Transformer推理优化全景:从模型架构到硬件底层的深度解析
如何让大语言模型推理更快、更省资源?本文从模型架构、推理过程到硬件底层,为你全面解析Transformer推理优化的核心技术方案
随着大语言模型(LLM)规模的不断扩大,其推理过程中的计算复杂度、内存占用和延迟问题日益凸显。本文将深入探讨Transformer推理优化的三大核心方向:模型架构与压缩、推理过程与系统优化以及硬件与编译器优化,分析各项技术的原理、特点与实践案例。
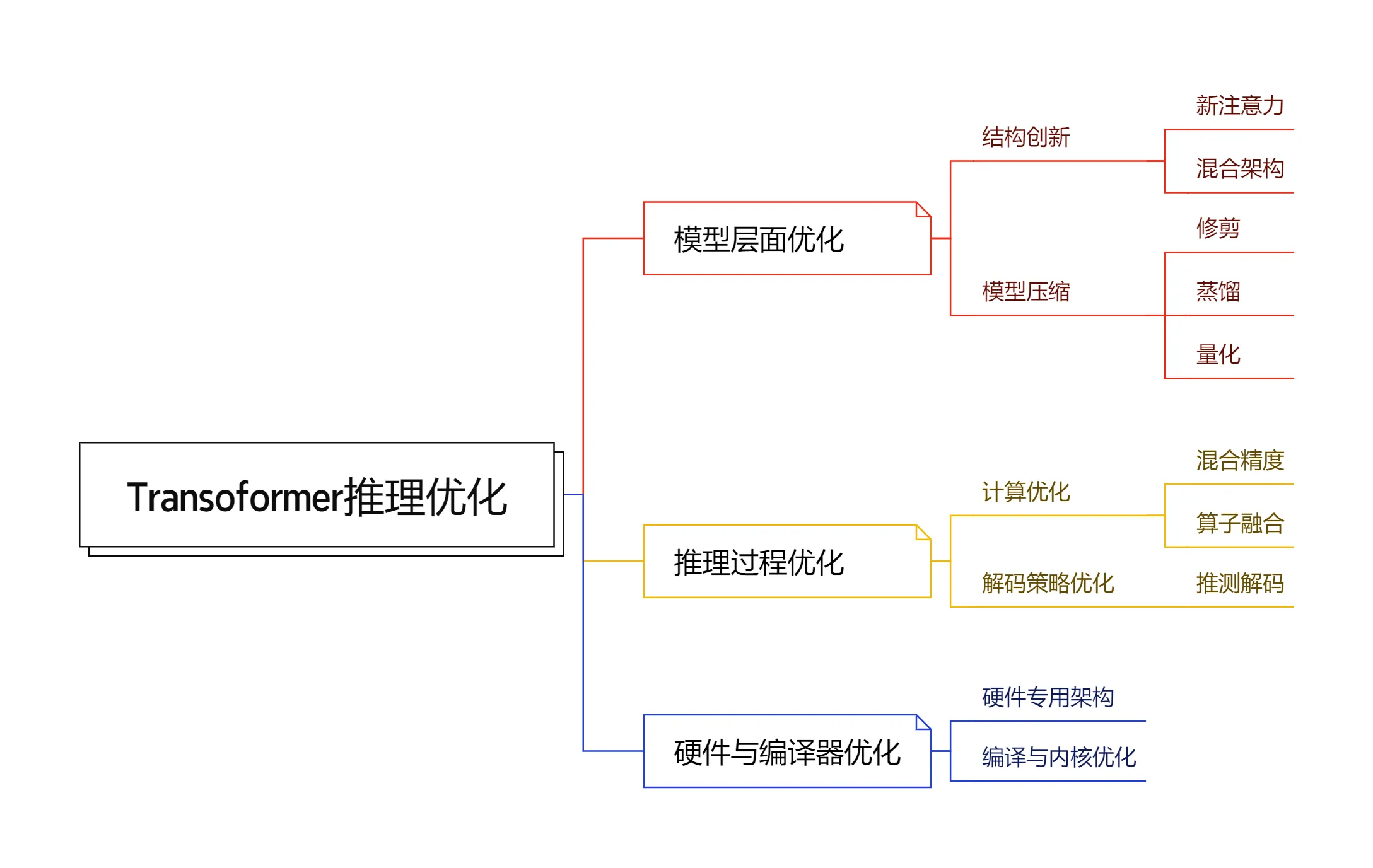
一、 模型架构与压缩优化
这类优化的核心思想是:在模型部署上线之前,通过算法手段,从根本上创建一个更小、更快、更高效的模型架构。这是最根本的优化,因为它改变了模型本身。之前的文章中有相关的介绍,《 让Transformer模型更小、更快的一系列技术》。
1.1 模型架构创新
目标是通过设计新的神经网络算子或架构,替代或改进原始Transformer中计算效率低下的部分。
1.1.1 高效注意力机制
原始自注意力的计算复杂度为 O(n²),是长序列的主要瓶颈。此类技术通过近似、稀疏化或线性化来降低复杂度。
- 稀疏注意力:如 Longformer 的滑动窗口注意力、 BigBird 的全局+局部+随机注意力。只让Token关注特定范围的Token,而非全部。
- 线性注意力:如 Linformer、 Performer,通过核函数将注意力计算分解为线性操作,将复杂度降至 O(n)。
- Flash Attention(严格说属于计算优化,但深刻影响架构设计):通过避免实例化巨大的注意力矩阵,利用GPU内存层次结构进行IO感知的精确计算,极大加速了标准注意力并降低了内存占用。
1.1.2 非Transformer架构
彻底摆脱注意力机制。
- 状态空间模型(SSM):如 Mamba,通过状态空间方程和硬件感知的并行扫描算法,实现了线性复杂度的长序列建模,在长上下文任务上性能和效率俱佳。
- 混合架构:如 Nemotron-H(Transformer + Mamba),结合二者的优势,让Mamba处理长序列,用少量注意力层捕捉关键全局依赖,在长文本推理上实现3倍吞吐提升。
# 混合架构示例:Transformer + Mambaclass HybridBlock(nn.Module):def __init__(self, dim, state_dim, num_heads):super().__init__()self.attention = MultiHeadAttention(dim, num_heads)self.mamba_block = MambaBlock(dim, state_dim)def forward(self, x):# Mamba处理长序列依赖x = self.mamba_block(x)# 注意力捕捉关键全局信息x = x + self.attention(x)return x特点:
- 根本性:从源头上解决了计算和内存瓶颈。
- 需要重训:大多数新架构需要从零开始预训练,成本高昂。
- 性能与效率的权衡:优秀的架构能在保持甚至提升性能的同时,大幅提升效率。
1.2 模型压缩技术
目标是在不显著损失性能的前提下,缩小预训练模型的大小和计算需求。
1.2.1 知识蒸馏
将一个庞大、高性能的 教师模型 的知识“迁移”到一个小的 学生模型 中。学生模型不仅学习真实标签,更关键的是学习教师模型的输出概率分布(软标签),从而模仿其内部逻辑。
- 响应蒸馏:学生模型模仿教师模型的输出分布
- 特征蒸馏:在中间层特征层面进行知识迁移
- 过程蒸馏:模仿教师模型的推理过程
1.2.2 模型修剪
移除模型中不重要的权重或组件。
- 结构化修剪:剪掉整个神经元、注意力头、甚至网络层。优点是与现有硬件兼容性好,可直接加速。
- 非结构化修剪:剪掉单个权重,产生稀疏矩阵。虽然压缩率高,但需要专用稀疏计算库或硬件才能实现实际加速。
# 结构化剪枝示例:基于L1范数的通道剪枝def prune_channels(weight, prune_ratio=0.3):# 计算每个输出通道的L1范数channel_importance = torch.norm(weight, p=1, dim=(1, 2, 3))# 选择重要性最低的通道进行剪枝prune_indices = torch.argsort(channel_importance)[:int(len(channel_importance) * prune_ratio)]mask = torch.ones_like(channel_importance)mask[prune_indices] = 0return mask1.2.3 量化
将模型权重和/或激活值从高精度(如FP32)转换为低精度(如INT8, INT4)。
- 训练后量化:对预训练模型直接进行量化,可能带来精度损失。
- 量化感知训练:在训练/微调过程中模拟量化效应,让模型适应低精度,从而在推理时保持更高精度。
特点:
- 高投资回报比:通常只需微调或无需微调,即可大幅减小模型体积、降低内存占用。
- 硬件友好:量化后的模型能更好地利用现代硬件的低精度计算单元,大幅提升吞吐。
二、 推理过程与系统优化
这类优化的核心思想是:不改变(或轻微改变)模型架构本身,而是通过优化推理时的计算策略、内存管理和调度,来提升系统整体的吞吐量和降低延迟。
2.1 解码策略优化
专门针对自回归文本生成任务的瓶颈进行优化。
2.1.1 KV缓存
在生成每个新Token时,避免重复计算之前所有Token的Key和Value向量,将其缓存起来。这是推理优化的基石,但其本身也会随序列增长而占用大量内存。
2.1.2 推测解码
一种“预测-验证”范式。用一个小的草稿模型快速生成多个候选Token(γ个),然后用原始大模型并行地对这γ个Token进行验证。如果验证通过,则单次步长从1变为γ,实现2-3倍的吞吐提升。
- 案例:Medusa、 DeepSpeed-FastGen。Medusa通过在主干模型上添加多个轻量级预测头来替代独立的草稿模型,避免了双模型加载的开销。
# 推测解码核心伪代码def speculative_decoding(target_model, draft_model, initial_input, max_steps):accepted_tokens = [initial_input]for step in range(max_steps):# 草稿模型快速生成多个候选tokendraft_output = draft_model.generate(accepted_tokens, num_candidates=5)# 目标模型并行验证候选序列target_logits = target_model(draft_output)# 验证并接受通过的tokenaccepted = verify_and_accept(draft_output, target_logits)accepted_tokens.extend(accepted)if len(accepted) < len(draft_output):break # 有token被拒绝,停止return accepted_tokens2.1.3 连续批处理
在服务场景下,不同用户的请求序列长度和生成步数差异很大。连续批处理允许GPU在一个批次内动态处理多个正在进行的请求,当一个请求生成完毕时,立即在批次空白处插入新请求,从而将GPU利用率提升至接近100%。
- 案例:vLLM 的核心优势之一就是实现了高效的连续批处理(其称为PagedAttention)。其技术受操作系统虚拟内存启发,将KV缓存物理上分散存储在非连续内存块中,逻辑上通过"页表"管理,几乎消除内存碎片,极大提升内存利用率。
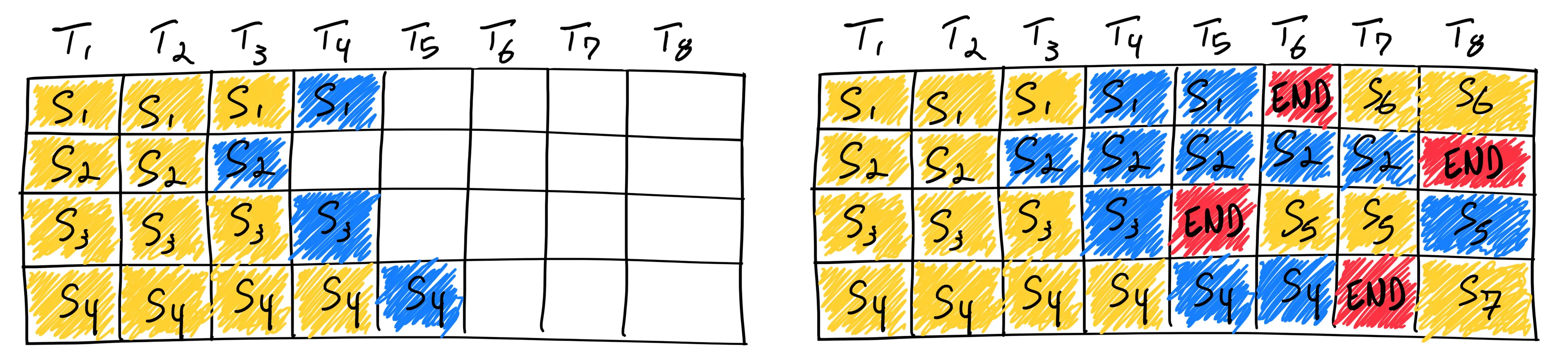
该流程展示了连续批处理如何依次处理七个序列。在运行过程中,每当一个序列完成推理(产生序列结束标记),系统便会动态地将一个新序列加入批次,以接替其位置。如图所示,序列S5、S6和S7正是以此方式后续加入的。这种方法通过持续向GPU供给新任务,避免了资源闲置,实现了近乎满负荷的运转
2.2 计算与内存系统优化
关注如何更高效地利用GPU的计算和内存资源。
2.2.1 算子融合
将模型中多个细粒度的操作(如:LayerNorm -> GeLU -> Linear)融合为一个单独的GPU内核。这避免了多次启动内核的开销和中间结果在慢速HBM上的读写,是极重要的优化手段。
// 简化版的LayerNorm + GeLU融合内核__global__ void fused_layernorm_gelu_kernel(float* output, const float* input,const float* weight, const float* bias,int hidden_size, int seq_len) {int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx >= seq_len) return;// 计算LayerNormfloat mean = compute_mean(input + idx * hidden_size, hidden_size);float var = compute_variance(input + idx * hidden_size, hidden_size, mean);// 应用LayerNorm然后GeLU激活for (int i = 0; i < hidden_size; i++) {float normalized = (input[idx * hidden_size + i] - mean) / sqrt(var + 1e-5);float scaled = normalized * weight[i] + bias[i];output[idx * hidden_size + i] = gelu(scaled); // 融合GeLU}}2.2.2 张量并行 & 流水线并行
对于单个GPU无法容纳的巨型模型,必须进行分布式推理。
- 张量并行: 将模型的单个层(如MLP、Attention)的权重矩阵切分到多个GPU上,计算时通过All-Reduce通信同步结果。模型间通信频繁,对网络要求高。
- 流水线并行: 将模型的不同层分布到多个GPU上。像一个工厂流水线,每个GPU完成一部分计算后,将激活值传递给下一个GPU。通信量小,但存在GPU空闲(气泡)问题。
2.2.3 内存管理
优化KV缓存的管理是重中之重。
- PagedAttention(vLLM):受操作系统虚拟内存和分页思想启发,将KV缓存物理上分散存储在非连续的内存块中,逻辑上通过“页表”进行管理。这几乎消除了内存碎片,允许不同序列共享物理内存,极大提升了内存利用率和吞吐量。
三、 硬件与编译器优化
这类优化的核心思想是:让模型的计算图能够被底层硬件以最高效的方式执行,充分发挥硬件潜力。
3.1 硬件专用架构
为Transformer类工作负载设计的专用计算单元。
- 矩阵计算单元:现代AI加速器(如NVIDIA的Tensor Cores、Google的TPU)内置了高效的矩阵乘加计算单元,专门针对 BF16/FP16/INT8 等低精度格式进行了优化。
- 片上内存 hierarchy:优化GPU中共享内存、L1/L2缓存的大小和带宽,以适应Attention等操作对高内存带宽的需求。
- 结构化稀疏硬件:一些研究中的芯片设计支持对结构化稀疏矩阵的直接高效计算,从而让修剪技术能发挥出实际的加速效果。
3.2 编译与内核优化
将高级的模型描述,转化为高度优化的、面向特定硬件的可执行代码。
3.2.1 模型编译
使用编译器(如 Apache TVM, OpenXLA)将模型(如PyTorch模型)转换并优化为一个静态的计算图。
- 图优化:编译器会进行常量折叠、公共子表达式消除、层融合等数十种优化。
- 自动代码生成:为优化后的计算图,针对目标硬件(如特定型号的GPU)自动生成高度优化的内核代码。
3.2.2 定制内核
对于编译器无法完美优化的极端性能瓶颈,由专家手工编写CUDA内核。
- 案例:FlashAttention 就是手工定制内核的典范,它通过精巧的 tiling 策略在SRAM上进行注意力计算,彻底改变了注意力层的实现方式。NVIDIA的 FasterTransformer 也提供了大量针对Transformer模块的优化内核。
四、协同优化的艺术
Transformer推理优化是一个涉及模型、算法、系统、硬件的复杂系统工程。成功的优化方案需要深入理解各层次技术的特点和相互作用,根据具体场景需求进行精心选择和组合,真正的性能飞跃来自于全栈协同优化。
一个典型的高性能部署流水线可能是这样的:
- 模型准备:选择一个经过架构优化(如Mamba) 的模型,或对一个标准模型进行蒸馏和修剪,然后进行量化感知训练,得到一个精简且低精度的模型。
- 系统部署:使用 vLLM 作为推理引擎,利用其 PagedAttention 和连续批处理来高效管理内存和请求。同时,启用推测解码(如Medusa) 来加速单个生成过程。
- 底层执行:模型通过 OpenXLA 或 TensorRT 编译器进行编译,实现算子融合和图优化,并链接 FlashAttention 等定制内核,最终在配备了Tensor Cores的GPU上以 FP8/INT8 精度高效执行。
总结
理解这三个层面如何相互作用,并根据你的具体场景(是追求最低延迟,还是最大吞吐,或是支持最长上下文)来选择和组合这些技术,正是大模型推理优化的核心艺术与挑战。