语义分割概述
分割概述
文章目录
- 分割概述
- Preliminaries
- 卷积模式
- 语义分割 vs 实例分割 vs 全景分割
- 转置卷积
- 相关工作
- FCN(Fully Convolutional Network)
- U-Net
- PSPNet 2016
- DeepLab
- SAM
- DINOv2
- Grounded SAM
Preliminaries
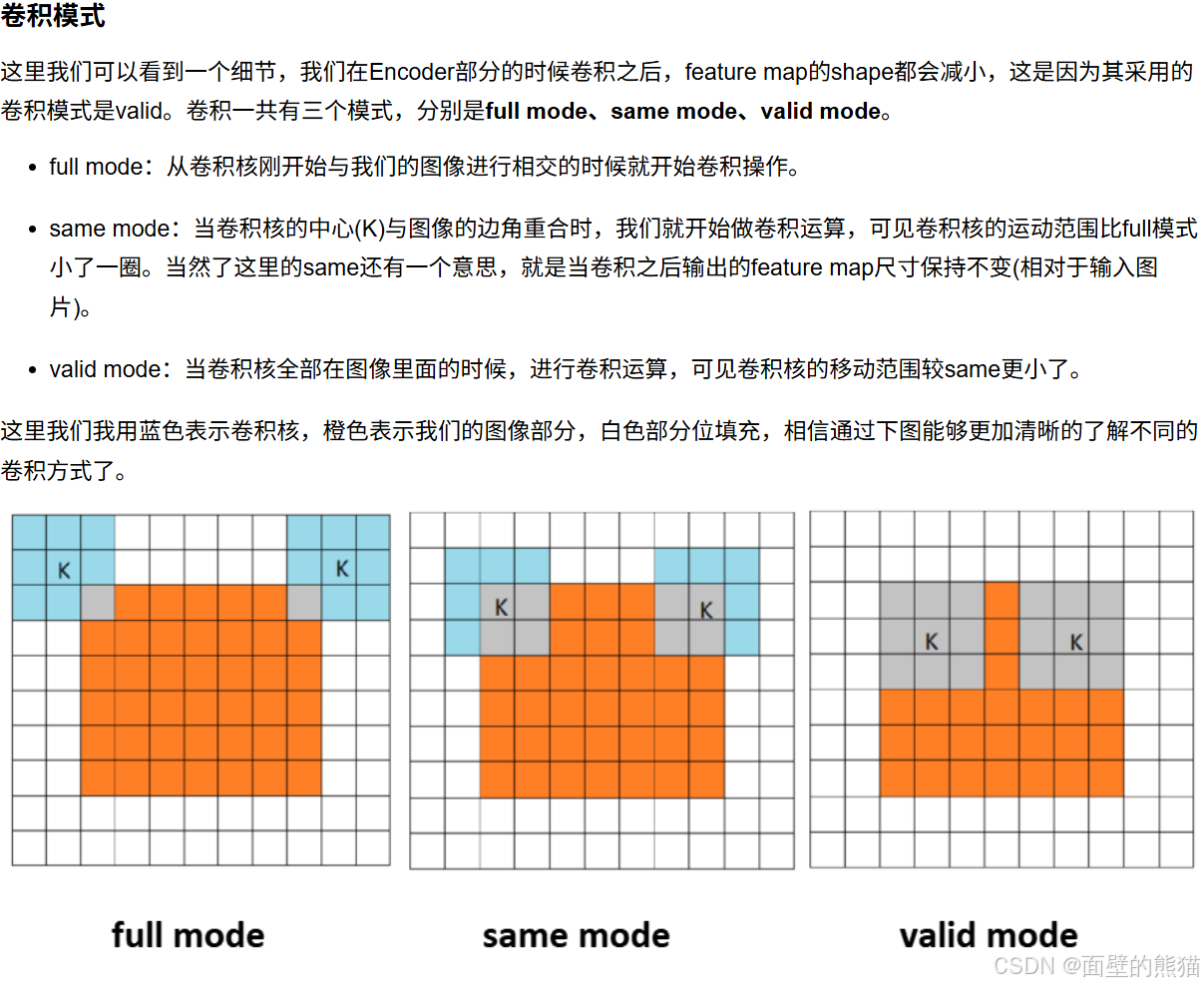
卷积模式
语义分割 vs 实例分割 vs 全景分割

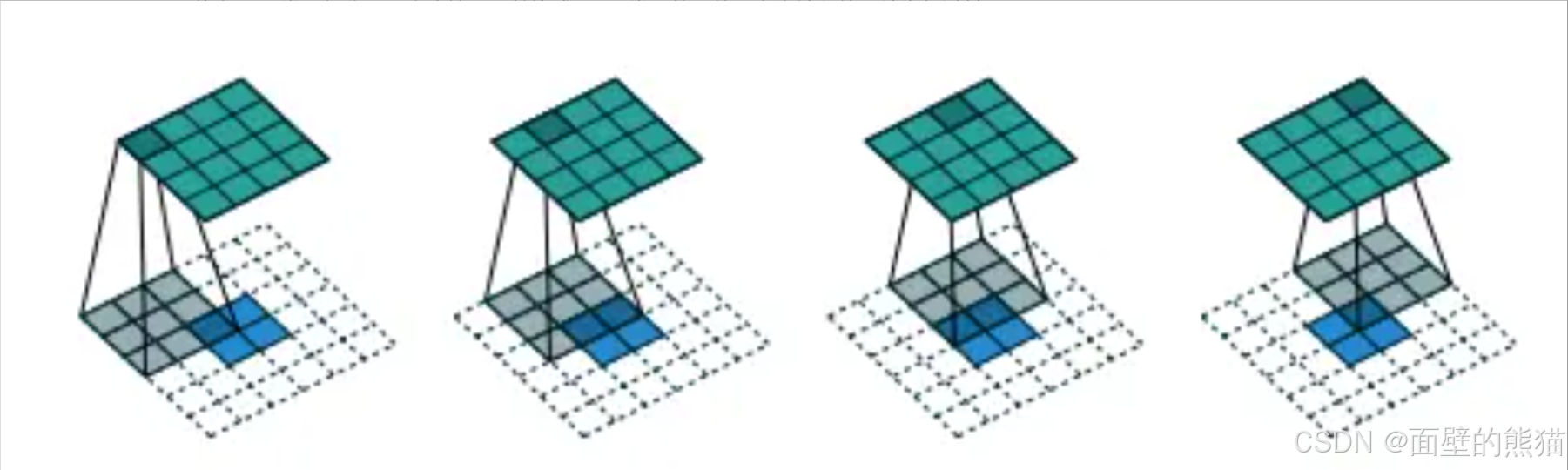
转置卷积
相关工作
FCN(Fully Convolutional Network)
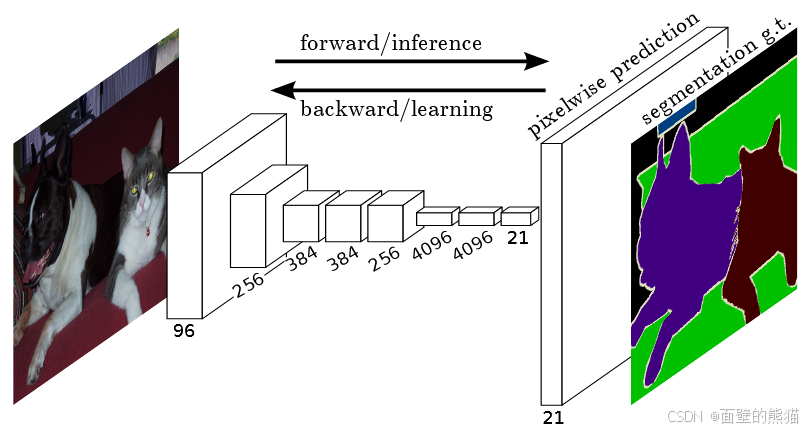
贡献:
-
FCN代替全连接FFN,以适应不同size的图片输入;
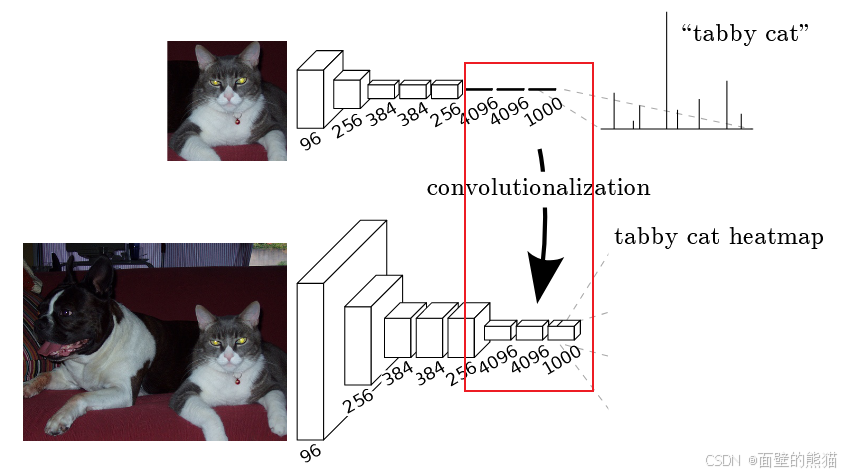
-
转置卷积(上采样)
-
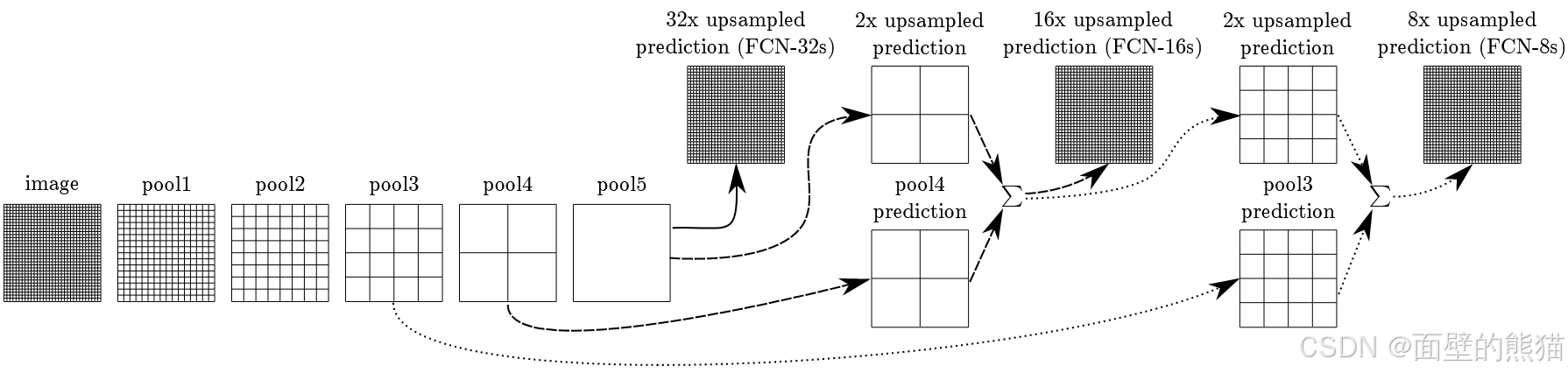
Skip结构
结合细层和粗层可以让模型做出尊重全局结构的局部预测,获取更多细粒度的特征和语义。
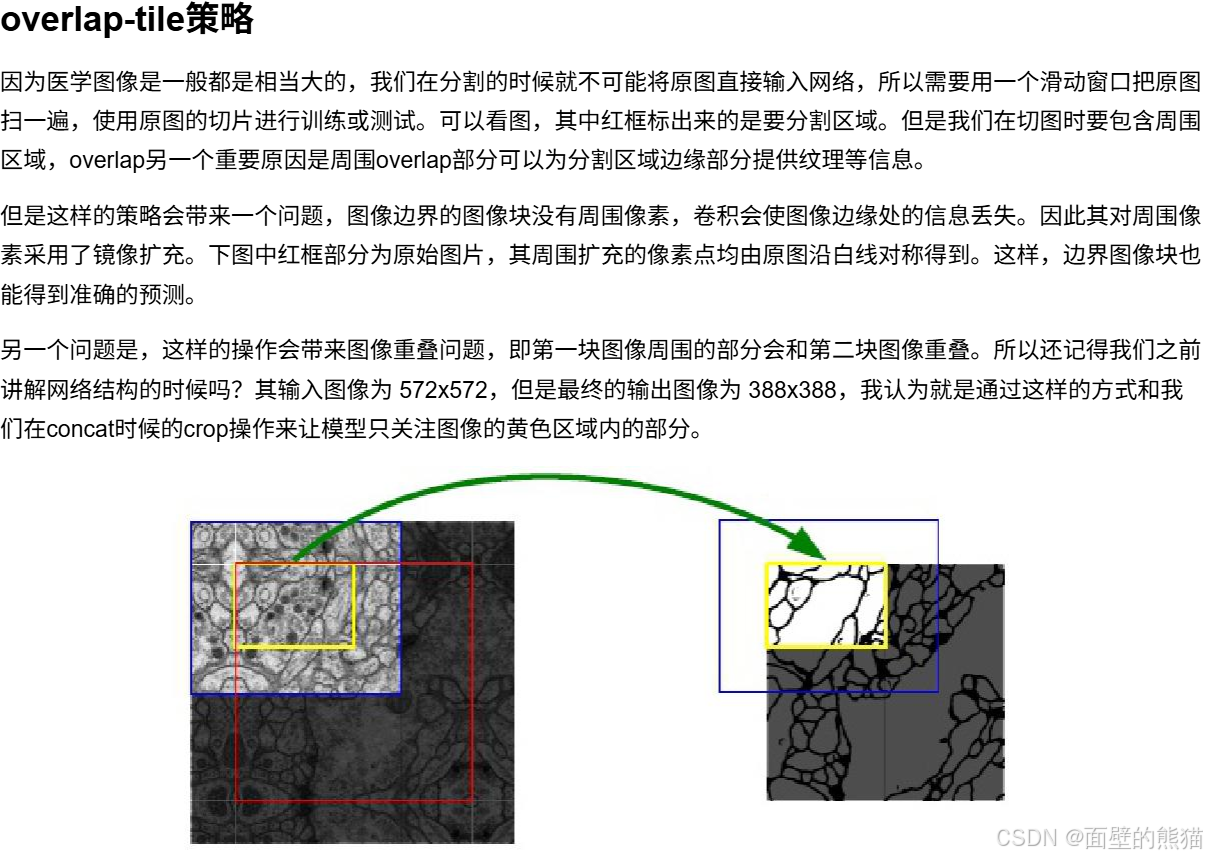
U-Net
参考:
- https://www.bbbdata.com/text/976
- https://blog.csdn.net/AggressiveYu/article/details/151256739
- https://www.cnblogs.com/carpell/p/18908044
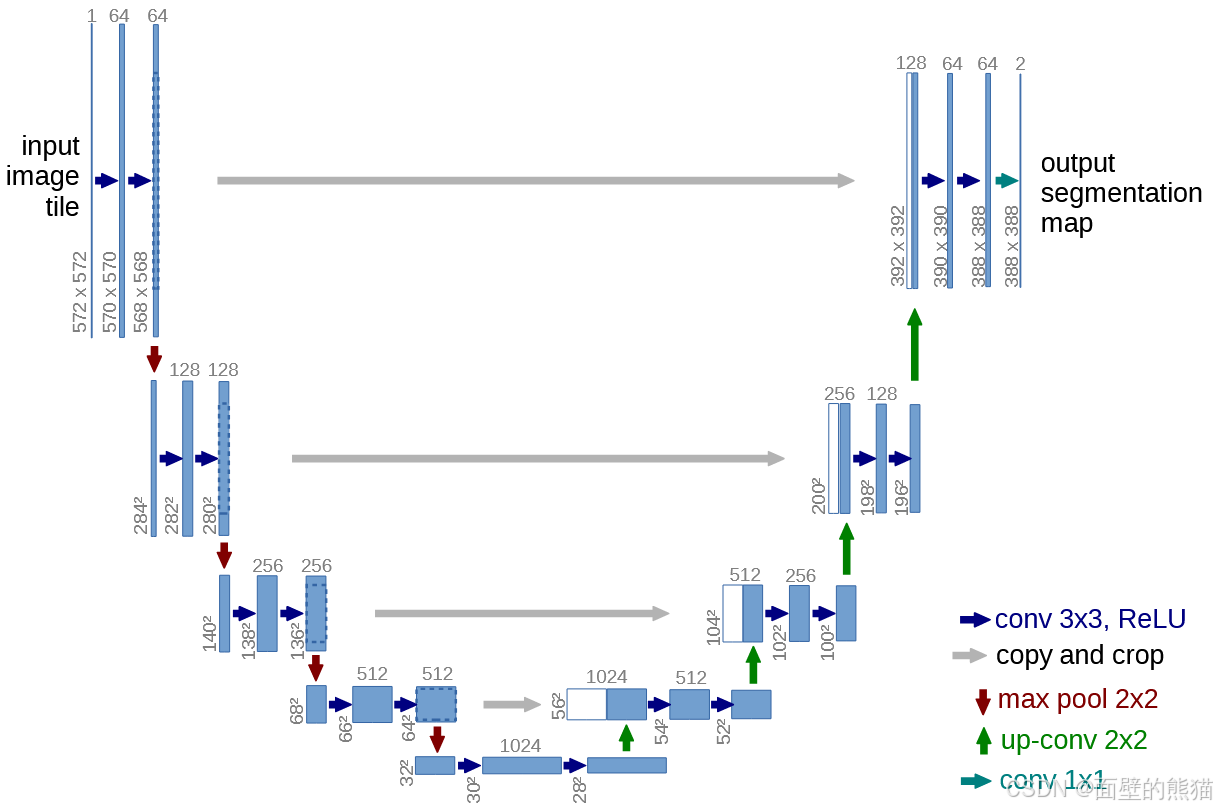
U-net的设计初衷是为了解决医学图像分割中数据稀缺的挑战。
贡献:
-
模型
U-Net的结构得名于它的形状,像一个英文字母“U”。它可以清晰地分为两个部分:左侧的编码器(收缩路径) 和 右侧的解码器(扩张路径)。 -
数据增强

-
损失函数
为交叉熵损失中的每个像素级(pixel-wise) 计算权重,重点加大接触细胞间背景区域的权重。
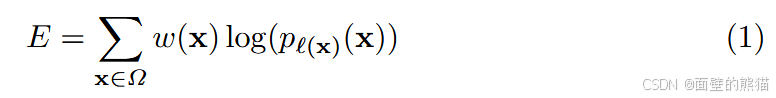
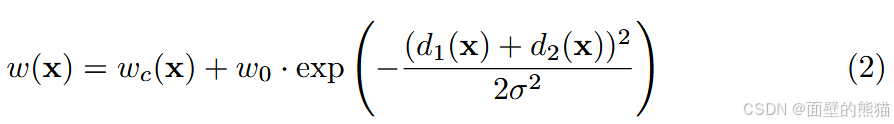
-
其他
PSPNet 2016
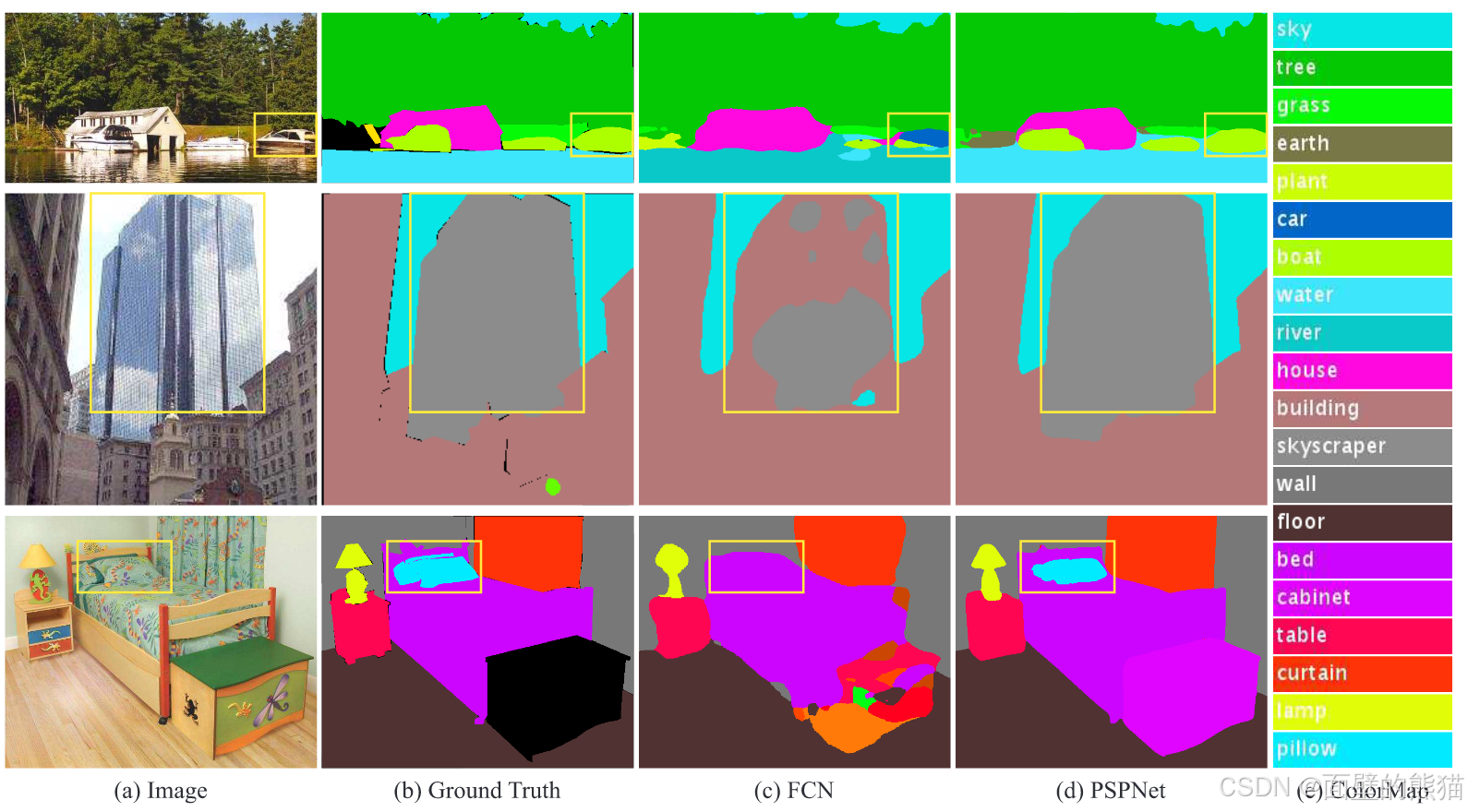
上下文关系是通用且重要的,特别是对于复杂的场景理解。如上图,一架飞机很可能在跑道上或在天空中飞行,而没有在道路上空飞行。FCN根据黄色框中的船的外观将其预测为“汽车”。但众所周知,汽车很少能过河。缺乏收集上下文信息的能力会增加错误分类的机会。
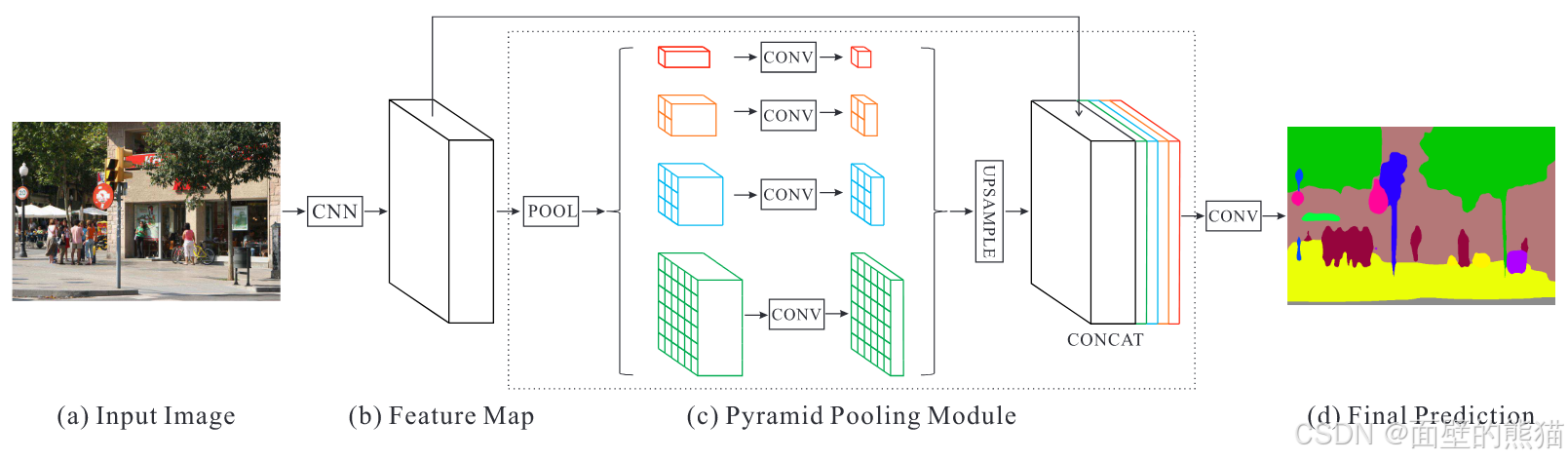
PSPNet 为像素级场景解析提供了有效的全局上下文先验。金字塔池模块可以收集信息层次,比全局池化更具代表性。
金字塔池模块融合了四种不同金字塔尺度下的特征。以红色突出显示的最粗略级别是全局池化,以生成单个bin输出。以下金字塔级别将特征图划分为不同的子区域,并形成不同位置的汇集表示。金字塔池化模块中不同级别的输出包含大小不一的特征图。为了保持全局特征的权重,作者在每个金字塔级别后使用1×11×11×1卷积层 ,在金字塔的级别大小为N的情况下,将上下文表示的维度降低到原始维度的 1/N1/N1/N 。然后,我们直接对低维特征图进行上采样,通过双线性插值获得与原始特征图相同大小的特征。最后,将不同级别的特征连接起来,作为最终的金字塔池化全局特征。
DeepLab
参考:
- https://blog.csdn.net/fanxuelian/article/details/85145558
SAM
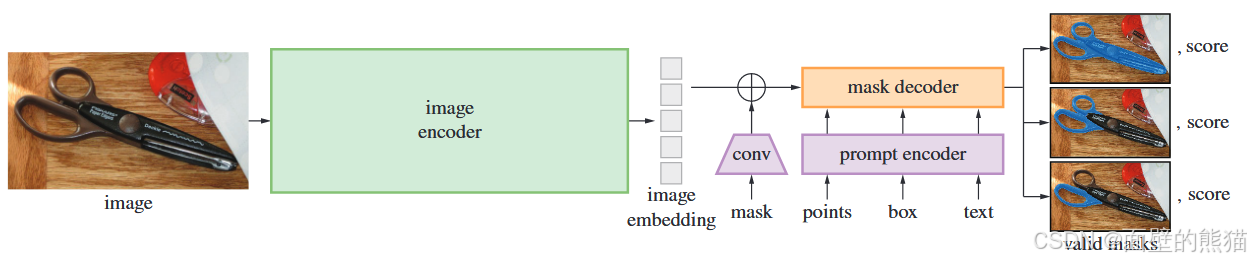
SAM借鉴了NLP领域的Prompt策略,通过给图像分割任务提供Prompt提示来完成任意目标的快速分割。Prompt类型可以是「前景/背景点集、粗略的框或遮罩、任意形式的文本或者任何指示图像中需要进行分割」的信息。如下图(a)所示,模型的输入是原始的图像和一些prompt,目标是输出"valid"的分割,所谓valid,就是当prompt的指向是模糊时,模型能够输出至少其中一个mask。
DINOv2
Grounded SAM
