第2章 线程同步精要
并发编程有两种基本模型,一种是message passing,另一种是shared memory。在分布式系统中,运行在多台机器上的多个进程的并行编程只有一种实用模型:message passing[注:Parallel Virtual Machine 似乎已经退出主流 HPC了。]。在单机上,我们也可以照搬message passing作为多个进程的并发模型。这样整个分布式系统的架构的一致性很强,扩容(scale out)起来也较容易。在多线程编程中,message passing更容易保证程序的正确性,有的语言只提供这一种模型。不过在用C/C++编写多线程程序时,我们仍然需要了解底层的shared memory模型下的同步原语,以备不时之需。本章不是多线程教程[注:教程可参考:https://computing.llnL.gov/tutorials/pthreads],而是个人经验总结,分享一些C++多线程编程的经验。本章多次引用《Real-World Concurrency》一文的观点,这篇文章的地址是http://queue.acm.org/detail.cfm?id=1454462,后文简称[RWC]。
线程同步的四项原则,按重要性排列:
1.首要原则是尽量最低限度地共享对象,减少需要同步的场合。一个对象能不暴露给别的线程就不要暴露;如果要暴露,优先考虑immutable对象;实在不行才暴露可修改的对象,并用同步措施来充分保护它。
2.其次是使用高级的并发编程构件,如TaskQueue、Producer-Consumer Queue、CountDownLatch等等。
3.最后不得已必须使用底层同步原语(primitives)时,只用非递归的互斥器和条件变量,慎用读写锁,不要用信号量。
4.除了使用atomic整数之外,不自己编写lock-free代码[注:[RWC]: Use wait- and lock-free structures only if you absolutely must.],也不要用“内核级”同步原语[注:http://www.thinkingparallel.com/2007/02/19/please-dont-rely-on-memory-barriers-for-synchronization/][注:http://zaitcev.livejournal.com/144041.html
https://www.kernel.org/doc/Documentation/volatile-considered-harmful.txt]。不凭空猜测“哪种做法性能会更好”,比如spin lock vs.mutex。
前面两条很容易理解,这里着重讲一下第3条:底层同步原语的使用。
2.1 互斥器(mutex)
互斥器(mutex)[注:请注意,本书谈的是 Pthreads里的mutex,不是Windows里的重量级跨进程Mutex 内核对象。]恐怕是使用得最多的同步原语,粗略地说,它保护了临界区,任何一个时刻最多只能有一个线程在此mutex划出的临界区内活动。单独使用mutex时,我们主要为了保护共享数据。我个人的原则是:
● 用RAII手法封装mutex的创建、销毁、加锁、解锁这四个操作。用RAII封装这几个操作是通行的做法,这几乎是C++的标准实践,后面我会给出具体的代码示例,相信大家都已经写过或用过类似的代码了。Java里的synchronized语句和C#的lock语句也有类似的效果,即保证锁的生效期间等于一个作用域(scope),不会因异常而忘记解锁。
● 只用非递归的mutex(即不可重入的mutex)。
● 不手工调用lock()和unlock()函数,一切交给栈上的Guard对象的构造和析构函数负责。Guard对象的生命期正好等于临界区(分析对象在什么时候析构是C++程序员的基本功)。这样我们保证始终在同一个函数同一个scope里对某个mutex加锁和解锁。避免在foo()里加锁,然后跑到bar()里解锁;也避免在不同的语句分支中分别加锁、解锁。这种做法被称为Scoped Locking [注:见Douglas Schmidt 的论文:https://www.cs.wustl.edu/-schmidt/PDF/locking-patterns.pdf]。
● 在每次构造Guard对象的时候,思考一路上(调用栈上)已经持有的锁,防止因加锁顺序不同而导致死锁(deadlock)。由于Guard对象是栈上对象,看函数调用栈就能分析用锁的情况,非常便利。
次要原则有:
● 不使用跨进程的mutex,进程间通信只用TCP sockets。
● 加锁、解锁在同一个线程,线程a不能去unlock线程b已经锁住的mutex(RAII自动保证)。
● 别忘了解锁(RAII自动保证)。
● 不重复解锁(RAII自动保证)。
● 必要的时候可以考虑用PTHREAD_MUTEX_ERRORCHECK来排错。
mutex恐怕是最简单的同步原语,按照上面的几条原则,几乎不可能用错。我自己从来没有违背过这些原则,编码时出现问题都很快能定位并修复。
2.1.1 只使用非递归的mutex
谈谈我坚持使用非递归的互斥器的个人想法。
mutex分为递归(recursive)和非递归(non-recursive)两种,这是POSIX的叫法,另外的名字是可重入(reentrant)与非可重入。这两种mutex作为线程间(inter-thread)的同步工具时没有区别,它们的唯一区别在于:同一个线程可以重复对recursive mutex加锁,但是不能重复对non-recursive mutex加锁。
首选非递归mutex,绝对不是为了性能,而是为了体现设计意图。non-recursive和recursive的性能差别其实不大,因为少用一个计数器,前者略快一点点而已。在同一个线程里多次对non-recursive mutex加锁会立刻导致死锁,我认为这是它的优点,能帮助我们思考代码对锁的期求,并且及早(在编码阶段)发现问题。
毫无疑问recursive mutex使用起来要方便一些,因为不用考虑一个线程会自己把自己给锁死了,我猜这也是Java和Windows默认提供recursive mutex的原因。(Java语言自带的intrinsic lock是可重入的,它的util.concurrent库里提供ReentrantLock,Windows的CRITICAL_SECTION也是可重入的。似乎它们都不提供轻量级的non-recursive mutex。)
正因为它方便,recursive mutex可能会隐藏代码里的一些问题。典型情况是你以为拿到一个锁就能修改对象了,没想到外层代码已经拿到了锁,正在修改(或读取)同一个对象呢。来看一个具体的例子(recipes/thread/test/NonRecursiveMutex_test.cc):
MutexLock mutex;
std::vector<Foo> foos;
void post(const Foo& f)
{MutexLockGuard lock(mutex);foos.push_back(f);
}
void traverse()
{MutexLockGuard lock(mutex);for(std::vector<Foo>::const_iterator it = foos.begin();it != foos.end(); ++it){it->doit();}
}post()加锁,然后修改foos对象;traverse()加锁,然后遍历foos向量。这些都是正确的。将来有一天,Foo::doit()间接调用了post(),那么会很有戏剧性的结果:
1.mutex是非递归的,于是死锁了。
2.mutex是递归的,由于push_back()可能(但不总是)导致vector迭代器失效,程序偶尔会crash。
这时候就能体现non-recursive的优越性:把程序的逻辑错误暴露出来。死锁比较容易debug,把各个线程的调用栈打出来[注:gdb 中使用thread apply all bt命令],只要每个函数不是特别长,很容易看出来是怎么死的,见§ 2.1.2的例子[注:另一方面支持了“函数不要写得过长”这一观点。]。或者可以用PTHREAD_MUTEX_ERRORCHECK一下子就能找到错误(前提是MutexLock带debug选项)。程序反正要死,不如死得有意义一点,留个“全尸”,让验尸(post-mortem)更容易些。
如果确实需要在遍历的时候修改vector,有两种做法,一是把修改推后,记住循环中试图添加或删除哪些元素,等循环结束了再依记录修改foos;二是用copy-on-write,见§2.8的例子。
如果一个函数既可能在已加锁的情况下调用,又可能在未加锁的情况下调用,那么就拆成两个函数:
1.跟原来的函数同名,函数加锁,转而调用第2个函数。
2.给函数名加上后缀WithLockHold,不加锁,把原来的函数体搬过来。就像这样:
void post(const Foo& f)
{MutexLockGuard lock(mutex);postWithLockHold(f); // 不用担心开销,编译器会自动内联的
}
// 引入这个函数是为了体现代码作者的意图, 尽管push_back通常可以手动内联
void postWithLockHold(const Foo& f)
{foos.push_back(f);
}这有可能出现两个问题(感谢水木网友ilovecpp提出):
(a)误用了加锁版本,死锁了。
(b)误用了不加锁版本,数据损坏了。
对于(a),仿造§ 2.1.2的办法能比较容易地排错。对于(b),如果Pthreads提供isLockedByThisThread()就好办,可以写成:
void postWithLockHold(const Foo& f)
{assert(mutex.isLockedByThisThread()); //muduo::MutexLock提供了这个成员函数//..
}另外,WithLockHold这个显眼的后缀也让程序中的误用容易暴露出来。
C++没有annotation,不能像Java那样给method或field标上@GuardedBy注解,需要程序员自己小心在意。虽然这里的办法不能一劳永逸地解决全部多线程错误,但能帮上一点是一点了。
我还没有遇到过需要使用recursive mutex的情况,我想将来遇到了都可以借助wrapper改用non-recursive mutex,代码只会更清晰。
Pthreads的权威专家,《Programming with POSIX Threads》的作者David Butenhof也排斥使用recursive mutex。他说:[注:http://zavalorg/resources/library/butenhof1.html]
First,implementation of efficient and reliable threaded code revolves around one simple and basic principle:follow your design.That implies,of course,that you have a design,and that you understand it.
A correct and well understood design does not require recursive mutexes.(后略)
回到正题。本文这里只谈了mutex本身的正确使用,在C++里多线程编程还会遇到其他一些race condition,请参看第1章。
性能注脚:Linux的Pthreads mutex采用futex(2)实现[注:https://www.akkadia.org/drepper/futex.pdf],不必每次加锁、解锁都陷入系统调用,效率不错。Windows的CRITICAL_SECTION也是类似的,不过它可以嵌入一小段spin lock。在多CPU系统上,如果不能立刻拿到锁,它会先spin一小段时间,如果还不能拿到锁,才挂起当前线程[注:https://learn.microsoft.com/zh-cn/windows/win32/sync/critical-section-objects?redirectedfrom=MSDN]。
--------------------------------分隔线-----------------------------
笔记:
//NonRecursiveMutex_test.cpp
#include <thread>
#include <mutex>
#include <vector>
#include <stdio.h>using namespace std;class Foo
{public:void doit() const;
};std::mutex g_mutex;
std::vector<Foo> foos;void post(const Foo& f)
{printf("post================%p\n", &f);std::lock_guard<std::mutex> lock(g_mutex);foos.push_back(f);printf("post============foos====%ld\n", foos.size());
}void traverse()
{printf("traverse===============1=\n");std::lock_guard<std::mutex> lock(g_mutex);printf("traverse============foos====%ld\n", foos.size());for (std::vector<Foo>::const_iterator it = foos.begin();it != foos.end(); ++it){it->doit();}printf("traverse===============2=\n");
}void Foo::doit() const
{Foo f;post(f);
}int main()
{Foo f;post(f);traverse();
}编译运行:
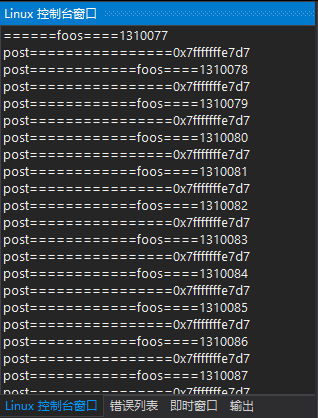
这个代码从理论上来说一定是死锁的,但用VS2019编译Linux平台时并没有产生死锁的效,
原因可能:在Linux环境下没有做线程安全性检查,直接跳过了,
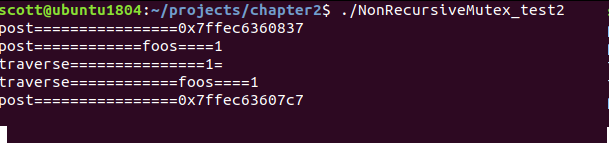
在Ubuntu环境下用g++ -fsanitize=thread -g NonRecursiveMutex_test.cpp -o NonRecursiveMutex_test2
这个时假生成的程序就会检测死锁了
--------------------------------分隔线-----------------------------
2.1.2 死锁
前面说过,如果坚持只使用Scoped Locking,那么在出现死锁的时候很容易定位。考虑下面这个线程自己与自己死锁的例子(recipes/thread/test/SelfDeadLock.cc)。
class Request
{
public:void process() // __attribute_—— ((noinline)){muduo::MutexLockGuard lock(mutex_);// ...print(); //原本没有这行,某人为了调试程序不小心添加了。}void print() const // __attribute__ ((noinline)){muduo::MutexLockGuard lock(mutex_);// ...}private:mutable muduo::MutexLock mutex_;
};int main()
{Request req;req.process();
} 在上面这个例子中,原本没有L8,在添加它之后,程序立刻出现了死锁。要调试定位这种死锁很容易,只要把函数调用栈打印出来,结合源码一看,我们立刻就会发现第6帧Request::process()和第5帧Request::print()先后对同一个mutex上锁,引发了死锁。(必要的时候可以加上__attribute__来防止函数inline展开。)
$ gdb ./self_deadlock core
(gdb) bt
#0 __lll_lock_wait()at ../nptl/sysdeps/unix/sysv/linux/x86_64/1owlevellock.S:136
#1 _L_lock 953()from /lib/libpthread.so.0
#2 __pthread_mutex_lock(mutex=0x7fffecf57bf0) at pthread_mutex_lock.c:61
#3 muduo::MutexLock::lock()at test/../Mutex.h:49
#4 MutexLockGuard()at test/../Mutex.h:75
#5 Request::print()at test/SelfDeadLock.cc:14
#6 Request::process()at test/SelfDeadLock.cc:9
#7 main()at test/SelfDeadLock.cc:24要修复这个错误也很容易,按前面的办法,从Request::print()抽取出[注:即extract method重构手法。] Request::printWithLockHold(),并让Request::print()和Request::process()都调用它即可。
再来看一个更真实的两个线程死锁的例子(recipes/thread/test/MutualDeadLock.cc)。
有一个Inventory(清单)class,记录当前的Request对象。[注:为了简单起见,这里没有使用第1章介绍的shared_ptr/weak_ptr来管理Request。]容易看出,下面这个Inventory class的add()和remove()成员函数都是线程安全的,它使用了mutex来保护共享数据requests_。
class Inventory
{
public:void add(Request* req){muduo::MutexLockGuard lock(mutex_);requests_.insert(req);}void remove(Request* req) // __attribute__ ((noinline)){muduo::MutexLockGuard lock(mutex_);requests_.rease(req);}void printAll() const;
private:mutable muduo::MutexLock mutex_;std::set<Request*> requests_;
};Inventory g_inventory; //为了简单起见,这里傅使用了全局对象。Request class与Inventory class的交互逻辑很简单,在处理(process)请求的时候,往g_inventory中添加自己。在析构的时候,从g_inventory中移除自己。目前看来,整个程序还是线程安全的。
class Request
{
public:void process() // __attribute__ ((noinline)){muduo::MutexLockGuard lock(mutex_);g_inventory.add(this);// ...}~Request() __attribute__ ((noinline)){muduo::MutexLockGuard lock(mutex_);sleep(1); // 为了容易复现死锁,这里用了延时g_inventory.remove(this);}void print() const __attribute__ ((noinline)){muduo::MutexLockGuard lock(mutex_);// ...}
private:mutable muduo::MutexLock mutex_;
};Inventory class还有一个功能是打印全部已知的Request对象。Inventory::printAll()里的逻辑单独看是没问题的,但是它有可能引发死锁。
void Inventory::printAll() const
{muduo::MutexLockGuard lock(mutex_);sleep(1); //为了容易复现死锁,这里用了延时for(std::set<Request*>::const_iterator it = requests_.begin();it != requests_.end();++it){(*it)->print();}printf("Inventory::printAll() unlocked\n");
}下面这个程序运行起来发生了死锁:
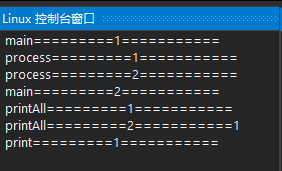
void threadFunc()
{Request* req = new Request;req->process();delete req;
}int main()
{muduo::Thread thread(threadFunc);thread.start();usleep(500 * 1000); //为了让另一个线程等在前面第14行的sleep()上。g_inventory.printAll();thread.join();
}通过gdb查看两个线程的函数调用栈,我们发现两个线程都等在mutex上(__lll_lock_wait),估计是发生了死锁。因为一个程序中的线程一般只会等在condition variable上,或者等在epoll_wait上(p.73)。
$ gdb./mutual_deadlock core
(gdb) thread apply all bt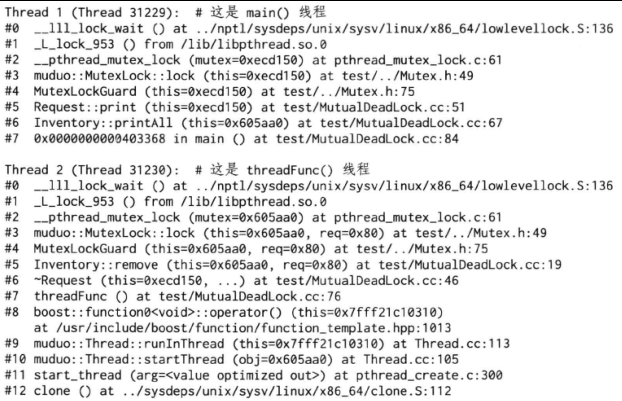
注意到main()线程是先调用Inventory::printAll(#6)再调用Request::print(#5),而threadFunc()线程是先调用Request::~Request(#6)再调用Inventory::remove(#5)。这两个调用序列对两个mutex的加锁顺序正好相反,于是造成了经典的死锁。见图2-1,Inventory class的mutex的临界区由灰底表示,Request class的mutex的临界区由斜纹表示。一旦main()线程中的printAll()在另一个线程的~Request()和remove()之间开始执行,死锁已不可避免。

图2-1
思考:如果printAll()晚于remove()执行,还会出现死锁吗?
练习:修改程序,让~Request()在printAll()和print()之间开始执行,复现另一种可能的死锁时序。
这里也出现了第1章所说的对象析构的race condition,即一个线程正在析构对象,另一个线程却在调用它的成员函数。
解决死锁的办法很简单,要么把print()移出printAll()的临界区,这可以用§ 2.8介绍的办法;要么把remove()移出~Request()的临界区,比如交换p.37中L13和L15两行代码的位置。当然这没有解决对象析构的race condition,留给读者当做练习吧。
思考:Inventory::printAll→Request::print有没有可能与Request::process→Inventory::add发生死锁?
死锁会让程序行为失常,其他一些锁使用不当则会影响性能,例如潘爱民老师写的《Lock Convoys Explained》[注:https://blog.csdn.net/panaimin/article/details/5981766]详细解释了一种性能衰退的现象。除此之外,编写高性能多线程程序至少还要知道false sharing和CPU cache效应,可看脚注中的这几篇文章[http://www.nwcpp.org/Downloads/2007/Machine_Architecture_-_NWCPP.pdf][https://www.aristeia.com/TalkNotes/ACCU2011_CPUCaches.pdf][http://igoro.com/archive/gallery-of-processor-cache-effects][http://simplygenius.net/Article/FalseSharing]。
--------------------------------分隔线-------------------------------------
笔记:
//SelfDeadLock.cpp
#include <iostream>
#include <thread>
#include <mutex>class Request
{
public:
void process() // __attribute__ ((noinline))
{std::cout << "process===============1====" << std::endl;std::lock_guard<std::mutex> lock(mutex_);print();std::cout << "process===============2====" << std::endl;
}void print() const // __attribute__ ((noinline))
{std::cout << "print=================1====" << std::endl;std::lock_guard<std::mutex> lock(mutex_);std::cout << "print=================2====" << std::endl;
}private:
mutable std::mutex mutex_;
};int main()
{Request req;req.process();
}
编译:g++ -fsanitize=thread -g SelfDeadLock.cpp -o SelfDeadLock
运行:

//MutualDeadLock.cpp
#include <iostream>
#include <thread>
#include <mutex>
#include <set>
#include <chrono>class Request;class Inventory
{public:void add(Request* req){std::lock_guard<std::mutex> lock(mutex_);requests_.insert(req);}void remove(Request* req) __attribute__ ((noinline)){std::lock_guard<std::mutex> lock(mutex_);requests_.erase(req);}void printAll() const;private:mutable std::mutex mutex_;std::set<Request*> requests_;
};Inventory g_inventory;class Request
{public:void process() __attribute__ ((noinline)){std::cout << " process=========1===========" << std::endl;std::lock_guard<std::mutex> lock(mutex_);g_inventory.add(this);std::cout << " process=========2===========" << std::endl;}~Request() __attribute__ ((noinline)){std::lock_guard<std::mutex> lock(mutex_);std::this_thread::sleep_for(std::chrono::seconds(1));g_inventory.remove(this);}void print() const __attribute__ ((noinline)){std::cout << " print=========1===========" << std::endl;std::lock_guard<std::mutex> lock(mutex_);std::cout << " print=========2===========" << std::endl;}private:mutable std::mutex mutex_;
};void Inventory::printAll() const
{std::cout << " printAll=========1===========" << std::endl;std::lock_guard<std::mutex> lock(mutex_);std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << " printAll=========2===========" << requests_.size() << std::endl;for (std::set<Request*>::const_iterator it = requests_.begin();it != requests_.end();++it){(*it)->print();}printf("Inventory::printAll() unlocked\n");
}/*
void Inventory::printAll() const
{std::set<Request*> requests{std::lock_guard<std::mutex> lock(mutex_);requests = requests_;}for (std::set<Request*>::const_iterator it = requests.begin();it != requests.end();++it){(*it)->print();}
}
*/void threadFunc()
{Request* req = new Request;req->process();delete req;
}int main()
{//muduo::Thread thread(threadFunc);//thread.start();//usleep( 500* 1000);std::thread trd(threadFunc);std::cout << " main=========1===========" << std::endl;std::this_thread::sleep_for(std::chrono::microseconds(500 * 1000));std::cout << " main=========2===========" << std::endl;g_inventory.printAll();std::cout << " main=========3===========" << std::endl;trd.join();return 0;
}
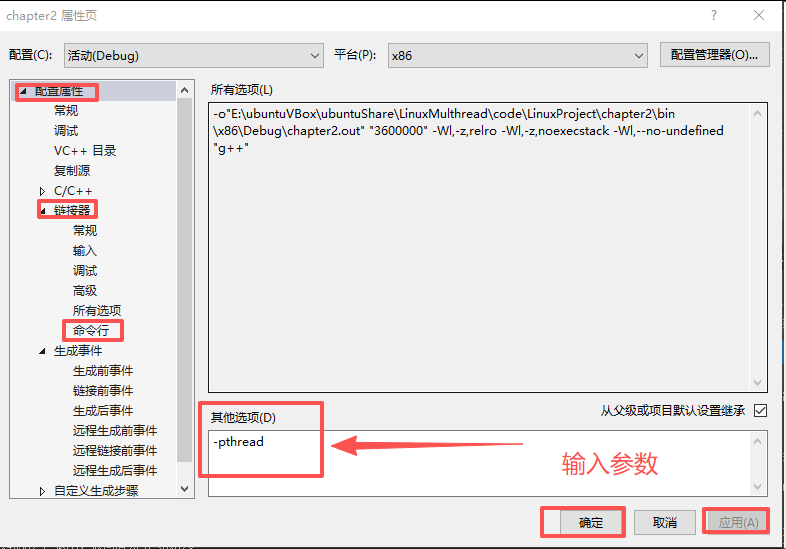
vs2019编译设置:右键工程=》【属性】=》【配置属性】=》【链接器】=》【命令行】输入-pthread参数
编译运行:
--------------------------------分隔线-------------------------------------
2.2 条件变量(condition variable)
互斥器(mutex)是加锁原语,用来排他性地访问共享数据,它不是等待原语。在使用mutex的时候,我们一般都会期望加锁不要阻塞,总是能立刻拿到锁。然后尽快访问数据,用完之后尽快解锁,这样才能不影响并发性和性能。
如果需要等待某个条件成立,我们应该使用条件变量(condition variable)。条件变量顾名思义是一个或多个线程等待某个布尔表达式为真,即等待别的线程“唤醒”它。条件变量的学名叫管程(monitor)。Java Object内置的wait()、notify()、notifyAll()是条件变量[注:Java的这三个函数以容易用错著称,一般建议用 java.util.concurrent 中的同步原语。]。
条件变量只有一种正确使用的方式,几乎不可能用错。对于wait端:
1.必须与mutex一起使用,该布尔表达式的读写需受此mutex保护。
2.在mutex已上锁的时候才能调用wait()。
3.把判断布尔条件和wait()放到while循环中。
写成代码是:
muduo::MutexLock mutex;
muduo::Condition cond(mutex);
std::deque<int> queue;int dequeue()
{MutexLockGuard lock(mutex);while(queue.empty()) //必须用循环;必须在判断之后再wait(){cond.wait(); //这一步会原子地 unlock mutex 并进入等待,不会与enqueue 死锁// wait() 执行完毕时会自动重新加锁}assert(!queue.empty());int top = queue.front();queue.pop_front();return top;
}上面的代码中必须用while循环来等待条件变量,而不能用if语句,原因是spurious wakeup[注:http://en.wikipedia.org/wiki/Spurious_wakeup]。这也是面试多线程编程的常见考点。
对于signal/broadcast端:
1.不一定要在mutex已上锁的情况下调用signal(理论上)。
2.在signal之前一般要修改布尔表达式。
3.修改布尔表达式通常要用mutex保护(至少用作full memory barrier)。
4.注意区分signal与broadcast:“broadcast通常用于表明状态变化,signal通常用于表示资源可用。(broadcast should generally be used to indicate state change rather than resource availability。)[注:[RWC]"Know when to broadcast and when to signal."]”
写成代码是[注:muduo::Condition采用了notify()和notifyAll()为函数名,避免重载 signal 这个术语。]:
void enqueue(int x)
{MutexLockGuard lock(mutex);queue.push_back(x);cond.notify(); //可以移出临界区之外
}上面的dequeue()/enqueue()实际上实现了一个简单的容量无限的(unbounded)BlockingQueue [注:实际使用时一般会做成类模板,如muduo/base/BlockingQueue.h。]。
思考:enqueue()中每次添加元素都会调用Condition::notify(),如果改成只在queue.size()从0变1的时候才调用Condition::notify(),会出现什么后果?[注:https://blog.csdn.net/Solstice/article/details/5829421#comments]
条件变量是非常底层的同步原语,很少直接使用,一般都是用它来实现高层的同步措施,如BlockingQueue<T>或CountDownLatch。
倒计时(CountDownLatch)[注:muduo/base/CountDownLatch.{h,cc}]是一种常用且易用的同步手段。它主要有两种用途:
● 主线程发起多个子线程,等这些子线程各自都完成一定的任务之后,主线程才继续执行。通常用于主线程等待多个子线程完成初始化。
● 主线程发起多个子线程,子线程都等待主线程,主线程完成其他一些任务之后通知所有子线程开始执行。通常用于多个子线程等待主线程发出“起跑”命令。
当然我们可以直接用条件变量来实现以上两种同步。不过如果用CountDownLatch的话,程序的逻辑更清晰。CountDownLatch的接口很简单:
class CountDownLatch: boost::noncopyable
{
public:explicit CountDownLatch(int count); //倒数几次void wait(); //等待计数值变为0void countDown(); //计数减一
private:mutable MutexLock mutex_;Condition condition_;int count_;
};CountDownLatch的实现同样简单,几乎就是条件变量的教科书式应用:
//构造函数见第48页
void CountDownLatch::wait()
{MutexLockGuard lock(mutex_);while(count_ > 0)condition_.wait();
}
void CountDownLatch::countDown()
{MutexLockGuard lock(mutex_);--count_;if(count_ == 0)condition_.notifyAll();
}注意到CountDownLatch::countDown()使用的是Condition::notifyAll(),而前面p.41的enqueue()使用的是Condition::notify(),这都是有意为之。请读者思考,如果交换两种用法会出现什么情况?
互斥器和条件变量构成了多线程编程的全部必备同步原语,用它们即可完成任何多线程同步任务,二者不能相互替代。[注:就像与非门和 D触发器构成了数字电路设计所需的全部基础元件一样,用它们可以完成任何组合和同步时序逻辑电路设计。]我认为应该精通这两个同步原语的用法,先学会编写正确的、安全的多线程程序,再在必要的时候考虑用其他“高技术”手段提高性能,如果确实能提高性能的话。千万不要连mutex都还没学会、用好,一上来就考虑lock-free设计[注:http://www.drdobbs.com/cpp/lock-free-code-a-false-sense-of-security/210600279]。
2.3 不要用读写锁和信号量
读写锁(Readers-Writer lock,简写为rwlock)是个看上去很美的抽象,它明确区分了read和write两种行为。
初学者常干的一件事情是,一见到某个共享数据结构频繁读而很少写,就把mutex替换为rwlock。甚至首选rwlock来保护共享状态,这不见得是正确的。[注:[RWC]"Be wary of readers/writer locks."]
● 从正确性方面来说,一种典型的易犯错误是在持有read lock的时候修改了共享数据。这通常发生在程序的维护阶段,为了新增功能,程序员不小心在原来read lock保护的函数中调用了会修改状态的函数。这种错误的后果跟无保护并发读写共享数据是一样的。
● 从性能方面来说,读写锁不见得比普通mutex更高效。无论如何reader lock加锁的开销不会比mutex lock小,因为它要更新当前reader的数目。如果临界区很小[注:在多线程编程中,我们总是设法缩短临界区,不是吗?],锁竞争不激烈,那么mutex往往会更快。见§1.9的例子。
● reader lock可能允许提升(upgrade)为writer lock,也可能不允许提升[注:Pthreads rwlock不允许提升]。考虑§ 2.1.1的post()和traverse()示例,如果用读写锁来保护foos对象,那么post()应该持有写锁,而traverse()应该持有读锁。如果允许把读锁提升为写锁,后果跟使用recursive mutex一样,会造成迭代器失效,程序崩溃。如果不允许提升,后果跟使用non-recursive mutex一样,会造成死锁。我宁愿程序死锁,留个“全尸”好查验。
● 通常reader lock是可重入的,writer lock是不可重入的。但是为了防止writer饥饿,writer lock通常会阻塞后来的reader lock,因此reader lock在重入的时候可能死锁。另外,在追求低延迟读取的场合也不适用读写锁,见p.55。
muduo线程库有意不提供读写锁的封装,因为我还没有在工作中遇到过用rwlock替换普通mutex会显著提高性能的例子。相反,我们一般建议首选mutex。
遇到并发读写,如果条件合适,我通常会用§ 2.8的办法,而不用读写锁,同时避免reader被writer阻塞。如果确实对并发读写有极高的性能要求,可以考虑read-copy-update [注:http://en.wikipedia.org/wiki/Read-copy-update]。
信号量(Semaphore):我没有遇到过需要使用信号量的情况,无从谈及个人经验。我认为信号量不是必备的同步原语,因为条件变量配合互斥器可以完全替代其功能,而且更不易用错。除了[RWC]指出的“semaphore has no notion of ownership”之外,信号量的另一个问题在于它有自己的计数值,而通常我们自己的数据结构也有长度值,这就造成了同样的信息存了两份,需要时刻保持一致,这增加了程序员的负担和出错的可能。如果要控制并发度,可以考虑用muduo::ThreadPool。
说一句不知天高地厚的话,如果程序里需要解决如“哲学家就餐”之类的复杂IPC问题,我认为应该首先检讨这个设计:为什么线程之间会有如此复杂的资源争抢(一个线程要同时抢到两个资源,一个资源可以被两个线程争夺)?如果在工作中遇到,我会把“想吃饭”这个事情专门交给一个为各位哲学家分派餐具的线程来做,然后每个哲学家等在一个简单的condition variable上,到时间了有人通知他去吃饭。从哲学上说,教科书上的解决方案是平权,每个哲学家有自己的线程,自己去拿筷子;我宁愿用集权的方式,用一个线程专门管餐具的分配,让其他哲学家线程拿个号等在食堂门口好了。这样不损失多少效率,却让程序简单很多。虽然Windows的WaitForMultipleObjects让这个问题trivial化,但在Linux下正确模拟WaitForMultipleObjects不是普通程序员该干的。
Pthreads还提供了barrier这个同步原语,我认为不如CountDownLatch实用。
2.4 封装MutexLock、MutexLockGuard、Condition
本节把前面用到的MutexLock、MutexLockGuard、Condition等class的代码列出来,前面两个class没多大难度,后面那个有点意思。这几个class都不允许拷贝构造和赋值。完整代码可以在muduo/base找到。
MutexLock和MutexLockGuard这两个class应该能在纸上默写出来,没有太多需要解释的。MutexLock的附加值在于提供了isLockedByThisThread()函数,用于程序断言。它用到的CurrentThread::tid()函数将在§ 4.3介绍。
class MutexLock: boost::noncopyable
{
public: //为了节省版面,单行函数都没有正确缩进MutexLock(): holder_(0){ pthread_mutex_init(&mutex_, NULL); }~MutexLock(){assert(holder_ == 0);pthread_mutex_destroy(&mutex_);}bool isLockedByThisThread(){ return holder_ == CurrentThread::tid(); }void assertLocked(){ assert(isLockedByThisThread()); }void lock() //仅供MutexLockGuard调用,严禁用户代码调用 {pthread_mutex_lock(&mutex_); //这两行顺序不能反holder_ = CurrentThread::tid(); }void unlock() //仅供MutexLockGuard调用, 严禁用户代码调用{holder_ = 0; //这两行顺序不能反pthread_mutex_unlock(&mutex_);}pthread_mutex_t *getPthreadMutex() //仅供Condition调用,严禁用户代码调用{ return &mutex_; }
private:pthread_mutex_t mutex_;pid_t holder_;
};class MutexLockGuard: boost::noncopyable
{
public:explicit MutexLockGuard(MutexLock& mutex): mutex_(mutex){ mutex_.lock(); }~MutexLockGuard(){ mutex_.unlock(); }
private:MutexLock& mutex_;
};
#define MutexLockGuard(x) static_assert(false, "missing mutex grard var name")注意上面代码的最后一行定义了一个宏,这个宏的作用是防止程序里出现如下错误:
void doit()
{MutexLockGuard(mutex); //遗漏变量名,产生一个临时对象又马上销毁了,//结果没有销住临界区。// 正确写法是MutexLockGuard lock(mutex);// 临界区
}我见过有人把MutexLockGuard写成template,我没有这么做是因为它的模板类型参数只有MutexLock一种可能,没有必要随意增加灵活性,于是我手工把模板具现化(instantiate)了。此外一种更激进的写法是,把lock/unlock放到private区,然后把MutexLockGuard设为MutexLock的friend。我认为在注释里告知程序员即可,另外check-in之前的code review也很容易发现误用的情况(grep getPthreadMutex)。
这段代码没有达到工业强度:
● mutex创建为PTHREAD_MUTEX_DEFAULT类型,而不是我们预想的PTHREAD_MU-TEX_NORMAL类型(实际上这二者很可能是等同的),严格的做法是用mutexattr来显示指定mutex的类型。
● 没有检查返回值。这里不能用assert()检查返回值,因为assert()在release build里是空语句。我们检查返回值的意义在于防止ENOMEM之类的资源不足情况,这一般只可能在负载很重的产品程序中出现。一旦出现这种错误,程序必须立刻清理现场并主动退出,否则会莫名其妙地崩溃,给事后调查造成困难。这里我们需要non-debug的assert,或许google-glog的CHECK()宏是个不错的思路。
以上两点改进留作练习。
muduo库的一个特点是只提供最常用、最基本的功能,特别有意避免提供多种功能近似的选择。muduo不是“杂货铺”,不会不分青红皂白地把各种有用的、没用的功能全铺开摆出来。muduo删繁就简,举重若轻;减少选择余地,生活更简单。MutexLock没有提供trylock()函数,因为我没有在生产代码中用过它。我想不出什么时候程序需要“试着去锁一锁”,或许我写过的代码太简单了[注:trylock 的一个用途是用来观察lock contention,见[RWC]"Consider using nonblocking synchronization routines to monitor contention."]。
Condition class的实现有点意思。Pthreads condition variable允许在wait()的时候指定mutex,但是我想不出有什么理由一个condition variable会和不同的mutex配合使用。Java的intrinsic condition和Condition class都不支持这么做,因此我觉得可以放弃这一灵活性,老老实实地一对一好了。
相反,boost::thread的condition_variable是在wait的时候指定mutex,请参观其同步原语的庞杂设计:
● Concept有四种Lockable、TimedLockable、SharedLockable、UpgradeLockable。
● Lock有六种:lock_guard、unique_lock、shared_lock、upgrade_lock、up-grade_to_unique_lock、scoped_try_lock。
● Mutex有七种:mutex、try_mutex、timed_mutex、recursive_mutex、recur-sive_try_mutex、recursive_timed_mutex、shared_mutex。
恕我愚钝,见到boost::thread这样如Rube Goldberg Machine一样让人眼花缭乱的库,我只得三揖绕道而行。很不幸C++11的线程库也采纳了这套方案。这些class名字也很无厘头,为什么不老老实实用readers_writer_lock这样的通俗名字呢?非得增加精神负担,自己发明新名字。我不愿为这样的灵活性付出代价,宁愿自己做几个简简单单的一看就明白的class来用,这种简单的几行代码的“轮子”造造也无妨。提供灵活性固然是本事,然而在不需要灵活性的地方把代码写死,更需要大智慧。
下面这个muduo::Condition class简单地封装了Pthreads condition variable,用起来也容易,见本节前面的例子。这里我用notify/notifyAll作为函数名,因为signal有别的含义,C++里的signal/slot、C里的signal handler等等。就别overload这个术语了。
class Condition:boost::noncopyable
{
public: //为了节省版本,单行函数没有正确缩进explicit Condition(MutexLock& mutex):mutex_(mutex){ pthread_cond_init(&pcond_, NULL); }~Condition() { pthread_cond_destroy(&pcond_); }void wait() {pthread_cond_wait(&pcond_, mutex_.getPthreadMutex()); }void notify() { pthread_cond_signal(&pcond_); }void notifyAll() { pthread_cond_broadcast(&pcond_); }
private:MutexLock& mutex_;pthread_cond_t pcond_;
};如果一个class要包含MutexLock和Condition,请注意它们的声明顺序和初始化顺序,mutex_应先于condition_构造,并作为后者的构造参数:
class CountDownLatch
{
public:CountDownLatch(int count):mutex_(),condition_(mutex_), //初始化顺序要与成员声明保持一致count_(count){}
private:mutable MutexLock mutex_; //顺序很重要,先mutex后conditoinCondition condition_;int count_;
};请允许我再次强调,虽然本章花了大量篇幅介绍如何正确使用mutex和condi-tion variable,但并不代表我鼓励到处使用它们。这两者都是非常底层的同步原语,主要用来实现更高级的并发编程工具。一个多线程程序里如果大量使用mutex和condition variable来同步,基本跟用铅笔刀锯大树(孟岩语)没啥区别。
在程序里使用Pthreads库有一个额外的好处:分析工具认得它们,懂得其语意。线程分析工具如Intel Thread Checker和Valgrind-Helgrind[34注:https://valgrind.org/docs/manual/hg-manual.html#hg-manual.data-races%20.algorithm]等能识别Pthreads调用,并依据happens-before关系[35注:http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf]分析程序有无data race。
2.5 线程安全的Singleton实现
研究Singleton的线程安全实现的历史会发现很多有意思的事情,人们一度认为double checked locking(缩写为DCL)是王道[36注:http://www.cs.wustLedu/-schmidt/PDF/DC-Locking.pdf
],兼顾了效率与正确性。后来有“神牛”指出由于乱序执行的影响,DCL是靠不住的[37注:https://www.cs.umd.edu/pugh/java/memoryModel/DoubleCheckedLocking.html][38注:http://www.javaworld.com/jw-02-2001/jw-0209-double.html][39注:这个又让我想起了SQL注人,10年前用字符串拼接出SQL语句是 Web开发的通行做法,直到有一天有人利用这个漏洞越权获得并修改网站数据,人们才然醒,赶紧补。]。Java开发者还算幸运,可以借助内部静态类的装载来实现。C++就比较惨,要么次次锁,要么eager initialize,或者动用memory barrier这样的“大杀器”[40注:https://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf]。接下来Java 5修订了内存模型,并给volatile赋予了acquire/release语义,这下DCL(with volatile)又是安全的了。然而C++的内存模型还在修订中[41注:http://scottmeyers.blogspot.com/2012/04/information-on-c11-memory-model.html],C++的volatile目前还不能(将来也难说)保证DCL的正确性(只在Visual C++2005及以上版本有效)。
其实没那么麻烦,在实践中用pthread_once就行:
template<typename T>
class Signletom: boost::noncopyable
{
public:static T& instance(){pthread_once(&ponce_, &Signleton::init);return *value_;}
private:Singleton();~Singleton();static void init(){value_ = new T();}
private:static pthread_once_t ponce_;static T* value_;
};
//必须在头文件中定义static 变量
template<typename T>
pthread_once_t Signleton<T>::ponce_t = PTHREAD_ONCE_INIT;template<typename T>
T* Singleton<T>::value_ = NULL;上面这个Singleton没有任何花哨的技巧,它用pthread_once_t来保证lazy-ini-tialization的线程安全。线程安全性由Pthreads库保证,如果系统的Pthreads库有bug,那就认命吧,多线程程序反正也不可能正确执行了。
使用方法也很简单:
Foo& foo=Singleton<Foo>::instance();
这个Singleton没有考虑对象的销毁。在长时间运行的服务器程序里,这不是一个问题,反正进程也不打算正常退出(§ 9.2.2)。在短期运行的程序中,程序退出的时候自然就释放所有资源了(前提是程序里不使用不能由操作系统自动关闭的资源,比如跨进程的mutex)。在实际的muduo::Singleton class中,通过atexit(3)提供了销毁功能[插图],聊胜于无罢了。
另外,这个Singleton只能调用默认构造函数,如果用户想要指定T的构造方式,我们可以用模板特化(template specialization)技术来提供一个定制点,这需要引入另一层间接(another level of indirection)。
2.6 sleep(3)不是同步原语
我认为sleep()/usleep()/nanosleep()只能出现在测试代码中,比如写单元测试的时候[43注:涉及时间的单元测试不那么好写,短的如一两秒,可以用sleep();长的如一小时、一天,则得想其他办法,比如把算法提取出来并把时间注人进去。];或者用于有意延长临界区,加速复现死锁的情况,就像§ 2.1.2示范的那样。sleep不具备memory barrier语义,它不能保证内存的可见性,见p.84的例子。
生产代码中线程的等待可分为两种:一种是等待资源可用(要么等在select/poll/epoll_wait上,要么等在条件变量上[44注:等待 BlockingQueue/CountDownLatch亦可归人此类]);一种是等着进入临界区(等在mutex上)以便读写共享数据。后一种等待通常极短,否则程序性能和伸缩性就会有问题。
在程序的正常执行中,如果需要等待一段已知的时间,应该往event loop里注册一个timer,然后在timer的回调函数里接着干活,因为线程是个珍贵的共享资源,不能轻易浪费(阻塞也是浪费)。如果等待某个事件发生,那么应该采用条件变量或IO事件回调,不能用sleep来轮询。不要使用下面这种业余做法:
while (true) {if(!dataAvailable)sleep(some_time);elseconsumeData();
}如果多线程的安全性和效率要靠代码主动调用sleep来保证,这显然是设计出了问题。等待某个事件发生,正确的做法是用select()等价物或Condition,抑或(更理想地)高层同步工具;在用户态做轮询(polling)是低效的。
2.7 归纳与总结
前面几节内容归纳如下:
● 线程同步的四项原则,尽量用高层同步设施(线程池、队列、倒计时);
● 使用普通互斥器和条件变量完成剩余的同步任务,采用RAII惯用手法(idiom)和Scoped Locking。
用好这几样东西,基本上就能应付多线程服务端开发的各种场合。或许有人会觉得性能没有发挥到极致。我认为,应该先把程序写正确(并尽量保持清晰和简单),然后再考虑性能优化,如果确实还有必要优化的话。这在多线程下仍然成立。让一个正确的程序变快,远比“让一个快的程序变正确”容易得多。
在现代的多核计算背景下,多线程是不可避免的。尽管在一定程度上可以通过framework来屏蔽,让你感觉像是在写单线程程序,比如Java Servlet。了解under the hood发生了什么对于编写这种程序也会有帮助。
多线程编程是一项重要的个人技能,不能因为它难就本能地排斥,现在的软件开发比起10年、20年前已经难了不知道多少倍。掌握多线程编程,才能更理智地选择用还是不用多线程,因为你能预估多线程实现的难度与收益,在一开始做出正确的选择。要知道把一个单线程程序改成多线程的,往往比从头实现一个多线程的程序更困难。要明白多线程编程中哪些是能做的,哪里是一般程序员应该避开的雷区。
掌握同步原语和它们的适用场合是多线程编程的基本功。以我的经验,熟练使用文中提到的同步原语,就能比较容易地编写线程安全的程序。本文没有考虑signal对多线程编程的影响(§ 4.10),Unix的signal在多线程下的行为比较复杂,一般要靠底层的网络库(如Reactor)加以屏蔽,避免干扰上层应用程序的开发。
通篇来看,“效率”并不是我的主要考虑点,我提倡正确加锁而不是自己编写lock-free算法(使用原子整数除外),更不要想当然地自己发明同步设施[45注:《Ad Hoc Synchronization Considered Harmful》https://www.usenix.org/legacy/events/osdi10/tech/full_papers/Xiong.pdf]。在没有实测数据支持的情况下,妄谈哪种做法效率更高是靠不住的[46注:https://pdos.csail.mit.edu/papers/linux:osdi10.pdf],不能听信传言或凭感觉“优化”。很多人误认为用锁会让程序变慢,其实真正影响性能的不是锁,而是锁争用(lock contention)[47注:https://preshing.com/20111118/locks-arent-slow-lock-contention-is/]。在程序的复杂度和性能之前取得平衡,并考虑未来两三年扩容的可能(无论是CPU变快、核数变多,还是机器数量增加、网络升级)。我认为在分布式系统中,多机伸缩性(scale out)比单机的性能优化更值得投入精力。
本章内容记录了我目前对多线程编程的理解,用文中介绍的手法,我能化繁为简,编写容易验证其正确性的多线程程序,解决自己面临的全部多线程编程任务。如果本章的观点与你的经验不合,比如你使用了我没有推荐使用的技术或手法(共享内存、信号量等等),只要你理由充分,但行无妨。
2.8 借shared_ptr实现copy-on-write本节解决§ 2.1的几个未决问题:
● § 2.1.1 post()和traverse()死锁。
● § 2.1.2 把Request::print()移出Inventory::printAll()临界区。
● § 2.1.2 解决Request对象析构的race condition。
然后再示范用普通mutex替换读写锁。解决办法都基于同一个思路,那就是用shared_ptr来管理共享数据。原理如下:
● shared_ptr是引用计数型智能指针,如果当前只有一个观察者,那么引用计数的值为1[48注:在实际代码中判断shared_ptr::unique()是否为true]。
● 对于write端,如果发现引用计数为1,这时可以安全地修改共享对象,不必担心有人正在读它。
● 对于read端,在读之前把引用计数加1,读完之后减1,这样保证在读的期间其引用计数大于1,可以阻止并发写。
● 比较难的是,对于write端,如果发现引用计数大于1,该如何处理?sleep()一小段时间肯定是错的。
先来看一个简单的例子,解决§ 2.1.1中的post()和traverse()死锁。[49注:recipes/thread/test/CopyOnWrite_test.cc]数据结构改成:
typedef std::vector<Foo> FooList;
typedef boost::shared_ptr<FooList> FooListPtr;
MutexLock mutex;
FooListPtr g_foos;在read端,用一个栈上局部FooListPtr变量当做“观察者”,它使得g_foos的引用计数增加(L6)。traverse()函数的临界区是L4~L8,临界区内只读了一次共享变量g_foos(这里多线程并发读写shared_ptr,因此必须用mutex保护),比原来的写法大为缩短。而且多个线程同时调用traverse()也不会相互阻塞。
void traverse()
{FooListPtr foos;{MutexLockGuard lock(mutex);foos = g_foos;assert(!g_foos.unique());}//assert(!foos.unique()); 这个断言不成立for(std::vector<Foo>::const_iterator it = foos->begin();it != foos->end(); ++it){it->doit();}
}关键看write端的post()该如何写。按照前面的描述,如果g_foos.unique()为true,我们可以放心地在原地(in-place)修改FooList。如果g_foos.unique()为false,说明这时别的线程正在读取FooList,我们不能原地修改,而是复制一份(L23),在副本上修改(L27)。这样就避免了死锁。
void post(const Foo& f)
{printf("post\n");MutexLockGuard lock(mutex);if(!g_foos.unique()){g_foos.reset(new FooList(*g_foos));printf("copy the whole list\n); //练习:将这句话移出临界区}assert(g_foos.unique());g_foos->push_back(f);
}注意这里临界区包括整个函数(L20~L27),其他写法都是错的。读者可以试着运行这个程序,看看什么时候会打印L24的消息。练习:找出以下几种写法的错误。
//错误一:直接修改g_foos所指的FooList
void post(const Foo& f)
{MutexLockGuard lock(mutex);g_foos->push_back(f);
}
//错误二:试图缩小临界区,把copying移出临界区
void post(const Foo& f)
{FooListPtr newFoos(new Foolist(*g_foos));newFoos->push_back(f);MutexLockGuard lock(mutex);g_foos = newFoos; //或者g_foos.swap(newFoos);
}
//错误三:把临界区拆成两个小的,把copying放到临界区之外
void post(const Foo& f)
{FooListPtr oldFoos;{MutexLockGuard lock(mutex);oldFoos = g_foos;}FooListPtr newFoos(new FooList(*oldFoos));newFoos->push_back(f);MutexLockGuard lock(mutex);g_foos = newFoos; //或者g_foos.swap(newFoos);
}希望读者先吃透上面举的这个例子,再来看如何用相同的思路解决剩下的问题。
解决§ 2.1.2把Request::print()移出Inventory::printAll()临界区有两个做法。其一很简单,把requests_复制一份,在临界区之外遍历这个副本。
void Inventory::printfAll() const
{std::set<Request*> requests;{muduo::MutexLockGuard lock(mutex_);requests = requests_;}//遍历局部变量requests, 调用Request::print()
}这么做有一个明显的缺点,它复制了整个std::set中的每个元素,开销可能会比较大。如果遍历期间没有其他人修改requests_,那么我们可以减小开销,这就引出了第二种做法。
第二种做法的要点是用shared_ptr管理std::set,在遍历的时候先增加引用计数,阻止并发修改。当然Inventory::add()和Inventory::remove()也要相应修改,采用本节前面post()和traverse()的方案。完整的代码见recipes/thread/test/Request-Inventory_test.cc。
注意目前的方案仍然没有解决Request对象析构的race condition,这点还是留作练习吧。一种可能的答案见recipes/thread/test/RequestInventory_test2.c。
用普通mutex替换读写锁的一个例子
场景:一个多线程的C++程序,24h x 5.5d运行。有几个工作线程Thread-Worker{0,1,2,3},处理客户发过来的交易请求;另外有一个背景线程ThreadBack-ground,不定期更新程序内部的参考数据。这些线程都跟一个hash表打交道,工作线程只读,背景线程读写,必然要用到一些同步机制,防止数据损坏。这里的示例代码用std::map代替hash表,意思是一样的:
using namespace std;
typedef map<string, vector<pair<string, int>>> Map;Map的key是用户名,value是一个vector,里边存的是不同stock的最小交易间隔,vector已经排好序,可以用二分查找。
我们的系统要求工作线程的延迟尽可能小,可以容忍背景线程的延迟略大。一天之内,背景线程对数据更新的次数屈指可数,最多一小时一次,更新的数据来自于网络,所以对更新的及时性不敏感。Map的数据量也不大,大约一千多条数据。
最简单的同步办法是用读写锁:工作线程加读锁,背景线程加写锁。但是读写锁的开销比普通mutex要大,而且是写锁优先,会阻塞后面的读锁。如果工作线程能用最普通的非重入mutex实现同步,就不必用读写锁,这能降低工作线程延迟。我们借助shared_ptr做到了这一点:(recipes/thread/test/Customer.cc)
class CustomerData:boost::noncopyable
{
public:CustomerData(): data_(new Map){ }int query(const string& customer, const string& stock) const;
private:typedef std::pair<string, int> Entry;typedef std::vector<Entry> EntryList;typedef std::map<string, EntryList> Map;typedef boost::shared_ptr<Map> MapPtr;void update(const string& customer, const EntryList& entries);void update(const string& message);//用lower_bound在entries里找stockstatic int findEntry(const EntryList& entries, const string& stock);static MapPtr parseData(const string& message);MapPtr getData() const{muduo::MutexLockGuard lock(mutex_);return data_;}mutable muduo::MutexLock mutex_;MapPtr data_;
};CustomerData::query()就用前面说的引用计数加1的办法,用局部MapPtr data变量来持有Map,防止并发修改。
int CustomerData::query(const string& customer, const string& stock) const
{MapPtr data = getData();//data一旦拿到,就不再需要锁骨了//取数据的时候只有getData()内部有锁,多线程并发读的性能很好。Map::const_iterator entries = data->find(customer);if (entries != data->end())return findEntry(entries->second, stock);elsereturn -1;
}关键看CustomerData::update()怎么写。既然要更新数据,那肯定得加锁,如果这时候其他线程正在读,那么不能在原来的数据上修改,得创建一个副本,在副本上修改,修改完了再替换。如果没有用户在读,那么就能直接修改,节约一次Map拷贝。
//每次收到一个customer的数据更新
void CustomerData::update(const string& customer, const EntryList& entries)
{muduo::MutexLockGuard lock(mutex_); //update必须全程持锁if (!data_.unique()){MapPtr newData(new Map(*data_));//在这里打印日志,然后统计日志来判断worst case发生的次数data_.swap(newData);}assert(data_.unique());(*data_)[customer] = entries;
}注意其中用了shared_ptr::unique()来判断是不是有人在读,如果有人在读,那么我们不能直接修改,因为query()并没有全程加锁,只在getData()内部有锁。shared_ptr::swap()把data_替换为新副本,而且我们还在锁里,不会有别的线程来读,可以放心地更新。如果别的reader线程已经刚刚通过getData()拿到了MapPtr,它会读到稍旧的数据。这不是问题,因为数据更新来自网络,如果网络稍有延迟,反正reader线程也会读到旧的数据。
如果每次都更新全部数据,而且始终是在同一个线程更新数据,临界区还可以进一步缩小。
MapPtr parseData(const string& message); //解析收到的消息,返回新的MapPtr
//函数原型有变,此时网络上传来的是完整的Map数据
void CustomerData::update(const string& message)
{//解析新数据,在临界区之外MapPtr newData = parseData(message);if(newData){MutexLockGuard lock(mutex_);data_.swap(newData); //不要用data_ = newData;}//旧数据的析构也在临界区外,进一步缩短了临界区
}据我们测试,大多数情况下更新都是在原来数据上进行的,拷贝的比例还不到1%,很高效。更准确地说,这不是copy-on-write,而是copy-on-other-reading。我们将来可能会采用无锁数据结构,不过目前这个实现已经非常好,可以满足我们的要求。
本节介绍的做法与read-copy-update颇有相似之处,但理解起来要容易得多。