高层次综合的基础-vivado_hls第二章
- 高层次综合的基础
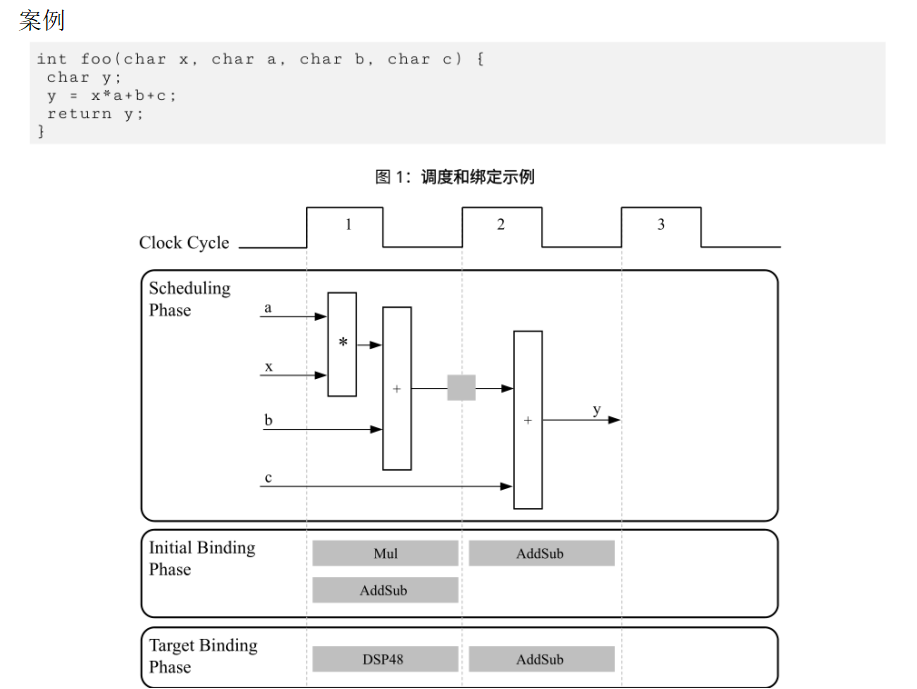
schedule调度:
- 判定每个时钟周期内发生的操作
- 时钟周期或者时钟频率
- 一个操作完成需要的时间
- 用户指定的最优化指令
- 如果时钟周期比较长,也就是时钟频率低,那么单独一个时钟周期可以完成很多个工作,由于时钟频率低,建立时间和保持时间比较容易满足,很多功能可以在一个时钟周期内完成逻辑设计。某个操作,使用快速高性能的FPGA比低速低性能的FPGA完成功能更加快速。
Binding操作:
- 判定每个C语言操作所需要逻辑资源
- 控制逻辑和状态机的提取
- 提取控制逻辑并创建有限状态机FSM,以便对C代码进行排序处理
高层次C语言代码综合为RTL:
- 顶层function函数的实参,综合为RTL的IO端口
- 内部的C语言function,综合为RTL层级内部的module模块
- C语言代码包含sub-function
- c语言代码实现的所有函数实例都使用相同RTL来实现
- C语言代码中for循环默认是全部unroll的,也就是for循环按照时钟节拍串行进行的
- C语言的for循环折叠的时候,综合工具会为了for循环的单次执行创建逻辑,RTL代码会为序列中的for循环的每次迭代,都重复执行这个逻辑
- 关于for循环,可以使用优化指令,将for循环展开,从而实现并行执行所有的迭代
- 关于for循环实现pipeline流水的方式有两种,一种是通过有限状态机的细颗粒度来实现循环流水线化,另外一种方式是采用dataflow数据流来实现比较粗颗粒度的握手流水线
C语言代码中的array数组,可以综合为FPGA中的block ram或者ultraRAM- 如果array数组在顶层函数的接口上,那么高层次综合工具会将数组综合为端口来实现,从而用于访问外部的存储模块,可用于方位外部的RAM或者FIFO
- 高层次综合基于默认行为,基于约束指令的高层次综合,指定的任意最优化指令来创建最优化的实现。
- 使用最优指令来修改,控制内部逻辑,规定IO的行为
- 设计是否满足你的要求,可以通过查看高层次综合生成的综合报告的中的性能指标
- 依据分析报告,配合优化指令,对c代码逻辑进行调优,从而实现c代码转为rtl的最优性能
- 综合性能指标:面积,时延,启动时间间隔,循环迭代时延,循环启动时间间隔,循环时延
- 面积:FPGA资源,LUT查找表,block_ram,寄存器,DSP48E来实现硬件逻辑
- 时延:函数计算所有的输出值所需要的时钟周期数,也就是从第一个输入开始到所有的数据输出需要的时间周期,也就是从start到最后一个数据处理开始输出的时间周期
- 启动时间间隔:函数接收一个新的数据之前所需要的时间,也就是程序运行起来到开始接收第一个数据需要的时间,就是启动时间间隔
- 循环迭代时延:循环的单词迭代需要的时钟周期数
- 循环启动时间间隔:下一次循环迭代开始处理数据之前的时间周期数
- 循环时延:完成所有的循环需要的时钟周期数
案例生成的verilog代码顶层接口
input ap_start;
output ap_done;
output ap_idle;
output ap_ready;
input [7:0] x;
input [7:0] a;
input [7:0] b;
input [7:0] c;
output [31:0] ap_return;
上述代码中调度和绑定阶段实现的功能,比较清晰了进行了描述。
- 函数的延时
- 函数的初始化间隔Function Initiation Interval,表示函数开始第一次迭代到第二次开始迭代需要的时间周期;function函数处理ram中三个元素后,表示完成第一轮函数操作,如果开始进行第二轮函数操作,那么这个时间间隔就是函数的II。
- 函数的一次完整执行的时间称为一项传输事务。多次传输事务执行有气泡产生