【论文阅读】通义实验室,VACE: All-in-One Video Creation and Editing
https://arxiv.org/pdf/2503.07598
首先针对论文《VACE: All-in-One Video Creation and Editing》进行导读,涵盖研究动机、现状、创新点、解决方案、实验设计、结论与未来方向六个方面:
一、研究动机:核心问题与背景
核心问题:
当前视频生成与编辑任务高度碎片化,不同任务(如参考图生成、视频编辑、局部重绘、时序扩展等)通常依赖独立模型,导致部署成本高、用户交互复杂,且难以实现多任务协同创作。
研究背景:
- 图像生成领域已出现统一模型(如 ACE、OmniGen),支持多种图像生成与编辑任务。
- 视频生成仍停留在“单任务单模型”阶段,缺乏统一的框架来处理多样化的视频创作需求。
- 视频任务对时序一致性和空间一致性要求更高,统一建模难度大。
研究目标:
构建一个统一的多模态视频生成与编辑框架,支持文本、图像、视频、掩码等多种输入形式,实现“一站式”视频创作与编辑。
二、研究现状:领域发展与已有工作
视频生成与编辑任务分类:
- T2V(文本生成视频)
- R2V(参考图生成视频)
- V2V(视频到视频编辑)
- MV2V(掩码控制下的局部编辑)
- 任务组合(如参考图+局部编辑)
已有方法:
- 单任务模型:如 ControlVideo、Follow-Your-Pose、ProPainter、I2VGenXL 等,功能单一,难以扩展。
- 图像统一模型:如 ACE、OmniGen、UniControl,支持多任务图像生成,但未扩展至视频。
- 视频统一建模挑战:时序一致性、多模态输入融合、任务间干扰等问题尚未解决。
研究空白:
目前缺乏一个统一支持多种视频生成与编辑任务的模型框架,VACE 填补了这一空白。
三、创新点:思路来源与核心贡献
创新思路来源:
- 借鉴图像统一模型(如 ACE)的设计思想,结合视频特有的时序建模需求。
- 引入“任务解耦”与“上下文适配”机制,解决多任务输入冲突与信息融合问题。
核心创新点:
- Video Condition Unit (VCU):统一表示文本、图像、视频、掩码等多模态输入,支持任务组合。
- Concept Decoupling:将输入帧分解为“需修改区域”与“保留区域”,提升模型对任务的理解能力。
- Context Adapter 结构:在 DiT 模型中引入可插拔的上下文适配模块,实现任务注入与模型解耦。
- 统一训练框架:支持 12 类任务及其组合,首次实现视频领域的“全能模型”。
四、解决方案:方法架构与关键技术
总体框架:
- 基于 DiT(Diffusion Transformer)结构,继承其强大的生成能力与扩展性。
- 引入 VCU 输入范式,将不同任务转化为统一的帧序列与掩码序列输入。
- 采用两种训练策略:
- 全参数微调(Fully Fine-tuning)
- 上下文适配器微调(Context Adapter Tuning,推荐方案)
关键模块:
-
Context Tokenization:
- Concept Decoupling:将输入帧拆分为 Fc(修改区域)与 Fk(保留区域)
- Context Latent Encoding:使用 VAE 编码为潜变量,保持时空一致性
- Context Embedder:将帧与掩码编码为上下文 token
-
Context Adapter:
- 复制部分 DiT Block 形成 Context Block
- 上下文 token 与文本 token 一起输入 Context Block
- 输出作为残差信号注入主分支,主模型参数冻结,仅训练适配器
-
任务统一表示:
- 所有任务通过 VCU 表示为
[T; F; M],支持灵活组合与扩展
- 所有任务通过 VCU 表示为
五、实验设计:验证方法与评估体系
数据集构建:
- 自主构建训练数据,涵盖 12 类任务(如 inpainting、outpainting、pose、depth、reference 等)
- 使用 SAM2、Grounding DINO、RAM 等工具进行实例级分割与标注
- 支持动态掩码、参考图增强、时序帧采样等多种数据增强策略
评估体系:
- VACE-Benchmark:首个面向多任务视频生成与编辑的评测基准
- 包含 240 条高质量测试样本,覆盖 12 类任务
- 提供原始视频、掩码、参考图、文本描述等输入
- 评估维度:
- 自动指标:视频质量(美学、成像、动态性等)、一致性(时序、背景、主体等)
- 用户主观评估:MOS 打分,涵盖 Prompt 遵循度、时序一致性、视频质量
对比方法:
- 与当前开源/商业模型对比,如 I2VGenXL、CogVideoX、ProPainter、ControlVideo、Keling、Pika 等
- 在 I2V、inpainting、outpainting、pose、depth、R2V 等任务上全面评估
六、研究结论:主要发现与成果
实验结果:
- VACE 在多个任务上超越现有开源方法,在自动指标与用户评估中均表现优异
- 在 R2V 任务上虽略逊于部分商业模型,但已具备竞争力
- 支持任务组合生成,如“参考图+局部编辑+时序扩展”,展现出强大的创作潜力
核心结论:
- 统一建模是可行的:通过 VCU 与 Context Adapter,VACE 实现了多任务统一训练与推理
- 任务解耦与上下文注入是关键:有效解决了多任务干扰与信息融合问题
- 统一模型性能不逊色于专用模型:在多个任务上达到或超越 SOTA 水平
七、未来方向:研究展望与潜在挑战
论文提出的未来方向:
- 更大规模训练:当前模型尚未充分应用“scaling law”,未来可扩大数据与算力,提升生成质量与身份一致性
- 更强的任务组合能力:探索更复杂的任务组合与长视频生成场景
- 交互式创作系统:结合大语言模型或智能体,构建更智能的视频创作助手
- 优化推理效率:在保持质量的前提下,提升生成速度,适配更多终端设备
潜在挑战:
- 多任务训练可能引入任务间冲突,需进一步优化任务平衡策略
- 掩码与参考图输入增加用户使用门槛,需设计更友好的交互方式
- 视频生成仍面临伦理与滥用风险,需配套内容审核与责任机制
总结
VACE 是视频生成领域的一项里程碑式工作,首次实现了多任务统一的视频创作与编辑框架。通过 VCU 输入范式、Concept Decoupling 与 Context Adapter 等创新设计,VACE 打破了“单任务单模型”的局限,为视频 AIGC 提供了更高效、更灵活的解决方案。未来,随着模型规模扩大与交互方式优化,VACE 有望成为视频内容创作的基础设施平台。
VACE: 一站式视频创作与编辑
Tongyi Lab, Alibaba Group

图1:全面的VACE。我们基于Wanx2.1(左侧)和LTX-Video(右侧)展示了卓越的生成结果。对于每个任务,原始输入图像或视频(左侧)、上下文视频(左上角)和生成的帧都进行了说明。
摘要
扩散Transformer在生成高质量图像和视频方面已展现出强大的能力和可扩展性。进一步追求生成和编辑任务的统一已在图像内容创作领域取得了显著进展。然而,由于时间和空间动态一致性内在的需求,实现视频合成的统一方法仍然具有挑战性。我们介绍了VACE,它使用户能够在Video任务的一站式All-in-oneCreation和Editing框架内进行操作。这些任务包括参考到视频的生成、视频到视频的编辑和掩码视频到视频的编辑。具体来说,我们有效地通过将视频任务输入(如编辑、参考和遮罩)组织到一个统一界面,即视频条件单元(VCU),整合各种任务的需求。此外,通过利用上下文适配器结构,我们使用时间和空间维度的形式化表示将不同的任务概念注入模型,使其能够灵活处理任意视频合成任务。大量实验表明,VACE的统一模型在各个子任务上的性能与特定任务模型相当。同时,它通过多任务组合实现多样化应用。项目页面:https://ali-vilab.github.io/VACE-Page/。
1. 简介
近年来,视觉生成任务领域取得了显著进展,这主要得益于扩散模型的快速演进[24,25,48,53,54,56,57]。除了早期用于文本到图像[7,16,33]或文本到视频[9,22,64]生成的领域基础预训练模型,还涌现了大量下游任务和应用,例如重绘[3,82],编辑[4, 42, 68, 70, 75], 可控生成 [30, 76], 帧参考生成 [20, 73], 和ID参考视频合成 [11, 35, 47, 74]。这一系列发展突显了视觉生成领域的动态性和复杂性。为了提高任务灵活性并减少部署多个模型的开销,研究人员开始关注构建统一模型架构 [12, 63](例如,ACE [23, 41]和Omni-Gen [71]),旨在将不同任务集成到一个图像模型中,在保持使用简便性的同时,促进各种应用工作流程的创建。在视频领域,由于时间和空间维度上的协同变换,利用统一模型为视频创作提供了无限可能。然而,利用多样化的输入模态并确保时空一致性,对于统一视频生成和编辑来说仍然具有挑战性。
我们提出了VACE,一个用于视频创作和编辑的一体化模型,该模型执行包括参考到视频生成、视频到视频编辑、掩码视频到视频编辑以及这些任务的自由组合等任务,如图1所示。一方面,各种能力的聚合降低了服务部署和用户交互的成本。另一方面,通过将不同任务的能力结合在一个模型中,它解决了现有视频生成模型面临的挑战,如可控的长视频生成、多条件和参考生成以及连续视频编辑,从而赋予用户更大的创造力。为了实现这一点,我们利用当前主流的扩散Transformer(DiTs)结构作为基础视频框架,并预训练了文本到视频生成模型[22,64],,该模型为处理长视频序列提供了更好的基础能力和可扩展性。具体来说,VACE在构建过程中考虑了不同任务的需求,并设计了一个统一接口,称为视频条件单元(VCU),该单元集成了图像或视频等多种模态用于编辑、参考和掩码。此外,为了区分编辑和参考任务中的视觉模态信息,我们引入了概念解耦策略,使模型能够理解需要保留哪些方面以及应该进行哪些修改。同时,通过采用可插拔的上下文适配器结构,来自不同任务的概念(例如,编辑或参考的区域或范围)被注入到通过协同时空表示的模型,使其具备对统一任务的自适应处理能力。
由于缺乏现有的视频合成多任务基准,我们构建了一个包含12种不同任务的480个评估样本数据集,同时通过将其与现有的专用模型进行比较来评估VACE统一模型的性能。实验结果表明,我们的框架在定量和定性分析中均表现出足够的竞争力。据我们所知,我们是第一个基于视频DiT架构的全功能模型,能够同时支持如此广泛的任务。值得注意的是,这个创新的框架允许基础任务的组合扩展,从而构建长视频重渲染等场景,为视频合成提供了一种多功能且高效的解决方案,为用户端的视频内容创建和编辑开辟了新的可能性。
2.相关工作
视觉生成与编辑。随着图像 [2, 7, 16, 18, 58, 59] 和视频 [22, 32,73, 77] 生成模型的快速发展,它们被用于创建高质量视觉内容,并广泛应用于广告、电影特效、游戏开发和动画制作 [13, 43-45, 55]。与此同时,为了满足视觉媒体生产的多样化需求,并提高效率和品质,精确的生成和编辑方法应运而生。模型需要根据多模态输入(如深度、结构、姿态、场景和角色)进行生成式创作。根据输入条件的用途,我们可以将其分为两类:输入编辑和概念引导的重新创作。大量工作,如 ControlNet [76], ControlVideo, Composer [26], VideoComposer [68], 和 SCEdit [30], ,专注于基于时间和空间对齐条件的时间单条件编辑和多条件组合编辑。此外,一些专注于交互式局部编辑场景的工作,如 DragGAN [46] 和 MagicBrush [75]。基于输入语义信息进行生成的方法,如 Cone [38], Cone 2 [39], InstantID [67], 和 PuLID [21], ,可以实现输入的概念理解,并将其注入模型以实现创意目的。
任务统一视觉生成模型。随着用户创作的复杂性和多样性不断增加,仅依赖单个模型或多个模型的复杂链路已无法为实施创意想法提供便捷高效的路径。在图像生成领域,一个统一的生成和编辑框架开始出现,允许更灵活的创意方法。例如 UltraEdit [81] 和 SEED-Data-Edit [19] 提供了通用编辑数据集,而像In-structPix2Pix [4],MagicBrush [61], 和CosXL [60] 提供基于指令的编辑功能。此外,像 UniControl [50] 和UNIC-Adapter [15] 实现了统一的可控生成。进一步的进展导致了 ACE [23, 41], OmniGen [71],OmniControl [63], 和UniReal [12], 的开发, 它们通过提供灵活的可控生成、局部编辑和参考引导生成来扩展任务的范围。在视频领域, 由于生成的难度增加, 方法通常表现为单任务单模型框架, 提供编辑或参考生成的能力, 例如 Video-P2P [37], MagicEdit [34],MotionC-trl [69], Magic Mirror [80], 和Phantom [35]。
VACE旨在填补视频领域的统一模型空白,为复杂的创意场景提供可能性。
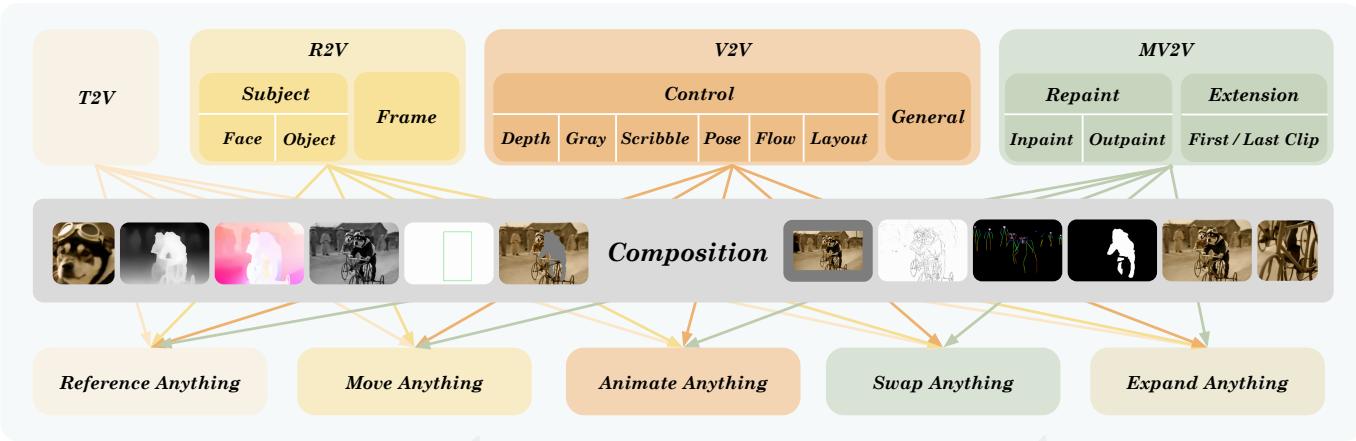
图2:VACE所涵盖的任务类别VACE。四种基本任务可以组合以创造出大量的可能性
3. 方法
VACE是设计为一种多模态到视频生成模型,其中文本、图像、视频和掩码被集成到一个统一的条件输入中。为了尽可能覆盖视频生成和编辑任务,我们对现有任务进行了深入研究,然后根据它们各自对多模态输入的要求将它们分为4个类别。在不失去普遍性的前提下,我们在视频条件单元(VCU)范式下,为每个类别专门设计了一种新的多模态输入格式。最后,我们重构了DiT模型以适应VCU输入,使其成为适用于广泛视频任务的通用模型。
3.1. 多模态输入和视频任务。
尽管现有的视频任务在复杂用户输入和雄心勃勃的创意目标上有所不同,但我们发现它们的大多数输入都可以用4种模态完全表示:文本、图像、视频和掩码。总体而言,如图2所示,我们根据对这些四种多模态输入的要求,将这些视频任务分为5个类别。
- 文本到视频生成 (T2V) 是一种基本的视频创作任务,文本是唯一的输入。
- 参考到视频生成 (R2V) 需要额外的图像作为参考输入,确保指定的内容,如人脸、动物和其他物体的主题,或视频帧,出现在生成的视频中。
- 视频到视频编辑 (V2V) 对提供的视频进行整体更改,例如上色、风格化、可控生成,等。我们使用视频控制类型,其控制信号可以表示和存储为 RGB 视频,包括深度、灰度、姿态、涂鸦、光流和布局;然而,该方法本身并不限于这些。
- 掩码视频到视频编辑 (MV2V) 仅在提供的 3D 感兴趣区域 (3D ROI) 内对输入视频进行更改,与其他未更改区域无缝融合,例如修复、扩展、视频扩展,等。我们使用额外的时空掩码来表示 3D ROI。
- 任务组合包括上述四种视频任务的所有组合可能性。
3.2. 视频条件单元
我们提出一种输入范式,视频条件单元(VCU),将多样化的输入条件统一为文本输入、帧序列和掩码序列。一个VCU可以表示为
V=[T;F;M],(1) V = [ T; F; M ], \tag {1} V=[T;F;M],(1)
其中 TTT 是文本提示,而 FFF 和 MMM 分别是上下文视频帧序列 {u1,u2,…,un}\{u_{1}, u_{2}, \dots, u_{n}\}{u1,u2,…,un} 和掩码 {m1,m2,…,mn}\{m_{1}, m_{2}, \dots, m_{n}\}{m1,m2,…,mn} 。在这里, uuu 是RGB空间,归一化到 [−1,1][-1, 1][−1,1] ,而 mmm 是二元的,其中“1”和“0”分别表示编辑位置或不编辑。 FFF 和 MMM 在空间大小 h×wh \times wh×w 和时间大小 nnn 上对齐。在T2V中,不需要上下文帧或掩码。为了保持通用性,我们为每个 uuu 分配默认值 0h×w0_{h \times w}0h×w 表示空输入,并将每个 mmm 设置为 1h×w1_{h \times w}1h×w ,意味着所有这些0值像素即将重新生成。
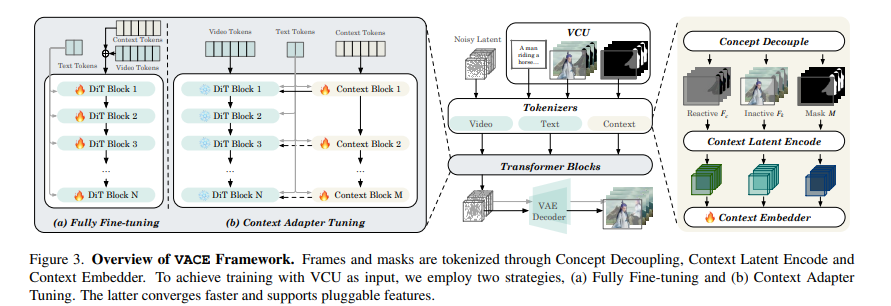
图3:概述VACE框架。帧和掩码通过概念解耦、上下文潜在编码和上下文嵌入器进行标记化。为了使用VCU作为输入进行训练,我们采用两种策略,(a)完全微调和(b)上下文适配器微调。后者收敛更快并支持可插拔功能。
表1:在四种基本任务下帧(Fs)和掩码(Ms)的正式表示。帧和掩码在空间和时间上对齐。

对于 R2V,需要额外的参考帧 rir_iri 插入在默认帧序列之前,而全零掩码 0h×w0_{h \times w}0h×w 插入在掩码序列之前。这些全零掩码表示相应的帧应保持不变。在 V2V 中,上下文帧序列是输入视频帧,上下文掩码是一个 1h×w1_{h \times w}1h×w 序列。对于 MV2V,需要上下文视频和掩码。正式的数学表示形式显示在表 1 中。1。
VCU也可以支持任务组合。例如,参考修复任务的上下文帧是 {r1,r2,…,rl,u1,u2,…,un}\{r_1,r_2,\dots ,r_l,u_1,u_2,\dots ,u_n\}{r1,r2,…,rl,u1,u2,…,un} ,上下文掩码是 {0h×w}×l+{m1,m2,…,mn}\{0_{h\times w}\} \times l + \{m_1,m_2,\dots ,m_n\}{0h×w}×l+{m1,m2,…,mn} 。在这种情况下,用户可以修改视频中的 lll 对象,并根据提供的参考图像重新生成。另一个例子是,用户只有一张涂鸦图像,并希望生成一个以该涂鸦图像描述的内容开头的视频,这是一个基于涂鸦的视频扩展任务。上下文帧是 {u}+{0h×w}×(n−1)\{u\} +\{0_{h\times w}\} \times (n - 1){u}+{0h×w}×(n−1) ,上下文掩码是 {1h×w}×n∘\{1_{h\times w}\} \times n_{\circ}{1h×w}×n∘ 通过这种方式,我们可以实现多条件和参考控制生成,用于长视频。
3.3. 架构
我们重构了DiT模型以VACE,如图3所示,旨在支持多模态VCU输入。由于已有文本分词流程,我们仅考虑上下文帧和掩码的分词。分词后,上下文token与噪声视频token结合,对DiT模型进行微调。不同于此,我们还提出了一种上下文适配器微调策略,该策略允许上下文token通过上下文块并添加回原始DiT块。
3.3.1.上下文分词
概念解耦。自然视频和控制信号(如深度、姿态)在 FFF 中同时编码。我们相信,显式分离这些不同模态和分布的数据对于模型收敛至关重要。概念解耦基于掩码,产生两个形状相同的帧序列: Fc=F×MF_{c} = F \times MFc=F×M 和 Fk=F×(1−M)F_{k} = F \times (1 - M)Fk=F×(1−M) ,其中 FcF_{c}Fc 称为反应帧,包含所有待更改的像素,而所有待保留的像素存储在 FkF_{k}Fk ,命名为非活动帧。具体来说,参考图像和 V2V 及 MV2V 的不变部分进入 FkF_{k}Fk ,而控制信号和即将更改的像素(如灰度像素)被收集到 FcF_{c}Fc 。
上下文潜在编码。一个典型的 DiT 处理带噪声的视频潜在 X∈Rn′×h′×w′×dX \in \mathbb{R}^{n' \times h' \times w' \times d}X∈Rn′×h′×w′×d , 其中 n′n'n′ , h′h'h′ 和 w′w'w′ 是潜在空间的时序和空间形状。类似于 X,Fc,FkX, F_c, F_kX,Fc,Fk 和 MMM 需要被编码到一个高维特征空间中, 以确保显著的时空相关性。因此, 我们将它们与 XXX 一起重新组织成一个层次化和时空对齐的视觉特征。 Fc,FkF_c, F_kFc,Fk 由视频 VAE 处理并映射到 XXX 的相同潜在空间中, 保持它们的时空一致性。为了避免图像和视频的任何意外混合, 参考图像由 VAE 编码器单独编码, 并沿时间维度连接回去, 而对应于 -
解码过程中需要移除 ingparts。 MMM 直接进行重塑和插值。之后, FcF_{c}Fc 、 FkF_{k}Fk 和 MMM 都被映射到潜在空间,并与形状为 n′×h′×w′n' \times h' \times w'n′×h′×w′ 的 XXX 在时空上对齐。
上下文嵌入器。我们通过在通道维度上连接 FcF_{c}Fc 、 FkF_{k}Fk 和 MMM 并将它们标记化为上下文标记,扩展了嵌入器层,这些上下文标记被称为上下文嵌入器。标记化 FcF_{c}Fc 和 FkF_{k}Fk 的对应权重直接从原始视频嵌入器复制,标记化 MMM 的权重由零初始化。
3.3.2. 完全微调和上下文适配器微调
为了使用 VCU 作为输入进行训练,一种简单的方法是完整地微调整个 DiT 模型,如图所示。3 上下文标记与噪声标记一起添加 XXX ,并且 DiT 和新建的上下文嵌入器的所有参数在训练过程中都会被更新。为了避免完整微调和实现更快的收敛,以及与基础模型建立可插拔的功能,我们还提出了另一种处理上下文标记的 Res-Tuning [29] 方式,如图所示。3b。特别地,我们选择并复制了原始 DiT 中的几个 Transformer 模块,形成分布式和级联型的上下文模块。原始 DiT 处理视频标记和文本标记,而新添加的 Transformer 模块处理上下文标记和文本标记。每个上下文模块的输出插入回 DiT 模块作为加性信号,以协助主分支执行生成和编辑任务。以这种方式,DiT 的参数被冻结。只有上下文嵌入器和上下文模块是可训练的。
4. 数据集
4.1. 数据构建
为了获得一体化模型,所需数据构建的多样性和复杂性也随之增加。现有的常见文本到视频和图像到视频任务只需要构建文本和视频的对。然而,对于VACE的任务,模态需要进一步扩展以包括目标视频、源视频、局部掩码、参考等。为了高效快速地获取各种任务的数据,在同时进行实例级分析和理解视频数据的同时,保持视频质量至关重要。
为此,我们首先通过执行镜头切片并根据分辨率、美学评分和运动幅度初步过滤数据来分析视频数据本身。接下来,我们使用RAM[78]并结合Grounding DINO [36] 进行检测,利用定位结果对具有太小或太大的目标区域视频进行二次过滤。此外,我们采用传播操作SAM2 [52] 用于视频分割以获取视频中的实例级信息。利用视频分割的结果,我们通过根据掩码区域阈值计算有效帧率来在时间维度上过滤实例。
在实际训练过程中,不同任务的构建也需要根据每个任务的特征进行定制:1)对于一些可控的视频生成任务,我们从过滤后的视频中预先提取深度[51],描绘[6],姿势[5,72],和光流[65]。对于灰度和布局任务,我们动态创建数据。2)对于重绘任务,可以从视频中随机选择实例进行掩码以进行修复,而掩码的逆操作可以用于构建外绘数据。掩码[62]的增强允许无条件修复。3)对于扩展任务,我们提取第一帧、最后一帧、两端帧、随机帧以及两端片段等关键帧,以支持更广泛的扩展类型。4)对于参考任务,我们可以从视频中提取几个面部或对象实例,并应用离线或在线增强操作以创建成对数据。值得注意的是,我们随机组合所有之前提到的任务进行训练,以适应更广泛的模型应用场景。此外,对于所有涉及掩码的操作,我们进行任意增强以满足各种粒度局部生成需求。
4.2. VACE-Benchmark
在视频生成领域已取得显著进展。然而,对这些模型性能进行科学和彻底的评估仍然是一个亟待解决的问题。VBench [27] 和 VBench++ [28] 通过广泛评估套件和维度设计,为文本到视频和图像到视频任务建立了一个精确的评估框架。尽管如此,随着视频生成生态系统的不断发展,更多衍生任务开始出现,如视频参考生成和视频编辑,而针对这些任务的综合基准仍然缺乏。为了填补这一空白,我们提出了VACE-Benchmark 以系统的方式评估与视频相关的各种下游任务。
从数据源来看,我们认识到真实视频和生成视频在评估过程中可能表现出不同的性能特征。因此,我们收集了总共240个按来源分类的高质量视频,涵盖各种数据类型,包括文本到视频、修复、扩展、灰度、深度、涂鸦、姿态、光流、布局、参考人脸和参考对象任务,每个任务平均20个样本。输入模态包括输入视频、掩码和参考,我们还提供了原始视频以支持开发人员根据每个任务的特定特征进行进一步处理。关于数据提示,我们提供视频的原始标题以进行定量评估,以及针对特定任务重新编写的提示以评估模型的创造力。
表2。在VACE-Benchmark上的定量评估。我们比较基于LTX-Video的统一VACE在视频质量和视频一致性维度上的自动化评分指标,以及人类用户研究的结果。
| Type | 方法 | Video Quality & Video Consistency | 用户研究 y | ||||||||||||
| Aesthetic Quality | Background Consistency | Dynamic Degree | Imaging Quality | Motion Smoothness | Overall Consistency | Subject Consistency | Temporal Flickering | Normalized Average | Prompt Following | Temporal Consistency | Video Quali | Average | |||
| I2V | I2VGenXL [77] | 55.20% | 92.87% | 60.00% | 63.31% | 97.43% | 23.78% | 89.58% | 95.67% | 71.54% | 2.65 | 1.60 | 2.34 | 2.20 | |
| CogVideoX-I2V [73] | 57.78% | 94.80% | 40.00% | 68.23% | 98.69% | 24.38% | 93.84% | 97.84% | 73.66% | 3.30 | 2.28 | 3.19 | 2.92 | ||
| LTX-视频 [22] | 56.12% | 94.57% | 35.00% | 62.72% | 99.27% | 24.92% | 92.83% | 98.41% | 72.89% | 2.95 | 2.28 | 2.28 | 2.50 | ||
| VACE (我们的) | 57.53% | 95.32% | 45.00% | 68.03% | 99.08% | 25.13% | 93.61% | 97.80% | 74.38% | 3.20 | 4.00 | 2.54 | 3.24 | ||
| Inpaint | ProPainter [82] | 44.70% | 95.64% | 50.00% | 61.57% | 99.01% | 18.48% | 92.99% | 98.47% | 70.15% | 2.35 | 4.00 | 2.99 | 3.11 | |
| VACE (我们的) | 51.30% | 96.30% | 50.00% | 60.39% | 99.12% | 21.12% | 94.59% | 98.21% | 72.05% | 2.40 | 4.00 | 2.60 | 3.00 | ||
| Outpaint | Follow-Your-Canvas [8] | 53.30% | 95.99% | 5.00% | 69.53% | 98.08% | 25.90% | 95.38% | 97.20% | 71.54% | 3.05 | 2.00 | 1.63 | 2.23 | |
| M3DDM [17] | 53.34% | 95.87% | 30.00% | 65.07% | 99.22% | 25.43% | 93.65% | 98.85% | 73.16% | 3.70 | 3.88 | 2.28 | 3.29 | ||
| VACE (我们的) | 57.04% | 96.55% | 30.00% | 69.49% | 99.20% | 25.36% | 94.47% | 98.47% | 74.25% | 3.90 | 3.92 | 3.58 | 3.80 | ||
| 深度 | 控制-A-视频 [10] | 50.62% | 91.71% | 70.00% | 67.76% | 97.58% | 24.48% | 88.10% | 96.58% | 72.35% | 2.70 | 2.28 | 1.54 | 2.17 | |
| 视频合成器 [68] | 50.03% | 94.18% | 70.00% | 59.44% | 96.23% | 24.95% | 89.79% | 94.38% | 70.74% | 2.60 | 2.44 | 2.17 | 2.40 | ||
| ControlVideo [79] | 63.30% | 95.02% | 10.00% | 65.13% | 96.49% | 24.20% | 92.29% | 95.42% | 70.07% | 2.55 | 2.50 | 1.82 | 2.29 | ||
| VACE (我们的) | 56.72% | 96.12% | 60.00% | 66.41% | 98.84% | 25.27% | 94.09% | 97.27% | 74.99% | 3.10 | 3.92 | 2.66 | 3.23 | ||
| Pose | Text2Video-Zero [31] | 57.63% | 87.67% | 100.00% | 70.74% | 79.65% | 23.94% | 84.82% | 76.57% | 59.69% | 2.15 | 2.00 | 1.88 | 2.01 | |
| 控制视频 [79] | 65.37% | 94.56% | 25.00% | 65.28% | 97.32% | 25.19% | 92.76% | 96.82% | 72.45% | 2.15 | 1.80 | 2.03 | 1.99 | ||
| 跟随你的姿势 [40] | 48.79% | 86.80% | 100.00% | 67.41% | 90.12% | 26.10% | 80.18% | 88.02% | 66.43% | 2.00 | 2.60 | 1.58 | 2.06 | ||
| VACE (我们的) | 60.17% | 94.92% | 75.00% | 64.71% | 98.63% | 26.44% | 94.82% | 96.60% | 76.13% | 2.95 | 3.96 | 2.63 | 3.18 | ||
| Flow | FLATTEN [14] | 56.23% | 95.80% | 70.00% | 61.65% | 97.86% | 26.23% | 93.94% | 96.17% | 74.42% | 3.50 | 2.40 | 3.19 | 3.03 | |
| VACE (我们的) | 55.76% | 96.07% | 75.00% | 65.37% | 98.98% | 25.89% | 94.63% | 96.93% | 75.90% | 2.90 | 3.75 | 2.60 | 3.08 | ||
| R2V | Keling1.6 [1] | 62.13% | 96.04% | 85.00% | 69.27% | 99.38% | 27.82% | 93.79% | 97.79% | 78.81% | 4.22 | 4.10 | 3.80 | 4.04 | |
| Pika2.2 [49] | 62.48% | 96.79% | 65.00% | 69.87% | 99.37% | 26.02% | 95.93% | 98.90% | 77.87% | 4.00 | 3.85 | 3.87 | 3.91 | ||
| Vidu2.0 [66] | 64.30% | 96.85% | 35.00% | 67.03% | 99.66% | 26.53% | 96.73% | 99.41% | 76.47% | 3.90 | 3.85 | 3.77 | 3.84 | ||
| VACE (我们的) | 63.25% | 98.03% | 30.00% | 72.29% | 99.51% | 25.85% | 98.54% | 99.15% | 76.76% | 3.47 | 3.42 | 3.30 | 3.40 | ||
5. 实验
5.1. 实验设置
实现细节。VACE是在不同尺度的文本到视频生成中基于扩散Transformer进行训练的。它利用LTX-Video-2B [22]进行更快的生成,而Wan-T2V-14B [64]专门用于更高质量的输出,支持高达720p的分辨率。训练采用分阶段方法。最初,我们专注于基础任务,如修复和扩展,这些任务被认为是与预训练的文本到视频模型互补的模态。这包括掩码的加入和在空间和时间维度上学习上下文生成。接下来,从任务扩展的角度来看,我们逐步从单输入参考帧过渡到多输入参考帧,从单任务过渡到复合任务。最后,我们使用更高质量的数据和更长的序列来微调模型的性能。模型训练的输入支持任意分辨率、动态时长和可变帧率,以支持用户的多样化输入需求。
基线。我们的目标是实现视频创建和编辑任务的统一,目前还没有可比较的一体化视频生成模型可用,这导致我们专注于将我们的通用模型与专有任务特定模型进行比较。此外,由于涉及的任务众多,且许多任务缺乏开源方法,我们在离线或在线可用的模型上进行比较。具体到任务,我们比较以下内容:1)对于I2V任务,我们考察I2VGenXL[77],CogVideoX-I2V[73],和LTX-Video-I2V[22];2)在重绘任务中,我们比较用于移除重绘的ProPainter[82],以及用于外绘的Follow-Your-Canvas[8]和M3DDM[17];3)对于可控任务,在深度条件下,我们使用Control-A-Video[10], VideoComposer[68],和ControlVideo[79],在姿态条件下,我们比较Text2Video-Zero[31], ControlVideo[79],和Follow-Your-Pose[40],以及FLAT-TEN [14] 在光流条件下;4) 在参考生成中,鉴于开源模型的缺失,我们比较了商业产品Keling1.6[1], Pika2.2[49],和Vidu2.0[66]。
**评估。**为了全面评估各种任务的性能,我们采用VACE-Benchmark进行评估。具体来说,我们将评估分为自动评分和手动评估的用户研究。对于自动评分,我们利用VBench中的部分指标来评估视频质量和视频一致性,包括八个指标:美学质量、背景一致性、动态程度、成像质量、运动平滑度、整体一致性、主体一致性和时间闪烁。对于手动评估,我们使用平均意见分数(MOS)作为评估指标,重点关注三个方面:提示遵循、时间一致性和视频质量。在实践中,我们对生成的数据进行匿名化,并随机分配给不同的参与者进行1到5分的评分。

5.2. 主要结果
定量评估。我们比较VACE基于LTX-Video的综合模型与任务专有方法在VACE-Benchmark上的表现。对于某些任务,我们遵循现有方法;例如,尽管我们支持基于任何帧生成,但我们使用当前开源方法的首次帧参考方法进行对比以确保公平性。从表2,我们可以看到,对于I2V、修复、扩展、深度、姿态和光流等任务,我们的方法在视频质量和视频一致性八个指标上均优于其他开源方法,标准化平均指标显示出更优的结果。一些竞争方法只能在256分辨率下生成,生成时间非常短,并且在时间连贯性上表现出不稳定,导致在自动指标计算上表现较差。对于R2V任务,对于旨在快速生成的小规模模型,指标与商业模型相比仍存在一定差距。
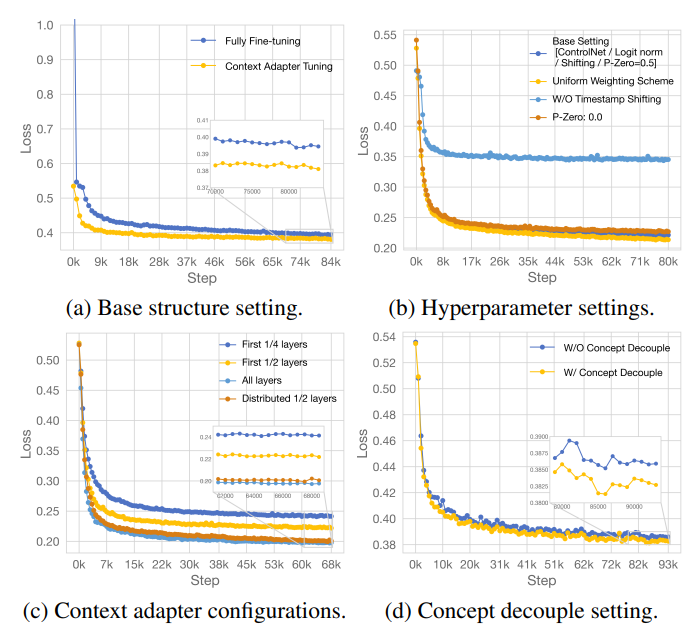
图5:消融研究关于结构、超参数和模块配置的VACE研究。
同时,在Vidu 2.0的指标上具有可比性。根据人类用户研究的结果,我们的方法在多个任务的评价指标上始终表现更好,与用户偏好高度一致。
定性结果。在图1中,我们展示了VACE单模型在各个任务上的结果。很明显,模型在视频质量和时间一致性方面达到了很高的性能水平。此外,在图4中展示的组合任务中,我们的模型展现出令人印象深刻的能力,有效地整合了不同的模态和任务,生成了现有单模型或多模型无法生成的结果,从而在视频生成和编辑领域展示了其强大的潜力。例如,在“移动任何东西”的案例中,通过提供一个输入图像和运动轨迹,我们能够精确地移动场景中的角色,并保持指定的方向、连贯性和叙事一致性。
5.3. 消融研究
为了更好地理解不同独立模块对统一视频生成框架的影响,我们基于LTX-Video模型进行了一系列系统的对比实验,以实现更好的模型结构和配置。为了准确评估不同的实验设置,我们对每个任务采样250个数据点作为验证集,并计算训练损失,通过不同任务的平均曲线变化反映模型的训练进度。
基础结构。文本引导的图像或视频生成模型仅将噪声作为推理输入。当扩展到我们的统一输入范式,VCU,我们可以使用全量微调或通过引入额外的参数微调进行训练。具体来说,如图5a所示,我们比较了沿通道维度连接的不同输入,并修改了patchify投影层的输入维度,以实现预训练模型的加载和全量微调。此外,我们以Res-Tuning[29],的形式引入了一些额外的训练参数,它在旁路分支中序列化VCU,并将信息注入主分支。结果表明,两种方法都产生了相似的效果;然而,由于额外的参数微调收敛更快,我们基于此方法进行了后续实验。如图5b所示,我们进一步基于此结构进行了超参数实验,重点关注权重方案、时间戳偏移和p-zero等方面。
上下文适配器。由于上下文块的数量将显著影响模型大小和推理时间消耗,我们尝试找到一个最优的上下文块数量和分布。我们从输入侧选择连续块开始,并比较前1/4块、1/2块和所有块。受Res-Tuning[29]方法的启发,我们还尝试均匀分布注入块,而不是选择连续的块序列。如图5c所示,当使用相同数量的块时,块的分布排列在浅层块中优于连续排列。此外,更多的块通常能获得更好的结果,但由于有效性的提升有限和训练资源的限制,我们采用部分分布的块排列。
概念解耦。在训练过程中,我们引入了一个概念解耦处理模块,以进一步分解视觉单元,明确模型需要学习修改或保留的内容。如图5d所示,使用该模块导致损失显著降低。
6. 结论
本文介绍了VACE,一个集成的视频生成和编辑框架。它统一了各种视频任务所需的多样化、复杂的多模态输入,弥合了每个独立任务的专业模型之间的差距。这使得大多数视频AI创建任务可以通过单个模型的单次推理来完成。虽然广泛涵盖了各种视频任务,VACE还支持这些任务的灵活和自由组合,极大地扩展了视频生成模型的应用场景,并满足了广泛的用户创意需求。VACE框架为开发具有多模态输入的统一视觉生成模型铺平了道路,并在视觉生成领域代表了一个重要的里程碑。
致谢。我们衷心感谢许多同事的贡献,包括他们富有见地的讨论、宝贵的建议和建设性的反馈,包括:王宇伟、赵海明、谢晨伟和姚胜对于数据贡献,以及张石伟、方涛、王翔对于讨论和建议。
附录
在补充材料中,我们提供更详细的实现细节(附录A)包括训练和推理中使用的超参数。然后,我们展示了与现有方法的额外比较和更多定性结果(附录B)。此外,我们讨论了社会影响和局限性(附录C)。
A. 实现细节
A.1. 超参数
在表3中,我们概述了超参数设置,并基于LTX-Video[22]和Wan-T2V[64]的基础文本到视频生成模型进行训练。前者允许在有限资源下快速推理;在一个A100单卡环境中,没有专门的加速策略,采样40步以生成一个约5秒时长的视频大约需要24秒。这满足了普通用户对视频处理的需求。相比之下,Wan-T2V是一个全面的性能视频生成模型,训练和推理需要相对更多的资源,但它能够生成高质量的视觉效果并保持平滑的时间一致性。
B. 其他结果
B.1. 更多可视化
在图 .6 和图 .7 中,我们基于 Wan-T2V 展示了更多定性的结果,包括诸如扩展、修复、延伸、灰度、深度、涂鸦、姿态、布局、人脸参考和物体参考等任务。
B.2. 可视化比较
在图.8中,我们展示了基于LTX-Video-2B的VACE与其他方法的比较可视化[22],包括与I2VGenXL[77],CogVideoX[73],和LTX-Video-I2V[22]的比较(扩展任务);与ProPainter[82]的比较(无条件修复任务);与Follow-Your-Canvas[8]和M3DDM[17]的比较(外绘任务);与Control-A-Video[10],VideoComposer[68],和ControlVideo[79]的比较(深度控制生成);与Text2Video-Zero[31],ControlVideo[79]和Follow-Your-Pose[40]的比较(姿态控制生成);与FLATTEN[14]的比较(光流控制生成);以及与商业闭源模型Keling1.6[1],Pika2.2[49],和Vidu2.0[66]的比较。
C. 讨论
C.1. 限制
首先,生成内容的质量和整体风格通常受基础模型的影响。本文跨不同模型规模验证了这一点:较小的模型
有利于快速视频生成,但视频的质量和连贯性不可避免地受到挑战;较大的参数模型显著提高了创意输出的成功率,但推理速度变慢,资源消耗增加。在两者之间找到一个相对的平衡也是我们未来工作的一个关键重点。
其次,与用于文本到视频生成的基础模型相比,当前的统一模型尚未在大规模数据和计算能力上进行训练。这导致了一些问题,例如在参考生成时无法完全保持身份,以及在执行组合任务时对输入缺乏完全控制。正如论文中关于完整微调和额外参数微调的讨论所述,当统一任务开始应用缩放规律时,结果是有希望的。
此外,与图像模型相比,统一模型的操作方法由于输入中包含时间信息和各种模态而存在一定的挑战。这方面为实际使用设置了一个门槛。因此,探索如何有效利用现有语言模型或代理模型的能力来指导视频生成和编辑,从而提高生产力,是值得研究的。
C.2. 社会影响
从积极的角度来看,智能视频生成和编辑可以为创作者提供一系列创新工具,帮助他们激发新想法并提升视频内容的艺术性和创新性。这些技术正逐渐应用于各个行业;例如,在商业领域,视频生成技术正在改变营销和广告策略。公司可以快速制作高质量的促销视频,有效传达品牌信息并吸引消费者。这种提高效率的能力不仅节省了劳动力成本,还使企业能够实施更具创意的营销策略,从而增强其市场竞争力。
然而,随着这些技术的普及,一些社会挑战也随之出现。视频生成和编辑的便利性可能导致虚假信息和错误内容的传播,损害公众对信息的信任。此外,在生成内容时,技术可能会无意中强化现有的偏见和刻板印象,对社会文化认知产生负面影响。这些问题促使人们反思伦理和责任,呼吁政策制定者、技术开发者以及社会各个领域共同努力,建立适当的法规,以确保这些技术的健康发展。我们还需要以谨慎的态度审视其潜在影响,积极探索平衡创新与社会责任的方法,以便它们能为社会带来更大的利益。
表 3. LTX-Video-based 和 Wan-T2V-based 的超参数选择 VACE.
| 配置 | #模型 | |
| LTX-Video-based | Wan-T2V-based | |
| Task | 12个任务+组成任务 | 12个任务+组成任务 |
| 批处理大小/GPU | 1 | 1/8 |
| 累积步长 | 8 | 1 |
| 优化器 | AdamW | AdamW |
| 权重衰减 | 0.1 | 0.1 |
| 学习率 | 0.0001 | 0.00005 |
| 学习率计划 | 常数 | 常数 |
| 训练步骤 | 200,000 | 200,000 |
| 分辨率~ | 480p | ~720p |
| 移动 | Ture | True |
| 加权方案 | 制服 | 制服 |
| 序列长度 | 4992 | 75600 |
| 层数 | 28 | 40 |
| 上下文适配器 | Res-Tuning | Res-Tuning |
| 上下文层 | [0,2,4,6,8,10,12,14,16,18,20,22,24,26] | [0,5,10,15,20,25,30,35] |
| 概念解耦 | Ture | True |
| 预训练模型 | LTX-Video-2b-v0.9 | Wan2.1-T2V-14B |
| Sampler | Flow Euler | Flow Euler |
| Sample Steps | 40 | 25 |
| 指南比例 | 3.0 | 4.0 |
| 生成速度~ | 24s | ~260s (8 gpus) |
| Device | A100×16 | A100×128 |
| Training Strategy | AMP / DDP / BFloat16 | FSDP / Tensor Parallel / BFloat16 |

TASK-OUTPAINTING:一艘巨大的飞船正在太空中飞行,背景中可见一艘较小的飞船。突然,较大的飞船爆炸成巨大的火球,碎片向四面八方飞散。爆炸非常剧烈和明亮,火焰和烟雾从残骸中腾起。较小的飞船完好无损,继续飞离现场。……

TASK-INPAINTING:一个人在户外画布上作画,使用调色板上的各种颜色的颜料。这个人穿着深蓝色夹克和配套的贝雷帽,坐在木椅子上。画布描绘了一幅风景画,背景有水体和山脉。这个人正在仔细地将绿色颜料涂抹在画布上,为场景添加细节。……

TASK-EXTENSION: 一只翅膀为黑色和橙色的蝴蝶飞向树枝上悬挂的棕色种子荚。蝴蝶落在种子荚上,使其轻微摇摆,然后迅速飞走。背景是模糊的绿色,暗示着森林或花园环境。光线明亮自然,表明是白天。相机保持静止,……

TASK-DEPTH: 一只穿着厨师服的猪站在厨房里,手里拿着一个下方有蓝色火焰的煎锅。猪戴着白色厨师帽和围裙,正在搅拌锅中黄色的碎食物。背景是一个现代化的厨房,配有不锈钢电器、水槽,以及放在台面上的各种厨房工具和容器。光线明亮自然,……

图6:更多可视化结果Wan-T2V-based VACE框架
TASK-POSE: 一位留着卷发的年轻女子身穿白色衬衫,站在黄色背景下。她面带微笑,看着镜头,同时用右手将太阳镜举到额头上。这位女士皮肤黝黑,头发是松散的卷发,垂落在肩膀周围。她戴着带有金色边框和红色镜片的宽大圆形太阳镜。……

TASK-GRAY: 一位留着长卷发的女孩躺在紫罗兰花和薄纱制成的床上。她身穿带有复杂蕾丝细节的粉色连衣裙。女孩伸手去触摸她头顶上的花朵,面带微笑,看起来很满足。背景中充满了更多的紫罗兰和绿叶,营造出梦幻般的氛围。相机角度从上方拍摄,捕捉了女孩和周围的鲜花,画面柔和……

TASK-SCRIBBLE: 一位身穿浅蓝色衬衫的人正轻柔地抚摸躺在白色桌子上的虎斑猫。猫身上穿着带有卡通人物的白色服装,看起来放松而满足,随着那人抚摸它的头部和身体。背景简洁且颜色浅淡,使人和猫的互动成为焦点。相机保持静止……

TASK-LAYOUT: 一只鹰在晴朗的天空下飞越平静的蓝色海洋。这只拥有棕色和白色羽毛以及黄色喙的鹰,朝着水面俯冲,翅膀展开宽阔。当它接近水面时,它潜入水中,激起水花,然后带着鱼爪中的鱼浮出水面。鹰随后再次起飞,带着紧握的鱼飞离相机……


任务对象:一件色彩鲜艳的中国舞狮服装在深红色背景下醒目地站立着,散发着传统文化的意义和节日气氛。该服装具有精致的细节,边缘装饰着黄色毛皮,并饰有复杂的绿色、红色和金色图案。装饰品如大而富有表现力的眼睛、宽大的带牙齿的笑容……


图7:更多可视化结果Wan-T2V-based VACE框架
人物:一个男人坐在桌子旁下棋。他右手拿着一个棋子,似乎正在思考他的下一步。这个男人有卷发和胡子,穿着一件黑色毛衣,外面套着一件白色衬衫。棋盘在他面前,棋盘上还放着几个棋子。桌子上还有几个瓶子。背景是简单和中性的。……
仕劳扩展:A man in a long-long-sleeve shirt is sitting inside a white vehicle, holding a walkie-talkie. He looks from窗外望出去,表情严肃。镜头逐渐聚焦在他的脸上,强调他专注的眼神…

TASK-UNCONDITIONAL. INPAINTING: The video shows the streets in autumn, with the ground covered in golden and reddish brown fallen leaves dancing gently in the wind. The colorful trees around shimmer with brilliant colors …

TASK-OUTPAINTING: A small monkey with a white and brown fur pattern is sitting in a lush green forest. The monkey looks around curiously, occasionally moving its head and raising its hand to its face. Its eyes are wide and expressive …

TASK-FACE: A man dressed in formal attire stood on the outdoor green grass, smiling. He is wearing a brown tuteed jacket over a white dress shirt, neatly buttoned up, and a maroon tie with small white polka dots. His dark hair is neatly combed and styled. The background is a grassland with a few trees. The man’s head is covered by a black hat and his face is bright and looking is even and bright, typical of studio lighting, which highlights the details of the man’s attire …


仕劳深度:A close-up shot of a white flower with yellow stamen in the center, surrounded by green leaves. The flower前景清晰而背景模糊,营造出美景色。光线自然明亮。…

TASK-POSE: A woman with long brown hair tied in a ponytail, wearing a black long-sleeve crop top and black leggings, is jogging along the edge of a calm body of water. She has white earphones in her ears and a smartwatch on her left wrist.

TASK-Flow: A group of white geese with orange beaks and feet walk in a line across a lush green field dotted with small white flowers. The geese move steadily from left to right, maintaining their formation as they traverse the grassy terrain …

TASK-OBJECT: A sleek and modern pair of white over-ear headphones is prominently displayed against a orange lighting background. The headphones, with their smooth curves and padded ear cups, seem to float effortlessly, emphasizing their lightweight and comfortable design. The headphones are also designed to be more comfortable and detailed along their outer panels. The background is a solid gray that sets a neutral backdrop …


图8:定性比较基于LTX-Video的VACE框架