DreamControl——结合扩散模型和RL的全身人形控制:利用在人体运动数据上训练得到的扩散先验,随后在仿真中引导RL策略完成特定任务
前言
博客很快将突破2500万访问量,在周更博客的同时,视频号也会作为博客之外 重点打造
而历经“数据结构/算法、机器学习、深度学习、大模型、具身智能”五大时代的十多年(本博客也算是陪伴、影响、帮助了好几代人),最终还是觉得:热爱,可抵岁月漫长,可解决一切问题
顺带觉得,相比大模型的paper而言,具身相关paper中的数学推导 还是相对少些的,原因有多种,其中之一便是
- 大模型paper更侧重理论层面的突破
- 而有相当一部分的具身paper 更加侧重大模型前沿技术在机器人身上的落地(当然,也有不少具身paper会侧重理论技术的突破)
由于我和我司更看重落地——包括过去一年中 一个个集团客户基本都是奔着让机器人干活而找到我或我们,故对于loco-manipulation方面的关注远高于单纯的locomotion,故而关注到本文待解读的DreamControl
第一部分 DreamControl:受人类启发的全身类人控制,通过引导扩散实现场景交互
1.1 引言与相关工作
1.1.1 引言
如原DreamControl论文所说,近年来,人形机器人控制领域取得了重大进展,尤其是在行走和动作追踪方面,促成了诸如机器人跳舞[1][2]和机器人功夫[3]等令人印象深刻的展示
然而,要让人形机器人从单纯的展览品转变为通用型助手,它们必须能够充分发挥人形结构的灵活性和广泛的运动范围,与环境进行高效互动。这包括诸如弯腰捡拾物品、下蹲搬运重箱、支撑打开抽屉或门,以及对特定目标进行精确的推动、击打或踢击等任务
这些任务有时被称为全身操作和运动-操作任务,并且仍然对人形机器人领域构成重大挑战。现有的人形机器人操作方法通常通过
- 固定下半身(例如,[4])
- 将上下半身分开训练,并让下半身对上半身的动作做出反应(例如,[5])
- 或仅专注于计算机图形学应用(例如,[6],[7])来简化问题
全身运动操作中的一个主要挑战是需要应对多重时间尺度
- 首先,动态维持稳定和平衡本身就是一个难题,这需要在亚秒级别实现短时域控制和鲁棒性,而高自由度、欠驱动性以及高重心等因素使得这一问题更加复杂。近期的方法通过强化学习(RL)和仿真到现实的迁移来应对这一部分的挑战
- 与此同时,机器人还需要为抓取远处物体制定运动规划,这属于长时域问题,持续时间可达数十秒
双臂操作的长时域和高维特性使得强化学习探索问题尤为复杂,要求两组手臂和手之间实现复杂且精确的协调
因此,在此类场景中直接应用强化学习,往往会失败或导致难以泛化到现实世界的不自然行为[8]
因此,现代方法通常依赖于真实世界数据收集和模仿学习。在这些方法中,扩散策略[9](以及相关的基于流匹配的方法[10])在生成长时序、一致性的时序数据方面表现出色,为应对这些挑战提供了潜在的解决方案
- 从概念上讲,基于扩散的方法非常适合处理操作任务中动作分布的多模态特性,并且具备良好的可扩展性,能够同时学习多种任务
- 然而,一个复杂之处在于,针对全身人形机器人控制的遥操作数据有限,导致一些研究团队提出仅使用上半身遥操作数据
无论采用何种形式,大规模收集遥操作数据仍然是一项挑战——毕竟摇操采集属于劳动密集型且难以扩展
对此,来自1 General Robotics、2 University of California, Berkeley、3 Brown University的研究者提出了DreamControl
- 其paper地址为:DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
其作者包括
Dvij Kalaria1,2、Sudarshan Harithas1,3、Pushkal Katara1、Sangkyung Kwak1
Sarthak Bhagat1、S. Shankar Sastry2、Srinath Sridhar3、Sai Vemprala1、Ashish Kapoor1、Jonathan Huang1 - 其项目地址为:genrobo.github.io/DreamControl
截止到25年10月初,其代码尚未公布
具体而言,这是一种两阶段方法论,用于学习自主的全身技能,明确针对上述问题,并结合扩散模型与强化学习(RL)的优势

- 他们的核心创新在于对人类动作引入扩散先验,具体采用OmniControl [12],该方法以文本条件(例如“打开抽屉”)和时空引导(例如在特定时间强制手腕处于某一位置)为输入
- 随后,将该先验中的动作样本重新定向至目标机器人的形态,并在仿真环境中训练RL策略,使其能够跟随这些重定向的动作样本,同时完成特定任务(如搬起重物箱)
作者展示了该策略的特权版与非特权版均可通过少量修改进行训练,从而便于在真实机器人上的部署
更进一步而言
- 首先,DreamControl在训练扩散先验时,仅依赖于人类数据,而不是遥操作数据。人类动作数据更加丰富(例如来自动作捕捉和视频源),并且由于这些数据仅用于构建先验,我们在策略执行过程中无需访问明确的参考轨迹,从而实现了完全自主的任务执行
作者证明,这种先验能够让强化学习发现直接RL方法无法获得的解决方案 - 此外,他们的扩散先验有助于缩小仿真到现实的差距,因为它能够生成更自然(不那么机械化)的运动规划,通常不会包含极端动作
1.1.2 相关工作
DreamControl的工作受三个主要研究方向的启发:
- 机器人操作(包括模仿学习以及基于策略的强化学习)
- 用于足式机器人的强化学习(涵盖运动控制、远程操作到完全自主)
- 以及角色动画和人体运动建模相关文献
首先,对于操作领域的最新进展
- 现代深度学习在机器人操作领域的应用通常基于模仿学习[13]–[15]。作者的工作尤其借鉴了利用扩散模型[16]、[17]或相关流匹配方法[18]进行策略参数化的研究[9]、[10]、[19]–[23]。这些方法试图模仿大型语言模型(LLM)的成功,因为它们在拥有大量数据时具备良好的扩展性
然而,与文本数据不同,机器人数据并非普遍存在于互联网上。收集机器人轨迹的成本很高,不仅需要昂贵的远程操作设备,还需要对人类远程操作员进行培训并支付报酬 - 也有一些在模拟环境中训练的基于策略的强化学习方法,这些方法具有更好的可扩展性 [4],[24],但实现鲁棒的模拟到现实(sim2real)迁移依然具有挑战性
与我们方法最相关的是Lin等人的工作 [4],他们展示了鲁棒的双臂操作技能,应用于类人机器人,但并未涉及全身技能 - 与 [4] 类似,作者采用基于策略的强化学习方法(而非基于遥操作轨迹的行为克隆)——但作者的模型基于对人体运动的扩散先验,有效减少了对奖励工程的需求
其次,对于面向足式机器人的强化学习控制器
近年来,深度强化学习在足式机器人控制器中的应用显著增加,最初主要用于四足机器人稳健的步态策略[25]–[27],随后扩展到双足机器人(包括类人机器人)[28]–[34]
- 最近,研究者提出了全身运动跟踪和远程操作方法,使机器人能够跟踪人类远程操作者的动作[1]、[2]、[35]–[42],并在应对敏捷及极限运动(如KungFuBot[3]和ASAP[43])方面取得了进展。更完整的领域综述可参考[44]
- 最后,除了跟踪给定的人体动作之外,还存在使系统能够完全自主地执行特定任务的挑战,例如踢球、坐下、挥动高尔夫球杆(有时将这些称为“技能”)[5],[43],[45]–[50]
在这些工作中
HumanPlus [48] 和 AMO [5] 展示了全身自主任务执行能力,但需要通过遥操作轨迹进行模仿学习(IL)
且BeyondMimic扩散策略中的引导是“粗粒度”的,而非DreamControl中的细粒度,并且没有考虑到物体交互或远距离规划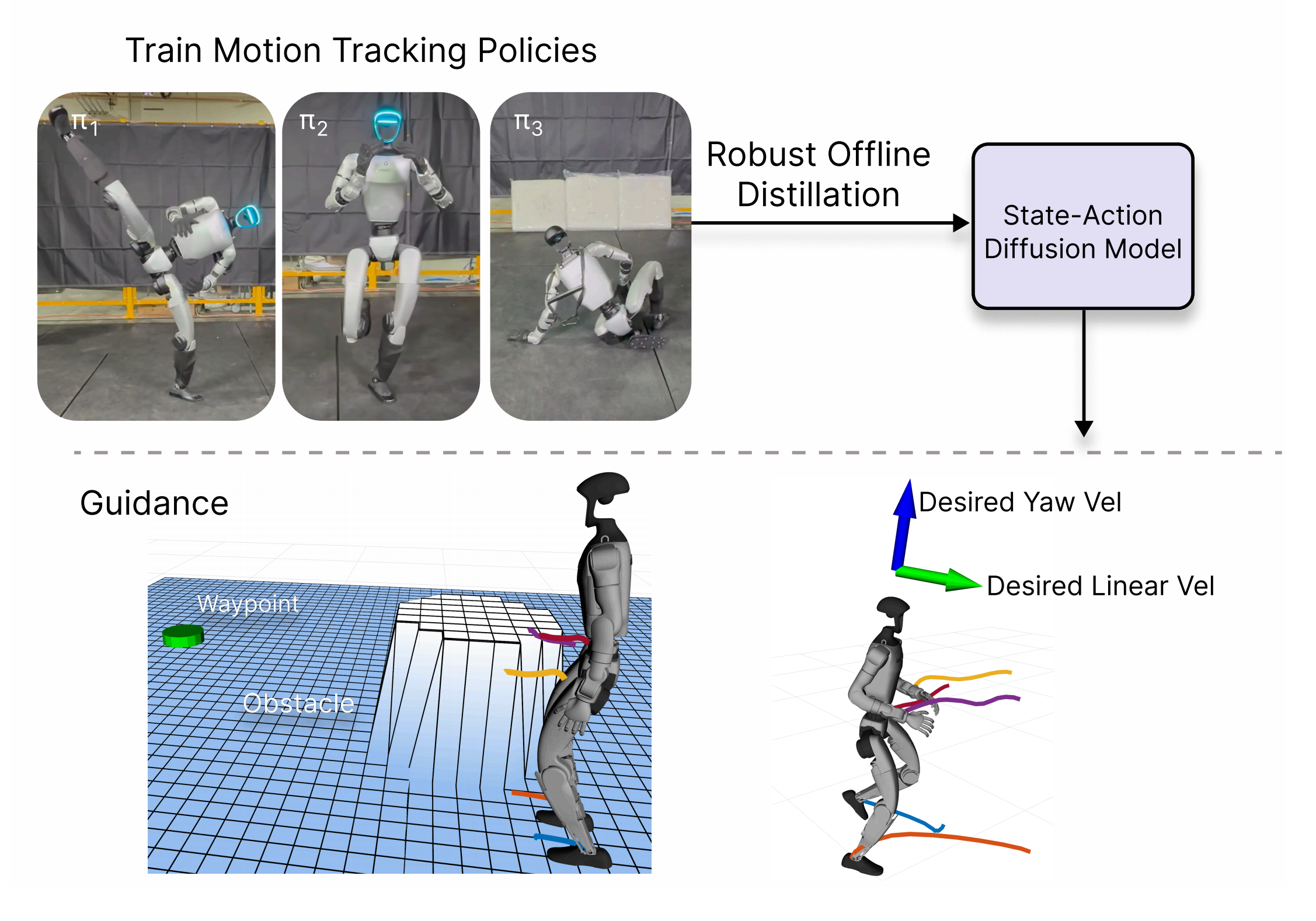
最后,对于角色动画与运动模型
在物理逼真的角色动画环境下,对类人角色运动建模的相关文献也较为丰富 [8],[51]–[58]。通过获取特权模拟状态,并且不存在从仿真到现实的分布转移问题,首先在这种简化的合成环境中解决问题已被证明对于跨越仿真到现实的鸿沟具有重要的铺垫作用
作者声称,他们尤其受到了关于人体运动的统计先验的影响——这一领域有着丰富的研究历史(参见如 [59]–[61]),并且现今已经利用了生成式人工智能的最新进展(如扩散模型和自回归变换器)[6]、[7]、[12]、[62]、[63]
在这些论文中,DreamControl的工作受到 Omnigrasp [8]、CloSd[7] 和 TokensHSI [6] 的影响最大,这些方法都明确处理了物体/场景交互
- Omnigrasp 利用了一种关于人类动作的先验(PULSE,[55]),其形式为瓶颈变分自编码器(VAE),能够直接预测动作,但其缺点是作为人类轨迹先验时,解释起来相对较为困难
- CloSd 通过扩散方法生成运动规划,并采用强化学习训练的策略在仿真中执行
DreamControl的工作在此基础上更进一步,通过利用更丰富/更细粒度的引导,使得能够处理更多样化的任务,并解决重要的仿真到现实(sim2real)问题(例如,消除对运动模型中参考轨迹的明确依赖),从而实现真实机器人上的部署
1.2 DreamControl完整方法论
DreamControl的方法在概念上起始于标准的用于四足机器人和双足/人形机器人的远程操作强化学习(RL)流程
- 通常,这类强化学习策略(如[35],[36])通过密集奖励来训练,以准确跟踪输入轨迹(例如通过对人类的动作捕捉获得)的关键点,并结合其他奖励(如稳定性、平衡性、平滑性等)
- 然而,当训练人形机器人自主执行技能(例如拾取物体)时,测试阶段并没有可用的输入轨迹,因此
在 DreamControl 中,作者采用后一种方法,首先通过预训练的人体动作先验在外部生成运动规划
In DreamControl, we take this latter route of first gener-ating motion plans externally through a pre-trained humanmotion prior.
这些生成的运动规划随后在RL训练过程中以奖励信号的形式被隐式使用,但并未被策略显式用作目标条件(因此将“Dream”融入“DreamControl”中)
These generated motion plans are then use dimplicitly during RL training in the reward signal but not explicitly used as goal conditions by the policy, (henceputting the “Dream” in “DreamControl”).
除了这些密集的跟踪奖励外,作者还使用稀疏且可验证的任务特定奖励,以明确促进任务的完成
整体流程如图 2 所示
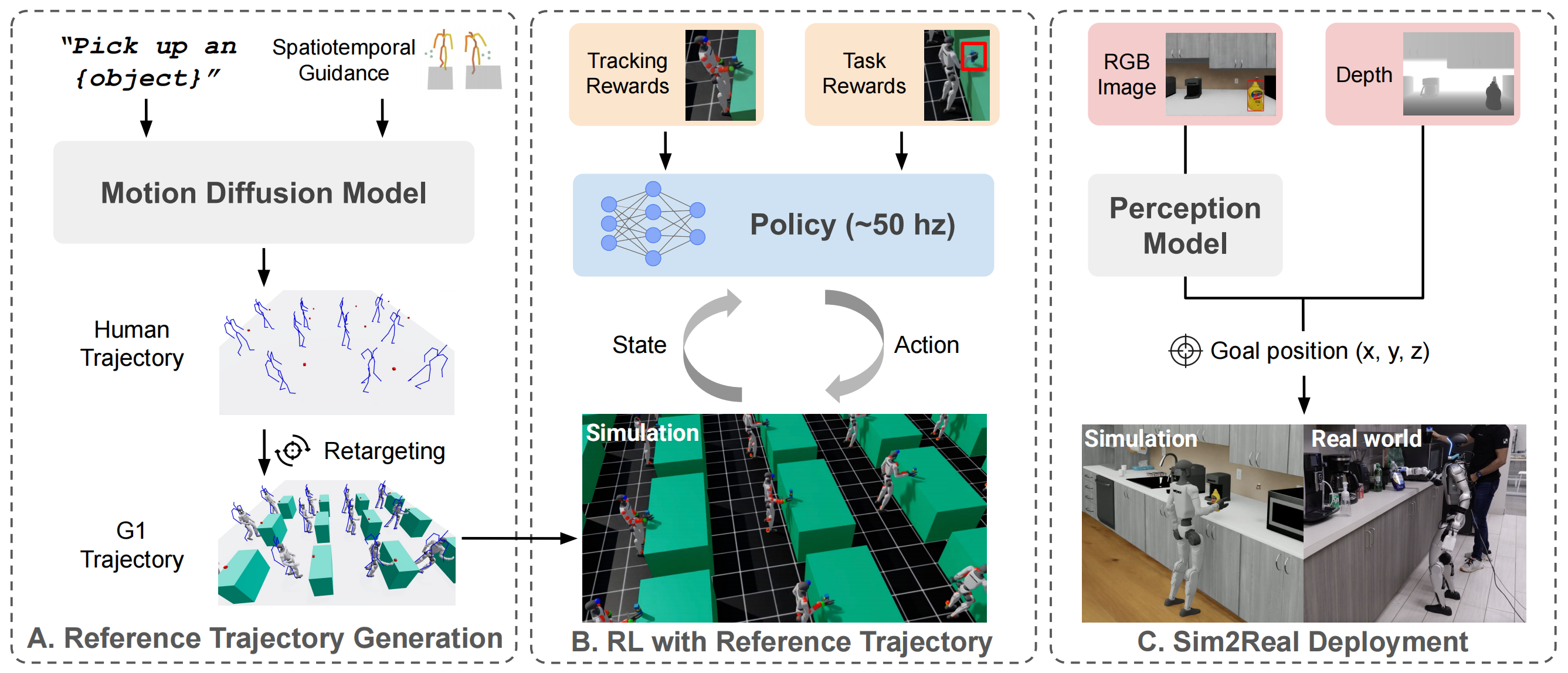
接下来将详细讨论
- 基于人体动作先验的轨迹生成
- 强化学习这两个阶段
1.2.1 阶段一:基于人类动作先验生成参考轨迹
首先,第一阶段的一个关键目标是利用人类动作数据,而不是昂贵的人形机器人远程操作数据
- 人类动作数据广泛可得(无论是以动作捕捉数据集的形式,还是以视频数据集中的隐式形式),因此能够学习到高质量的先验知识,并覆盖多种任务
通过生成逼真的类人动作,作者还期望能够实现更顺畅的仿真到现实迁移,并带来更自然的人机交互 - 此外,作者希望选择一种在数据扩展性方面表现优异的模型
因此,作者采用了扩散transformer(diffusion transformer)[9],[62],[64]
该模型已被证明在建模人体运动以及机器人操作轨迹方面非常成功,并且在大规模数据集下具有良好的扩展性,同时在数据量较少的情况下依然表现稳定 [65]
在以往的运动扩散模型中,作者以OmniControl[12]为基础,该模型能够灵活地基于文本和时空引导进行条件控制
- OmniControl可以根据给定的文本指令(例如,“捡起瓶子”)生成轨迹,同时规定某个关节或一组关节在预定的时间到达指定的空间位置。通过这种方式,作者的轨迹生成阶段类似于图像或视频的修复过程
这种时空引导方式使得能够将生成的轨迹与其环境相连接(例如,允许指定人形机器人应该坐在哪里、应跳多高,或被操控物体的位置)
能够控制这一交互点至关重要,因为在强化学习模拟器中,作者可以在某个位置实例化一个物体,然后使用能够保证接近该物体的轨迹,这极大地促进了强化学习的探索过程 - 在DreamControl中,作者专门为每种情况设计了时空引导的形式任务。例如,作者的抓取任务涉及为手腕提供一个空间目标。关于引导控制实现的更多细节,请参见附录
其次,重定向与轨迹滤波
- 由于Omni-control是在以SMPL参数化[66]表示的人类轨迹上训练的,作者接下来将这些生成的轨迹重定向到G1形态(类似于[67]的方法):通过求解一个优化问题(使用PyRoki[67]库),最小化相对关键点位置、相对角度以及用于调整连杆长度差异的缩放因子
此外,还引入了额外的残差项,如足部接触成本、自碰撞成本和足部朝向成本,以提升物理合理性 - 且在将生成的 G1 轨迹传递给强化学习(RL)之前,作者对其应用了一层后处理。一些生成的轨迹在动力学上不可行,因此不适用于第二阶段的跟踪
作者基于一些启发式方法,设计了任务特定的过滤机制,具体细节在附录中有详细讨论
且还针对不同任务对轨迹进行了优化,以避免不必要的动作,例如在只使用右臂的Pick 任务中,将所有左臂关节设为默认值。这些内容同样在附录中进行了说明
最后,对于轨迹表示
- 在所有后处理和优化完成后,作者得到了一组参考轨迹
,这些轨迹是通过相同的任务特定文本提示生成的,但具有不同的
时空“目标”,即关节
应在时间
处于位置
- 此外,作者还定义了
,表示任务特定目标交互发生的时间
例如,Pick 任务中的
这个
进一步而言,每个参考轨迹被表示为一个目标帧序列,,其中
为时间步长,
为轨迹长度(因此每条轨迹跨度为9.8 s)
每一帧被表示为
其中
为根部的位置
为四元数形式的根部朝向
为参考关节角度
为左右手状态,0 表示张开,1 表示闭合
这些状态针对每个任务进行人工标注;例如,对于右手抓取任务,作者确保右手在时间 后立即闭合,并且左手在任务期间始终保持闭合。更多细节请参见附录
此外,对于分布外任务
- 在本文中,作者以“零样本”的方式使用 OmniControl,即使用作者最初发布的权重和超参数,并在生成轨迹后将其重新定向到 G1
由于 OmniControl 是在 HumanML3d [68] 上训练的,作者发现它能够“开箱即用”地处理各种各样的任务- 然而,作者还探索了一种方法,用于处理某些Omnicontrol未能很好覆盖的新型任务——比如对于训练分布中不常见的任务(例如拉抽屉),作者通过在一个人站立静止(或弯腰拉低于腰部的抽屉)的基础轨迹上,利用基于逆运动学(IK)的优化来实现
更多细节见附录
1.2.2 第二阶段:基于参考轨迹的强化学习(涉及场景合成、动作空间、观测、奖励)
在获得第一阶段生成的参考轨迹后,作者将该交互式任务建模为一个强化学习问题
本节中,作者描述了一种“特权”变体,即能够访问模拟器内部状态的方法。关于如何将该方法应用于实际部署的讨论,将在原论文的第四节展开
第一,对于场景合成
首先,作者需要为每一个第一阶段的运动轨迹合成一个合理的场景,以便执行交互任务——例如,如果在第一阶段使用引导要求手腕在时间时位于点
,那么在RL过程中,就在点
附近放置待操作的物体
更正式地说,给定生成轨迹中交互发生的时间(例如,物体被拾取、按钮被按下等的时间),作者将感兴趣的物体(拾取物体、按钮等)放置在以下位置:
其中
表示机器人身体部件连杆在世界坐标系下的位姿(例如,对于用右手抓取任务来说,是右手腕连杆)
- 而
表示物体相对于机器人身体部件连杆的偏移量,即物体应放置的位置
每个任务中使用的所有具体偏移量和身体部件连杆在附录中列出
- 且作者对时间戳
和物体的其他特性(如质量和摩擦)进行随机化
- 更选择随机化超参数,以展示可以通过精心工程扩展的任务范围内,能够生成和使用参考轨迹来解决的问题。环境的具体随机化超参数在附录中报告
// 待更