爬虫反反爬1
目录
经常被反爬的都有谁
常见的反爬策略
通过headers字段来反爬
通过headers中的User-Agent字段来反爬
通过referer字段或者是其他字段来反爬
通过请求参数来反爬
通过从html静态文件中获取请求数据(github登录数据)
通过发送请求获取请求数据
通过js生成请求参数
通过验证码来反爬
常见基于爬虫行为进行反爬
基于请求频率或总请求数量
根据爬取行为进行反爬,通常在爬取步骤上做分析
常见基于数据加密进行反爬
对响应中含有的数据进行特殊化处理
Splash介绍
安装
拉取镜像
运行scrapinghub/splash
查看效果
Splash的基本使用
Splash对象属性
scroll_position
Splash对象的方法
go()
wait()
jsfunc()
evaljs()与 runjs()
html()
png()
har()
url()
set_user_agent()
set_custom_headers()
select()
send_text()
mouse_click()
代理Ip

爬虫:使用任何技术手段,批量获取网站信息的一种方式。关键在于批量
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量
-
因爬虫的访问频率过高影响服务器的运行
-
影响别人业务
-
导致服务器宕机
单一的DoS攻击一般是采用一对一方式的,它利用网络协议和操作系统的一些缺陷,采用欺骗和伪装的策略来进行网络攻击,使网站服务器充斥大量要求回复的信息,消耗网络带宽或系统资源,导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。
-
-
公司的劳动果实轻松并拿走
- 免费资源被拿走丢失竞争力
- 收费资源属于侵权
-
商业竞争对象
-
服务器流量需要钱!!!(服务器不是免费的,不做慈善)
-
起诉浪费时间、钱,还不一定赢!!
经常被反爬的都有谁

-
十分低级的小白(应届生,刚入行)
应届毕业生,与小白的的爬虫通常简单粗暴,根本不管服务器压力,加上人数不可测,很容易被反爬
-
十分低级的创业公司
现在的创业公司越来越多,为了发展公司,需要做不少的分析程序,与分析行为,但是分析是需要数据的。若不想买,就只能写爬虫,为了公司的生死存亡,只能不断的爬取数据
-
不小心写错代码,没人停止的爬虫
程序不小心写错,进也死循环。再就是部署服务器,无人维护了,依然不停的爬取数据
-
成型的商业对手
最主要的对手,往往商业对手既然选择爬取对方的数据,基本都是有技术、钱。如果他们要爬,只能和他们死磕。
常见的反爬策略

通过headers字段来反爬
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
通过headers中的User-Agent字段来反爬
- 反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置
- 解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
通过referer字段或者是其他字段来反爬
-
反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法
-
解决方法:添加referer字段
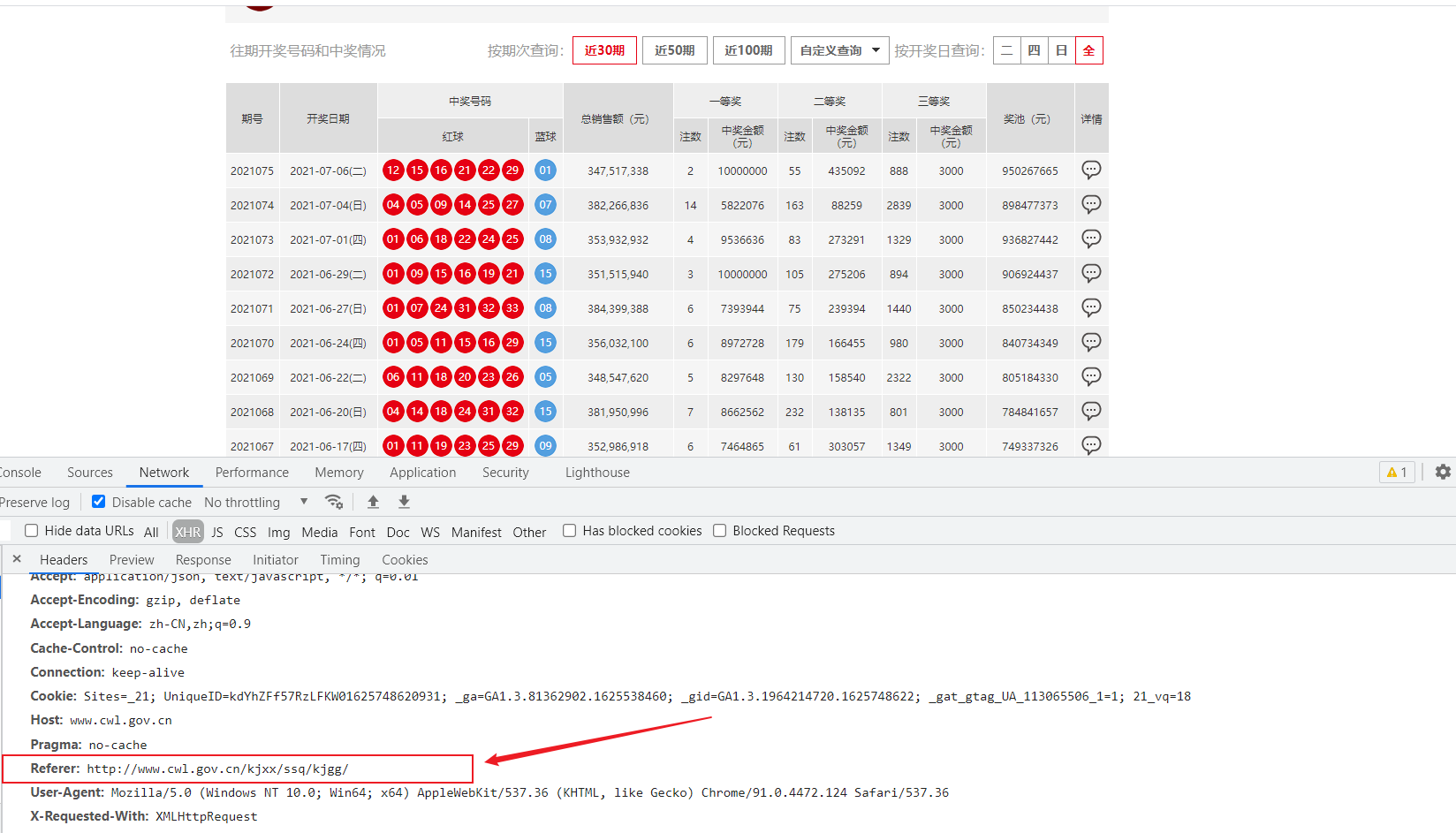
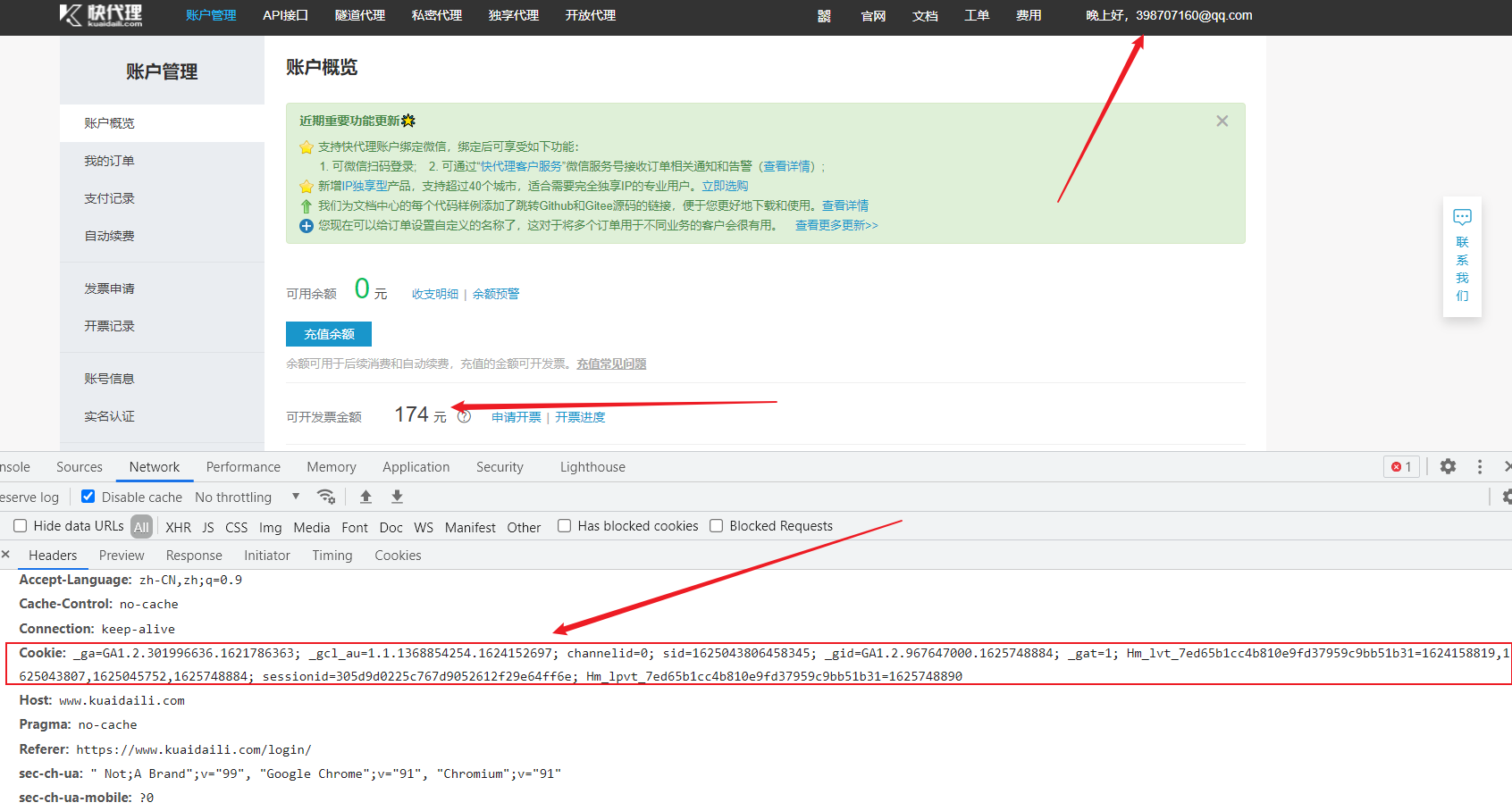
通过cookie来反爬
- 反爬原理:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
- 解决方案:进行模拟登陆,成功获取cookies之后在进行数据爬取
通过请求参数来反爬
请求参数的获取方法有很多,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫
通过从html静态文件中获取请求数据(github登录数据)
-
反爬原理:通过增加获取请求参数的难度进行反爬
-
解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
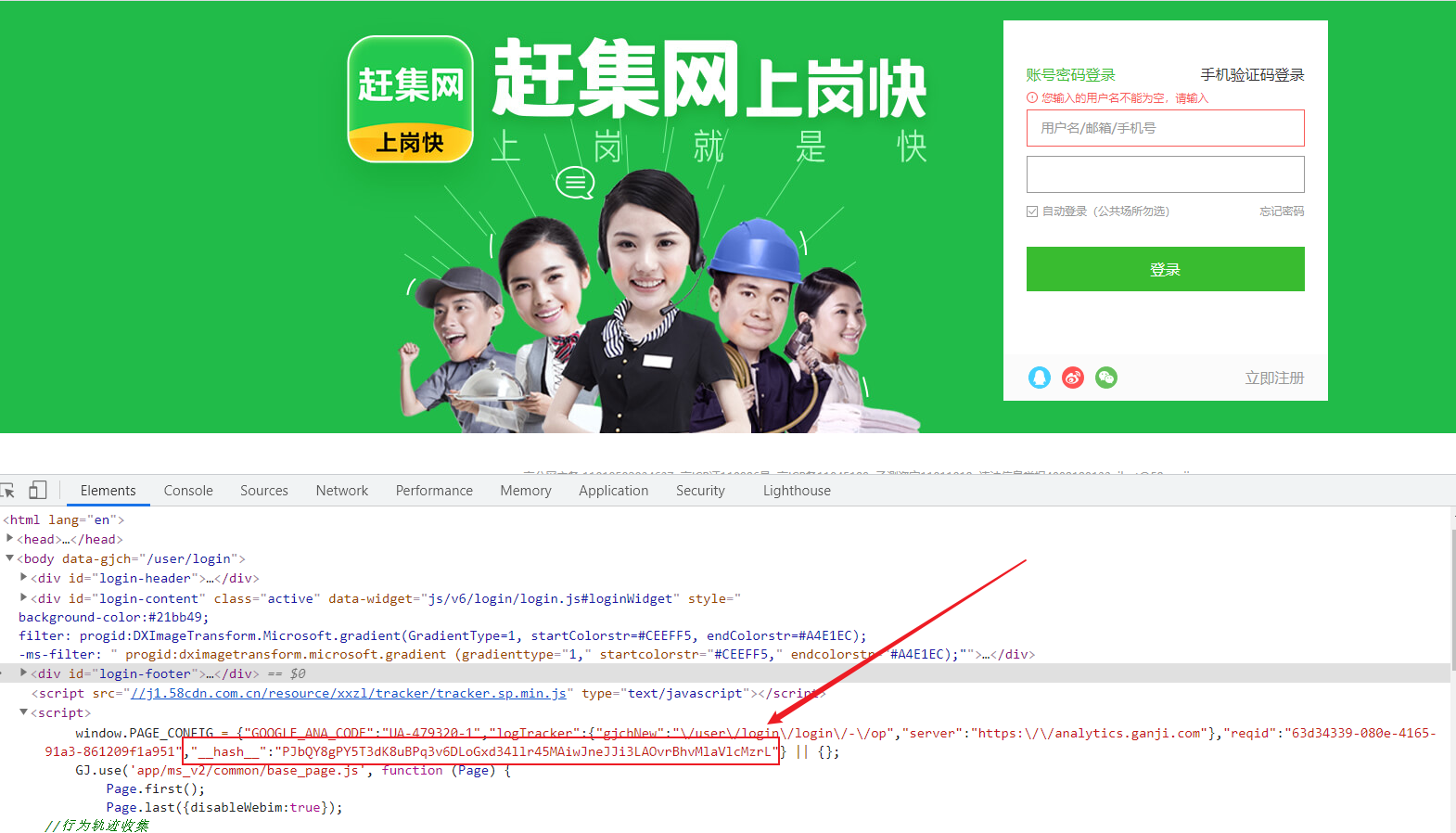
通过发送请求获取请求数据
-
反爬原因:通过增加获取请求参数的难度进行反爬
-
解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系,搞清楚请求参数的来源
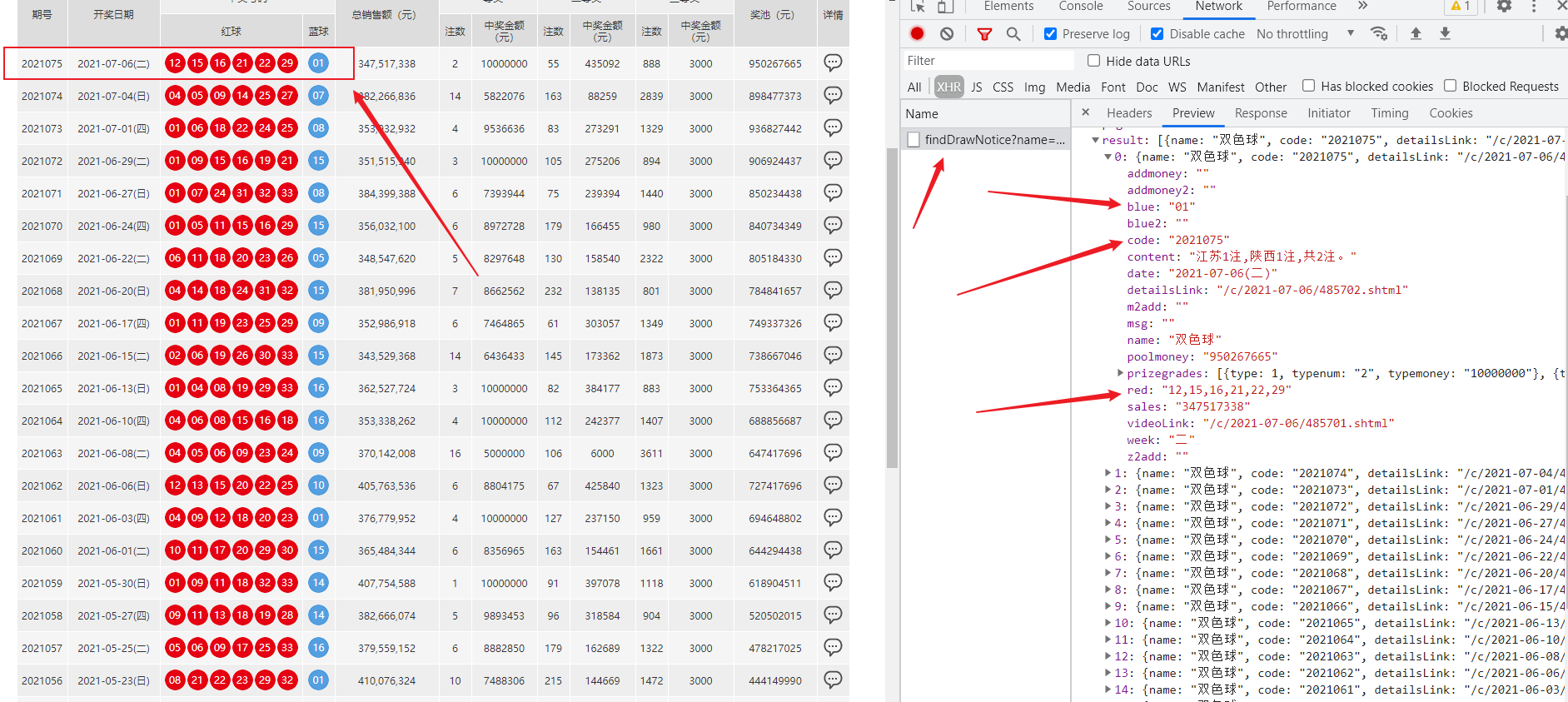
通过js生成请求参数
- 反爬原理:js生成了请求参数
- 解决方法:分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
通过验证码来反爬
- 反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为
- 解决方法:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐
常见基于爬虫行为进行反爬
基于请求频率或总请求数量
爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户
-
通过请求ip/账号单位时间内总请求数量进行反爬
- 反爬原理:正常浏览器请求网站,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫
- 解决方法:对应的通过购买高质量的ip的方式能够解决问题/购买个多账号
-
通过同一ip/账号请求之间的间隔进行反爬
- 反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间时间间隔通常比较固定同时时间间隔较短,因此可以用来做反爬
- 解决方法:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠
根据爬取行为进行反爬,通常在爬取步骤上做分析
通过js实现跳转来反爬
- 反爬原理:js实现页面跳转,无法在源码中获取下一页url
- 解决方法: 多次抓包获取条状url,分析规律
通过陷阱获取爬虫ip(或者代理ip),进行反爬
- 反爬原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户
- 解决方法: 完成爬虫的编写之后,使用代理批量爬取测试/仔细分析响应内容结构,找出页面中存在的陷阱
通过假数据反爬(投毒)
- 反爬原理:向返回的响应中添加假数据污染数据库,通常不会被正常用户看到
- 解决方法: 长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容
阻塞任务队列
- 反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率
- 解决方法: 观察运行过程中请求响应状态/仔细分析源码获取垃圾url生成规则,对URL进行过滤
阻塞网络IO
- 反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络io,如果是有多线程则会占用线程
- 解决方法: 观察爬虫运行状态/多线程对请求线程计时
运维平台综合审计
- 反爬原理:通过运维平台进行综合管理,通常采用复合型反爬虫策略,多种手段同时使用
- 解决方法: 仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理
常见基于数据加密进行反爬
对响应中含有的数据进行特殊化处理
通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等
通过自定义字体来反爬 下图来自猫眼电影电脑版
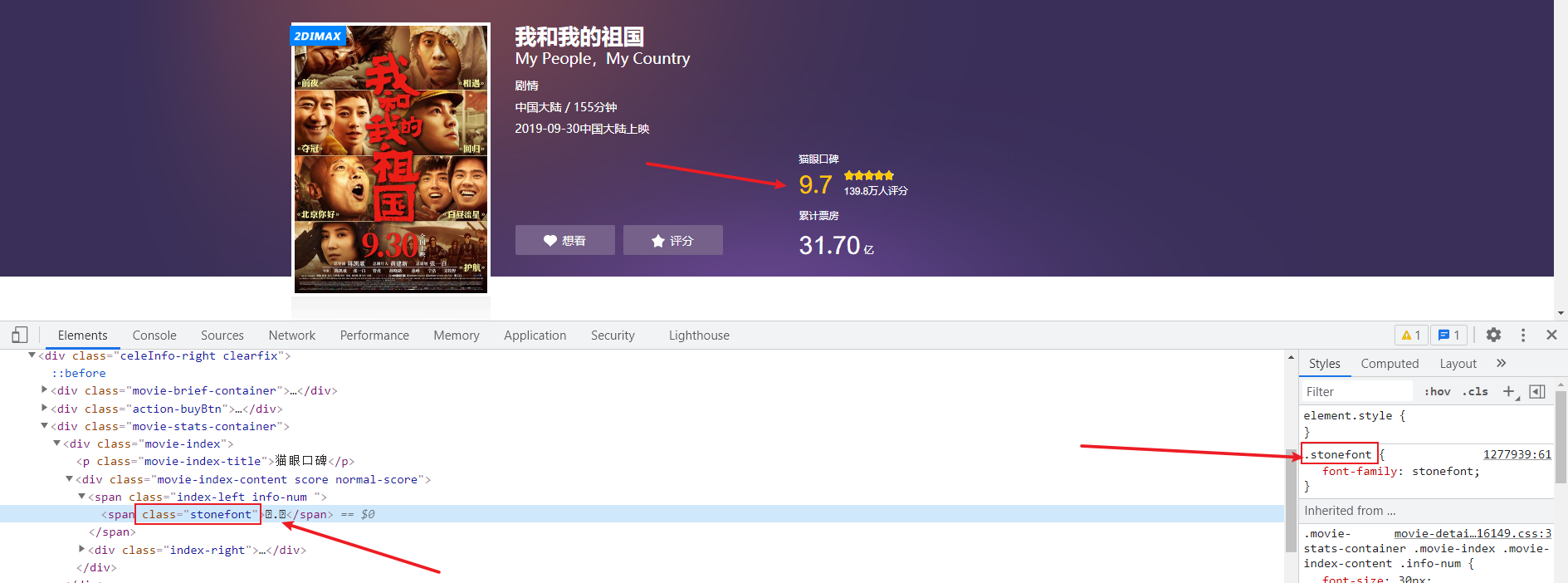
- 反爬思路: 使用自有字体文件
- 解决思路:切换到手机版/解析字体文件进行翻译
通过css来反爬 去哪儿电脑版
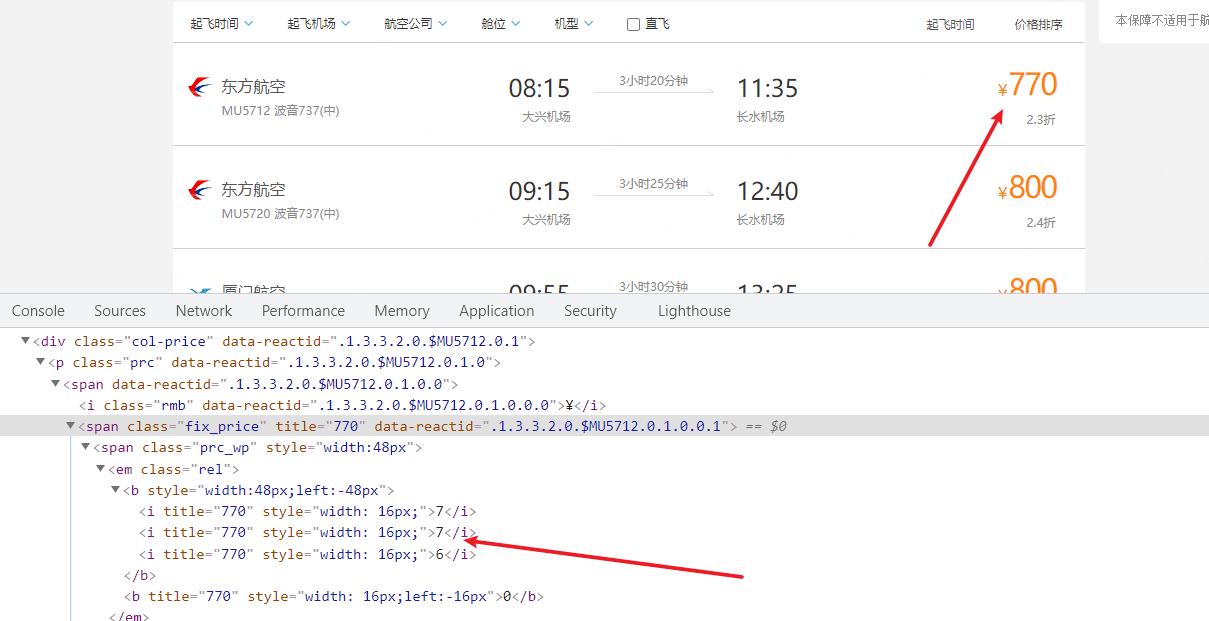
- 反爬思路:源码数据不为真正数据,需要通过css位移才能产生真正数据
- 解决思路:计算css的偏移
通过js动态生成数据进行反爬
- 反爬原理:通过js动态生成
- 解决思路:解析关键js,获得数据生成流程,模拟生成数据
通过数据图片化反爬
- 解决思路:通过使用图片解析引擎从图片中解析数据
通过编码格式进行反爬
- 反爬原理: 不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错
- 解决思路:根据源码进行多格式解码,或者真正的解码格式
Splash介绍

Splash是一个JavaScript渲染服务,是一个带有HTTP API的轻量级浏览器,同时它对接了Python中的Twisted和QT库。利用它,我们同样可以实现动态渲染页面的抓取。
文档地址: 文档http://splash.readthedocs.io/en/stable/
安装
使用docker安装
注意
一定要开启了docker服务后才可使用如下命令
拉取镜像
docker pull scrapinghub/splash
运行scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash
查看效果
我们在8050端口上运行了Splash服务,打开http://localhost:8050/即可看到其Web页面
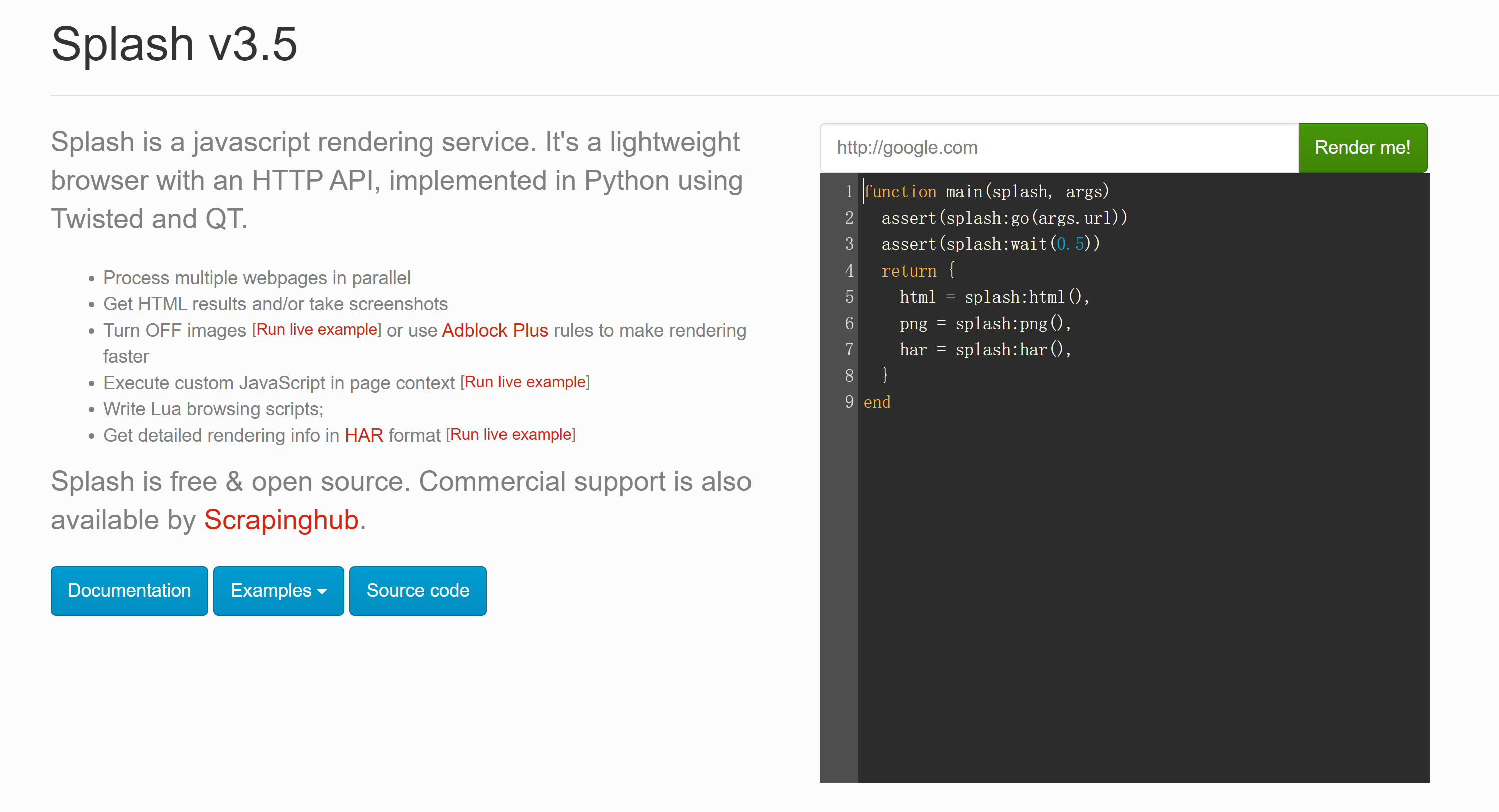
Splash的基本使用

Splash对象属性
上图中main()方法的第一个参数是splash,这个对象非常重要,它类似于Selenium中的WebDriver对象
scroll_position
控制页面上下或左右滚动
splash.scroll_position = {x=100, y=200}
Splash对象的方法
go()
该方法用来请求某个链接,而且它可以模拟GET和POST请求,同时支持传入请求头、表单等数据
ok, reason = splash:go{url, baseurl=nil, headers=nil, http_method="GET", body=nil, formdata=nil}
返回结果是结果ok和原因reason
如果ok为空,代表网页加载出现了错误,此时reason变量中包含了错误的原因
| 参数 | 含义 |
|---|---|
| url | 请求的URL |
| baseurl | 可选参数,默认为空,表示资源加载相对路径 |
| headers | 可选参数,默认为空,表示请求头 |
| http_method | 可选参数,默认为GET,同时支持POST |
| body | 可选参数,默认为空,发POST请求时的表单数据,使用的Content-type为application/json |
| formdata | 可选参数,默认为空,POST的时候的表单数据,使用的Content-type为application/x-www-form-urlencoded |
splash:go{"http://www.sxt.cn", http_method="POST", body="name=17703181473"}
wait()
控制页面的等待时间
splash:wait{time, cancel_on_redirect=false, cancel_on_error=true}
| 参数 | 含义 |
|---|---|
| time | 等待的秒数 |
| cancel_on_redirect | 可选参数,默认为false,表示如果发生了重定向就停止等待,并返回重定向结果 |
| cancel_on_error | 可选参数,默认为false,表示如果发生了加载错误,就停止等待 |
function main(splash)splash:go("https://www.taobao.com")splash:wait(2)return {html=splash:html()}
end
jsfunc()
直接调用JavaScript定义的方法,但是所调用的方法需要用双中括号包围,这相当于实现了JavaScript方法到Lua脚本的转换
function main(splash, args)splash:go("http://www.sxt.cn")local scroll_to = splash:jsfunc("window.scrollTo")scroll_to(0, 300)return {png=splash:png()}
end
function main(splash, args)local get_div_count = splash:jsfunc([[function () {var divs = document.getElementsByClassName("course_p")[0].innerHTML;return divs;}]])splash:go(args.url)return get_div_count()
end
evaljs()与 runjs()
- evaljs() 以执行JavaScript代码并返回最后一条JavaScript语句的返回结果
- runjs() 以执行JavaScript代码,它与evaljs()的功能类似,但是更偏向于执行某些动作或声明某些方法
function main(splash, args)splash:runjs("foo = function() { return 'sxt' }")local result = splash:evaljs("foo()")return result
end
html()
获取网页的源代码
function main(splash, args)splash:go("https://www.bjsxt.com")return splash:html()
end
png()
获取PNG格式的网页截图
function main(splash, args)splash:go("https://www.bjsxt.com")return splash:png()
end
har()
获取页面加载过程描述
function main(splash, args)splash:go("https://www.bjsxt.com")return splash:har()
end
url()
获取当前正在访问的URL
function main(splash, args)splash:go("https://www.bjsxt.com")return splash:url()
end
get_cookies()
获取当前页面的Cookies
function main(splash, args)splash:go("https://www.bjsxt.com")return splash:get_cookies()
end
add_cookie()
当前页面添加Cookie
cookies = splash:add_cookie{name, value, path=nil, domain=nil, expires=nil, httpOnly=nil, secure=nil}function main(splash)splash:add_cookie{"sessionid", "123456abcdef", "/", domain="http://bjsxt.com"}splash:go("http://bjsxt.com/")return splash:html()
end
set_user_agent()
设置浏览器的User-Agent
function main(splash)splash:set_user_agent('Splash')splash:go("http://httpbin.org/get")return splash:html()
end
set_custom_headers()
设置请求头
function main(splash)splash:set_custom_headers({["User-Agent"] = "Splash",["Site"] = "Splash",})splash:go("http://httpbin.org/get")return splash:html()
end
select()
选中符合条件的第一个节点
如果有多个节点符合条件,则只会返回一个
其参数是CSS选择器
function main(splash)splash:go("https://www.baidu.com/")input = splash:select("#kw")splash:wait(3)return splash:png()
end
send_text()
填写文本
function main(splash)splash:go("https://www.baidu.com/")input = splash:select("#kw")input:send_text('Splash')splash:wait(3)return splash:png()
end
mouse_click()
模拟鼠标点击操作
function main(splash)splash:go("https://www.baidu.com/")input = splash:select("#kw")input:send_text('Splash')submit = splash:select('#su')submit:mouse_click()splash:wait(3)return splash:png()
end
代理Ip
function main(splash)splash:on_request(function(request)request:set_proxy{host='61.138.33.20',port=808,username='uanme',password='passwrod'}end)-- 设置请求头splash:set_user_agent("Mozilla/5.0")splash:go("https://httpbin.org/get")return splash:html()
end