C语言 ——— 自定义类型
目录
结构体内存对齐
结构体内存对齐规则
一、规则 1:第一个成员的 “固定偏移”—— 偏移量为 0
二、规则 2:从第二个成员开始,按 “对齐数” 对齐
1. 对齐数的定义(VS 与 GCC 的区别)
2. 实例拆解(按 VS 环境计算)
三、规则 3:结构体总大小的对齐要求
四、规则4:结构体嵌套结构体情况
规则 4 的核心拆解
实例解析:用嵌套结构体验证规则(VS 环境,默认对齐数 8)
#pragma pack() --- 修改默认对齐数
一、#pragma pack (1) 的核心作用:强制 1 字节对齐
二、struct Test 的内存布局拆解(1 字节对齐下)
三、结构体总大小计算:成员大小直接求和
位段(位域)
一、位段的核心定义:“按位分配” 的特殊结构体
二、位段与结构体的两个关键差异
1. 成员类型必须属于 “整型家族”
2. 成员名后必须加 “冒号 + 数字”(指定占用位数)
三、结合代码示例:struct S的内存分配逻辑(直观感受位段的优势)
联合(共用体)
定义联合体关键字 union
一、union Un 的内存空间:大小由 “最大成员” 决定
二、核心特性:所有成员共用同一块空间,起始地址完全相同
三、关键推论:修改一个成员,会影响另一个成员的数据
四、延伸见解:联合体的核心价值与适用场景
结构体内存对齐
offsetof 是 C 语言标准库提供的一个宏(而非函数),其核心作用是以字节为单位,精准计算结构体中某个成员相对于结构体起始位置的偏移量—— 这里的 “偏移量”,指的是从结构体变量的首地址(起始位置)到该成员首地址的字节数,是衡量成员在结构体内存中 “位置” 的关键指标。
所以可以通过 offsetof 宏来辅助了解结构体内存对齐
代码演示:
struct Test
{int a;char c;float f;
};int main()
{printf("%d\n", offsetof(struct Test, a));printf("%d\n", offsetof(struct Test, c));printf("%d\n", offsetof(struct Test, f));return 0;
}
代码验证:
一、offsetof 宏的核心作用:打印成员偏移量
代码中通过offsetof(struct Test, 成员名)的形式,分别计算并打印了struct Test结构体中三个成员(a、c、f)相对于结构体起始位置的偏移量(即成员首地址与结构体首地址的字节差):
offsetof(struct Test, a):计算int类型成员a的偏移量,由于a是结构体第一个成员,其偏移量为 0;offsetof(struct Test, c):计算char类型成员c的偏移量,受对齐规则影响,其偏移量为 4(紧跟在a的 4 字节空间之后);offsetof(struct Test, f):计算float类型成员f的偏移量,这一结果是关键 —— 它并非紧随c的偏移量 4(若紧密存储应为 5),而是更大的数值(实际为 8)。
二、输出结果揭示的关键现象:成员间存在内存间隙
从offsetof的输出可直接发现:char类型成员c与float类型成员f之间并非连续存储,而是存在一段 “内存间隙”。
这种 “非连续” 的本质,正是 C 语言结构体内存对齐规则的体现:结构体成员的存储地址需满足 “自身数据类型大小的整数倍”(即对齐数)——float类型的对齐数通常为 4,因此f的偏移量必须是 4 的整数倍(8 是距离c最近的符合条件的地址),这就导致c(偏移 4)与f(偏移 8)之间出现了 3 字节的 “对齐填充”,而非紧密衔接。
结构体内存对齐规则
代码演示:
struct Test
{int a;char c;float f;
};一、规则 1:第一个成员的 “固定偏移”—— 偏移量为 0
结构体的第一个成员,无论其数据类型是什么,永远存储在 “相对于结构体变量起始位置偏移量为 0” 的地址处。
- 实例对应:
int类型的成员a是struct Test的第一个成员,因此它的存储地址从结构体起始位置(偏移 0)开始,占用 0~3 字节(int占 4 字节)。 - 本质:第一个成员无需考虑对齐(本身就是结构体的起始点),直接 “顶格存储”。
二、规则 2:从第二个成员开始,按 “对齐数” 对齐
从结构体的第二个成员起,每个成员都必须存储在 “其对齐数的整数倍” 的偏移量处。这是对齐规则的核心,需先明确 “对齐数” 的计算方式:
1. 对齐数的定义(VS 与 GCC 的区别)
- VS 环境:对齐数 =
min(成员自身数据类型大小, 默认对齐数)(VS 的默认对齐数固定为 8); - GCC 环境:无 “默认对齐数” 概念,对齐数直接等于 “成员自身数据类型大小”。
2. 实例拆解(按 VS 环境计算)
结合struct Test的后两个成员,逐个分析对齐逻辑:
-
成员
c(char类型):- 自身大小 = 1 字节,VS 默认对齐数 = 8,因此对齐数 =
min(1,8)=1; - 需存储在 “1 的整数倍” 的偏移量处。由于前一个成员
a占用 0~3 字节,下一个可用偏移量是 4,而 4 是 1 的整数倍,因此c从偏移 4 开始存储,占用 4 字节(char仅占 1 字节,偏移 4 的剩余空间暂时闲置)。 - 这里需注意:并非 “偏移量 1”—— 因为第一个成员
a已占用 0~3 字节,偏移 1~3 属于a的空间,不能重复使用,所以c的起始偏移是 4,而非 1。
- 自身大小 = 1 字节,VS 默认对齐数 = 8,因此对齐数 =
-
成员
f(float类型):- 自身大小 = 4 字节,VS 默认对齐数 = 8,因此对齐数 =
min(4,8)=4; - 需存储在 “4 的整数倍” 的偏移量处。前一个成员
c占用偏移 4,下一个可用偏移量是 5,但 5 不是 4 的整数倍,需向后找最近的 4 的整数倍 —— 即 8,因此f从偏移 8 开始存储,占用 8~11 字节; - 偏移 5~7:这 3 字节是 “对齐填充字节”(无实际数据,仅为满足
f的对齐要求),也是 “成员不连续存储” 的核心原因。
- 自身大小 = 4 字节,VS 默认对齐数 = 8,因此对齐数 =
三、规则 3:结构体总大小的对齐要求
除了成员的对齐,结构体的总大小也需满足 “所有成员中最大对齐数的整数倍”—— 这是为了保证多个结构体数组存储时,每个结构体都能符合对齐规则。
- 实例对应:
struct Test中 3 个成员的对齐数分别是 4(a的min(4,8))、1(c的min(1,8))、4(f的min(4,8)),最大对齐数为 4; - 结构体总大小需是 4 的整数倍:当前成员占用 0~11 字节(共 12 字节),12 是 4 的整数倍,因此
struct Test的总大小为 12 字节(其中偏移 5~7 的 3 字节是填充字节,占总大小的 25%)。
四、规则4:结构体嵌套结构体情况
当结构体中嵌套了另一个结构体时,对齐规则会在基础规则上延伸,核心是保证嵌套结构体内部的对齐有效性,同时满足外层结构体的整体对齐要求。规则 4 可拆分为两个关键要点,结合具体实例能更清晰理解:
规则 4 的核心拆解
规则 4 包含两层含义,需分步理解:
- 嵌套结构体成员的对齐要求:外层结构体中的 “嵌套结构体成员”(如
struct Outer中的struct Inner in),需对齐到该嵌套结构体自身的最大对齐数的整数倍处;- 这里的 “嵌套结构体自身的最大对齐数”,指嵌套结构体内部所有成员的对齐数中最大的那个(而非嵌套结构体的总大小),本质是将嵌套结构体视为一个 “特殊的大成员”,其 “对齐数” 由自身内部的最大对齐数决定。
- 外层结构体总大小的对齐要求:外层结构体的总大小,需对齐到所有成员(含嵌套结构体的最大对齐数)的最大对齐数的整数倍处,确保整个结构体作为一个整体时,后续存储(如数组)仍符合对齐规则。
实例解析:用嵌套结构体验证规则(VS 环境,默认对齐数 8)
为了直观理解,我们构造一个包含嵌套结构的示例,先定义嵌套的内层结构体struct Inner,再定义包含它的外层结构体struct Outer:
// 内层结构体:含char和int成员
struct Inner {char x; // 自身大小1,对齐数min(1,8)=1int y; // 自身大小4,对齐数min(4,8)=4
};// 外层结构体:含int、嵌套结构体、float成员
struct Outer {int a; // 自身大小4,对齐数min(4,8)=4struct Inner in; // 嵌套结构体成员float f; // 自身大小4,对齐数min(4,8)=4
};我们按规则逐步计算struct Outer的内存布局(偏移量、占用字节):
步骤 1:先确定内层结构体struct Inner的关键信息
在分析外层前,需先明确嵌套结构体自身的 “最大对齐数” 和 “总大小”(这是外层对齐的基础):
- Inner 的最大对齐数:内部成员
x对齐数 1,y对齐数 4 → 最大对齐数是 4; - Inner 的总大小:按基础对齐规则计算:
x在偏移 0(占 0 字节);y需对齐到 4 的整数倍,因此从偏移 4 开始(占 4~7 字节);- Inner 总大小需对齐到自身最大对齐数 4 的整数倍 → 总大小 = 8 字节(0~7)。
步骤 2:计算外层结构体struct Outer的成员偏移与总大小
按规则 1~4 逐步分析每个成员:
- 第一个成员
int a:符合规则 1,偏移 0,占 0~3 字节(4 字节); - 第二个成员
struct Inner in(嵌套结构体):- 按规则 4 第 1 点,需对齐到 “Inner 自身的最大对齐数(4)” 的整数倍;
- 前一个成员
a占 0~3,下一个 4 的整数倍是 4 →in从偏移 4 开始存储,占用 4~11 字节(共 8 字节,即 Inner 的总大小);
- 第三个成员
float f:- 对齐数 min (4,8)=4,需对齐到 4 的整数倍;
- 前一个成员
in占 4~11,下一个 4 的整数倍是 12 →f从偏移 12 开始,占 12~15 字节(4 字节);
- 外层结构体总大小:
- 按规则 4 第 2 点,需对齐到 “所有成员的最大对齐数” 的整数倍;
- 外层成员的对齐数:
a(4)、in(4,即 Inner 的最大对齐数)、f(4) → 最大对齐数是 4; - 当前成员占用到 15 字节,16 是 4 的整数倍 → 外层总大小 = 16 字节(0~15)。
#pragma pack() --- 修改默认对齐数
代码演示:
#pragma pack(1)
struct Test
{char c1;int a;char c2;
};
#pragma pack()一、#pragma pack (1) 的核心作用:强制 1 字节对齐
默认情况下,结构体成员的对齐数是 “成员自身大小” 与 “编译器默认对齐数” 的较小值(如 VS 中int成员的对齐数是 4),会导致成员间出现对齐填充。而 #pragma pack(1) 直接将 “全局默认对齐数” 修改为 1,此时所有成员的对齐数都遵循 “min(成员自身大小, 1)”—— 由于 1 是最小的正整数,最终所有成员的对齐数都会被强制为 1。
关键逻辑:任何整数都是 1 的倍数,因此结构体中所有成员的 “目标偏移量” 必然满足 “1 的整数倍” 要求,无需额外的对齐填充字节,成员将完全按声明顺序紧密存储。
二、struct Test 的内存布局拆解(1 字节对齐下)
以 struct Test(含char c1、int a、char c2)为例,每个成员的存储位置和占用字节完全无间隙:
-
第一个成员 char c1:按规则 1,第一个成员永远在偏移量 0 处,占用 0~0 字节(共 1 字节),无任何争议。
-
第二个成员 int a:从第二个成员开始,需对齐到 “对齐数 1 的整数倍”—— 由于任何偏移量都是 1 的倍数,因此
a无需等待填充,直接紧跟在c1之后,从偏移量 1 处开始存储,占用 1~4 字节(共 4 字节)。(对比默认对齐:若按 VS 默认 8 字节对齐,int a的对齐数是 4,需从偏移 4 处开始,c1与a间会有 3 字节填充,此时a占用 4~7 字节)。 -
第三个成员 char c2:同样遵循 1 字节对齐,直接紧跟在
a之后,从偏移量 5 处开始存储,占用 5~5 字节(共 1 字节),无任何填充。
三、结构体总大小计算:成员大小直接求和
在 1 字节对齐模式下,结构体总大小的计算也无需考虑 “最大对齐数的整数倍”(因为最大对齐数是 1,任何总大小都是 1 的整数倍)。因此:struct Test 总大小 = c1大小 + a大小 + c2大小 = 1 + 4 + 1 = 6 字节。
对比默认对齐(以 VS 为例):默认情况下struct Test总大小为 12 字节(c1占 0~0,填充 3 字节到偏移 3,a占 4~7,c2占 8~8,填充 3 字节到偏移 11,总大小 12,满足最大对齐数 4 的整数倍),而#pragma pack(1)直接消除了所有填充,内存利用率达到 100%。
位段(位域)
一、位段的核心定义:“按位分配” 的特殊结构体
位段的声明语法几乎和结构体一致(都用struct关键字),但本质是 “对内存的精细化切割”—— 普通结构体的成员按 “字节” 为单位分配内存(如int占 4 字节、char占 1 字节),而位段的成员则按 “二进制位(bit)” 为单位分配内存,成员名后紧跟的 “冒号 + 数字”,就是该成员占用的二进制位数。
二、位段与结构体的两个关键差异
位段虽像结构体,但有两个严格限制,这是区分二者的核心:
1. 成员类型必须属于 “整型家族”
位段的成员只能是整型家族类型,具体包括:
- 有符号整型:
int、signed int; - 无符号整型:
unsigned int; - 字符类型:
char(本质是 1 字节的小整型,可视为int的子集)。
这是因为 “位操作” 仅对整型数据有意义,非整型类型(如float、double、结构体)无法按位分配内存,因此不能作为位段成员。
2. 成员名后必须加 “冒号 + 数字”(指定占用位数)
这是位段最显著的特征:冒号后的数字表示该成员占用的二进制位数(必须是正整数,且不能超过对应整型类型的总位数,如int通常占 32 位,成员位数不能超过 32)。
代码演示:
struct S
{int _a : 2;int _b : 5;int _c : 10;int _d : 20;
};三、结合代码示例:struct S的内存分配逻辑(直观感受位段的优势)
以struct S为例,我们可以通过 “位数累加” 看位段如何节省内存:
- 所有成员占用的总位数 =
_a(2) + _b(5) + _c(10) + _d(20) = 37位; - 普通
int类型占 32 位(4 字节),因此 37 位需要2 个int的内存空间(32 位 ×2=64 位,足够容纳 37 位),即struct S的总大小为 8 字节(4 字节 ×2)。
若用普通结构体实现相同需求(4 个int成员),总大小会是4字节×4=16字节—— 对比可见,位段通过 “按位分配” 将内存占用从 16 字节减少到 8 字节,节省了 50% 的内存,这正是位段的核心价值。
联合(共用体)
定义联合体关键字 union
联合也是一种特殊的自定义类型,这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间
代码演示:
union Un
{char c;int a;
};int main()
{union Un n = { 0 };printf("%d\n", sizeof(n));printf("%p\n", &n);printf("%p\n", &n.c);printf("%p\n", &n.a);return 0;
}代码验证: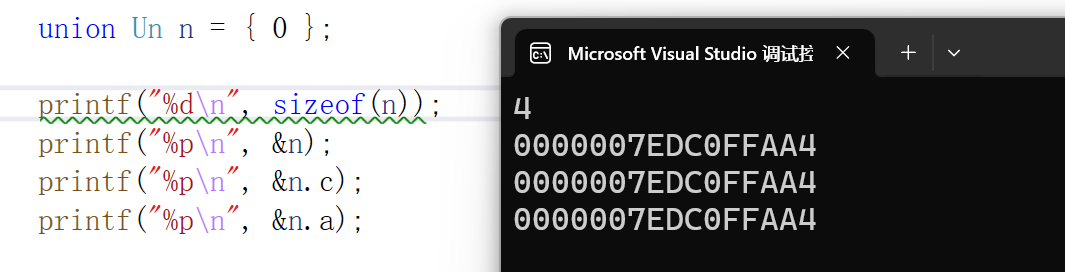
一、union Un 的内存空间:大小由 “最大成员” 决定
联合体的内存空间分配遵循 “以最大成员的大小为基准” 的规则 —— 即联合体变量的总大小,等于其所有成员中 “占用字节数最大的成员的大小”,目的是确保能容纳下任何一个成员的数据。
以 union Un 为例:
- 成员
char c:char类型占 1 字节; - 成员
int a:int类型通常占 4 字节(32 位 / 64 位平台通用);因此,union Un类型的变量总大小为 4 字节(取最大成员int a的大小),这 4 字节空间会被c和a共同使用,而非像结构体那样 “1 字节 + 4 字节 = 5 字节(加对齐后 8 字节)”。
二、核心特性:所有成员共用同一块空间,起始地址完全相同
“共用空间” 的本质是:联合体的所有成员都从同一个内存地址开始存储,不存在 “成员各自独立的地址范围”。具体到 union Un 的变量(假设变量名为 un):
un.a(int类型)占用的内存地址范围是&un~&un + 3(共 4 字节,&un是联合体变量的起始地址);un.c(char类型)仅占用这 4 字节中的 “第一个字节”,即地址&un(char仅需 1 字节);也就是说,&un.a、&un.c、&un这三个地址的值完全相同 —— 所有成员的起始地址与联合体变量的起始地址一致,这是 “共用空间” 最直接的证明。
三、关键推论:修改一个成员,会影响另一个成员的数据
由于成员共用同一块空间,对任意一个成员的修改,都会覆盖共享空间中的数据,进而影响其他成员的取值。例如:
- 给
un.a赋值0x12345678(假设为小端存储,内存中字节顺序是78 56 34 12); - 此时访问
un.c,会读取共享空间的第一个字节(0x78),因此un.c的值为0x78(对应 ASCII 码或数值); - 若再给
un.c赋值0x99,则共享空间的第一个字节会被覆盖为0x99,此时un.a的值会变为0x12345699—— 原本的0x78被替换,数据发生改变。
这一特性决定了:联合体的成员不能 “同时有效”,同一时间只能使用一个成员(否则会因数据覆盖导致逻辑错误),这与结构体 “成员可同时访问” 形成鲜明对比。
四、延伸见解:联合体的核心价值与适用场景
联合体 “共用空间” 的设计,本质是 “用空间复用换取内存节省”—— 当多个成员不会同时使用时,无需为每个成员分配独立空间,仅用最大成员的空间即可满足需求,尤其适用于以下场景:
- 节省内存的场景:如嵌入式设备(内存资源有限)中,存储 “不同类型但不同时使用的数据”(例如一个变量要么存字符,要么存整数,不会同时存两种);
- 判断系统大小端:利用 “
int成员和char成员共用起始字节” 的特性,给int赋值后读取char的值,即可判断 CPU 是小端(低字节存低地址)还是大端(高字节存低地址),这是联合体的经典实用场景; - 数据类型转换(谨慎使用):通过修改一个成员、读取另一个成员,可实现简单的二进制层面数据转换(但需注意平台兼容性,避免未定义行为)。