Nacos 工作原理及流量走向
Nacos 的工作原理核心是围绕服务生命周期管理和配置全流程管控两大模块,通过 “客户端 - 服务端” 交互 +“集群化高可用设计” 实现,访问流量则根据 “服务注册 / 发现”“配置读写” 等场景有明确走向。
一、核心模块工作原理(含流量走向)
1. 服务注册与发现(最核心场景)
这是微服务架构中 “服务间找到彼此” 的关键流程,流量在服务实例(客户端)→ Nacos 集群(服务端)→ 消费端(客户端) 之间流转,分 3 个关键步骤:
(1)服务注册:实例 “报到”,流量从服务端到 Nacos
- 触发时机:服务提供者(如订单服务)启动时,内置的 Nacos 客户端自动发起注册。
- 流量走向:
服务实例(IP:Port)→ Nacos集群(任意节点,通过负载均衡) - 具体过程:
- 客户端封装注册请求:包含服务名(serviceName,如 order-service) 、实例 IP、端口、健康检查参数(心跳间隔等)。
- 流量通过 HTTP/GRPC 协议发送到 Nacos 集群(若集群部署,请求会先到负载均衡器,再转发到任意 Nacos 节点)。
- Nacos 服务端处理:
- 接收请求的节点将注册信息写入内存注册表(默认,支持持久化到 MySQL),同时生成实例的 “健康状态”(初始为 UP)。
- 通过Raft 协议将注册信息同步到集群其他节点,确保所有节点数据一致(避免单点故障)。
- 向客户端返回 “注册成功” 响应。
(2)健康检查:Nacos “盯防” 实例,确保流量不流向故障节点
- 核心目的:剔除故障实例,避免消费端调用失败。
- 流量走向:
Nacos集群 ↔ 服务实例(双向心跳) - 具体过程:
- 客户端主动心跳:服务实例(客户端)每隔 5 秒向 Nacos 发送 “心跳包”(含服务名、实例 ID),证明自己存活。
- 服务端被动检测:
- 若 Nacos 超过 15 秒未收到某实例心跳,将其标记为 “不健康”(状态变为 UNHEALTHY),此时该实例不会被推送给消费端。
- 若超过 30 秒未收到心跳,直接从注册表中删除该实例,并通过 Raft 同步到集群所有节点。
- 主动检测(可选):若实例无法发心跳(如网络分区),Nacos 可配置 TCP/HTTP 主动探测实例端口,探测失败则标记为不健康。
(3)服务发现:消费端 “找服务”,流量从 Nacos 到消费端
- 触发时机:服务消费者(如支付服务)启动时,或服务列表更新时。
- 流量走向:
消费端 → Nacos集群 → 消费端(拉取 + 推送结合) - 具体过程:
- 初始拉取:消费端启动时,通过 “服务名” 向 Nacos 发送 “获取服务列表” 请求,Nacos 返回该服务下所有 “健康实例” 列表(含 IP、端口、权重等),消费端本地缓存列表。
- 实时更新(拉取 + 推送):
- 定时拉取:消费端每隔 30 秒向 Nacos 发起 “增量拉取” 请求(仅拉取上次之后变化的实例),更新本地缓存,避免全量拉取的性能损耗。
- 主动推送:若服务列表发生变化(如实例上线 / 下线 / 不健康),Nacos 会主动通过长连接(GRPC)向所有订阅该服务的消费端 “推送更新”,确保消费端能实时拿到最新列表(延迟 < 1 秒)。
- 消费端调用:消费端从本地缓存的实例列表中,通过负载均衡(如轮询、随机)选择一个实例,发起业务调用(此时流量不经过 Nacos,直接在服务间流转)。
2. 配置中心(集中管理配置,避免硬编码)
核心是 “配置集中存储、动态推送”,流量在配置管理员→Nacos 集群→应用实例之间流转,分 4 个步骤:
(1)配置发布:管理员上传配置,流量从管理端到 Nacos
- 触发时机:开发 / 运维人员在 Nacos 控制台、或通过 API/SDK 上传配置。
- 流量走向:
配置管理端(控制台/API)→ Nacos集群 - 具体过程:
- 管理员指定配置的唯一标识:
Data ID(如 payment-service-dev.yaml)、Group(如 DEFAULT_GROUP,用于分组隔离)、Namespace(如 dev/test/prod,用于环境隔离)。 - 上传配置内容(Key-Value 格式,支持 YAML/JSON/Properties 等),Nacos 服务端将配置:
- 存储到MySQL(持久化,避免集群重启丢失)。
- 生成配置的MD5 值(用于后续客户端对比是否更新)。
- 通过 Raft 同步到集群所有节点,确保配置一致性。
- 管理员指定配置的唯一标识:
(2)配置拉取:应用实例 “拿配置”,流量从 Nacos 到应用
- 触发时机:应用实例(客户端)启动时。
- 流量走向:
应用实例 → Nacos集群 → 应用实例 - 具体过程:
- 应用实例启动时,通过 “Data ID+Group+Namespace” 向 Nacos 发送 “拉取配置” 请求。
- Nacos 返回对应的配置内容和 MD5 值,应用实例:
- 将配置加载到本地内存(或本地文件),用于业务逻辑。
- 缓存 MD5 值(后续用于对比配置是否变化)。
(3)配置监听:实例 “盯配置更新”,流量从 Nacos 到应用
- 核心目的:配置修改后,应用无需重启即可生效。
- 流量走向:
Nacos集群 → 应用实例(主动推送) - 具体过程:
- 应用实例拉取配置后,会与 Nacos 建立长连接(HTTP 长轮询,默认 30 秒超时),持续监听该配置的变化。
- 当管理员修改配置并发布后,Nacos 服务端:
- 更新 MySQL 中的配置,重新生成 MD5 值。
- 检测到该配置有监听实例,立即通过长连接 “推送更新通知”(含新 MD5 值)。
- 应用实例收到通知后,对比本地缓存的 MD5 值:若不一致,主动向 Nacos 拉取新配置,更新本地缓存和业务配置(全程无需重启应用)。
(4)配置回滚:恢复历史版本,流量从管理端到 Nacos
- 若新配置有 bug,管理员可在 Nacos 控制台选择 “历史版本” 回滚,Nacos 会将历史配置重新写入 MySQL,同时触发 “配置推送” 流程,让所有实例加载旧配置,快速恢复服务。
二、Nacos 集群高可用原理(支撑大规模流量)
单机 Nacos 无法应对高并发和单点故障,生产环境必须部署集群,核心依赖Raft 协议和负载均衡:
1. 集群节点角色(基于 Raft)
Nacos 集群中每个节点有 3 种角色,通过 Raft 选举产生,确保数据一致:
- Leader(领导者):唯一负责处理 “写请求”(如服务注册、配置发布),将数据同步给 Follower;若 Leader 宕机,Follower 会重新选举新 Leader。
- Follower(追随者):处理 “读请求”(如服务发现、配置拉取),同时同步 Leader 的数据;若收到写请求,会转发给 Leader。
- Candidate(候选人):Leader 宕机时,Follower 会转为 Candidate,参与新 Leader 选举(获得半数以上节点投票者成为新 Leader)。
2. 集群流量分发(负载均衡)
- 前端负载均衡:所有客户端(服务实例、消费端、管理端)的请求,先发送到NGINX / 阿里云 SLB等负载均衡器,由负载均衡器将请求分发到任意 Nacos 节点(Follower 优先处理读请求,Leader 处理写请求)。
- 后端数据同步:Leader 处理写请求后,通过 Raft 将数据同步到所有 Follower,确保所有节点数据一致,因此客户端访问任意节点,都能拿到正确的服务列表或配置。
三、关键总结(流量走向核心路径)
| 场景 | 核心流量走向 | 关键协议 / 机制 |
|---|---|---|
| 服务注册 | 服务实例 → 负载均衡器 → Nacos 集群(Leader) | HTTP/GRPC + Raft 同步 |
| 服务发现(拉取) | 消费端 → 负载均衡器 → Nacos 集群(Follower) | HTTP/GRPC |
| 服务发现(推送) | Nacos 集群 → 消费端 | GRPC 长连接 |
| 配置发布 | 管理端 → 负载均衡器 → Nacos 集群(Leader) | HTTP/GRPC + Raft 同步 |
| 配置拉取 / 监听 | 应用实例 ↔ Nacos 集群(Follower) | HTTP 长轮询 |
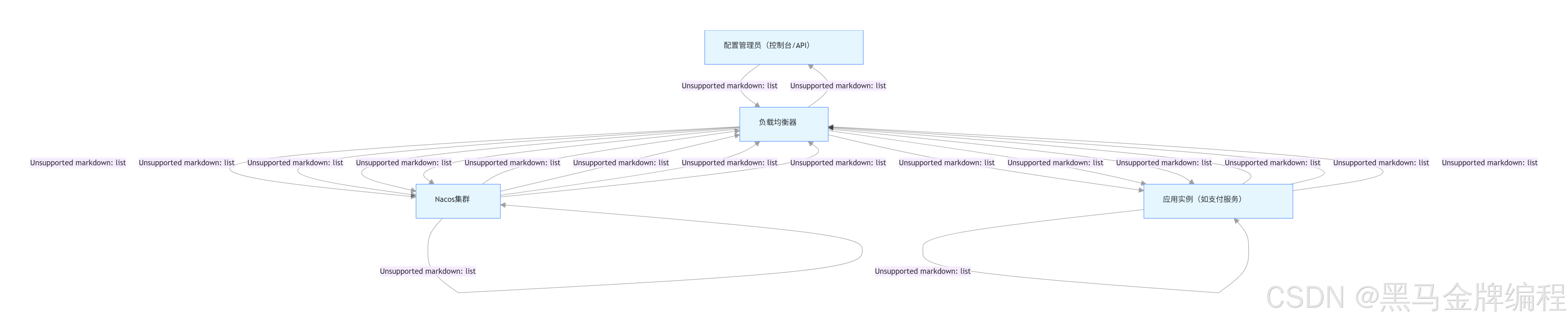
Nacos 核心场景的流量走向流程图(比如服务注册发现全链路),用可视化方式标注每个节点的交互,如下:
一、服务注册发现全链路流量图
(核心角色:服务提供者、Nacos 集群、服务消费者、负载均衡器(SLB/NGINX))
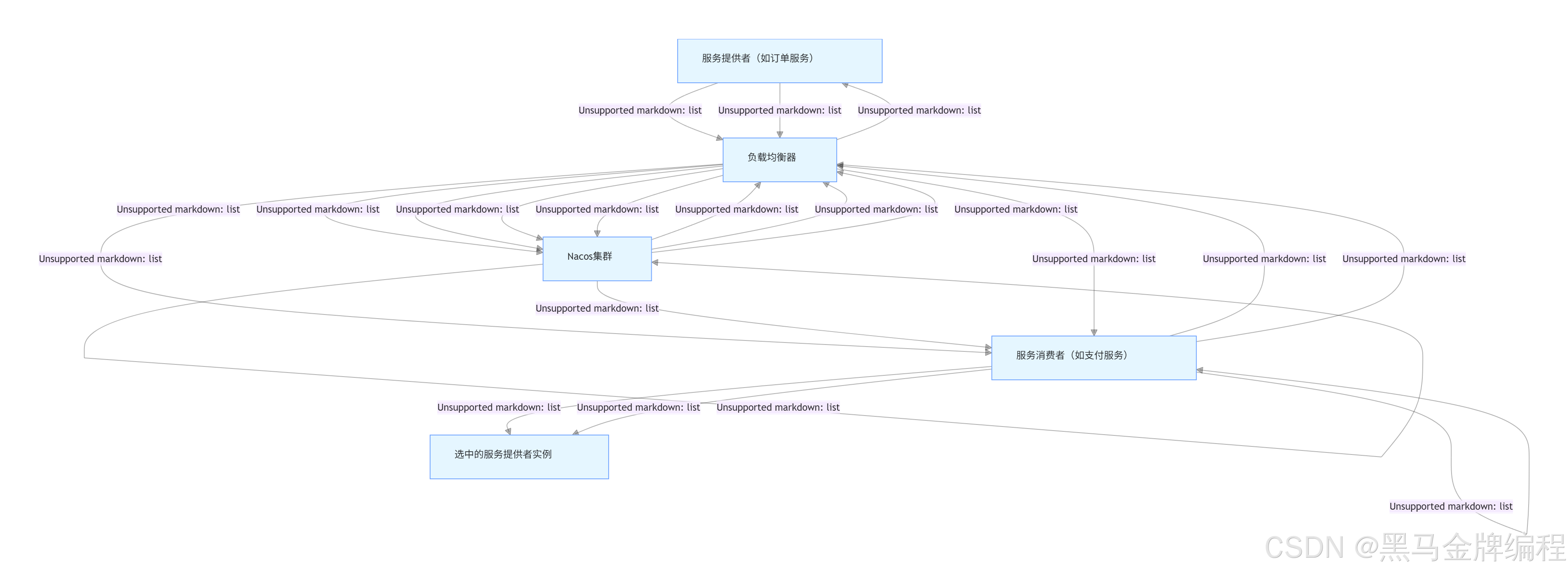
二、配置中心全链路流量图
(核心角色:配置管理员、Nacos 集群、应用实例、负载均衡器)