Apache Iceberg介绍、原理与性能优化
介绍
首先我们要知道Iceberg是什么。简单地说,它是一种开放式的表格式,用于取代Hive表。
那什么是表格式?表格式是数据湖屋这种OLAP系统的一个组件,用于将数据文件组织起来,对上层提供“表”这一抽象。或者说得更通俗一点,就是让我们能用在OLAP系统里用SQL执行数据定义和数据计算,类似功能的产品还有Hive, Hudi, Delta Lake等。
这篇文章是Apache Iceberg: The Definitive Guide的读书笔记。由于时间推移,书和文章的内容很可能过时,因此入门了解概念后,在真正使用中,最好的参考文档永远是官方文档:Introduction - Apache Iceberg™
数据湖屋的产生
最开始的数据处理系统都以OLTP为主,因为OLTP是应用运行必须的组件。随着时间的发展,各家公司不仅要让产品能运行,还需要分析用户行为来指导产品设计,以在未来的竞争中占据上风,因此分析的需求也逐渐增加,慢慢演化出了OLAP系统。
最早开始OLTP和OLAP都在同一套存储中进行,但是这样会造成很多问题,比方说OLAP的大批量操作会影响OLTP系统性能。所以慢慢地,就将OLTP系统产生的数据传输到OLAP的专用组件中处理,发展出了数据仓库(Data Warehouse),数据湖(Data Lake),数据湖屋等(Data Lake House)等独立的OLAP组件。
关于OLAP系统的发展可以详见这篇文章TBD,这里简单介绍一下三个阶段:
- 数据仓库(Data warehouse):只能存储和处理结构化数据。数仓系统通常是一个完整(而不像数据湖屋是多个不同功能的组件组合而成)的软件,各个组件之间是强耦合的,存储数据的格式一般也不公开,但是性能通常比较高。看它的描述,可以理解为一个为OLAP负载设计的
MySQL。 - 数据湖(Data Lake):可以存储各种数据,并使用MapReduce框架来分布式执行计算任务,代表是第一代Hadoop。可以认为它由一个云存储引擎和一个支持用户自定义计算逻辑的框架构成。
- 数据湖屋(Data Lakehouse):利用数据湖发展过程中形成的一批开源存储格式、表格式、计算引擎等OLAP组件组合而成的,运行在数据湖上的数据仓库。它通常处理的也是结构化数据,只不过存储更开放、成本更低廉、选择更多元
数据湖屋通常由多个部分构成:
- 文件存储:通常基于云存储,比如Azure Blob Storage,Amazon S3等。这些云存储服务通常提供类似的功能,接口也都兼容Hadoop,因此没有特殊要求的话可以互换。如果运行于其上的组件对原子化操作等有要求,则要仔细阅读存储提供商的文档以确定具体行为
- 文件格式:用于高效存储数据,目前常见的有
parquetavro等,我们常见的csv``tsv也是一种文件存储格式 - 表格式:存储着与“表”相关的metadata和数据,经过正确的程序可以构建出类似SQL中表的概念。表可以提供文件格式中无法记录的额外metadata,提供历史版本管理、行记录插入删除等功能。
- 数据目录:存储着表的相关信息,比如有什么表,表格式是什么,表数据在哪,表的描述等。可以认为它将零散的表都集中到一处,便于管理和发现
- 计算引擎:对于结构化数据,通常提供高效的内部格式来操作数据,可以与其它插件集成来从各种数据源中读取数据并处理,比方说可以与数据目录交互来读取某个指定的表,也可以直接读取表格式、文件格式等
以一次查询为例,说明数据湖屋内各个组件如何交互:
- 用户指定要查询
myTable表 - 存储引擎与数据目录交互,得到该表的表格式、数据存储路径等信息
- 存储引擎用相应的表读取模块来读取表存储路径下的元数据,比如分区信息、数据文件的位置等
- 存储引擎读取数据文件,并将结果返回给用户
通过上面的介绍,大家应该了解了数据湖屋和表格式在数据湖屋中的作用。接下来我们介绍表格式的发展历史
从Hive到Iceberg
在Hadoop诞生后的一段时间内,OLAP的处理逻辑基本都是用MapReduce框架编写。但是MapReduce的编程非常繁琐,由于最常处理的负载还是结构化数据,计算方式也很固定,所以大家希望使用传统的SQL语句来分析数据。Hive就是在这种背景下诞生了,它最大的特点是将SQL语句转化为MapReduce任务执行。除了计算,Hive还包含其它组件,包括数据目录Hive Metastore和Hive表格式。所以某种意义上,可以将Hive架构看作是数据湖屋的鼻祖,虽然其中大部分组件都发展出了更现代的实现,但其组件的构造以及组件之间相互独立的特性都和现代数据湖屋一样。
Hive表格式具有以下优点:
- 文件格式无关性:Hive表格式只要求数据是按照目录组织的,通常数据存储在
{dbName}/{tableName}/{partitionValue}下 - 支持通过分区和分桶来实现查询时数据剪枝:分区指的是将数据按照某个维度分成不同的目录,分桶指的是单个分区内用哈希函数将行均匀地分到不同的数据文件内,这样当查询语句中包含过滤条件时,可以根据过滤条件筛选出所需读取的分区,避免全表扫描
- 支持分区级别的原子操作:如果底层存储支持目录级别的原子替换操作,那可以利用底层存储的目录替换来实现分区数据的原子级修改
可以看到,Hive表将目录结构作为表元数据的一部分,这导致了以下的一些问题:
- 文件级别的操作很低效,即使要更新一个文件,也需要替换整个目录;
- 多分区的文件替换无法原子化,除非直接替换整个表
- 不支持并发更新,假如有两套系统同时写入一个Hive表,很可能导致表损坏
- 目录结构中包含表的元数据,比如目录结构中包含着表有哪些分区、分区内有哪些文件等信息,这导致如果要进行谓词下推进行剪枝,需要列出目录下所有的目录或文件,而这一操作通常很费时
此外,表的metadata是由额外的异步任务计算的(而不是在修改表时就自动更新),因此表metadata不能及时更新,这会使谓词下推等优化失效。
因此,在Hive之后发展出了更现代的表格式,它们通常支持更强的原子特性,并且考虑并发,且具有更丰富的元数据来支持查询优化。Iceberg就是其中的代表,它除了解决了Hive列出的这些问题之外,还具有这些特性:
- schema演化:支持修改schema、partition等表的核心定义
- 高性能读取:可处理PB级数据
- 隐式分区:支持使用推导出的值来分区,比方说已有
dateTime列,则可以使用YEAR(dateTime)类似的语句,按照年分量进行分区,而不用创建新列。这样减少了不必要的分区列,降低了数据的维护成本 - 行级数据操作:高效支持插入一行、修改某行、删除某行等行级操作。通常OLAP文件存储格式如
parquet是不可变的,iceberg通过读时合并(merge-on-read, MOR),和写时复制(copy-on-write, COW)两种机制来支持行级操作。 - 时间旅行(Time travel):支持查询过去某一时间点的快照。也就是说,每次对表的修改都会创建一个快照(snapshot),用户可以通过快照查询历史某一时间点的数据
- 版本回滚:将数据回滚到某一快照时的状态
Iceberg数据组织方式
介绍完了Iceberg的特性,接下来就要说说Iceberg是如何实现这些特性的。首先要强调,iceberg的理念是数据不可变,即数据文件和元数据文件都不可变,如果要修改,一定要新建一个新文件写入。
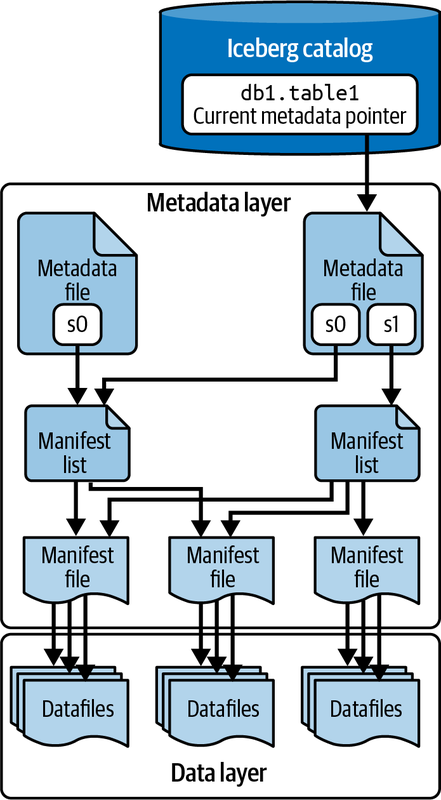
其存储结构如图(图出自Oreilly电子书Apache Iceberg: The Definitive Guide)所示,主要分为三层:
- 数据层:真正存储数据的地方,是文件格式无关的,可以支持parquet/avro等格式,但是更推荐parquet因为它基本上是OLAP存储的业界标准,工具支持非常完善。
- 元数据层:有三层元数据来提供表的元数据,并且提供时间旅行、并发控制、查询优化等特性。元数据层的每个文件都是不可修改的,一旦修改,就要创建新的元数据文件,并更新上层元数据(上层元数据也需要写到新的文件),最后替换数据目录中指向顶层表元数据的指针
- 目录层:虽然看起来它不属于Iceberg的范畴,但它在读写Iceberg表中发挥很重要的作用。它是读取Iceberg表的入口,也是修改流程最后一步要更新的地方。
数据层
数据层通常由两种文件构成,数据文件和删除文件(delete file,或者更准确地说叫“修改记录”文件)。
- 数据文件:一般情况下写入的文件都存在于数据文件中。不限制格式,主要有
parquet和avro两种,前者通常适合批处理分析,后者更适合流式数据处理。 - 删除文件:在启用“读时合并”策略,执行
UPDATE/DELETE/MERGE INTO语句删除行或更新已有行数据时产生的数据补丁文件。当读取时发现某一行有多次修改记录,就按顺序执行所有的修改计算其最终值。其记录方式有两种:- 记录修改的行号,相当于物理操作信息,update了哪一行,update完是什么。这种方式在写入时要去原始数据文件中找到对应的行记录,因此写入时开销大,记录的内容也比较多;但是读取时无需过多计算,开销比较小
- 第二种是记录逻辑操作信息,记录了行的命中条件和更新值,比如update的条件是
where a = b,update完是啥样。这种方式写入时无需执行语句找到变更的行,开销小;但读取时需要计算引擎按顺序执行所有的逻辑过滤条件,开销大。
- Puffin file:当iceberg默认的metrics不够用时,可以选择写入额外的puffin file来提供
distinct count的metrics。
元数据层
iceberg提供了三层元数据,从最靠近数据层到最靠近目录层分别是:
- Manifest file:将多个数据文件或删除文件的元数据聚集起来,放在同一个文件中。这样通过读取一个manifest file就可以一次性了解多个数据文件的存储位置、partition分区、metrics比如包含的最大最小值范围,避免列出目录文件或读取多个文件,提高了查询优化时的效率。此外,这些metrics也是在修改表时就立刻写入的,因此metadata时刻保持最新,既减少了后期维护的开销,又避免了数据过时导致查询优化效率下降。
- Manifest list:每个manifest list(以下简称list)都是iceberg表在某个时间点的快照。每个list都会引用多个Manifest file(以下简称file),并包含快照id、快照时间等元数据。
- Metadata file:最顶层的元数据,包含表历史schemas、历史partition、当前version、当前schema id、当前partition id等信息,以及快照列表(每个快照都会引用一个manifest list)。同一时间点只会有一个生效的metadata file
Iceberg确保表的相关文件都是不可变的,因此每次修改Iceberg表,都会生成一个或多个Manifest file/list,以及一个新的metadata file。
我看到这里的时候有一个小问题,既然Manifest file包含了多个文件的元数据,那何时该创建一个全新的文件写入,何时又该修改(这里的修改指的是读取旧文件,修改后再写一个新的文件,而不是替换旧文件)已有文件呢?我问了大名鼎鼎的GPT,它告诉我Iceberg会根据用户设置来改变默认行为,比如可以设置为尽量避免修改旧文件,每次都写一个新的,这也是默认行为;或者尽量更新旧文件,这样当改变的是已有分区的信息,且文件大小不超过上限时直接修改旧文件,这样可以减少过多碎片文件。
目录层
目录层存储的方式与具体使用的数据目录有关,比如文件型数据目录(比如用Hadoop作为数据目录),存储的就是某个固定的文件;服务型数据目录就会修改表元信息的某个特定字段等。但是不论格式如何,最重要的是存储指向当前metadata file的指针(路径)。
每次修改Iceberg表的最后一步都是更新数据目录,将表的指针替换为最新的路径并写入metadata file。因此要求数据目录必须提供CAS功能,否则无法iceberg无法正常工作。
存储结构与iceberg特性
了解完数据组织的方式,我们做一个小小的总结,把iceberg的特性与其存储结构关联起来:
-
行级数据操作:通过写时复制或者读时合并两种机制实现,前者会在每次写入时都将新的修改与旧数据合并,并生成新的文件;后者会用delete file记录变更的行信息,然后在读取的时候动态计算出最终的结果
-
时间旅行和回滚更改:首先已有的数据文件和元数据文件都是不可变的,这确保了只要能了解某个时间点包含的数据文件和元数据即可实现快照查询,而快照的元数据入口即为manifest list;其次metadata file里包含了快照列表,这确保了每次修改记录都会被记录下来。因此快照读的实现就简化为从metadata file找到该时刻之前,最近一次修改的manifest list,并读取相应数据。另外读写也不会相互阻塞。
-
并发修改:对于数据文件,数据文件都不可修改不可替换,因此读取同一路径的数据文件,不会出现不一致的情况;关于元数据,iceberg乐观地生成所有元数据文件并在最后一步——数据目录替换表指针时,使用CAS操作确保在读取表信息和提交修改之间没有其它的修改出现。
-
高性能读取:在表很大时,通过Manifest file可以避免读取每个文件中的元数据来提高剪枝效率,进而提高大表查询的效率
-
Schema/partition演化:我们看到metadata file里存储了历史schema和历史partition信息,以及当前使用的schema id和partition id,相当于schema/partition的snapshot都存储在metadata file中。因此其演化也比较简单,甚至可以做一些不兼容的操作比如删column。不过出于性能考虑iceberg并不会修改旧数据的schema或partition,新的修改只会在下一次写入时生效
性能优化
Iceberg支持的时间旅行、行级修改等特性虽然很方便,但由于Iceberg表文件的不可变特性,随着时间发展,势必会保留很多不再访问的快照文件、历史数据,或者很多碎片化的元数据文件。因此这一节介绍如何通过一些清理、压缩操作来优化Iceberg的性能。
小文件问题与压缩
OLAP存储系统通常是为了顺序读取大量数据而设计的,大量的小文件(比如<1MB)会非常影响读取效率。小文件有许多产生原因。首先要检查分区策略,比如使用原生的user_id作为分区键,就容易造成分区数量过多。如果希望用user_id分区,又不希望产生太多分区,则可以使用iceberg的transform分区方式,比如使用PARTITIONED BY (bucket(16, user_id))函数来将用户id划分到16个桶内。
排除掉不合理的分区策略的影响,同一分区下也可能有大量小文件,比如:
- Spark通常每个task写入一个文件,而很可能一个分区值的数据被多个task一起处理,造成每个分区的目录下有许多小文件
- 流式处理通常会频繁更新表数据,而iceberg每次提交数据都会添加新的数据文件,并且添加新的manifest file/list,造成metadata快速增加
- UPDATE/DELETE操作引入的delete file
在执行压缩操作时,可以选择不同的压缩算法:
- binPack:将各个小文件的数据拼接在一起成为大文件,只会在task内部(也就是单文件级别)做局部排序,不会进行全局排序操作。它的压缩过程很快,但是读取性能不如全局排序后的提升大。
- sort:全局排序,类似于计算引擎生成数据时的排序键。
- zOrder:使用zOrder排序数据。它是一种优化多维查询的算法,目标是为了让多维空间内比较接近的向量放的近一点,这样能照顾到各个维度查询的性能(但实际上造成哪个维度的查询性能都不是特别好)。这是一种公开的排序算法,如果感兴趣可以自行搜索探究。
要注意,即使是binPack级别,虽然没有全局排序,但每个task也将多个小文件合并成了一个大文件,而且大文件内部是排好序的,因此依然提升了性能。
除了压缩算法之外,还可以设定以下这些参数:
- 用
filter参数来过滤无用的值等,比方只压缩近一年的数据; - Partial Progress:支持在压缩过程中多次提交已经压缩的部分文件组,并对用户可见。一方面可以让用户快速使用已压缩文件的性能提升,另一方面可以减少需要在内存里维护的任务信息,避免OOM。
- 设定数据文件的参数,比如
rowGroupSize,每个文件最大大小等。对于iceberg表格式来说,由于大部分的谓词下推是使用iceberg的元数据而非parquet的metadata,也就是通常谓词下推优化是为了减少读取的文件个数,因此一个文件内包含过多的rowGroup可能对iceberg表的读取性能影响不大;
如果希望实现自动压缩,则可以借助一些pipeline工具或者定时服务来触发压缩任务。
排序和分区
大家都知道排序过的数据查询时很高效,比如进行点查询的时间复杂度是O(LogN)。但在OLAP领域不会使用BTree这样的结构来维护数据的有序性,而每次写入都重新全局排序又太浪费时间,因此需要时不时地通过压缩整理过程来将数据变得更有序。
相比于排序是全局性的、细粒度的整理,分区则是粗粒度的分类。一般来说,像iceberg和spark,写入数据时,会给每个数据分区键的枚举值(比如key1=1, key2=3,会枚举每种值而不是将一定范围的值划入同一文件夹下)都创建单独的文件夹,然后将分区相关的数据都放在这个文件夹下。因此每次写入数据时都会遵循表的分区策略,而不像排序需要定期压缩维护。
Hidden partition
Iceberg支持隐式分区键,即不用为分区而在schema里加上物理的分区键,而是用一些转换函数从已有的列计算出分区键。经典的例子是如果我们有一个时间戳列,我们可以。常用的分区转换函数有:
- 时间相关:year, month, day, hour
- 字符串相关:truncate
- 范围分桶:bucket
Metrics Collection
iceberg默认会收集以下的metrics:
- count,null count,distinct count
- 上下界
当表太宽(比如大于100列)时,metadata里包含的内容可能很多,而manifest file一般存储上限是1MB,因此manifest file的数量可能也会增加,造成性能下降。此时可以指定只收集某些column的metrics,减少无用的元数据。
压缩manifests
默认情况下,iceberg在写入数据时会倾向于新建一个新的manifest文件,因此manifest文件的数量可能会因为写入次数的增加而急剧增加,而manifest文件的数量严重影响读取时的性能。因此如果数据文件大小比较合适,但manifest文件太多(比方说每个manifest里只记录不到10个数据文件),就可以压缩manifest文件。
清除无用快照和孤儿文件
还记得我们之前说的,iceberg表为每次修改都创建一个快照吗?长久以往,快照的数量会慢慢增多,填满我们的存储空间,因此需要定期清理老旧的快照。此外,当进行了一次压缩操作,iceberg会为压缩后的数据新创建一个(或多个,取决于是否允许部分提交)快照,这意味着即使新快照和旧快照的数据包含的内容是一样的,iceberg也会继续保存未压缩的数据,用于快照读。
这里要注意,清除旧的快照不意味着以前写入的数据就无法读取了,而是意味着如果曾经对旧数据做了一些修改,那再也无法回到修改前的状态。清除旧数据是在压缩过程中,通过指定filter做的。
可以使用如下命令清理某个时间戳以前的快照,但至少要保留最近的100个快照
CALL catalog.system.expire_snapshots('MyTable', TIMESTAMP '2023-02-01
00:00:00.000', 100)
除了无用快照,孤儿文件是由失败任务写入的,它们通常只有数据文件,而并没有被iceberg表的元数据记录。可以使用如下命令清理某个表的孤儿文件
CALL catalog.system.remove_orphan_files(table => 'MyTable')
数据分布模式
Spark的task数量和并行度(比如使用了repartition指定并行度)数量相同,而默认会为每个有数据的分区写入一个文件。这意味着如果有10个任务,每个任务都包含了所有分区的数据,那每个分区文件夹下最终都会有10个文件,造成小文件问题。
数据分布模式就是为了解决这一问题,它可以让同一写入分区的数据都尽量被少量task处理,这样每个分区内的文件数量会减少。
可以设置分布模式为hash,range或者none。其中none指的是随意,基本上就是遵循数据源的分区策略。假如数据无需按写入分区键排序,或者数据已经排序了,选择none就好。
解决对象存储系统的前缀限流
有时对象(文件)存储系统会对读取相同前缀的文件限流,反映到实际目录结构就是对读写目录的总体流量限流。但默认情况下表数据都存储于同一目录下,因此会限制表的读写性能。
iceberg可以为表设定参数来避免限流,比如用以下语句:
ALTER TABLE catalog.MyTable SET TBLPROPERTIES ('write.object-storage.enabled'= true
);
开启后,它会为写入目录的顶层目录加上随机生成的前缀,比如
s3://bucket/4809098/database/table/field=value1/datafile1.parquet
s3://bucket/5840329/database/table/field=value1/datafile2.parquet
布隆过滤器
布隆过滤器可以确定某些值一定不在某个文件内,通常用于加速点查询。parquet格式原生支持布隆过滤器,可以通过以下语句开启col1的布隆过滤器:
ALTER TABLE catalog.MyTable SET TBLPROPERTIES ('write.parquet.bloom-filter-enabled.column.col1'= true,'write.parquet.bloom-filter-max-bytes'= 1048576
);
附录
读写Iceberg的例子
计算引擎如Spark,Flink,Presto等都支持读写Iceberg表。具体示例可以从官方文档中找到Spark and Iceberg Quickstart - Apache Iceberg™,故而不再赘述。
额外提一下,读取操作是支持快照读的,如果有需要可以特别查询快照读的语法。