动态规划 - 回文子串问题

回文子串
动态规划解决的回文串问题,核心是要求解“最值”(如最长回文子串)或“数目”(如回文子串总数),并且其判断过程天然存在“一个大的回文串去掉两头后依然是回文串”这种重叠子问题。
详细说明
这类问题的题目类型和适用场景如下:
1. 典型的题目类型
-
统计回文子串的个数
-
例题: “给你一个字符串
s,请你统计并返回这个字符串中 回文子串 的数目。” -
为什么用DP: 暴力枚举所有子串是 O(n²),判断每个子串是否是回文又是 O(n),总复杂度 O(n³)。使用DP可以在 O(1) 时间内判断一个子串是否是回文,从而将总复杂度降至 O(n²)。
-
-
寻找最长的回文子串
-
例题: “给你一个字符串
s,找到s中最长的回文子串。” -
为什么用DP: 与上题类似,需要高效地判断任意子串
[i...j]是否为回文,并记录其长度,从而找到最大值。
-
-
分割回文串(及其变种)
-
例题: “给你一个字符串
s,请你将s分割成一些子串,使每个子串都是回文串。返回所有可能的分割方案。” 或者 “返回符合要求的最少分割次数。” -
为什么用DP: 这类问题通常需要两步DP。第一步,先用标准的回文DP表预计算出所有可能的回文子串,这样在第二步进行分割(DFS回溯或再次DP求最小分割)时,可以快速查询任意子串是否为回文。
-
2. 什么题目适用于动态规划?
判断一个回文串问题是否适合用动态规划解决,主要看它是否满足以下两个条件:
-
问题性质: 要求解的是与“所有子串”或“某一连续区间”相关的全局信息,比如总数、最大值、最小值或所有具体方案。如果只是判断单个字符串是否是回文,直接双指针即可,无需DP。
-
状态转移(核心): 存在重叠子问题。
一个回文串的判断具有最优子结构:一个字符串
s是回文串的充要条件是:-
它的首尾两个字符相等。
-
去掉首尾两个字符后的子串(即
s[i+1...j-1])也必须是回文串。
这个性质允许我们定义状态
dp[i][j]表示子串s[i...j]是否为回文。那么状态转移方程就是:
dp[i][j] = (s[i] == s[j]) && (j - i < 2 || dp[i+1][j-1])这意味着,要计算
dp[i][j],我们需要先知道dp[i+1][j-1]。这种依赖关系使得我们可以用填表的方式,从短子串向长子串扩展,避免重复计算。 -
总结
当你的问题涉及到枚举或统计字符串中大量连续子串的回文性质,并且可以利用小回文串的结果来推导大回文串的结果时,动态规划就是最合适的算法。它通过一张二维DP表,空间换时间,将指数级或立方级的暴力解法优化到多项式时间复杂度(通常是 O(n²))。
题目练习
647. 回文子串 - 力扣(LeetCode)
解法(动态规划):
算法思路:
我们可以先 **「预处理」一下,将所有子串「是否回文」** 的信息统计在 dp 表里面,然后直接在表里面统计 true 的个数即可。
1. 状态表示:
为了能表示出来所有的子串,我们可以创建一个 n * n 的二维 dp 表,只用到 **「上三角部分」** 即可。
其中,dp[i][j] 表示:s 字符串 [i, j] 的子串,是否是回文串。
2. 状态转移方程:
对于回文串,我们一般分析一个 **「区间两头」** 的元素:
-
ⅰ. 当
s[i] != s[j]的时候:不可能是回文串,dp[i][j] = 0; -
ⅱ. 当
s[i] == s[j]的时候:根据长度分三种情况讨论:-
长度为
1,也就是i == j:此时一定是回文串,dp[i][j] = true; -
长度为
2,也就是i + 1 == j:此时也一定是回文串,dp[i][j] = true; -
长度大于
2,此时要去看看[i + 1, j - 1]区间的子串是否回文:dp[i][j] = dp[i + 1][j - 1]。
-
综上,状态转移方程分情况谈论即可。
3. 初始化:
因为我们的状态转移方程分析的很细致,因此无需初始化。
4. 填表顺序:
根据 **「状态转移方程」,我们需要「从下往上」** 填写每一行,每一行的顺序无所谓。
5. 返回值:
根据 **「状态表示和题目要求」**,我们需要返回 dp 表中 true 的个数。
class Solution {
public:int countSubstrings(string s) {int n = s.size(), ret = 0;vector<vector<bool>> dp(n, vector<bool>(n));for(int i = n - 1; i >= 0; i--){for(int j = i; j < n; ++j){if(s[i] == s[j])dp[i][j] = i + 1 < j ? dp[i + 1][j - 1] : true;if(dp[i][j]) ret++;}}return ret;}
};
5. 最长回文子串 - 力扣(LeetCode)
解法(动态规划):
算法思路:
- a. 我们可以先用
dp表统计出 **「所有子串是否回文」** 的信息; - b. 然后根据
dp表中true的位置,得到回文串的 **「起始位置」和「长度」**。
那么我们就可以在表中找出最长回文串。
关于 **「预处理所有子串是否回文」**,已经在上一道题目里面讲过,这里就不再赘述啦~
class Solution {
public:string longestPalindrome(string s) {int n = s.size(), start = 0, max_len = 0;vector<vector<bool>> dp(n, vector<bool>(n));for(int i = n - 1; i >= 0; i--){for(int j = i; j < n; ++j){if(s[i] == s[j])dp[i][j] = i + 1 < j ? dp[i + 1][j - 1] : true;if(dp[i][j]){int tmp_len = j - i + 1;if(tmp_len > max_len){start = i;max_len = tmp_len;}}}}areturn s.substr(start, max_len);}
};
1745. 分割回文串 IV - 力扣(LeetCode)
解法(动态规划):
算法思路:
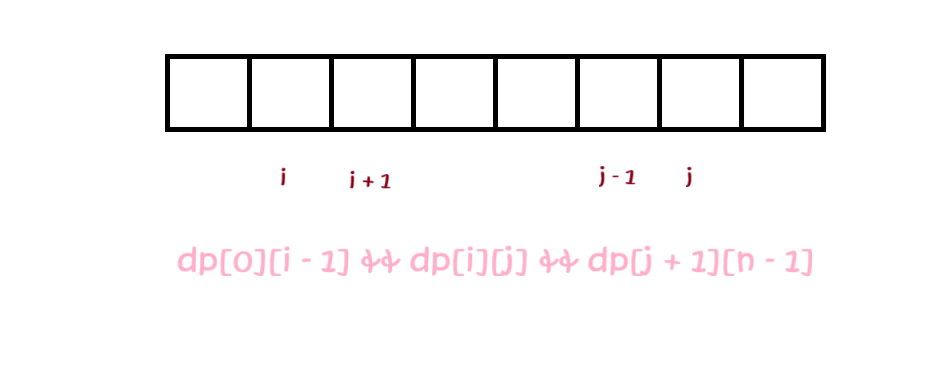
题目要求一个字符串被分成 **「三个非空回文子串」**,乍一看,要表示的状态很多,有些无从下手。
其实,我们可以把它拆成 **「两个小问题」**:
- ⅰ. 动态规划求解字符串中的一段非空子串是否是回文串;
- ⅱ. 枚举三个子串除字符串端点外的起止点,查询这三段非空子串是否是回文串。
那么这道困难题就免秒变为简单题啦,变成了一道枚举题。
关于预处理所有子串是否回文,已经在上一道题目里面讲过,这里就不再赘述啦~
class Solution {
public:bool checkPartitioning(string s) {int n = s.size();vector<vector<bool>> dp(n, vector<bool>(n));for(int i = n - 1; i >= 0; i--){for(int j = i; j < n; ++j){if(s[i] == s[j])dp[i][j] = i + 1 < j ? dp[i + 1][j - 1] : true;}}for(int i = 1; i < n - 1; ++i)for(int j = i; j < n - 1; ++j)if(dp[0][i - 1] && dp[i][j] && dp[j + 1][n - 1]){return true;}return false;}
};
132. 分割回文串 II - 力扣(LeetCode)
解法(动态规划):
算法思路:
1. 状态表示:
根据 **「经验」**,继续尝试用 i 位置为结尾,定义状态表示,看看能否解决问题:
dp[i] 表示:s 中 [0, i] 区间上的字符串,最少分割的次数。
2. 状态转移方程:
状态转移方程一般都是根据 **「最后一个位置」** 的信息来分析:设 0 <= j <= i,那么我们可以根据 j ~ i 位置上的子串是否是回文串分成下面两类:
-
ⅰ. 当
[j, i]位置上的子串能够构成一个回文串,那么dp[i]就等于[0, j - 1]区间上最少回文串的个数+1,即dp[i] = dp[j - 1] + 1; -
ⅱ. 当
[j, i]位置上的子串不能构成一个回文串,此时j位置就不用考虑。
由于我们要的是最小值,因此应该循环遍历一遍 j 的取值,拿到里面的最小值即可。
优化:我们在状态转移方程里面分析到,要能够快速判读字符串里面的子串是否回文。因此,我们可以先处理一个 dp 表,里面保存所有子串是否回文的信息。
3. 初始化:
观察 **「状态转移方程」**,我们会用到 j - 1 位置的值。我们可以思考一下当 j == 0 的时候,表示的区间就是 [0, i]。如果 [0, i] 区间上的字符串已经是回文串了,最小的回文串就是 1 了,j 往后的值就不用遍历了。
因此,我们可以在循环遍历 j 的值之前处理 j == 0 的情况,然后 j 从 1 开始循环。
但是,为了防止求 min 操作时,0 干扰结果。我们先把表里面的值初始化为 **「无穷大」**。
4. 填表顺序:
毫无疑问是 **「从左往右」**。
5. 返回值:
根据 **「状态表示」**,应该返回 dp[n - 1]。
class Solution {
public:int minCut(string s) {int n = s.size();vector<vector<bool>> hash(n, vector<bool>(n));for (int i = n - 1; i >= 0; i--)for (int j = i; j < n; ++j)if (s[i] == s[j])hash[i][j] = i + 1 < j ? hash[i + 1][j - 1] : true;vector<int> dp(n, INT_MAX);for (int i = 0; i < n; ++i) {if (hash[0][i])dp[i] = 0;else {for (int j = 1; j <= i; ++j)if (hash[j][i])dp[i] = min(dp[j - 1] + 1, dp[i]);}}return dp[n - 1];}
};
516. 最长回文子序列 - 力扣(LeetCode)
解法(动态规划):
算法思路:
1. 状态表示:
关于 **「单个字符串」问题中的「回文子序列」,或者「回文子串」**,我们的状态表示研究的对象一般都是选取原字符串中的一段区域 [i, j] 内部的情况。这里我们继续选取字符串中的一段区域来研究:
dp[i][j] 表示:s 字符串 [i, j] 区间内的所有的子序列中,最长的回文子序列的长度。
2. 状态转移方程:
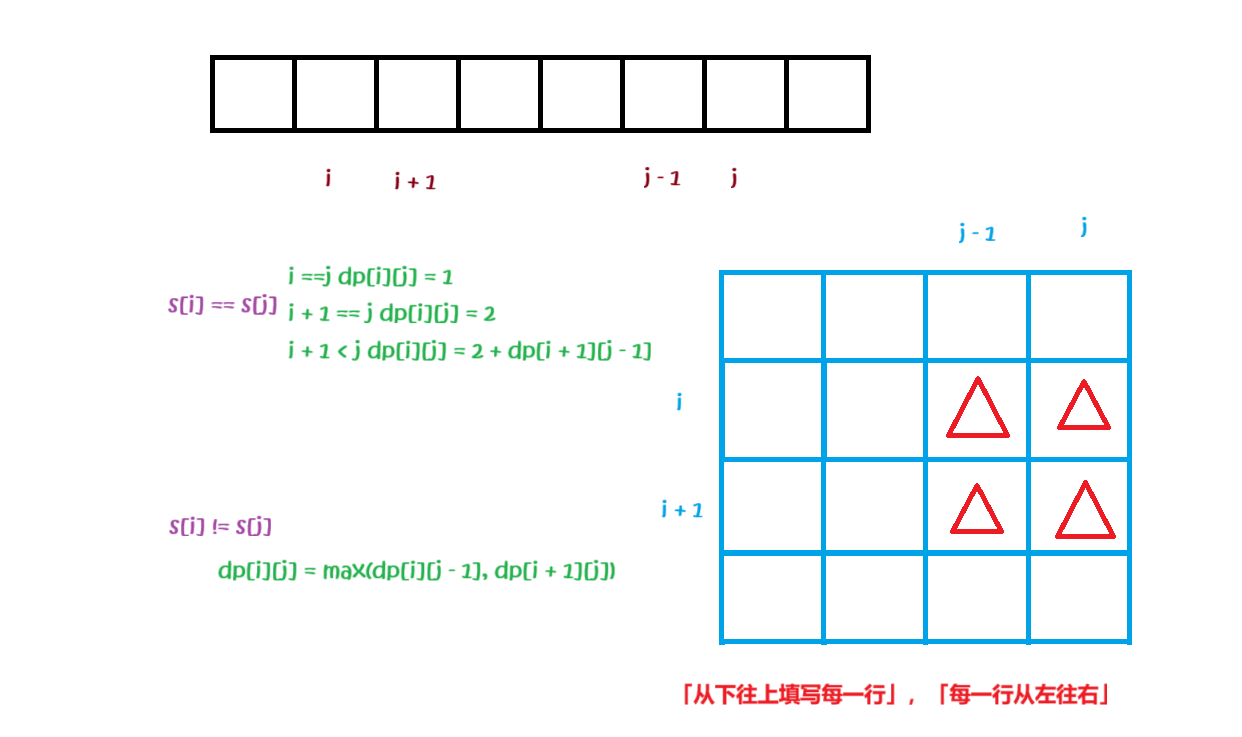
关于 **「回文子序列」和「回文子串」的分析方式,一般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果一个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」** 的不同,可以分为下面两种情况:
-
ⅰ. 当首尾两个元素 **「相同」** 的时候,也就是
s[i] == s[j]:那么[i, j]区间上的最长回文子序列,应该是[i + 1, j - 1]区间内的那个最长回文子序列首尾填上s[i]和s[j],此时dp[i][j] = dp[i + 1][j - 1] + 2; -
ⅱ. 当首尾两个元素不 **「相同」** 的时候,也就是
s[i] != s[j]:此时这两个元素就不能同时添加在一个回文串的左右,那么我们就应该让s[i]单独加在一个序列的左边,或者让s[j]单独放在一个序列的右边,看看这两种情况下的最大值:-
单独加入
s[i]后的区间在[i, j - 1],此时最长的回文序列的长度就是dp[i][j - 1]; -
单独加入
s[j]后的区间在[i + 1, j],此时最长的回文序列的长度就是dp[i + 1][j];
取两者的最大值,于是
dp[i][j] = max(dp[i][j - 1], dp[i + 1][j])。 -
综上所述,状态转移方程为:
-
当
s[i] == s[j]时:dp[i][j] = dp[i + 1][j - 1] + 2; -
当
s[i] != s[j]时:dp[i][j] = max(dp[i][j - 1], dp[i + 1][j])。
3. 初始化:
我们的初始化一般就是为了处理在状态转移的过程中,遇到的一些边界情况,因为我们需要根据状态转移方程来分析哪些位置需要初始化。
根据状态转移方程 dp[i][j] = dp[i + 1][j - 1] + 2,我们状态表示的时候,选取的是一段区间,因此需要要求左端点的值要小于等于右端点的值,因此会有两种边界情况:
-
ⅰ. 当
i == j的时候,i + 1就会大于j - 1,此时区间内只有一个字符。这个比较好分析,dp[i][j]表示一个字符的最长回文序列,一个字符能够自己组成回文串,因此此时dp[i][j] = 1; -
ⅱ. 当
i + 1 == j的时候,i + 1也会大于j - 1,此时区间内有两个字符。这样也好分析,当这两个字符相同的时候,dp[i][j] = 2;不相同的时候,d[i][j] = 0。
对于第一种边界情况,我们在填表的时候,就可以同步处理。
对于第二种边界情况,dp[i + 1][j - 1] 的值为 0,不会影响最终的结果,因此可以不用考虑。
4. 填表顺序:
根据 **「状态转移」,我们发现,在 dp 表所表示的矩阵中,dp[i + 1] 表示下一行的位置,dp[j - 1] 表示前一列的位置。因此我们的填表顺序应该是「从下往上填写每一行」,「每一行从左往右」**。
这个与我们一般的填写顺序不太一致。
5. 返回值:
根据 **「状态表示」**,我们需要返回 [0, n - 1] 区域上的最长回文子序列的长度,因此需要返回 dp[0][n - 1]。
class Solution {
public:int longestPalindromeSubseq(string s) {int n =s.size();vector<vector<int>> dp(n, vector<int>(n));for(int i = n - 1; i >= 0; i--){dp[i][i] = 1;for(int j = i + 1; j < n; ++j){if(s[i] == s[j])dp[i][j] = dp[i + 1][j - 1] + 2;else dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);}}return dp[0][n - 1];}
};1312. 让字符串成为回文串的最少插入次数 - 力扣(LeetCode)
解法(动态规划):
算法思路:
1. 状态表示:
关于 **「单个字符串」问题中的「回文子序列」,或者「回文子串」**,我们的状态表示研究的对象一般都是选取原字符串中的一段区域 [i, j] 内部的情况。这里我们继续选取字符串中的一段区域来研究:
状态表示:dp[i][j] 表示字符串 [i, j] 区域成为回文子串的最少插入次数。
2. 状态转移方程:
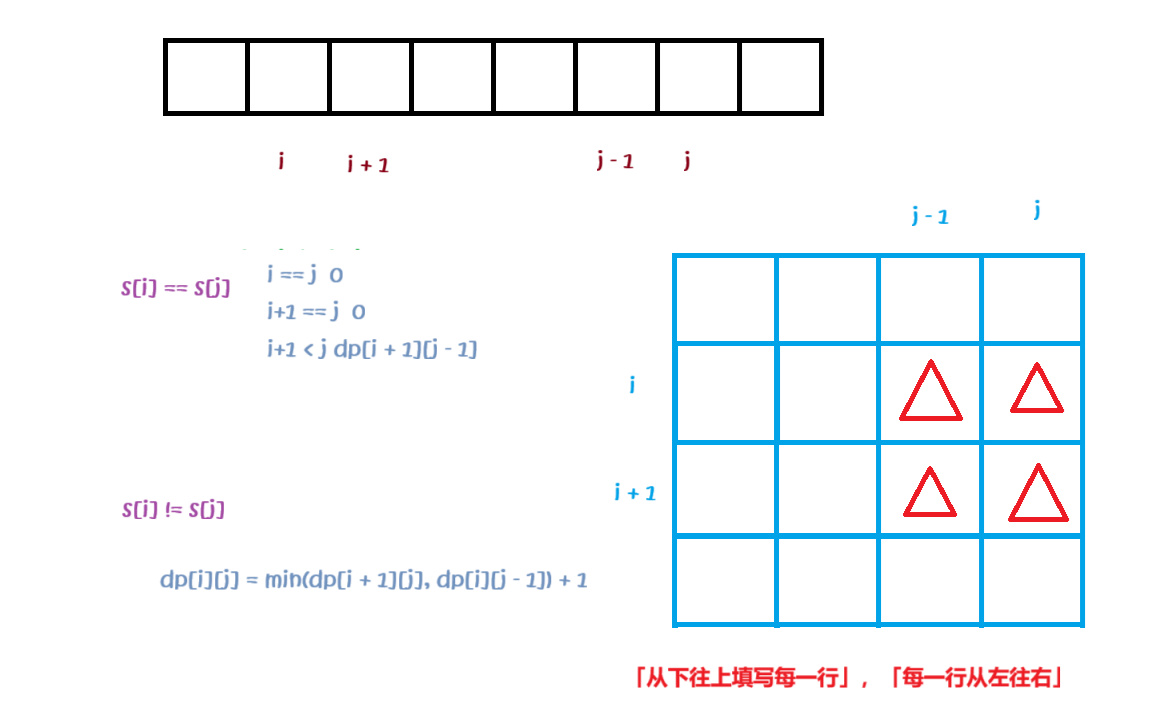
关于 **「回文子序列」和「回文子串」的分析方式,一般都是比较固定的,都是选择这段区域的「左右端点」的字符情况来分析。因为如果一个序列是回文串的话,「去掉首尾两个元素之后依旧是回文串」,「首尾加上两个相同的元素之后也依旧是回文串」。因为,根据「首尾元素」** 的不同,可以分为下面两种情况:
-
ⅰ. 当首尾两个元素 **「相同」** 的时候,也就是
s[i] == s[j]:-
那么
[i, j]区间内成为回文子串的最少插入次数,取决于[i + 1, j - 1]区间内成为回文子串的最少插入次数; -
若
i == j或i == j - 1([i + 1, j - 1]不构成合法区间),此时只有1 ~ 2个相同的字符,[i, j]区间一定是回文子串,成为回文子串的最少插入次数是此时dp[i][j] = i >= j - 1 ? 0 : dp[i + 1][j - 1];
-
-
ⅱ. 当首尾两个元素 **「不相同」** 的时候,也就是
s[i] != s[j]:-
此时可以在区间最右边补上一个
s[i],需要的最少插入次数是[i + 1, j]成为回文子串的最少插入次数 + 本次插入,即dp[i][j] = dp[i + 1][j] + 1; -
此时可以在区间最左边补上一个
s[j],需要的最少插入次数是[i, j - 1]成为回文子串的最少插入次数 + 本次插入,即dp[i][j] = dp[i][j - 1] + 1;
-
综上所述,状态转移方程为:
-
当
s[i] == s[j]时:dp[i][j] = i >= j - 1 ? 0 : dp[i + 1][j - 1]; -
当
s[i] != s[j]时:dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1。
3. 初始化:
根据 **「状态转移方程」**,没有不能递推表示的值。无需初始化。
4. 填表顺序:
根据 **「状态转移」,我们发现,在 dp 表所表示的矩阵中,dp[i + 1] 表示下一行的位置,dp[j - 1] 表示前一列的位置。因此我们的填表顺序应该是「从下往上填写每一行」,「每一行从左往右」**。
这个与我们一般的填写顺序不太一致。
5. 返回值:
根据 **「状态表示」**,我们需要返回 [0, n - 1] 区域上成为回文子串的最少插入次数,因此需要返回 dp[0][n - 1]。
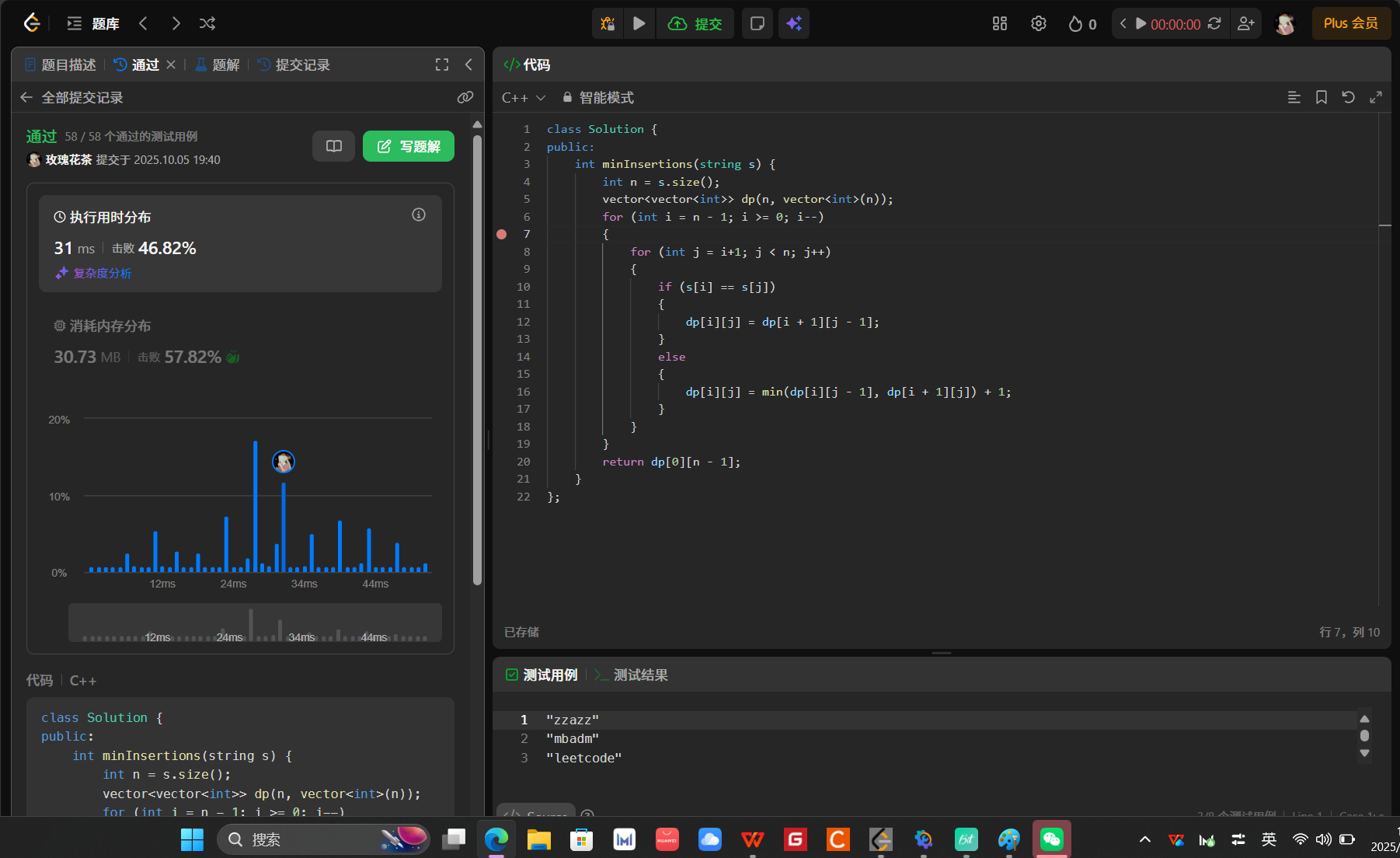
class Solution {
public:int minInsertions(string s) {int n = s.size();vector<vector<int>> dp(n, vector<int>(n));for (int i = n - 1; i >= 0; i--){for (int j = i+1; j < n; j++){if (s[i] == s[j]){dp[i][j] = dp[i + 1][j - 1];}else{dp[i][j] = min(dp[i][j - 1], dp[i + 1][j]) + 1;}}}return dp[0][n - 1];}
};