datawhale RAG技术全栈指南 202509 第6次作业
基于知识图谱的RAG
将结构化知识图谱融入RAG流程的新范式——KG-RAG应运而生。通过利用知识图谱的显式语义关系和图结构优势,KG-RAG能够提供更精准的上下文检索和更强的推理能力,在多跳查询和事实性要求较高的场景中表现尤为出色。
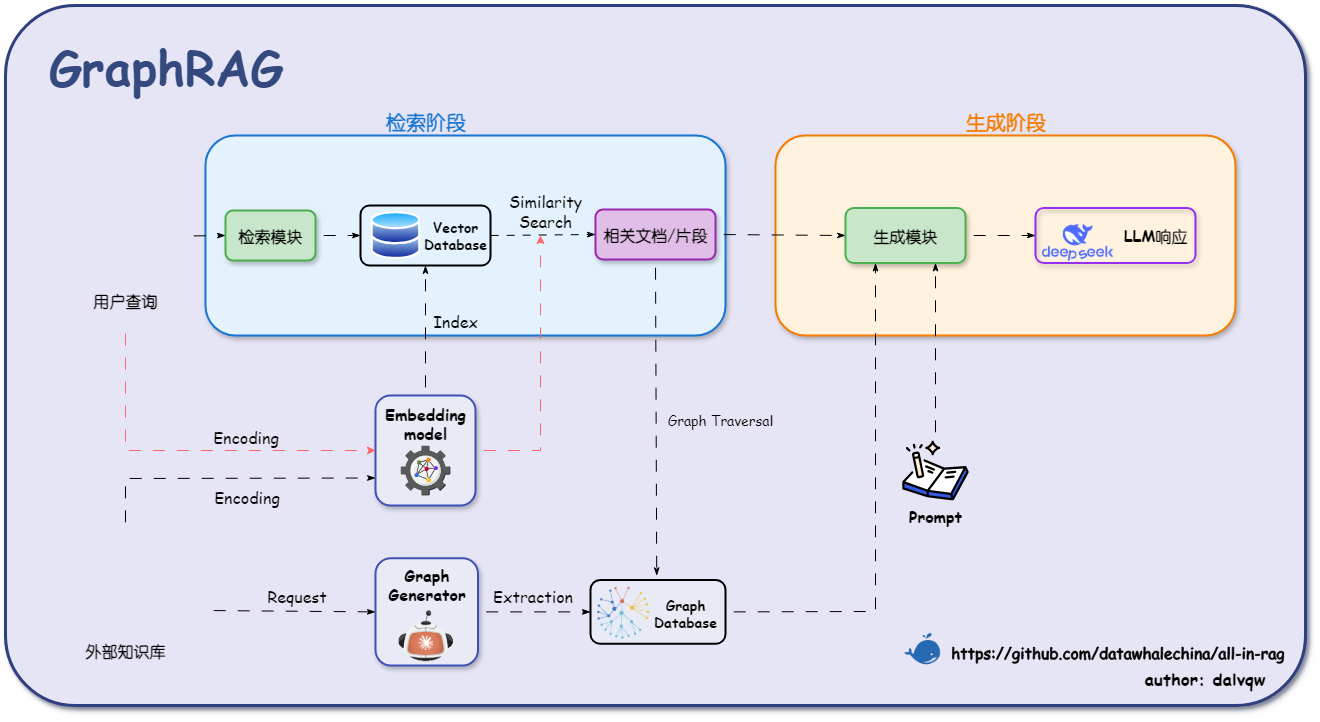
大多数KG-RAG框架遵循一个通用的三阶段流程:知识图谱构建、图谱检索与增强生成。
通用架构三阶段
知识图谱构建 是KG-RAG的基础。该阶段的目标是从原始数据中构建一个高质量的知识图谱。知识抽取环节利用LLM强大的自然语言理解能力,从非结构化或半结构化文本中自动抽取实体、关系以及属性,形成知识三元组(例如,<实体A, 关系, 实体B>)。随后的图谱融合与存储将抽取的知识三元组与现有知识进行对齐、融合和去重,并存入专门的图数据库(如Neo4j)中,以便进行高效的图查询和遍历。
图谱检索 阶段,当用户提出查询时,系统不再是简单地进行向量相似度搜索,而是执行更复杂的图谱检索操作。混合检索策略是主流趋势,例如,首先通过向量检索定位查询中的核心实体节点,然后从这些节点出发,利用图查询语言(如Cypher)或图遍历算法进行子图探索、路径发现。一些高级框架(如GraphRAG)会采用社区检测算法(如Leiden算法)将图谱划分为语义社区,并生成摘要,从而实现从局部细节到全局概览的多层次上下文检索。
增强生成 是最后一步,将检索到的结构化知识(如相关实体的属性、实体间的关系路径、描述子图的文本摘要等)与原始查询一同注入到LLM的提示(Prompt)中。LLM基于这些高度结构化、事实性强的上下文信息,生成最终的、更准确、更具逻辑性的回答。
图RAG系统架构与环境配置
从传统RAG到图RAG的演进
上一章中,我们构建了基于向量检索的传统RAG系统,采用了父子文本块的分块策略,能够有效回答简单的菜谱查询。但在处理复杂的关系推理和多跳查询时仍存在明显局限:
- 关系理解缺失:虽然父子分块保持了文档结构,但无法显式建模食材、菜谱、烹饪方法之间的语义关系
- 跨文档关联困难:难以发现不同菜谱之间的相似性、替代关系等隐含联系
- 推理能力有限:缺乏基于知识图谱的多跳推理能力,难以回答需要复杂逻辑推理的问题
图RAG系统的核心优势
通过引入知识图谱,我们的新系统将具备:
- 结构化知识表达:以图的形式显式编码实体间的语义关系
- 增强推理能力:支持多跳推理和复杂关系查询
- 智能查询路由:根据查询复杂度自动选择最适合的检索策略
- 事实性与可解释性:基于图结构的推理路径提供可追溯的答案
环境配置
1 创建虚拟环境
# 使用conda创建环境
conda create -n graph-rag python=3.12.7
conda activate graph-rag2 安装核心依赖
cd code/C9
pip install -r requirements.txt3 Neo4j数据库配置
使用Docker Compose方式安装Neo4j,配置文件位于 data/C9/docker-compose.yml:
启动Neo4j服务
# 进入docker-compose.yml所在目录
cd data/C9# 启动Neo4j服务
docker-compose up -d# 检查服务状态
docker-compose ps访问Neo4j Web界面
启动成功后,可以通过以下方式访问:
- Web界面:http://localhost:7474
- 用户名:neo4j
- 密码:all-in-rag
当前网址为本地访问,如果你是部署在远程服务器上,需要将
localhost修改为你的服务器IP地址。
数据导入
Docker Compose配置中包含了自动数据导入功能。启动服务时会自动执行以下步骤:
- 等待Neo4j服务就绪:通过健康检查确保数据库可用
- 执行导入脚本:自动运行
data/C9/cypher/neo4j_import.cypher - 导入菜谱数据:包括菜谱、食材、烹饪步骤等节点和关系
如果需要手动重新导入数据:
# 进入容器执行导入脚本
docker exec -it neo4j-db cypher-shell -u neo4j -p all-in-rag -f /import/cypher/neo4j_import.cypher
4 Milvus向量数据库配置
如果前面已经安装过了可以跳过此步,通过 docker-compose ps 确认Milvus服务正在运行即可。
# 下载Milvus standalone配置文件
wget https://github.com/milvus-io/milvus/releases/download/v2.5.11/milvus-standalone-docker-compose.yml -O docker-compose.yml# 启动Milvus
docker-compose up -d验证安装
# 检查Milvus服务状态
docker-compose ps配置连接参数
在项目根目录创建 .env 文件:
# Neo4j配置
NEO4J_URI=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=all-in-rag
NEO4J_DATABASE=neo4j# Milvus配置
MILVUS_HOST=localhost
MILVUS_PORT=19530# LLM API配置
MOONSHOT_API_KEY=your_api_key_here系统架构设计
核心模块说明
图数据准备模块 (GraphDataPreparationModule)
- 功能:连接Neo4j数据库,加载图数据,构建结构化菜谱文档
- 特点:支持图数据到文档的智能转换,保持知识结构完整性
向量索引模块 (MilvusIndexConstructionModule)
- 功能:构建和管理Milvus向量索引,支持语义相似度检索
- 特点:使用BGE-small-zh-v1.5模型,512维向量空间
混合检索模块 (HybridRetrievalModule)
- 功能:传统的混合检索策略,结合向量检索和图扩展
- 特点:双层检索(实体级+主题级),RRF轮询融合
图RAG检索模块 (GraphRAGRetrieval)
- 功能:基于图结构的高级检索,支持多跳推理和子图提取
- 特点:图查询理解、多跳遍历、知识子图提取
智能查询路由 (IntelligentQueryRouter)
- 功能:分析查询特征,自动选择最适合的检索策略
- 特点:LLM驱动的查询分析,动态策略选择
生成集成模块 (GenerationIntegrationModule)
- 功能:基于检索结果生成最终答案,支持流式输出
- 特点:自适应生成策略,错误处理与重试机制
3.3 数据流程
-
数据准备阶段:
- 从Neo4j加载图数据(菜谱、食材、步骤节点及其关系)
- 构建结构化菜谱文档,保持知识完整性
- 进行智能文档分块,支持章节和长度双重分块策略
- 构建Milvus向量索引,支持语义检索
-
查询处理阶段:
- 用户输入查询
- 智能查询路由器分析查询特征(复杂度、关系密集度、推理需求)
- 根据分析结果选择检索策略:
- 简单查询 → 传统混合检索
- 复杂推理 → 图RAG检索
- 中等复杂 → 组合检索策略
- 执行相应的检索操作
- 生成模块基于检索结果生成答案
-
错误处理与降级:
- 高级策略失败时自动降级到传统混合检索
- 传统混合检索失败时返回系统异常
- 支持流式输出中断时的自动重试机制
main.py
"""
基于图RAG的智能烹饪助手 - 主程序
整合传统检索和图RAG检索,实现真正的图数据优势
"""import os
import sys
import time
import logging
from typing import List, Optional# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 添加当前目录到Python路径
sys.path.append(os.path.dirname(os.path.abspath(__file__)))from dotenv import load_dotenv
from config import DEFAULT_CONFIG, GraphRAGConfig
from rag_modules import (GraphDataPreparationModule,MilvusIndexConstructionModule, GenerationIntegrationModule
)
from rag_modules.hybrid_retrieval import HybridRetrievalModule
from rag_modules.graph_rag_retrieval import GraphRAGRetrieval
from rag_modules.intelligent_query_router import IntelligentQueryRouter, QueryAnalysis# 加载环境变量
load_dotenv()class AdvancedGraphRAGSystem:"""图RAG系统核心特性:1. 智能路由:自动选择最适合的检索策略2. 双引擎检索:传统混合检索 + 图RAG检索3. 图结构推理:多跳遍历、子图提取、关系推理4. 查询复杂度分析:深度理解用户意图5. 自适应学习:基于反馈优化系统性能"""def __init__(self, config: Optional[GraphRAGConfig] = None):self.config = config or DEFAULT_CONFIG# 核心模块self.data_module = Noneself.index_module = Noneself.generation_module = None# 检索引擎self.traditional_retrieval = Noneself.graph_rag_retrieval = Noneself.query_router = None# 系统状态self.system_ready = Falsedef initialize_system(self):"""初始化高级图RAG系统"""logger.info("启动高级图RAG系统...")try:# 1. 数据准备模块print("初始化数据准备模块...")self.data_module = GraphDataPreparationModule(uri=self.config.neo4j_uri,user=self.config.neo4j_user,password=self.config.neo4j_password,database=self.config.neo4j_database)# 2. 向量索引模块print("初始化Milvus向量索引...")self.index_module = MilvusIndexConstructionModule(host=self.config.milvus_host,port=self.config.milvus_port,collection_name=self.config.milvus_collection_name,dimension=self.config.milvus_dimension,model_name=self.config.embedding_model)# 3. 生成模块print("初始化生成模块...")self.generation_module = GenerationIntegrationModule(model_name=self.config.llm_model,temperature=self.config.temperature,max_tokens=self.config.max_tokens)# 4. 传统混合检索模块print("初始化传统混合检索...")self.traditional_retrieval = HybridRetrievalModule(config=self.config,milvus_module=self.index_module,data_module=self.data_module,llm_client=self.generation_module.client)# 5. 图RAG检索模块print("初始化图RAG检索引擎...")self.graph_rag_retrieval = GraphRAGRetrieval(config=self.config,llm_client=self.generation_module.client)# 6. 智能查询路由器print("初始化智能查询路由器...")self.query_router = IntelligentQueryRouter(traditional_retrieval=self.traditional_retrieval,graph_rag_retrieval=self.graph_rag_retrieval,llm_client=self.generation_module.client,config=self.config)print("✅ 高级图RAG系统初始化完成!")except Exception as e:logger.error(f"系统初始化失败: {e}")raisedef build_knowledge_base(self):"""构建知识库(如果需要)"""print("\n检查知识库状态...")try:# 检查Milvus集合是否存在if self.index_module.has_collection():print("✅ 发现已存在的知识库,尝试加载...")if self.index_module.load_collection():print("知识库加载成功!")# 重要:即使从已存在的知识库加载,也需要加载图数据以支持图索引print("加载图数据以支持图检索...")self.data_module.load_graph_data()print("构建菜谱文档...")self.data_module.build_recipe_documents()print("进行文档分块...")chunks = self.data_module.chunk_documents(chunk_size=self.config.chunk_size,chunk_overlap=self.config.chunk_overlap)self._initialize_retrievers(chunks)returnelse:print("❌ 知识库加载失败,开始重建...")print("未找到已存在的集合,开始构建新的知识库...")# 从Neo4j加载图数据print("从Neo4j加载图数据...")self.data_module.load_graph_data()# 构建菜谱文档print("构建菜谱文档...")self.data_module.build_recipe_documents()# 进行文档分块print("进行文档分块...")chunks = self.data_module.chunk_documents(chunk_size=self.config.chunk_size,chunk_overlap=self.config.chunk_overlap)# 构建Milvus向量索引print("构建Milvus向量索引...")if not self.index_module.build_vector_index(chunks):raise Exception("构建向量索引失败")# 初始化检索器self._initialize_retrievers(chunks)# 显示统计信息self._show_knowledge_base_stats()print("✅ 知识库构建完成!")except Exception as e:logger.error(f"知识库构建失败: {e}")raisedef _initialize_retrievers(self, chunks: List = None):"""初始化检索器"""print("初始化检索引擎...")# 如果没有chunks,从数据模块获取if chunks is None:chunks = self.data_module.chunks or []# 初始化传统检索器self.traditional_retrieval.initialize(chunks)# 初始化图RAG检索器self.graph_rag_retrieval.initialize()self.system_ready = Trueprint("✅ 检索引擎初始化完成!")def _show_knowledge_base_stats(self):"""显示知识库统计信息"""print(f"\n知识库统计:")# 数据统计stats = self.data_module.get_statistics()print(f" 菜谱数量: {stats.get('total_recipes', 0)}")print(f" 食材数量: {stats.get('total_ingredients', 0)}")print(f" 烹饪步骤: {stats.get('total_cooking_steps', 0)}")print(f" 文档数量: {stats.get('total_documents', 0)}")print(f" 文本块数: {stats.get('total_chunks', 0)}")# Milvus统计milvus_stats = self.index_module.get_collection_stats()print(f" 向量索引: {milvus_stats.get('row_count', 0)} 条记录")# 图RAG统计route_stats = self.query_router.get_route_statistics()print(f" 路由统计: 总查询 {route_stats.get('total_queries', 0)} 次")if stats.get('categories'):categories = list(stats['categories'].keys())[:10]print(f" 🏷️ 主要分类: {', '.join(categories)}")def ask_question_with_routing(self, question: str, stream: bool = False, explain_routing: bool = False):"""智能问答:自动选择最佳检索策略"""if not self.system_ready:raise ValueError("系统未就绪,请先构建知识库")print(f"\n❓ 用户问题: {question}")# 显示路由决策解释(可选)if explain_routing:explanation = self.query_router.explain_routing_decision(question)print(explanation)start_time = time.time()try:# 1. 智能路由检索print("执行智能查询路由...")relevant_docs, analysis = self.query_router.route_query(question, self.config.top_k)# 2. 显示路由信息strategy_icons = {"hybrid_traditional": "🔍","graph_rag": "🕸️", "combined": "🔄"}strategy_icon = strategy_icons.get(analysis.recommended_strategy.value, "❓")print(f"{strategy_icon} 使用策略: {analysis.recommended_strategy.value}")print(f"📊 复杂度: {analysis.query_complexity:.2f}, 关系密集度: {analysis.relationship_intensity:.2f}")# 3. 显示检索结果信息if relevant_docs:doc_info = []for doc in relevant_docs:recipe_name = doc.metadata.get('recipe_name', '未知内容')search_type = doc.metadata.get('search_type', doc.metadata.get('route_strategy', 'unknown'))score = doc.metadata.get('final_score', doc.metadata.get('relevance_score', 0))doc_info.append(f"{recipe_name}({search_type}, {score:.3f})")print(f"📋 找到 {len(relevant_docs)} 个相关文档: {', '.join(doc_info[:3])}")if len(doc_info) > 3:print(f" 等 {len(relevant_docs)} 个结果...")else:return "抱歉,没有找到相关的烹饪信息。请尝试其他问题。"# 4. 生成回答print("🎯 智能生成回答...")if stream:try:for chunk_text in self.generation_module.generate_adaptive_answer_stream(question, relevant_docs):print(chunk_text, end="", flush=True)print("\n")result = "流式输出完成"except Exception as stream_error:logger.error(f"流式输出过程中出现错误: {stream_error}")print(f"\n⚠️ 流式输出中断,切换到标准模式...")# 使用非流式作为后备result = self.generation_module.generate_adaptive_answer(question, relevant_docs)else:result = self.generation_module.generate_adaptive_answer(question, relevant_docs)# 5. 性能统计end_time = time.time()print(f"\n⏱️ 问答完成,耗时: {end_time - start_time:.2f}秒")return result, analysisexcept Exception as e:logger.error(f"问答处理失败: {e}")return f"抱歉,处理问题时出现错误:{str(e)}", Nonedef run_interactive(self):"""运行交互式问答"""if not self.system_ready:print("❌ 系统未就绪,请先构建知识库")returnprint("\n欢迎使用尝尝咸淡RAG烹饪助手!")print("可用功能:")print(" - 'stats' : 查看系统统计")print(" - 'rebuild' : 重建知识库")print(" - 'quit' : 退出系统")print("\n" + "="*50)while True:try:user_input = input("\n您的问题: ").strip()if not user_input:continueif user_input.lower() == 'quit':breakelif user_input.lower() == 'stats':self._show_system_stats()continueelif user_input.lower() == 'rebuild':self._rebuild_knowledge_base()continue# 普通问答 - 使用默认设置use_stream = True # 默认使用流式输出explain_routing = False # 默认不显示路由决策print("\n回答:")result, analysis = self.ask_question_with_routing(user_input, stream=use_stream, explain_routing=explain_routing)if not use_stream and result:print(f"{result}\n")except KeyboardInterrupt:breakexcept Exception as e:print(f"处理问题时出错: {e}")import tracebacktraceback.print_exc()print("\n👋 感谢使用尝尝咸淡RAG烹饪助手!")self._cleanup()def _show_system_stats(self):"""显示系统统计信息"""print("\n系统运行统计")print("=" * 40)# 路由统计route_stats = self.query_router.get_route_statistics()total_queries = route_stats.get('total_queries', 0)if total_queries > 0:print(f"总查询次数: {total_queries}")print(f"传统检索: {route_stats.get('traditional_count', 0)} ({route_stats.get('traditional_ratio', 0):.1%})")print(f"图RAG检索: {route_stats.get('graph_rag_count', 0)} ({route_stats.get('graph_rag_ratio', 0):.1%})")print(f"组合策略: {route_stats.get('combined_count', 0)} ({route_stats.get('combined_ratio', 0):.1%})")else:print("暂无查询记录")# 知识库统计self._show_knowledge_base_stats()def _rebuild_knowledge_base(self):"""重建知识库"""print("\n准备重建知识库...")# 确认操作confirm = input("⚠️ 这将删除现有的向量数据并重新构建,是否继续?(y/N): ").strip().lower()if confirm != 'y':print("❌ 重建操作已取消")returntry:print("删除现有的Milvus集合...")if self.index_module.delete_collection():print("✅ 现有集合已删除")else:print("删除集合时出现问题,继续重建...")# 重新构建知识库print("开始重建知识库...")self.build_knowledge_base()print("✅ 知识库重建完成!")except Exception as e:logger.error(f"重建知识库失败: {e}")print(f"❌ 重建失败: {e}")print("建议:请检查Milvus服务状态后重试")def _cleanup(self):"""清理资源"""if self.data_module:self.data_module.close()if self.traditional_retrieval:self.traditional_retrieval.close()if self.graph_rag_retrieval:self.graph_rag_retrieval.close()if self.index_module:self.index_module.close()def main():"""主函数"""try:print("启动高级图RAG系统...")# 创建高级图RAG系统rag_system = AdvancedGraphRAGSystem()# 初始化系统rag_system.initialize_system()# 构建知识库rag_system.build_knowledge_base()# 运行交互式问答rag_system.run_interactive()except Exception as e:logger.error(f"系统运行失败: {e}")import tracebacktraceback.print_exc()print(f"\n❌ 系统错误: {e}")if __name__ == "__main__":main() milvus_index_construction.py
"""
Milvus索引构建模块
"""import logging
import time
from typing import List, Dict, Any, Optionalfrom pymilvus import MilvusClient, DataType, CollectionSchema, FieldSchema
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
import numpy as nplogger = logging.getLogger(__name__)class MilvusIndexConstructionModule:"""Milvus索引构建模块 - 负责向量化和Milvus索引构建"""def __init__(self, host: str = "localhost", port: int = 19530,collection_name: str = "cooking_knowledge",dimension: int = 512,model_name: str = "BAAI/bge-small-zh-v1.5"):"""初始化Milvus索引构建模块Args:host: Milvus服务器地址port: Milvus服务器端口collection_name: 集合名称dimension: 向量维度model_name: 嵌入模型名称"""self.host = hostself.port = portself.collection_name = collection_nameself.dimension = dimensionself.model_name = model_nameself.client = Noneself.embeddings = Noneself.collection_created = Falseself._setup_client()self._setup_embeddings()def _safe_truncate(self, text: str, max_length: int) -> str:"""安全截取字符串,处理None值Args:text: 输入文本max_length: 最大长度Returns:截取后的字符串"""if text is None:return ""return str(text)[:max_length]def _setup_client(self):"""初始化Milvus客户端"""try:self.client = MilvusClient(uri=f"http://{self.host}:{self.port}")logger.info(f"已连接到Milvus服务器: {self.host}:{self.port}")# 测试连接collections = self.client.list_collections()logger.info(f"连接成功,当前集合: {collections}")except Exception as e:logger.error(f"连接Milvus失败: {e}")raisedef _setup_embeddings(self):"""初始化嵌入模型"""logger.info(f"正在初始化嵌入模型: {self.model_name}")self.embeddings = HuggingFaceEmbeddings(model_name=self.model_name,model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True})logger.info("嵌入模型初始化完成")def _create_collection_schema(self) -> CollectionSchema:"""创建集合模式Returns:集合模式对象"""# 定义字段fields = [FieldSchema(name="id", dtype=DataType.VARCHAR, max_length=150, is_primary=True),FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=self.dimension),FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=15000),FieldSchema(name="node_id", dtype=DataType.VARCHAR, max_length=100),FieldSchema(name="recipe_name", dtype=DataType.VARCHAR, max_length=300),FieldSchema(name="node_type", dtype=DataType.VARCHAR, max_length=100),FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=100),FieldSchema(name="cuisine_type", dtype=DataType.VARCHAR, max_length=200),FieldSchema(name="difficulty", dtype=DataType.INT64),FieldSchema(name="doc_type", dtype=DataType.VARCHAR, max_length=50),FieldSchema(name="chunk_id", dtype=DataType.VARCHAR, max_length=150),FieldSchema(name="parent_id", dtype=DataType.VARCHAR, max_length=100)]# 创建集合模式schema = CollectionSchema(fields=fields,description="中式烹饪知识图谱向量集合")return schemadef create_collection(self, force_recreate: bool = False) -> bool:"""创建Milvus集合Args:force_recreate: 是否强制重新创建集合Returns:是否创建成功"""try:# 检查集合是否存在if self.client.has_collection(self.collection_name):if force_recreate:logger.info(f"删除已存在的集合: {self.collection_name}")self.client.drop_collection(self.collection_name)else:logger.info(f"集合 {self.collection_name} 已存在")self.collection_created = Truereturn True# 创建集合schema = self._create_collection_schema()self.client.create_collection(collection_name=self.collection_name,schema=schema,metric_type="COSINE", # 使用余弦相似度consistency_level="Strong")logger.info(f"成功创建集合: {self.collection_name}")self.collection_created = Truereturn Trueexcept Exception as e:logger.error(f"创建集合失败: {e}")return Falsedef create_index(self) -> bool:"""创建向量索引Returns:是否创建成功"""try:if not self.collection_created:raise ValueError("请先创建集合")# 使用prepare_index_params创建正确的IndexParams对象index_params = self.client.prepare_index_params()# 添加向量字段索引index_params.add_index(field_name="vector",index_type="HNSW",metric_type="COSINE",params={"M": 16,"efConstruction": 200})self.client.create_index(collection_name=self.collection_name,index_params=index_params)logger.info("向量索引创建成功")return Trueexcept Exception as e:logger.error(f"创建索引失败: {e}")return Falsedef build_vector_index(self, chunks: List[Document]) -> bool:"""构建向量索引Args:chunks: 文档块列表Returns:是否构建成功"""logger.info(f"正在构建Milvus向量索引,文档数量: {len(chunks)}...")if not chunks:raise ValueError("文档块列表不能为空")try:# 1. 创建集合(如果schema不兼容则强制重新创建)if not self.create_collection(force_recreate=True):return False# 2. 准备数据logger.info("正在生成向量embeddings...")texts = [chunk.page_content for chunk in chunks]vectors = self.embeddings.embed_documents(texts)# 3. 准备插入数据entities = []for i, (chunk, vector) in enumerate(zip(chunks, vectors)):entity = {"id": self._safe_truncate(chunk.metadata.get("chunk_id", f"chunk_{i}"), 150),"vector": vector,"text": self._safe_truncate(chunk.page_content, 15000),"node_id": self._safe_truncate(chunk.metadata.get("node_id", ""), 100),"recipe_name": self._safe_truncate(chunk.metadata.get("recipe_name", ""), 300),"node_type": self._safe_truncate(chunk.metadata.get("node_type", ""), 100),"category": self._safe_truncate(chunk.metadata.get("category", ""), 100),"cuisine_type": self._safe_truncate(chunk.metadata.get("cuisine_type", ""), 200),"difficulty": int(chunk.metadata.get("difficulty", 0)),"doc_type": self._safe_truncate(chunk.metadata.get("doc_type", ""), 50),"chunk_id": self._safe_truncate(chunk.metadata.get("chunk_id", f"chunk_{i}"), 150),"parent_id": self._safe_truncate(chunk.metadata.get("parent_id", ""), 100)}entities.append(entity)# 4. 批量插入数据logger.info("正在插入向量数据...")batch_size = 100for i in range(0, len(entities), batch_size):batch = entities[i:i + batch_size]self.client.insert(collection_name=self.collection_name,data=batch)logger.info(f"已插入 {min(i + batch_size, len(entities))}/{len(entities)} 条数据")# 5. 创建索引if not self.create_index():return False# 6. 加载集合到内存self.client.load_collection(self.collection_name)logger.info("集合已加载到内存")# 7. 等待索引构建完成logger.info("等待索引构建完成...")time.sleep(2)logger.info(f"向量索引构建完成,包含 {len(chunks)} 个向量")return Trueexcept Exception as e:logger.error(f"构建向量索引失败: {e}")return Falsedef add_documents(self, new_chunks: List[Document]) -> bool:"""向现有索引添加新文档Args:new_chunks: 新的文档块列表Returns:是否添加成功"""if not self.collection_created:raise ValueError("请先构建向量索引")logger.info(f"正在添加 {len(new_chunks)} 个新文档到索引...")try:# 生成向量texts = [chunk.page_content for chunk in new_chunks]vectors = self.embeddings.embed_documents(texts)# 准备插入数据entities = []for i, (chunk, vector) in enumerate(zip(new_chunks, vectors)):entity = {"id": self._safe_truncate(chunk.metadata.get("chunk_id", f"new_chunk_{i}_{int(time.time())}"), 150),"vector": vector,"text": self._safe_truncate(chunk.page_content, 15000),"node_id": self._safe_truncate(chunk.metadata.get("node_id", ""), 100),"recipe_name": self._safe_truncate(chunk.metadata.get("recipe_name", ""), 300),"node_type": self._safe_truncate(chunk.metadata.get("node_type", ""), 100),"category": self._safe_truncate(chunk.metadata.get("category", ""), 100),"cuisine_type": self._safe_truncate(chunk.metadata.get("cuisine_type", ""), 200),"difficulty": int(chunk.metadata.get("difficulty", 0)),"doc_type": self._safe_truncate(chunk.metadata.get("doc_type", ""), 50),"chunk_id": self._safe_truncate(chunk.metadata.get("chunk_id", f"new_chunk_{i}_{int(time.time())}"), 150),"parent_id": self._safe_truncate(chunk.metadata.get("parent_id", ""), 100)}entities.append(entity)# 插入数据self.client.insert(collection_name=self.collection_name,data=entities)logger.info("新文档添加完成")return Trueexcept Exception as e:logger.error(f"添加新文档失败: {e}")return Falsedef similarity_search(self, query: str, k: int = 5, filters: Optional[Dict[str, Any]] = None) -> List[Dict[str, Any]]:"""相似度搜索Args:query: 查询文本k: 返回结果数量filters: 过滤条件Returns:搜索结果列表"""if not self.collection_created:raise ValueError("请先构建或加载向量索引")try:# 生成查询向量query_vector = self.embeddings.embed_query(query)# 构建过滤表达式filter_expr = ""if filters:filter_conditions = []for key, value in filters.items():if isinstance(value, str):filter_conditions.append(f'{key} == "{value}"')elif isinstance(value, (int, float)):filter_conditions.append(f'{key} == {value}')elif isinstance(value, list):# 支持IN操作if all(isinstance(v, str) for v in value):value_str = '", "'.join(value)filter_conditions.append(f'{key} in ["{value_str}"]')else:value_str = ', '.join(map(str, value))filter_conditions.append(f'{key} in [{value_str}]')if filter_conditions:filter_expr = " and ".join(filter_conditions)# 执行搜索 - 修复参数传递search_params = {"metric_type": "COSINE","params": {"ef": 64}}# 构建搜索参数,避免重复传递search_kwargs = {"collection_name": self.collection_name,"data": [query_vector],"anns_field": "vector","limit": k,"output_fields": ["text", "node_id", "recipe_name", "node_type", "category", "cuisine_type", "difficulty", "doc_type","chunk_id", "parent_id"],"search_params": search_params}# 只在有过滤条件时添加filter参数if filter_expr:search_kwargs["filter"] = filter_exprresults = self.client.search(**search_kwargs)# 处理结果formatted_results = []if results and len(results) > 0:for hit in results[0]: # results[0]因为我们只发送了一个查询向量result = {"id": hit["id"],"score": hit["distance"], # 注意:在COSINE距离中,值越大相似度越高"text": hit["entity"]["text"],"metadata": {"node_id": hit["entity"]["node_id"],"recipe_name": hit["entity"]["recipe_name"],"node_type": hit["entity"]["node_type"],"category": hit["entity"]["category"],"cuisine_type": hit["entity"]["cuisine_type"],"difficulty": hit["entity"]["difficulty"],"doc_type": hit["entity"]["doc_type"],"chunk_id": hit["entity"]["chunk_id"],"parent_id": hit["entity"]["parent_id"]}}formatted_results.append(result)return formatted_resultsexcept Exception as e:logger.error(f"相似度搜索失败: {e}")return []def get_collection_stats(self) -> Dict[str, Any]:"""获取集合统计信息Returns:统计信息字典"""try:if not self.collection_created:return {"error": "集合未创建"}stats = self.client.get_collection_stats(self.collection_name)return {"collection_name": self.collection_name,"row_count": stats.get("row_count", 0),"index_building_progress": stats.get("index_building_progress", 0),"stats": stats}except Exception as e:logger.error(f"获取集合统计信息失败: {e}")return {"error": str(e)}def delete_collection(self) -> bool:"""删除集合Returns:是否删除成功"""try:if self.client.has_collection(self.collection_name):self.client.drop_collection(self.collection_name)logger.info(f"集合 {self.collection_name} 已删除")self.collection_created = Falsereturn Trueelse:logger.info(f"集合 {self.collection_name} 不存在")return Trueexcept Exception as e:logger.error(f"删除集合失败: {e}")return Falsedef has_collection(self) -> bool:"""检查集合是否存在Returns:集合是否存在"""try:return self.client.has_collection(self.collection_name)except Exception as e:logger.error(f"检查集合存在性失败: {e}")return Falsedef load_collection(self) -> bool:"""加载集合到内存Returns:是否加载成功"""try:if not self.client.has_collection(self.collection_name):logger.error(f"集合 {self.collection_name} 不存在")return Falseself.client.load_collection(self.collection_name)self.collection_created = Truelogger.info(f"集合 {self.collection_name} 已加载到内存")return Trueexcept Exception as e:logger.error(f"加载集合失败: {e}")return Falsedef close(self):"""关闭连接"""if hasattr(self, 'client') and self.client:# Milvus客户端不需要显式关闭logger.info("Milvus连接已关闭")def __del__(self):"""析构函数"""self.close() intelligent_query_router.py
"""
智能查询路由器
根据查询特点自动选择最适合的检索策略:
- 传统混合检索:适合简单的信息查找
- 图RAG检索:适合复杂的关系推理和知识发现
"""import json
import logging
from typing import List, Dict, Tuple, Any, Optional
from dataclasses import dataclass
from enum import Enumfrom langchain_core.documents import Documentlogger = logging.getLogger(__name__)class SearchStrategy(Enum):"""搜索策略枚举"""HYBRID_TRADITIONAL = "hybrid_traditional" # 传统混合检索GRAPH_RAG = "graph_rag" # 图RAG检索COMBINED = "combined" # 组合策略@dataclass
class QueryAnalysis:"""查询分析结果"""query_complexity: float # 查询复杂度 (0-1)relationship_intensity: float # 关系密集度 (0-1)reasoning_required: bool # 是否需要推理entity_count: int # 实体数量recommended_strategy: SearchStrategyconfidence: float # 推荐置信度reasoning: str # 推荐理由class IntelligentQueryRouter:"""智能查询路由器核心能力:1. 查询复杂度分析:识别简单查找 vs 复杂推理2. 关系密集度评估:判断是否需要图结构优势3. 策略自动选择:路由到最适合的检索引擎4. 结果质量监控:基于反馈优化路由决策"""def __init__(self, traditional_retrieval, # 传统混合检索模块graph_rag_retrieval, # 图RAG检索模块llm_client,config):self.traditional_retrieval = traditional_retrievalself.graph_rag_retrieval = graph_rag_retrievalself.llm_client = llm_clientself.config = config# 路由统计self.route_stats = {"traditional_count": 0,"graph_rag_count": 0,"combined_count": 0,"total_queries": 0}def analyze_query(self, query: str) -> QueryAnalysis:"""深度分析查询特征,决定最佳检索策略"""logger.info(f"分析查询特征: {query}")# 使用LLM进行智能分析analysis_prompt = f"""作为RAG系统的查询分析专家,请深度分析以下查询的特征:查询:{query}请从以下维度分析:1. 查询复杂度 (0-1):- 0.0-0.3: 简单信息查找(如:红烧肉怎么做?)- 0.4-0.7: 中等复杂度(如:川菜有哪些特色菜?)- 0.8-1.0: 高复杂度推理(如:为什么川菜用花椒而不是胡椒?)2. 关系密集度 (0-1):- 0.0-0.3: 单一实体信息(如:西红柿的营养价值)- 0.4-0.7: 实体间关系(如:鸡肉配什么蔬菜?)- 0.8-1.0: 复杂关系网络(如:川菜的形成与地理、历史的关系)3. 推理需求:- 是否需要多跳推理?- 是否需要因果分析?- 是否需要对比分析?4. 实体识别:- 查询中包含多少个明确实体?- 实体类型是什么?基于分析推荐检索策略:- hybrid_traditional: 适合简单直接的信息查找- graph_rag: 适合复杂关系推理和知识发现- combined: 需要两种策略结合返回JSON格式:{{"query_complexity": 0.6,"relationship_intensity": 0.8,"reasoning_required": true,"entity_count": 3,"recommended_strategy": "graph_rag","confidence": 0.85,"reasoning": "该查询涉及多个实体间的复杂关系,需要图结构推理"}}"""try:response = self.llm_client.chat.completions.create(model=self.config.llm_model,messages=[{"role": "user", "content": analysis_prompt}],temperature=0.1,max_tokens=800)result = json.loads(response.choices[0].message.content.strip())analysis = QueryAnalysis(query_complexity=result.get("query_complexity", 0.5),relationship_intensity=result.get("relationship_intensity", 0.5),reasoning_required=result.get("reasoning_required", False),entity_count=result.get("entity_count", 1),recommended_strategy=SearchStrategy(result.get("recommended_strategy", "hybrid_traditional")),confidence=result.get("confidence", 0.5),reasoning=result.get("reasoning", "默认分析"))logger.info(f"查询分析完成: {analysis.recommended_strategy.value} (置信度: {analysis.confidence:.2f})")return analysisexcept Exception as e:logger.error(f"查询分析失败: {e}")# 降级方案:基于规则的简单分析return self._rule_based_analysis(query)def _rule_based_analysis(self, query: str) -> QueryAnalysis:"""基于规则的降级分析"""# 简单的规则判断complexity_keywords = ["为什么", "如何", "关系", "影响", "原因", "比较", "区别"]relation_keywords = ["配", "搭配", "组合", "相关", "联系", "连接"]complexity = sum(1 for kw in complexity_keywords if kw in query) / len(complexity_keywords)relation_intensity = sum(1 for kw in relation_keywords if kw in query) / len(relation_keywords)if complexity > 0.3 or relation_intensity > 0.3:strategy = SearchStrategy.GRAPH_RAGelse:strategy = SearchStrategy.HYBRID_TRADITIONALreturn QueryAnalysis(query_complexity=complexity,relationship_intensity=relation_intensity,reasoning_required=complexity > 0.3,entity_count=len(query.split()),recommended_strategy=strategy,confidence=0.6,reasoning="基于规则的简单分析")def route_query(self, query: str, top_k: int = 5) -> Tuple[List[Document], QueryAnalysis]:"""智能路由查询到最适合的检索引擎"""logger.info(f"开始智能路由: {query}")# 1. 分析查询特征analysis = self.analyze_query(query)# 2. 更新统计self._update_route_stats(analysis.recommended_strategy)# 3. 根据策略执行检索documents = []try:if analysis.recommended_strategy == SearchStrategy.HYBRID_TRADITIONAL:logger.info("使用传统混合检索")documents = self.traditional_retrieval.hybrid_search(query, top_k)elif analysis.recommended_strategy == SearchStrategy.GRAPH_RAG:logger.info("🕸️ 使用图RAG检索")documents = self.graph_rag_retrieval.graph_rag_search(query, top_k)elif analysis.recommended_strategy == SearchStrategy.COMBINED:logger.info("🔄 使用组合检索策略")documents = self._combined_search(query, top_k)# 4. 结果后处理documents = self._post_process_results(documents, analysis)logger.info(f"路由完成,返回 {len(documents)} 个结果")return documents, analysisexcept Exception as e:logger.error(f"查询路由失败: {e}")# 降级到传统检索documents = self.traditional_retrieval.hybrid_search(query, top_k)return documents, analysisdef _combined_search(self, query: str, top_k: int) -> List[Document]:"""组合搜索策略:结合传统检索和图RAG的优势"""# 分配结果数量traditional_k = max(1, top_k // 2)graph_k = top_k - traditional_k# 执行两种检索traditional_docs = self.traditional_retrieval.hybrid_search(query, traditional_k)graph_docs = self.graph_rag_retrieval.graph_rag_search(query, graph_k)# 合并和去重combined_docs = []seen_contents = set()# 交替添加结果(Round-robin)max_len = max(len(traditional_docs), len(graph_docs))for i in range(max_len):# 先添加图RAG结果(通常质量更高)if i < len(graph_docs):doc = graph_docs[i]content_hash = hash(doc.page_content[:100])if content_hash not in seen_contents:seen_contents.add(content_hash)doc.metadata["search_source"] = "graph_rag"combined_docs.append(doc)# 再添加传统检索结果if i < len(traditional_docs):doc = traditional_docs[i]content_hash = hash(doc.page_content[:100])if content_hash not in seen_contents:seen_contents.add(content_hash)doc.metadata["search_source"] = "traditional"combined_docs.append(doc)return combined_docs[:top_k]def _post_process_results(self, documents: List[Document], analysis: QueryAnalysis) -> List[Document]:"""结果后处理:根据查询分析优化结果"""for doc in documents:# 添加路由信息到元数据doc.metadata.update({"route_strategy": analysis.recommended_strategy.value,"query_complexity": analysis.query_complexity,"route_confidence": analysis.confidence})return documentsdef _update_route_stats(self, strategy: SearchStrategy):"""更新路由统计"""self.route_stats["total_queries"] += 1if strategy == SearchStrategy.HYBRID_TRADITIONAL:self.route_stats["traditional_count"] += 1elif strategy == SearchStrategy.GRAPH_RAG:self.route_stats["graph_rag_count"] += 1elif strategy == SearchStrategy.COMBINED:self.route_stats["combined_count"] += 1def get_route_statistics(self) -> Dict[str, Any]:"""获取路由统计信息"""total = self.route_stats["total_queries"]if total == 0:return self.route_statsreturn {**self.route_stats,"traditional_ratio": self.route_stats["traditional_count"] / total,"graph_rag_ratio": self.route_stats["graph_rag_count"] / total,"combined_ratio": self.route_stats["combined_count"] / total}def explain_routing_decision(self, query: str) -> str:"""解释路由决策过程"""analysis = self.analyze_query(query)explanation = f"""查询路由分析报告查询:{query}特征分析:- 复杂度:{analysis.query_complexity:.2f} ({'简单' if analysis.query_complexity < 0.4 else '中等' if analysis.query_complexity < 0.8 else '复杂'})- 关系密集度:{analysis.relationship_intensity:.2f} ({'单一实体' if analysis.relationship_intensity < 0.4 else '实体关系' if analysis.relationship_intensity < 0.8 else '复杂关系网络'})- 推理需求:{'是' if analysis.reasoning_required else '否'}- 实体数量:{analysis.entity_count}推荐策略:{analysis.recommended_strategy.value}置信度:{analysis.confidence:.2f}决策理由:{analysis.reasoning}"""return explanationhybrid_retrieval.py
"""
混合检索模块
基于双层检索范式:实体级 + 主题级检索
结合图结构检索和向量检索,使用Round-robin轮询策略
"""import json
import logging
from typing import List, Dict, Tuple, Any
from dataclasses import dataclassfrom langchain_core.documents import Document
from langchain_community.retrievers import BM25Retriever
from neo4j import GraphDatabase
from .graph_indexing import GraphIndexingModulelogger = logging.getLogger(__name__)@dataclass
class RetrievalResult:"""检索结果数据结构"""content: strnode_id: strnode_type: strrelevance_score: floatretrieval_level: str # 'low' or 'high'metadata: Dict[str, Any]class HybridRetrievalModule:"""混合检索模块核心特点:1. 双层检索范式(实体级 + 主题级)2. 关键词提取和匹配3. 图结构+向量检索结合4. 一跳邻居扩展5. Round-robin轮询合并策略"""def __init__(self, config, milvus_module, data_module, llm_client):self.config = configself.milvus_module = milvus_moduleself.data_module = data_moduleself.llm_client = llm_clientself.driver = Noneself.bm25_retriever = None# 图索引模块self.graph_indexing = GraphIndexingModule(config, llm_client)self.graph_indexed = Falsedef initialize(self, chunks: List[Document]):"""初始化检索系统"""logger.info("初始化混合检索模块...")# 连接Neo4jself.driver = GraphDatabase.driver(self.config.neo4j_uri, auth=(self.config.neo4j_user, self.config.neo4j_password))# 初始化BM25检索器if chunks:self.bm25_retriever = BM25Retriever.from_documents(chunks)logger.info(f"BM25检索器初始化完成,文档数量: {len(chunks)}")# 初始化图索引self._build_graph_index()def _build_graph_index(self):"""构建图索引"""if self.graph_indexed:returnlogger.info("开始构建图索引...")try:# 获取图数据recipes = self.data_module.recipesingredients = self.data_module.ingredientscooking_steps = self.data_module.cooking_steps# 创建实体键值对self.graph_indexing.create_entity_key_values(recipes, ingredients, cooking_steps)# 创建关系键值对(这里需要从Neo4j获取关系数据)relationships = self._extract_relationships_from_graph()self.graph_indexing.create_relation_key_values(relationships)# 去重优化self.graph_indexing.deduplicate_entities_and_relations()self.graph_indexed = Truestats = self.graph_indexing.get_statistics()logger.info(f"图索引构建完成: {stats}")except Exception as e:logger.error(f"构建图索引失败: {e}")def _extract_relationships_from_graph(self) -> List[Tuple[str, str, str]]:"""从Neo4j图中提取关系"""relationships = []try:with self.driver.session() as session:query = """MATCH (source)-[r]->(target)WHERE source.nodeId >= '200000000' OR target.nodeId >= '200000000'RETURN source.nodeId as source_id, type(r) as relation_type, target.nodeId as target_idLIMIT 1000"""result = session.run(query)for record in result:relationships.append((record["source_id"],record["relation_type"],record["target_id"]))except Exception as e:logger.error(f"提取图关系失败: {e}")return relationshipsdef extract_query_keywords(self, query: str) -> Tuple[List[str], List[str]]:"""提取查询关键词:实体级 + 主题级"""prompt = f"""作为烹饪知识助手,请分析以下查询并提取关键词,分为两个层次:查询:{query}提取规则:1. 实体级关键词:具体的食材、菜品名称、工具、品牌等有形实体- 例如:鸡胸肉、西兰花、红烧肉、平底锅、老干妈- 对于抽象查询,推测相关的具体食材/菜品2. 主题级关键词:抽象概念、烹饪主题、饮食风格、营养特点等- 例如:减肥、低热量、川菜、素食、下饭菜、快手菜- 排除动作词:推荐、介绍、制作、怎么做等示例:查询:"推荐几个减肥菜" {{"entity_keywords": ["鸡胸肉", "西兰花", "水煮蛋", "胡萝卜", "黄瓜"],"topic_keywords": ["减肥", "低热量", "高蛋白", "低脂"]}}查询:"川菜有什么特色"{{"entity_keywords": ["麻婆豆腐", "宫保鸡丁", "水煮鱼", "辣椒", "花椒"],"topic_keywords": ["川菜", "麻辣", "香辣", "下饭菜"]}}请严格按照JSON格式返回,不要包含多余的文字:{{"entity_keywords": ["实体1", "实体2", ...],"topic_keywords": ["主题1", "主题2", ...]}}"""try:response = self.llm_client.chat.completions.create(model=self.config.llm_model,messages=[{"role": "user", "content": prompt}],temperature=0.1,max_tokens=500)result = json.loads(response.choices[0].message.content.strip())entity_keywords = result.get("entity_keywords", [])topic_keywords = result.get("topic_keywords", [])logger.info(f"关键词提取完成 - 实体级: {entity_keywords}, 主题级: {topic_keywords}")return entity_keywords, topic_keywordsexcept Exception as e:logger.error(f"关键词提取失败: {e}")# 降级方案:简单的关键词分割keywords = query.split()return keywords[:3], keywords[3:6] if len(keywords) > 3 else keywordsdef entity_level_retrieval(self, entity_keywords: List[str], top_k: int = 5) -> List[RetrievalResult]:"""实体级检索:专注于具体实体和关系使用图索引的键值对结构进行检索"""results = []# 1. 使用图索引进行实体检索for keyword in entity_keywords:# 检索匹配的实体entities = self.graph_indexing.get_entities_by_key(keyword)for entity in entities:# 获取邻居信息neighbors = self._get_node_neighbors(entity.metadata["node_id"], max_neighbors=2)# 构建增强内容enhanced_content = entity.value_contentif neighbors:enhanced_content += f"\n相关信息: {', '.join(neighbors)}"results.append(RetrievalResult(content=enhanced_content,node_id=entity.metadata["node_id"],node_type=entity.entity_type,relevance_score=0.9, # 精确匹配得分较高retrieval_level="entity",metadata={"entity_name": entity.entity_name,"entity_type": entity.entity_type,"index_keys": entity.index_keys,"matched_keyword": keyword}))# 2. 如果图索引结果不足,使用Neo4j进行补充检索if len(results) < top_k:neo4j_results = self._neo4j_entity_level_search(entity_keywords, top_k - len(results))results.extend(neo4j_results)# 3. 按相关性排序并返回results.sort(key=lambda x: x.relevance_score, reverse=True)logger.info(f"实体级检索完成,返回 {len(results)} 个结果")return results[:top_k]def _neo4j_entity_level_search(self, keywords: List[str], limit: int) -> List[RetrievalResult]:"""Neo4j补充检索"""results = []try:with self.driver.session() as session:cypher_query = """UNWIND $keywords as keywordCALL db.index.fulltext.queryNodes('recipe_fulltext_index', keyword + '*') YIELD node, scoreWHERE node:RecipeRETURN node.nodeId as node_id,node.name as name,node.description as description,labels(node) as labels,scoreORDER BY score DESCLIMIT $limit"""result = session.run(cypher_query, {"keywords": keywords,"limit": limit})for record in result:content_parts = []if record["name"]:content_parts.append(f"菜品: {record['name']}")if record["description"]:content_parts.append(f"描述: {record['description']}")results.append(RetrievalResult(content='\n'.join(content_parts),node_id=record["node_id"],node_type="Recipe",relevance_score=float(record["score"]) * 0.7, # 补充检索得分较低retrieval_level="entity",metadata={"name": record["name"],"labels": record["labels"],"source": "neo4j_fallback"}))except Exception as e:logger.error(f"Neo4j补充检索失败: {e}")return resultsdef topic_level_retrieval(self, topic_keywords: List[str], top_k: int = 5) -> List[RetrievalResult]:"""主题级检索:专注于广泛主题和概念使用图索引的关系键值对结构进行主题检索"""results = []# 1. 使用图索引进行关系/主题检索for keyword in topic_keywords:# 检索匹配的关系relations = self.graph_indexing.get_relations_by_key(keyword)for relation in relations:# 获取相关实体信息source_entity = self.graph_indexing.entity_kv_store.get(relation.source_entity)target_entity = self.graph_indexing.entity_kv_store.get(relation.target_entity)if source_entity and target_entity:# 构建丰富的主题内容content_parts = [f"主题: {keyword}",relation.value_content,f"相关菜品: {source_entity.entity_name}",f"相关信息: {target_entity.entity_name}"]# 添加源实体的详细信息if source_entity.entity_type == "Recipe":newline = '\n'content_parts.append(f"菜品详情: {source_entity.value_content.split(newline)[0]}")results.append(RetrievalResult(content='\n'.join(content_parts),node_id=relation.source_entity, # 以主要实体为IDnode_type=source_entity.entity_type,relevance_score=0.95, # 主题匹配得分retrieval_level="topic",metadata={"relation_id": relation.relation_id,"relation_type": relation.relation_type,"source_name": source_entity.entity_name,"target_name": target_entity.entity_name,"matched_keyword": keyword,"index_keys": relation.index_keys}))# 2. 使用实体的分类信息进行主题检索for keyword in topic_keywords:entities = self.graph_indexing.get_entities_by_key(keyword)for entity in entities:if entity.entity_type == "Recipe":# 构建分类主题内容content_parts = [f"主题分类: {keyword}",entity.value_content]results.append(RetrievalResult(content='\n'.join(content_parts),node_id=entity.metadata["node_id"],node_type=entity.entity_type,relevance_score=0.85, # 分类匹配得分retrieval_level="topic",metadata={"entity_name": entity.entity_name,"entity_type": entity.entity_type,"matched_keyword": keyword,"source": "category_match"}))# 3. 如果结果不足,使用Neo4j进行补充检索if len(results) < top_k:neo4j_results = self._neo4j_topic_level_search(topic_keywords, top_k - len(results))results.extend(neo4j_results)# 4. 按相关性排序并返回results.sort(key=lambda x: x.relevance_score, reverse=True)logger.info(f"主题级检索完成,返回 {len(results)} 个结果")return results[:top_k]def _neo4j_topic_level_search(self, keywords: List[str], limit: int) -> List[RetrievalResult]:"""Neo4j主题级检索补充"""results = []try:with self.driver.session() as session:cypher_query = """UNWIND $keywords as keywordMATCH (r:Recipe)WHERE r.category CONTAINS keyword OR r.cuisineType CONTAINS keywordOR r.tags CONTAINS keywordWITH r, keywordOPTIONAL MATCH (r)-[:REQUIRES]->(i:Ingredient)WITH r, keyword, collect(i.name)[0..3] as ingredientsRETURN r.nodeId as node_id,r.name as name,r.category as category,r.cuisineType as cuisine_type,r.difficulty as difficulty,ingredients,keyword as matched_keywordORDER BY r.difficulty ASC, r.nameLIMIT $limit"""result = session.run(cypher_query, {"keywords": keywords,"limit": limit})for record in result:content_parts = []content_parts.append(f"菜品: {record['name']}")if record["category"]:content_parts.append(f"分类: {record['category']}")if record["cuisine_type"]:content_parts.append(f"菜系: {record['cuisine_type']}")if record["difficulty"]:content_parts.append(f"难度: {record['difficulty']}")if record["ingredients"]:ingredients_str = ', '.join(record["ingredients"][:3])content_parts.append(f"主要食材: {ingredients_str}")results.append(RetrievalResult(content='\n'.join(content_parts),node_id=record["node_id"],node_type="Recipe",relevance_score=0.75, # 补充检索得分retrieval_level="topic",metadata={"name": record["name"],"category": record["category"],"cuisine_type": record["cuisine_type"],"difficulty": record["difficulty"],"matched_keyword": record["matched_keyword"],"source": "neo4j_fallback"}))except Exception as e:logger.error(f"Neo4j主题级检索失败: {e}")return resultsdef dual_level_retrieval(self, query: str, top_k: int = 5) -> List[Document]:"""双层检索:结合实体级和主题级检索"""logger.info(f"开始双层检索: {query}")# 1. 提取关键词entity_keywords, topic_keywords = self.extract_query_keywords(query)# 2. 执行双层检索entity_results = self.entity_level_retrieval(entity_keywords, top_k)topic_results = self.topic_level_retrieval(topic_keywords, top_k)# 3. 结果合并和排序all_results = entity_results + topic_results# 4. 去重和重排序seen_nodes = set()unique_results = []for result in sorted(all_results, key=lambda x: x.relevance_score, reverse=True):if result.node_id not in seen_nodes:seen_nodes.add(result.node_id)unique_results.append(result)# 5. 转换为Document格式documents = []for result in unique_results[:top_k]:# 确保recipe_name字段正确设置recipe_name = result.metadata.get("name") or result.metadata.get("entity_name", "未知菜品")doc = Document(page_content=result.content,metadata={"node_id": result.node_id,"node_type": result.node_type,"retrieval_level": result.retrieval_level,"relevance_score": result.relevance_score,"recipe_name": recipe_name, # 确保有recipe_name字段"search_type": "dual_level", # 设置搜索类型**result.metadata})documents.append(doc)logger.info(f"双层检索完成,返回 {len(documents)} 个文档")return documentsdef vector_search_enhanced(self, query: str, top_k: int = 5) -> List[Document]:"""增强的向量检索:结合图信息"""try:# 使用Milvus进行向量检索vector_docs = self.milvus_module.similarity_search(query, k=top_k*2)# 用图信息增强结果并转换为Document对象enhanced_docs = []for result in vector_docs:# 从Milvus结果创建Document对象content = result.get("text", "")metadata = result.get("metadata", {})node_id = metadata.get("node_id")if node_id:# 从图中获取邻居信息neighbors = self._get_node_neighbors(node_id)if neighbors:# 将邻居信息添加到内容中neighbor_info = f"\n相关信息: {', '.join(neighbors[:3])}"content += neighbor_info# 确保recipe_name字段正确设置recipe_name = metadata.get("recipe_name", "未知菜品")# 调试:打印向量得分vector_score = result.get("score", 0.0)logger.debug(f"向量检索得分: {recipe_name} = {vector_score}")# 创建Document对象doc = Document(page_content=content,metadata={**metadata,"recipe_name": recipe_name, # 确保有recipe_name字段"score": vector_score,"search_type": "vector_enhanced"})enhanced_docs.append(doc)return enhanced_docs[:top_k]except Exception as e:logger.error(f"增强向量检索失败: {e}")return []def _get_node_neighbors(self, node_id: str, max_neighbors: int = 3) -> List[str]:"""获取节点的邻居信息"""try:with self.driver.session() as session:query = """MATCH (n {nodeId: $node_id})-[r]-(neighbor)RETURN neighbor.name as nameLIMIT $limit"""result = session.run(query, {"node_id": node_id, "limit": max_neighbors})return [record["name"] for record in result if record["name"]]except Exception as e:logger.error(f"获取邻居节点失败: {e}")return []def hybrid_search(self, query: str, top_k: int = 5) -> List[Document]:"""混合检索:使用Round-robin轮询合并策略公平轮询合并不同检索结果,不使用权重配置"""logger.info(f"开始混合检索: {query}")# 1. 双层检索(实体+主题检索)dual_docs = self.dual_level_retrieval(query, top_k)# 2. 增强向量检索vector_docs = self.vector_search_enhanced(query, top_k)# 3. Round-robin轮询合并merged_docs = []seen_doc_ids = set()max_len = max(len(dual_docs), len(vector_docs))origin_len = len(dual_docs) + len(vector_docs)for i in range(max_len):# 先添加双层检索结果if i < len(dual_docs):doc = dual_docs[i]doc_id = doc.metadata.get("node_id", hash(doc.page_content))if doc_id not in seen_doc_ids:seen_doc_ids.add(doc_id)doc.metadata["search_method"] = "dual_level"doc.metadata["round_robin_order"] = len(merged_docs)# 设置统一的final_score字段doc.metadata["final_score"] = doc.metadata.get("relevance_score", 0.0)merged_docs.append(doc)# 再添加向量检索结果if i < len(vector_docs):doc = vector_docs[i]doc_id = doc.metadata.get("node_id", hash(doc.page_content))if doc_id not in seen_doc_ids:seen_doc_ids.add(doc_id)doc.metadata["search_method"] = "vector_enhanced"doc.metadata["round_robin_order"] = len(merged_docs)# 设置统一的final_score字段(向量得分需要转换)vector_score = doc.metadata.get("score", 0.0)# COSINE距离转换为相似度:distance越小,相似度越高similarity_score = max(0.0, 1.0 - vector_score) if vector_score <= 1.0 else 0.0doc.metadata["final_score"] = similarity_scoremerged_docs.append(doc)# 取前top_k个结果final_docs = merged_docs[:top_k]logger.info(f"Round-robin合并:从总共{origin_len}个结果合并为{len(final_docs)}个文档")logger.info(f"混合检索完成,返回 {len(final_docs)} 个文档")return final_docsdef close(self):"""关闭资源连接"""if self.driver:self.driver.close()logger.info("Neo4j连接已关闭") graph_rag_retrieval.py
"""
真正的图RAG检索模块
基于图结构的知识推理和检索,而非简单的关键词匹配
"""import json
import logging
from collections import defaultdict, deque
from typing import List, Dict, Tuple, Any, Optional, Set
from dataclasses import dataclass
from enum import Enumfrom langchain_core.documents import Document
from neo4j import GraphDatabaselogger = logging.getLogger(__name__)class QueryType(Enum):"""查询类型枚举"""ENTITY_RELATION = "entity_relation" # 实体关系查询:A和B有什么关系?MULTI_HOP = "multi_hop" # 多跳查询:A通过什么连接到C?SUBGRAPH = "subgraph" # 子图查询:A相关的所有信息PATH_FINDING = "path_finding" # 路径查找:从A到B的最佳路径CLUSTERING = "clustering" # 聚类查询:和A相似的都有什么?@dataclass
class GraphQuery:"""图查询结构"""query_type: QueryTypesource_entities: List[str]target_entities: List[str] = Nonerelation_types: List[str] = Nonemax_depth: int = 2max_nodes: int = 50constraints: Dict[str, Any] = None@dataclass
class GraphPath:"""图路径结构"""nodes: List[Dict[str, Any]]relationships: List[Dict[str, Any]]path_length: intrelevance_score: floatpath_type: str@dataclass
class KnowledgeSubgraph:"""知识子图结构"""central_nodes: List[Dict[str, Any]]connected_nodes: List[Dict[str, Any]]relationships: List[Dict[str, Any]]graph_metrics: Dict[str, float]reasoning_chains: List[List[str]]class GraphRAGRetrieval:"""真正的图RAG检索系统核心特点:1. 查询意图理解:识别图查询模式2. 多跳图遍历:深度关系探索3. 子图提取:相关知识网络4. 图结构推理:基于拓扑的推理5. 动态查询规划:自适应遍历策略"""def __init__(self, config, llm_client):self.config = configself.llm_client = llm_clientself.driver = None# 图结构缓存self.entity_cache = {}self.relation_cache = {}self.subgraph_cache = {}def initialize(self):"""初始化图RAG检索系统"""logger.info("初始化图RAG检索系统...")# 连接Neo4jtry:self.driver = GraphDatabase.driver(self.config.neo4j_uri, auth=(self.config.neo4j_user, self.config.neo4j_password))# 测试连接with self.driver.session() as session:session.run("RETURN 1")logger.info("Neo4j连接成功")except Exception as e:logger.error(f"Neo4j连接失败: {e}")return# 预热:构建实体和关系索引self._build_graph_index()def _build_graph_index(self):"""构建图索引以加速查询"""logger.info("构建图结构索引...")try:with self.driver.session() as session:# 构建实体索引 - 修复Neo4j语法兼容性问题entity_query = """MATCH (n)WHERE n.nodeId IS NOT NULLWITH n, COUNT { (n)--() } as degreeRETURN labels(n) as node_labels, n.nodeId as node_id, n.name as name, n.category as category, degreeORDER BY degree DESCLIMIT 1000"""result = session.run(entity_query)for record in result:node_id = record["node_id"]self.entity_cache[node_id] = {"labels": record["node_labels"],"name": record["name"],"category": record["category"],"degree": record["degree"]}# 构建关系类型索引relation_query = """MATCH ()-[r]->()RETURN type(r) as rel_type, count(r) as frequencyORDER BY frequency DESC"""result = session.run(relation_query)for record in result:rel_type = record["rel_type"]self.relation_cache[rel_type] = record["frequency"]logger.info(f"索引构建完成: {len(self.entity_cache)}个实体, {len(self.relation_cache)}个关系类型")except Exception as e:logger.error(f"构建图索引失败: {e}")def understand_graph_query(self, query: str) -> GraphQuery:"""理解查询的图结构意图这是图RAG的核心:从自然语言到图查询的转换"""prompt = f"""作为图数据库专家,分析以下查询的图结构意图:查询:{query}请识别:1. 查询类型:- entity_relation: 询问实体间的直接关系(如:鸡肉和胡萝卜能一起做菜吗?)- multi_hop: 需要多跳推理(如:鸡肉配什么蔬菜?需要:鸡肉→菜品→食材→蔬菜)- subgraph: 需要完整子图(如:川菜有什么特色?需要川菜相关的完整知识网络)- path_finding: 路径查找(如:从食材到成品菜的制作路径)- clustering: 聚类相似性(如:和宫保鸡丁类似的菜有哪些?)2. 核心实体:查询中的关键实体名称3. 目标实体:期望找到的实体类型4. 关系类型:涉及的关系类型5. 遍历深度:需要的图遍历深度(1-3跳)示例:查询:"鸡肉配什么蔬菜好?"分析:这是multi_hop查询,需要通过"鸡肉→使用鸡肉的菜品→这些菜品使用的蔬菜"的路径推理返回JSON格式:{{"query_type": "multi_hop","source_entities": ["鸡肉"],"target_entities": ["蔬菜类食材"],"relation_types": ["REQUIRES", "BELONGS_TO_CATEGORY"],"max_depth": 3,"reasoning": "需要多跳推理:鸡肉→菜品→食材→蔬菜"}}"""try:response = self.llm_client.chat.completions.create(model=self.config.llm_model,messages=[{"role": "user", "content": prompt}],temperature=0.1,max_tokens=1000)result = json.loads(response.choices[0].message.content.strip())return GraphQuery(query_type=QueryType(result.get("query_type", "subgraph")),source_entities=result.get("source_entities", []),target_entities=result.get("target_entities", []),relation_types=result.get("relation_types", []),max_depth=result.get("max_depth", 2),max_nodes=50)except Exception as e:logger.error(f"查询意图理解失败: {e}")# 降级方案:默认子图查询return GraphQuery(query_type=QueryType.SUBGRAPH,source_entities=[query],max_depth=2)def multi_hop_traversal(self, graph_query: GraphQuery) -> List[GraphPath]:"""多跳图遍历:这是图RAG的核心优势通过图结构发现隐含的知识关联"""logger.info(f"执行多跳遍历: {graph_query.source_entities} -> {graph_query.target_entities}")paths = []if not self.driver:logger.error("Neo4j连接未建立")return pathstry:with self.driver.session() as session:# 构建多跳遍历查询source_entities = graph_query.source_entitiestarget_entities = graph_query.target_entities or []max_depth = graph_query.max_depth# 根据查询类型选择不同的遍历策略if graph_query.query_type == QueryType.MULTI_HOP:cypher_query = f"""// 多跳推理查询UNWIND $source_entities as source_nameMATCH (source)WHERE source.name CONTAINS source_name OR source.nodeId = source_name// 执行多跳遍历MATCH path = (source)-[*1..{max_depth}]-(target)WHERE NOT source = target{"AND ANY(label IN labels(target) WHERE label IN $target_labels)" if target_entities else ""}// 计算路径相关性WITH path, source, target,length(path) as path_len,relationships(path) as rels,nodes(path) as path_nodes// 路径评分:短路径 + 高度数节点 + 关系类型匹配WITH path, source, target, path_len, rels, path_nodes,(1.0 / path_len) + (REDUCE(s = 0.0, n IN path_nodes | s + COUNT {{ (n)--() }}) / 10.0 / size(path_nodes)) +(CASE WHEN ANY(r IN rels WHERE type(r) IN $relation_types) THEN 0.3 ELSE 0.0 END) as relevanceORDER BY relevance DESCLIMIT 20RETURN path, source, target, path_len, rels, path_nodes, relevance"""result = session.run(cypher_query, {"source_entities": source_entities,"target_labels": target_entities,"relation_types": graph_query.relation_types or []})for record in result:path_data = self._parse_neo4j_path(record)if path_data:paths.append(path_data)elif graph_query.query_type == QueryType.ENTITY_RELATION:# 实体间关系查询paths.extend(self._find_entity_relations(graph_query, session))elif graph_query.query_type == QueryType.PATH_FINDING:# 最短路径查找paths.extend(self._find_shortest_paths(graph_query, session))except Exception as e:logger.error(f"多跳遍历失败: {e}")logger.info(f"多跳遍历完成,找到 {len(paths)} 条路径")return pathsdef extract_knowledge_subgraph(self, graph_query: GraphQuery) -> KnowledgeSubgraph:"""提取知识子图:获取实体相关的完整知识网络这体现了图RAG的整体性思维"""logger.info(f"提取知识子图: {graph_query.source_entities}")if not self.driver:logger.error("Neo4j连接未建立")return self._fallback_subgraph_extraction(graph_query)try:with self.driver.session() as session:# 简化的子图提取(不依赖APOC)cypher_query = f"""// 找到源实体UNWIND $source_entities as entity_nameMATCH (source)WHERE source.name CONTAINS entity_name OR source.nodeId = entity_name// 获取指定深度的邻居MATCH (source)-[r*1..{graph_query.max_depth}]-(neighbor)WITH source, collect(DISTINCT neighbor) as neighbors, collect(DISTINCT r) as relationshipsWHERE size(neighbors) <= $max_nodes// 计算图指标WITH source, neighbors, relationships,size(neighbors) as node_count,size(relationships) as rel_countRETURN source,neighbors[0..{graph_query.max_nodes}] as nodes,relationships[0..{graph_query.max_nodes}] as rels,{{node_count: node_count,relationship_count: rel_count,density: CASE WHEN node_count > 1 THEN toFloat(rel_count) / (node_count * (node_count - 1) / 2) ELSE 0.0 END}} as metrics"""result = session.run(cypher_query, {"source_entities": graph_query.source_entities,"max_nodes": graph_query.max_nodes})record = result.single()if record:return self._build_knowledge_subgraph(record)except Exception as e:logger.error(f"子图提取失败: {e}")# 降级方案:简单邻居查询return self._fallback_subgraph_extraction(graph_query)def graph_structure_reasoning(self, subgraph: KnowledgeSubgraph, query: str) -> List[str]:"""基于图结构的推理:这是图RAG的智能之处不仅检索信息,还能进行逻辑推理"""reasoning_chains = []try:# 1. 识别推理模式reasoning_patterns = self._identify_reasoning_patterns(subgraph)# 2. 构建推理链for pattern in reasoning_patterns:chain = self._build_reasoning_chain(pattern, subgraph)if chain:reasoning_chains.append(chain)# 3. 验证推理链的可信度validated_chains = self._validate_reasoning_chains(reasoning_chains, query)logger.info(f"图结构推理完成,生成 {len(validated_chains)} 条推理链")return validated_chainsexcept Exception as e:logger.error(f"图结构推理失败: {e}")return []def adaptive_query_planning(self, query: str) -> List[GraphQuery]:"""自适应查询规划:根据查询复杂度动态调整策略"""# 分析查询复杂度complexity_score = self._analyze_query_complexity(query)query_plans = []if complexity_score < 0.3:# 简单查询:直接邻居查询plan = GraphQuery(query_type=QueryType.ENTITY_RELATION,source_entities=[query],max_depth=1,max_nodes=20)query_plans.append(plan)elif complexity_score < 0.7:# 中等复杂度:多跳查询plan = GraphQuery(query_type=QueryType.MULTI_HOP,source_entities=[query],max_depth=2,max_nodes=50)query_plans.append(plan)else:# 复杂查询:子图提取 + 推理plan1 = GraphQuery(query_type=QueryType.SUBGRAPH,source_entities=[query],max_depth=3,max_nodes=100)plan2 = GraphQuery(query_type=QueryType.MULTI_HOP,source_entities=[query],max_depth=3,max_nodes=50)query_plans.extend([plan1, plan2])return query_plansdef graph_rag_search(self, query: str, top_k: int = 5) -> List[Document]:"""图RAG主搜索接口:整合所有图RAG能力"""logger.info(f"开始图RAG检索: {query}")if not self.driver:logger.warning("Neo4j连接未建立,返回空结果")return []# 1. 查询意图理解graph_query = self.understand_graph_query(query)logger.info(f"查询类型: {graph_query.query_type.value}")results = []try:# 2. 根据查询类型执行不同策略if graph_query.query_type in [QueryType.MULTI_HOP, QueryType.PATH_FINDING]:# 多跳遍历paths = self.multi_hop_traversal(graph_query)results.extend(self._paths_to_documents(paths, query))elif graph_query.query_type == QueryType.SUBGRAPH:# 子图提取subgraph = self.extract_knowledge_subgraph(graph_query)# 图结构推理reasoning_chains = self.graph_structure_reasoning(subgraph, query)results.extend(self._subgraph_to_documents(subgraph, reasoning_chains, query))elif graph_query.query_type == QueryType.ENTITY_RELATION:# 实体关系查询paths = self.multi_hop_traversal(graph_query)results.extend(self._paths_to_documents(paths, query))# 3. 图结构相关性排序results = self._rank_by_graph_relevance(results, query)logger.info(f"图RAG检索完成,返回 {len(results[:top_k])} 个结果")return results[:top_k]except Exception as e:logger.error(f"图RAG检索失败: {e}")return []# ========== 辅助方法 ==========def _parse_neo4j_path(self, record) -> Optional[GraphPath]:"""解析Neo4j路径记录"""try:path_nodes = []for node in record["path_nodes"]:path_nodes.append({"id": node.get("nodeId", ""),"name": node.get("name", ""),"labels": list(node.labels),"properties": dict(node)})relationships = []for rel in record["rels"]:relationships.append({"type": type(rel).__name__,"properties": dict(rel)})return GraphPath(nodes=path_nodes,relationships=relationships,path_length=record["path_len"],relevance_score=record["relevance"],path_type="multi_hop")except Exception as e:logger.error(f"路径解析失败: {e}")return Nonedef _build_knowledge_subgraph(self, record) -> KnowledgeSubgraph:"""构建知识子图对象"""try:central_nodes = [dict(record["source"])]connected_nodes = [dict(node) for node in record["nodes"]]relationships = [dict(rel) for rel in record["rels"]]return KnowledgeSubgraph(central_nodes=central_nodes,connected_nodes=connected_nodes,relationships=relationships,graph_metrics=record["metrics"],reasoning_chains=[])except Exception as e:logger.error(f"构建知识子图失败: {e}")return KnowledgeSubgraph(central_nodes=[],connected_nodes=[],relationships=[],graph_metrics={},reasoning_chains=[])def _paths_to_documents(self, paths: List[GraphPath], query: str) -> List[Document]:"""将图路径转换为Document对象"""documents = []for i, path in enumerate(paths):# 构建路径描述path_desc = self._build_path_description(path)doc = Document(page_content=path_desc,metadata={"search_type": "graph_path","path_length": path.path_length,"relevance_score": path.relevance_score,"path_type": path.path_type,"node_count": len(path.nodes),"relationship_count": len(path.relationships),"recipe_name": path.nodes[0].get("name", "图结构结果") if path.nodes else "图结构结果"})documents.append(doc)return documentsdef _subgraph_to_documents(self, subgraph: KnowledgeSubgraph, reasoning_chains: List[str], query: str) -> List[Document]:"""将知识子图转换为Document对象"""documents = []# 子图整体描述subgraph_desc = self._build_subgraph_description(subgraph)doc = Document(page_content=subgraph_desc,metadata={"search_type": "knowledge_subgraph","node_count": len(subgraph.connected_nodes),"relationship_count": len(subgraph.relationships),"graph_density": subgraph.graph_metrics.get("density", 0.0),"reasoning_chains": reasoning_chains,"recipe_name": subgraph.central_nodes[0].get("name", "知识子图") if subgraph.central_nodes else "知识子图"})documents.append(doc)return documentsdef _build_path_description(self, path: GraphPath) -> str:"""构建路径的自然语言描述"""if not path.nodes:return "空路径"desc_parts = []for i, node in enumerate(path.nodes):desc_parts.append(node.get("name", f"节点{i}"))if i < len(path.relationships):rel_type = path.relationships[i].get("type", "相关")desc_parts.append(f" --{rel_type}--> ")return "".join(desc_parts)def _build_subgraph_description(self, subgraph: KnowledgeSubgraph) -> str:"""构建子图的自然语言描述"""central_names = [node.get("name", "未知") for node in subgraph.central_nodes]node_count = len(subgraph.connected_nodes)rel_count = len(subgraph.relationships)return f"关于 {', '.join(central_names)} 的知识网络,包含 {node_count} 个相关概念和 {rel_count} 个关系。"def _rank_by_graph_relevance(self, documents: List[Document], query: str) -> List[Document]:"""基于图结构相关性排序"""return sorted(documents, key=lambda x: x.metadata.get("relevance_score", 0.0), reverse=True)def _analyze_query_complexity(self, query: str) -> float:"""分析查询复杂度"""complexity_indicators = ["什么", "如何", "为什么", "哪些", "关系", "影响", "原因"]score = sum(1 for indicator in complexity_indicators if indicator in query)return min(score / len(complexity_indicators), 1.0)def _identify_reasoning_patterns(self, subgraph: KnowledgeSubgraph) -> List[str]:"""识别推理模式"""return ["因果关系", "组成关系", "相似关系"]def _build_reasoning_chain(self, pattern: str, subgraph: KnowledgeSubgraph) -> Optional[str]:"""构建推理链"""return f"基于{pattern}的推理链"def _validate_reasoning_chains(self, chains: List[str], query: str) -> List[str]:"""验证推理链"""return chains[:3]def _find_entity_relations(self, graph_query: GraphQuery, session) -> List[GraphPath]:"""查找实体间关系"""return []def _find_shortest_paths(self, graph_query: GraphQuery, session) -> List[GraphPath]:"""查找最短路径"""return []def _fallback_subgraph_extraction(self, graph_query: GraphQuery) -> KnowledgeSubgraph:"""降级子图提取"""return KnowledgeSubgraph(central_nodes=[],connected_nodes=[],relationships=[],graph_metrics={},reasoning_chains=[])def close(self):"""关闭资源连接"""if hasattr(self, 'driver') and self.driver:self.driver.close()logger.info("图RAG检索系统已关闭") graph_indexing.py
"""
图索引模块
实现实体和关系的键值对结构 (K,V)
K: 索引键(简短词汇或短语)
V: 详细描述段落(包含相关文本片段)
"""import json
import logging
from typing import Dict, List, Tuple, Any, Optional
from dataclasses import dataclass
from collections import defaultdictfrom langchain_core.documents import Documentlogger = logging.getLogger(__name__)@dataclass
class EntityKeyValue:"""实体键值对"""entity_name: strindex_keys: List[str] # 索引键列表value_content: str # 详细描述内容entity_type: str # 实体类型 (Recipe, Ingredient, CookingStep)metadata: Dict[str, Any]@dataclass
class RelationKeyValue:"""关系键值对"""relation_id: strindex_keys: List[str] # 多个索引键(可包含全局主题)value_content: str # 关系描述内容relation_type: str # 关系类型source_entity: str # 源实体target_entity: str # 目标实体metadata: Dict[str, Any]class GraphIndexingModule:"""图索引模块核心功能:1. 为实体创建键值对(名称作为唯一索引键)2. 为关系创建键值对(多个索引键,包含全局主题)3. 去重和优化图操作4. 支持增量更新"""def __init__(self, config, llm_client):self.config = configself.llm_client = llm_client# 键值对存储self.entity_kv_store: Dict[str, EntityKeyValue] = {}self.relation_kv_store: Dict[str, RelationKeyValue] = {}# 索引映射:key -> entity/relation IDsself.key_to_entities: Dict[str, List[str]] = defaultdict(list)self.key_to_relations: Dict[str, List[str]] = defaultdict(list)def create_entity_key_values(self, recipes: List[Any], ingredients: List[Any], cooking_steps: List[Any]) -> Dict[str, EntityKeyValue]:"""为实体创建键值对结构每个实体使用其名称作为唯一索引键"""logger.info("开始创建实体键值对...")# 处理菜谱实体for recipe in recipes:entity_id = recipe.node_identity_name = recipe.name or f"菜谱_{entity_id}"# 构建详细内容content_parts = [f"菜品名称: {entity_name}"]if hasattr(recipe, 'properties'):props = recipe.propertiesif props.get('description'):content_parts.append(f"描述: {props['description']}")if props.get('category'):content_parts.append(f"分类: {props['category']}")if props.get('cuisineType'):content_parts.append(f"菜系: {props['cuisineType']}")if props.get('difficulty'):content_parts.append(f"难度: {props['difficulty']}")if props.get('cookingTime'):content_parts.append(f"制作时间: {props['cookingTime']}")# 创建键值对entity_kv = EntityKeyValue(entity_name=entity_name,index_keys=[entity_name], # 使用名称作为唯一索引键value_content='\n'.join(content_parts),entity_type="Recipe",metadata={"node_id": entity_id,"properties": getattr(recipe, 'properties', {})})self.entity_kv_store[entity_id] = entity_kvself.key_to_entities[entity_name].append(entity_id)# 处理食材实体for ingredient in ingredients:entity_id = ingredient.node_identity_name = ingredient.name or f"食材_{entity_id}"content_parts = [f"食材名称: {entity_name}"]if hasattr(ingredient, 'properties'):props = ingredient.propertiesif props.get('category'):content_parts.append(f"类别: {props['category']}")if props.get('nutrition'):content_parts.append(f"营养信息: {props['nutrition']}")if props.get('storage'):content_parts.append(f"储存方式: {props['storage']}")entity_kv = EntityKeyValue(entity_name=entity_name,index_keys=[entity_name],value_content='\n'.join(content_parts),entity_type="Ingredient",metadata={"node_id": entity_id,"properties": getattr(ingredient, 'properties', {})})self.entity_kv_store[entity_id] = entity_kvself.key_to_entities[entity_name].append(entity_id)# 处理烹饪步骤实体for step in cooking_steps:entity_id = step.node_identity_name = f"步骤_{entity_id}"content_parts = [f"烹饪步骤: {entity_name}"]if hasattr(step, 'properties'):props = step.propertiesif props.get('description'):content_parts.append(f"步骤描述: {props['description']}")if props.get('order'):content_parts.append(f"步骤顺序: {props['order']}")if props.get('technique'):content_parts.append(f"技巧: {props['technique']}")if props.get('time'):content_parts.append(f"时间: {props['time']}")entity_kv = EntityKeyValue(entity_name=entity_name,index_keys=[entity_name],value_content='\n'.join(content_parts),entity_type="CookingStep", metadata={"node_id": entity_id,"properties": getattr(step, 'properties', {})})self.entity_kv_store[entity_id] = entity_kvself.key_to_entities[entity_name].append(entity_id)logger.info(f"实体键值对创建完成,共 {len(self.entity_kv_store)} 个实体")return self.entity_kv_storedef create_relation_key_values(self, relationships: List[Tuple[str, str, str]]) -> Dict[str, RelationKeyValue]:"""为关系创建键值对结构关系可能有多个索引键,包含从LLM增强的全局主题"""logger.info("开始创建关系键值对...")for i, (source_id, relation_type, target_id) in enumerate(relationships):relation_id = f"rel_{i}_{source_id}_{target_id}"# 获取源实体和目标实体信息source_entity = self.entity_kv_store.get(source_id)target_entity = self.entity_kv_store.get(target_id)if not source_entity or not target_entity:continue# 构建关系描述content_parts = [f"关系类型: {relation_type}",f"源实体: {source_entity.entity_name} ({source_entity.entity_type})",f"目标实体: {target_entity.entity_name} ({target_entity.entity_type})"]# 生成多个索引键(包含全局主题)index_keys = self._generate_relation_index_keys(source_entity, target_entity, relation_type)# 创建关系键值对relation_kv = RelationKeyValue(relation_id=relation_id,index_keys=index_keys,value_content='\n'.join(content_parts),relation_type=relation_type,source_entity=source_id,target_entity=target_id,metadata={"source_name": source_entity.entity_name,"target_name": target_entity.entity_name,"created_from_graph": True})self.relation_kv_store[relation_id] = relation_kv# 为每个索引键建立映射for key in index_keys:self.key_to_relations[key].append(relation_id)logger.info(f"关系键值对创建完成,共 {len(self.relation_kv_store)} 个关系")return self.relation_kv_storedef _generate_relation_index_keys(self, source_entity: EntityKeyValue, target_entity: EntityKeyValue, relation_type: str) -> List[str]:"""为关系生成多个索引键,包含全局主题"""keys = [relation_type] # 基础关系类型键# 根据关系类型和实体类型生成主题键if relation_type == "REQUIRES":# 菜谱-食材关系的主题键keys.extend(["食材搭配","烹饪原料",f"{source_entity.entity_name}_食材",target_entity.entity_name])elif relation_type == "HAS_STEP":# 菜谱-步骤关系的主题键keys.extend(["制作步骤","烹饪过程",f"{source_entity.entity_name}_步骤","制作方法"])elif relation_type == "BELONGS_TO_CATEGORY":# 分类关系的主题键keys.extend(["菜品分类","美食类别",target_entity.entity_name])# 使用LLM增强关系索引键(可选)if getattr(self.config, 'enable_llm_relation_keys', False):enhanced_keys = self._llm_enhance_relation_keys(source_entity, target_entity, relation_type)keys.extend(enhanced_keys)# 去重并返回return list(set(keys))def _llm_enhance_relation_keys(self, source_entity: EntityKeyValue, target_entity: EntityKeyValue, relation_type: str) -> List[str]:"""使用LLM增强关系索引键,生成全局主题"""prompt = f"""分析以下实体关系,生成相关的主题关键词:源实体: {source_entity.entity_name} ({source_entity.entity_type})目标实体: {target_entity.entity_name} ({target_entity.entity_type})关系类型: {relation_type}请生成3-5个相关的主题关键词,用于索引和检索。返回JSON格式:{{"keywords": ["关键词1", "关键词2", "关键词3"]}}"""try:response = self.llm_client.chat.completions.create(model=self.config.llm_model,messages=[{"role": "user", "content": prompt}],temperature=0.1,max_tokens=200)result = json.loads(response.choices[0].message.content.strip())return result.get("keywords", [])except Exception as e:logger.error(f"LLM增强关系索引键失败: {e}")return []def deduplicate_entities_and_relations(self):"""去重相同的实体和关系,优化图操作"""logger.info("开始去重实体和关系...")# 实体去重:基于名称name_to_entities = defaultdict(list)for entity_id, entity_kv in self.entity_kv_store.items():name_to_entities[entity_kv.entity_name].append(entity_id)# 合并重复实体entities_to_remove = []for name, entity_ids in name_to_entities.items():if len(entity_ids) > 1:# 保留第一个,合并其他的内容primary_id = entity_ids[0]primary_entity = self.entity_kv_store[primary_id]for entity_id in entity_ids[1:]:duplicate_entity = self.entity_kv_store[entity_id]# 合并内容primary_entity.value_content += f"\n\n补充信息: {duplicate_entity.value_content}"# 标记删除entities_to_remove.append(entity_id)# 删除重复实体for entity_id in entities_to_remove:del self.entity_kv_store[entity_id]# 关系去重:基于源-目标-类型relation_signature_to_ids = defaultdict(list)for relation_id, relation_kv in self.relation_kv_store.items():signature = f"{relation_kv.source_entity}_{relation_kv.target_entity}_{relation_kv.relation_type}"relation_signature_to_ids[signature].append(relation_id)# 合并重复关系relations_to_remove = []for signature, relation_ids in relation_signature_to_ids.items():if len(relation_ids) > 1:# 保留第一个,删除其他for relation_id in relation_ids[1:]:relations_to_remove.append(relation_id)# 删除重复关系for relation_id in relations_to_remove:del self.relation_kv_store[relation_id]# 重建索引映射self._rebuild_key_mappings()logger.info(f"去重完成 - 删除了 {len(entities_to_remove)} 个重复实体,{len(relations_to_remove)} 个重复关系")def _rebuild_key_mappings(self):"""重建键到实体/关系的映射"""self.key_to_entities.clear()self.key_to_relations.clear()# 重建实体映射for entity_id, entity_kv in self.entity_kv_store.items():for key in entity_kv.index_keys:self.key_to_entities[key].append(entity_id)# 重建关系映射for relation_id, relation_kv in self.relation_kv_store.items():for key in relation_kv.index_keys:self.key_to_relations[key].append(relation_id)def get_entities_by_key(self, key: str) -> List[EntityKeyValue]:"""根据索引键获取实体"""entity_ids = self.key_to_entities.get(key, [])return [self.entity_kv_store[eid] for eid in entity_ids if eid in self.entity_kv_store]def get_relations_by_key(self, key: str) -> List[RelationKeyValue]:"""根据索引键获取关系"""relation_ids = self.key_to_relations.get(key, [])return [self.relation_kv_store[rid] for rid in relation_ids if rid in self.relation_kv_store]def get_statistics(self) -> Dict[str, Any]:"""获取键值对存储统计信息"""return {"total_entities": len(self.entity_kv_store),"total_relations": len(self.relation_kv_store),"total_entity_keys": sum(len(kv.index_keys) for kv in self.entity_kv_store.values()),"total_relation_keys": sum(len(kv.index_keys) for kv in self.relation_kv_store.values()),"entity_types": {"Recipe": len([kv for kv in self.entity_kv_store.values() if kv.entity_type == "Recipe"]),"Ingredient": len([kv for kv in self.entity_kv_store.values() if kv.entity_type == "Ingredient"]),"CookingStep": len([kv for kv in self.entity_kv_store.values() if kv.entity_type == "CookingStep"])}} graph_data_preparation.py
"""
图数据库数据准备模块
"""import logging
import json
from typing import List, Dict, Any, Optional
from dataclasses import dataclassfrom neo4j import GraphDatabase
from langchain_core.documents import Documentlogger = logging.getLogger(__name__)@dataclass
class GraphNode:"""图节点数据结构"""node_id: strlabels: List[str]name: strproperties: Dict[str, Any]@dataclass
class GraphRelation:"""图关系数据结构"""start_node_id: strend_node_id: strrelation_type: strproperties: Dict[str, Any]class GraphDataPreparationModule:"""图数据库数据准备模块 - 从Neo4j读取数据并转换为文档"""def __init__(self, uri: str, user: str, password: str, database: str = "neo4j"):"""初始化图数据库连接Args:uri: Neo4j连接URIuser: 用户名password: 密码database: 数据库名称"""self.uri = uriself.user = userself.password = passwordself.database = databaseself.driver = Noneself.documents: List[Document] = []self.chunks: List[Document] = []self.recipes: List[GraphNode] = []self.ingredients: List[GraphNode] = []self.cooking_steps: List[GraphNode] = []self._connect()def _connect(self):"""建立Neo4j连接"""try:self.driver = GraphDatabase.driver(self.uri, auth=(self.user, self.password),database=self.database)logger.info(f"已连接到Neo4j数据库: {self.uri}")# 测试连接with self.driver.session() as session:result = session.run("RETURN 1 as test")test_result = result.single()if test_result:logger.info("Neo4j连接测试成功")except Exception as e:logger.error(f"连接Neo4j失败: {e}")raisedef close(self):"""关闭数据库连接"""if hasattr(self, 'driver') and self.driver:self.driver.close()logger.info("Neo4j连接已关闭")def load_graph_data(self) -> Dict[str, Any]:"""从Neo4j加载图数据Returns:包含节点和关系的数据字典"""logger.info("正在从Neo4j加载图数据...")with self.driver.session() as session:# 加载所有菜谱节点,从Category关系中读取分类信息recipes_query = """MATCH (r:Recipe)WHERE r.nodeId >= '200000000'OPTIONAL MATCH (r)-[:BELONGS_TO_CATEGORY]->(c:Category)WITH r, collect(c.name) as categoriesRETURN r.nodeId as nodeId, labels(r) as labels, r.name as name, properties(r) as originalProperties,CASE WHEN size(categories) > 0 THEN categories[0] ELSE COALESCE(r.category, '未知') END as mainCategory,CASE WHEN size(categories) > 0 THEN categories ELSE [COALESCE(r.category, '未知')] END as allCategoriesORDER BY r.nodeId"""result = session.run(recipes_query)self.recipes = []for record in result:# 合并原始属性和新的分类信息properties = dict(record["originalProperties"])properties["category"] = record["mainCategory"]properties["all_categories"] = record["allCategories"]node = GraphNode(node_id=record["nodeId"],labels=record["labels"],name=record["name"],properties=properties)self.recipes.append(node)logger.info(f"加载了 {len(self.recipes)} 个菜谱节点")# 加载所有食材节点ingredients_query = """MATCH (i:Ingredient)WHERE i.nodeId >= '200000000'RETURN i.nodeId as nodeId, labels(i) as labels, i.name as name,properties(i) as propertiesORDER BY i.nodeId"""result = session.run(ingredients_query)self.ingredients = []for record in result:node = GraphNode(node_id=record["nodeId"],labels=record["labels"],name=record["name"],properties=record["properties"])self.ingredients.append(node)logger.info(f"加载了 {len(self.ingredients)} 个食材节点")# 加载所有烹饪步骤节点steps_query = """MATCH (s:CookingStep)WHERE s.nodeId >= '200000000'RETURN s.nodeId as nodeId, labels(s) as labels, s.name as name,properties(s) as propertiesORDER BY s.nodeId"""result = session.run(steps_query)self.cooking_steps = []for record in result:node = GraphNode(node_id=record["nodeId"],labels=record["labels"],name=record["name"],properties=record["properties"])self.cooking_steps.append(node)logger.info(f"加载了 {len(self.cooking_steps)} 个烹饪步骤节点")return {'recipes': len(self.recipes),'ingredients': len(self.ingredients),'cooking_steps': len(self.cooking_steps)}def build_recipe_documents(self) -> List[Document]:"""构建菜谱文档,集成相关的食材和步骤信息Returns:结构化的菜谱文档列表"""logger.info("正在构建菜谱文档...")documents = []with self.driver.session() as session:for recipe in self.recipes:try:recipe_id = recipe.node_idrecipe_name = recipe.name# 获取菜谱的相关食材ingredients_query = """MATCH (r:Recipe {nodeId: $recipe_id})-[req:REQUIRES]->(i:Ingredient)RETURN i.name as name, i.category as category, req.amount as amount, req.unit as unit,i.description as descriptionORDER BY i.name"""ingredients_result = session.run(ingredients_query, {"recipe_id": recipe_id})ingredients_info = []for ing_record in ingredients_result:amount = ing_record.get("amount", "")unit = ing_record.get("unit", "")ingredient_text = f"{ing_record['name']}"if amount and unit:ingredient_text += f"({amount}{unit})"if ing_record.get("description"):ingredient_text += f" - {ing_record['description']}"ingredients_info.append(ingredient_text)# 获取菜谱的烹饪步骤steps_query = """MATCH (r:Recipe {nodeId: $recipe_id})-[c:CONTAINS_STEP]->(s:CookingStep)RETURN s.name as name, s.description as description,s.stepNumber as stepNumber, s.methods as methods,s.tools as tools, s.timeEstimate as timeEstimate,c.stepOrder as stepOrderORDER BY COALESCE(c.stepOrder, s.stepNumber, 999)"""steps_result = session.run(steps_query, {"recipe_id": recipe_id})steps_info = []for step_record in steps_result:step_text = f"步骤: {step_record['name']}"if step_record.get("description"):step_text += f"\n描述: {step_record['description']}"if step_record.get("methods"):step_text += f"\n方法: {step_record['methods']}"if step_record.get("tools"):step_text += f"\n工具: {step_record['tools']}"if step_record.get("timeEstimate"):step_text += f"\n时间: {step_record['timeEstimate']}"steps_info.append(step_text)# 构建完整的菜谱文档内容content_parts = [f"# {recipe_name}"]# 添加菜谱基本信息if recipe.properties.get("description"):content_parts.append(f"\n## 菜品描述\n{recipe.properties['description']}")if recipe.properties.get("cuisineType"):content_parts.append(f"\n菜系: {recipe.properties['cuisineType']}")if recipe.properties.get("difficulty"):content_parts.append(f"难度: {recipe.properties['difficulty']}星")if recipe.properties.get("prepTime") or recipe.properties.get("cookTime"):time_info = []if recipe.properties.get("prepTime"):time_info.append(f"准备时间: {recipe.properties['prepTime']}")if recipe.properties.get("cookTime"):time_info.append(f"烹饪时间: {recipe.properties['cookTime']}")content_parts.append(f"\n时间信息: {', '.join(time_info)}")if recipe.properties.get("servings"):content_parts.append(f"份量: {recipe.properties['servings']}")# 添加食材信息if ingredients_info:content_parts.append("\n## 所需食材")for i, ingredient in enumerate(ingredients_info, 1):content_parts.append(f"{i}. {ingredient}")# 添加步骤信息if steps_info:content_parts.append("\n## 制作步骤")for i, step in enumerate(steps_info, 1):content_parts.append(f"\n### 第{i}步\n{step}")# 添加标签信息if recipe.properties.get("tags"):content_parts.append(f"\n## 标签\n{recipe.properties['tags']}")# 组合成最终内容full_content = "\n".join(content_parts)# 创建文档对象doc = Document(page_content=full_content,metadata={"node_id": recipe_id,"recipe_name": recipe_name,"node_type": "Recipe","category": recipe.properties.get("category", "未知"),"cuisine_type": recipe.properties.get("cuisineType", "未知"),"difficulty": recipe.properties.get("difficulty", 0),"prep_time": recipe.properties.get("prepTime", ""),"cook_time": recipe.properties.get("cookTime", ""),"servings": recipe.properties.get("servings", ""),"ingredients_count": len(ingredients_info),"steps_count": len(steps_info),"doc_type": "recipe","content_length": len(full_content)})documents.append(doc)except Exception as e:logger.warning(f"构建菜谱文档失败 {recipe_name} (ID: {recipe_id}): {e}")continueself.documents = documentslogger.info(f"成功构建 {len(documents)} 个菜谱文档")return documentsdef chunk_documents(self, chunk_size: int = 500, chunk_overlap: int = 50) -> List[Document]:"""对文档进行分块处理Args:chunk_size: 分块大小chunk_overlap: 重叠大小Returns:分块后的文档列表"""logger.info(f"正在进行文档分块,块大小: {chunk_size}, 重叠: {chunk_overlap}")if not self.documents:raise ValueError("请先构建文档")chunks = []chunk_id = 0for doc in self.documents:content = doc.page_content# 简单的按长度分块if len(content) <= chunk_size:# 内容较短,不需要分块chunk = Document(page_content=content,metadata={**doc.metadata,"chunk_id": f"{doc.metadata['node_id']}_chunk_{chunk_id}","parent_id": doc.metadata["node_id"],"chunk_index": 0,"total_chunks": 1,"chunk_size": len(content),"doc_type": "chunk"})chunks.append(chunk)chunk_id += 1else:# 按章节分块(基于标题)sections = content.split('\n## ')if len(sections) <= 1:# 没有二级标题,按长度强制分块total_chunks = (len(content) - 1) // (chunk_size - chunk_overlap) + 1for i in range(total_chunks):start = i * (chunk_size - chunk_overlap)end = min(start + chunk_size, len(content))chunk_content = content[start:end]chunk = Document(page_content=chunk_content,metadata={**doc.metadata,"chunk_id": f"{doc.metadata['node_id']}_chunk_{chunk_id}","parent_id": doc.metadata["node_id"],"chunk_index": i,"total_chunks": total_chunks,"chunk_size": len(chunk_content),"doc_type": "chunk"})chunks.append(chunk)chunk_id += 1else:# 按章节分块total_chunks = len(sections)for i, section in enumerate(sections):if i == 0:# 第一个部分包含标题chunk_content = sectionelse:# 其他部分添加章节标题chunk_content = f"## {section}"chunk = Document(page_content=chunk_content,metadata={**doc.metadata,"chunk_id": f"{doc.metadata['node_id']}_chunk_{chunk_id}","parent_id": doc.metadata["node_id"],"chunk_index": i,"total_chunks": total_chunks,"chunk_size": len(chunk_content),"doc_type": "chunk","section_title": section.split('\n')[0] if i > 0 else "主标题"})chunks.append(chunk)chunk_id += 1self.chunks = chunkslogger.info(f"文档分块完成,共生成 {len(chunks)} 个块")return chunksdef get_statistics(self) -> Dict[str, Any]:"""获取数据统计信息Returns:统计信息字典"""stats = {'total_recipes': len(self.recipes),'total_ingredients': len(self.ingredients),'total_cooking_steps': len(self.cooking_steps),'total_documents': len(self.documents),'total_chunks': len(self.chunks)}if self.documents:# 分类统计categories = {}cuisines = {}difficulties = {}for doc in self.documents:category = doc.metadata.get('category', '未知')categories[category] = categories.get(category, 0) + 1cuisine = doc.metadata.get('cuisine_type', '未知')cuisines[cuisine] = cuisines.get(cuisine, 0) + 1difficulty = doc.metadata.get('difficulty', 0)difficulties[str(difficulty)] = difficulties.get(str(difficulty), 0) + 1stats.update({'categories': categories,'cuisines': cuisines,'difficulties': difficulties,'avg_content_length': sum(doc.metadata.get('content_length', 0) for doc in self.documents) / len(self.documents),'avg_chunk_size': sum(chunk.metadata.get('chunk_size', 0) for chunk in self.chunks) / len(self.chunks) if self.chunks else 0})return statsdef __del__(self):"""析构函数,确保关闭连接"""self.close() generation_integration.py
"""
生成集成模块
"""import logging
import os
import time
from typing import Listfrom openai import OpenAI
from langchain_core.documents import Documentlogger = logging.getLogger(__name__)class GenerationIntegrationModule:"""生成集成模块 - 负责答案生成"""def __init__(self, model_name: str = "kimi-k2-0711-preview", temperature: float = 0.1, max_tokens: int = 2048):"""初始化生成集成模块"""self.model_name = model_nameself.temperature = temperatureself.max_tokens = max_tokens# 初始化OpenAI客户端(使用Moonshot API)api_key = os.getenv("MOONSHOT_API_KEY")if not api_key:raise ValueError("请设置 MOONSHOT_API_KEY 环境变量")self.client = OpenAI(api_key=api_key,base_url="https://api.moonshot.cn/v1")logger.info(f"生成模块初始化完成,模型: {model_name}")def generate_adaptive_answer(self, question: str, documents: List[Document]) -> str:"""智能统一答案生成自动适应不同类型的查询,无需预先分类"""# 构建上下文context_parts = []for doc in documents:content = doc.page_content.strip()if content:# 添加检索层级信息(如果有的话)level = doc.metadata.get('retrieval_level', '')if level:context_parts.append(f"[{level.upper()}] {content}")else:context_parts.append(content)context = "\n\n".join(context_parts)# LightRAG风格的统一提示词prompt = f"""作为一位专业的烹饪助手,请基于以下信息回答用户的问题。检索到的相关信息:{context}用户问题:{question}请提供准确、实用的回答。根据问题的性质:- 如果是询问多个菜品,请提供清晰的列表- 如果是询问具体制作方法,请提供详细步骤- 如果是一般性咨询,请提供综合性回答回答:"""try:response = self.client.chat.completions.create(model=self.model_name,messages=[{"role": "user", "content": prompt}],temperature=self.temperature,max_tokens=self.max_tokens)return response.choices[0].message.content.strip()except Exception as e:logger.error(f"LightRAG答案生成失败: {e}")return f"抱歉,生成回答时出现错误:{str(e)}"def generate_adaptive_answer_stream(self, question: str, documents: List[Document], max_retries: int = 3):"""LightRAG风格的流式答案生成(带重试机制)"""# 构建上下文context_parts = []for doc in documents:content = doc.page_content.strip()if content:level = doc.metadata.get('retrieval_level', '')if level:context_parts.append(f"[{level.upper()}] {content}")else:context_parts.append(content)context = "\n\n".join(context_parts)# LightRAG风格的统一提示词prompt = f"""作为一位专业的烹饪助手,请基于以下信息回答用户的问题。检索到的相关信息:{context}用户问题:{question}请提供准确、实用的回答。根据问题的性质:- 如果是询问多个菜品,请提供清晰的列表- 如果是询问具体制作方法,请提供详细步骤- 如果是一般性咨询,请提供综合性回答回答:"""for attempt in range(max_retries):try:response = self.client.chat.completions.create(model=self.model_name,messages=[{"role": "user", "content": prompt}],temperature=self.temperature,max_tokens=self.max_tokens,stream=True,timeout=60 # 增加超时设置)if attempt == 0:print("开始流式生成回答...\n")else:print(f"第{attempt + 1}次尝试流式生成...\n")full_response = ""for chunk in response:if chunk.choices[0].delta.content:content = chunk.choices[0].delta.contentfull_response += contentyield content # 使用yield返回流式内容# 如果成功完成,退出重试循环returnexcept Exception as e:logger.warning(f"流式生成第{attempt + 1}次尝试失败: {e}")if attempt < max_retries - 1:wait_time = (attempt + 1) * 2 # 递增等待时间print(f"⚠️ 连接中断,{wait_time}秒后重试...")time.sleep(wait_time)continueelse:# 所有重试都失败,使用非流式作为后备logger.error(f"流式生成完全失败,尝试非流式后备方案")print("⚠️ 流式生成失败,切换到标准模式...")try:fallback_response = self.generate_adaptive_answer(question, documents)yield fallback_responsereturnexcept Exception as fallback_error:logger.error(f"后备生成也失败: {fallback_error}")error_msg = f"抱歉,生成回答时出现网络错误,请稍后重试。错误信息:{str(e)}"yield error_msgreturn __init__.py
"""
基于图数据库的RAG模块包
"""from .graph_data_preparation import GraphDataPreparationModule
from .milvus_index_construction import MilvusIndexConstructionModule
from .hybrid_retrieval import HybridRetrievalModule
from .generation_integration import GenerationIntegrationModule__all__ = ['GraphDataPreparationModule','MilvusIndexConstructionModule', 'HybridRetrievalModule','GenerationIntegrationModule'
]