浅谈 Base64 编码与解码:原理、变体及实践
一、Base64编码
在现代软件工程中,Base64 是我们最常见却容易被忽视的一种编码方式。无论是在邮件、URL 参数、JSON 传输,还是 JWT、OAuth 等安全协议中,我们都会看到 Base64 的身影。但很多人对它的理解还停留在“就是一种编码”的层面。本文将带大家逐步理解 Base64 的原理、解码公式的推导过程以及常见变体。
1. 什么是 Base64?
Base64 是一种把任意二进制数据编码为文本的方案。它的核心思想是:将输入字节流按 6 位一组重新映射为 64 个可打印字符,从而能在只允许文本(ASCII)的通道中安全传输二进制数据。
- 不是加密:Base64 没有任何安全性,只是一种可逆的编码。
- 主要目的:解决二进制数据在文本协议中的兼容性问题。
2. 字符表与基本规则
Base64 的核心就是一个长度为 64 的字符表:
索引: 0–25 26–51 52–61 62 63
字符: A–Z a–z 0–9 + /
- 填充符号:
=(最多出现 2 个) - URL 安全变体:
+替换为-,/替换为_,结尾的=可选省略
3. 编码过程
Base64 的编码是 3 字节 → 4 字符 的转换:
- 输入按 3 个字节(24 bit)分组,不足 3 字节补零。
- 将 24 位切分为 4 个 6 位段,每段对应一个 0–63 的数字。
- 查表得到 Base64 字符,拼接成 4 个字符。
- 不足 3 字节的情况用
=补齐。
示例
"Man"→TWFu"Ma"→TWE="M"→TQ==
开销
每 3 字节变 4 字符,体积膨胀 约 33%。
4. 解码公式是怎么来的?
编码的本质是把 3×8 位(24 位)切分为 4×6 位,那么解码就是反过来:把 4×6 位拼回 3×8 位。
编码方向(正向)
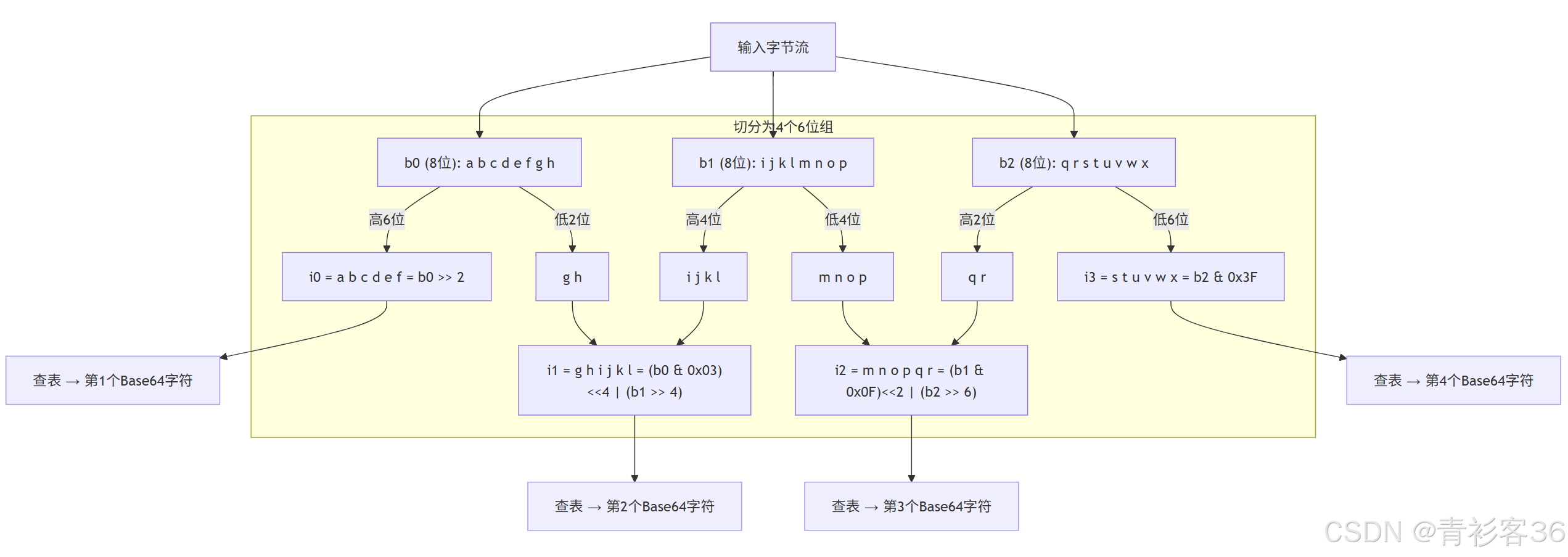
b0 b1 b2
abcdefgh ijklmnop qrstuvwx (每个字母代表 1 bit)分成 6 位一组:
i0 = abcdef
i1 = ghijkl
i2 = mnopqr
i3 = stuvwx
编码公式:
i0 = b0 >> 2
i1 = (b0 & 0x03) << 4 | (b1 >> 4)
i2 = (b1 & 0x0F) << 2 | (b2 >> 6)
i3 = b2 & 0x3F
解码方向(反向)
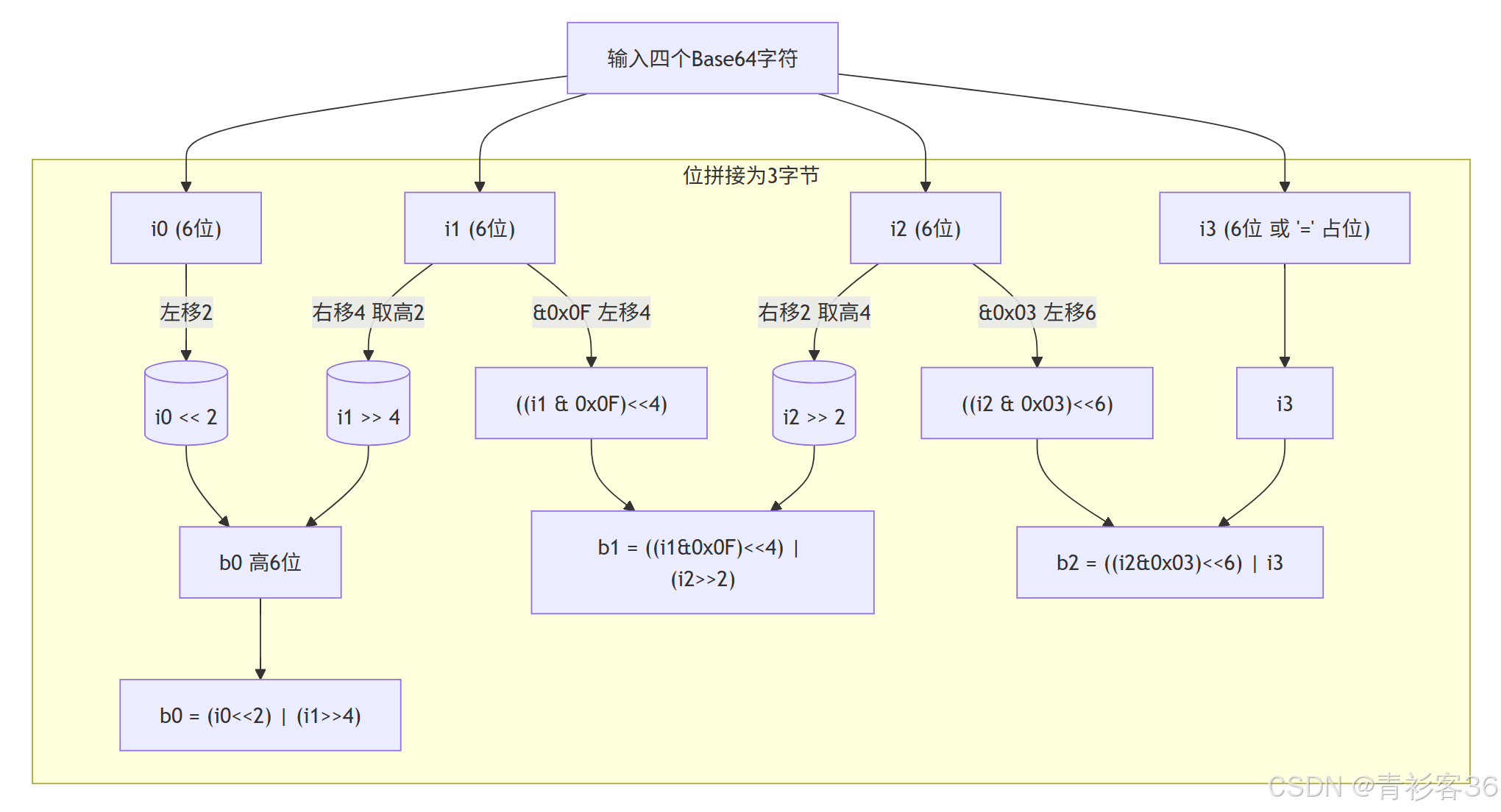
已知 i0…i3,要拼回 b0…b2:
-
b0 = i0 的 6 位 + i1 的高 2 位
b0 = (i0 << 2) | (i1 >> 4) -
b1 = i1 的低 4 位 + i2 的高 4 位
b1 = ((i1 & 0x0F) << 4) | (i2 >> 2) -
b2 = i2 的低 2 位 + i3 的 6 位
b2 = ((i2 & 0x03) << 6) | i3
这些移位与掩码操作正好对应位段拼接的位置。
填充 = 的意义
- 末尾
=:原始数据只有 2 字节,i3 无效 - 末尾
==:原始数据只有 1 字节,i2 和 i3 无效
示例:
"TWE="→"Ma""TQ=="→"M"
5. 变体与历史差异
-
标准 Base64(RFC 4648):最常见形式,带
=填充。 -
Base64url:
+→-,/→_- 填充
=可省略 - 常用于 JWT、OAuth、Web 安全协议
-
MIME/PEM 风格:
- 邮件、证书中常见,每行 76 字符换行
- JSON/HTTP 传输一般不换行
6. 常见坑点
- 误以为加密:Base64 只是编码,不提供安全性。
- 字符集问题:文本必须先转字节(通常 UTF-8),再 Base64。
- 填充缺失:无填充的 Base64url 在解码时需手动补
= - 自动换行:部分库默认输出 76 列换行,需关闭。
- 宽松/严格解码:不同语言实现不一样,协议要统一。
7. 与其他编码对比
| 编码方式 | 体积膨胀 | 特点 |
|---|---|---|
| Hex(Base16) | +100% | 可读性好,调试常用 |
| Base32 | +60% | 无大小写混淆,常用于密钥 |
| Base58 | 不固定 | 去掉混淆字符,常见于区块链 |
| Base85 | +25% | 更紧凑,但兼容性差 |
8. 工程实践
- URL 参数:推荐 Base64url 无填充
- 大文件:用流式 Base64,避免内存峰值
- 协议声明:在文档/Schema 中明确标注字段是 Base64 编码
- 安全性:需要隐私时请使用加密后再 Base64
9. 练习对照表
""→"""f"→Zg=="fo"→Zm8="foo"→Zm9v"foob"→Zm9vYg=="fooba"→Zm9vYmE="foobar"→Zm9vYmFy
小结
Base64 看似简单,但在实际工程中却充满细节。理解其编码与解码的位操作公式、常见变体和应用场景,才能避免协议对接、跨语言处理时踩坑。记住:Base64 只是编码,不是加密。在需要传输二进制数据时它很有用,但安全性要交给加密算法来保证。
二、Base64url
1. 它是什么
Base64url(RFC 4648)是为 URL、文件名、Cookie、JWT 等场景设计的 Base64 变体。目标是:避免在这些位置里需要转义或会引起歧义的字符。
2. 与标准 Base64 的差异
| 项 | 标准 Base64 | Base64url(URL-safe) |
|---|---|---|
| 字符 62 | + | - |
| 字符 63 | / | _ |
| 填充 | 末尾 0–2 个 = | 可选去掉 = |
| 换行 | 历史上常 76 列换行(MIME) | 一般不换行 |
算法完全一致(仍是 3 字节→4 字符),只有 字符表 与 填充策略不同。
3. 为什么需要它
- URL / 查询参数 / 路径 / 文件名 / Cookie 中,
+、/、=要转义或可能歧义。 - Base64url 直接换成
-和_,并常省略=, 让传输更稳妥、可读。
4. 示例(同一比特流)
- 标准:
abc+/== - URL-safe:把
+→-,/→_,去尾部=⇒abc-_
再比如标准 TWE=(表示原文 “Ma”)在 URL-safe 中通常写成 TWE(去掉 =)。
5. 解码与补齐
很多实现会去掉填充 =。解码前需:
- 将
-→+、_→/; - 把长度补到 4 的倍数(末尾补 0–2 个
=); - 再按标准 Base64 解码。
6. 常见坑
- 无填充导致解码失败:严格按标准 Base64 的解析器需要补齐
=。 - 误当加密:它只是编码;需要机密性请先加密再(Base64url)编码。
- 换行/空白:URL-safe 通常不换行;若数据中出现空白,解析时应忽略或事先移除。
- 协议约定:在接口文档/Schema 中写清楚“使用 Base64url,是否省略填充”。
7. 何时选 Base64url
- URL 参数/路径、文件名、Cookie、JWT/OAuth、前后端 JSON/表单字段:优先 Base64url(常无填充)。
- 日志、普通文本存储:标准 Base64 即可。
三、标准 Base64 ↔ Base64url 互转
1. 标准 Base64 ⇒ Base64url
目标:把可能在 URL/文件名/Cookie 里引起歧义的字符替换掉,并可选去掉结尾填充。
-
移除空白与换行
- 去掉所有空格、
\r、\n(MIME 场景常有 76 列换行)。
- 去掉所有空格、
-
字符替换(核心)
- 将所有
+替换为- - 将所有
/替换为_
- 将所有
-
处理填充(可选)
- 如果末尾有
=(0–2 个),可删除它们(很多协议偏好无填充)。
- 如果末尾有
-
完成
- 得到的就是 Base64url 字符串。
校验示例
abc+/==→ 替换 →abc-_/==→ 去填充 →abc-_TWE=→TWE(去掉=);Zm9vYg==→Zm9vYg(去掉==)
2. Base64url ⇒ 标准 Base64
目标:把 URL-safe 形式还原为标准 Base64,便于通用解码器处理。
-
移除空白与换行
- 去掉所有空格、
\r、\n(若有)。
- 去掉所有空格、
-
字符还原(核心)
- 将所有
-替换为+ - 将所有
_替换为/
- 将所有
-
补齐填充(必要时)
- 计算长度
L = 当前字符串长度 - 需要补的
=个数:pad = (4 - L % 4) % 4(取值 0/1/2) - 在结尾补上
pad个=,使总长度变为 4 的倍数
- 计算长度
-
完成
- 得到的就是 标准 Base64 字符串,可直接用任何 Base64 解码器解码。
校验示例
abc-_→ 还原 →abc+/,长度 5 ⇒ 需补=:(4 - 5%4)%4 = 3(不可能;说明例子应先还原到无填充的等价:abc-_/==)
更规范做法:abc-_→abc+/→ 长度 5 ⇒ 补===直至为 8?(注意:实际可行的 URL 片段需源于有效 Base64;推荐用下一条可验证样例)TWE→ 还原 →TWE,长度 3 ⇒pad = 1→TWE=(可解码为"Ma")Zm9vYg→ 还原 →Zm9vYg,长度 6 ⇒pad = 2→Zm9vYg==(可解码为"foob")
小贴士:如果某个 Base64url 片段无法通过上述补齐变成长度为 4 的倍数的合法串,多半源字符串就不是有效的 Base64url(或被截断/损坏)。
3. 判定与健壮性检查(双向通用)
-
字符集合检查
- 标准 Base64:只允许
A–Z a–z 0–9 + / = - Base64url:只允许
A–Z a–z 0–9 - _(以及可选结尾=)
- 标准 Base64:只允许
-
填充规则
-
只允许结尾出现 0–2 个
=;中间出现=为非法。 -
当存在
=时:- 1 个
=⇒ 原始最后块是 2 字节 - 2 个
==⇒ 原始最后块是 1 字节
- 1 个
-
-
长度规则
- 标准 Base64:长度必须是 4 的倍数。
- Base64url(无填充时):长度可以不是 4 的倍数,但在“还原为标准 Base64”时必须补到 4 的倍数。
-
空白处理
- 双方在传输前最好去除所有空白;解析时若出现空白应先移除再处理。
4. 选型建议
- 放在 URL/文件名/Cookie/JWT 的字段:使用 Base64url(通常 无填充)。
- 日志/普通文本/通用库解码:使用 标准 Base64(保留填充、无换行)。
- 接口/Schema 文档:明确声明字段采用哪种形式,以及是否省略填充。