,但普通人这辈子可能都摸不着。
转机出现在2015年之后。一方面,Python生态里出了不少“懒人工具”,比如Scikit-learn把复杂的算法打包成了简单的函数,一行代码就能跑起来;另一方面,企业的数据量实在太大了,传统分析方法彻底不够用。就拿银行做信贷风控来说,以前靠人工审核,一天最多看几百份申请,现在用机器学习模型自动筛查,每秒能处理上千条,还能把坏账率压得更低。这时候,“不会机器学习就做不好数据分析”慢慢成了行业共识。
但新的问题又冒出来了:工具是变简单了,但还是得写代码啊。很多业务出身的分析师,Excel玩得溜,SQL写得顺,可一看到“for循环”“决策树”就头大。他们最懂业务需求——知道该关注哪些指标,明白数据背后的业务逻辑,但就是跨不过技术这道坎。结果就是,大量有价值的分析需求被卡在了“技术实现”这一步,要么得排队等数据团队支持,要么就只能退而求其次,用粗糙的方法凑合。
所以你看,数据分析领域其实一直有个没被满足的需求:能不能有个工具,让懂业务但不懂代码的人,也能顺顺当当用上机器学习?最近接触到的开源零代码机器学习应用平台 MLquick,大概就是朝着这个方向努力的。
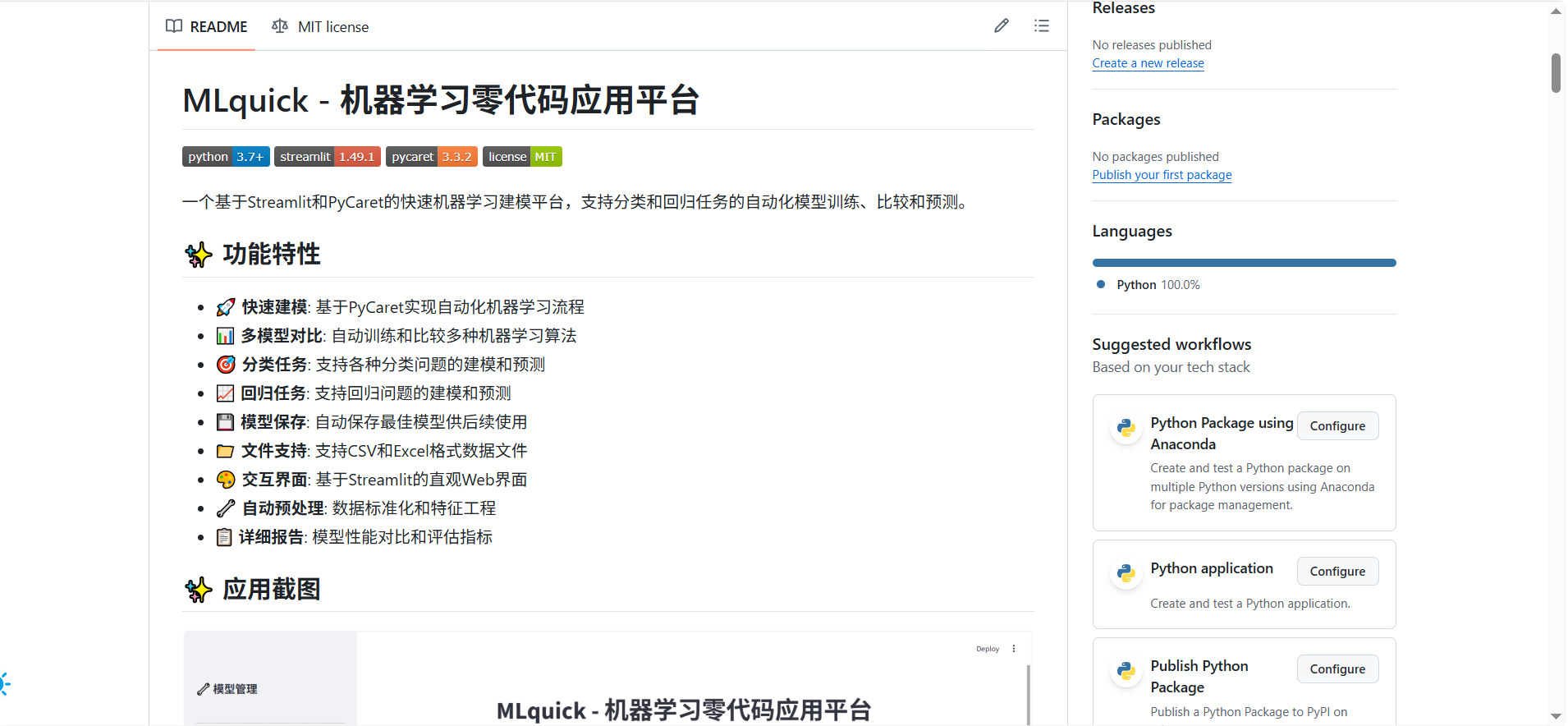
MLquick的核心理念很简单:把机器学习的复杂流程“打包”起来,用户不用写一行代码,点点鼠标就能完成从数据上传到模型部署的全流程。说起来可能有点抽象,咱们拿个实际场景举例子:比如你是电商平台的运营,手里有一份客户数据,包含年龄、消费金额、购买频率这些信息,想知道这些客户能分成几类,好针对性地推活动。以前你可能得求着数据分析师帮忙,现在用MLquick,自己就能搞定。
打开MLquick的网页界面,第一步是上传数据。它支持CSV和Excel格式,基本覆盖了日常工作中最常用的文件类型。上传之后,系统会自动帮你预览数据,告诉你有多少行多少列,有多少个数值型特征——这些都是机器学习前必须了解的基本情况,但以前得自己用Excel函数算半天。
接下来选任务类型。这里分三种:分类、回归、聚类。刚才说的客户分群,属于“聚类”;如果想预测客户会不会买某个商品,那是“分类”;要是想预测下个月的销售额,就是“回归”。选好之后,聚类任务需要设置分几类(比如3类还是5类),再挑几个想用的特征(比如年龄、消费金额这些);分类和回归则需要选一个“目标变量”——也就是你想预测的那个指标,比如“是否购买”“销售额”,再设置一下训练集比例(一般选70%的数据用来训练模型,30%用来测试效果)。
然后点一下“开始训练模型”,剩下的事儿就不用管了。系统会自动做数据预处理——比如把文字型的数据转换成数字,把差异大的数值统一尺度;还会自动试很多种算法,比如聚类会试试K-means,分类会跑跑随机森林、XGBoost这些,然后挑出效果最好的那个。这个过程要是自己写代码,光预处理可能就得写几十行,还容易出错,现在全交给系统了。
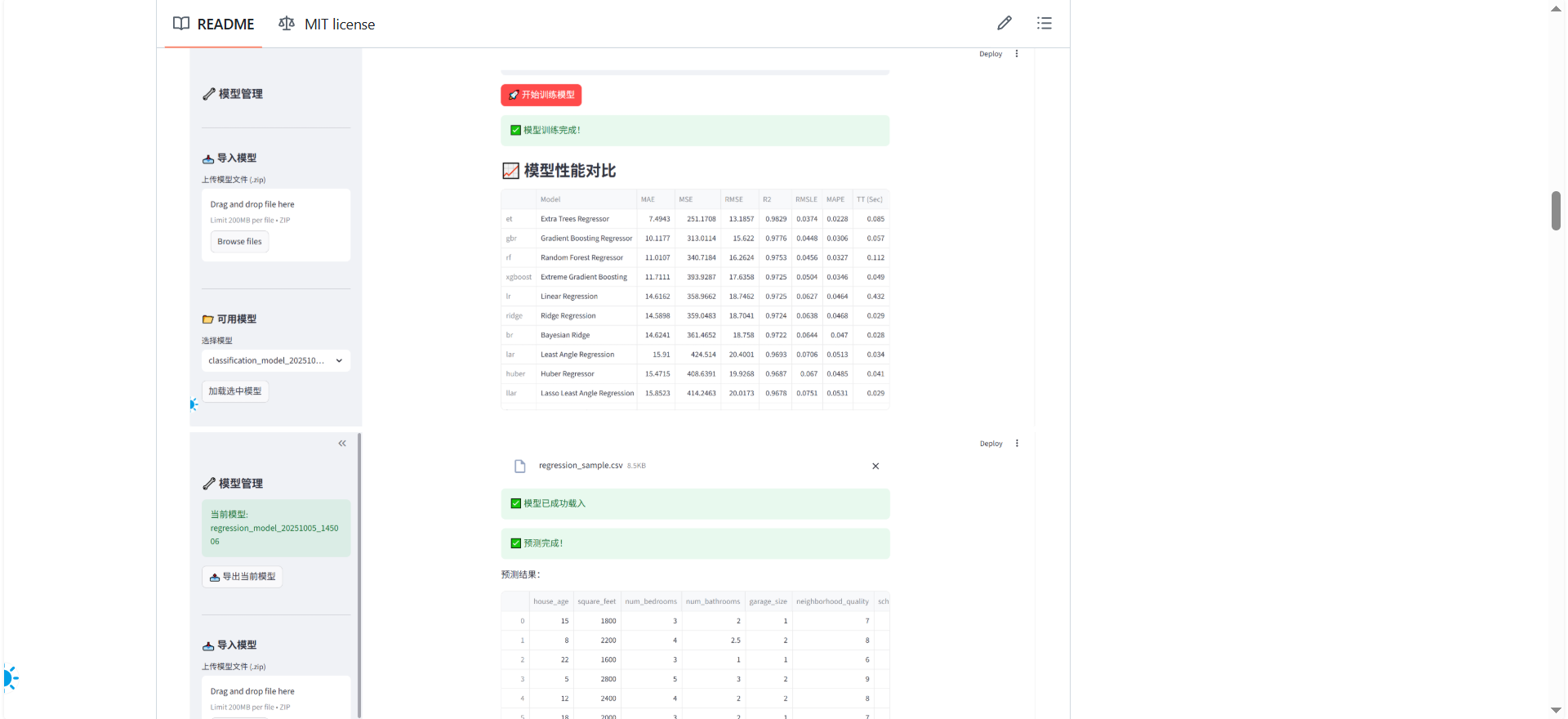
等模型训练完,结果会直接展示在界面上。聚类任务会给你画好散点图、3D图,直观地看出几类客户的分布,还会生成一个统计表格,告诉你每类客户的平均年龄、平均消费这些特征——比如“聚类0是高收入高消费的优质客户,聚类2是年轻的低消费客户”,这些结论直接就能用到营销策略里。分类和回归任务则会给出不同模型的性能对比,比如哪个模型的准确率高,哪个预测误差小,让你一目了然知道哪个模型更靠谱。
最方便的是预测功能。模型训练好之后,上传一份新的数据(比如新客户的信息),系统就能直接给出预测结果——哪些新客户可能会买东西,下个月的销售额大概是多少。结果还能下载成CSV文件,直接用Excel打开分析。
之所以能做到这么简单,背后其实是两大技术在撑腰。一个是Streamlit,它是个Python的Web框架,能把代码快速转换成网页界面,开发者不用费劲去设计前端,专注做功能就行;另一个是PyCaret,这是个机器学习工具包,把数据预处理、模型训练、结果评估这些步骤都自动化了,相当于给机器学习流程装了个“自动驾驶”模式。MLquick把这两个工具结合起来,再针对业务场景做了优化,就成了现在这个零代码的平台。
用下来最大的感受是,它真的把机器学习“平民化”了。以前觉得很高大上的技术,现在业务人员自己就能上手用。比如市场专员想做用户画像,不用再等数据团队排期;运营想快速验证“天气是否影响销量”的假设,上传数据跑个回归模型,半小时就能出结果。这种效率的提升,对业务来说太重要了——市场机会往往转瞬即逝,等得起一周的分析周期,可能早就错过了最佳时机。
当然,MLquick也不是万能的。它更适合处理结构化数据(就是像Excel表格那样一行一行的数据),对于文本、图片这些非结构化数据,目前支持得还不够好。另外,它的自动化流程虽然省事儿,但对于特别复杂的业务场景,可能还是需要人工调参。不过话说回来,对于大多数日常数据分析需求,这些限制基本不影响使用。
其实从Excel到SPSS,再到现在的MLquick,数据分析工具的进化一直围绕着一个核心:让技术门槛越来越低,让更多人能用上高级的分析方法。早期的Excel解决了“计算”的问题,后来的SPSS简化了“统计分析”,现在的零代码机器学习工具,则是想让“AI预测”变得和画折线图一样简单。
这种趋势背后,是数据分析角色的转变。以前数据分析更像“专家职能”,只有少数人掌握;现在它慢慢变成了“基础能力”,就像写PPT、发邮件一样,是很多岗位都需要的技能。MLquick这类工具的价值,就是帮那些懂业务但缺技术的人补上短板,让他们能直接用数据说话,而不是被困在“不会代码”的瓶颈里。
可能有人会担心:工具这么智能,会不会让数据分析师失业?其实恰恰相反。工具能帮分析师省去清洗数据、调模型这些重复性工作,让他们有更多时间去思考“这个分析结果对业务有什么意义”“下一步该怎么行动”。就像计算器没让会计失业,反而让他们能做更复杂的财务分析一样,机器学习工具也会让数据分析从“做报表”升级到“做决策支持”。
回到MLquick这个项目本身,它现在已经支持分类、回归、聚类这些最常用的机器学习任务,还能自动保存模型、导出结果,基本能覆盖中小企业的日常分析需求。如果你是刚接触数据分析的新手,或者是业务岗位想自己做些简单的预测,完全可以试试——官网有示例数据,下载下来跟着流程走一遍,很快就能上手。
最后想说的是,机器学习在数据分析里的应用,从来都不是为了“炫技”,而是为了让数据更好地服务业务。不管是写代码还是用零代码工具,能解决实际问题的才是好方法。MLquick这类工具的出现,让更多人有机会用机器学习去挖掘数据里的价值,这本身就是件挺有意义的事——毕竟,数据的价值不在于存了多少,而在于用了多少。