知识图谱(Knowledge Graph)详解
在人工智能和大数据时代,知识图谱(Knowledge Graph)已成为连接信息、实现语义理解与智能推理的重要工具。它通过结构化的方式表示现实世界中的实体、属性及其相互关系,为搜索引擎、推荐系统、智能问答、医疗诊断等众多应用提供了强大的知识支持。
本文将结合一张典型的知识图谱构建流程图,深入解析知识图谱的核心构成、关键技术环节以及实际应用场景,帮助读者全面理解知识图谱是如何从海量数据中“提炼”出可计算、可推理的知识体系的。
知识图谱由哪两层构成?
数据层(data layer)和模式层(schema layer)
信息抽取包含哪三样技术?
实体抽取、关系抽取、属性抽取
一、什么是知识图谱?
知识图谱是一种以图结构组织的知识库,其中:
- 节点(Node) 表示实体(如人物、地点、事件、概念等)
- 边(Edge) 表示实体之间的关系(如“出生于”、“属于”、“是……的作者”等)
- 每个节点还可以拥有多个属性(如姓名、出生日期、职业等)
例如,在一个电影知识图谱中:
[张艺谋] ——(导演)——> [《英雄》]
[《英雄》] ——(主演)——> [李连杰]
[李连杰] ——(国籍)——> [中国]这种结构使得机器不仅能“知道”信息,还能“理解”信息之间的逻辑联系。
二、知识图谱的构建流程详解
下图展示了一个典型的知识图谱构建流程,我们可以将其分为四个主要阶段:
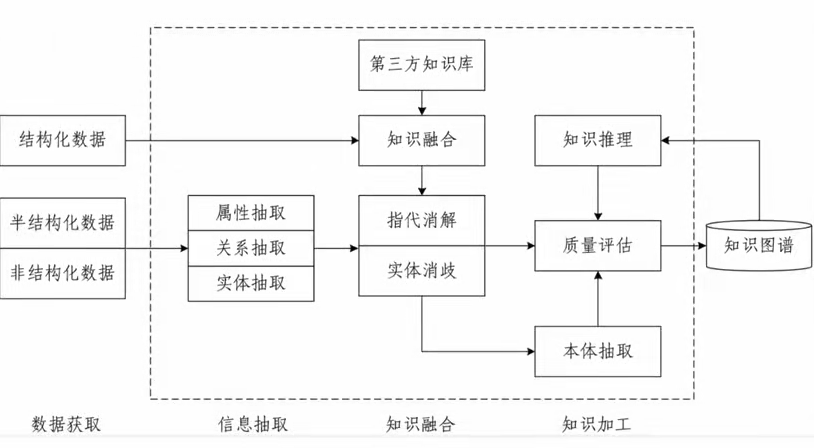
阶段一:数据获取(Data Acquisition)
知识图谱的基础是数据。原始数据来源多样,可分为三类:
- 结构化数据:如数据库中的表格(如用户表、商品表),字段清晰,易于提取。
- 半结构化数据:如JSON、XML、HTML等格式的数据,有一定结构但不完全规则。
- 非结构化数据:如网页文本、新闻文章、社交媒体内容、科研论文等,信息隐含且无固定格式。
✅ 目标:从多种数据源中收集尽可能多的相关信息。
阶段二:信息抽取(Information Extraction)
这是将原始数据转化为结构化知识的关键步骤,主要包括以下三个子任务:
1. 实体抽取(Entity Extraction)
识别文本中的关键实体,如人名、地名、机构名、时间等。
- 示例:在句子“马云创立了阿里巴巴”中,“马云”、“阿里巴巴”是两个重要实体。
- 技术手段:基于规则、词典匹配、命名实体识别(NER)模型(如BERT + CRF)。
2. 关系抽取(Relation Extraction)
确定实体之间的语义关系。
- 示例:“马云” 和 “阿里巴巴” 的关系是 “创始人”。
- 方法:模板匹配、依存句法分析、深度学习模型(如BiLSTM-CRF、Transformer)。
3. 属性抽取(Attribute Extraction)
提取实体的属性值。
- 示例:“马云”的“出生年份”是“1964”。
- 可通过关键词匹配或序列标注完成。
📌 输出结果通常是一个三元组形式:
(主体, 关系, 客体)或(实体, 属性, 值)。
阶段三:知识融合(Knowledge Fusion)
由于数据来自不同来源,可能存在同义异名(同一个实体有不同的名称)、一义多名(同一个名字代表不同实体)等问题。因此需要进行整合与统一。
主要任务包括:
实体消歧(Entity Disambiguation)
- 判断某个提及是否指向唯一的实体。
- 如“苹果”可能指水果或公司,需根据上下文判断。
指代消解(Coreference Resolution)
- 解决代词或简称所指代的对象。
- 如“他创办了公司”中的“他”是指谁?
知识融合
- 将来自不同来源的知识合并,并与第三方权威知识库(如Wikidata、DBpedia、Freebase)对齐。
- 提高一致性与完整性。
🔁 这一步确保知识图谱内部的一致性和准确性。
阶段四:知识加工(Knowledge Processing)
在得到初步知识后,还需进一步优化和扩展其价值。
1. 本体抽取(Ontology Extraction)
- 构建领域内的概念体系,定义类(Class)、属性(Property)、层级关系(如继承、并列)。
- 例如:
Person → CEO → Founder是一种分类层次。
2. 质量评估(Quality Assessment)
- 对生成的知识进行校验,剔除错误或低置信度的三元组。
- 使用规则、人工审核、统计方法等方式进行质量控制。
3. 知识推理(Knowledge Reasoning)
- 利用逻辑规则或机器学习模型推导出新的知识。
- 例如:
- 已知:
A 是 B 的父亲,B 是 C 的父亲→ 推理得:A 是 C 的祖父 - 或利用路径推理发现隐藏关联。
- 已知:
💡 推理能力使知识图谱具备“主动思考”的潜力,而不仅是存储事实。
最终输出:知识图谱(Knowledge Graph)
所有处理后的知识被存储在一个统一的图数据库中(如Neo4j、JanusGraph),形成完整的知识网络。这个图谱可以:
- 支持查询(如SPARQL)
- 用于语义搜索
- 作为大模型的“外部记忆”增强推理能力
三、知识图谱的应用场景
| 应用领域 | 具体案例 |
|---|---|
| 搜索引擎 | Google Knowledge Graph 提供右侧卡片信息 |
| 智能问答 | 小爱同学、Siri 回答“姚明多高?”时调用知识图谱 |
| 推荐系统 | 根据用户的兴趣点推荐相似内容 |
| 金融风险控制 | 分析企业之间的关联关系,识别潜在风险 |
| 医疗健康 | 构建疾病-症状-药物-基因的知识网络辅助诊断 |
| 智能制造 | 设备故障预测与维护策略优化 |
四、挑战与未来趋势
尽管知识图谱技术发展迅速,但仍面临一些挑战:
- 数据质量与噪声问题:非结构化数据中存在大量错误或模糊表达。
- 跨语言、跨领域融合难:如何让中文知识图谱与英文知识库无缝对接?
- 动态更新机制不足:现实世界变化快,知识图谱需持续更新。
- 隐私与安全问题:敏感信息泄露风险。
未来发展方向:
- 与大语言模型(LLM)结合:知识图谱为LLM提供“事实锚点”,防止幻觉;LLM则助力自动构建和补全知识。
- 自动化构建工具链:实现端到端的知识图谱生成。
- 联邦知识图谱:在保护隐私的前提下实现多方协作建模。
五、结语
知识图谱不仅是AI时代的“大脑”,更是连接人类智慧与机器智能的桥梁。从原始数据出发,经过抽取、融合、加工、推理等多个环节,最终形成一个可理解、可推理、可扩展的知识网络。
正如这张流程图所示,每一个模块都至关重要:没有高质量的信息抽取,就没有可靠的知识;没有有效的知识融合,就会陷入混乱;没有推理能力,知识就只是静态的“死数据”。
随着技术的进步,知识图谱将在更多领域发挥其巨大潜力,推动智能化社会的建设进程。