TensorFlow深度学习实战(39)——机器学习实践指南
TensorFlow深度学习实战(39)——机器学习实践指南
- 0. 前言
- 1. 深度学习最佳实践
- 2. 数据最佳实践
- 2.1 特征选择
- 2.2 特征和数据
- 2.3 增强文本和语音数据
- 3. 模型最佳实践
- 3.1 基准模型
- 3.2 预训练模型、模型API和AutoML
- 4. 模型评估和验证
- 5. 模型改进
- 小结
- 系列链接
0. 前言
机器学习不仅仅是构建和训练模型,在本节中,我们将介绍机器学习中的最佳实践,旨在提高模型性能、可靠性和可维护性。
1. 深度学习最佳实践
深度学习算法不仅是一个活跃的研究领域,也是许多商业系统和产品不可或缺的一部分。从医疗保健到虚拟助手,从房间清洁机器人到自动驾驶汽车,人工智能 (Artificial Intelligence, AI) 现在是许多重要技术进步的推动力。AI 已经可以用于决定一个人是否应该被聘用,或者生成社交媒体内容。由于一个成功模型从构建到部署的复杂性,建立最佳实践非常重要,最佳实践并没有明确的答案,因为机器学习中的最佳实践取决于具体的问题和数据集。在本节中,我们将介绍一些关于机器学习最佳实践的一般性建议。
机器学习最佳实践十分重要:
- 确保模型的构建既有效又高效
- 避免过拟合等问题,从而提高模型在未见过的数据上的表现
- 确保模型可解释,并能轻松向非技术受众解释
- 促进机器学习研究的可重复性
接下来,介绍一些常见的最佳实践,遵循这些建议可以避免常见的错误,从而避免不准确或不良结果。遵循最佳实践有助于确保 AI 模型准确可靠,并优化 AI 模型的性能和效率。
2. 数据最佳实践
在当今世界,数据变得越来越重要,数据正在成为驱动全球经济的“新石油”。数据在决策过程、交通管理、供应链问题处理、医疗支持等方面发挥着重要作用。
最重要的是,数据可以用于揭示其内在规律。例如,在商业中,数据可以用来识别新趋势。在医学中,数据可以用来发现疾病之间的新关系,并开发新的治疗方法。模型与其训练所用的数据的质量息息相关,随着数据变得越来越易于获取,数据的重要性还会继续增加。
2.1 特征选择
在处理任何 AI 问题时,遇到的第一个问题就是,哪些输入特征可以用于分类或预测。选择正确的特征对任何机器学习模型都是至关重要的,但确定选择哪些特征可能很困难。如果在模型中包含了太多不相关的特征,结果可能不准确;如果特征过少,模型可能无法从数据中学习。因此,特征选择是机器学习中的关键步骤,有助于减少噪音并提高模型的准确性:
- 原始特征:在进行任何特征工程之前,应该首先使用原始特征,而不是使用学习得到的特征。学习得到的特征是通过外部系统(如聚类算法)或深度模型本身生成的特征。使用原始特征可以获得一个稳定的基线性能,之后可以尝试更复杂的策略
- 移除未使用的特征:未使用的特征会使代码难以阅读和维护,还可能导致意外的错误和安全漏洞。当然,跟踪哪些特征正在使用,哪些未使用可能很困难,但不要随意丢弃特征,在进行数据分析和探索了解特征后再决定丢弃哪些特征。通过理解和移除未使用的特征,可以保持代码的整洁
- 特征数量与模型质量:我们常常会错误的认为更多的特征可以创建更好的模型,但这并非事实。与其使用数百万个特征,不如专注于特定特征,可以使用正则化方法移除部分特征
- 组合和修改特征:可以通过组合和修改特征来创建新特征。组合和修改的方式有很多,例如,可以将连续值特征离散化成多个离散特征。还可以通过交叉多个现有特征来创建合成的新特征。例如,如果有“身高”和“体重”这两个特征,可以通过组合这两个特征创建一个新的特征。特征交叉可以提供超出单个特征能力的预测能力,这是因为组合特征捕捉了单个特征所未能捕捉的信息,特征交叉可以帮助提高预测模型的准确性
2.2 特征和数据
当我们尝试利用深度学习解决实际问题时,面临的一个主要问题是数据的缺乏。尽管互联网、移动设备和物联网设备生成了大量数据,但获得高质量的标注数据仍然具有挑战性。数据标注的成本通常既高昂又耗时,并且需要专业知识。
我们需要确保有足够的数据来训练模型,模型可以学习的输入特征数量 nnn 大致与数据量 NNN 成正比 n≪Nn \ll Nn≪N:
- 根据数据规模调整模型学习规模。例如,如果只有
1,000个标注样本,那么应使用精心设计的特征工程,好的特征数量大约只有十几个;如果有数百万个样本,那么可以使用大约数十万个特征;如果有数十亿个数据样本,则可以构建包含数百万个特征的模型 - 不应随意丢弃数据:如果数据量过大,可以使用重要性加权采样,基本思想是根据某种分布特征为每个样本分配重要性权重,以捕捉数据的相似性
- 数据增强。使用数据增强是应对数据不足的另一种方法,利用简单的图像变换可以有效的增加图像数据,如水平翻转、垂直翻转、旋转、平移等。大多数深度学习框架都具有数据生成器,可以用于执行图像数据增强
在主流的深度学习框架中内置了图像数据增强方法,但通常并未包含文本数据增强和音频数据增强方法。接下来,介绍一些用于增强文本和语音数据的技术。
2.3 增强文本和语音数据
增强文本数据的方法包括:
- 同义词替换:从句子中随机选择单词,并使用同义词替换。例如,如果有句子 “The movie was incredibly entertaining.”,可以选择加粗的两个词进行同义词替换,得到:“The film was remarkably entertaining.”
- 回译:基本思路是将句子翻译成另一种语言,然后再翻译回原始语言,可以使用语言翻译
API。例如,将句子从英语翻译成中文,然后再翻译回英语
from googletrans import Translator
translator = Translator()
text = 'We discuss the existing problems and challenges in AI.'
translated = translator.translate(text, src='en', dest='zh-cn')
synthetic_text = translator.translate(translated.text, src='zh-cn', dest='en')
print(f'text: {text}\nTranslated: {translated.text}\nSynthetic Text: {synthetic_text.text}')
# We discuss the problems and challenges in artificial intelligence.
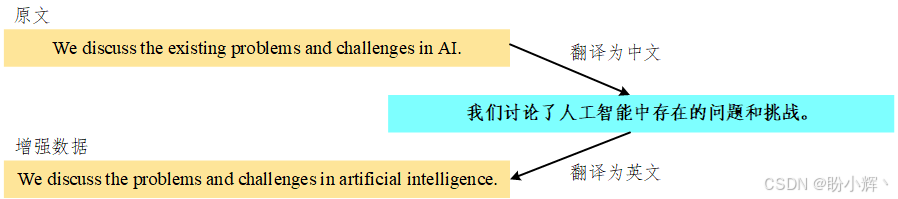
因此,上述两个句子:“We discuss the existing problems and challenges in AI.” 和 “We discuss the problems and challenges in artificial intelligence.” 属于同一类别,上图详细描述了使用回译进行数据增强的过程。近年来,随着大语言模型成功,研究人员开始尝试它们用于数据增强。
语音数据可以使用以下技术进行增强:
- 时间扭曲 (
Time warping):随机选择一个点,将数据向左或右扭曲,距离 www 从均匀分布 [0,W][0, W][0,W] 中选择 - 频率掩码 (
Frequency Masking):掩码一段频率通道 [f0,f0+f)][f_0, f_0+f)][f0,f0+f)],选择的频率 f0f_0f0 和 fff 取决于频率通道的数量和频率掩码参数 FFF - 时间掩码 (
Time Masking):掩码连续的时间步
3. 模型最佳实践
模型性能对深度学习的成功至关重要。如果模型性能不加,相关的应用也不会成功,因此,需要重点关注模型性能。影响模型准确性和性能的因素有很多,了解这些因素对于优化模型性能至关重要。
3.1 基准模型
基准模型是机器学习中用于评估其他模型的工具,通常是最简单模型,充当更复杂模型的比较基点,目标是观察更复杂的模型是否在实际表现上优于基准模型。如果没有提升,那么使用更复杂的模型就没有意义。基准模型还可以用于检测数据泄漏,数据泄漏是指测试集中的信息渗入训练集,导致过拟合。通过比较基线模型与其他模型的表现,可以检测是否发生了数据泄露。基准模型是机器学习中不可或缺的一部分,因此,每当我们开始处理一个新问题时,考虑一个最简单的适合数据的模型并建立基准模型是非常必要的。一旦建立了合适的基准模型,就需要考虑以下方面。
观察数据集的初始假设和初始算法的选择。例如,可能在开始处理数据时,假设数据模式最适合用高斯混合模型 (Gaussian Mixture Model, GMM),但经过进一步探索后,可能发现 GMM 不能准确捕捉数据的潜在结构。在这种情况下,需要重新考虑策略。最终,选择的算法由数据本身的性质决定。
确认模型是否过拟合或欠拟合。如果模型过拟合,可以尝试增加数据量、降低模型复杂性、增加批处理大小,或使用正则化方法,如岭回归、Lasso 回归或 dropout。如果模型欠拟合,可以尝试增加模型复杂性、添加更多特征,并训练更多 epoch。
根据性能指标分析模型。例如,如果是分类模型,分析其混淆矩阵及其精度/召回率。识别哪些类别模型没有正确预测,能够提供对这些类别数据的深入了解。
执行超参数调优以获得强大的基准模型。建立强大的基准模型非常重要,因为它为未来模型改进提供了基准。基准应包含所有业务和技术要求,并测试模型部署流程。通过开发一个强大的基准,可以确保机器学习模型朝正确方向发展。此外,一个好的基准可以帮助我们再迭代模型时识别可能的改进方向。
3.2 预训练模型、模型API和AutoML
在处理新项目时,从头开始训练基准模型可能非常耗时。但使用预训练模型可以节省大量时间和精力。包括 GitHub、Kaggle,以及来自谷歌、OpenAI、微软和百度等公司的各种 API。
此外,还有一些相关领域初创公司,如 Scale AI 和 Hugging Face,提供适用于不同任务的预训练模型。利用这些资源,可以快速启动机器学习项目,而无需从头开始训练模型。因此,如果我们的任务是标准的分类或回归问题,或者数据是结构化的表格数据,可以利用预训练模型或谷歌、微软和百度等公司提供的 API,节省大量时间和精力。
另一种解决方案是使用自动机器学习 (AutoML)。借助 AutoML,可以创建更符合具体需求的定制模型,可以通过利用 AutoML 来实现大规模的机器学习。
4. 模型评估和验证
在本节中,我们讨论评估模型的方法,我们并不介绍常规的机器学习指标,而是关注最终用户的体验:
- 用户体验技术:当模型接近生产阶段时,应该进一步进行测试,在模型部署前获取用户反馈。例如,如果我们构建了一个推荐系统,可以通过邀请实际用户进行可用性测试
- 使用模型差异:部署新模型时,衡量其成功的最佳方法之一是计算其与已部署的模型的差异。例如,如果我们的排序算法给出的结果好于预期,但并不明显,那么我们应该在整个系统中对样本运行两个模型,并根据排名给予权重。如果发现两者之间的差异很小,就可以得知模型性能变化不大;但如果差异很大,我们应该确保变化朝性能提升方向进行。我们应探索差异较大的样本,以便定性地了解变化
- 实用性比预测能力更重要:我们可能有一个具有最高准确率和最佳预测的模型,但这并不是终点;关键是如何利用这些预测。例如,假设我们建立了一个垃圾邮件过滤器,模型预测给定消息是垃圾邮件还是正常邮件的概率;接下来,我们会根据这些预测决定屏蔽哪些文本,在这种情况下,允许通过过滤器的内容更为重要,因此,可能我们获得了一个具有更小损失值的模型,但整体表现并没有改善,在这种情况下,我们需要寻找其他特征以提升性能
- 寻找测量误差中的模式:在训练样本中,检查模型无法正确预测的样本。探索我们尚未考虑的特征,观察使用这些特征是否能改善对不正确样本的预测,我们可以添加多个特征,让模型决定如何使用它们。为了可视化分类问题中的错误,我们可以使用混淆矩阵;在回归任务中,我们可以查看损失较高的情况
- 在未见数据上测试:为了评估模型的性能,我们应在模型训练后收集的数据上进行测试;这样可以估算模型在实际环境中的表现。模型在未见数据上的性能会有所下降,但下降程度不应过于严重
性能监控是模型开发的关键部分。训练数据和生产数据之间的性能可能会有很大差异,这意味着我们必须持续监控已部署模型的行为,确保它们没有出现意外情况。我们应建立一个监控流程,持续监控性能、质量和误差指标以及用户交互。
5. 模型改进
建立并部署了优秀的模型后,工作仍远未结束。模型可能需要因各种原因进行更改,例如数据漂移或概念漂移。数据漂移是指数据分布随时间变化,而概念漂移则是指标签的特性随时间变化。为了应对这些变化,模型必须在新数据上重新训练并进行相应更新。这个过程可能耗时且成本高,但对于维持高性能的机器学习模型至关重要。然而,在进行模型改进之前,重要的是识别和衡量低性能的原因——“先衡量,后优化”:
- 数据漂移:机器学习模型的性能可能会因训练和部署的时间不同而有所变化。这是因为训练和服务时使用的数据可能不同,为了避免这个问题,重要的是在部署时记录特征。监控服务生产环境数据的变化,一旦数据漂移(训练数据与生产环境数据之间的差异)超过某个阈值,我们应使用新数据重新训练模型。确保模型在与其部署环境相同的数据上进行训练,从而提高性能
- 训练-服务偏差:训练-服务偏差是机器学习模型的主要问题。如果模型的训练方式与实际使用方式存在差异,可能导致性能不佳。训练-服务偏差的主要原因有三种:训练和服务中使用的数据之间的差异、数据发生变化,以及模型之间的反馈循环。例如,如果我们构建了一个推荐系统来推荐电影,之后可以根据用户从推荐列表中观看的电影来重新训练推荐系统。前两种原因可以通过数据管理来解决,而第三种原因需要在设计机器学习模型时予以考虑
可能即使经过充分的实验,当前使用的特征仍无法进一步提高模型性能。然而,对于实际应用而言,持续改进是必要的。因此,当我们发现模型性能达到瓶颈时,就该寻找新的改进途径,而不是继续使用现有的特征。
软件开发过程永远没有真正“完成”。即使在产品发布之后,总会有新的功能可以添加或现有功能可以改进,机器学习模型同样如此。即使模型“完成”并部署到生产环境中,仍然会有新的数据可以用来训练更好的模型。随着时间的推移,数据会发生变化,模型也需要在新数据上重新训练以保持准确性。因此,重要的是将机器学习模型视为处于不断变化的状态。
在构建模型时,考虑添加或移除特征的难易程度非常重要。我们能否轻松创建全新模型并验证其正确性?是否可能同时运行两个或三个模型副本?这些都是在构建模型时需要考虑的重要因素。提前考虑这些问题,可以在后续节省大量时间和精力。
小结
在本节中,我们讨论了获取最佳模型性能的策略和最佳实践,随着人工智能技术的不断成熟,规则和最佳实践可能也会随之变化。但如果遵循本节的最佳实践,能够得到更可靠、更鲁棒的人工智能模型。
系列链接
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(2)——使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)——深度学习中常用激活函数详解
TensorFlow深度学习实战(4)——正则化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(6)——回归分析详解
TensorFlow深度学习实战(7)——分类任务详解
TensorFlow深度学习实战(8)——卷积神经网络
TensorFlow深度学习实战(9)——构建VGG模型实现图像分类
TensorFlow深度学习实战(10)——迁移学习详解
TensorFlow深度学习实战(11)——风格迁移详解
TensorFlow深度学习实战(12)——词嵌入技术详解
TensorFlow深度学习实战(13)——神经嵌入详解
TensorFlow深度学习实战(14)——循环神经网络详解
TensorFlow深度学习实战(15)——编码器-解码器架构
TensorFlow深度学习实战(16)——注意力机制详解
TensorFlow深度学习实战(17)——主成分分析详解
TensorFlow深度学习实战(18)——K-means 聚类详解
TensorFlow深度学习实战(19)——受限玻尔兹曼机
TensorFlow深度学习实战(20)——自组织映射详解
TensorFlow深度学习实战(21)——Transformer架构详解与实现
TensorFlow深度学习实战(22)——从零开始实现Transformer机器翻译
TensorFlow深度学习实战(23)——自编码器详解与实现
TensorFlow深度学习实战(24)——卷积自编码器详解与实现
TensorFlow深度学习实战(25)——变分自编码器详解与实现
TensorFlow深度学习实战(26)——生成对抗网络详解与实现
TensorFlow深度学习实战(27)——CycleGAN详解与实现
TensorFlow深度学习实战(28)——扩散模型(Diffusion Model)
TensorFlow深度学习实战(29)——自监督学习(Self-Supervised Learning)
TensorFlow深度学习实战(30)——强化学习(Reinforcement learning,RL)
TensorFlow深度学习实战(31)——强化学习仿真库Gymnasium
TensorFlow深度学习实战(32)——深度Q网络(Deep Q-Network,DQN)
TensorFlow深度学习实战(33)——深度确定性策略梯度
TensorFlow深度学习实战(34)——TensorFlow Probability
TensorFlow深度学习实战(35)——概率神经网络
TensorFlow深度学习实战(36)——自动机器学习(AutoML)
TensorFlow深度学习实战(37)——深度学习的数学原理
TensorFlow深度学习实战(38)——常用深度学习库