【开题答辩实录分享】以《基于Python的旅游网站数据爬虫研究》为例进行答辩实录分享
大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少“避坑”经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批“好上手且有亮点”的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

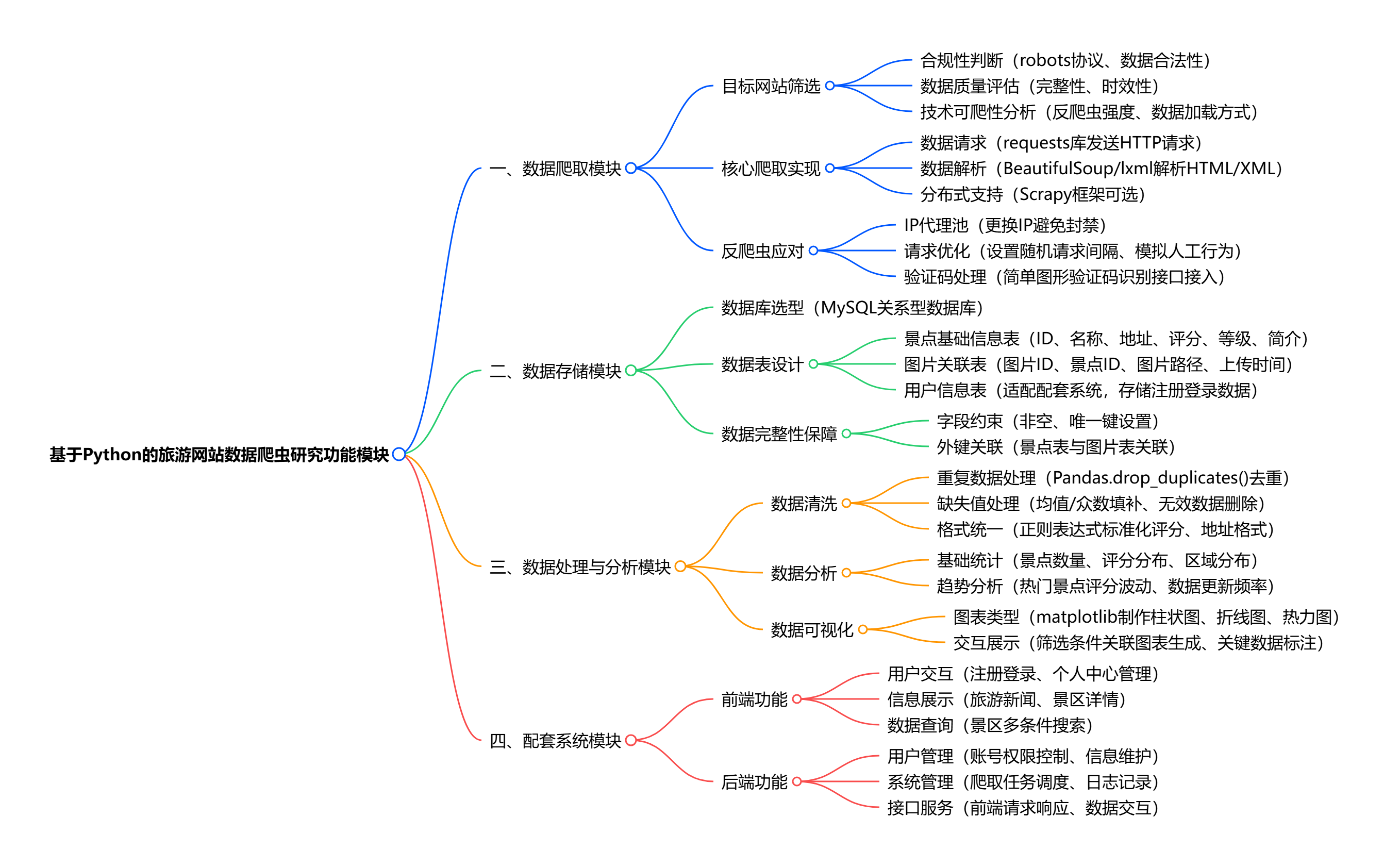
基于 Python 的旅游网站数据爬虫研究功能总结
- 数据爬取功能:以 Python 为核心,借助 requests、BeautifulSoup、Scrapy 等库 / 框架,从合规旅游网站爬取景点名称、地址、评分、等级、图片、简介等数据,筛选目标网站时兼顾合法性、数据完整性与技术可爬性,同时通过更换 IP 代理、设置合理请求频率等策略应对反爬虫机制。
- 数据存储功能:选用 MySQL 关系型数据库,设计结构化数据表(如景点表、图片表),存储爬取的各类旅游数据,通过外键关联保证数据关联性与完整性,便于后续查询与调用。
- 数据处理与分析功能:利用 Python 的 Pandas、NumPy 库清洗数据(去除重复数据、填补缺失值、统一数据格式),再通过数据分析工具挖掘数据特征(如景点评分分布、区域景点数量差异),结合 matplotlib 制作柱状图、折线图、热力图等可视化图表,直观展示分析结果。
- 配套系统功能:
- 前端:实现用户注册登录、旅游新闻展示、景区多条件搜索、景区数据详情查看、个人中心管理等交互功能;
- 后端:完成用户管理、系统管理、数据爬取任务调度、数据分析计算、数据可视化图表生成与展示等功能,支持前端请求响应与数据交互。
【开题陈述】
各位老师好,我是H同学,本次课题是《基于Python的旅游网站数据爬虫研究》。系统分前端与后端:前端用Vue3+ElementPlus,实现注册/登录、景区搜索、新闻展示、个人中心;后端用Flask+MySQL,完成用户管理、数据爬取(景点名称、地址、评分、等级、图片、简介)、数据清洗、分析与可视化。爬虫层采用requests+BeautifulSoup+Selenium轮换UA与IP池,定时增量抓取主流OTA网站,把清洗后的结构化数据存入MySQL,再用Pandas、Matplotlib、ECharts做统计与趋势预测,为游客和商家提供决策参考。下面请各位老师提问。
【答辩开始】
评委老师1:为什么选择Python而不是Java或Go做爬虫?
答辩学生:Python语法简洁,三方库最丰富;requests、BeautifulSoup、Scrapy、Selenium生态成熟,开发效率高,适合毕业设计周期短的场景。
评委老师2:目标站点如果采用动态渲染+反爬,你怎么保证数据完整性?
答辩学生:先用Selenium+显式等待拿到完整DOM,再对返回的HTML用BeautifulSoup解析;同时维护IP代理池、随机UA、随机鼠标轨迹,并控制1.5~3 s随机间隔,若遇滑块则调用第三方打码平台,失败超过阈值就记录URL留待增量补爬。
评委老师3:爬下来的图片只存URL还是本地下载?如何防止重复?
答辩学生:采用“URL+MD5”双保险:先下载到本地NAS,计算文件MD5存入MySQL唯一索引;如果MD5已存在则跳过,保证同一张图片只存一份,节省存储。
评委老师4:景区评分字段在不同站点尺度不同(5分制/100分制),你如何归一化?
答辩学生:写一条映射规则:遇到100分制就除以20,遇到10分制就乘以0.5,统一转成5分制浮点;同时保留原始分值与单位,方便回溯。
评委老师5:数据库里景点记录随时间更新,你怎么设计主键?
答辩学生:用“站点+外部ID”做联合主键,再增加update_time字段;每次增量爬取先ON DUPLICATE KEY UPDATE,只改变化字段,保证历史可追溯。
评委老师6:如果某天目标站点升级接口,把列表页换成GraphQL+JWT鉴权,你现有架构需要改动哪些部分?
答辩学生:①在请求层新增JWT自动刷新拦截器,用requests.Session维护Authorization头;②把原HTML解析模块抽象成“解析插件”,新写GraphQL JSON解析插件,通过工厂模式动态选择,业务层和存储层无需改动,实现开闭原则。
评委老师7:系统声称能做“趋势预测”,可旅游数据受节假日、疫情、天气等外生变量影响,仅用历史评分或销量做时间序列可能过拟合,你怎么解决?
答辩学生:①特征工程侧:除自身历史数据外,引入节假日虚拟变量、天气API的降水温度、百度指数的关键词热度,做多源特征拼接;②模型侧:用Prophet做baseline,再用XGBoost融合外生特征,交叉验证调参;③评估侧:按时间顺序划分训练/验证集,用MAPE与RMSE双指标,若MAPE>15%就触发模型重训;④前端同时给出预测区间(95%置信带),提示用户不确定性,避免盲目相信单值预测。
【评价总结】
H同学对爬虫链路、数据清洗与可视化都有清晰实现,外生变量融合与模型评估考虑得较周到,具备落地价值。若后续能在JWT自动刷新与GraphQL适配部分再给出单元测试与性能基准,将更完善。总体表现良好,同意开题,继续推进。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告,可发送使用或参考。