python爬虫scrapy框架使用
Scrapy的介绍
目录
Scrapy的介绍
Scrapy的优势
Scrapy的架构
安装
Scarpy开发第一个爬虫
创建第一个项目
文件说明
创建第一个爬虫
爬虫包含的内容
Scrapy项目的启动介绍
Scrapy启动-命令启动
scrapy命令
方法1
方法2
Scrapy输出日志-了解
Scrapy 数据的提取
获得选择器
Response对象获取
创建对象
选择器的方法
Scrapy Shell的使用
Scrapy 保存数据到文件
Item Pipeline的使用
特点
功能
案例代码
Scrapy 使用ImagePipeline 保存图片
使用图片管道
Scrapy 自定义ImagePipeline
自定义图片管道
代码
Scrapy 中settings配置 的使用
配置文档
Scrapy默认BASE设置
Scrapy 保存数据案例-小说保存
Scrapy 中 CrawlSpider 使用
创建CrawlSpider
使用CrawlSpider中核心的2个类对象
Rule对象
LinkExtractors
作用
使用
查看效果-shell中验证
查看效果 CrawlSpider版本
Scrapy 中 Request 的使用
Request对象
将附加数据传递给回调函数
Scrapy 中 FormRequest 的使用
请求使用示例
响应对象
Scrapy中下载中间件
process_request(self, request, spider)
process_response(self, request, response, spider)
Scrapy 中 Downloader 设置UA
开发UserAgent下载中间件
三方模块
Scrapy 中 Downloader 设置代理
爬虫代理原理
代码
下载中间件实战-Scrapy与Selenium结合
MongoDB介绍
MongoDB简介
MongoDB的适用场景
MongoDB的行业具体应用
如何抉择是否使用MongoDB
快速学习方法-与关系型数据库比较
什么是BSON
Windows安装与启动MongoDB
下载
启动MongoDB
通过命令启动
脚本
MongoDB通过配置文件管理参数
建立配置文件
启动方式
脚本
Linux安装MongoDB
环境
下载依赖与安装包
解压安装
配置环境变量
创建数据存放目录
开启服务
配置文件
MongoDB GUI管理工具
独立软件GUI软件
Robo 3T使用
VSCode集成GUI插件
Docker 安装 MongoDB
MongoDB基础命令
查看数据库
切换数据库/创建数据库
删除当前数据库
创建集合
查看集合
删除集合
数据的增加
样例
数据的更新
举例
删除文档
样例
数据的查询
运算符
模糊匹配
自定义查询
limit
skip
sort
count
$exists
dictinct
样例数据
聚合操作之分组、过滤
管道命令之$group
按照某个字段进行分组
常用表达式
管道命令之$match
聚合操作之排序、分页
管道命令之$sort
管道命令之$skip 和 $limit
管道命令之$project
MongoDB索引Index
索引概述
创建索引
样例
索引的查看
索引的查看
样例
检测索引的速度优势
Mongo中唯一索引\复合索引
唯一索引
添加唯一索引的语法c
利用唯一索引进行数据去重
复合索引
建立索引注意点
mongodb和python交互
安装环境
使用样例
引入包pymongo
连接,创建客户端
获得数据库test1
获得集合movie
添加数据
查找数据
获取文档个数
排序
偏移/分页
删除
Scrapy保存数据到多个数据库
代码
Scrapy案例
爬虫的分布式思维与实现思路
分布式爬虫的实现
scrapy-redis框架的安装
爬虫分布式-搭建Main端Redis
安装Redis
开启redis服务
爬虫分布式-搭建Slave端环境配置
Python环境
下载 Python3
安装
安装scrapy
安装scrapy的环境
安装scrapy
安装 scrapy-redis
安装 scrapy-fake-useragent
爬虫分布式-代码的改写1
修改setting
运行代码
爬虫分布式-代码的改写2
修改setting
修改Spider类
运行代码
爬虫分布式-代码的改写3
修改setting
修改Spider类
运行代码
爬虫分布式-代码Slave端运行
Redis数据导出到Mongo中
思路
安装redis模块
代码

Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序,如数据挖掘、信息处理或历史存档。
尽管 Scrapy 最初是为网络抓取而设计的,但它也可用于使用 API提取数据或用作通用网络爬虫。
Scrapy的优势
- 可以容易构建大规模的爬虫项目
- 内置re、xpath、css选择器
- 可以自动调整爬行速度
- 开源和免费的网络爬虫框架
- 可以快速导出数据文件: JSON,CSV和XML
- 可以自动方式从网页中提取数据(自己编写规则)
- Scrapy很容易扩展,快速和功能强大
- 这是一个跨平台应用程序框架(在Windows,Linux,Mac OS)
- Scrapy请求调度和异步处理
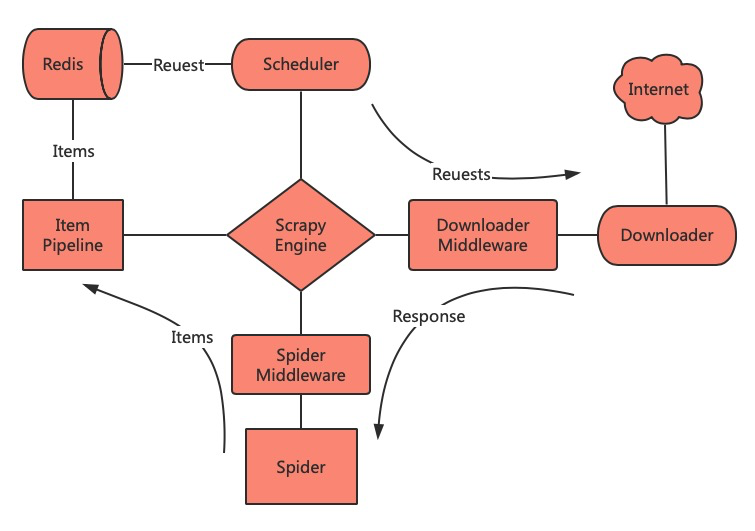
Scrapy的架构
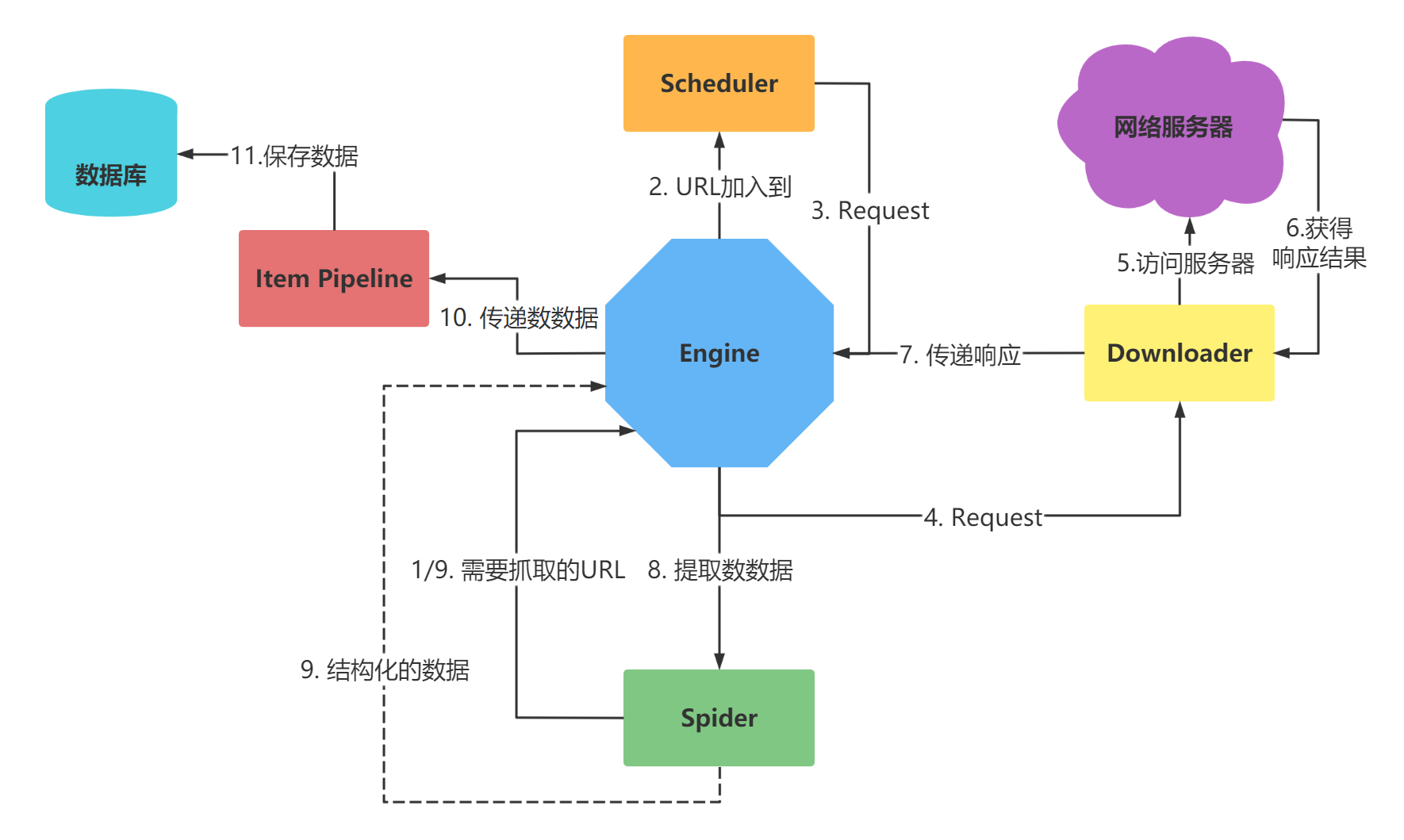
最简单的单个网页爬取流程是 spiders > scheduler > downloader > spiders > item pipeline
省略了engine环节!
-
引擎(engine)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
-
调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
-
下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
-
爬虫(Spiders)
- 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
-
项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
-
下载器中间件(Downloader Middlewares)
- 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应
-
爬虫中间件(Spider Middlewares)
- 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出
-
调度中间件(Scheduler Middewares)
- 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
安装
pip install scrapy
注意
- 企业也追求更稳定的不追求最新,而且我们的主要目的是做项目写代码
- 没必要因为环境版本问题出bug浪费太多时间
Scarpy开发第一个爬虫

创建第一个项目
scrapy startproject myfrist(project_name)
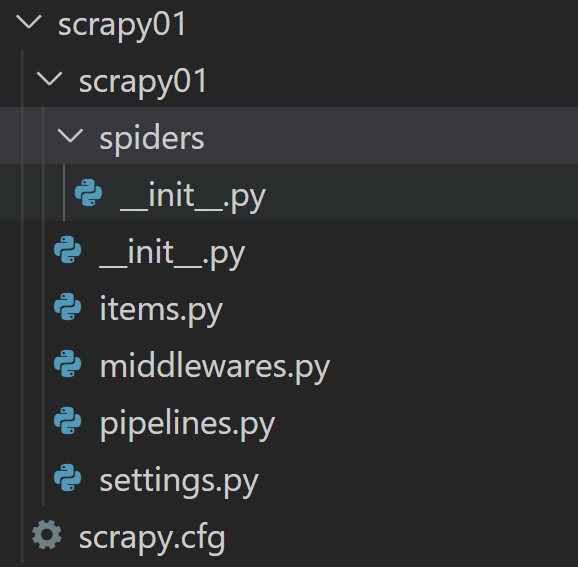
文件说明
| 名称 | 作用 |
|---|---|
| scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) |
| items.py | 设置数据存储模板,用于结构化数据,如:Django的Model |
| pipelines | 数据处理行为,如:一般结构化的数据持久化 |
| settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 |
| spiders | 爬虫目录,如:创建文件,编写爬虫规则 |
创建第一个爬虫
scrapy genspider 爬虫名 爬虫的地址
注意
一般创建爬虫文件时,以网站域名命名
爬虫包含的内容
- name: 它定义了蜘蛛的唯一名称
- allowed_domains: 它包含了蜘蛛抓取的基本URL;
- start-urls: 蜘蛛开始爬行的URL列表;
- parse(): 这是提取并解析刮下数据的方法;
代码
import scrapyclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = 'douban.com'start_urls = ['https://movie.douban.com/top250/']def parse(self, response):movie_name = response.xpath("//div[@class='item']//a/span[1]/text()").extract()movie_core = response.xpath("//div[@class='star']/span[2]/text()").extract()yield {'movie_name':movie_name,'movie_core':movie_core}
Scrapy项目的启动介绍

Scrapy启动的方式有多种方式:
-
Scrapy命令运行
-
运行环境
- 命令行:cmd/powershell/等等
-
-
运行Python脚本
-
运行环境
- 命令行:cmd/powershell/等等
- 编辑器:VSCode/PyCharm等等
-
注意
运行程序之前,要确认网站是否允许爬取
robots.txt文件
Scrapy启动-命令启动

scrapy命令
scrapy框架提供了对项目的命令scrapy ,具体启动项目命令格式如下:
方法1
scrapy crawl 爬虫名
注意
这的爬虫名是爬虫文件中name属性的值
问题
命令无法启动
解决方案
切换到项目目录中,运行即可

方法2
scrapy runspider spider_file.py
注意
- 这是爬虫文件的名字
- 要指定到spider文件夹
Scrapy输出日志-了解

启动Scrapy时,默认会输出日志,内容如下(做为参考):
2030-07-13 16:45:19 [scrapy.utils.log] INFO: Scrapy 2.6.1 started (bot: scrapy02)
2030-07-13 16:45:19 [scrapy.utils.log] INFO: Versions: lxml 4.8.0.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 22.4.0, Python 3.10.2 (tags/v3.10.2:a58ebcc, Jan 17 2022, 14:12:15) [MSC v.1929 64 bit (AMD64)], pyOpenSSL 22.0.0 (OpenSSL 3.0.4 21 Jun 2022), cryptography 37.0.3, Platform Windows-10-10.0.22000-SP0
2030-07-13 16:45:19 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scrapy02','NEWSPIDER_MODULE': 'scrapy02.spiders','SPIDER_MODULES': ['scrapy02.spiders']}
2030-07-13 16:45:19 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2030-07-13 16:45:19 [scrapy.extensions.telnet] INFO: Telnet Password: a7b76850d59e14d0
2030-07-13 16:45:20 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats','scrapy.extensions.telnet.TelnetConsole','scrapy.extensions.logstats.LogStats']
2030-07-13 16:45:20 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware','scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware','scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware','scrapy.downloadermiddlewares.useragent.UserAgentMiddleware','scrapy.downloadermiddlewares.retry.RetryMiddleware','scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware','scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware','scrapy.downloadermiddlewares.redirect.RedirectMiddleware','scrapy.downloadermiddlewares.cookies.CookiesMiddleware','scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware','scrapy.downloadermiddlewares.stats.DownloaderStats']
2030-07-13 16:45:20 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware','scrapy.spidermiddlewares.offsite.OffsiteMiddleware','scrapy.spidermiddlewares.referer.RefererMiddleware','scrapy.spidermiddlewares.urllength.UrlLengthMiddleware','scrapy.spidermiddlewares.depth.DepthMiddleware']
2030-07-13 16:45:20 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2030-07-13 16:45:20 [scrapy.core.engine] INFO: Spider opened
2030-07-13 16:45:20 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2030-07-13 16:45:20 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2030-07-13 16:45:24 [filelock] DEBUG: Attempting to acquire lock 1733280163264 on D:\python_env\spider2_env\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG: Lock 1733280163264 acquired on D:\python_env\spider2_env\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG: Attempting to release lock 1733280163264 on D:\python_env\spider2_env\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG: Lock 1733280163264 released on D:\python_env\spider2_env\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2030-07-13 16:45:24 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/> (referer: None)
1111111111111111111111111111111111111111111111
2030-07-13 16:45:24 [scrapy.core.engine] INFO: Closing spider (finished)
2030-07-13 16:45:24 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 213,'downloader/request_count': 1,'downloader/request_method_count/GET': 1,'downloader/response_bytes': 1476,'downloader/response_count': 1,'downloader/response_status_count/200': 1,'elapsed_time_seconds': 4.716963,'finish_reason': 'finished','finish_time': datetime.datetime(2030, 7, 13, 8, 45, 24, 923094),'httpcompression/response_bytes': 2381,'httpcompression/response_count': 1,'log_count/DEBUG': 6,'log_count/INFO': 10,'response_received_count': 1,'scheduler/dequeued': 1,'scheduler/dequeued/memory': 1,'scheduler/enqueued': 1,'scheduler/enqueued/memory': 1,'start_time': datetime.datetime(2030, 7, 13, 8, 45, 20, 206131)}
2030-07-13 16:45:24 [scrapy.core.engine] INFO: Spider closed (finished)
-
启动爬虫
-
使用的模块与版本
-
加载配置文件
-
打开下载中间件
-
打开中间件
-
打开管道
-
爬虫开启
-
打印统计
Scrapy 数据的提取

Scrapy有自己的数据提取机制。它们被称为选择器。我们可以通过使用的选择器re、xpath、css提取数据
提示
不用再安装与引入Xpath,BS4
获得选择器
Response对象获取
正常使用
response.selector.xpath('//span/text()').get()
response.selector.css('span::text').get()
response.selector.re('<span>')
快捷使用
response.xpath('//span/text').get()
response.css('span::text').get()
创建对象
from scrapy.selector import Selector
通过text参数 初始化
body = '<html><body><span>good</span></body></html>'
Selector(text=body).xpath('//span/text()').get()
通过response参数 初始化
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
response = HtmlResponse(url='http://example.com', body=body)
Selector(response=response).xpath('//span/text()').get()
'good'
选择器的方法
| S.N. | 方法 & 描述 |
|---|---|
| extract()、getall() | 它返回一个unicode字符串以及所选数据 |
| extract_first()、get() | 它返回第一个unicode字符串以及所选数据 |
| re() | 它返回Unicode字符串列表,当正则表达式被赋予作为参数时提取 |
| xpath() | 它返回选择器列表,它代表由指定XPath表达式参数选择的节点 |
| css() | 它返回选择器列表,它代表由指定CSS表达式作为参数所选择的节点 |
Scrapy Shell的使用

Scrapy Shell是一个交互式shell,可以在不运行spider项目时,快速调试 scrapy 代码。
提示
一般用于测试xpath或css表达式,查看它们是否能提取想要的数据
注意
当从命令行运行Scrapy Shell时,记住总是用引号括住url,否则url包含参数(即
&字符)不起作用。在Windows上,使用双引号:
scrapy shell "https://scrapy.org"
Scrapy 保存数据到文件

-
用Python原生方式保存
with open("movie.txt", 'wb') as f:for n, c in zip(movie_name, movie_core):str = n+":"+c+"\n"f.write(str.encode())
2.使用Scrapy内置方式
scrapy 内置主要有四种:JSON,JSON lines,CSV,XML
最常用的导出结果格为JSON,命令如下:
scrapy crawl dmoz -o douban.json -t json
-
参数设置:
-
-o 后面导出文件名
-
-t 后面导出的类型
可以省略,但要保存的文件名后缀,写清楚类型
-
注意
将数据解析完,返回数据,才可以用命令保存,代码如下,格式为dict或item类型
- return data
- yield data
Item Pipeline的使用

当数据在Spider中被收集之后,可以传递到Item Pipeline中统一进行处理
特点
每个item pipeline就是一个普通的python类,包含的方法名如下:
| 方法名 | 含义 | 是否必须实现 |
|---|---|---|
| process_item(self,item,spider) | 用于处理接收到的item | 是 |
| open_spider(self,spider) | 表示当spider被开启的时候调用这个方法 | 否 |
| close_spider(self,spider) | 当spider关闭时候这个方法被调用 | 否 |
功能
-
接收item
在
process_item方法中保存 -
是否要保存数据
取决于是否编写代码用于保存数据
-
决定此Item是否进入下一个pipeline
- return item 数据进入下一个pipeline
- drop item 抛弃数据
案例代码
class SaveFilePipeline:def open_spider(self,spider):self.file = open('douban5.txt','w')def process_item(self, item, spider):self.file.write(f'name:{item.get("name")} score:{item.get("score")}\n')def close_spider(self,spider):self.file.close()
from scrapy.exceptions import DropItem
class XSPipeline:def open_spider(self,spider):self.file = open('xs.txt','w',encoding='utf-8')def process_item(self, item, spider):if item.get('title'):self.file.write(item.get('title'))self.file.write('\n')return itemelse:raise DropItem(f"Missing title in {item}")def close_spider(self,spider):self.file.close()
Scrapy 使用ImagePipeline 保存图片

Scrapy提供了一个 ImagePipeline,用来下载图片这条管道,图片管道ImagesPipeline 提供了方便并具有额外特性的功能,比如:
- 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
- 避免重新下载最近已经下载过的图片
- 缩略图生成
- 检测图像的宽/高,确保它们满足最小限制
使用图片管道
scrapy.pipelines.images.ImagesPipeline
使用 ImagesPipeline ,典型的工作流程如下所示:
- 在一个爬虫中,把图片的URL放入
image_urls组内(image_urls是个列表) - URL从爬虫内返回,进入图片管道
- 当图片对象进入 ImagesPipeline,image_urls 组内的URLs将被Scrapy的调度器和下载器安排下载
- settings.py文件中配置保存图片路径参数
IMAGES_STORE - 开启管道
注意
需要安装pillow4.0.0以上版本
pip install pillow==9.2.0
问题
报错:twisted.python.failure.Failure OpenSSL.SSL.Error
解决方案
pip uninstall cryptography pip install cryptography==36.0.2
Scrapy 自定义ImagePipeline

问题
使用官方默认图片管道,有如下几个问题:
- 文件名不友好
- 存储图片URL的参数名称与类型太固定
解决方案
自定义ImagePipeline,扩展
自定义图片管道
-
继承
scrapy.pipelines.images import ImagesPipeline -
实现
get_media_requests(self, item, info)方法- 发送请求,下载图片
- 转发文件名
-
实现
file_path(self,request,response=None,info=None,*,item=None)- 修改文件名与保存路径
代码
import reclass Scrapy05Pipeline:def process_item(self, item, spider):return itemfrom scrapy.pipelines.images import ImagesPipeline
from scrapy.http.request import Requestclass MyImagePipeline(ImagesPipeline):def get_media_requests(self, item, info):return Request(item['image_url'])def file_path(self, request, response=None, info=None, *, item=None):# 处理文件名中的特殊字符# name = item.get('name').strip().replace('\r\n\t\t','').replace('(','').replace(')','').replace('/','_')name = re.sub('/','_',re.sub('[\s()]','',item.get('name')))return f'{name}.jpg'
Scrapy 中settings配置 的使用

Scrapy允许自定义设置所有Scrapy组件的行为,包括核心、扩展、管道和spider本身。
官网-参考配置
设置 — Scrapy 2.5.0 文档 (osgeo.cn)https://www.osgeo.cn/scrapy/topics/settings.html
配置文档
-
BOT_NAME
默认: 'scrapybot'
Scrapy项目实现的bot的名字。用来构造默认 User-Agent,同时也用来log。 当你使用 startproject 命令创建项目时其也被自动赋值。
-
CONCURRENT_ITEMS
默认: 100
Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值
-
CONCURRENT_REQUESTS
默认: 16
Scrapy downloader 并发请求(concurrent requests)的最大值。
-
CONCURRENT_REQUESTS_PER_DOMAIN
默认: 8
对单个网站进行并发请求的最大值。
-
CONCURRENT_REQUESTS_PER_IP
默认: 0
对单个IP进行并发请求的最大值。如果非0,则忽略 CONCURRENT_REQUESTS_PER_DOMAIN 设定, 使用该设定。 也就是说,并发限制将针对IP,而不是网站。
该设定也影响 DOWNLOAD_DELAY: 如果 CONCURRENT_REQUESTS_PER_IP 非0,下载延迟应用在IP而不是网站上。
-
FEED_EXPORT_ENCODING ='utf-8'
设置导出时文件的编码
-
DEFAULT_REQUEST_HEADERS
默认:
{'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
-
Scrapy HTTP Request使用的默认header。由 DefaultHeadersMiddleware 产生。
-
DOWNLOADER_MIDDLEWARES
默认:: {}
保存项目中启用的下载中间件及其顺序的字典
-
DOWNLOAD_DELAY
默认: 0
下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数
-
DOWNLOAD_TIMEOUT
默认: 180
下载器超时时间(单位: 秒)
-
ITEM_PIPELINES
默认: {}
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意。 不过值(value)习惯设定在0-1000范围内
-
DEPTH_LIMIT
默认:
0类:
scrapy.spidermiddlewares.depth.DepthMiddleware允许为任何站点爬行的最大深度。如果为零,则不会施加任何限制。
-
LOG_ENABLED
默认: True
是否启用logging
-
LOG_ENCODING
默认: 'utf-8'
logging使用的编码。
-
LOG_FILE
默认: None
logging输出的文件名。如果为None,则使用标准错误输出(standard error)。
-
LOG_FORMAT
默认: '%(asctime)s [%(name)s] %(levelname)s: %(message)s'
日志的数据格式
-
LOG_DATEFORMAT
默认: '%Y-%m-%d %H:%M:%S'
日志的日期格式
-
LOG_LEVEL
默认: 'DEBUG'
log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG
-
LOG_STDOUT
默认: False
如果为 True ,进程所有的标准输出(及错误)将会被重定向到log中
-
ROBOTSTXT_OBEY
默认: True
是否遵循robots协议
-
USER_AGENT
默认: "Scrapy/VERSION (+http://scrapy.org)"
爬取的默认User-Agent,除非被覆盖
Scrapy默认BASE设置
scrapy对某些内部组件进行了默认设置,这些组件通常情况下是不能被修改的,但是我们在自定义了某些组件以后,比如我们设置了自定义的middleware中间件,需要按照一定的顺序把他添加到组件之中,这个时候需要参考scrapy的默认设置,因为这个顺序会影响scrapy的执行,下面列出了scrapy的默认基础设置
注意
如果想要修改以下的某些设置,应该避免直接修改下列内容,而是修改其对应的自定义内容
{'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 400,'scrapy.downloadermiddlewares.retry.RetryMiddleware': 500,'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 550,'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware': 830,'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
如果需要关闭下载处理器,为其赋值为 None 即可
提示
有时添加了一些自定义的组件,无法应用到效果,可以从执行顺序方面入手
执行顺序:输值越小,优先级越高
Scrapy 保存数据案例-小说保存

spider
import scrapyclass XiaoshuoSpiderSpider(scrapy.Spider):name = 'xiaoshuo_spider'allowed_domains = ['zy200.com']url = 'http://www.zy200.com/5/5943/'start_urls = [url + '11667352.html']def parse(self, response):info = response.xpath("/html/body/div[@id='content']/text()").extract()href = response.xpath("//div[@class='zfootbar']/a[3]/@href").extract_first()yield {'content':info}if href != 'index.html':new_url = self.url + hrefyield scrapy.Request(new_url, callback=self.parse)
pipeline
class XiaoshuoPipeline(object):def __init__(self):self.filename = open("dp1.txt", "w", encoding="utf-8")def process_item(self, item, spider):content = item["title"] + item["content"] + '\n'self.filename.write(content)self.filename.flush()return itemdef close_spider(self, spider):self.filename.close()
Scrapy 中 CrawlSpider 使用

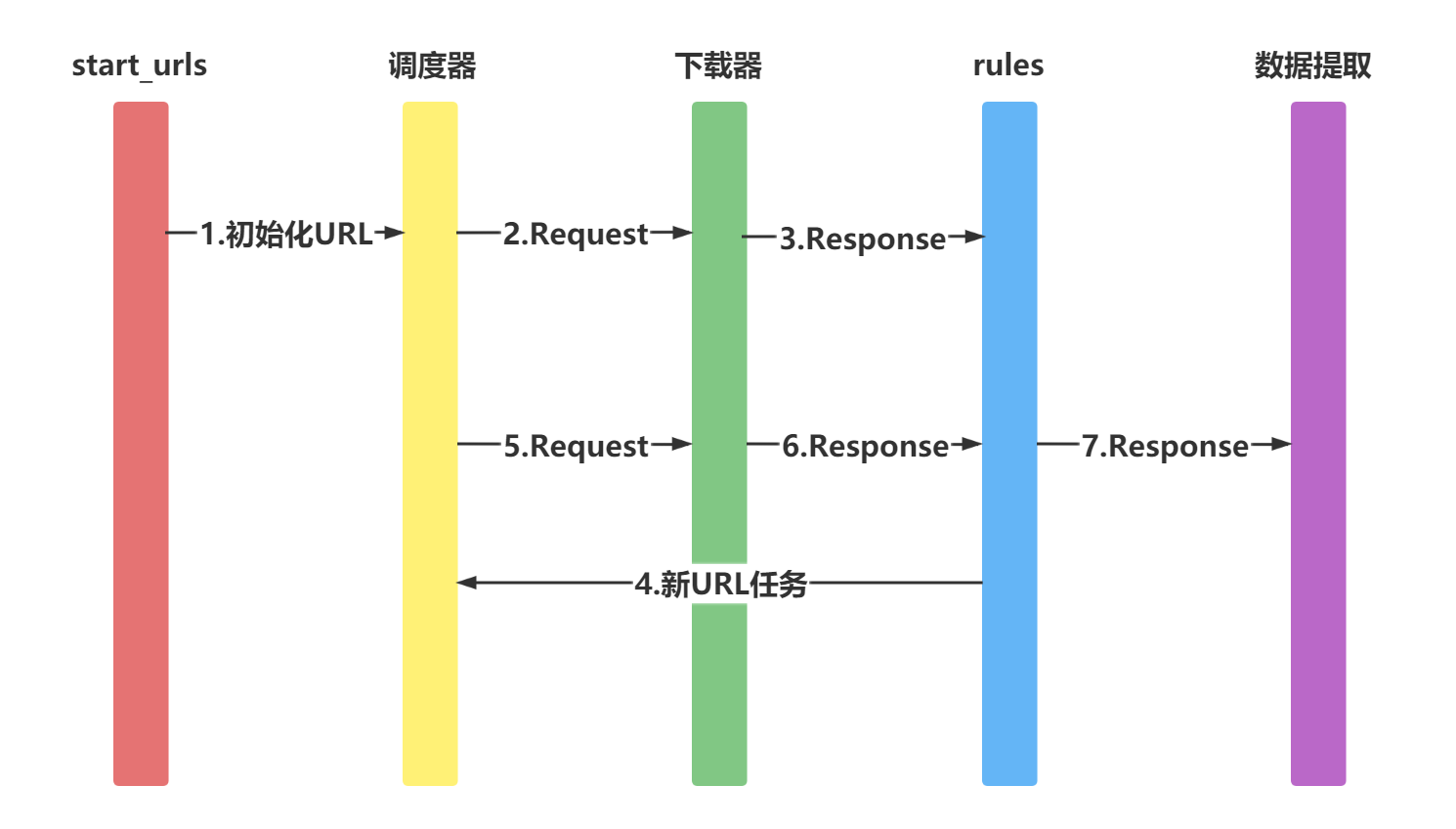
在Scrapy中Spider是所有爬虫的基类,而CrawSpiders就是Spider的派生类。
适用于先爬取start_url列表中的网页,再从爬取的网页中获取link并继续爬取的工作。运行图如下
创建CrawlSpider
scrapy genspider -t crawl 爬虫名 (allowed_url)
使用CrawlSpider中核心的2个类对象
Rule对象
Rule类与CrawlSpider类都位于scrapy.contrib.spiders模块中
class scrapy.contrib.spiders.Rule( link_extractor, callback=None,cb_kwargs=None,follow=None,process_links=None,process_request=None)
参数含义:
-
link_extractor为LinkExtractor,用于定义需要提取的链接
-
callback参数:当link_extractor获取到链接时参数所指定的值作为回调函数
注意 回调函数尽量不要用parse方法,crawlspider已使用了parse方法
-
follow:指定了根据该规则从response提取的链接是否需要跟进。当callback为None,默认值为True
-
process_links:主要用来过滤由link_extractor获取到的链接
-
process_request:主要用来过滤在rule中提取到的request
LinkExtractors
顾名思义,链接提取器
作用
response对象中获取链接,并且该链接会被接下来爬取 每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象
使用
class scrapy.linkextractors.LinkExtractor(allow = (),deny = (),allow_domains = (),deny_domains = (),deny_extensions = None,restrict_xpaths = (),tags = ('a','area'),attrs = ('href'),canonicalize = True,unique = True,process_value = None
)
主要参数:
- allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
- deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
- allow_domains:会被提取的链接的domains。
- deny_domains:一定不会被提取链接的domains。
- restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接(只选到节点,不选到属性)
- restrict_css:使用css表达式,和allow共同作用过滤链接(只选到节点,不选到属性)
查看效果-shell中验证
首先运行
scrapy shell 'https://www.zhhbqg.com/1_1852/835564.html'
继续import相关模块:
from scrapy.linkextractors import LinkExtractor
提取当前网页中获得的链接
link = LinkExtractor(restrict_xpaths=(r'//a'))
调用LinkExtractor实例的extract_links()方法查询匹配结果
link.extract_links(response)
查看效果 CrawlSpider版本
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from xiaoshuo.items import XiaoshuoItemclass XiaoshuoSpiderSpider(CrawlSpider):name = 'xiaoshuo_spider'allowed_domains = ['fhxiaoshuo.com']start_urls = ['http://www.fhxiaoshuo.com/read/33/33539/17829387.shtml']rules = [Rule(LinkExtractor(restrict_xpaths=(r'//div[@class="bottem"]/a[4]')), callback='parse_item'),]def parse_item(self, response):info = response.xpath("//div[@id='TXT']/text()").extract()it = XiaoshuoItem()it['info'] = infoyield it复制
注意
- callback后面函数名用引号引起
- 函数名不要用parse
- 参数的括号嵌套,不要出问题
Scrapy 中 Request 的使用

爬虫中请求与响应是最常见的操作,Request对象在爬虫程序中生成并传递到下载器中,后者执行请求并返回一个Response对象
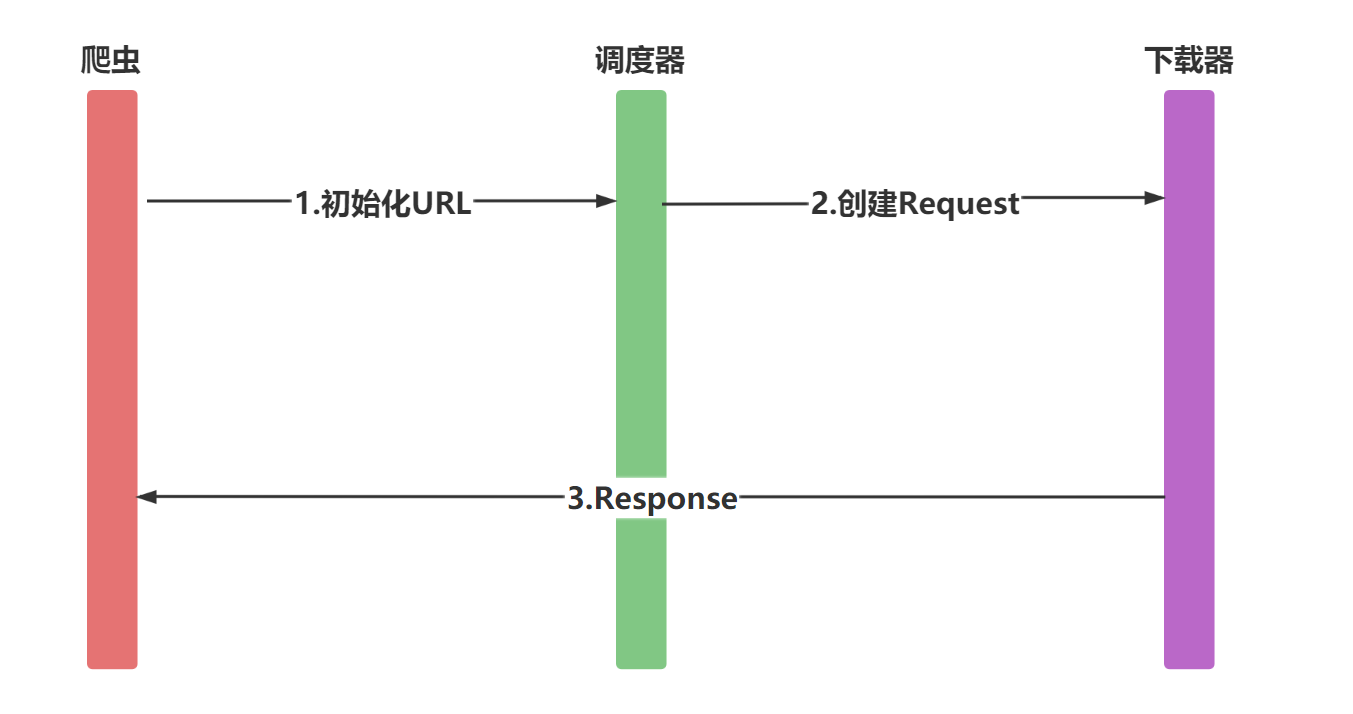
Request对象
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
一个Request对象表示一个HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成Response
-
参数
-
url(string) - 此请求的网址
-
callback(callable) - 将使用此请求的响应(一旦下载)作为其第一个参数调用的函数。有关更多信息,请参阅下面的将附加数据传递给回调函数。如果请求没有指定回调,parse()将使用spider的 方法。请注意,如果在处理期间引发异常,则会调用errback。
-
method(string) - 此请求的HTTP方法。默认为'GET'。可设置为"GET", "POST", "PUT"等,且保证字符串大写
-
meta(dict) - 属性的初始值Request.meta,在不同的请求之间传递数据使用
-
body(str或unicode) - 请求体。如果unicode传递了,那么它被编码为 str使用传递的编码(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个str(不会是unicode或None)。
-
headers(dict) - 这个请求的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None作为值传递,则不会发送HTTP头.一般不需要
-
encoding: 使用默认的 'utf-8' 就行
-
dont_filter:是否过滤重复的URL地址,默认为
False过滤 -
cookie(dict或list) - 请求cookie。这些可以以两种形式发送。
- 使用dict:
-
request_with_cookies = Request(url="http://www.sxt.cn/index/login/login.html",)
- 使用列表:
request_with_cookies = Request(url="http://www.example.com",cookies=[{'name': 'currency','value': 'USD','domain': 'example.com','path': '/currency'}])
后一种形式允许定制 cookie的属性domain和path属性。这只有在保存Cookie用于以后的请求时才有用
request_with_cookies = Request(url="http://www.example.com",cookies={'currency': 'USD', 'country': 'UY'},meta={'dont_merge_cookies': True})
将附加数据传递给回调函数
请求的回调是当下载该请求的响应时将被调用的函数。将使用下载的Response对象作为其第一个参数来调用回调函数
def parse_page1(self, response):item = MyItem()item['main_url'] = response.urlrequest = scrapy.Request("http://www.example.com/some_page.html",callback=self.parse_page2)request.meta['item'] = itemreturn requestdef parse_page2(self, response):item = response.meta['item']item['other_url'] = response.urlreturn item
Scrapy 中 FormRequest 的使用

FormRequest是Request的扩展类,具体常用的功能如下:
-
请求时,携带参数,如表单数据
-
从Response中获取表单的数据
FormRequest类可以携带参数主要原因是:增加了新的构造函数的参数formdata。其余的参数与Request类相同.
- formdata参数类型为:dict
class scrapy.http.FormRequest(url[, formdata, ...])
class method from_response(response[, formname=None, formid=None, formnumber=0, formdata=None, formxpath=None, formcss=None, clickdata=None, dont_click=False, ...])
返回一个新FormRequest对象,其中的表单字段值已预先<form>填充在给定响应中包含的HTML 元素中.
参数:
- response(Responseobject) - 包含将用于预填充表单字段的HTML表单的响应
- formname(string) - 如果给定,将使用name属性设置为此值的形式
- formid(string) - 如果给定,将使用id属性设置为此值的形式
- formxpath(string) - 如果给定,将使用匹配xpath的第一个表单
- formcss(string) - 如果给定,将使用匹配css选择器的第一个形式
- formnumber(integer) - 当响应包含多个表单时要使用的表单的数量。第一个(也是默认)是0
- formdata(dict) - 要在表单数据中覆盖的字段。如果响应元素中已存在字段,则其值将被在此参数中传递的值覆盖
- clickdata(dict) - 查找控件被点击的属性。如果没有提供,表单数据将被提交,模拟第一个可点击元素的点击。除了html属性,控件可以通过其相对于表单中其他提交表输入的基于零的索引,通过nr属性来标识
- dont_click(boolean) - 如果为True,表单数据将在不点击任何元素的情况下提交
请求使用示例
通过HTTP POST发送数据
FormRequest(url="http://www.example.com/post/action",formdata={'name': 'John Doe', 'age': '27'},callback=self.after_post)
通过FormRequest.from_response()发送数据
FormRequest.from_response(response,formdata={'username': 'john', 'password': 'secret'},callback=self.after_login
)
响应对象
class scrapy.http.Response(url[, status=200, headers=None, body=b'', flags=None, request=None])
一个Response对象表示的HTTP响应,这通常是下载器下载后,并供给到爬虫进行处理
参数:
- url(string) - 此响应的URL
- status(integer) - 响应的HTTP状态。默认为200
- headers(dict) - 这个响应的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)
- body(bytes) - 响应体。它必须是str,而不是unicode,除非你使用一个编码感知响应子类,如 TextResponse
- flags(list) - 是一个包含属性初始值的 Response.flags列表。如果给定,列表将被浅复制
- request(Requestobject) - 属性的初始值Response.request。这代表Request生成此响应
- text 获取文本
Scrapy中下载中间件

下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。
通过可下载中间件,可以处理请求之前和请求之后的数据。
每个中间件组件都是一个Python类,它定义了一个或多个以下方法,我们可能需要使用方法如下:
-
process_request()
-
process_response()
process_request(self, request, spider)
当每个request通过下载中间件时,该方法被调用
必须返回以下其中之一
-
返回 None
- Scrapy 将继续处理该 request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该 request 被执行(其 response 被下载)
-
返回一个 Response 对象
- Scrapy 将不会调用 任何 其他的 process_request()或 process_exception()方法,或相应地下载函数; 其将返回该 response。已安装的中间件的 process_response()方法则会在每个 response 返回时被调用
-
返回一个 Request 对象
- Scrapy 则停止调用 process_request 方法并重新调度返回的 request。当新返回的 request 被执行后, 相应地中间件链将会根据下载的 response 被调用
-
raise IgnoreRequest
- 如果抛出 一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则 request 的 errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)
参数:
- request (Request 对象) – 处理的request
- spider (Spider 对象) – 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
process_response()应该是:返回一个 Response对象,则返回一个 Request 对象或引发 IgnoreRequest例外情况。
-
如果它返回
Response(可能是相同的给定响应,也可能是全新的响应),该响应将继续使用process_response()链中的下一个中间件 -
如果它返回一个
Request对象时,中间件链将暂停,返回的请求将重新计划为将来下载。这与从返回请求的行为相同process_request() -
如果它引发了
IgnoreRequest异常,请求的errback函数 (Request.errback)。如果没有代码处理引发的异常,则忽略该异常,不记录该异常(与其他异常不同)。 -
参数
- request (is a
Requestobject) -- 发起响应的请求 - response (
Responseobject) -- 正在处理的响应 - spider (
Spiderobject) -- 此响应所针对的蜘蛛
- request (is a
Scrapy 中 Downloader 设置UA

下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。
通过可下载中间件,可以处理请求之前和请求之后的数据。
如果使用下载中间件需要在Scrapy中的setting.py的配置DOWNLOADER_MIDDLEWARES才可以使用,
比如:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
开发UserAgent下载中间件
问题
每次创建项目后,需要自己复制UserAgent到settings,比较繁琐
解决方案
开发下载中间件,设置UserAgent
代码
from fake_useragent import UserAgentclass MyUserAgentMiddleware:def process_request(self, request, spider):request.headers.setdefault(b'User-Agent', UserAgent().chrome)
三方模块
pip install scrapy-fake-useragent==1.4.4
配置模块到Setting文件
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,'scrapy_fake_useragent.middleware.RetryUserAgentMiddleware': 401,
}
Scrapy 中 Downloader 设置代理

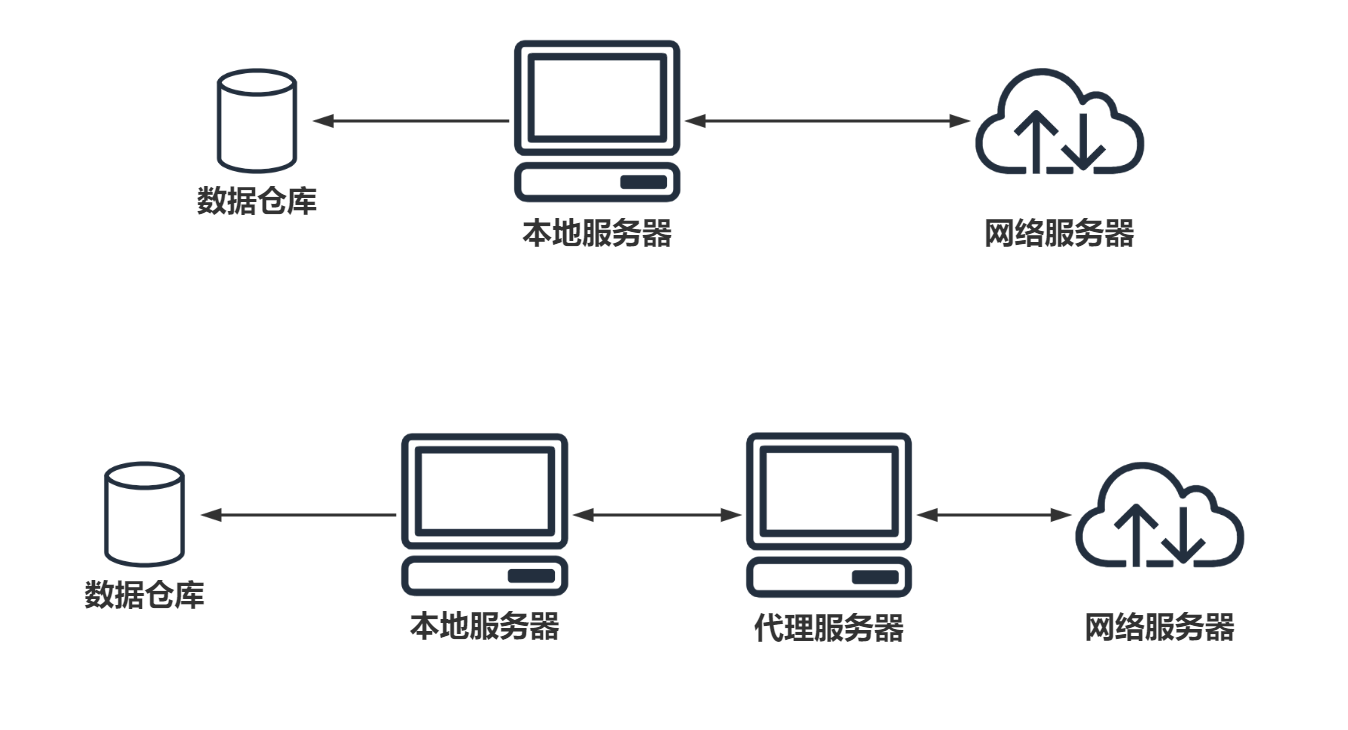
爬虫设置代理就是让别的服务器或电脑代替自己的服务器去获取数据
爬虫代理原理
代码
通过request.meta['proxy']可以设置代理,如下:
class MyProxyDownloaderMiddleware:def process_request(self, request, spider):# request.meta['proxy'] ='http://ip:port'# request.meta['proxy'] ='http://name:pwd@ip:port'request.meta['proxy'] ='http://139.224.211.212:8080'下载中间件实战-Scrapy与Selenium结合

有的页面反爬技术比较高端,一时破解不了,这时我们就是可以考虑使用selenium来降低爬取的难度。
问题来了,如何将Scrapy与Selenium结合使用呢?
思考的思路: 只是用Selenium来帮助下载数据。因此可以考虑通过下载中间件来处理这块内容。
具体代码如下:
Spider文件
@classmethoddef from_crawler(cls, crawler, *args, **kwargs):spider = super(BaiduSpider, cls).from_crawler(crawler, *args, **kwargs)spider.chrome = webdriver.Chrome(executable_path='../tools/chromedriver.exe')crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed) # connect里的参数 # 1. 处罚事件后用哪个函数处理# 2. 捕捉哪个事件return spiderdef spider_closed(self, spider):spider.chrome.close()
middlewares文件
def process_request(self, request, spider): spider.chrome.get(request.url)html = spider.chrome.page_sourcereturn HtmlResponse(url = request.url,body = html,request = request,encoding='utf-8')
MongoDB介绍

MongoDB简介
MongoDB 是免费开源的跨平台 NoSQL 数据库,命名源于英文单词 humongous,意思是「巨大无比」,可见开发组对 MongoDB 的定位。
与关系型数据库不同,MongoDB 的数据以类似于 JSON 格式的二进制文档存储:
{name: "itBaiZhan",age: 18,hobbies: ["python", "mongo"]
}
文档型的数据存储方式有几个重要好处:
- 文档的数据类型可以对应到语言的数据类型,如数组类型(Array)和对象类型(Object)
- 文档可以嵌套,有时关系型数据库涉及几个表的操作,在 MongoDB 中一次就能完成,可以减少昂贵的连接花销;
- 文档不对数据结构加以限制,不同的数据结构可以存储在同一张表
MongoDB的适用场景
-
网站数据
Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性
-
缓存
由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载
-
大尺寸、低价值的数据
使用传统的关系型数据库存储一些大尺寸低价值数据时会比较浪费,在此之前,很多时候程序员往往会选择传统的文件进行存储
-
高伸缩性的场景
Mongo 非常适合由数十或数百台服务器组成的数据库,Mongo 的路线图中已经包含对MapReduce 引擎的内置支持以及集群高可用的解决方案
-
用于对象及JSON 数据的存储
Mongo 的BSON 数据格式非常适合文档化格式的存储及查询
MongoDB的行业具体应用
-
游戏场景
使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新
-
物流场景
使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
-
社交场景
使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
-
物联网场景
使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
-
直播
使用 MongoDB 存储用户信息、礼物信息等
如何抉择是否使用MongoDB
| 应用特征 | Yes/No |
|---|---|
| 应用不需要复杂事务及复杂join支持 | yes |
| 新应用,需求会变,数据模型无法确定,想快速迭代开发 | ? |
| 应用需要2000-3000以上的读写QPS(更高也可以) | ? |
| 应用需要TB甚至 PB 级别数据存储 | ? |
| 应用发展迅速,需要能快速水平扩展 | ? |
| 应用需要大量的地理位置查询、文本查询 | ? |
| 应用需要99.999%高可用 | ? |
有一个yes就可以选择MongoDB,两个以上yes,选MongoDB绝对不后悔
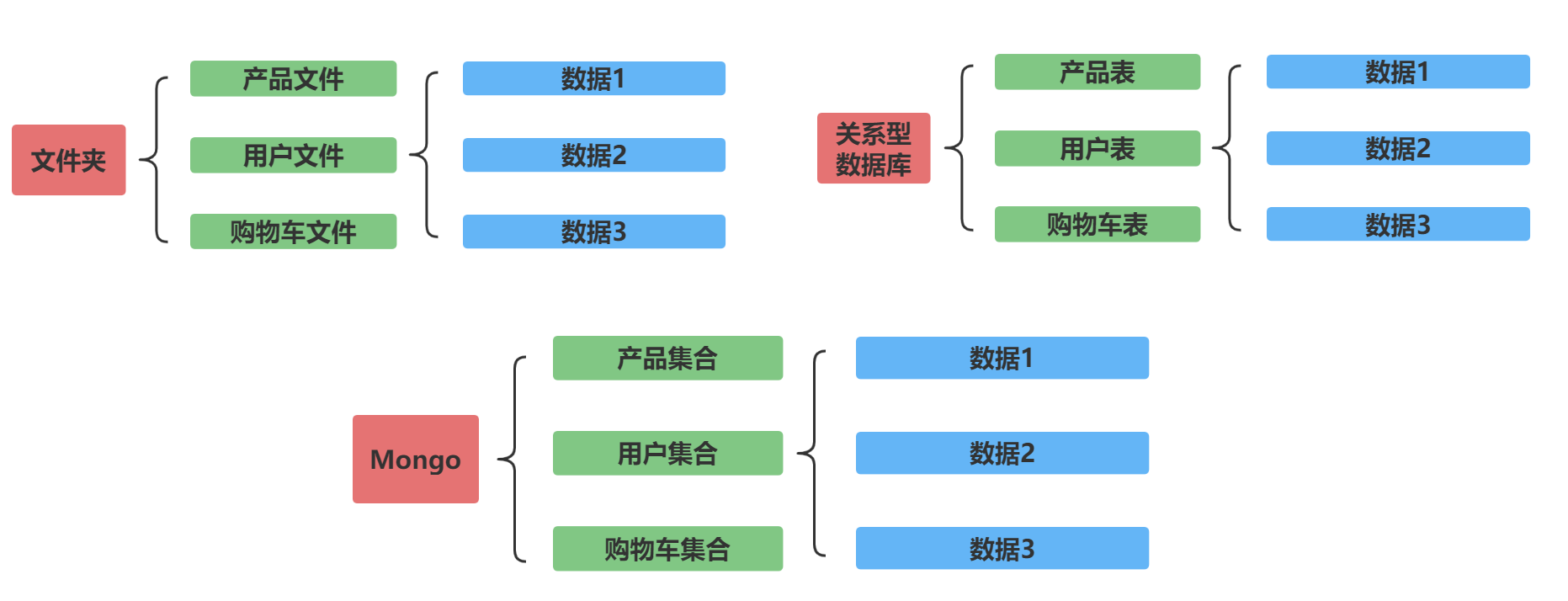
快速学习方法-与关系型数据库比较

MongoDB与RDMS(关系型数据库)比较,如下图所示
| RDMS | MongoDB |
|---|---|
| database(数据库) | database(数据库) |
| table (表) | collection( 集合) |
| row( 行) | document( BSON 文档) |
| column (列) | field (字段) |
| index(唯一索引、主键索引) | index (支持地理位置索引、全文索引 、哈希索引) |
| join (主外键关联) | embedded Document (嵌套文档) |
| primary key(指定1至N个列做主键) | primary key (指定_id field做为主键) |
什么是BSON
BSON是一种类似于JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。BSON有三个特点:轻量性、可遍历性、高效性。
下表列出了MongoDB中Document可以出现的数据类型:
| 数据类型 | 说明 | document举例 |
|---|---|---|
| String | 字符串 | {key:“cba”} |
| Integer | 整型数值 | {key:2} |
| Boolean | 布尔型 | {key:true} |
| Double | 双精度浮点数 | {key:0.23} |
| ObjectId | 对象id,用于创建文档的id | {_id:new ObjectId()} |
| Array | 数组 | {arr:[“jack”,“tom”]} |
| Timestamp | 时间戳 | { createTime: new Timestamp() } |
| object | 内嵌文档 | {student:{name:“zhangsan”,age:18}} |
| null | 空值 | {key:null} |
| Date或者ISODate | 日期时间 | {birthday:new Date()} |
| Code | 代码 | {setPersonInfo:function(){}} |
Windows安装与启动MongoDB

下载
企业版-收费
社区版-免费
下载Mongodb https://www.mongodb.com/try/download/community
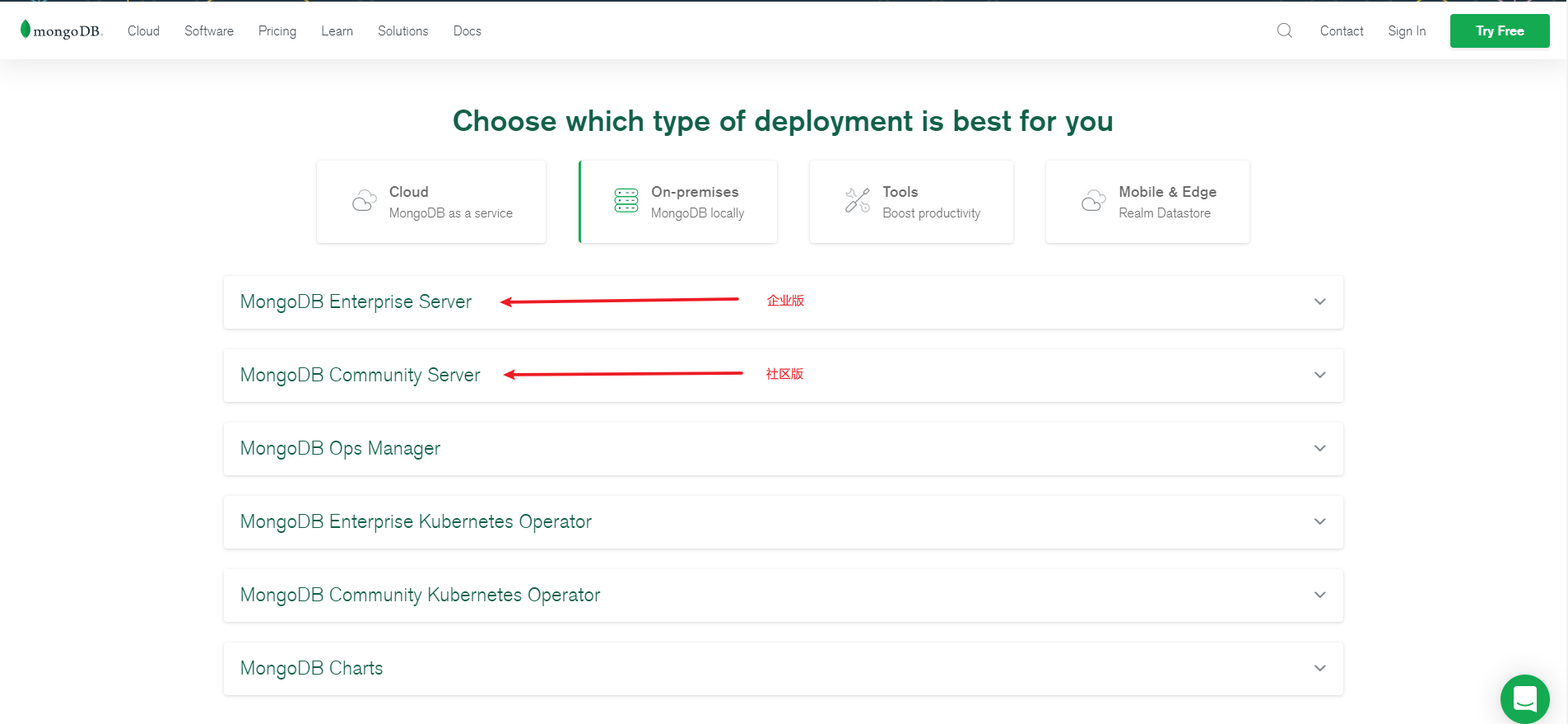
-
选择版本
- 稳定版5.0.9
-
选择平台
- Windows
-
选择安装包类型
- ZIP压缩版

解压即用
启动MongoDB
通过命令启动
mongod.exe --dbpath=path --logpath=path
- dbpath 指定数据存储位置
- logpath 指定日志存储在哪个位置
注意
指定的路径一定要存在
脚本
在创建mongo_home目录下创建start.bat文件输入内容,如下
D:\mongodb5_0_9\bin\mongod.exe --dbpath="d:\mongodb5_0_9\data" --logpath="d:\mongodb5_0_9\log\log.txt"
注意
里面路径改成自己的路径
MongoDB通过配置文件管理参数

问题
启动MongoDB时,编写参数太麻烦
解决方案
通过配置文件统一管理
建立配置文件
在MongoDB家目录创建mongo.conf配置文件,编写内容如下:
#数据库路径
dbpath=D:\Program Files\mongodb-win32-x86_64-windows-4.4.6\db
#日志输出文件路径
logpath=D:\Program Files\mongodb-win32-x86_64-windows-4.4.6\logs\mongo.log
#错误日志采用追加模式
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
bind_ip=0.0.0.0
# 启用权限验证,使用账号密码登录
#auth=true
提示
文件名随便起,不一定是mongo.conf
启动方式
mongod.exe -f 配置文件地址
脚本
D:\mongodb5_0_9\bin\mongod.exe -f d:\mongodb5_0_9\mongo.conf
Linux安装MongoDB

环境
-
Linux: Centos7
-
MongoDB: 5.0.9
- 下载位置官网:https://www.mongodb.com/try/download/community
- https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.9.tgz
下载依赖与安装包
安装所需要工具:
yum install wget -y
yum install vim -y
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.9.tgz
解压安装
tar -zxvf mongodb-linux-x86_64-rhel70-5.0.9.tgz
mv mongodb-linux-x86_64-rhel70-5.0.9 mongodb5
配置环境变量
修改环境变量vim ~/.bash_profile
修改PATH变量
PATH=/opt/mongodb5/bin:$PATH:$HOME/bin
创建数据存放目录
sudo mkdir -p /var/mongo/log
sudo mkdir -p /var/mongo/data
touch /var/mongo/log/mongo.log
开启服务
mongod --dbpath /var/mongo/data --logpath /var/mongo/log/mongo.log --fork
配置文件
通过配置文件开启服务,更加简单。
在Mongo文件夹增加配置文件, 命令如下:
touch /opt/mongodb5/mongo.cfgvim /opt/mongodb5/mongo.cfg- 增加如下内容
#数据库路径
dbpath=/var/mongo/data
#日志输出文件路径
logpath=/var/mongo/log/mongo.log
#错误日志采用追加模式
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
bind_ip=0.0.0.0
port=27017
MongoDB GUI管理工具

MongoDB数据库默认的管理工具是(CLI)Shell命令行,对于专业的DBA来说比较容易上手,但是对于普通人员GUI可视化工具更方便使用。我们来介绍下MongoDB可视化工具。
独立软件GUI软件
目前在网络要有多种图形软件比如:
- Robo 3T 免费
- Navicat for MongoDB 收费
- MongoDB Compass 社区版 免费
- NoSQLBooster(mongobooster) 免费
- NOSQLCLIENT 收费
- Aqua Data Studio Mongo 收费
- 等等
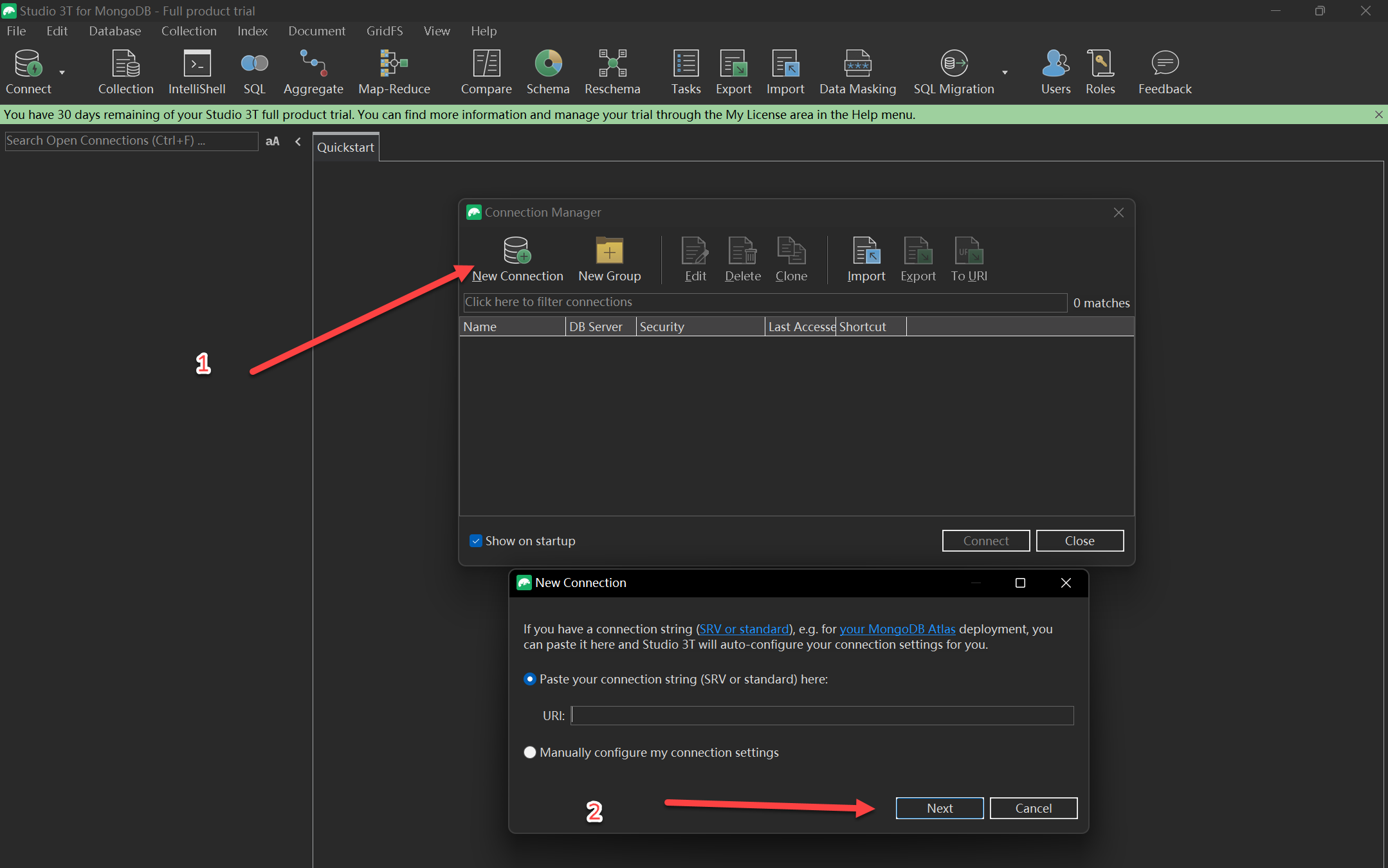
Robo 3T使用
下载:
Download Studio 3T for MongoDB | Windows, macOS & Linux
https://download.studio3t.com/studio-3t/windows/2022.6.1/studio-3t-x64.zip
打开后,选择“New Connection”新建链接 ===> Next
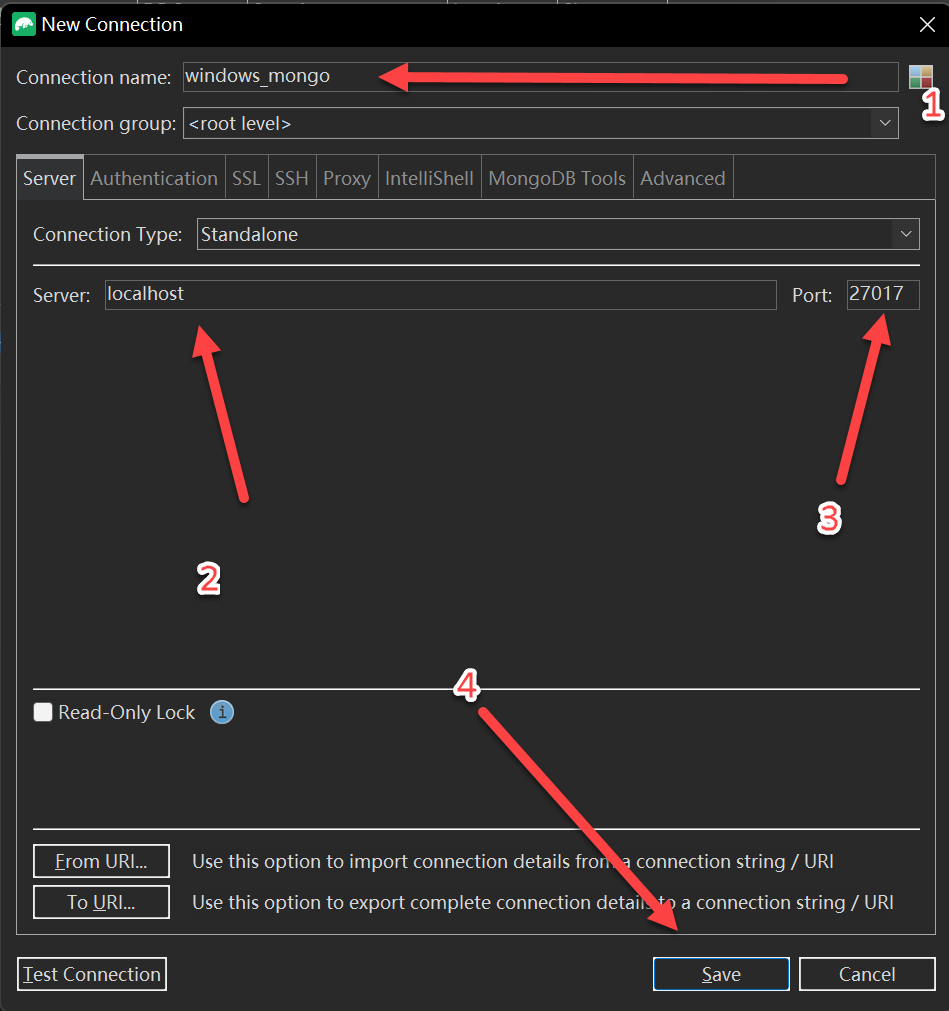
输入“Connection name”链接名 ===> 输入“Server”与“Port”Mongo地址与端口号 ===> Save
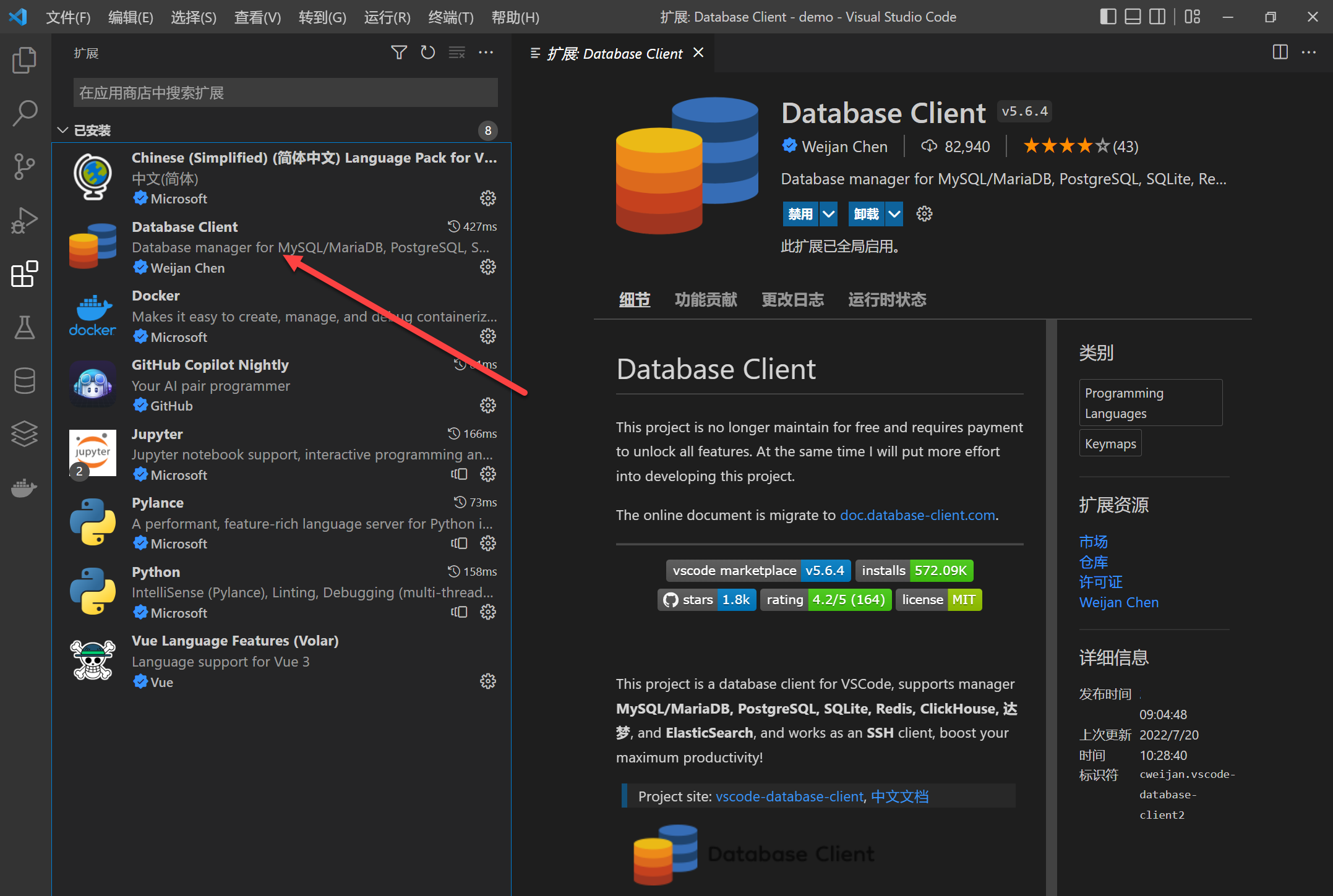
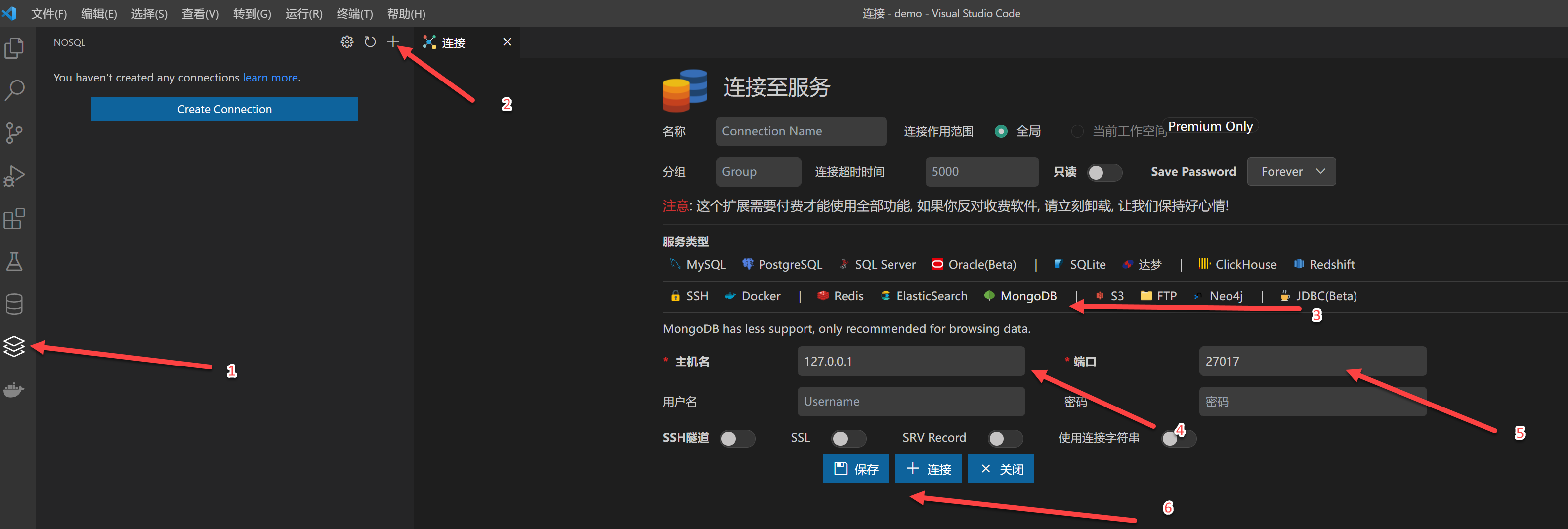
VSCode集成GUI插件
安装插件 ===> Database Client
Docker 安装 MongoDB

Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。
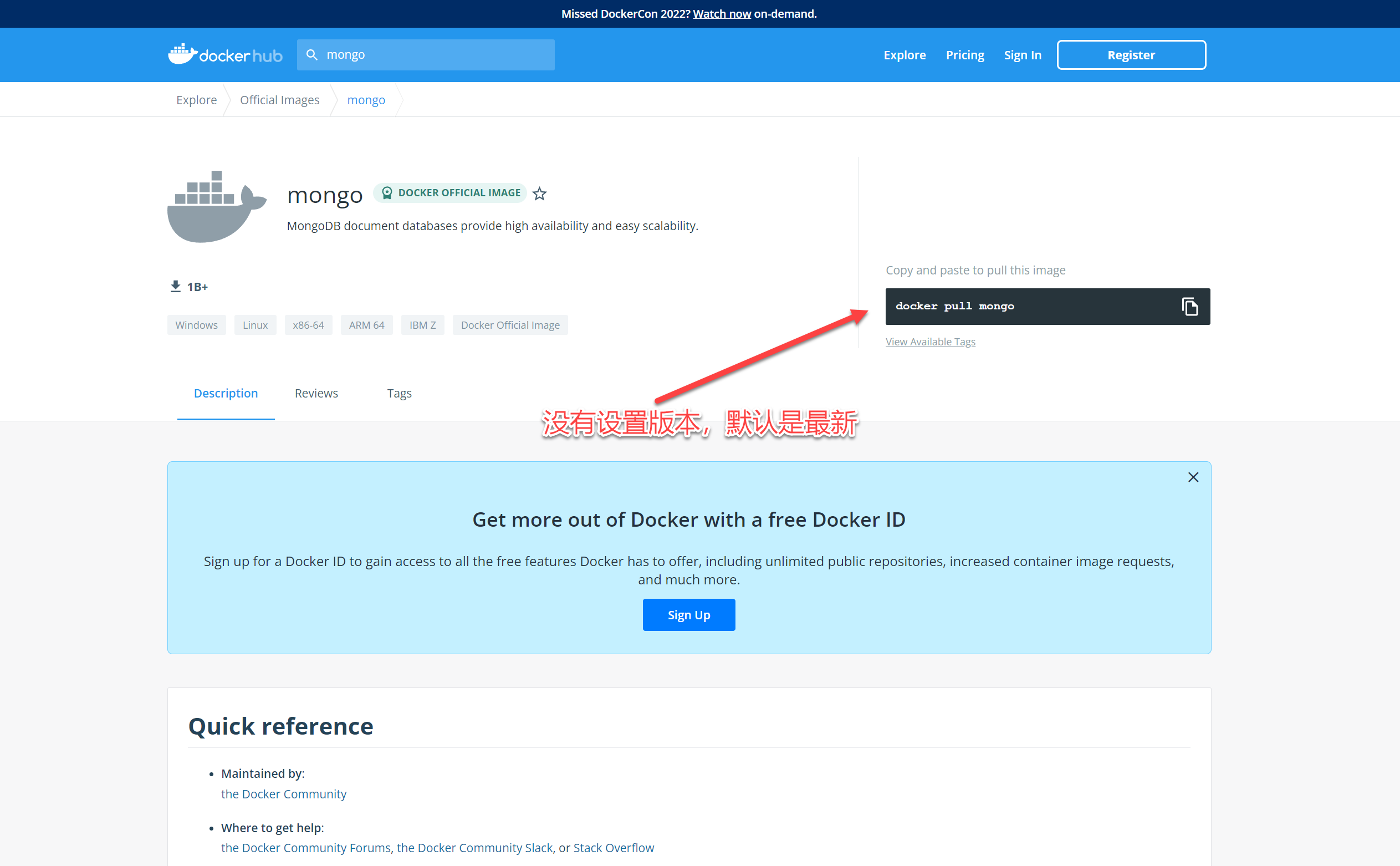
访问Explore Docker's Container Image Repository | Docker Hub,搜索mongo镜像
https://hub.docker.com/search?q=mongo
查看可用的镜像
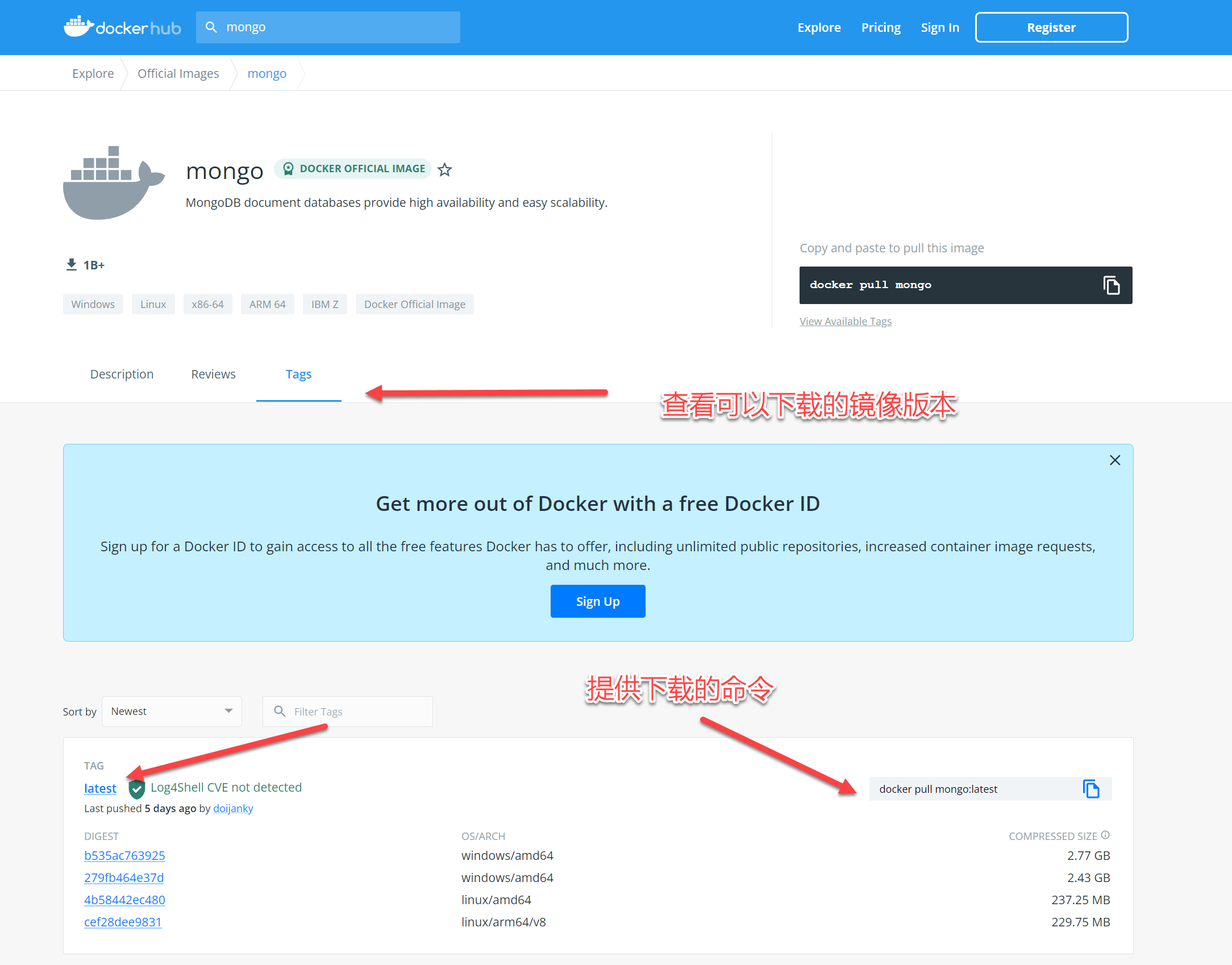
获取你想要拉取的镜像
docker pull mongo:5.0.9
查看已下载的镜像
docker images
创建挂载目录
mkdir d:\docker_app\mongodb_data --创建保存数据目录
创建并运行 mongo 容器
第一次
docker run -itd --name mongo5 -p 27017:27017 -v D:\docker_app\mongodb_data\:/data/db mongo:5.0.9
停止服务
docker stop mongo5
启动服务
docker start mongo5
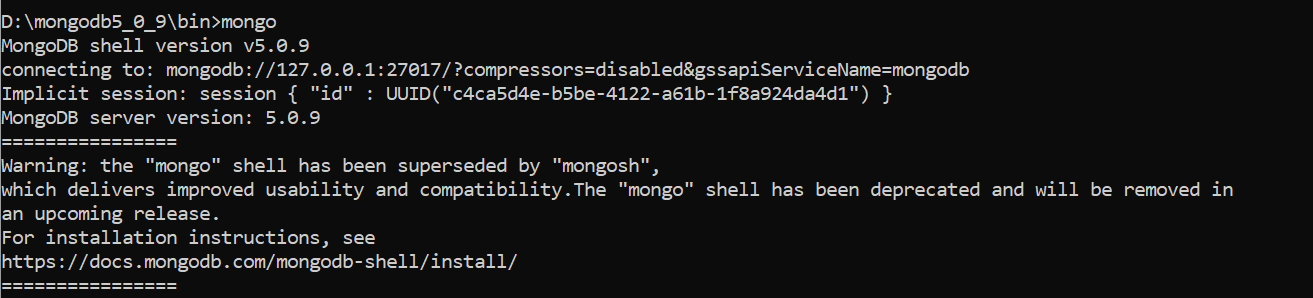
使用MongoShell工具连接MongoDB
MongoDB基础命令

计算机存储数据的概念如下:
查看数据库
列出所有在物理上存在的数
show dbs;
切换数据库/创建数据库
如果数据库不存在,则指向数据库,但不创建,直到插入数据或创建集合时数据库才被创建
use 数据库名;
删除当前数据库
删除当前指向的数据库 如果数据库不存在,则什么也不做
use 数据库名
db.dropDatabase()
创建集合
单纯创建集合命令
db.createCollection("集合名")
注意:
无需手动创建集合, 向不存在的集合中第一次添加数据时,集合会自动被创建出来
查看集合
showtables; //5.0.9不再支持
show collections;
删除集合
db.集合名.drop();
数据的增加

MongoDB将文档存储在集合中。集合类似于关系数据库中的表。如果集合不存在,MongoDB 会在首次存储该集合的数据时创建该集合。
编写语法为
db.集合名.函数名()
| 函数名 | 含义 |
|---|---|
| save( ) | 保存文档。文档不存在时,新创建一个文档; 文档存在,更新文档 |
| insert( ) | 插入文档,可以保存单文档,也可以是多文档 |
| insertOne( ) | 插入一个文档 |
| insertMany( ) | 插入多个文档 |
注意:
插入文档时,如果不指定_id参数,MongoDB会为文档分配一个唯一的ObjectId
样例
db.集合名.save(document)
db.集合名.insert(document)
db.集合名.insertOne(document)
db.集合名.insertMany([document,document])
数据的更新

编写语法为
db.集合名.函数名()
| 函数名 | 含义 |
|---|---|
update( <query>, <update> ,{multi: <boolean>}) | 参数query:查询条件,类似sql语句update中where部分 参数update:更新操作符,类似sql语句update中set部分 参数multi:可选,默认是false,表示只更新找到的第一条记录,值为true表示把满足条件的文档全部更新 |
updateOne( <query>, <update>) | 更新一条数据 |
updateMany( <query>, <update>) | 更新多条数据 |
replaceOne(<query>, <update>) | 只能更新整文档 |
注意:
更新的字段若不存在,会生成一个相应字段
举例
# 只更新找到的第一条,并且会修改结构
db.person.update({name:"zs"},{age:16})
# 只更新数据,为不更新文档结构
db.person.update({name:"zs"},{$set:{age:123})
# 更新所有找到匹配的数据
db.person.update({name:"zs"},{$set:{age:123}}, {multi: true})
# 只更新找到的第一条
db.person.updateOne({name:"zs"},{age:16})
# 更新所有找到匹配的数据
db.person.updateMany({name:"zs"},{age:16})
删除文档

编写语法为
db.集合名.函数名()
| 函数名 | 含义 |
|---|---|
remove( <query>) | 参数query:匹配符合的删除条件数据 |
deleteOne( <query>) | 更新一条数据 |
deleteMany( <query>) | 更新多条数据 |
样例
删除集合所有文档
db.集合名.deleteMany({})
删除指定条件的文档
db.集合名.deleteMany({ status : "A" })
最多删除1个指定条件的文档
db.集合名.deleteOne( { status: "D" } )
数据的查询

若要从集合中选择文档,可以使用 find()或者findOne() 方法。若要选择集合中的所有文档,请将空文档作为查询筛选器文档传递给该方法。
编写语法为
db.集合名.函数名()
| 函数名 | 含义 |
|---|---|
find( <{条件文档}>) | 查找到所有匹配数据 |
findOne( <{条件文档}>) | 只返回匹配的第一个数据 |
运算符
| 语法 | 操作 | 格式 |
|---|---|---|
| $eq | 等于 | {:} |
| $lt | 小于 | {:{$lt:}} |
| $lte | 小于或等于 | {:{$lte:}} |
| $gt | 大于 | {:{$gt:}} |
| $gte | 大于或等于 | {:{$gte:}} |
| $ne | 不等于 | {:{$ne:}} |
| $or | 或 | {$or:[{},{}]} |
| $in | 在范围内 | {age:{$in:[val1,val2]}} |
| $nin | 不在范围内 | {age:{$nin:[val1,val2]}} |
举例
db.person.find({age:{$gt:16}})
db.person.find({$or:[{age:{$gte:18}},{name:"zs"}])
模糊匹配
使用//或$regex编写正则表达式
db.person.find({name:/^zs/})
db.person.find({name:{$regex:'^zs'}}})
自定义查询
使用$where后面写一个函数,返回满足条件的数据
db.person.find({$where:function(){return this.age>20}}) # 5.0版本不能用了
db.person.find({$where:"this.age==23"});
db.person.find("this.age >23");
db.person.find('this.country=="吴国" || this.age==23');
limit
用于读取指定数量的文档
db.集合名称.find().limit(NUMBER)
skip
用于跳过指定数量的文档
db.集合名称.find().skip(2)
sort
用于对结果集进行排序
db.集合名称.find().sort({字段:1,...})
- 参数1为升序排列
- 参数-1为降序排列
count
用于统计结果集中文档条数
db.集合名称.find({条件}).count()
db.集合名称.count({条件})db.stu.find({gender:true}).count()
db.stu.count({age:{$gt:20},gender:true})
$exists
判断是否有某个字段
db.集合名称.find({'field':{$exists:true}})
dictinct
去重
db.集合名称.distinct(field)
db.集合名称.distinct(field,{过滤条件 })
样例数据
首先插入一批文档,再进行查询
db.person.insert([{"name":"司马懿","country":"魏国","age":35},
{"name":"张辽","country":"魏国","age":34},
{"name":"徐晃","country":"魏国","age":24},
{"name":"夏侯惇","country":"魏国","age":23},
{"name":"夏侯渊","country":"魏国","age":23},
{"name":"庞德","country":"魏国","age":23},
{"name":"张郃","country":"魏国","age":34},
{"name":"李典","country":"魏国","age":41},
{"name":"乐进","country":"魏国","age":34},
{"name":"典韦","country":"魏国","age":12},
{"name":"曹洪","country":"魏国","age":21},
{"name":"曹仁","country":"魏国","age":11},
{"name":"诸葛亮","country":"蜀国","age":20},
{"name":"关羽","country":"蜀国","age":32},
{"name":"张飞","country":"蜀国","age":23},
{"name":"马超","country":"蜀国","age":53},
{"name":"黄忠","country":"蜀国","age":23},
{"name":"赵云","country":"蜀国","age":32},
{"name":"魏延","country":"蜀国","age":42},
{"name":"关平","country":"蜀国","age":12},
{"name":"周仓","country":"蜀国","age":42},
{"name":"关兴","country":"蜀国","age":23},
{"name":"张苞","country":"蜀国","age":12},
{"name":"周瑜","country":"吴国","age":32},
{"name":"吕蒙","country":"吴国","age":11},
{"name":"甘宁","country":"吴国","age":23},
{"name":"太史慈","country":"吴国","age":23},
{"name":"程普","country":"吴国","age":24},
{"name":"黄盖","country":"吴国","age":28},
{"name":"韩当","country":"吴国","age":23},
{"name":"周泰","country":"吴国","age":29},
{"name":"蒋钦","country":"吴国","age":19},
{"name":"丁奉","country":"吴国","age":17},
{"name":"徐盛","country":"吴国","age":27}
])
聚合操作之分组、过滤

MongoDB 中聚合(aggregate)主要用于处理多个文档(诸如统计平均值,求和等),并返回计算后的数据结果。
- 对多个文档进行分组
- 对分组的文档执行操作并返回单个结果
- 分析数据变化
语法:db.集合名称.aggregate([{管道:{表达式}}])
管道命令之$group
按照某个字段进行分组
$group是所有聚合命令中用的最多的一个命令,用来将集合中的文档分组,可用于统计结果
使用示例如下
db.stu.aggregate({$group:{_id:"$country",counter:{$sum:1}}}
)
其中注意点:
db.db_name.aggregate是语法,所有的管道命令都需要写在其中_id表示分组的依据,按照哪个字段进行分组,例如:需要使用$gender表示选择这个字段进行分组$sum:1表示把每条数据作为1进行统计,统计的是该分组下面数据的条数
常用表达式
表达式:处理输⼊⽂档并输出 语法:表达式:'$列名' 常⽤表达式:
$sum: 计算总和, $sum:1 表示以⼀倍计数$avg: 计算平均值$min: 获取最⼩值$max: 获取最⼤值$push: 在结果⽂档中插⼊值到⼀个数组中
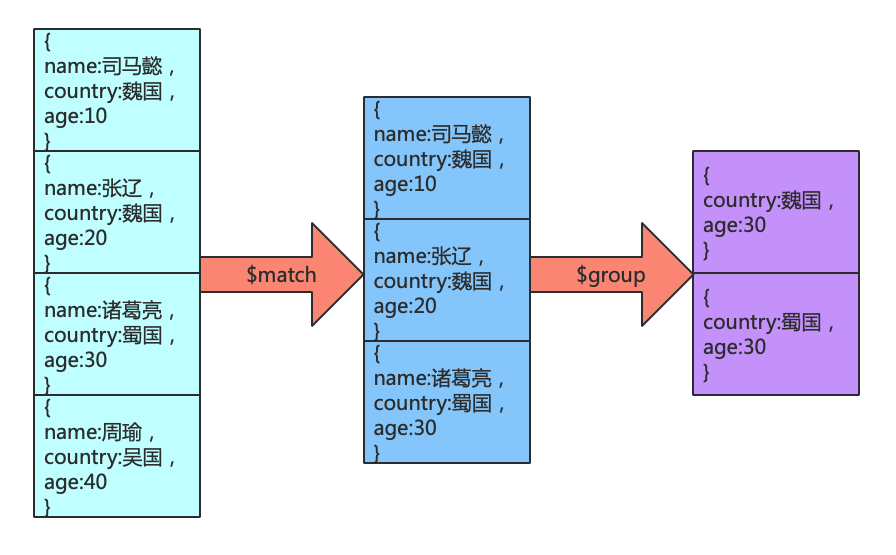
管道命令之$match
$match用于进行数据的过滤,是在能够在聚合操作中使用的命令,和find区别在于$match 操作可以把结果交给下一个管道处理,而find不行
使用示例如下:
-
查询年龄大于20的人
db.person.aggregate([{$match:{age:{$gt:20}}}])
2.查询年龄大于20的魏国的人数
db.person.aggregate([{$match:{age:{$gt:20}}},{$group:{_id:"$country",counter:{$sum:1}}}])
聚合操作之排序、分页

管道命令之$sort
$sort用于将输入的文档排序后输出
使用示例如下:
-
查询人物,按照年龄升序
db.person.aggregate([{$sort:{age:1}}])
2.查询每个国家的人数,并排序
db.person.aggregate([{$group:{_id:"$country",counter:{$sum:1}}},{$sort:{counter:-1}}
])
管道命令之$skip 和 $limit
$limit限制返回数据的条数$skip跳过指定的文档数,并返回剩下的文档数
注意
同时使用时先使用skip在使用limit
使用示例如下:
-
查询2条信息
db.person.aggregate([{$limit:2}
])
2.查询从第三条开始的信息
db.person.aggregate([{$skip:3}
])
3.查询每个国家的人数,按照人数升序,返回第二条数据
db.person.aggregate([{$group:{_id:"$country",counter:{$sum:1}}},{$sort:{counter:-1}},{$skip:1},{$limit:1}
])
管道命令之$project
$project用于修改文档的输入输出结构
字段值:0不显示,1显示
使用示例如下:
-
查询人物的姓名、年龄,不显示ID
db.person.aggregate([{$project:{_id:0,name:1,age:1}}])
2.查询每个国家的人数,只显示数量
db.person.aggregate([{$group:{_id:"$country",counter:{$sum:1}}},{$project:{_id:0,counter:1}}])
注意
_id与其他字段共同设置时,0只能设置在_id上- 设置字段时,除了_id字段,其他默认取反
MongoDB索引Index

索引概述
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对应用的性能是非常致命的
创建索引
MongoDB使用 createIndex() 方法来创建索引
db.集合名.createIndex(keys, options)
语法中 Key 值为要创建的索引字段,1 为指定按升序创建索引,如果想按降序来创建索引指定为 -1 即可
注意
- 在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名
- MongoDB默认所有的集合在_id字段上有一个索引。
样例
db.person.createIndex({"name":1})
索引的查看
默认情况下_id是集合的索引,查看方式:
db.集合名.getIndexes()
索引的查看
默认情况下_id是集合的索引,查看方式:
db.集合名.getIndexes()
样例
db.person.dropIndex({name:1})
db.person.getIndexes()
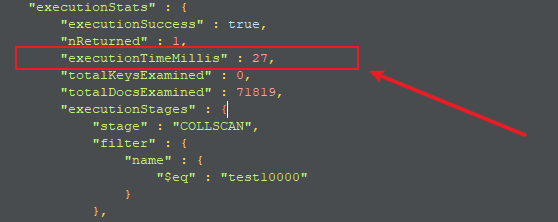
检测索引的速度优势
测试:插入10万条数据到数据库中
插入数据:
for(i=0;i<100000;i++){db.t1.insert({name:'test'+i,age:i})}
创建索引前:
db.t1.find({name:'test10000'})
db.t1.find({name:'test10000'}).explain('executionStats') # 显示查询操作的详细信息
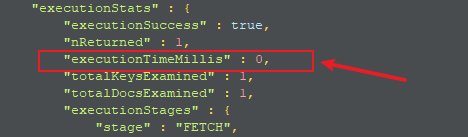
创建索引:
db.t1.creatIndexIndex({name:1})
创建索引后:
db.t1.find({name:'test10000'}).explain('executionStats')
前后速度对比
Mongo中唯一索引\复合索引

唯一索引
在默认情况下mongdb的索引的值是可以相同的,创建唯一索引之后,数据库会在插入数据的时候检查创建索引域的值是否存在,如果存在则不会插入该条数据,但是创建索引仅仅能够提高查询速度,同时降低数据库的插入速度
添加唯一索引的语法c
db.集合名.createIndex({"字段名":1}, {"unique":true})
利用唯一索引进行数据去重
根据唯一索引指定的字段的值,如果相同,则无法插入数据
db.person.createIndex({"name":1}, {"unique":true})
db.person.insert({name: 'test10000'})
复合索引
在进行数据去重的时候,可能用多个字段来做数据的唯一性,这个时候可以考虑建立复合索引来实现。
建立复合索引的语法:
db.collection_name.createIndex({字段1:1,字段2:1})
建立索引注意点
-
根据需要选择是否需要建立唯一索引
-
索引字段是升序还是降序在单个索引的情况下不影响查询效率,但是带复合索引的条件下会有影响
-
数据量巨大并且数据库的读出操作非常频繁的时候才需要创建索引,如果写入操作非常频繁,创建索引会影响写入速度
mongodb和python交互

安装环境
pip install pymongo==4.2.0
官方文档:https://pymongo.readthedocs.io/en/stable/
使用样例
引入包pymongo
import pymongo
连接,创建客户端
client = pymongo.MongoClient("localhost", 27017)
client = pymongo.MongoClient('mongodb://localhost:27017/')
获得数据库test1
db = client.test1
db = client['test']
获得集合movie
collection = db.movie
collection = db['movie']
添加数据
#增加一条
m1={name:'300集',actor:'高总',level:10}
m1_id = movie.insert_one(s1).inserted_id
#增加多条
mids = movie.insert_many([movie1,movie2])
注意
原insert方法也可以实现上面的功能,但是在PyMongo 3.x的版本已经不推荐使用了
查找数据
- find() 返回一个生成器对象
- find_one() 返回一条数据
result = movie.find_one()
result = movie.find_one({'name':'300集'})
result = movie.find_one({'_id':OjectId('5932a80115c2606a59e8a049')})
result = movie.find_one({level:{'$gt':1}})
results = movie.find()
比较符号
| 符号 | 含义 | 示例 |
|---|---|---|
| $lt | 小于 | {'age': {'$lt': 20}} |
| $gt | 大于 | {'age': {'$gt': 20}} |
| $lte | 小于等于 | {'age': {'$lte': 20}} |
| $gte | 大于等于 | {'age': {'$gte': 20}} |
| $ne | 不等于 | {'age': {'$ne': 20}} |
| $in | 在范围内 | {'age': {'$in': [20, 23]}} |
| $nin | 不在范围内 | {'age': {'$nin': [20, 23]}} |
功能符号
| 符号 | 含义 | 示例 | 示例含义 |
|---|---|---|---|
| $regex | 匹配正则表达式 | {'name': {'$regex': '^M.*'}} | name以M开头 |
| $exists | 属性是否存在 | {'name': {'$exists': True}} | name属性存在 |
| $type | 类型判断 | {'age': {'$type': 'int'}} | age的类型为int |
| $mod | 数字模操作 | {'age': {'$mod': [5, 0]}} | 年龄模5余0 |
| $text | 文本查询 | {'$text': {'$search': 'Mike'}} | text类型的属性中包含Mike字符串 |
| $where | 高级条件查询 | {'$where': 'obj.fans_count == obj.follows_count'} | 自身粉丝数等于关注数 |
获取文档个数
count = movie.count_documents()
排序
results = collection.find().sort('name', pymongo.ASCENDING)
偏移/分页
collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
注意
update也可以实现上面的功能,但是在PyMongo 3.x的版本已经不推荐使用了
删除
result = collection.remove({'name': '300集'}) # 4.2版本不支持
result = collection.delete_one({'name': '300集'})
result = collection.delete_many({'age': {'$lt': 25}})
Scrapy保存数据到多个数据库

目标网站:中国福利彩票网 双色球往期数据
阳光开奖 (cwl.gov.cn) http://www.cwl.gov.cn/ygkj/wqkjgg/
代码
class MongoPipeline:def open_spider(self, spider):self.client = pymongo.MongoClient()self.ssq = self.client.bjsxt.ssqdef process_item(self, item, spider):if item.get('code') =='2022086':self.ssq.insert_one(item)return itemdef close_spider(self, spider):self.client.close()# pip install pymysql==1.0.2
import pymysql
from scrapy.exceptions import DropItem
class MySQLPipeline:def open_spider(self, spider):# 创建数据库连接self.client = pymysql.connect(host='192.168.31.151',port=3306,user='root',password='123',db='bjsxt',charset='utf8')# 获取游标self.cursor = self.client.cursor()def process_item(self, item, spider):if item.get('code') =='2022086':raise DropItem('2022086 数据已经在mongo保存过了')# 写入数据库SQLsql = 'insert into t_ssq (id,code,red,blue) values (0,%s,%s,%s)'# 写的数据参数args = (item['code'],item['red'],item['blue'])# 执行SQLself.cursor.execute(sql,args)# 提交事务self.client.commit()return itemdef close_spider(self, spider):self.cursor.close()self.client.close()
Scrapy案例
需求: 爬取二手房数据,要求包含房屋基本信息与详情
网址:https://bj.lianjia.com/ershoufang/
爬虫的分布式思维与实现思路
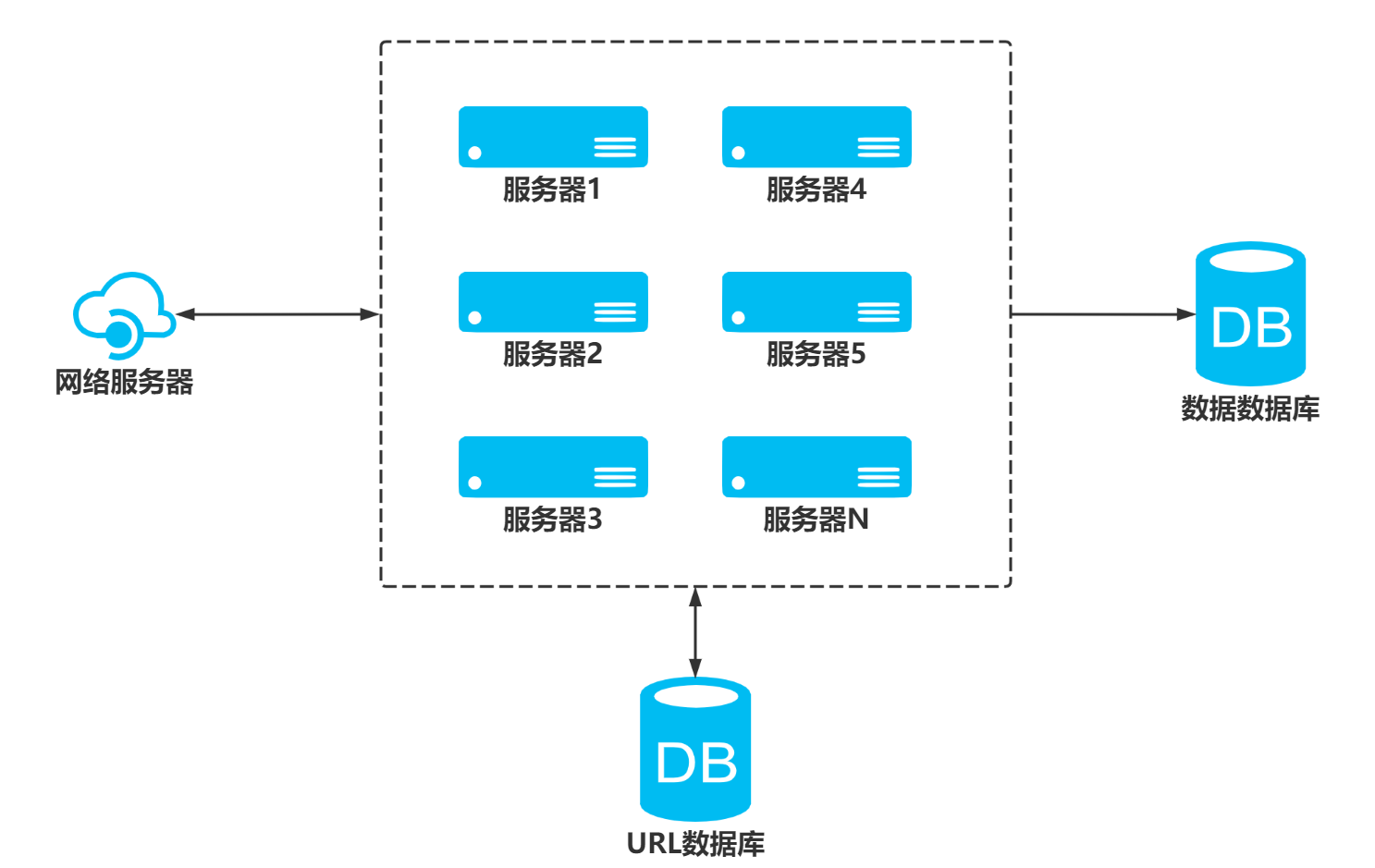
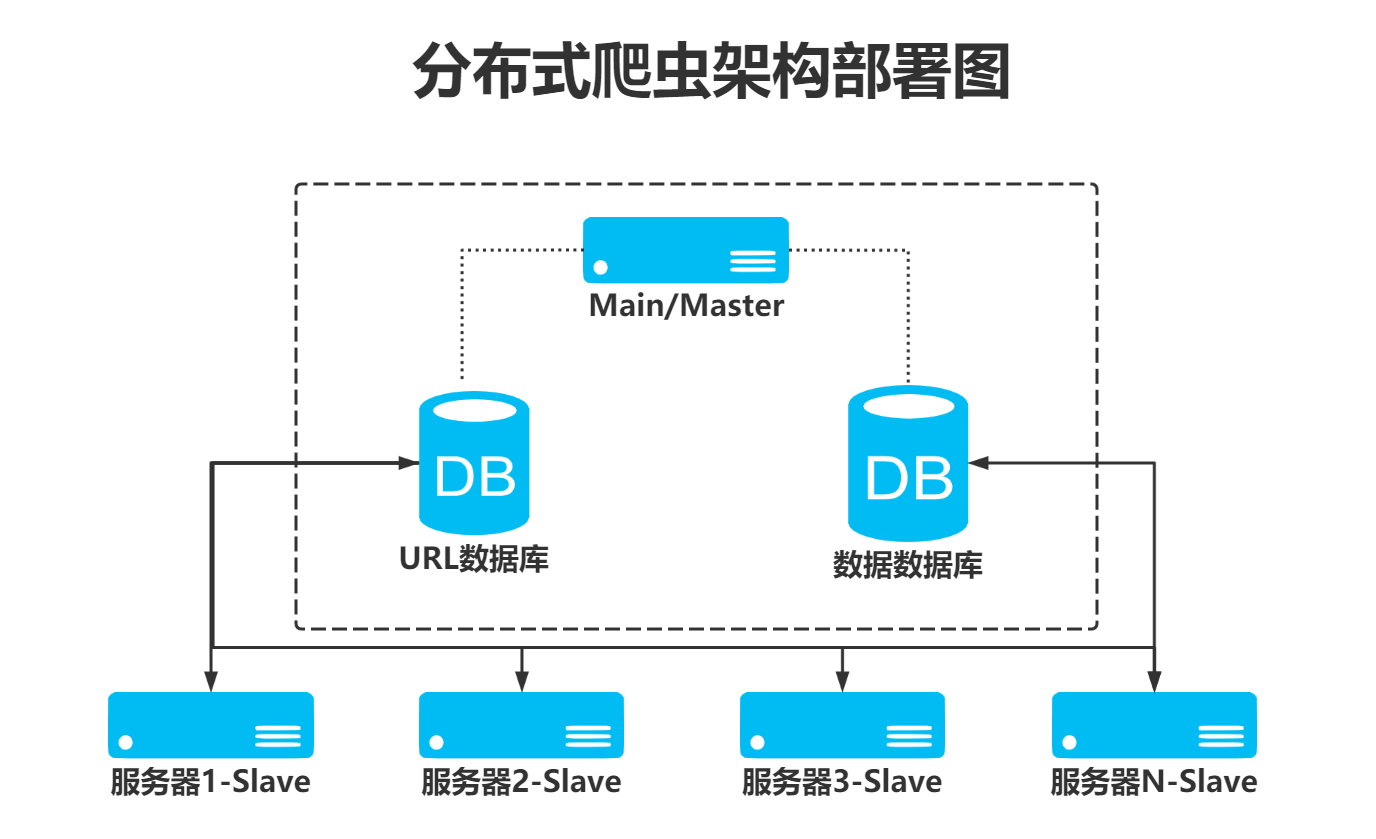
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave
我们知道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上
好处
程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情
分布式爬虫的实现
-
使用三台机器,一台是windows,两台是centos,分别在两台机器上部署scrapy来进行分布式抓取一个网站
-
windows的ip地址为
192.168.xxx.XXX,用来作为redis的master端,centos的机器作为slave -
master的爬虫运行时会把提取到的url封装成request放到redis中的数据库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库中“dmoz:items”
-
slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis
-
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到mongodb中
-
master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的
scrapy-redis框架的安装
一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能
github地址: https://github.com/darkrho/scrapy-redis
安装
pip install scrapy-redis==0.7.3
爬虫分布式-搭建Main端Redis

安装Redis
Redis是有名的NoSql数据库,一般Linux都会默认支持。但在Windows环境中,目前也有支持版本。下载地址也可以GitHub中获取(https://github.com/microsoftarchive/redis/releases)
- 下载安装包
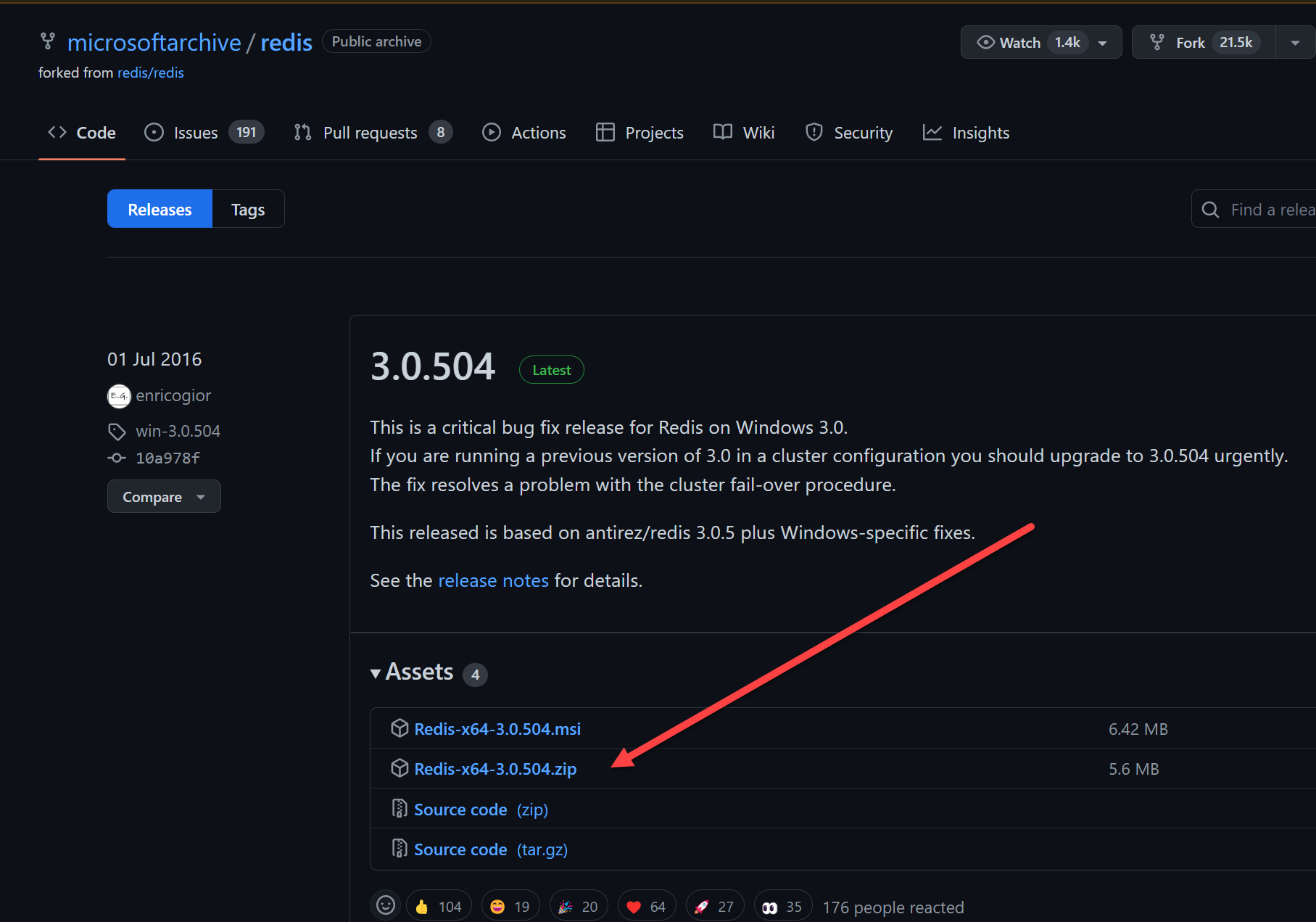
- 下载压缩版,解压即可
- 修改配置文件
redis.windows.conf,配置redis参数
# bind 127.0.0.1 =::1 允许远程访问
protected-mode no 关闭私有模式
开启redis服务
redis-server redis.windows.conf
爬虫分布式-搭建Slave端环境配置

Python环境
python安装与使用的前置环境
yum install gcc* zlib* libffi-devel bzip2-devel xz-devel openssl* -y
下载 Python3
yum install wget -y
wget https://www.python.org/ftp/python/3.9.4/Python-3.9.4.tgz
注意
可在python官网https://www.python.org/downloads/查找最新版本python复制链接,以下文件夹名称均需要替换为对应版本名称
技巧
理论是服务器安装的Python版本与运行环境版本一致。但是也要看服务器是否支持!!
安装
tar -xf Python-3.9.4.tgz # 解压
cd Python-3.9.4
./configure prefix=/usr/local/python3 --enable-optimizations #编译
make install # 安装
export PATH=$PATH:/usr/local/python3/bin/ # 配置环境变量
# ~/.bash_profile
安装scrapy
安装scrapy的环境
提示
如果twisted安装不成功,可以考虑单独下载安装
https://twistedmatrix.com
安装scrapy
pip3 install scrapy
pip3 install scrapy
注意
为了避免安装失败,修改pypi数据源
找到下列文件
~/.pip/pip.conf
在上述文件中添加或修改:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/[install]
trusted-host=mirrors.aliyun.com
安装 scrapy-redis
pip3 install scrapy-redis
安装 scrapy-fake-useragent
pip3 install scrapy-fake-useragent
爬虫分布式-代码的改写1

参考案例:
https://github.com/darkrho/scrapy-redis
修改setting
增加代码,配置redis地址
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
增加代码,配置Scrapy调度器、去重对象、队列、管道
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"ITEM_PIPELINES = {'example.pipelines.ExamplePipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400,
}
运行代码
shell 运行Scrapy即可
python 脚本文件.py
爬虫分布式-代码的改写2

修改setting
增加代码,配置redis地址
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
增加代码,配置Scrapy调度器、去重对象、队列、管道
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"ITEM_PIPELINES = {'example.pipelines.ExamplePipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400,
}
修改Spider类
- 继承RedisSpider类
- 建立任务开始关键字redis_key
from scrapy_redis.spiders import RedisSpiderclass MySpider(RedisSpider):"""Spider that reads urls from redis queue (myspider:start_urls)."""name = 'myspider_redis'redis_key = 'myspider:start_urls'def __init__(self, *args, **kwargs):# Dynamically define the allowed domains list.domain = kwargs.pop('domain', '')self.allowed_domains = filter(None, domain.split(','))super(MySpider, self).__init__(*args, **kwargs)def parse(self, response):return {'name': response.css('title::text').extract_first(),'url': response.url,}
运行代码
shell 运行Scrapy即可
python 脚本文件.py
redis 中增加url任务
lpush (redis_key) url #括号不用写
爬虫分布式-代码的改写3

修改setting
增加代码,配置redis地址
REDIS_HOST = 'localhost' #master IP
REDIS_PORT = 6379
增加代码,配置Scrapy调度器、去重对象、队列、管道
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"ITEM_PIPELINES = {'example.pipelines.ExamplePipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400,
}
修改Spider类
- 继承RedisCrawlSpider类
- 建立任务开始关键字redis_key
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractorfrom scrapy_redis.spiders import RedisCrawlSpiderclass MyCrawler(RedisCrawlSpider):"""Spider that reads urls from redis queue (myspider:start_urls)."""name = 'mycrawler_redis'redis_key = 'mycrawler:start_urls'rules = (# follow all linksRule(LinkExtractor(), callback='parse_page', follow=True),)def __init__(self, *args, **kwargs):# Dynamically define the allowed domains list.domain = kwargs.pop('domain', '')self.allowed_domains = filter(None, domain.split(','))super(MyCrawler, self).__init__(*args, **kwargs)def parse_page(self, response):return {'name': response.css('title::text').extract_first(),'url': response.url,}
运行代码
shell 运行Scrapy即可
python 脚本文件.py
redis 中增加url任务
lpush (redis_key) url #括号不用写
爬虫分布式-代码Slave端运行

Slave主要功能就是爬取数据,因此需要做的事:
-
复制代码到服务器
-
修改配置信息
- 设置Redis地址为Main端IP
-
运行代码
错误
ModuleNotFoundError: No module named '_lzma'
解决方案
- yum install xz-devel -y
- 重新安装python,命令如下make install
错误
ModuleNotFoundError: No module named '_ssl'
解决方案
yum install openssl* -y
重新安装python
- 重新编译 ./configure prefix=path --enable-optimizations
- 重新安装 make install
Redis数据导出到Mongo中

思路
- 链接redis数据库
- 读取redis中的数据
- 链接mongo数据库
- 写入数据
安装redis模块
pip install reids
代码
import redis # pip install redis
from pymongo import MongoClient
from json import loads# 连接Redis数据库
r_client = redis.Redis(host='localhost',port=6379,db=0)
# 连接Mongo数据库
m_client = MongoClient()
# 获取指定的集合
lianjia = m_client.room.lianjia
# 获取数据
while True:try:s,d = r_client.blpop(['lianjia3:items'],timeout=2)except Exception as e:# 关闭连接m_client.close()r_client.close()# 转换数据data = loads(d)print(data)# 保存数据lianjia.insert_one(data)