玩转Pod调度及K8S集群的扩缩容实战案例
🌟玩转Pod调度之nodeName
什么是nodeName
就是指定pod调度到worker节点,该节点必须在etcd中有记录。
一般用户用于指定调度,如果使用了该字段,则不会使用k8s默认的scheduler调度器(‘default-scheduler’)。
实战案例
[root@master231 scheduler]# cat 01-deploy-scheduler-nodeName.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-nodename
spec:replicas: 3selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:nodeName: worker233containers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2ports:- containerPort: 80

[root@master231 scheduler]# kubectl describe pod deploy-nodename-699559557c-8fb89
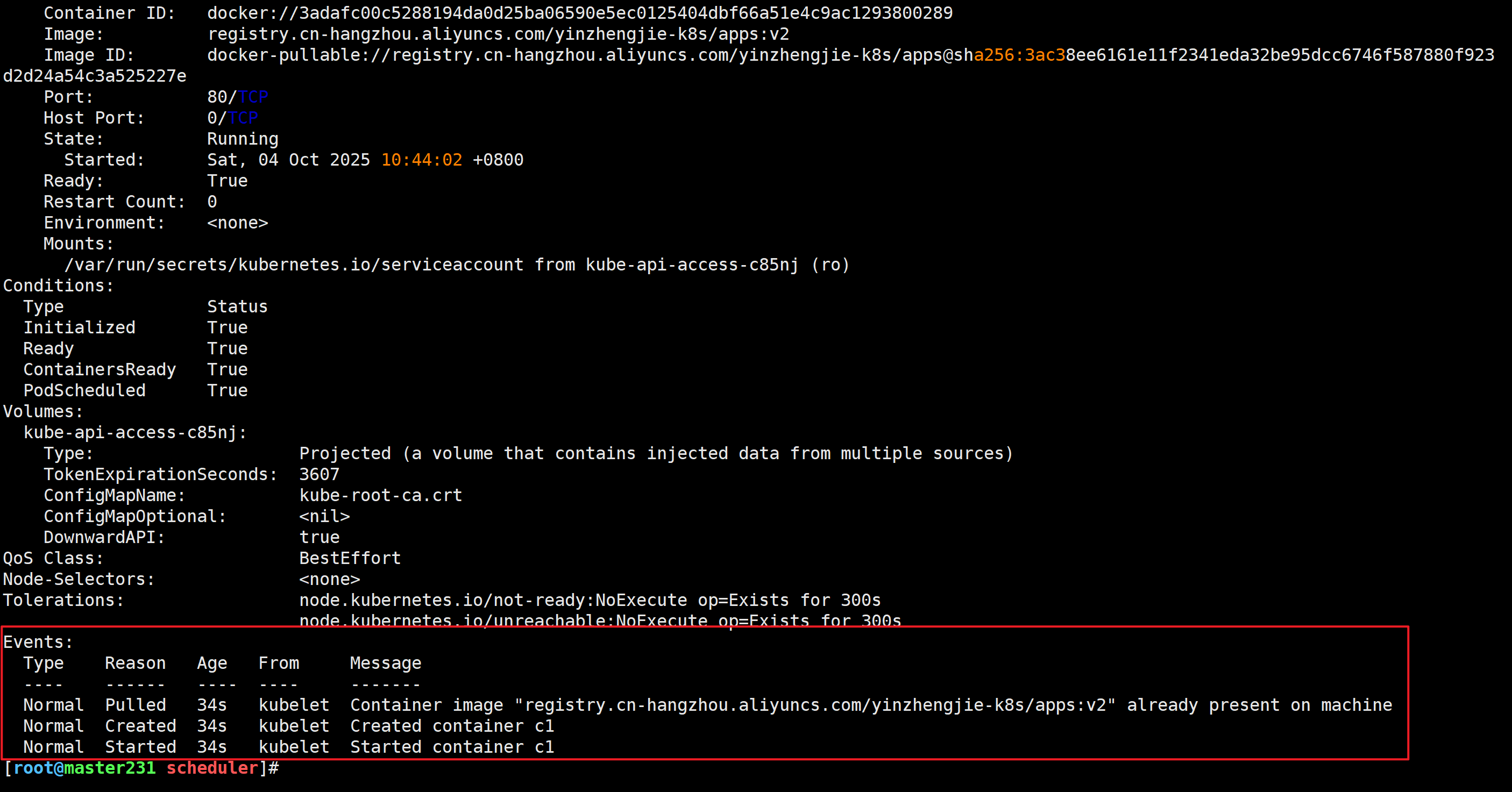
没有调度事件
🌟玩转Pod调度之hostPort
什么是hostPort
hostPort会让worker节点添加转发规则,将监听端口流量转发到该容器的端口。
如果宿主机的端口被占用,则无法完成调度。
测试案例
[root@master231 scheduler]# cat 02-deploy-scheduler-hostPort.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-hostport
spec:replicas: 3selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:containers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2ports:- containerPort: 80hostPort: 90

[root@master231 scheduler]# kubectl describe pod deploy-hostport-557b7f449b-wzw6wEvents:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling 70s (x2 over 71s) default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 node(s) didn't have free ports for the requested pod ports.
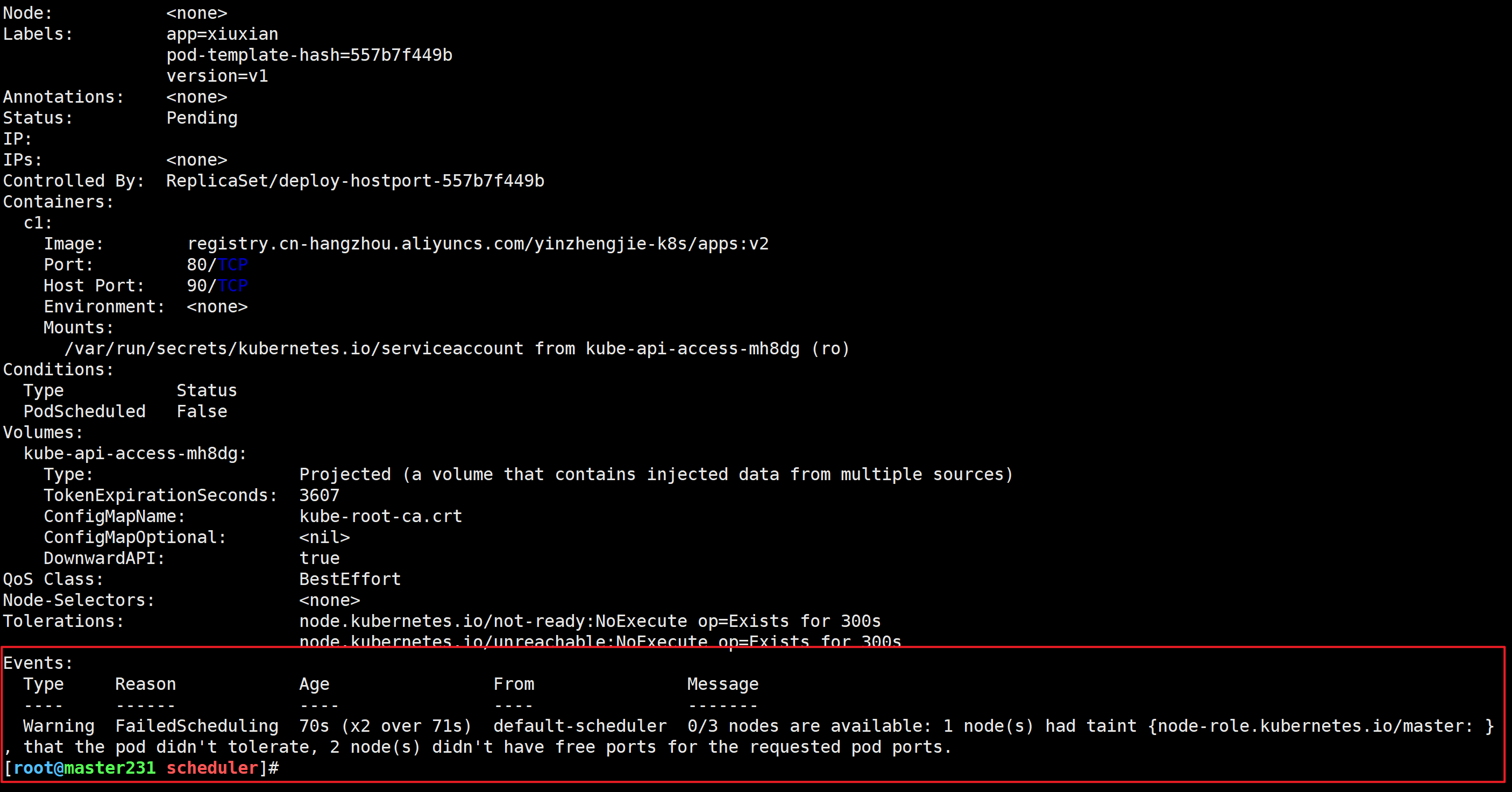
端口被占用,无法完成调度
🌟玩转Pod调度之hostNetwork
什么是hostNetwork
就是让pod使用宿主机的网络(net)名称空间。
实战案例
[root@master231 scheduler]# cat 03-deploy-scheduler-hostNetwork.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-hostnetwork
spec:replicas: 3selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:hostNetwork: truecontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2ports:- containerPort: 80

[root@master231 scheduler]# kubectl describe pods deploy-hostnetwork-698ddcf86d-hfh6b
...
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling 26s (x2 over 27s) default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 node(s) didn't have free ports for the requested pod ports.
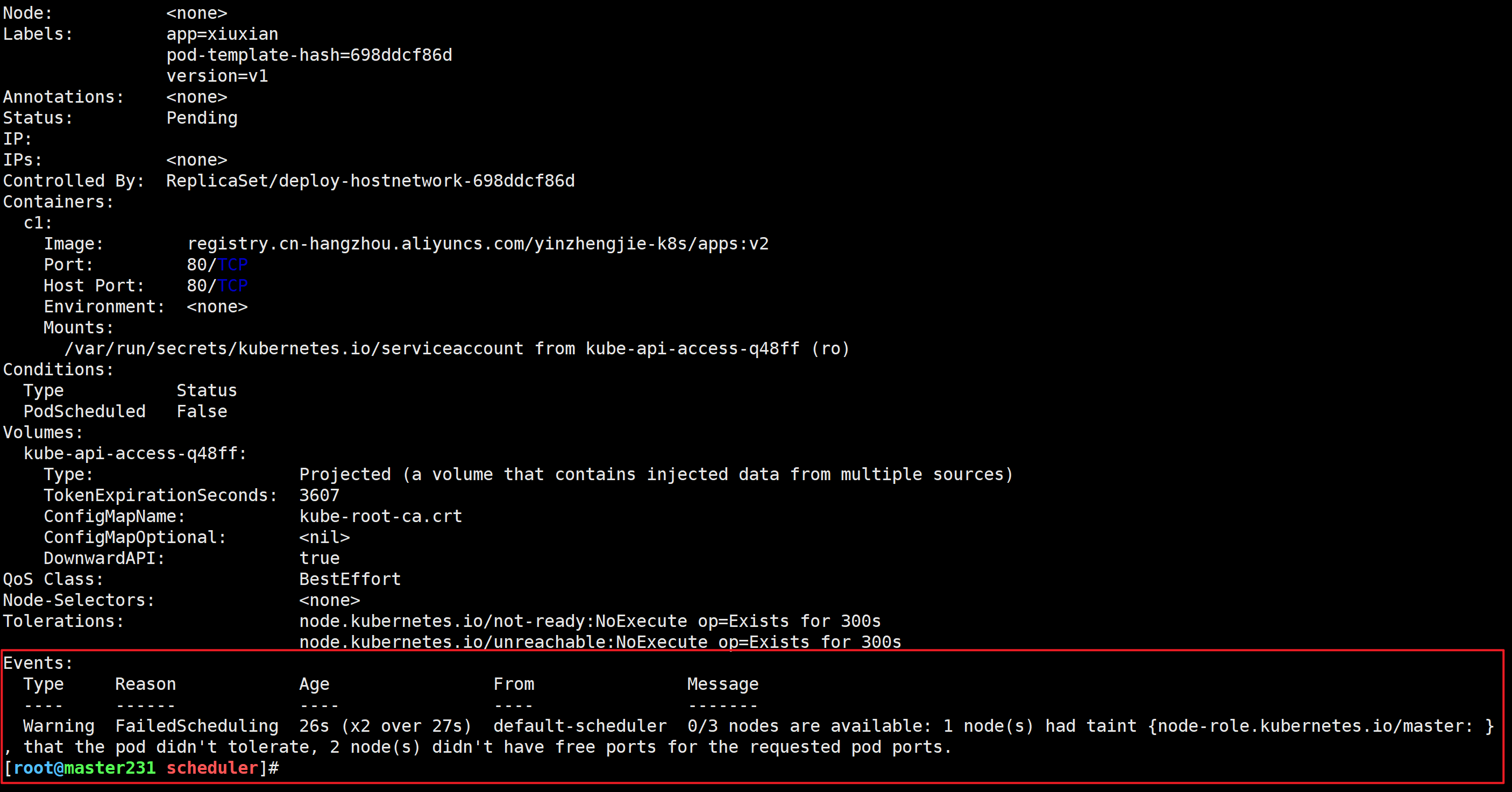
端口被占用无法完成调度
🌟玩转Pod调度之resources
什么是resources
requests可以对容器的调度进行期望阈值,如果不符合期望则无法完成调度。
limits用于控制容器对资源的使用上限,如果用户没有定义requests字段,则requests值默认和limits相等。
实战案例
[root@master231 scheduler]# cat 04-deploy-scheduler-resources.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-resources
spec:replicas: 3selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:containers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2resources:# requests:# cpu: 200m# memory: 200Mi# limits:# cpu: 0.5# memory: 500Milimits:cpu: 1memory: 500Miports:- containerPort: 80

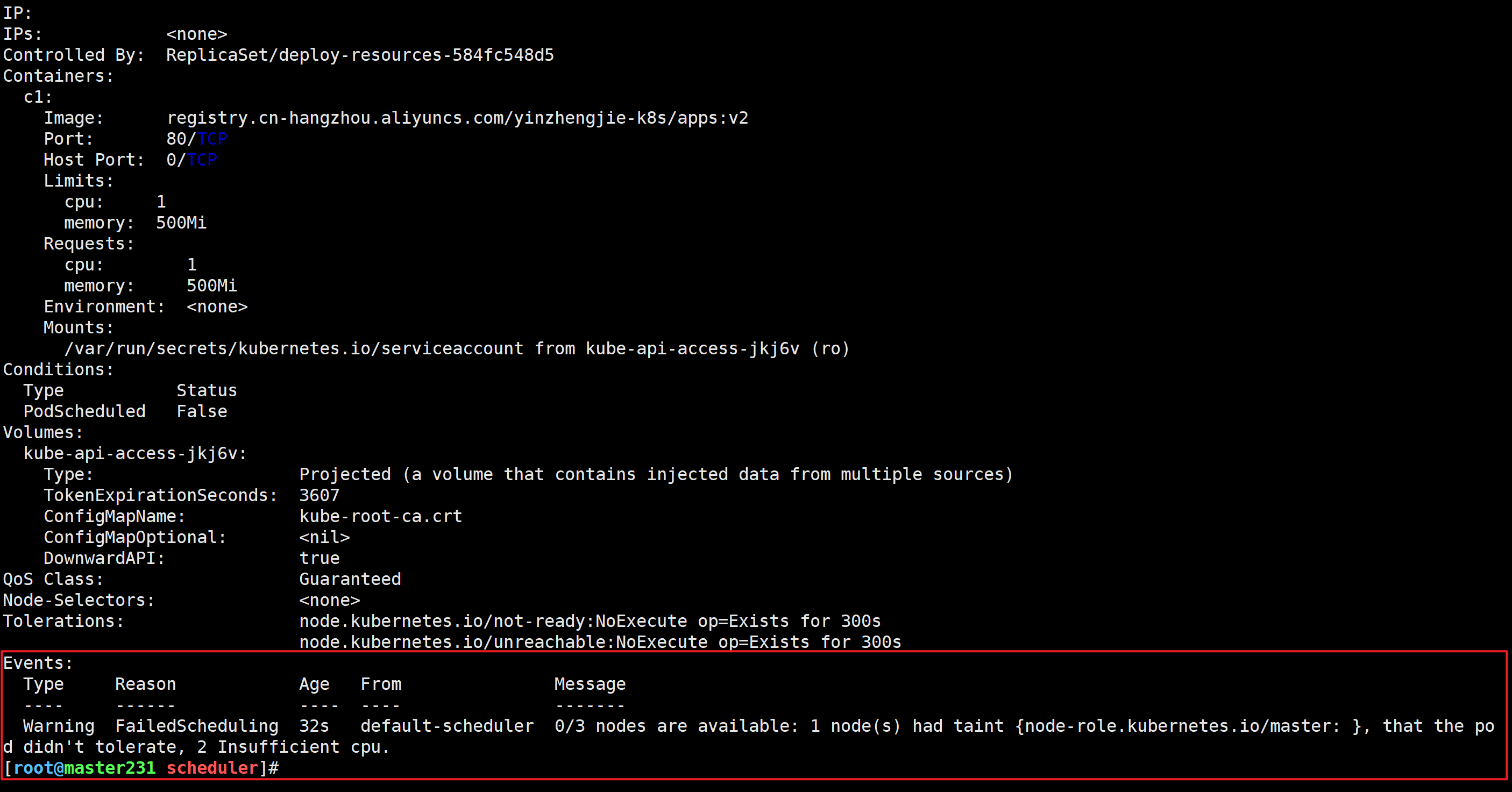
[root@master231 scheduler]# kubectl describe pod deploy-resources-584fc548d5-djrt4Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling 32s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient cpu.
🌟玩转Pod调度之nodeSelector
什么是nodeSelector
可以根据节点的标签进行调度。
实战案例
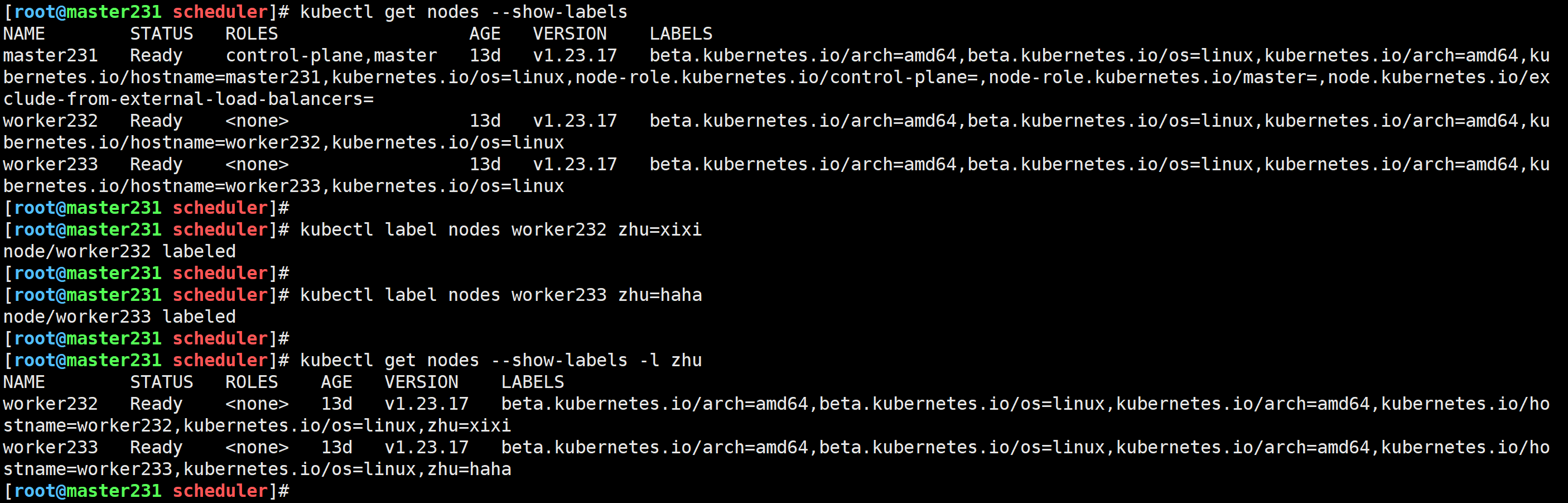
给节点打标签
[root@master231 scheduler]# kubectl label nodes worker232 zhu=xixi
node/worker232 labeled
[root@master231 scheduler]#
[root@master231 scheduler]# kubectl label nodes worker233 zhu=haha
node/worker233 labeled
[root@master231 scheduler]#
[root@master231 scheduler]# kubectl get nodes --show-labels -l zhu
测试案例
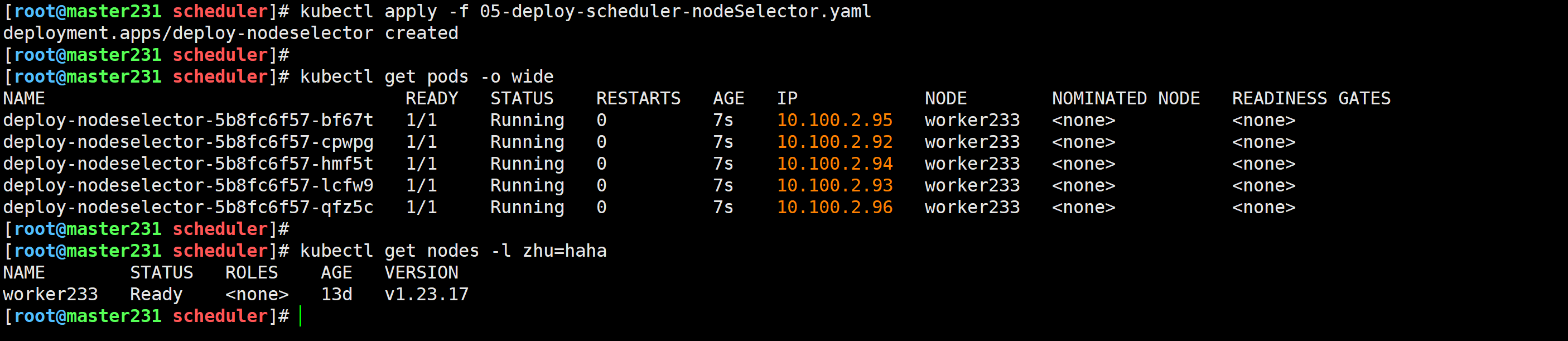
[root@master231 scheduler]# cat 05-deploy-scheduler-nodeSelector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-nodeselector
spec:replicas: 5selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:nodeSelector:zhu: hahacontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2ports:- containerPort: 80
🌟玩转Pod调度基础之Taints
什么是Taints
Taints表示污点,作用在worker工作节点上。
污点类型大概分为三类:
- NoSchedule: 不在接受新的Pod调度,已经调度到该节点的Pod不会被驱逐。
- PreferNoSchedule: 优先将Pod调度到其他节点,当其他节点不可调度时,再往该节点调度。
- NoExecute: 不在接受新的Pod调度,且已经调度到该节点的Pod会被立刻驱逐。
污点的格式: key[=value]:effect
污点的基础管理
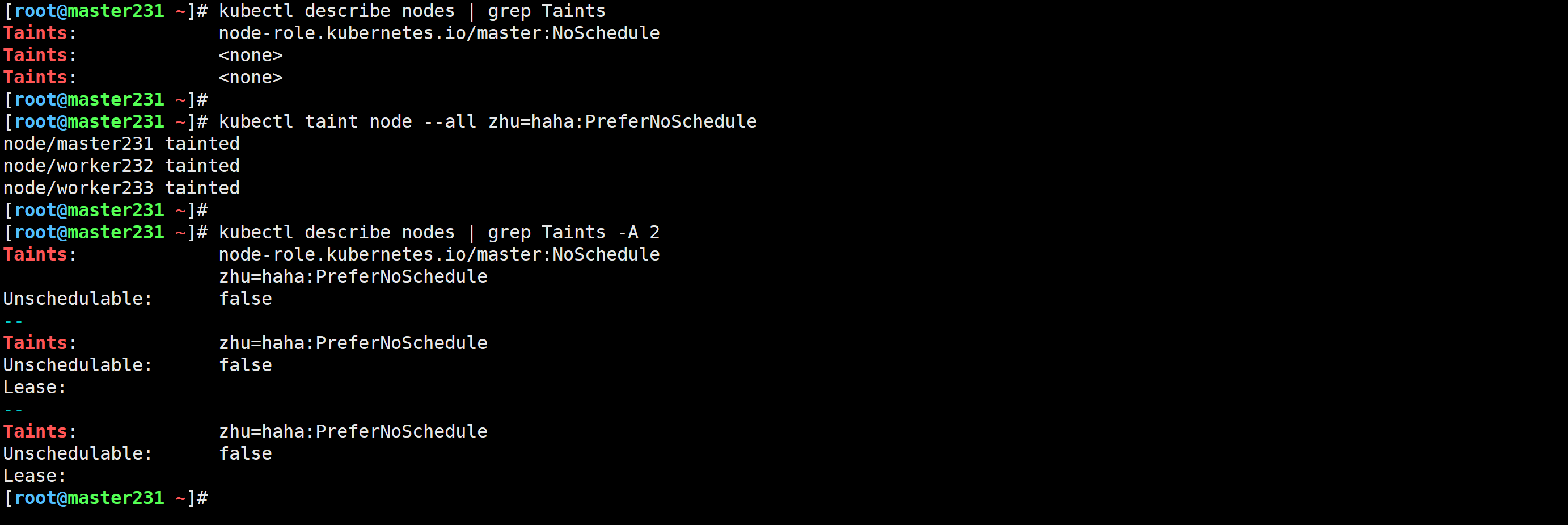
查看污点
[root@master231 ~]# kubectl describe nodes | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
Taints: <none>
Taints: <none>
[root@master231 ~]#
温馨提示: 表示该节点没有污点。
给指定节点打污点
[root@master231 ~]# kubectl taint node --all zhu=haha:PreferNoSchedule
node/master231 tainted
node/worker232 tainted
node/worker233 tainted
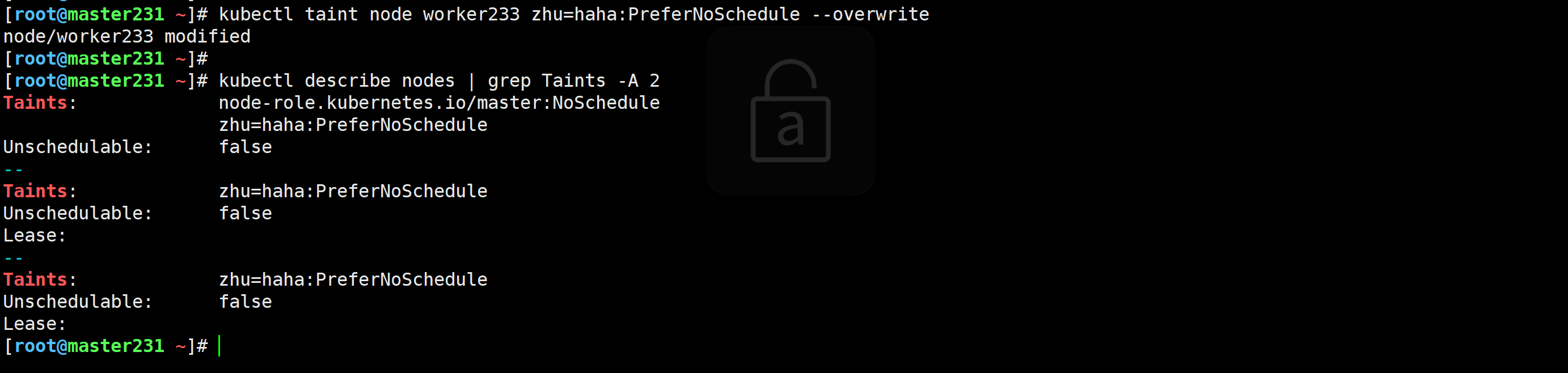
修改污点
只能修改value字段,修改effect则表示创建了一个新的污点类型
[root@master231 ~]# kubectl taint node worker233 zhu=haha:PreferNoSchedule --overwrite
node/worker233 modified
删除污点
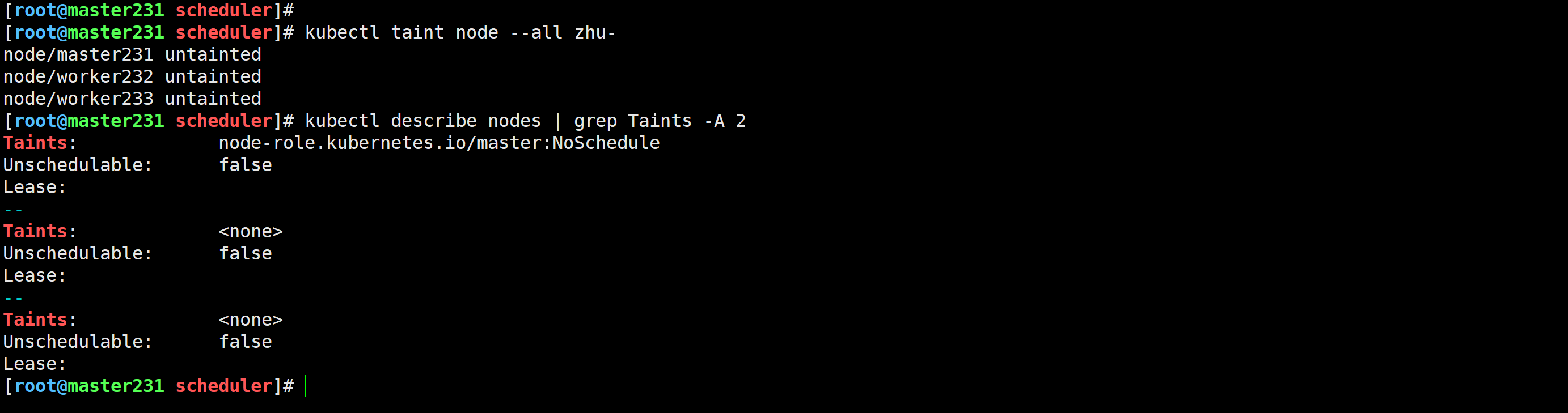
[root@master231 ~]# kubectl taint node --all zhu-
node/master231 untainted
node/worker232 untainted
node/worker233 untainted
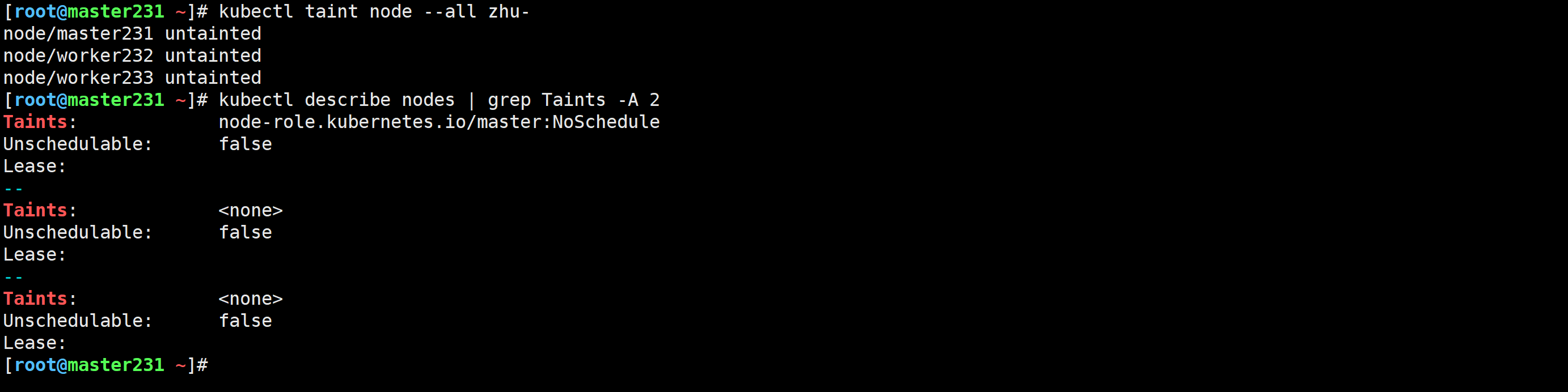
测试污点类型案例
添加污点
[root@master231 ~]# kubectl taint node worker233 zhu:NoSchedule
node/worker233 tainted
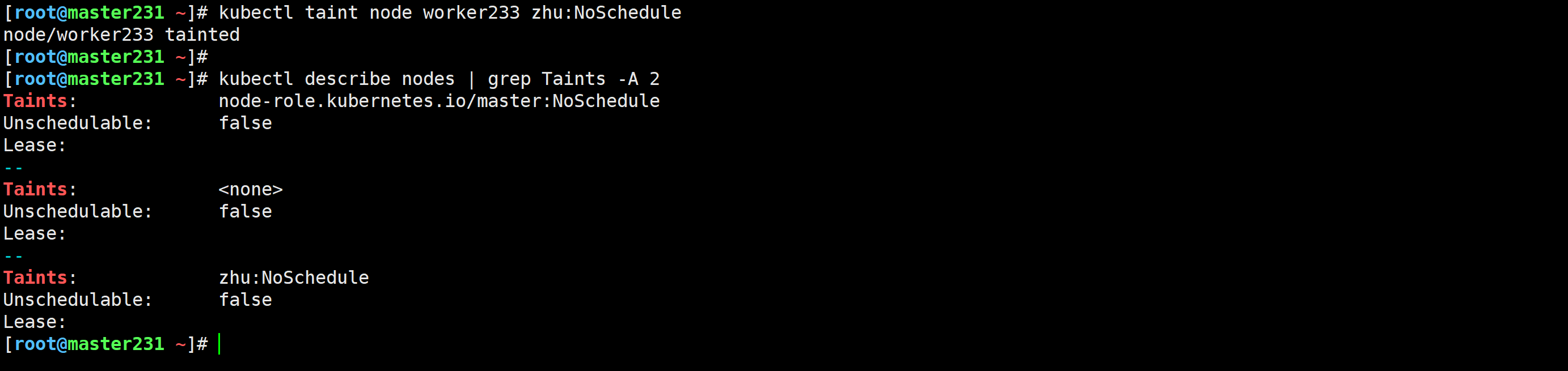
测试案例
[root@master231 scheduler]# cat 06-deploy-scheduler-Taints.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-taints
spec:replicas: 5selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:containers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2resources:limits:cpu: 1memory: 500Miports:- containerPort: 80

修改污点类型
[root@master231 scheduler]# kubectl taint node worker233 zhu:PreferNoSchedule
node/worker233 tainted
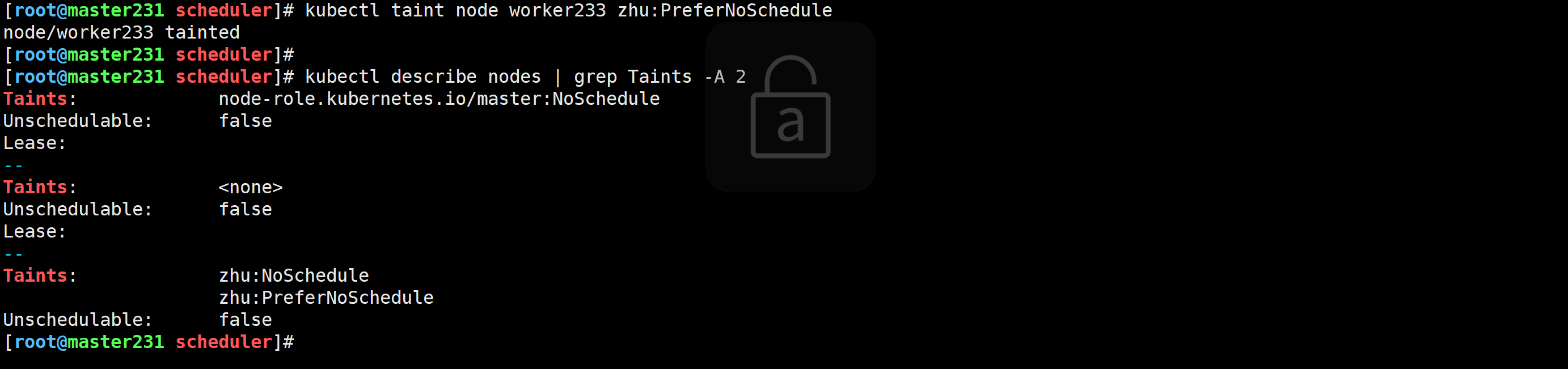
[root@master231 scheduler]# kubectl taint node worker233 zhu:NoSchedule-
node/worker233 untainted
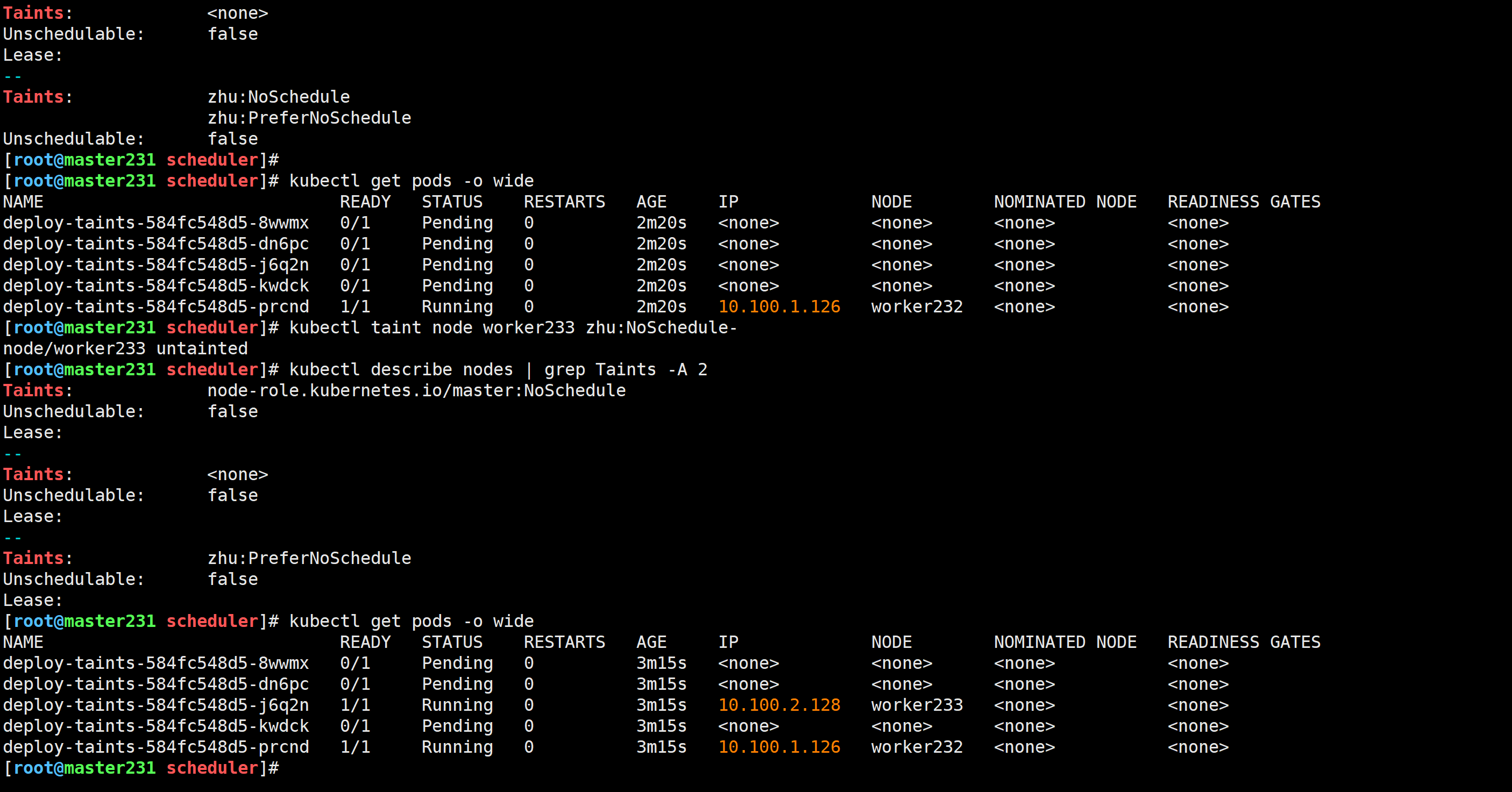
再次修改污点类型
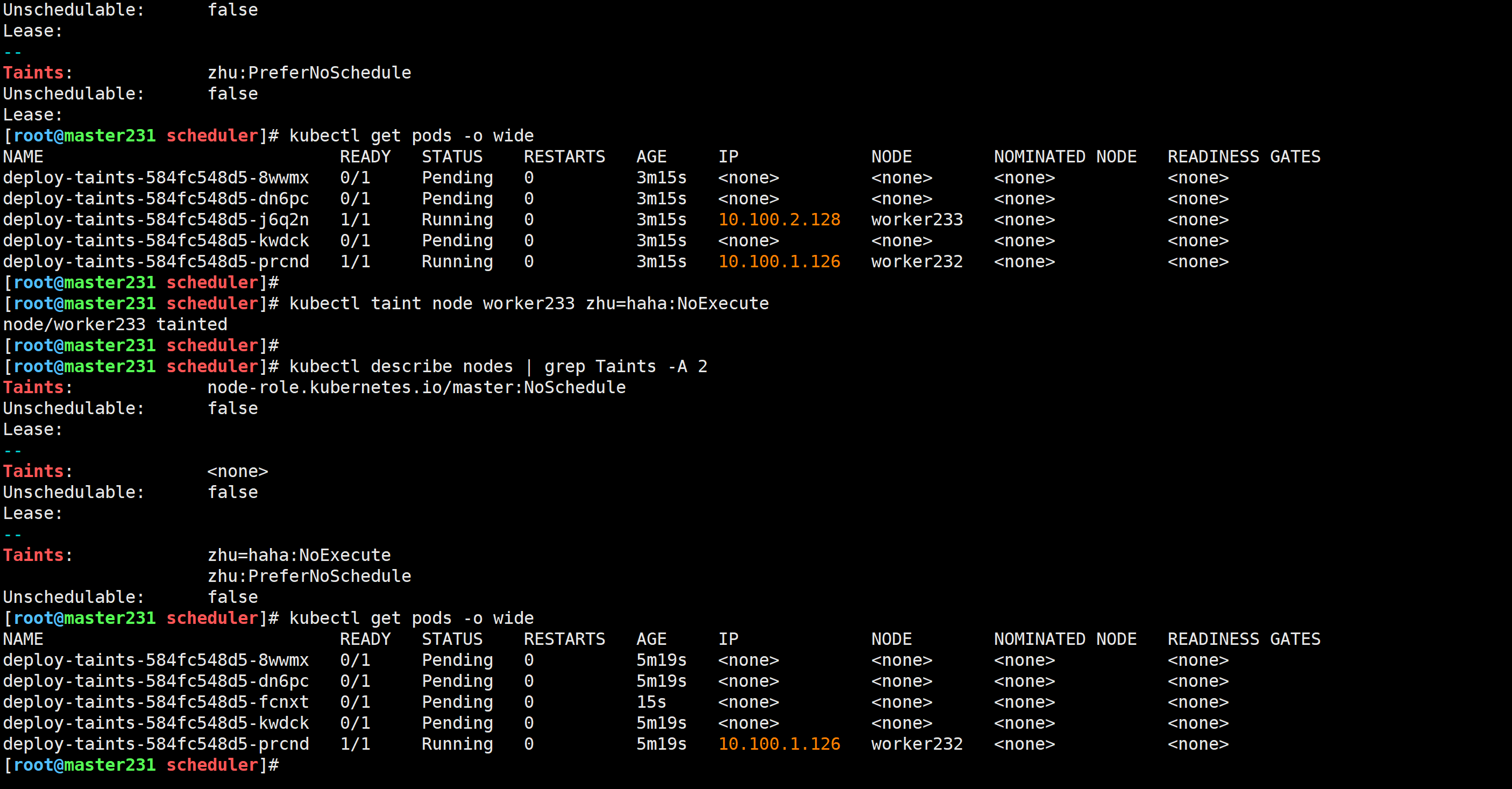
[root@master231 scheduler]# kubectl taint node worker233 zhu=haha:NoExecute
node/worker233 tainted
删除测试
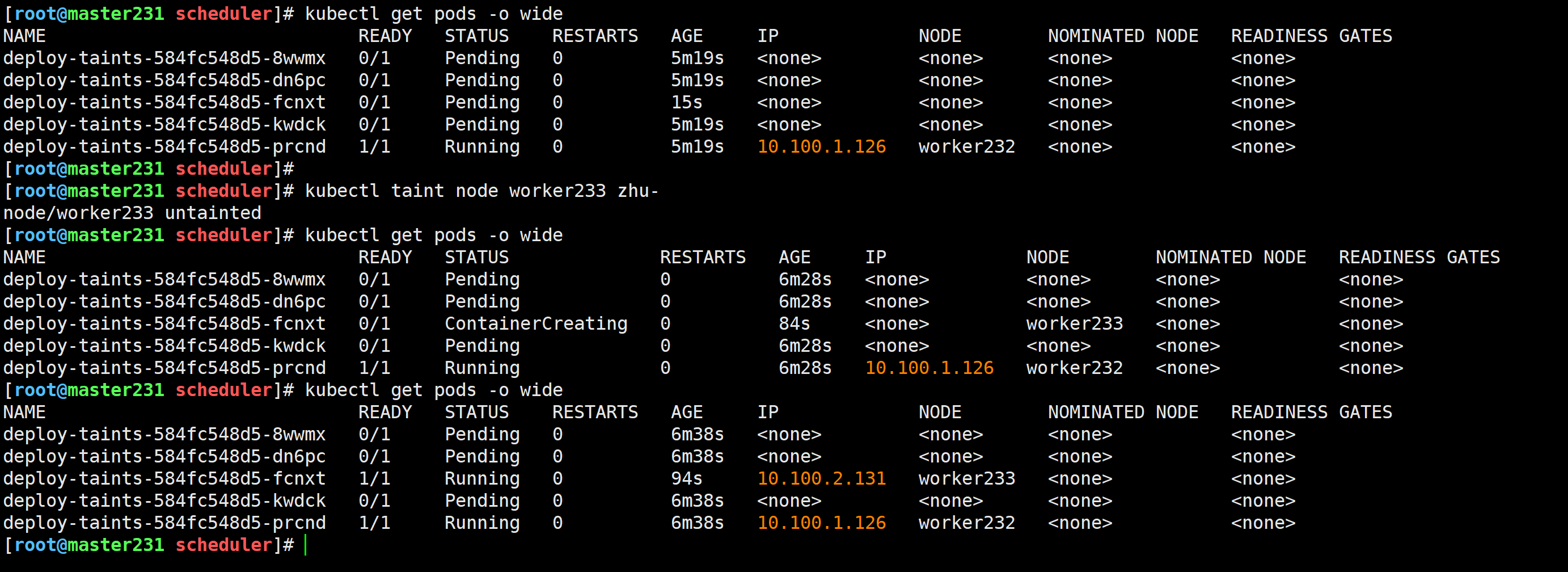
[root@master231 scheduler]# kubectl taint node worker233 zhu-
node/worker233 untainted
🌟玩转Pod调度基础之tolerations
什么是tolerations
tolerations是污点容忍,用该技术可以让Pod调度到一个具有污点的节点。
值得注意的是,一个Pod如果想要调度到某个worker节点,则必须容忍该worker的所有污点。
实战案例
环境准备就绪
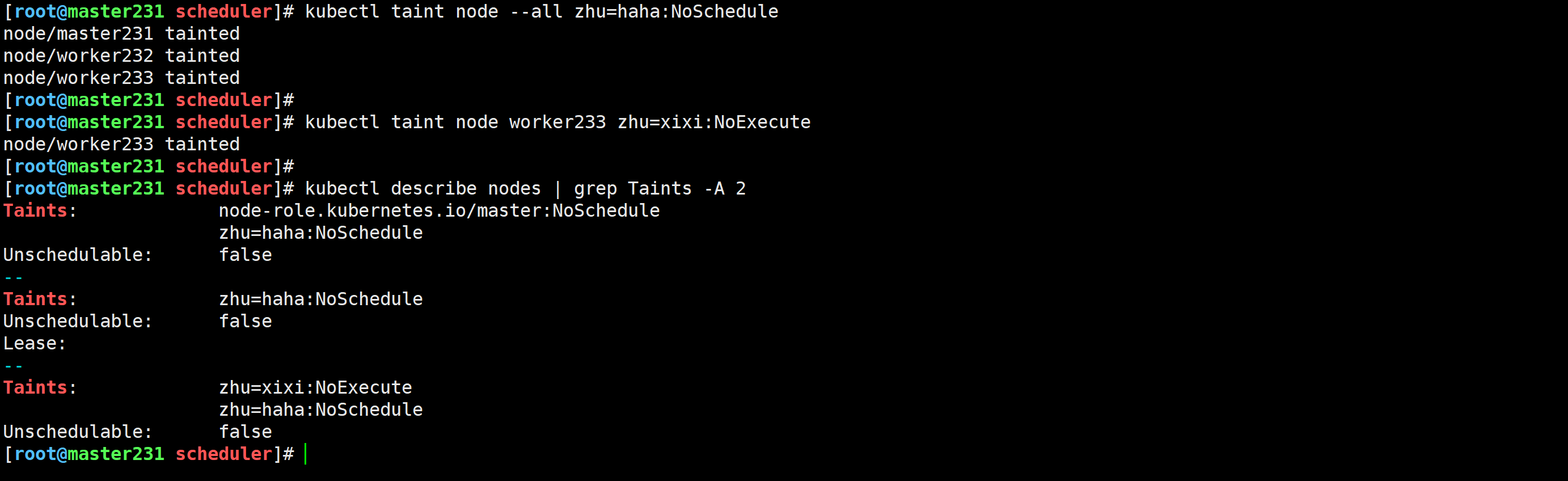
[root@master231 scheduler]# kubectl taint node --all zhu=haha:NoSchedule
node/master231 tainted
node/worker232 tainted
node/worker233 tainted
[root@master231 scheduler]#
[root@master231 scheduler]# kubectl taint node worker233 zhu=xixi:NoExecute
node/worker233 tainted
测试验证
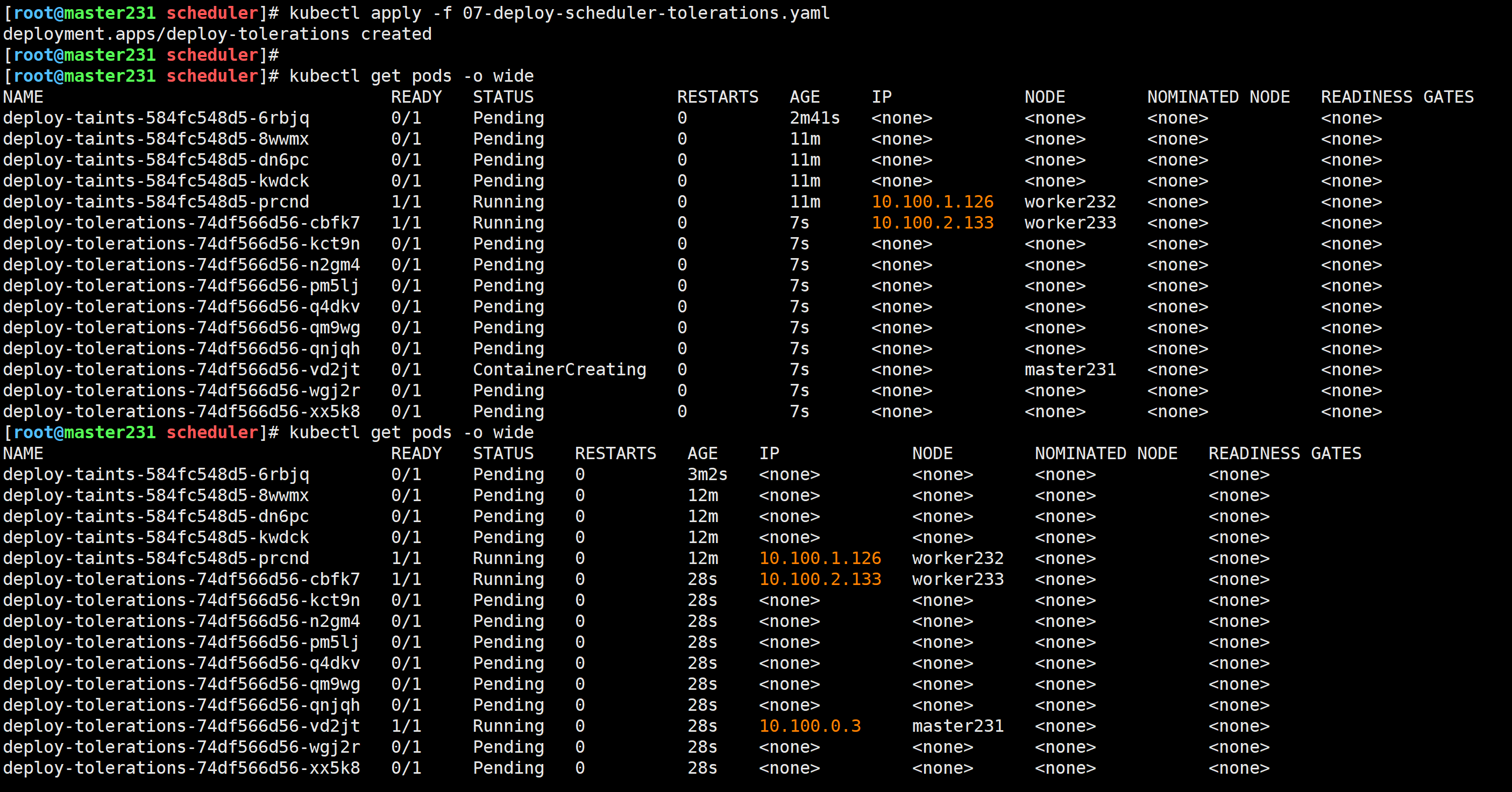
[root@master231 scheduler]# cat 07-deploy-scheduler-tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-tolerations
spec:replicas: 10selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:# 配置污点容忍tolerations:# 指定污点的key,如果不定义,则默认匹配所有的key。- key: zhu# 指定污点的value,如果不定义,则默认匹配所有的value。value: haha# 指定污点的effect类型,如果不定义,则默认匹配所有的effect类型。effect: NoSchedule- key: zhu# 注意,operator表示key和value的关系,有效值为: Exists and Equal,默认值为: Equal。# 如果只写key不写value,则表示匹配所有的value值。operator: Existseffect: NoExecute- key: node-role.kubernetes.io/mastereffect: NoSchedule# 如果将operator的值设置为: Exists,且不定义key,value,effect时,表示无视污点。#- operator: Existscontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2resources:limits:cpu: 1memory: 500Miports:- containerPort: 80
删除污点
[root@master231 scheduler]# kubectl taint node --all zhu-
node/master231 untainted
node/worker232 untainted
node/worker233 untainted
🌟玩转Pod调度之nodeAffinity
什么是nodeAffinity
nodeAffinity的作用和nodeSelector类似,但功能更强大。
nodeSelector可以基于节点的标签进行调度,但是匹配节点标签时,key和value必须相同。
而nodeAffinity则可以让key相同,value不相同。
测试案例
修改节点的标签
[root@master231 scheduler]# kubectl label nodes master231 dc=hangzhou
node/master231 labeled
[root@master231 scheduler]# kubectl label nodes worker232 dc=beijing
node/worker232 labeled
[root@master231 scheduler]# kubectl label nodes worker233 dc=shanghai
node/worker233 labeled

测试案例
[root@master231 scheduler]# cat 08-deploy-scheduler-nodeAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-nodeaffinity
spec:replicas: 5selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:# 配置Pod的粘性(亲和性)affinity:# 配置Pod更倾向于哪些节点进行调度,匹配条件基于节点标签实现。nodeAffinity:# 硬限制要求,必须满足requiredDuringSchedulingIgnoredDuringExecution:# 基于节点标签匹配nodeSelectorTerms:# 基于表达式匹配节点标签- matchExpressions:# 指定节点标签的key- key: dc# 指定节点标签的value values:- hangzhou- shanghai# 指定key和values之间的关系。operator: Intolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2resources:limits:cpu: 200mmemory: 100Miports:- containerPort: 80

🌟玩转Pod调度之podAffinity
什么是podAffinity
所谓的podAffinity指的是某个Pod调度到特定的拓扑域(暂时理解为’机房’)后,后续的所有Pod都往该拓扑域调度。
实战案例
编写资源清单
[root@master231 scheduler]# cat 09-deploy-scheduler-podAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-podaffinity
spec:replicas: 5selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:affinity:# 配置Pod的亲和性podAffinity:# 硬限制要求,必须满足requiredDuringSchedulingIgnoredDuringExecution:# 指定拓扑域的key- topologyKey: dc# 指定标签选择器关联PodlabelSelector:matchExpressions:- key: appvalues:- xiuxianoperator: Intolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2
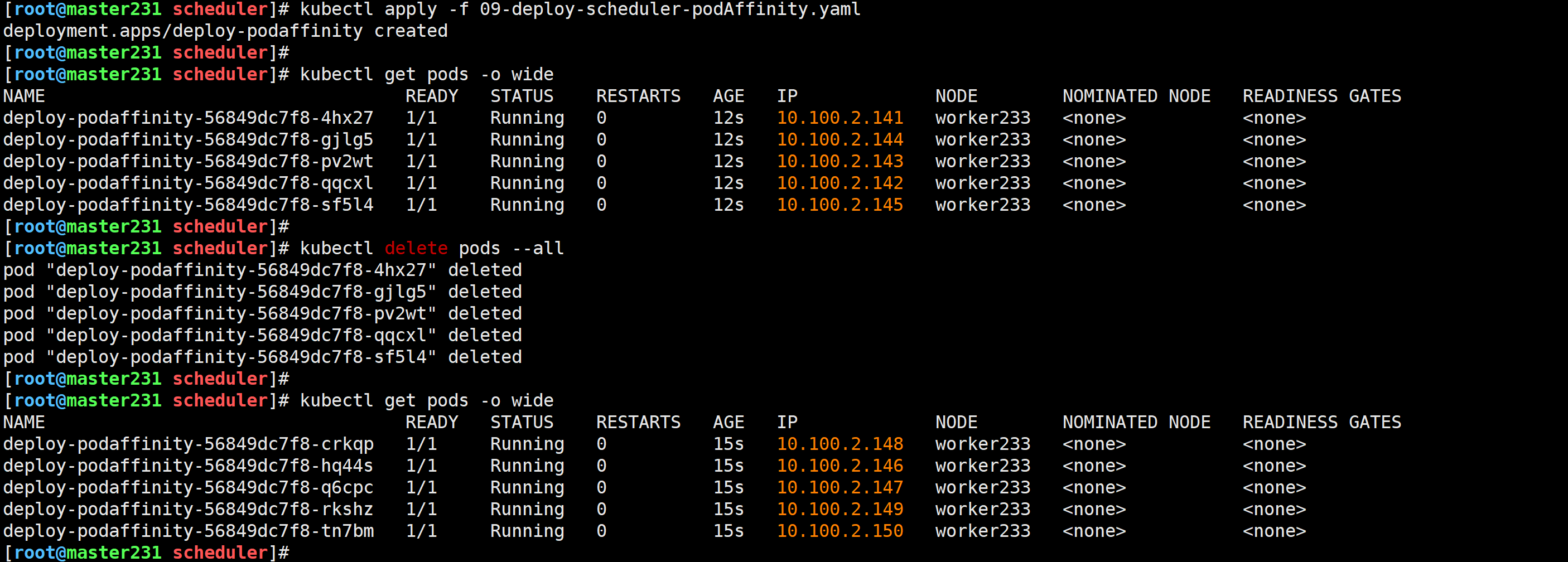
修改标签
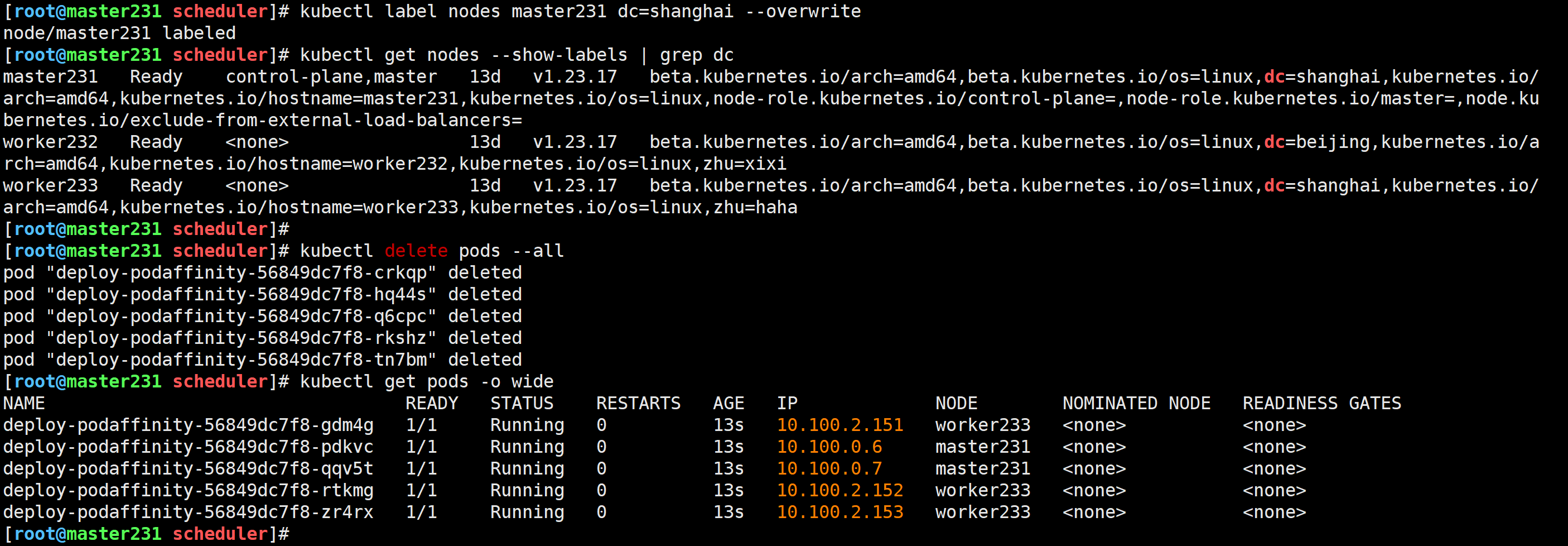
[root@master231 scheduler]# kubectl label nodes master231 dc=shanghai --overwrite
node/master231 labeled
🌟玩转Pod调度之PodAntiAffinity
什么是PodAntiAffinity
所谓的PodAntiAffinity和PodAffinity的作用相反,表示pod如果调度到某个拓扑域后,后续的Pod不会往该拓扑域调度。
实战案例
查看标签
[root@master231 scheduler]# kubectl get nodes --show-labels | grep dc

编写资源清单测试验证
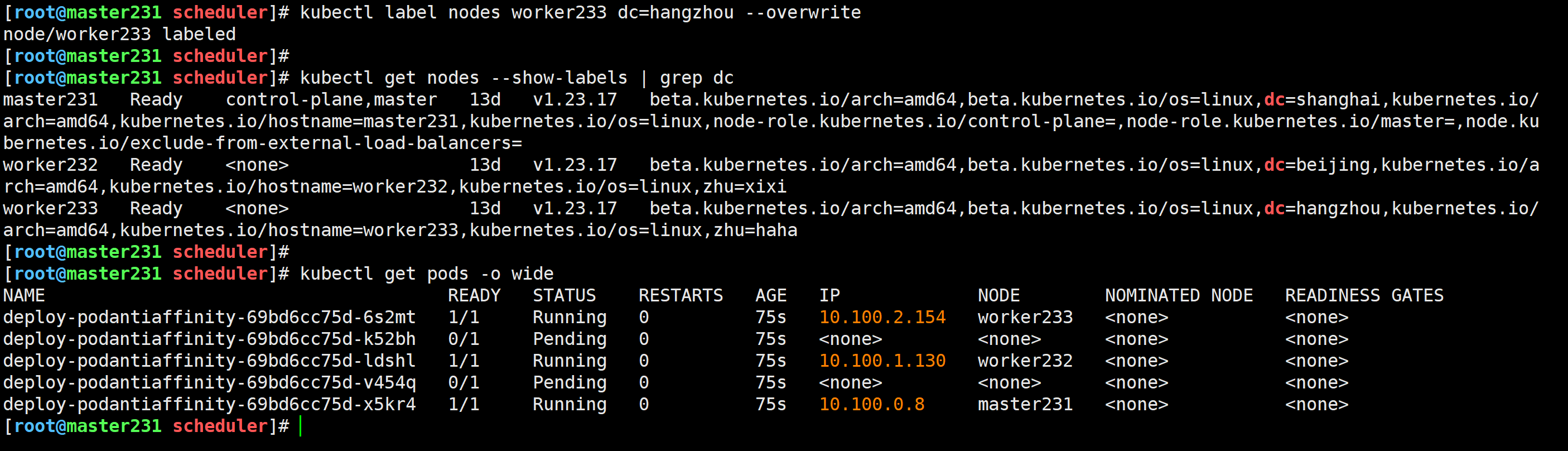
[root@master231 scheduler]# cat 10-deploy-scheduler-podAntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-podantiaffinity
spec:replicas: 5selector:matchLabels:app: xiuxiantemplate:metadata:labels:app: xiuxianversion: v1spec:affinity:# 配置Pod的反亲和性podAntiAffinity:# 硬限制要求,必须满足requiredDuringSchedulingIgnoredDuringExecution:# 指定拓扑域的key- topologyKey: dc# 指定标签选择器关联PodlabelSelector:matchExpressions:- key: appvalues:- xiuxianoperator: Intolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: c1image: registry.cn-hangzhou.aliyuncs.com/yinzhengjie-k8s/apps:v2

修改节点的标签并验证Pod调度情况
[root@master231 scheduler]# kubectl label nodes worker233 dc=hangzhou --overwrite
node/worker233 labeled
🌟玩转Pod调度基础之cordon
什么是cordon
cordon标记节点不可调度,一般用于集群维护。
cordon的底层实现逻辑其实就给节点打污点。
实战案例
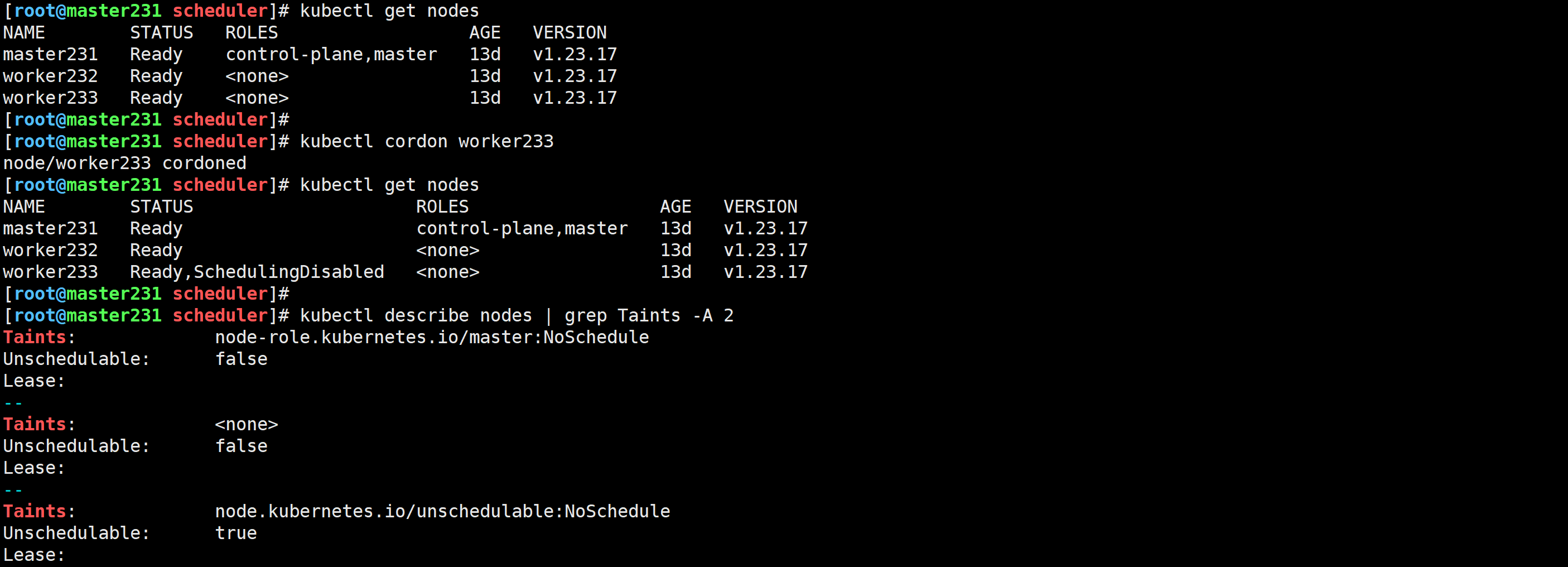
[root@master231 scheduler]# kubectl cordon worker233
node/worker233 cordoned
[root@master231 scheduler]# kubectl describe nodes | grep Taints -A 2

🌟玩转Pod调度基础之uncordon
什么uncordon
uncordon的操作和cordon操作相反,表示取消节点不可调度功能。
实战案例
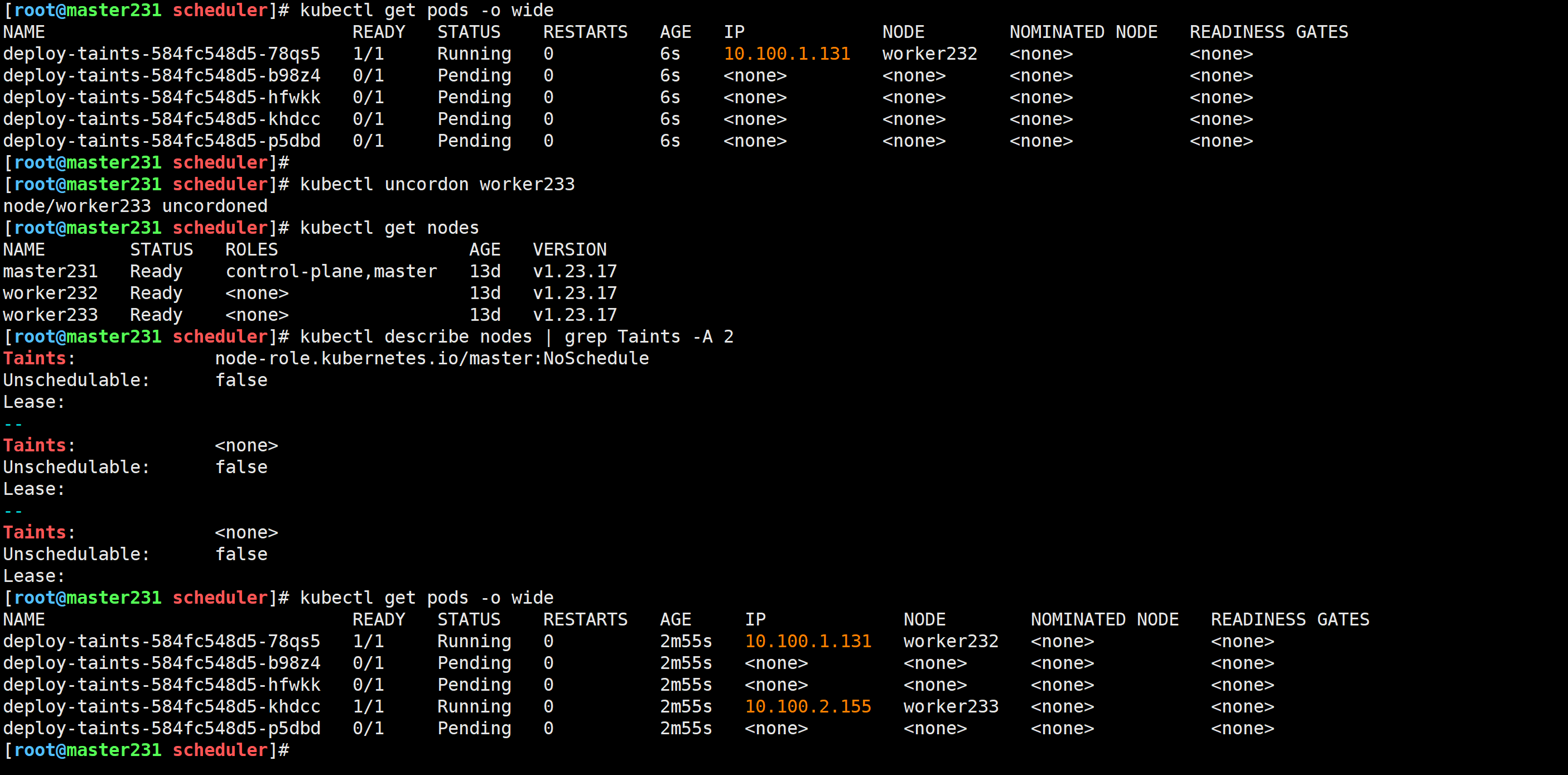
[root@master231 scheduler]# kubectl uncordon worker233
node/worker233 uncordoned
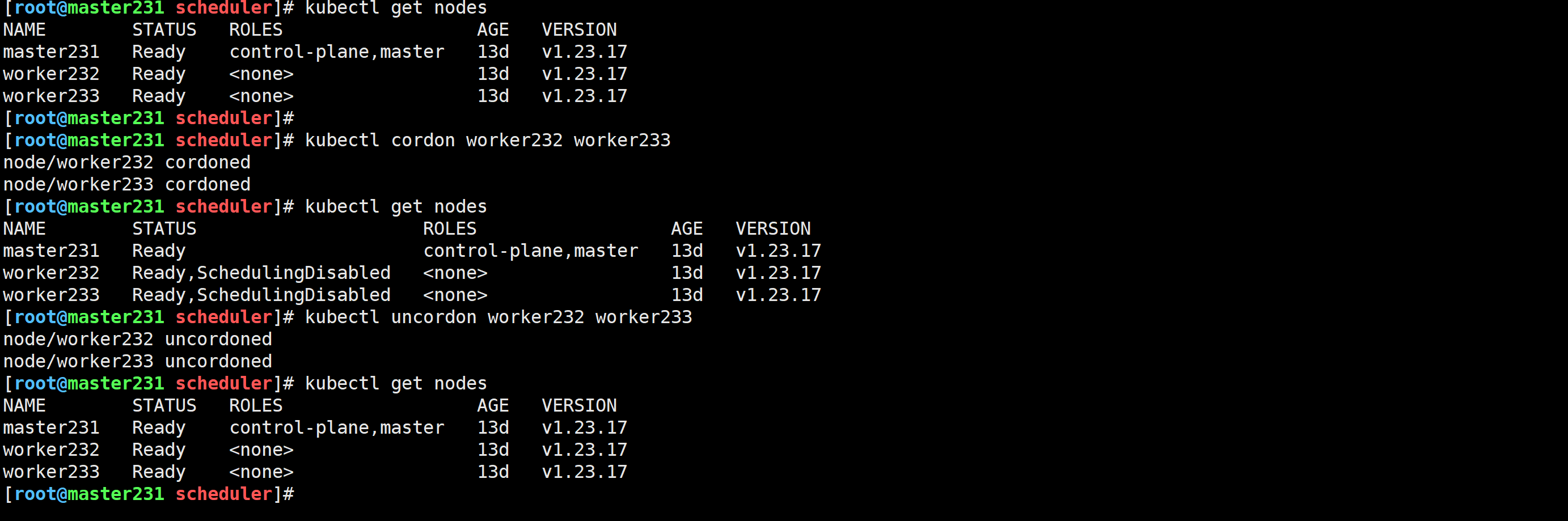
同时可以对多个节点操作
[root@master231 scheduler]# kubectl cordon worker232 worker233
node/worker232 cordoned
node/worker233 cordoned
[root@master231 scheduler]# kubectl uncordon worker232 worker233
node/worker232 uncordoned
node/worker233 uncordoned
🌟玩转Pod调度基础之drain
什么是drain
所谓drain其实就是将所在节点的pod进行驱逐的操作,说白了,就是将当前节点的Pod驱逐到其他节点运行。
在驱逐Pod时,需要忽略ds控制器创建的pod。
驱逐的主要应用场景是集群的缩容。
drain底层调用的cordon。
测试案例
部署测试服务
[root@master231 scheduler]# kubectl apply -f 06-deploy-scheduler-Taints.yaml
deployment.apps/deploy-taints created

驱逐worker233节点的Pod
[root@master231 scheduler]# kubectl drain worker233 --ignore-daemonsets --delete-emptydir-data

-
limits
限制Pod的资源使用情况,若pod的容器没有配置resources,则默认使用limits预定义的资源限制。
如果没有使用limits,也没有定义resources,则默认使用资源的上限worker节点的所有资源。
-
quota
可以限制pod,deploy,svc等的资源数量,控制用户创建过多的资源。
🌟k8s集群的缩容
k8s集群的缩容的流程
A.将已经调度到该节点下的所有Pod驱逐到其他节点;
B.停止kubelet进程,避免kubelet实时上报数据给apiServer;
C.如果是二进制部署的话,可以将kube-proxy组件停止;【可选】
D.将该节点重置环境,重新安装操作系统(防止数据泄露),然后再将服务器用做其他处理;
E.master节点移除待下线节点;
实操案例
驱逐已经调度到节点的Pod
[root@master231 scheduler]# kubectl drain worker233 --ignore-daemonsets --delete-emptydir-data# 如果驱逐失败,可以使用--disable-eviction参数,会跳过 PDB 检查
[root@master231 ~]# kubectl drain worker233 --ignore-daemonsets --delete-emptydir-data --disable-eviction

停止kubelet进程
[root@worker233 ~]# systemctl stop kubelet.service
重置worker节点并移除环境
[root@worker233 ~]# kubeadm reset -f[root@worker233 ~]# ipvsadm --clear
[root@worker233 ~]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConn[root@worker233 ~]# rm -f /etc/cni/net.d/10-flannel.conflist
[root@worker233 ~]#
[root@worker233 ~]# ll /etc/cni/net.d
total 8
drwxr-xr-x 2 root root 4096 Oct 4 16:25 ./
drwxr-xr-x 3 root root 4096 Sep 19 11:29 ../
[root@worker233 ~]#
重新安装操作系统
master移除待下线节点
[root@master231 scheduler]# kubectl delete nodes worker233
node "worker233" deleted

🌟kubelet首次加入集群bootstrap原理
参考链接:https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/kubelet-tls-bootstrapping/
- kubeadm基于apiserver创建于kubelet首次登录认证的token
- kubelet在启动时会先找kubeconfig相关文件,如果没有kubeconfig文件一般指的是首次加入集群,需要携带token认证
- 验证客户端是否有效,如果有效则可以加入集群
- 客户端发起csr证书签发请求,目前就是为了得到一个ApiServer签发的证书,用于后续工作中上报当前节点状态
- 服务端Api-Server并不负责签发证书,而是交由controller-manager组件来签发证书,并将证书返回给kubelet
- kubelet组件取回证书并存在"/var/lib/kubelet/pki",与此同时,会创建一个kubeconfig文件,放在"/etc/kubernetes/kubelet.conf",后续操作就可以使用kubeconfig文件进行认证传输
🌟k8s集群的扩容实战案例
扩容流程
A. 创建token;
B. 待加入节点安装docker,kubectl,kubeadm,kubelet等相关组件;
C. kubeadm join即可
实战案例
token的基本管理
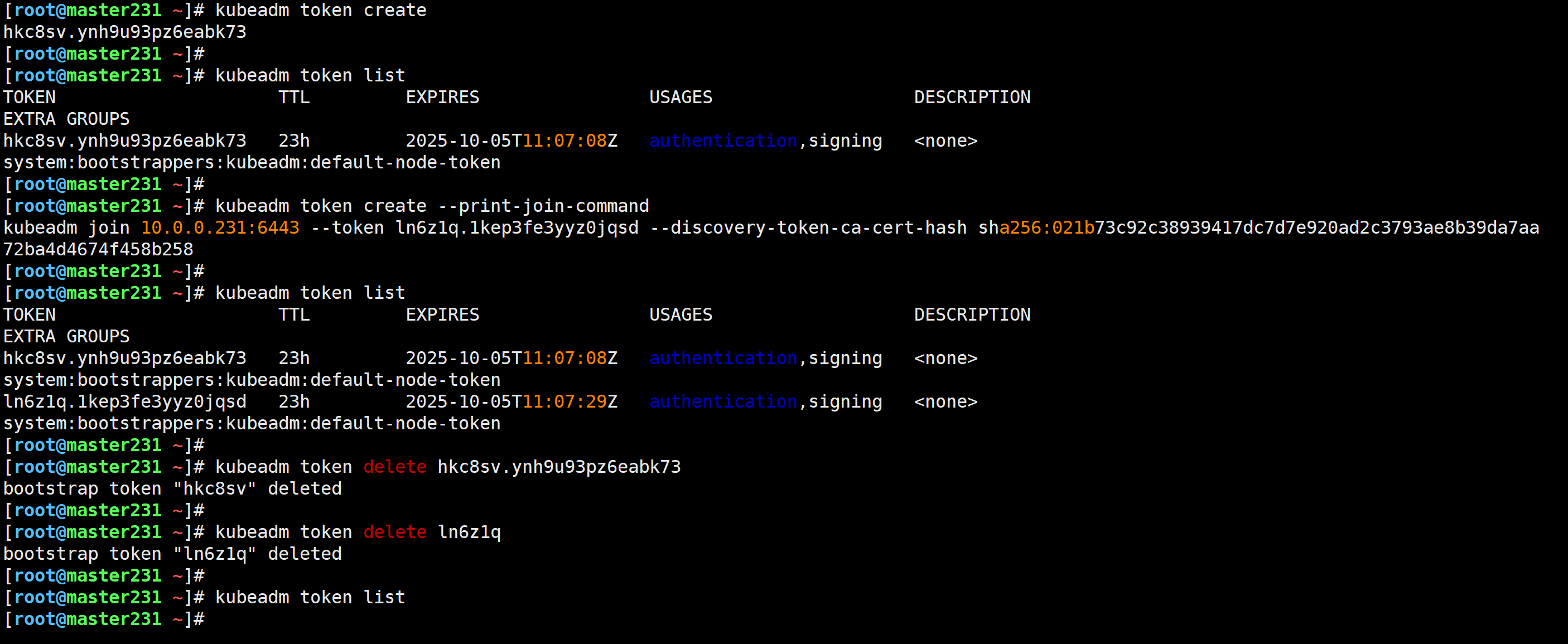
1.创建token
[root@master231 ~]# kubeadm token create
hkc8sv.ynh9u93pz6eabk732.查看token
[root@master231 ~]# kubeadm token list3.创建token并打印出加入集群的命令
[root@master231 ~]# kubeadm token create --print-join-command
kubeadm join 10.0.0.231:6443 --token ln6z1q.1kep3fe3yyz0jqsd --discovery-token-ca-cert-hash sha256:021b73c92c38939417dc7d7e920ad2c3793ae8b39da7aa72ba4d4674f458b258 4.删除token
[root@master231 ~]# kubeadm token delete hkc8sv.ynh9u93pz6eabk73
bootstrap token "hkc8sv" deleted
[root@master231 ~]#
[root@master231 ~]# kubeadm token delete ln6z1q
bootstrap token "ln6z1q" deleted
[root@master231 ~]#
[root@master231 ~]# kubeadm token list
[root@master231 ~]#
master节点创建token
[root@master231 ~]# kubeadm token create baolin.zhubaolinzhubaol --print-join-command --ttl 0
[root@master231 ~]# kubeadm token list
[root@master231 ~]# kubectl get secrets -n kube-system bootstrap-token-baolin

客户端安装相关软件包
主要安装docker,kubectl,kubeadm,kubelet等相关组件
待加入节点加入集群
使用刚刚生成的token、
[root@worker233 ~]# kubeadm join 10.0.0.231:6443 --token baolin.zhubaolinzhubaol --discovery-token-ca-cert-hash sha256:021b73c92c38939417dc7d7e920ad2c3793ae8b39da7aa72ba4d4674f458b258
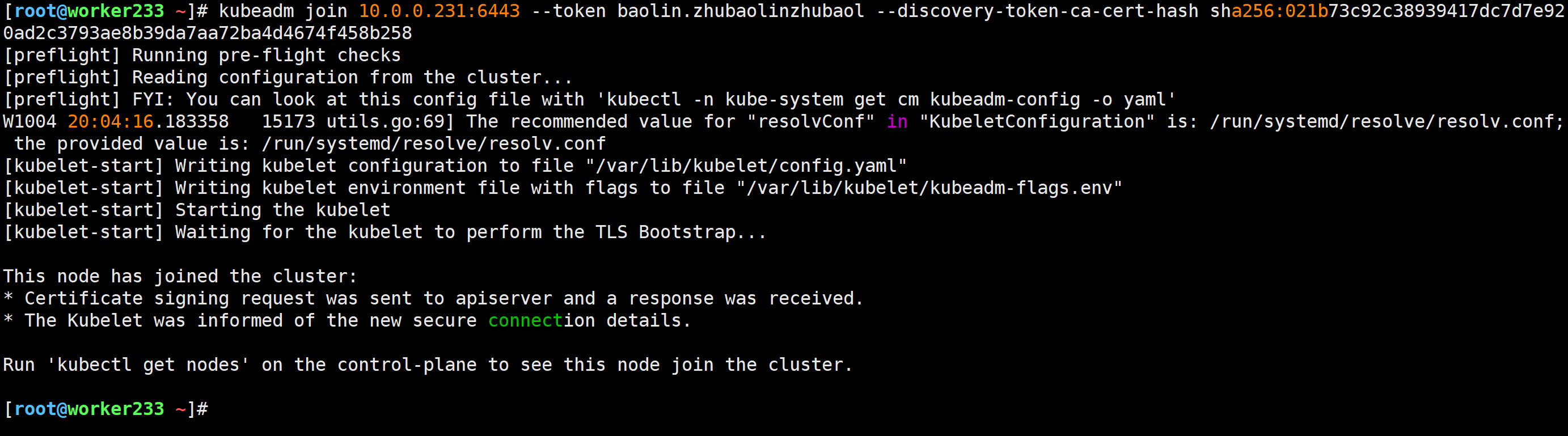
master节点验证
kubectl get csr,node

验证客户端证书信息
[root@worker233 ~]# ll /var/lib/kubelet/
[root@worker233 ~]# ll /var/lib/kubelet/pki/
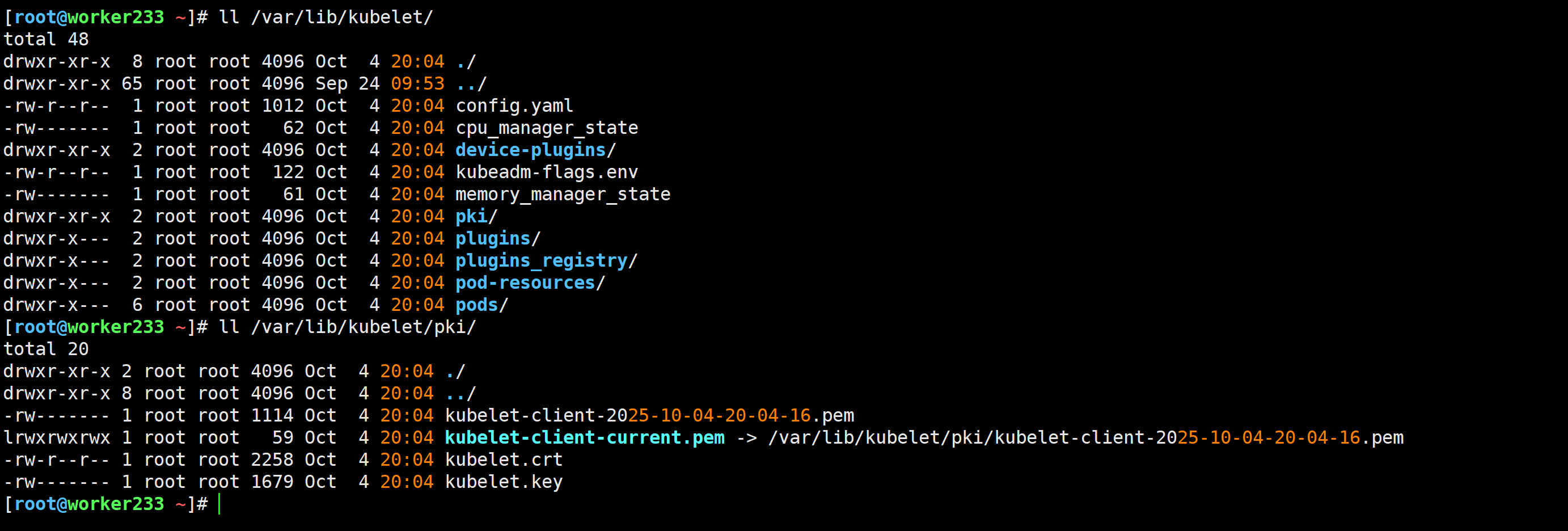
master节点查看证书签发请求
[root@master231 scheduler]# kubectl get csr[root@master231 scheduler]# kubectl get csr csr-54j4s -o yaml
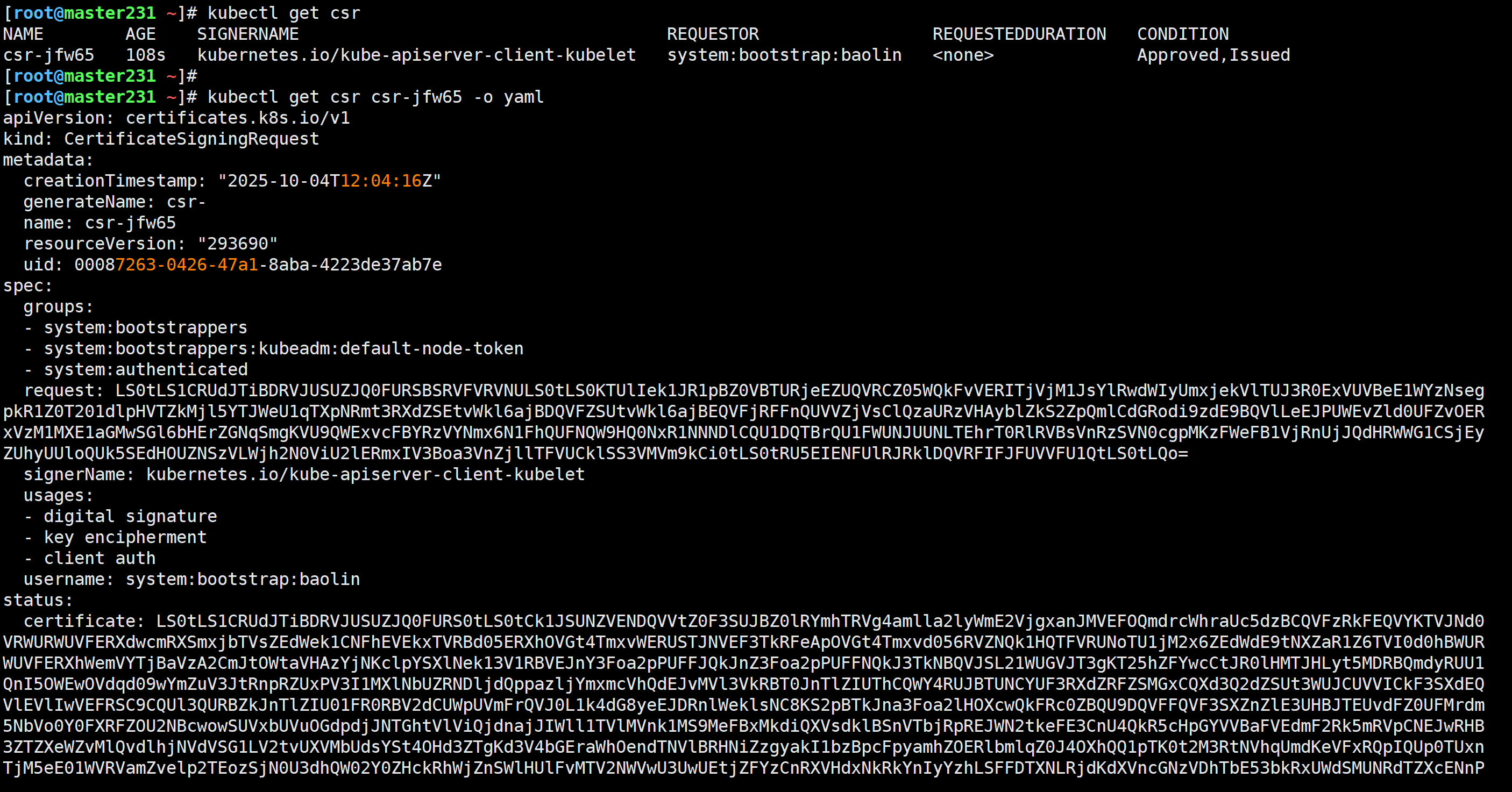
移除token
[root@master231 ~]# kubeadm token list
[root@master231 ~]# kubeadm token delete baolin
