一、环境准备
二、爬取思路
- 分析网站的html结构
- 发出请求获取html
- 解析html获取想要的内容
- 存储解析后的数据
三、代码
import requests
from bs4 import BeautifulSoup
import pandas as pddef request(url):r = requests.get(url);return r.text;def parse(html):movie_list = [];soup = BeautifulSoup(html, 'lxml')for div in soup.find_all(name='div', attrs={'class': 'is-hover-shadow'}):movie_info = {};h2 = div.find(name='h2', attrs={'class': 'm-b-sm'})movie_info['name'] = h2.text;category_list = [];for button in div.find_all(name='button'):category = button.find(name='span').textcategory_list.append(category);movie_info['categories'] = ",".join(category_list);info_list = [];for infoTag in div.find_all(attrs={'class': 'm-v-sm info'}):for spanTag in infoTag.find_all(name='span'):info_list.append(spanTag.text);movie_info['location'] = info_list[0];movie_info['duration'] = info_list[2];if len(info_list) == 4:movie_info['release_date'] = info_list[3][0:10];else:movie_info['release_date'] = '';score_tag = div.find(name='p', attrs={'class': 'score'});movie_info['score'] = score_tag.text.strip();movie_list.append(movie_info);return movie_list;def save(data):df = pd.DataFrame(data);df.columns = ['电影名', '类型', '地域', '时长', '上映时间', '评分'];df.to_csv("data.csv", index=False, encoding='utf-8-sig');if __name__ == '__main__':html = request('https://ssr1.scrape.center/page/1')print('获取html成功..')movie_list = parse(html);print('解析html成功..')save(movie_list)print('写入文件成功...')
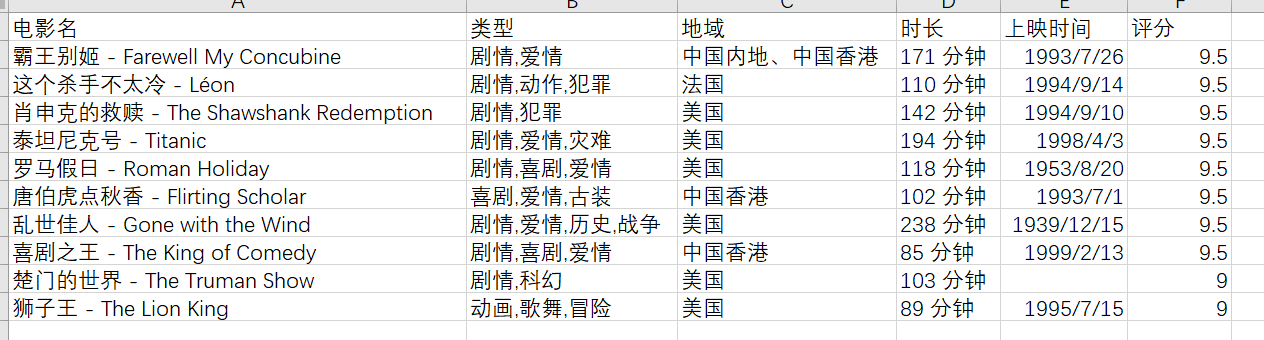
四、结果展示