基于ASRPRO的语音对话
目录
效果展示
前置准备
环境配置
工程分析
识别词
添加播放语音
语音替换
最近在研究一个小项目,我打算加入语音对话来提高体验度,在上篇文章的基础上趁热打铁便有了这篇文章。
在本文中,我将介绍如何基于ASRPRO搭建一个简单的语音对话工程。
效果展示
下面的链接是我初步制作的内容,目前还在改进中。我这里使用的是另一种音频转换发方式,比本文介绍的方法损失的音质较多,请大家自行甄别是否使用ASRPRO。
(PS:语音素材是我自己录制游戏音频剪的,有需求的可以评论区讲一下。)
基于ASRPro做的一个小语音对话助手_哔哩哔哩_bilibili
前置准备
在开始之前,我们需要做以下准备:
1.安装天问Block,我这里使用的软件版本是2025夏季正式版。
(这是ASRPRO的编程软件,图形化编程,超简单)
2.准备好我们需要的语音。(语音建议大家先做好备份,防止意外丢失)
环境配置
天问Block安装好之后,我们需要注册一个账号,因为没有账号的话是不允许我们生成语音模型的。
在设备处,我们选ASRPRO。
在 项目 下可以选择新建或打开已有工程,这里我随便起一个名字abc,直接保存在桌面上。这时,我们应该会看到工具自动生成的代码。
然后我们在左侧点击 添加扩展 安装了叫做 播放语音ID 的库。
除了软件默认的这些图形模块,官方还提供了海量的官方扩展库可用户自己设计的库。通过这个模块我们就可以在逻辑判断的语句体里播放对应的语音。
工程分析
下图为我前面那个演示的工程,我将通过对这个工程的讲解让大家能上手使用语音识别模块。
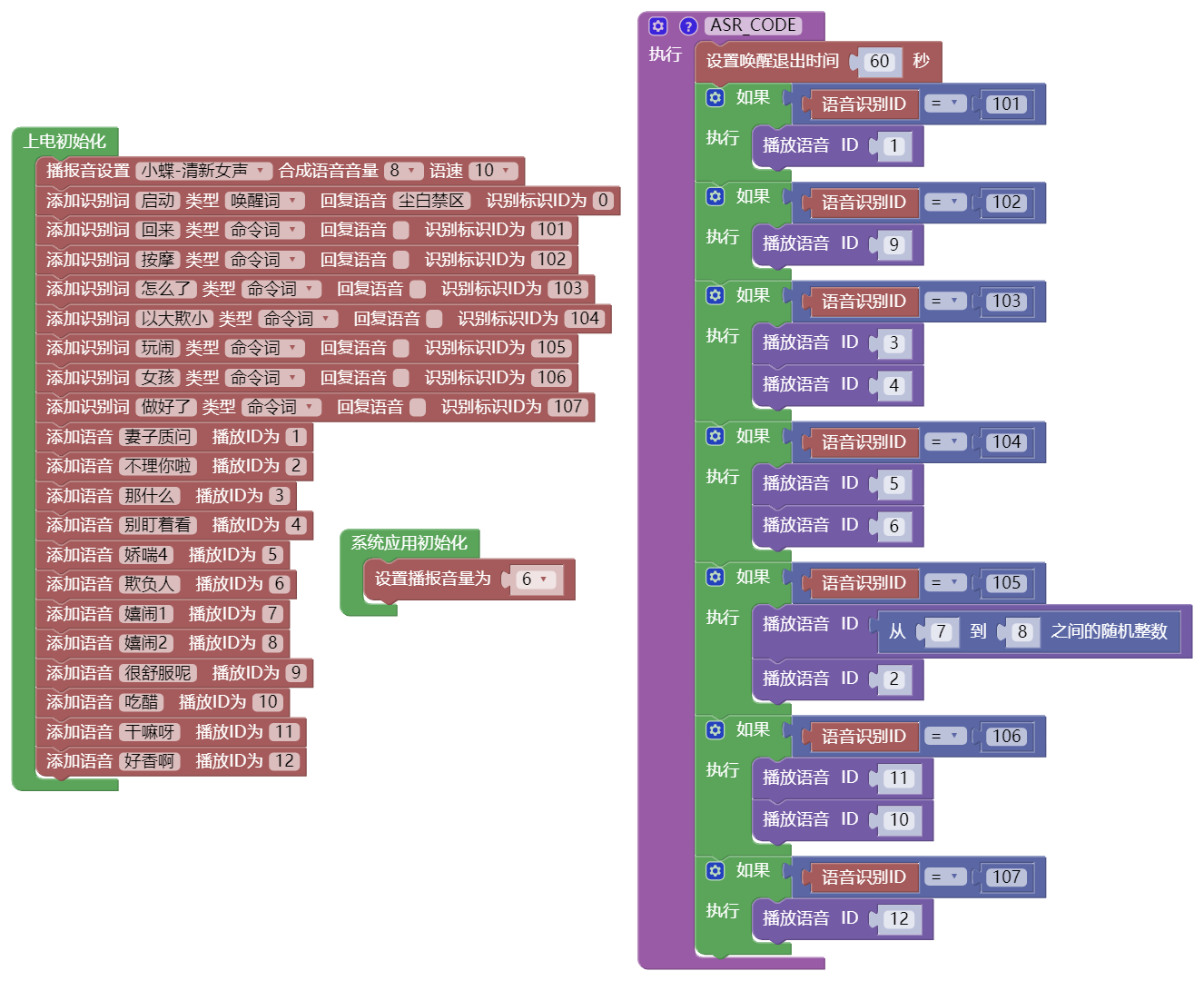
我们先看左边的上电初始化,开头有一个播报音设置,官方提供了很多声音供我们使用,在这个模块还可以修改声音的语速和音量,但是如果我们把全部语音替换掉的话,其实也没什么用,不用管它。
此外默认情况下还会有上电播放的欢迎词和提示进入休眠状态的退出语音,我这里用不上所以去掉了。
识别词
往下,我们看到添加识别词这里。识别词就是我们说的话,当模块识别到这个辞职后就会触发相应的逻辑。
唤醒词:当模块检测到该词之后,模块才会对命令词有反应。
命令词:除了在检测到唤醒词之后才能被识别,其他同唤醒词。
当检测到识别词之后,模块可以回应我们一个语音,在默认状态下该语音就是我们在回复语音输入框内输入的话。我们可以不设置识别词的回复语音,同样识别词的语音也可以被替换,替换方式会在后面讲。
最后是识别标识ID,它就是我们识别词的标号,应用在后面的逻辑判断里面,比如检测到标识ID为0时,让某个引脚输出高电平。
添加播放语音
下一部分就是添加语音。同样,在不替换音频的情况下模块会默认播放我们输入的文字。后面的播放ID也是这段语音的标识,也是用于逻辑执行里面。
注意!!!识别词的ID不能和播放语音的ID重复!!!
在上电初始化里我们还可以进行一些引脚和其他功能的初始化,我这里暂时没有使用那么多功能,所以没有加进来。
现在让我们看一下右边的一大坨。首先是退出时间,注意,这个退出时间是从最后一个识别词被识别到开始算的。在我现在使用的这个软件版本里,我们可以选择是模块永远不休眠。
我在这里使用的都是if判断,都是如果识别到某个识别ID,然后播放对应的语音。
到这里为止,我们的逻辑就写好了,接下来就是替换语音了。
语音替换
首先,我们需要点击生成模型,生成所有语音,之后在 更多->一键替换语音 处打开如下图界面。
大家可以看到,左边就是我们可以替换的音频。右边的文件是我添加的,软件支持wav等文件格式,大家不需要担心音频文件太大会导致内存溢出,所有音频文件会通过软件的音频转换功能进行压缩转换,我工程里使用的13条共10M大小的语音经过转换大小为1M,但是音质肯定会有损伤。我使用的模块自带2M的内存,对于一些小功能还是完全够用的。如果你的语音文件很多,可以买一个内存模块连到与语音识别模块上面。
大家看编号为0的那条语音,这个就是唤醒词的回复语音。10001和10002为欢迎和退出语音,所以为空。
替换时大家点击替换按键,选择要换上的音频文件即可,最后一键替换就能完成。
最后连接语音识别模块,点击2M编译下载,等待下载完成我们就能体验我们的成果啦。