datawhale RAG技术全栈指南 202509 第5次作业
项目实战一:
程序员做饭指南
环境配置
# 使用conda创建环境
conda create -n cook-rag-1 python=3.12.7
conda activate cook-rag-12 安装核心依赖
cd code/C8
pip install -r requirements.txt3 申请Kimi API Key
4 API配置
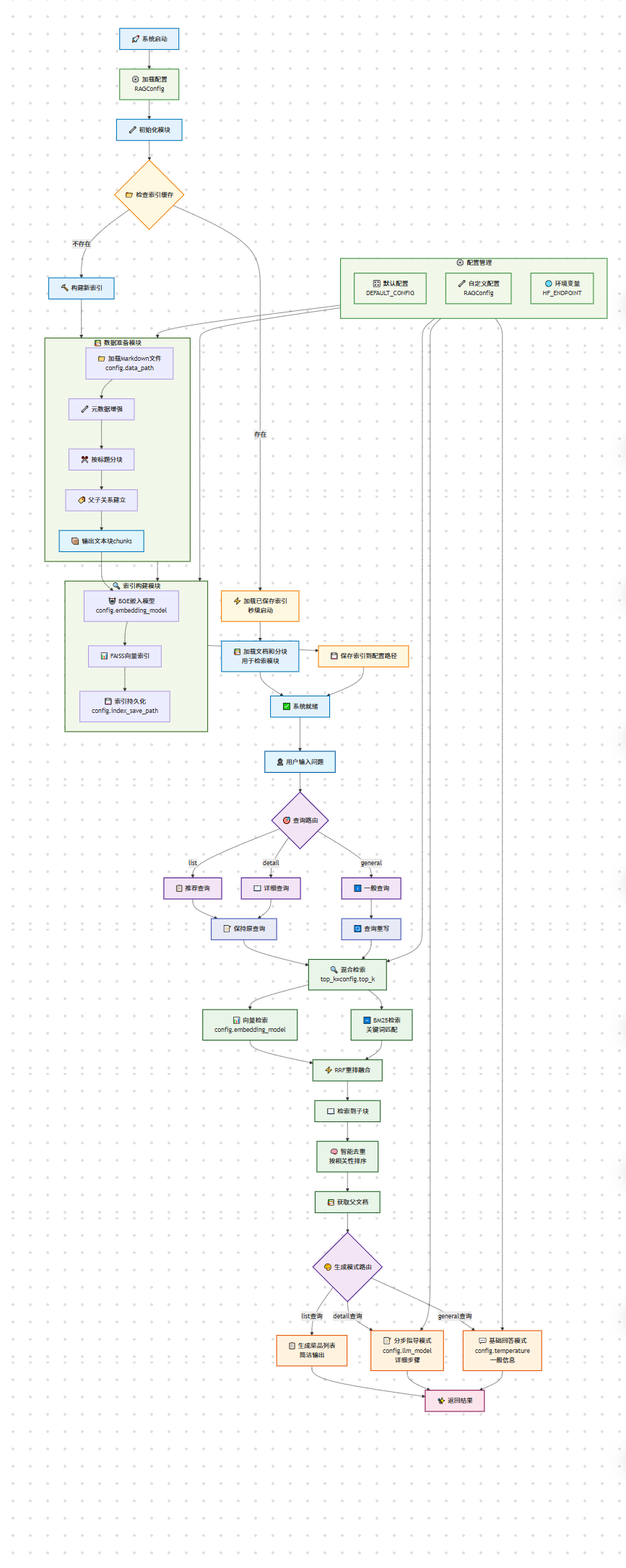
项目架构
采用父子文本块的策略:用小的子块进行精确检索,但在生成时传递完整的父文档给LLM。
关键在于当用户问"宫保鸡丁需要什么调料"时,如果直接用整个文档做向量检索,这个具体问题在整个文档中的占比很小,很可能检索不到或者排名很靠后。但如果用小块检索,"必备原料和工具"这个章节就能精确匹配用户的需求。
简单来说,这种设计是"小块检索,大块生成"——用小块的精确性找到相关内容,用大块的完整性保证回答质量。如果直接用整个文档分块,就失去了检索的精确性优势。
项目结构
code/C8/
├── config.py # 配置管理
├── main.py # 主程序入口
├── requirements.txt # 依赖列表
├── rag_modules/ # 核心模块
│ ├── __init__.py
│ ├── data_preparation.py # 数据准备模块
│ ├── index_construction.py # 索引构建模块
│ ├── retrieval_optimization.py # 检索优化模块
│ └── generation_integration.py # 生成集成模块
└── vector_index/ # 向量索引缓存(自动生成)
数据准备模块实现
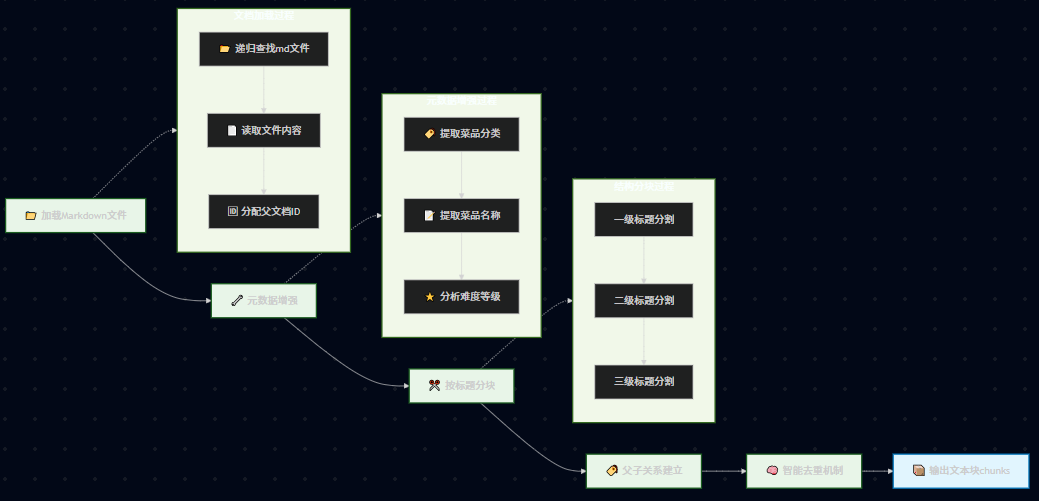
一、核心设计
数据准备模块的核心是实现"小块检索,大块生成"的父子文本块架构。
父子文本块映射关系:
父文档(完整菜谱)
├── 子块1:菜品介绍 + 难度评级
├── 子块2:必备原料和工具
├── 子块3:计算(用量配比)
├── 子块4:操作(制作步骤)
└── 子块5:附加内容(变化做法)
基本流程:
- 检索阶段:使用小的子块进行精确匹配,提高检索准确性
- 生成阶段:传递完整的父文档给LLM,确保上下文完整性
- 智能去重:当检索到同一道菜的多个子块时,合并为一个完整菜谱
元数据增强:
- 菜品分类:从文件路径推断(荤菜、素菜、汤品等)
- 难度等级:从内容中的星级标记提取
- 菜品名称:从文件名提取
- 文档关系:建立父子文档的ID映射关系
二、模块实现详解
"""
数据准备模块
"""import logging
import hashlib
from pathlib import Path
from typing import List, Dict, Anyfrom langchain_text_splitters import MarkdownHeaderTextSplitter
from langchain_core.documents import Document
from pathlib import Path
import uuidlogger = logging.getLogger(__name__)class DataPreparationModule:"""数据准备模块 - 负责数据加载、清洗和预处理"""# 统一维护的分类与难度配置,供外部复用,避免关键词重复定义CATEGORY_MAPPING = {'meat_dish': '荤菜','vegetable_dish': '素菜','soup': '汤品','dessert': '甜品','breakfast': '早餐','staple': '主食','aquatic': '水产','condiment': '调料','drink': '饮品'}CATEGORY_LABELS = list(set(CATEGORY_MAPPING.values()))DIFFICULTY_LABELS = ['非常简单', '简单', '中等', '困难', '非常困难']def __init__(self, data_path: str):"""初始化数据准备模块Args:data_path: 数据文件夹路径"""self.data_path = data_pathself.documents: List[Document] = [] # 父文档(完整食谱)self.chunks: List[Document] = [] # 子文档(按标题分割的小块)self.parent_child_map: Dict[str, str] = {} # 子块ID -> 父文档ID的映射def load_documents(self) -> List[Document]:"""加载文档数据Returns:加载的文档列表"""logger.info(f"正在从 {self.data_path} 加载文档...")# 直接读取Markdown文件以保持原始格式documents = []data_path_obj = Path(self.data_path)for md_file in data_path_obj.rglob("*.md"):try:# 直接读取文件内容,保持Markdown格式with open(md_file, 'r', encoding='utf-8') as f:content = f.read()# 为每个父文档分配确定性的唯一ID(基于数据根目录的相对路径)try:data_root = Path(self.data_path).resolve()relative_path = Path(md_file).resolve().relative_to(data_root).as_posix()except Exception:relative_path = Path(md_file).as_posix()parent_id = hashlib.md5(relative_path.encode("utf-8")).hexdigest()# 创建Document对象doc = Document(page_content=content,metadata={"source": str(md_file),"parent_id": parent_id,"doc_type": "parent" # 标记为父文档})documents.append(doc)except Exception as e:logger.warning(f"读取文件 {md_file} 失败: {e}")# 增强文档元数据for doc in documents:self._enhance_metadata(doc)self.documents = documentslogger.info(f"成功加载 {len(documents)} 个文档")return documentsdef _enhance_metadata(self, doc: Document):"""增强文档元数据Args:doc: 需要增强元数据的文档"""file_path = Path(doc.metadata.get('source', ''))path_parts = file_path.parts# 提取菜品分类doc.metadata['category'] = '其他'for key, value in self.CATEGORY_MAPPING.items():if key in path_parts:doc.metadata['category'] = valuebreak# 提取菜品名称doc.metadata['dish_name'] = file_path.stem# 分析难度等级content = doc.page_contentif '★★★★★' in content:doc.metadata['difficulty'] = '非常困难'elif '★★★★' in content:doc.metadata['difficulty'] = '困难'elif '★★★' in content:doc.metadata['difficulty'] = '中等'elif '★★' in content:doc.metadata['difficulty'] = '简单'elif '★' in content:doc.metadata['difficulty'] = '非常简单'else:doc.metadata['difficulty'] = '未知'@classmethoddef get_supported_categories(cls) -> List[str]:"""对外提供支持的分类标签列表"""return cls.CATEGORY_LABELS@classmethoddef get_supported_difficulties(cls) -> List[str]:"""对外提供支持的难度标签列表"""return cls.DIFFICULTY_LABELSdef chunk_documents(self) -> List[Document]:"""Markdown结构感知分块Returns:分块后的文档列表"""logger.info("正在进行Markdown结构感知分块...")if not self.documents:raise ValueError("请先加载文档")# 使用Markdown标题分割器chunks = self._markdown_header_split()# 为每个chunk添加基础元数据for i, chunk in enumerate(chunks):if 'chunk_id' not in chunk.metadata:# 如果没有chunk_id(比如分割失败的情况),则生成一个chunk.metadata['chunk_id'] = str(uuid.uuid4())chunk.metadata['batch_index'] = i # 在当前批次中的索引chunk.metadata['chunk_size'] = len(chunk.page_content)self.chunks = chunkslogger.info(f"Markdown分块完成,共生成 {len(chunks)} 个chunk")return chunksdef _markdown_header_split(self) -> List[Document]:"""使用Markdown标题分割器进行结构化分割Returns:按标题结构分割的文档列表"""# 定义要分割的标题层级headers_to_split_on = [("#", "主标题"), # 菜品名称("##", "二级标题"), # 必备原料、计算、操作等("###", "三级标题") # 简易版本、复杂版本等]# 创建Markdown分割器markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on,strip_headers=False # 保留标题,便于理解上下文)all_chunks = []for doc in self.documents:try:# 检查文档内容是否包含Markdown标题content_preview = doc.page_content[:200]has_headers = any(line.strip().startswith('#') for line in content_preview.split('\n'))if not has_headers:logger.warning(f"文档 {doc.metadata.get('dish_name', '未知')} 内容中没有发现Markdown标题")logger.debug(f"内容预览: {content_preview}")# 对每个文档进行Markdown分割md_chunks = markdown_splitter.split_text(doc.page_content)logger.debug(f"文档 {doc.metadata.get('dish_name', '未知')} 分割成 {len(md_chunks)} 个chunk")# 如果没有分割成功,说明文档可能没有标题结构if len(md_chunks) <= 1:logger.warning(f"文档 {doc.metadata.get('dish_name', '未知')} 未能按标题分割,可能缺少标题结构")# 为每个子块建立与父文档的关系parent_id = doc.metadata["parent_id"]for i, chunk in enumerate(md_chunks):# 为子块分配唯一IDchild_id = str(uuid.uuid4())# 合并原文档元数据和新的标题元数据chunk.metadata.update(doc.metadata)chunk.metadata.update({"chunk_id": child_id,"parent_id": parent_id,"doc_type": "child", # 标记为子文档"chunk_index": i # 在父文档中的位置})# 建立父子映射关系self.parent_child_map[child_id] = parent_idall_chunks.extend(md_chunks)except Exception as e:logger.warning(f"文档 {doc.metadata.get('source', '未知')} Markdown分割失败: {e}")# 如果Markdown分割失败,将整个文档作为一个chunkall_chunks.append(doc)logger.info(f"Markdown结构分割完成,生成 {len(all_chunks)} 个结构化块")return all_chunksdef filter_documents_by_category(self, category: str) -> List[Document]:"""按分类过滤文档Args:category: 菜品分类Returns:过滤后的文档列表"""return [doc for doc in self.documents if doc.metadata.get('category') == category]def filter_documents_by_difficulty(self, difficulty: str) -> List[Document]:"""按难度过滤文档Args:difficulty: 难度等级Returns:过滤后的文档列表"""return [doc for doc in self.documents if doc.metadata.get('difficulty') == difficulty]def get_statistics(self) -> Dict[str, Any]:"""获取数据统计信息Returns:统计信息字典"""if not self.documents:return {}categories = {}difficulties = {}for doc in self.documents:# 统计分类category = doc.metadata.get('category', '未知')categories[category] = categories.get(category, 0) + 1# 统计难度difficulty = doc.metadata.get('difficulty', '未知')difficulties[difficulty] = difficulties.get(difficulty, 0) + 1return {'total_documents': len(self.documents),'total_chunks': len(self.chunks),'categories': categories,'difficulties': difficulties,'avg_chunk_size': sum(chunk.metadata.get('chunk_size', 0) for chunk in self.chunks) / len(self.chunks) if self.chunks else 0}def export_metadata(self, output_path: str):"""导出元数据到JSON文件Args:output_path: 输出文件路径"""import jsonmetadata_list = []for doc in self.documents:metadata_list.append({'source': doc.metadata.get('source'),'dish_name': doc.metadata.get('dish_name'),'category': doc.metadata.get('category'),'difficulty': doc.metadata.get('difficulty'),'content_length': len(doc.page_content)})with open(output_path, 'w', encoding='utf-8') as f:json.dump(metadata_list, f, ensure_ascii=False, indent=2)logger.info(f"元数据已导出到: {output_path}")def get_parent_documents(self, child_chunks: List[Document]) -> List[Document]:"""根据子块获取对应的父文档(智能去重)Args:child_chunks: 检索到的子块列表Returns:对应的父文档列表(去重,按相关性排序)"""# 统计每个父文档被匹配的次数(相关性指标)parent_relevance = {}parent_docs_map = {}# 收集所有相关的父文档ID和相关性分数for chunk in child_chunks:parent_id = chunk.metadata.get("parent_id")if parent_id:# 增加相关性计数parent_relevance[parent_id] = parent_relevance.get(parent_id, 0) + 1# 缓存父文档(避免重复查找)if parent_id not in parent_docs_map:for doc in self.documents:if doc.metadata.get("parent_id") == parent_id:parent_docs_map[parent_id] = docbreak# 按相关性排序(匹配次数多的排在前面)sorted_parent_ids = sorted(parent_relevance.keys(),key=lambda x: parent_relevance[x],reverse=True)# 构建去重后的父文档列表parent_docs = []for parent_id in sorted_parent_ids:if parent_id in parent_docs_map:parent_docs.append(parent_docs_map[parent_id])# 收集父文档名称和相关性信息用于日志parent_info = []for doc in parent_docs:dish_name = doc.metadata.get('dish_name', '未知菜品')parent_id = doc.metadata.get('parent_id')relevance_count = parent_relevance.get(parent_id, 0)parent_info.append(f"{dish_name}({relevance_count}块)")logger.info(f"从 {len(child_chunks)} 个子块中找到 {len(parent_docs)} 个去重父文档: {', '.join(parent_info)}")return parent_docs索引构建与检索优化
"""
索引构建模块
"""import logging
from typing import List
from pathlib import Pathfrom langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Documentlogger = logging.getLogger(__name__)class IndexConstructionModule:"""索引构建模块 - 负责向量化和索引构建"""def __init__(self, model_name: str = "BAAI/bge-small-zh-v1.5", index_save_path: str = "./vector_index"):"""初始化索引构建模块Args:model_name: 嵌入模型名称index_save_path: 索引保存路径"""self.model_name = model_nameself.index_save_path = index_save_pathself.embeddings = Noneself.vectorstore = Noneself.setup_embeddings()def setup_embeddings(self):"""初始化嵌入模型"""logger.info(f"正在初始化嵌入模型: {self.model_name}")self.embeddings = HuggingFaceEmbeddings(model_name=self.model_name,model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True})logger.info("嵌入模型初始化完成")def build_vector_index(self, chunks: List[Document]) -> FAISS:"""构建向量索引Args:chunks: 文档块列表Returns:FAISS向量存储对象"""logger.info("正在构建FAISS向量索引...")if not chunks:raise ValueError("文档块列表不能为空")# 构建FAISS向量存储self.vectorstore = FAISS.from_documents(documents=chunks,embedding=self.embeddings)logger.info(f"向量索引构建完成,包含 {len(chunks)} 个向量")return self.vectorstoredef add_documents(self, new_chunks: List[Document]):"""向现有索引添加新文档Args:new_chunks: 新的文档块列表"""if not self.vectorstore:raise ValueError("请先构建向量索引")logger.info(f"正在添加 {len(new_chunks)} 个新文档到索引...")self.vectorstore.add_documents(new_chunks)logger.info("新文档添加完成")def save_index(self):"""保存向量索引到配置的路径"""if not self.vectorstore:raise ValueError("请先构建向量索引")# 确保保存目录存在Path(self.index_save_path).mkdir(parents=True, exist_ok=True)self.vectorstore.save_local(self.index_save_path)logger.info(f"向量索引已保存到: {self.index_save_path}")def load_index(self):"""从配置的路径加载向量索引Returns:加载的向量存储对象,如果加载失败返回None"""if not self.embeddings:self.setup_embeddings()if not Path(self.index_save_path).exists():logger.info(f"索引路径不存在: {self.index_save_path},将构建新索引")return Nonetry:self.vectorstore = FAISS.load_local(self.index_save_path,self.embeddings,allow_dangerous_deserialization=True)logger.info(f"向量索引已从 {self.index_save_path} 加载")return self.vectorstoreexcept Exception as e:logger.warning(f"加载向量索引失败: {e},将构建新索引")return Nonedef similarity_search(self, query: str, k: int = 5) -> List[Document]:"""相似度搜索Args:query: 查询文本k: 返回结果数量Returns:相似文档列表"""if not self.vectorstore:raise ValueError("请先构建或加载向量索引")return self.vectorstore.similarity_search(query, k=k)生成集成与系统整合
"""
生成集成模块
"""import os
import logging
from typing import Listfrom langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_community.chat_models.moonshot import MoonshotChat
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParserlogger = logging.getLogger(__name__)class GenerationIntegrationModule:"""生成集成模块 - 负责LLM集成和回答生成"""def __init__(self, model_name: str = "kimi-k2-0711-preview", temperature: float = 0.1, max_tokens: int = 2048):"""初始化生成集成模块Args:model_name: 模型名称temperature: 生成温度max_tokens: 最大token数"""self.model_name = model_nameself.temperature = temperatureself.max_tokens = max_tokensself.llm = Noneself.setup_llm()def setup_llm(self):"""初始化大语言模型"""logger.info(f"正在初始化LLM: {self.model_name}")api_key = os.getenv("MOONSHOT_API_KEY")if not api_key:raise ValueError("请设置 MOONSHOT_API_KEY 环境变量")self.llm = MoonshotChat(model=self.model_name,temperature=self.temperature,max_tokens=self.max_tokens,moonshot_api_key=api_key)logger.info("LLM初始化完成")def generate_basic_answer(self, query: str, context_docs: List[Document]) -> str:"""生成基础回答Args:query: 用户查询context_docs: 上下文文档列表Returns:生成的回答"""context = self._build_context(context_docs)prompt = ChatPromptTemplate.from_template("""
你是一位专业的烹饪助手。请根据以下食谱信息回答用户的问题。用户问题: {question}相关食谱信息:
{context}请提供详细、实用的回答。如果信息不足,请诚实说明。回答:""")# 使用LCEL构建链chain = ({"question": RunnablePassthrough(), "context": lambda _: context}| prompt| self.llm| StrOutputParser())response = chain.invoke(query)return responsedef generate_step_by_step_answer(self, query: str, context_docs: List[Document]) -> str:"""生成分步骤回答Args:query: 用户查询context_docs: 上下文文档列表Returns:分步骤的详细回答"""context = self._build_context(context_docs)prompt = ChatPromptTemplate.from_template("""
你是一位专业的烹饪导师。请根据食谱信息,为用户提供详细的分步骤指导。用户问题: {question}相关食谱信息:
{context}请灵活组织回答,建议包含以下部分(可根据实际内容调整):## 🥘 菜品介绍
[简要介绍菜品特点和难度]## 🛒 所需食材
[列出主要食材和用量]## 👨🍳 制作步骤
[详细的分步骤说明,每步包含具体操作和大概所需时间]## 💡 制作技巧
[仅在有实用技巧时包含。优先使用原文中的实用技巧,如果原文的"附加内容"与烹饪无关或为空,可以基于制作步骤总结关键要点,或者完全省略此部分]注意:
- 根据实际内容灵活调整结构
- 不要强行填充无关内容或重复制作步骤中的信息
- 重点突出实用性和可操作性
- 如果没有额外的技巧要分享,可以省略制作技巧部分回答:""")chain = ({"question": RunnablePassthrough(), "context": lambda _: context}| prompt| self.llm| StrOutputParser())response = chain.invoke(query)return responsedef query_rewrite(self, query: str) -> str:"""智能查询重写 - 让大模型判断是否需要重写查询Args:query: 原始查询Returns:重写后的查询或原查询"""prompt = PromptTemplate(template="""
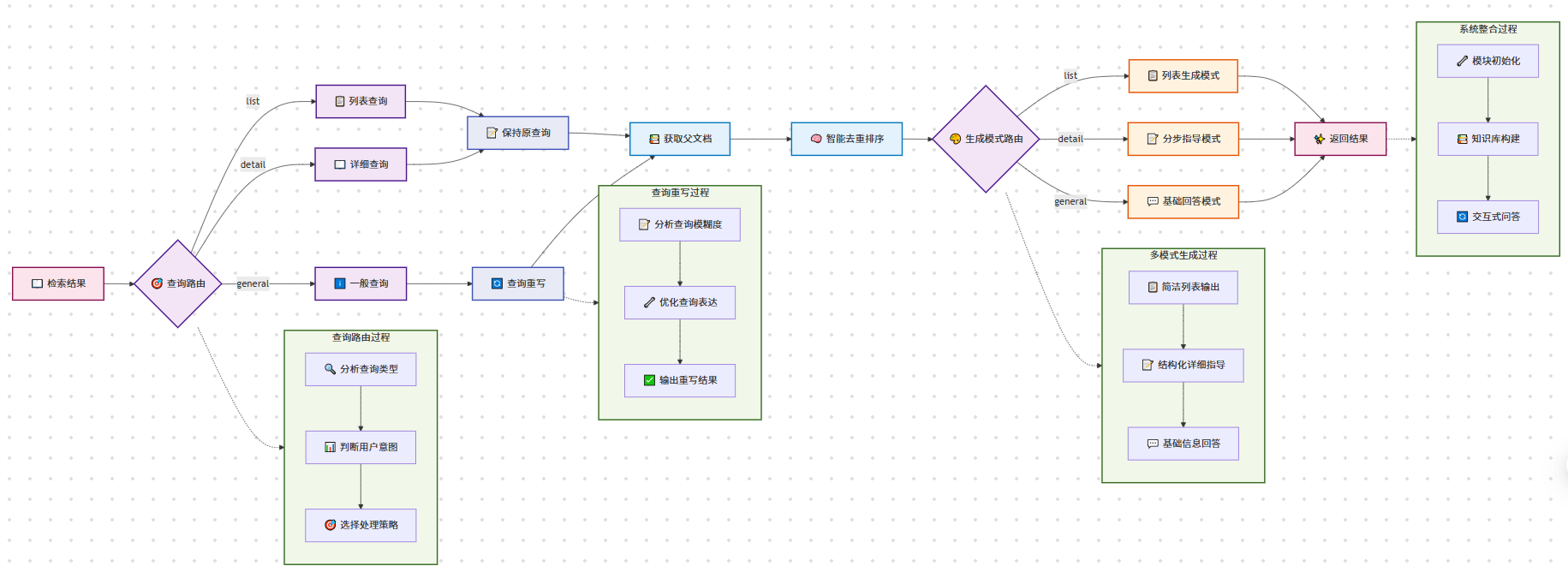
你是一个智能查询分析助手。请分析用户的查询,判断是否需要重写以提高食谱搜索效果。原始查询: {query}分析规则:
1. **具体明确的查询**(直接返回原查询):- 包含具体菜品名称:如"宫保鸡丁怎么做"、"红烧肉的制作方法"- 明确的制作询问:如"蛋炒饭需要什么食材"、"糖醋排骨的步骤"- 具体的烹饪技巧:如"如何炒菜不粘锅"、"怎样调制糖醋汁"2. **模糊不清的查询**(需要重写):- 过于宽泛:如"做菜"、"有什么好吃的"、"推荐个菜"- 缺乏具体信息:如"川菜"、"素菜"、"简单的"- 口语化表达:如"想吃点什么"、"有饮品推荐吗"重写原则:
- 保持原意不变
- 增加相关烹饪术语
- 优先推荐简单易做的
- 保持简洁性示例:
- "做菜" → "简单易做的家常菜谱"
- "有饮品推荐吗" → "简单饮品制作方法"
- "推荐个菜" → "简单家常菜推荐"
- "川菜" → "经典川菜菜谱"
- "宫保鸡丁怎么做" → "宫保鸡丁怎么做"(保持原查询)
- "红烧肉需要什么食材" → "红烧肉需要什么食材"(保持原查询)请输出最终查询(如果不需要重写就返回原查询):""",input_variables=["query"])chain = ({"query": RunnablePassthrough()}| prompt| self.llm| StrOutputParser())response = chain.invoke(query).strip()# 记录重写结果if response != query:logger.info(f"查询已重写: '{query}' → '{response}'")else:logger.info(f"查询无需重写: '{query}'")return responsedef query_router(self, query: str) -> str:"""查询路由 - 根据查询类型选择不同的处理方式Args:query: 用户查询Returns:路由类型 ('list', 'detail', 'general')"""prompt = ChatPromptTemplate.from_template("""
根据用户的问题,将其分类为以下三种类型之一:1. 'list' - 用户想要获取菜品列表或推荐,只需要菜名例如:推荐几个素菜、有什么川菜、给我3个简单的菜2. 'detail' - 用户想要具体的制作方法或详细信息例如:宫保鸡丁怎么做、制作步骤、需要什么食材3. 'general' - 其他一般性问题例如:什么是川菜、制作技巧、营养价值请只返回分类结果:list、detail 或 general用户问题: {query}分类结果:""")chain = ({"query": RunnablePassthrough()}| prompt| self.llm| StrOutputParser())result = chain.invoke(query).strip().lower()# 确保返回有效的路由类型if result in ['list', 'detail', 'general']:return resultelse:return 'general' # 默认类型def generate_list_answer(self, query: str, context_docs: List[Document]) -> str:"""生成列表式回答 - 适用于推荐类查询Args:query: 用户查询context_docs: 上下文文档列表Returns:列表式回答"""if not context_docs:return "抱歉,没有找到相关的菜品信息。"# 提取菜品名称dish_names = []for doc in context_docs:dish_name = doc.metadata.get('dish_name', '未知菜品')if dish_name not in dish_names:dish_names.append(dish_name)# 构建简洁的列表回答if len(dish_names) == 1:return f"为您推荐:{dish_names[0]}"elif len(dish_names) <= 3:return f"为您推荐以下菜品:\n" + "\n".join([f"{i+1}. {name}" for i, name in enumerate(dish_names)])else:return f"为您推荐以下菜品:\n" + "\n".join([f"{i+1}. {name}" for i, name in enumerate(dish_names[:3])]) + f"\n\n还有其他 {len(dish_names)-3} 道菜品可供选择。"def generate_basic_answer_stream(self, query: str, context_docs: List[Document]):"""生成基础回答 - 流式输出Args:query: 用户查询context_docs: 上下文文档列表Yields:生成的回答片段"""context = self._build_context(context_docs)prompt = ChatPromptTemplate.from_template("""
你是一位专业的烹饪助手。请根据以下食谱信息回答用户的问题。用户问题: {question}相关食谱信息:
{context}请提供详细、实用的回答。如果信息不足,请诚实说明。回答:""")chain = ({"question": RunnablePassthrough(), "context": lambda _: context}| prompt| self.llm| StrOutputParser())for chunk in chain.stream(query):yield chunkdef generate_step_by_step_answer_stream(self, query: str, context_docs: List[Document]):"""生成详细步骤回答 - 流式输出Args:query: 用户查询context_docs: 上下文文档列表Yields:详细步骤回答片段"""context = self._build_context(context_docs)prompt = ChatPromptTemplate.from_template("""
你是一位专业的烹饪导师。请根据食谱信息,为用户提供详细的分步骤指导。用户问题: {question}相关食谱信息:
{context}请灵活组织回答,建议包含以下部分(可根据实际内容调整):## 🥘 菜品介绍
[简要介绍菜品特点和难度]## 🛒 所需食材
[列出主要食材和用量]## 👨🍳 制作步骤
[详细的分步骤说明,每步包含具体操作和大概所需时间]## 💡 制作技巧
[仅在有实用技巧时包含。如果原文的"附加内容"与烹饪无关或为空,可以基于制作步骤总结关键要点,或者完全省略此部分]注意:
- 根据实际内容灵活调整结构
- 不要强行填充无关内容
- 重点突出实用性和可操作性回答:""")chain = ({"question": RunnablePassthrough(), "context": lambda _: context}| prompt| self.llm| StrOutputParser())for chunk in chain.stream(query):yield chunkdef _build_context(self, docs: List[Document], max_length: int = 2000) -> str:"""构建上下文字符串Args:docs: 文档列表max_length: 最大长度Returns:格式化的上下文字符串"""if not docs:return "暂无相关食谱信息。"context_parts = []current_length = 0for i, doc in enumerate(docs, 1):# 添加元数据信息metadata_info = f"【食谱 {i}】"if 'dish_name' in doc.metadata:metadata_info += f" {doc.metadata['dish_name']}"if 'category' in doc.metadata:metadata_info += f" | 分类: {doc.metadata['category']}"if 'difficulty' in doc.metadata:metadata_info += f" | 难度: {doc.metadata['difficulty']}"# 构建文档文本doc_text = f"{metadata_info}\n{doc.page_content}\n"# 检查长度限制if current_length + len(doc_text) > max_length:breakcontext_parts.append(doc_text)current_length += len(doc_text)return "\n" + "="*50 + "\n".join(context_parts)根据环境修改main.py
"""
RAG系统主程序
"""import os
import sys
import logging
from pathlib import Path
from typing import List# 添加模块路径
sys.path.append(str(Path(__file__).parent))from dotenv import load_dotenv
from config import DEFAULT_CONFIG, RAGConfig
# from code.C8.config原始 import DEFAULT_CONFIG, RAGConfig
from rag_modules import (DataPreparationModule,IndexConstructionModule,RetrievalOptimizationModule,GenerationIntegrationModule
)# 加载环境变量
load_dotenv()# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)class RecipeRAGSystem:"""食谱RAG系统主类"""def __init__(self, config: RAGConfig = None):"""初始化RAG系统Args:config: RAG系统配置,默认使用DEFAULT_CONFIG"""self.config = config or DEFAULT_CONFIGself.data_module = Noneself.index_module = Noneself.retrieval_module = Noneself.generation_module = None# 检查数据路径if not Path(self.config.data_path).exists():raise FileNotFoundError(f"数据路径不存在: {self.config.data_path}")# 检查API密钥if not os.getenv("MOONSHOT_API_KEY"):raise ValueError("请设置 MOONSHOT_API_KEY 环境变量")def initialize_system(self):"""初始化所有模块"""print("🚀 正在初始化RAG系统...")# 1. 初始化数据准备模块print("初始化数据准备模块...")self.data_module = DataPreparationModule(self.config.data_path)# 2. 初始化索引构建模块print("初始化索引构建模块...")self.index_module = IndexConstructionModule(model_name=self.config.embedding_model,index_save_path=self.config.index_save_path)# 3. 初始化生成集成模块print("🤖 初始化生成集成模块...")self.generation_module = GenerationIntegrationModule(model_name=self.config.llm_model,temperature=self.config.temperature,max_tokens=self.config.max_tokens)print("✅ 系统初始化完成!")def build_knowledge_base(self):"""构建知识库"""print("\n正在构建知识库...")# 1. 尝试加载已保存的索引vectorstore = self.index_module.load_index()if vectorstore is not None:print("✅ 成功加载已保存的向量索引!")# 仍需要加载文档和分块用于检索模块print("加载食谱文档...")self.data_module.load_documents()print("进行文本分块...")chunks = self.data_module.chunk_documents()else:print("未找到已保存的索引,开始构建新索引...")# 2. 加载文档print("加载食谱文档...")self.data_module.load_documents()# 3. 文本分块print("进行文本分块...")chunks = self.data_module.chunk_documents()# 4. 构建向量索引print("构建向量索引...")vectorstore = self.index_module.build_vector_index(chunks)# 5. 保存索引print("保存向量索引...")self.index_module.save_index()# 6. 初始化检索优化模块print("初始化检索优化...")self.retrieval_module = RetrievalOptimizationModule(vectorstore, chunks)# 7. 显示统计信息stats = self.data_module.get_statistics()print(f"\n📊 知识库统计:")print(f" 文档总数: {stats['total_documents']}")print(f" 文本块数: {stats['total_chunks']}")print(f" 菜品分类: {list(stats['categories'].keys())}")print(f" 难度分布: {stats['difficulties']}")print("✅ 知识库构建完成!")def ask_question(self, question: str, stream: bool = False):"""回答用户问题Args:question: 用户问题stream: 是否使用流式输出Returns:生成的回答或生成器"""if not all([self.retrieval_module, self.generation_module]):raise ValueError("请先构建知识库")print(f"\n❓ 用户问题: {question}")# 1. 查询路由route_type = self.generation_module.query_router(question)print(f"🎯 查询类型: {route_type}")# 2. 智能查询重写(根据路由类型)if route_type == 'list':# 列表查询保持原查询rewritten_query = questionprint(f"📝 列表查询保持原样: {question}")else:# 详细查询和一般查询使用智能重写print("🤖 智能分析查询...")rewritten_query = self.generation_module.query_rewrite(question)# 3. 检索相关子块(自动应用元数据过滤)print("🔍 检索相关文档...")filters = self._extract_filters_from_query(question)if filters:print(f"应用过滤条件: {filters}")relevant_chunks = self.retrieval_module.metadata_filtered_search(rewritten_query, filters, top_k=self.config.top_k)else:relevant_chunks = self.retrieval_module.hybrid_search(rewritten_query, top_k=self.config.top_k)# 显示检索到的子块信息if relevant_chunks:chunk_info = []for chunk in relevant_chunks:dish_name = chunk.metadata.get('dish_name', '未知菜品')# 尝试从内容中提取章节标题content_preview = chunk.page_content[:50].replace('\n', ' ').strip()if content_preview.startswith('#'):# 如果是标题开头,提取标题title_end = content_preview.find('\n') if '\n' in chunk.page_content[:100] else len(content_preview)section_title = chunk.page_content[:title_end].strip('#').strip()chunk_info.append(f"{dish_name}({section_title})")else:chunk_info.append(f"{dish_name}(内容片段)")print(f"找到 {len(relevant_chunks)} 个相关文档块: {', '.join(chunk_info)}")else:print(f"找到 {len(relevant_chunks)} 个相关文档块")# 4. 检查是否找到相关内容if not relevant_chunks:return "抱歉,没有找到相关的食谱信息。请尝试其他菜品名称或关键词。"# 5. 根据路由类型选择回答方式if route_type == 'list':# 列表查询:直接返回菜品名称列表print("📋 生成菜品列表...")relevant_docs = self.data_module.get_parent_documents(relevant_chunks)# 显示找到的文档名称doc_names = []for doc in relevant_docs:dish_name = doc.metadata.get('dish_name', '未知菜品')doc_names.append(dish_name)if doc_names:print(f"找到文档: {', '.join(doc_names)}")return self.generation_module.generate_list_answer(question, relevant_docs)else:# 详细查询:获取完整文档并生成详细回答print("获取完整文档...")relevant_docs = self.data_module.get_parent_documents(relevant_chunks)# 显示找到的文档名称doc_names = []for doc in relevant_docs:dish_name = doc.metadata.get('dish_name', '未知菜品')doc_names.append(dish_name)if doc_names:print(f"找到文档: {', '.join(doc_names)}")else:print(f"对应 {len(relevant_docs)} 个完整文档")print("✍️ 生成详细回答...")# 根据路由类型自动选择回答模式if route_type == "detail":# 详细查询使用分步指导模式if stream:return self.generation_module.generate_step_by_step_answer_stream(question, relevant_docs)else:return self.generation_module.generate_step_by_step_answer(question, relevant_docs)else:# 一般查询使用基础回答模式if stream:return self.generation_module.generate_basic_answer_stream(question, relevant_docs)else:return self.generation_module.generate_basic_answer(question, relevant_docs)def _extract_filters_from_query(self, query: str) -> dict:"""从用户问题中提取元数据过滤条件"""filters = {}# 分类关键词category_keywords = DataPreparationModule.get_supported_categories()for cat in category_keywords:if cat in query:filters['category'] = catbreak# 难度关键词difficulty_keywords = DataPreparationModule.get_supported_difficulties()for diff in sorted(difficulty_keywords, key=len, reverse=True):if diff in query:filters['difficulty'] = diffbreakreturn filtersdef search_by_category(self, category: str, query: str = "") -> List[str]:"""按分类搜索菜品Args:category: 菜品分类query: 可选的额外查询条件Returns:菜品名称列表"""if not self.retrieval_module:raise ValueError("请先构建知识库")# 使用元数据过滤搜索search_query = query if query else categoryfilters = {"category": category}docs = self.retrieval_module.metadata_filtered_search(search_query, filters, top_k=10)# 提取菜品名称dish_names = []for doc in docs:dish_name = doc.metadata.get('dish_name', '未知菜品')if dish_name not in dish_names:dish_names.append(dish_name)return dish_namesdef get_ingredients_list(self, dish_name: str) -> str:"""获取指定菜品的食材信息Args:dish_name: 菜品名称Returns:食材信息"""if not all([self.retrieval_module, self.generation_module]):raise ValueError("请先构建知识库")# 搜索相关文档docs = self.retrieval_module.hybrid_search(dish_name, top_k=3)# 生成食材信息answer = self.generation_module.generate_basic_answer(f"{dish_name}需要什么食材?", docs)return answerdef run_interactive(self):"""运行交互式问答"""print("=" * 60)print("🍽️ 尝尝咸淡RAG系统 - 交互式问答 🍽️")print("=" * 60)print("💡 解决您的选择困难症,告别'今天吃什么'的世纪难题!")# 初始化系统self.initialize_system()# 构建知识库self.build_knowledge_base()print("\n交互式问答 (输入'退出'结束):")while True:try:user_input = input("\n您的问题: ").strip()if user_input.lower() in ['退出', 'quit', 'exit', '']:break# 询问是否使用流式输出stream_choice = input("是否使用流式输出? (y/n, 默认y): ").strip().lower()use_stream = stream_choice != 'n'print("\n回答:")if use_stream:# 流式输出for chunk in self.ask_question(user_input, stream=True):print(chunk, end="", flush=True)print("\n")else:# 普通输出answer = self.ask_question(user_input, stream=False)print(f"{answer}\n")except KeyboardInterrupt:breakexcept Exception as e:print(f"处理问题时出错: {e}")print("\n感谢使用尝尝咸淡RAG系统!")def main():"""主函数"""try:# 创建RAG系统rag_system = RecipeRAGSystem()# 运行交互式问答rag_system.run_interactive()except Exception as e:logger.error(f"系统运行出错: {e}")print(f"系统错误: {e}")if __name__ == "__main__":main()
根据环境修改config.py
"""
RAG系统配置文件
"""import os
from dataclasses import dataclass
from typing import Dict, Any@dataclass
class RAGConfig:"""RAG系统配置类"""# 路径配置data_path: str = "../../data/C8/cook"index_save_path: str = "./vector_index"# 模型配置 - 使用本地模型路径embedding_model: str = "E:/Datawhale/All in rag 202509/code/all-in-rag-main/models/bge-small-zh-v1___5"llm_model: str = "kimi-k2-0711-preview"# API Key 配置moonshot_api_key: str = None# 检索配置top_k: int = 3# 生成配置temperature: float = 0.1max_tokens: int = 2048def __post_init__(self):"""初始化后的处理"""# 从环境变量读取 API Keyif self.moonshot_api_key is None:self.moonshot_api_key = os.getenv('MOONSHOT_API_KEY')# 验证 API Keyif not self.moonshot_api_key:raise ValueError("请设置 MOONSHOT_API_KEY 环境变量")# 验证本地模型路径是否存在if not os.path.exists(self.embedding_model):raise ValueError(f"本地模型路径不存在: {self.embedding_model}")@classmethoddef from_dict(cls, config_dict: Dict[str, Any]) -> 'RAGConfig':"""从字典创建配置对象"""return cls(**config_dict)def to_dict(self) -> Dict[str, Any]:"""转换为字典"""return {'data_path': self.data_path,'index_save_path': self.index_save_path,'embedding_model': self.embedding_model,'llm_model': self.llm_model,'moonshot_api_key': '***' if self.moonshot_api_key else None,'top_k': self.top_k,'temperature': self.temperature,'max_tokens': self.max_tokens}# 默认配置实例
DEFAULT_CONFIG = RAGConfig()运行如下:
(cook-rag-1) PS E:\Datawhale\All in rag 202509\code\all-in-rag-main\code\C8> python main.py
============================================================
🍽️ 尝尝咸淡RAG系统 - 交互式问答 🍽️
============================================================
💡 解决您的选择困难症,告别'今天吃什么'的世纪难题!
🚀 正在初始化RAG系统...
初始化数据准备模块...
初始化索引构建模块...
2025-10-03 12:38:46,361 - rag_modules.index_construction - INFO - 正在初始化嵌入模型: E:/Datawhale/All in rag 202509/code/all-in-rag-main/models/bge-small-zh-v1___5
2025-10-03 12:38:48,254 - sentence_transformers.SentenceTransformer - INFO - Load pretrained SentenceTransformer: E:/Datawhale/All in rag 202509/code/all-in-rag-main/models/bge-small-zh-v1___5
2025-10-03 12:38:48,654 - rag_modules.index_construction - INFO - 嵌入模型初始化完成
🤖 初始化生成集成模块...
2025-10-03 12:38:48,654 - rag_modules.generation_integration - INFO - 正在初始化LLM: kimi-k2-0711-preview
2025-10-03 12:38:49,355 - rag_modules.generation_integration - INFO - LLM初始化完成
✅ 系统初始化完成!正在构建知识库...
2025-10-03 12:38:49,355 - faiss.loader - INFO - Loading faiss with AVX2 support.
2025-10-03 12:38:49,386 - faiss.loader - INFO - Successfully loaded faiss with AVX2 support.
2025-10-03 12:38:49,413 - rag_modules.index_construction - INFO - 向量索引已从 ./vector_index 加载
✅ 成功加载已保存的向量索引!
加载食谱文档...
2025-10-03 12:38:49,413 - rag_modules.data_preparation - INFO - 正在从 ../../data/C8/cook 加载文档...
2025-10-03 12:38:49,583 - rag_modules.data_preparation - INFO - 成功加载 323 个文档
进行文本分块...
2025-10-03 12:38:49,583 - rag_modules.data_preparation - INFO - 正在进行Markdown结构感知分块...
2025-10-03 12:38:49,641 - rag_modules.data_preparation - INFO - Markdown结构分割完成,生成 1764 个结构化块
2025-10-03 12:38:49,641 - rag_modules.data_preparation - INFO - Markdown分块完成,共生成 1764 个chunk
初始化检索优化...
2025-10-03 12:38:49,641 - rag_modules.retrieval_optimization - INFO - 正在设置检索器...
2025-10-03 12:38:49,668 - rag_modules.retrieval_optimization - INFO - 检索器设置完成📊 知识库统计:
文档总数: 323
文本块数: 1764
菜品分类: ['水产', '早餐', '调料', '饮品', '荤菜', '其他', '汤品', '主食', '素菜', '甜品']
难度分布: {'困难': 78, '中等': 115, '非常简单': 27, '简单': 83, '非常困难': 20}
✅ 知识库构建完成!交互式问答 (输入'退出'结束):
您的问题: 大虾
是否使用流式输出? (y/n, 默认y): y回答:
❓ 用户问题: 大虾
2025-10-03 12:39:27,576 - httpx - INFO - HTTP Request: POST https://api.moonshot.cn/v1/chat/completions "HTTP/1.1 200 OK"
🎯 查询类型: list
📝 列表查询保持原样: 大虾
🔍 检索相关文档...
E:\Datawhale\All in rag 202509\code\all-in-rag-main\code\C8\rag_modules\retrieval_optimization.py:61: LangChainDeprecationWarning: The method `BaseRetriever.get_relevant_documents` was deprecated in langchain-core 0.1.46 and will be removed in 1.0. Use :meth:`~invoke` instead.
vector_docs = self.vector_retriever.get_relevant_documents(query)
vector_docs = self.vector_retriever.get_relevant_documents(query)
vector_docs = self.vector_retriever.get_relevant_documents(query)
vector_docs = self.vector_retriever.get_relevant_documents(query)
vector_docs = self.vector_retriever.get_relevant_documents(query)
2025-10-03 12:39:28,419 - rag_modules.retrieval_optimization - INFO - RRF重排完成: 向量检索5个文档, BM25检索5个文档, 合并后10个文档
找到 3 个相关文档块: 油焖大虾(油焖大虾的做法
预估烹饪难度:★★★), 蒜香黄油虾(计算
2025-10-03 12:39:28,419 - rag_modules.retrieval_optimization - INFO - RRF重排完成: 向量检索5个文档, BM25检索5个文档, 合并后10个文档
找到 3 个相关文档块: 油焖大虾(油焖大虾的做法
预估烹饪难度:★★★), 蒜香黄油虾(计算
预估烹饪难度:★★★), 蒜香黄油虾(计算
每次制作前需要确定计划做几份。一份正好够 1-2 人食用。
每次制作前需要确定计划做几份。一份正好够 1-2 人食用。
每份:
- 大虾 8-10 只(约 200g)
每份:
- 大虾 8-10 只(约 200g)
- 无盐黄油 30g
- 无盐黄油 30g
- 大蒜 4 瓣(约 20g)
- 大蒜 4 瓣(约 20g)
- 白葡萄酒 15ml(可选)
- 柠檬 1/4 个
- 白葡萄酒 15ml(可选)
- 柠檬 1/4 个
- 橄榄油 10m), 蒜香黄油虾(操作
- 大虾去头去壳留尾,用牙签挑去虾线,洗净后用厨房纸吸干水分
- 大虾去头去壳留尾,用牙签挑去虾线,洗净后用厨房纸吸干水分
- 大蒜切成蒜末,备用
- 中火加热平底锅,放入 10ml 橄榄油
- 油热后放入大虾,每面煎 1-1.5 分钟至变色,取出备用
- 同一锅中加入黄油,融化后放入蒜末,小火炒香(约 30 秒)
- 如使用白葡萄酒,此时加入并煮至酒精挥发(约 1 分钟)
- 如使用白葡萄酒,此时加入并煮至酒精挥发(约 1 分钟)
- 将虾放回锅中,与蒜香黄油酱汁翻炒均匀(约 1 分钟)
- 挤入柠檬汁,翻炒均匀后立即关火
- 装盘,淋上锅中剩余酱)
📋 生成菜品列表...
2025-10-03 12:39:28,420 - rag_modules.data_preparation - INFO - 从 3 个子块中找到 2 个去重父文档: 蒜香黄油虾(2块), 油焖大虾(1块)
找到文档: 蒜香黄油虾, 油焖大虾
为您推荐以下菜品:
1. 蒜香黄油虾
2. 油焖大虾