INT305 Machine Learning 机器学习 Pt.3二元分类和多类分类
文章目录
- 1.分类(Classification)
- 1.1 线性分类
- 1.1.1 简化模型
- 1.1.1.1 消除阈值(Eliminating the threshold)
- 1.1.1.2 消除阈偏置(Eliminating the bias)
- 1.1.2 线性分类的示例
- 1.1.3 二元线性分类器的总结
- 2.线性回归
- 2.1 损失函数(loss function)
- 2.1.1 0-1损失函数
- 2.1.2 0-1损失函数的成本函数
- 2.1.3 0-1损失函数的优化
- 2.1.3.1 0-1损失函数
- 2.1.3.2 线性回归
- 2.1.3.3 逻辑激活函数(Logistic Activation Function)
- 2.1.3.3.1 交叉熵损失函数(Cross-Entropy Loss)/对数损失(Log Loss)
- 1.2 多类分类(Multiclass Classification)和 Softmax 回归(Softmax Regression)
- 1.2.1 多类分类(Multiclass Classification)
- 1.2.2 Softmax 回归(Softmax Regression)
- 1.3 线性分类器的局限性
1.分类(Classification)
分类是机器学习中的一种任务,目标是预测一个离散值(discrete-valued)的目标变量。
因此二元分类(Binary Classification)是分类问题的一个子集,目标是预测一个二元值(binary-valued)的目标变量,即只有两个可能的类别。
例如:
- 疾病诊断:给定患者各种症状的存在或缺失,预测患者是否患有某种疾病。
- 垃圾邮件分类:将电子邮件分类为垃圾邮件或非垃圾邮件。
- 欺诈检测:预测金融交易是否为欺诈行为。
而多类分类(Multiclass Classification)是另一种分类问题,目标是预测一个有多个离散值(超过两个类别)的目标变量。
1.1 线性分类
我们给出详细的定义。
分类是一种监督学习任务,给定一个 D-维的输入x∈RD\mathbf{x} \in \mathbb{R}^Dx∈RD,目标是预测一个离散值的目标变量。
二元分类是分类问题的一个子集,目标是预测一个二元值(binary-valued)的目标变量ttt,即t∈{0,1}t∈\{0,1\}t∈{0,1}。
训练样本中,目标变量t=1t=1t=1的样本称为正例(positive examples),目标变量 t=0 的样本称为负例(negative examples)。
为了方便计算,有时会使用t∈{−1,+1}t∈\{−1,+1\}t∈{−1,+1}来表示二元目标变量。
在二元线性分类中,模型的预测yyy是输入xxx的线性函数,然后通过一个阈值rrr进行分类:
z=w⊤x+bz = \mathbf{w}^\top \mathbf{x} + bz=w⊤x+b
y={1if z≥r0if z<ry = \begin{cases} 1 & \text{if } z \geq r \\ 0 & \text{if } z < r \end{cases}y={10if z≥rif z<r
其中,w\mathbf{w}w是权重向量,bbb是偏置项,zzz是线性函数的输出,rrr是分类阈值。
1.1.1 简化模型
在二元线性分类中简化模型有两种方法:消除阈值和消除偏置项。
1.1.1.1 消除阈值(Eliminating the threshold)
我们可以假设(在不损失一般性的情况下,即WLOG)阈值r=0r=0r=0。
因此源氏的分类条件就可以进行转化。
w⊤x+b≥r⟺w⊤x+b−r≥0\mathbf{w}^\top \mathbf{x} + b \geq r \iff \mathbf{w}^\top \mathbf{x} + b - r \geq 0w⊤x+b≥r⟺w⊤x+b−r≥0
由于r=0r=0r=0,这个条件进一步简化。
w⊤x+b≥0\mathbf{w}^\top \mathbf{x} + b \geq 0w⊤x+b≥0
这里我们将w0w_0w0定义为bbb,即w0≜bw_0 \triangleq bw0≜b。
1.1.1.2 消除阈偏置(Eliminating the bias)
添加一个总是取值为1的虚拟特征x0x_0x0 。这样,权重w0=bw_0=bw0=b就相当于偏置项(与线性回归中的偏置相同)。
因此现在我们可以简化模型为:
输入:接受输入x∈RD+1\mathbf{x} \in \mathbb{R}^{D+1}x∈RD+1,其中x0=1x_0=1x0=1。
线性函数:计算z=w⊤xz=\mathbf{w}^\top \mathbf{x}z=w⊤x
因此我们根据zzz的值进行分类:
y={1if z≥00if z<0y = \begin{cases} 1 & \text{if } z \geq 0 \\ 0 & \text{if } z < 0 \end{cases}y={10if z≥0if z<0
1.1.2 线性分类的示例
在学习初期,我们会介绍简单的示例,专注于最小化训练集误差并暂时忽略泛化能力。
例1:逻辑运算NOT。
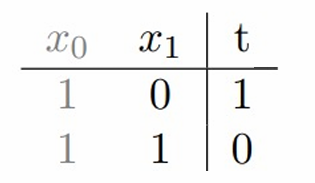
这里输入的数据会接受特征,如果特征相同,那其标签就为0,否则就为1。
为了实现完美分类,需要找到合适的权重w0w_0w0和w1w_1w1,使得对于所有特征,模型的预测z=w0x0+w1x1z=w_0x_0+w_1x_1z=w0x0+w1x1与真实标签ttt一致。
按照上表的这几个样本我们可以得到:
当x1=0x_1=0x1=0时,需要z=w0≥0z=w_0≥0z=w0≥0以确保分类正确,这意味着w0w_0w0必须非负。
当x1=1x_1=1x1=1时,需要z=w0+w1<0z=w_0+w_1<0z=w0+w1<0以确保分类正确,这意味着w0+w1w_0+w_1w0+w1必须为负。
对于这个例子,w0=1,w1=−2w_0=1,w_1=-2w0=1,w1=−2就是可以满足的一个解,当然满足的解有很多。
例2:逻辑运算AND。
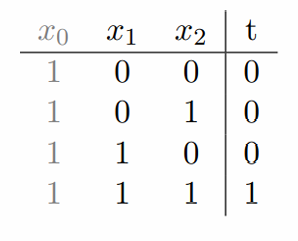
对于现在这个例子,那我们现在的预测z=w0x0+w1x1+w2x2z=w_0x_0+w_1x_1+w_2x_2z=w0x0+w1x1+w2x2
按照上表的这几个样本我们可以得到:
w0<0w_0<0w0<0
w0+w2<0w_0+w_2<0w0+w2<0
w0+w1<0w_0+w_1<0w0+w1<0
w0+w1+w2≥0w_0+w_1+w_2≥0w0+w1+w2≥0
这里给出一个可行的解:w0=−1.5,w1=1,w2=1w_0=-1.5,w_1=1,w_2=1w0=−1.5,w1=1,w2=1
我们尝试用几何图来展示刚刚的两个例子。
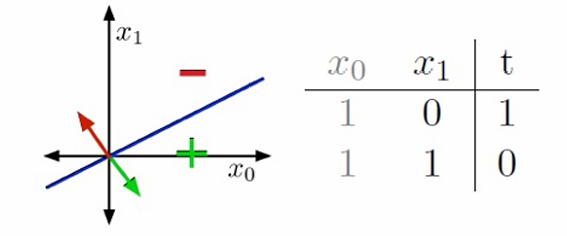
图中展示了输入空间(也称为数据空间),其中x0x_0x0和x1x_1x1是特征轴,代表数据的两个维度。训练样本在输入空间中表示为点。
权重向量w\mathbf{w}w定义了两个半空间:
H+={x:w⊤x≥0}H_+ = \{ \mathbf{x} : \mathbf{w}^\top \mathbf{x} \geq 0 \}H+={x:w⊤x≥0} :正半空间,其中所有点的线性组合w⊤x≥0\mathbf{w}^\top \mathbf{x} \geq 0w⊤x≥0
H−={x:w⊤x<0}H_- = \{ \mathbf{x} : \mathbf{w}^\top \mathbf{x} < 0 \}H−={x:w⊤x<0}负半空间,其中所有点的线性组合w⊤x<0\mathbf{w}^\top \mathbf{x} < 0w⊤x<0
决策边界是w⊤x=0\mathbf{w}^\top \mathbf{x} = 0w⊤x=0的集合,它将输入空间分为两个区域。
在二维空间(2-D)中,决策边界是一条直线;在更高维度中,它是超平面。
如果训练样本可以通过一个线性决策规则完美分开,那么我们说数据是线性可分的(linear separable)。这意味着存在一个权重向量w\mathbf{w}w,使得所有正例和负例分别位于决策边界的两侧。
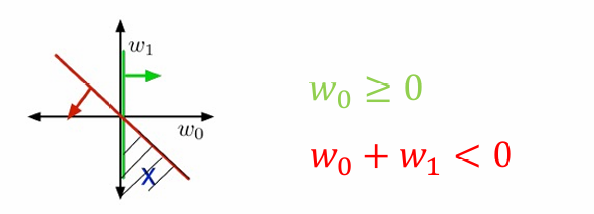
图片展示了权重空间(Weight Space)。
在权重空间中,权重向量w\mathbf{w}w被视为点。
每个训练样本xxx指定了一个半空间,权重向量w\mathbf{w}w必须位于这个半空间内,以便正确分类该样本:
如果t=1t=1t=1,则需要w⊤x≥0\mathbf{w}^\top \mathbf{x} \geq 0w⊤x≥0。
如果t=0t=0t=0,则需要w⊤x<0\mathbf{w}^\top \mathbf{x} < 0w⊤x<0。
满足所有约束条件的区域称为可行区域(feasible region)。
如果这个区域不为空,则问题是可行的(feasible);如果这个区域为空,则问题是不可行的(infeasible)。
这里红线和绿线之间的阴影部分代表了可行解的范围,也就是可行区域(feasible region)。
在例2中,由于是三维空间,其中包括一个虚拟维度(dummy dimension),通常用于表示偏置项(bias)。所以为了可视化三维数据空间和权重空间,我们可以查看一个二维切片(slice)。
无论在数据空间还是权重空间中,可视化的结果都是相似的。满足所有约束条件的可行集(feasible set)总是有一个角在原点(origin)。这是因为当所有权重都为零时,模型不会对任何输入产生影响,这通常满足所有分类约束。
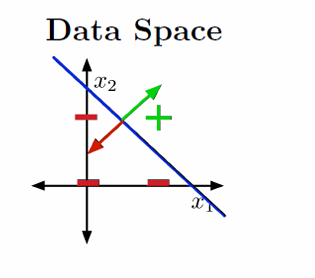
这里选择x0=1x_0=1x0=1进行切片。
示例解如w0=−1.5,w1=1,w2=1w_0=-1.5,w_1=1,w_2=1w0=−1.5,w1=1,w2=1。
决策边界的方程是w0x0+w1x1+w2x2=0w_0x_0+w_1x_1+w_2x_2=0w0x0+w1x1+w2x2=0,代入示例解得到−1.5+x1+x2=0-1.5+x_1+x_2=0−1.5+x1+x2=0。
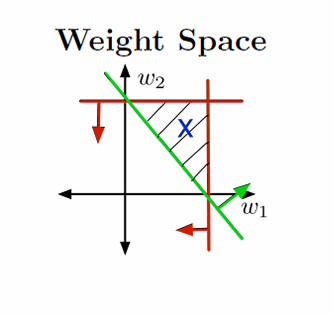
这里选择w0=−1.5w_0=-1.5w0=−1.5进行切片。
约束条件为w0<0,w0+w2<0,w0+w1<0,w0+w1+w2≥0w_0<0,w_0+w_2<0,w_0+w_1<0,w_0+w_1+w_2≥0w0<0,w0+w2<0,w0+w1<0,w0+w1+w2≥0
同理这里阴影部分代表了可行解的范围。
1.1.3 二元线性分类器的总结
目标变量ttt取值为{0,1}\{0,1\}{0,1}。
输入向量x∈RD+1\mathbf{x} \in \mathbb{R}^{D+1}x∈RD+1,其中x0=1x_0=1x0=1是一个虚拟特征,用于表示偏置项。
模型由权重向量w\mathbf{w}w定义,预测yyy是输入xxx的线性函数,然后通过阈值进行分类:z=w⊤xz = \mathbf{w}^\top \mathbf{x}z=w⊤x
y={1if z≥00if z<0y = \begin{cases} 1 & \text{if } z \geq 0 \\ 0 & \text{if } z < 0 \end{cases}y={10if z≥0if z<0
如果训练集是线性可分的,我们可以使用线性规划来求解权重 w。
也可以使用感知机算法(perceptron algorithm),这是一种迭代过程,但主要是出于历史兴趣。
如果数据不是线性可分的,问题会变得更加困难。
在现实生活中,数据几乎从不具有线性可分性。
2.线性回归
2.1 损失函数(loss function)
在机器学习模型的训练过程中,我们首先需要定义一个损失函数(loss function),用于量化模型预测值与实际值之间的差异。
然后最小化小化这个损失函数在整个训练集上的平均值(或总和),这个平均值(或总和)被称为成本函数(cost function)。
2.1.1 0-1损失函数
0-1损失函数是一种看似直观的损失函数,其定义如下:
L0−1(y,t)={0if y=t1if y≠t\mathcal{L}_{0-1}(y, t) = \begin{cases} 0 & \text{if } y = t \\ 1 & \text{if } y \neq t \end{cases}L0−1(y,t)={01if y=tif y=t
其中,yyy是模型的预测值,ttt是真实值。如果预测值与真实值相等,损失为0;否则,损失为1。
也可以用指示函数(indicator function)表示为L0−1(y,t)=I[y≠t]\mathcal{L}_{0-1}(y, t) = \mathbb{I}[y \neq t]L0−1(y,t)=I[y=t],其中I\mathbb{I}I是指示函数。
2.1.2 0-1损失函数的成本函数
成本函数是训练样本上损失的平均值(或总和)。对于0-1损失,成本函数实际上就是错误分类率(misclassification rate),即训练集中被错误分类的样本比例。因此公式为:J=1N∑i=1NI[y(i)≠t(i)]\mathcal{J} = \frac{1}{N} \sum_{i=1}^{N} \mathbb{I}[y^{(i)} \neq t^{(i)}]J=N1∑i=1NI[y(i)=t(i)]。
2.1.3 0-1损失函数的优化
2.1.3.1 0-1损失函数
因此我们现在要尝试优化0-1损失函数,但这个问题可能是NP难(NP-hard)问题。因为0-1损失函数是一个阶梯函数(step function),它在预测正确和错误之间有一个突然的变化。这种函数不是“良好”的,因为它不满足一些优化算法所需的性质,如连续性(continuity)、平滑性(smoothness)和凸性(convexity)。由于这些性质的缺失,常见的优化算法(如梯度下降)可能无法有效地应用于0-1损失函数。
我们现在使用链式法则计算0-1损失函数关于权重wjw_jwj的偏导数:∂L0−1∂wj=∂L0−1∂z⋅∂z∂wj\frac{\partial \mathcal{L}_{0-1}}{\partial w_j} = \frac{\partial \mathcal{L}_{0-1}}{\partial z} \cdot \frac{\partial z}{\partial w_j}∂wj∂L0−1=∂z∂L0−1⋅∂wj∂z
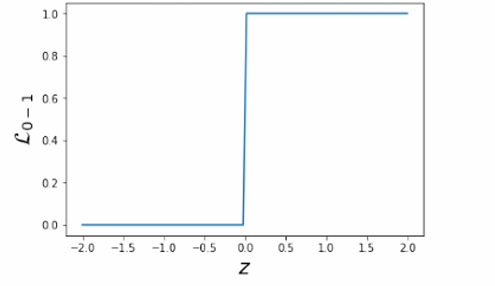
我们会发现这个导数在定义域内处处为零,因为0-1损失函数是一个阶梯函数,没有平滑的过渡。
∂L0−1∂z=0\frac{\partial \mathcal{L}_{0-1}}{\partial z} = 0∂z∂L0−1=0 意味着微小地改变权重对损失几乎没有影响。
几乎任何点的梯度都是零,这意味着无法使用基于梯度的优化算法(如梯度下降)来找到损失函数的最小值。
2.1.3.2 线性回归
我们现在尝试使用使用线性回归来替代原始损失函数来进行优化。我们这种方法被称为使用平滑替代损失函数的松弛(relaxation)。
与其基于最终预测结果定义损失,不如直接基于模型的中间输出zzz来定义损失。这里zzz是模型的线性组合输出,即z=w⊤xz=\mathbf{w}^\top \mathbf{x}z=w⊤x。
由于我们已经知道如何拟合线性回归模型,我们可以考虑使用平方误差损失函数(Squared Error Loss, SE)来衡量预测值zzz与真实标签ttt之间的差异:LSE(z,t)=12(z−t)2\mathcal{L}_{\text{SE}}(z, t) = \frac{1}{2}(z - t)^2LSE(z,t)=21(z−t)2
尽管目标变量实际上是二元的(0或1),我们可以将其视为连续值进行处理。
对于这个损失函数,通过在12\frac{1}{2}21处对zzz进行阈值处理来进行最终预测是有意义的。这是因为平方误差损失函数在z=tz=tz=t时达到最小值,而在二元分类的上下文中,ttt通常取值为0或1。因此,将zzz阈值化在0.5处,可以有效地将连续的预测值zzz转换为二元预测。
这种方法也有问题,如下图所示。
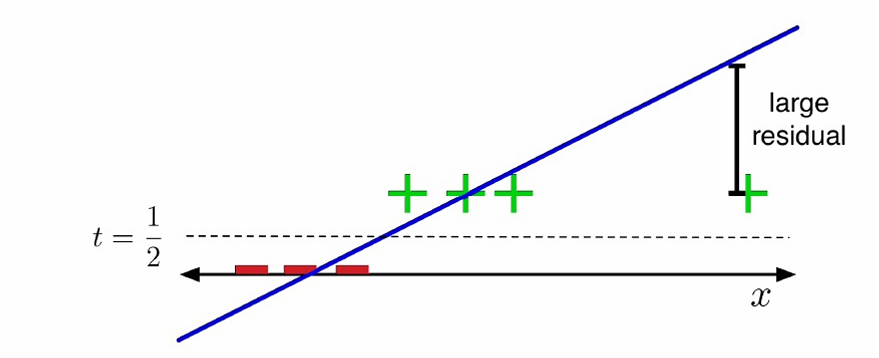
图中展示了一个线性决策边界。
损失函数“不喜欢”高置信度的正确预测。这是因为平方误差损失函数对所有误差赋予相同的权重,无论预测值与真实值之间的差距有多大。
例如,如果t=1t=1t=1,模型预测z=10z=10z=10比预测z=0z=0z=0更糟糕,因为z=10z=10z=10与真实值t=1t=1t=1之间的差距更大,导致平方误差更大。
2.1.3.3 逻辑激活函数(Logistic Activation Function)
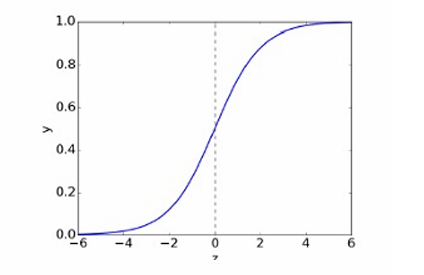
逻辑激活函数(Logistic Activation Function),也称为sigmoid函数,它在二元分类问题中用于将线性模型的输出映射到0和1之间的概率值。
没有理由预测超出[0, 1]区间的值,因此需要将输出值压缩到这个区间内。
逻辑函数是一种S形函数(sigmoid function),其定义为:
σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1
这个函数将任何实数zzz映射到0和1之间。
σ−1(y)=log(y1−y)\sigma^{-1}(y) = \log\left(\frac{y}{1 - y}\right)σ−1(y)=log(1−yy)被称为logit,它是逻辑函数的逆函数。
将线性模型与逻辑非线性函数结合,称为逻辑线性模型(Log-linear Model:
z=w⊤xz = \mathbf{w}^\top \mathbf{x}z=w⊤x
y=σ(z)y = \sigma(z)y=σ(z)
这里,zzz是线性组合的输出,yyy是通过逻辑函数映射后的概率输出。
使用平方误差损失函数来衡量预测值yyy与真实标签 t 之间的差异:
LSE(y,t)=12(y−t)2\mathcal{L}_{\text{SE}}(y, t) = \frac{1}{2}(y - t)^2LSE(y,t)=21(y−t)2
在这种用法中,σ\sigmaσ被称为激活函数(activation function)。
在使用逻辑激活函数时,当预测值zzz远离真实标签时,可能会出现梯度消失问题。
下图展示了平方误差损失函数LSE\mathcal{L}_{SE}LSE作为zzz的函数的图,假设真实标签t=1t=1t=1。
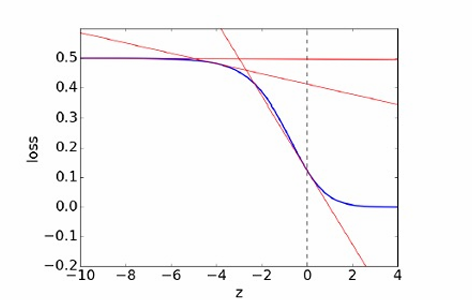
损失函数关于权重wjw_jwj的导数为 ∂L∂wj=∂L∂z⋅∂z∂wj\frac{\partial \mathcal{L}}{\partial w_j} = \frac{\partial \mathcal{L}}{\partial z} \cdot \frac{\partial z}{\partial w_j}∂wj∂L=∂z∂L⋅∂wj∂z
当z≪0z≪0z≪0时,逻辑激活函数σ(z)≈0σ(z)≈0σ(z)≈0。
损失函数关于zzz的导数∂L∂z≈0\frac{\partial \mathcal{L}}{\partial z} \approx 0∂z∂L≈0,因此∂L∂wj≈0\frac{\partial \mathcal{L}}{\partial w_j} \approx 0∂wj∂L≈0。这意味着权重wjw_jwj的梯度很小,导致权重更新很小,权重wjw_jwj像是一个临界点。
如果预测结果与真实标签相差很大(即zzz远离0),那么模型应该远离临界点(即候选解)。
2.1.3.3.1 交叉熵损失函数(Cross-Entropy Loss)/对数损失(Log Loss)
逻辑回归模型输出yyy属于区间 [0, 1],可以解释为t=1t=1t=1的估计概率。如果t=0t=0t=0,则希望对接近 1 的yyy进行重罚。
交叉熵损失函数捕捉了这种直觉,其定义如下:
LCE(y,t)={−logyif t=1−log(1−y)if t=0\mathcal{L}_{\text{CE}}(y, t) = \begin{cases} -\log y & \text{if } t = 1 \\ -\log(1 - y) & \text{if } t = 0 \end{cases}LCE(y,t)={−logy−log(1−y)if t=1if t=0
这可以简化为:LCE(y,t)=−tlogy−(1−t)log(1−y)\mathcal{L}_{\text{CE}}(y, t) = -t \log y - (1 - t) \log(1 - y)LCE(y,t)=−tlogy−(1−t)log(1−y)
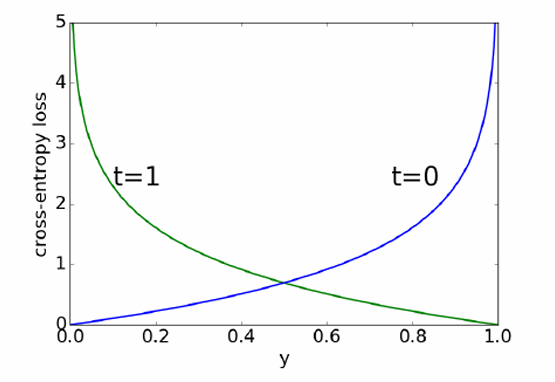
当t=1t=1t=1时,如果模型预测yyy接近 1,损失较小;如果yyy远离 1,损失较大。
当t=0t=0t=0时,如果模型预测yyy接近 0,损失较小;如果yyy远离 0,损失较大。
下图展示了当目标t=1t=1t=1时,交叉熵损失函数关于zzz的图形。
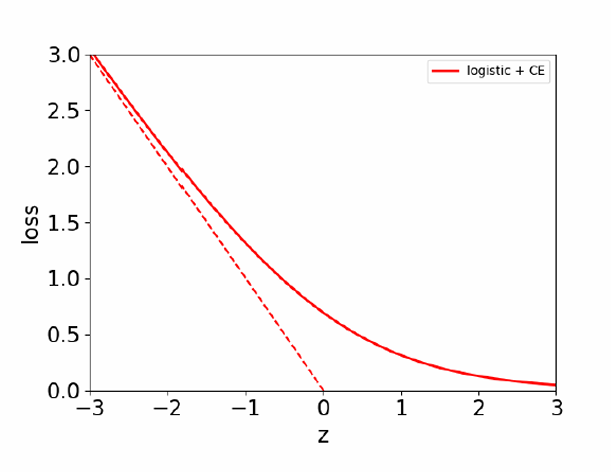
图中实线表示逻辑回归模型的损失,虚线表示线性回归模型的损失(平方误差损失)。
可以看到,当zzz值较大(即模型对正例的预测置信度较高)时,逻辑回归的损失较小,这与交叉熵损失函数的特性相符。
现在我们可以使用梯度下降法来最小化逻辑回归(Logistic Regression)的成本函数J\mathcal{J}J。逻辑损失函数在权重www上是凸函数(convex function)。凸函数的一个重要性质是它们有一个全局最小值。
标准的权重初始化是将权重www设置为零。这样做的原因包括:
- 零初始化简单且计算方便。
- 它可以防止某些特征在训练初期对损失函数的影响过大,从而有助于模型的稳定训练。
- 在某些情况下,非零初始化可能导致梯度消失或梯度爆炸问题,这些问题会阻碍模型的学习过程。
首先交叉熵损失函数的定义为:
LCE(y,t)=−tlogy−(1−t)log(1−y)\mathcal{L}_{\text{CE}}(y, t) = -t \log y - (1 - t) \log(1 - y)LCE(y,t)=−tlogy−(1−t)log(1−y)这里,yyy是模型预测的概率,ttt是真实标签。
逻辑函数yyy定义为:y=11+e−zy = \frac{1}{1 + e^{-z}}y=1+e−z1。其中,z=w⊤xz = \mathbf{w}^\top \mathbf{x}z=w⊤x是线性组合的输出。
根据链式法则:∂LCE∂wj=(−ty+1−t1−y)⋅y(1−y)⋅xj=(y−t)xj\frac{\partial \mathcal{L}_{\text{CE}}}{\partial w_j} = \left(-\frac{t}{y} + \frac{1 - t}{1 - y}\right) \cdot y(1 - y) \cdot x_j = (y - t)x_j∂wj∂LCE=(−yt+1−y1−t)⋅y(1−y)⋅xj=(y−t)xj
梯度下降(coordinate-wise)更新规则用于找到逻辑回归的权重:
wj←wj−α∂J∂wjw_j \leftarrow w_j - \alpha \frac{\partial \mathcal{J}}{\partial w_j}wj←wj−α∂wj∂J
=wj−αN∑i=1N(y(i)−t(i))xj(i)= w_j - \frac{\alpha}{N} \sum_{i=1}^{N} (y^{(i)} - t^{(i)}) x_j^{(i)}=wj−Nα∑i=1N(y(i)−t(i))xj(i)
这里,ααα是学习率,NNN是样本数量。
我们可以注意到线性回归和逻辑回归的梯度下降更新规则都为:
w←w−αN∑i=1N(y(i)−t(i))x(i)\mathbf{w} \leftarrow \mathbf{w} - \frac{\alpha}{N} \sum_{i=1}^{N} (y^{(i)} - t^{(i)}) \mathbf{x}^{(i)}w←w−Nα∑i=1N(y(i)−t(i))x(i)
它们都是广义线性模型(generalized linear models)的例子。
注意到求和符号前的 1N\frac{1}{N}N1,这是由于损失是平均计算的。当损失是求和而不是平均值时,需要较小的学习率α′=αN\alpha' = \frac{\alpha}{N}α′=Nα
1.2 多类分类(Multiclass Classification)和 Softmax 回归(Softmax Regression)
1.2.1 多类分类(Multiclass Classification)
前面我们说的是二元分类,现在我们将注意力放在多类分类上,我们现在的目标是预测一个大于两个类别的离散值目标变量。
例如:1.手写数字识别:预测手写数字的值,例如,识别手写数字0到9。

2.邮件分类:将电子邮件分类为不同的类别,如垃圾邮件、旅行邮件、工作邮件、个人邮件等。

在多类分类问题中,目标变量(targets)形成一个离散集合{1,⋯,K}\{1,⋯,K\}{1,⋯,K},其中KKK表示类别的总数。
我们可以使用独热向量表示多类标签法,它将每个类别编码为一个长度为KKK的向量,其中只有一个位置是1,其余位置都是0。
t=(0,⋯,0,1,0⋯,0)∈RKt = (0, \cdots, 0, 1, 0 \cdots, 0) \in \mathbb{R}^Kt=(0,⋯,0,1,0⋯,0)∈RK
这里,t∈RKt ∈ \mathbb{R}^Kt∈RK表示向量ttt是一个KKK维实数向量,其中第kkk个位置是1,其余位置都是0。
对于每个类别kkk,线性函数可以表示为:zk=∑j=1Dwkjxj+bkfor k=1,2,⋯,Kz_k = \sum_{j=1}^{D} w_{kj} x_j + b_k \quad \text{for } k = 1, 2, \cdots, Kzk=∑j=1Dwkjxj+bkfor k=1,2,⋯,K
这里,zkz_kzk是第kkk类的线性组合输出,wkjw_{kj}wkj是权重,xjx_jxj是输入特征,bkb_kbk是偏置项,DDD是输入维度的数量,KKK是输出类别的数量。
可以通过将权重矩阵W\mathbf{W}W扩展到RK×(D+1)\mathbb{R}^{K×(D+1)}RK×(D+1)并添加一个虚拟变量x0=1x_0=1x0=1来消除偏置bbb。
这样,线性函数可以向量化表示为:z=Wx+b\mathbf{z} = \mathbf{W} \mathbf{x} + \mathbf{b}z=Wx+b
这里权重W\mathbf{W}W是一个K×DK×DK×D的矩阵,其中每一行对应一个类别的权重。偏置bbb是一个KKK维向量,其中每个元素对应一个类别的偏置。
其中,z\mathbf{z}z是KKK维的输出向量,W\mathbf{W}W是扩展后的权重矩阵,xxx是扩展后的输入向量。
向量化表示,添加虚拟变量x0=1x_0=1x0=1:z=Wx\mathbf{z} = \mathbf{W} \mathbf{x}z=Wx
那么现在如何将线性预测转换为独热编码(one-hot encoding)的预测呢?
我们可以将zkz_kzk的大小解释为模型偏好类别kkk作为其预测的程度的度量。
如果我们这样做,我们应该设置预测值yiy_iyi为yi={1if i=argmaxkzk0otherwisey_i = \begin{cases} 1 & \text{if } i = \arg\max_k z_k \\ 0 & \text{otherwise} \end{cases}yi={10if i=argmaxkzkotherwise
这里argmaxkzk\arg\max_k z_kargmaxkzk表示选择zkz_kzk中最大的索引iii,即模型最偏好的类别。
1.2.2 Softmax 回归(Softmax Regression)
我们需要“软化”我们的预测,以便进行优化。这里会使用 Softmax 回归。这意味着我们希望模型的输出更平滑,而不是像0-1损失函数那样在正确和错误预测之间有突然的变化。
我们希望模型的输出像概率一样“软”,即0≤yk≤10≤y_k≤10≤yk≤1并且所有输出的和为1。
一个自然的激活函数选择是Softmax函数,它是逻辑函数的多变量推广。Softmax函数定义为:yk=softmax(z1,⋯,zK)k=ezk∑k′ezk′y_k = \text{softmax}(z_1, \cdots, z_K)_k = \frac{e^{z_k}}{\sum_{k'} e^{z_{k'}}}yk=softmax(z1,⋯,zK)k=∑k′ezk′ezk这里,zkz_kzk是第kkk类的线性组合输出,yky_kyk是第kkk类的预测概率。
输出可以解释为概率(正值且和为1)。如果zkz_kzk远大于其他值,则softmax(z)k≈1softmax(z)_k≈1softmax(z)k≈1,Softmax函数表现得像argmax(选择最大值的函数)。
和前面类似,我们可以使用交叉熵损失函数作为损失函数。交叉熵损失函数定义为:LCE(y,t)=−∑k=1Ktklogyk\mathcal{L}_{\text{CE}}(\mathbf{y}, \mathbf{t}) = - \sum_{k=1}^{K} t_k \log y_kLCE(y,t)=−∑k=1Ktklogyk
这里,yyy是模型输出的概率向量,ttt是真实标签的独热编码向量,KKK是类别的数量,tkt_ktk和yky_kyk分别是第kkk类的真实标签和预测概率。
交叉熵损失函数也可以表示为向量形式:LCE=−t⊤(logy),\mathcal{L}_{\text{CE}}= - \mathbf{t}^\top (\log \mathbf{y}),LCE=−t⊤(logy),
通常,Softmax函数和交叉熵损失结合在一起使用,形成Softmax-交叉熵损失函数。这种组合允许模型输出类别概率,并使用交叉熵损失来衡量预测概率与真实标签之间的差异。
因此Softmax回归的更新规则与线性回归和逻辑回归的更新规则相似。
Softmax回归模型:线性组合的输出zzz计算为:z=Wxz = \mathbf{W} \mathbf{x}z=Wx
然后通过Softmax函数转换为预测概率yyy:y=softmax(z)y = \text{softmax}(z)y=softmax(z)
交叉熵损失函数定义为:LCE=−t⊤(logy)\mathcal{L}_{\text{CE}} = -\mathbf{t}^\top (\log \mathbf{y})LCE=−t⊤(logy)
梯度下降更新规则用于更新权重矩阵W\mathbf{W}W的每一行:∂LCE∂wk=∂LCE∂zk⋅∂zk∂wk=(yk−tk)⋅x\frac{\partial \mathcal{L}_{\text{CE}}}{\partial \mathbf{w}_k} = \frac{\partial \mathcal{L}_{\text{CE}}}{\partial z_k} \cdot \frac{\partial z_k}{\partial \mathbf{w}_k} = (y_k - t_k) \cdot \mathbf{x}∂wk∂LCE=∂zk∂LCE⋅∂wk∂zk=(yk−tk)⋅x,其中,yky_kyk是第kkk类的预测概率,tkt_ktk是第kkk类的真实标签,xxx是输入特征向量。
权重更新公式为:wk←wk−α1N∑i=1N(yk(i)−tk(i))x(i)\mathbf{w}_k \leftarrow \mathbf{w}_k - \alpha \frac{1}{N} \sum_{i=1}^{N} (y_k^{(i)} - t_k^{(i)}) \mathbf{x}^{(i)}wk←wk−αN1∑i=1N(yk(i)−tk(i))x(i)
这里的这些相似性表明这些方法在数学形式上具有一定的共通性。
1.3 线性分类器的局限性
线性分类器,如感知机或线性支持向量机(SVM),假设数据可以通过线性决策边界来分离。然而,并非所有数据集都能用直线(或超平面)来分离。
例如逻辑运算符异或(XOR)问题就是一个非线性可分数据集的一个例子。
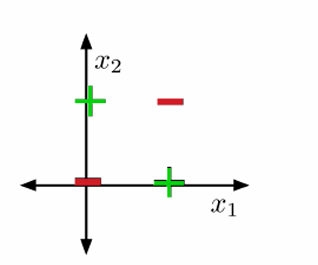
我们可以使用反证法来证明XOR问题不是线性可分的。
假设存在一组权重(w\mathbf{w}w)能够将XOR问题的数据集线性分开。
如果正例(绿色点)位于正半空间,则连接这些点的线段也必须位于正半空间。
同理,负例(红色点)必须位于负半空间。
然而,连接正例和负例的线段的交点不能同时位于两个半空间,这产生了矛盾。
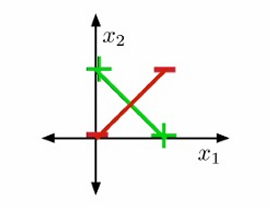
但是我们可以通过手工构造新的特征(feature map)让它变得线性可分。
我们定义三个新特征(即把二维点映射到三维空间):ϕ(x)=(x1,x2,x1x2)⊤\phi(\mathbf{x}) = \bigl(x_1,\; x_2,\; x_1 x_2\bigr)^{\!\top}ϕ(x)=(x1,x2,x1x2)⊤

这样我们就可以找到一张超平面把四类点完美分开。