Video Understanding--ECCV2022
Accepted papers | ECCV2022
ECVA | European Computer Vision Association
LLM
oral
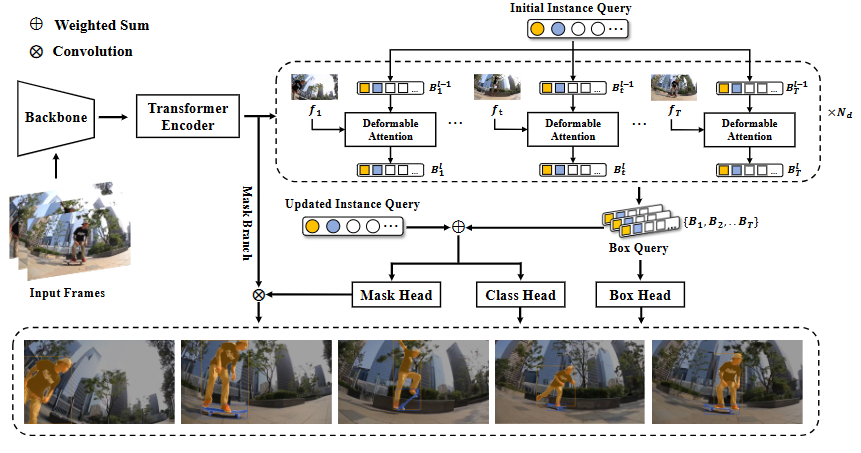
SeqFormer: Sequential Transformer for Video Instance Segmentation
136880547.pdf
实例分割
核心方法:
(1)不flatten编码器给的时空特征,让每帧过deformable attention通过这种形变学习目标框的帧间关系
(2)updated query是在多个解码器block中,学一个加权系数加权最后的box query和上一个block产的updated query
(3)此时的updated query已经聚合了目标在所有帧的全局特征
遗留问题:
(1)不适合超长视频
(2)难处理目标被完全遮挡且持续多帧
(3)可变形注意力对小目标需要加强
(4)两帧直接差距太大,可形变注意力会有问题
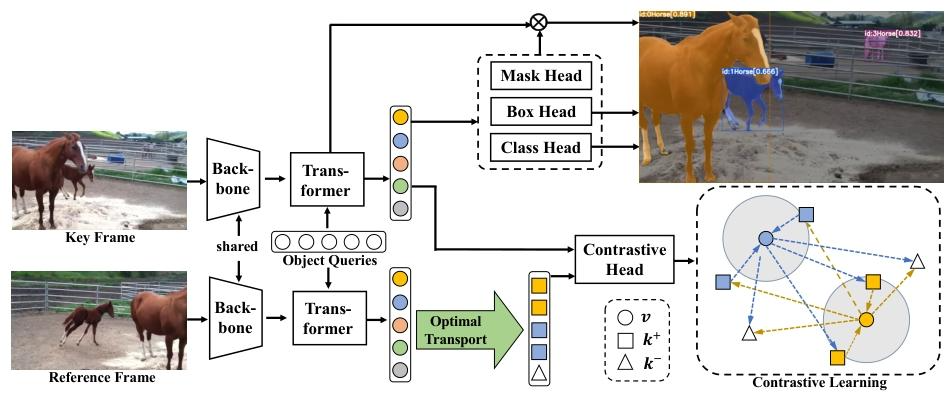
In Defense of Online Models for Video Instance Segmentation
136880582.pdf
实例分割
核心方法:
(1)对每个Object Query用可形变注意力+backbone提取的多尺度信息
(2)对比学习动态正负样本选择:用了个数学的最优传输去判断predict和label的嵌入的分布相似度,然后取topk为正,其余为负
(3)维护记忆库解决在线分割实例ID分配问题,每个实例有一条独立记录,记录包含该实例的 “多帧时序对比嵌入(历史嵌入)”、“存在时长(帧数)”、“最新帧的边界框与类别标签”;历史嵌入->当前帧的嵌入做相似度计算,当前帧的所有嵌入(不同实例)->历史嵌入做相似度计算,若这俩嵌入的相似度高,按多帧的时间顺序加权得到新的历史嵌入
(4)预测mask的分支很简单,把分割+追踪拆开了,所以推理的时间很快
遗留的问题:
(1)记忆库不支持超长视频->记忆库的增删
(2)利用多帧
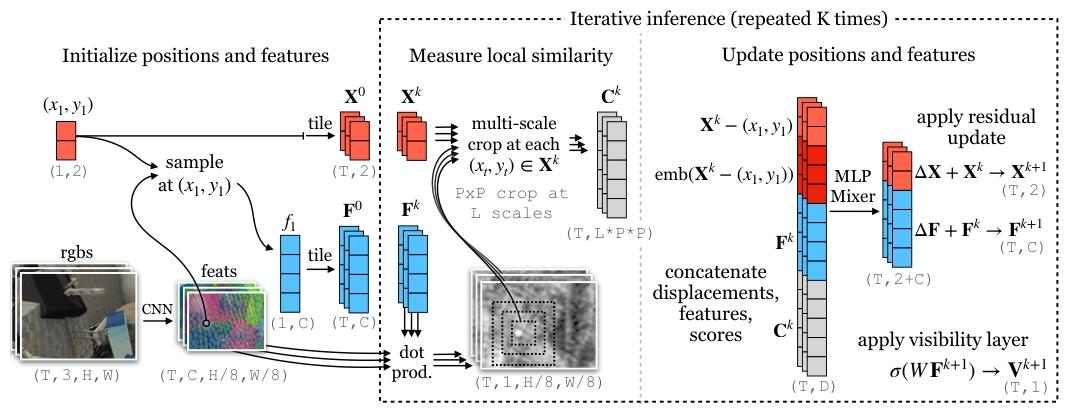
Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories
ecva.net/papers/eccv_2022/papers_ECCV/papers/136820055.pdf
实现遮挡下的长时序像素跟踪
核心方法:
(1)粒子群算法
(2)学习目标的长时运动先验(如运动趋势、外观变化规律)
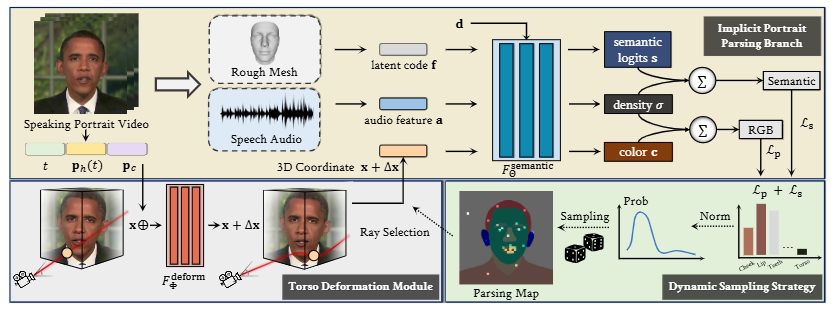
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
136970105.pdf
数字人视频生成
核心方法:
(1)在NeRF基础上,额外细粒度化预测面部各部分的语义
(2)在采样时,对嘴唇、牙齿等难学习的地方获得更多采样权重
(3)头和躯干不拆开生成
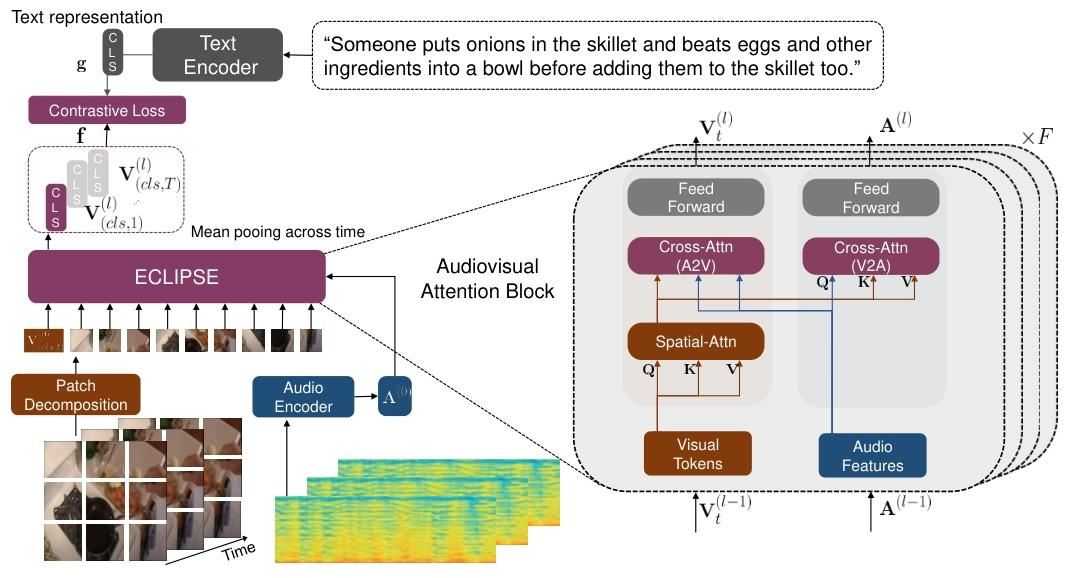
ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound
136940405.pdf
长视频检索
核心方法:
(1)稀疏采样过ViT得到视觉嵌入和CLS token;以每个视频帧为中心截取10秒音频转换为频谱图,过预训练的resnet得到听觉嵌入;文字过CLIP的编码器得到文本嵌入
(2)CLIP的Transformer块中,视觉先做自注意力,视听觉再做双向交叉注意力,其中一方向的输入是视觉嵌入、听觉嵌入和视觉的CLS token
(3)得到视听觉CLS token,去和文本做对比学习
遗留的问题:
(1)未探索音频有噪声情况
(2)定位不到短的局部视频
(3)未探索小时级的长视频