Python学习之Day04学习(持久存储与推倒数据)
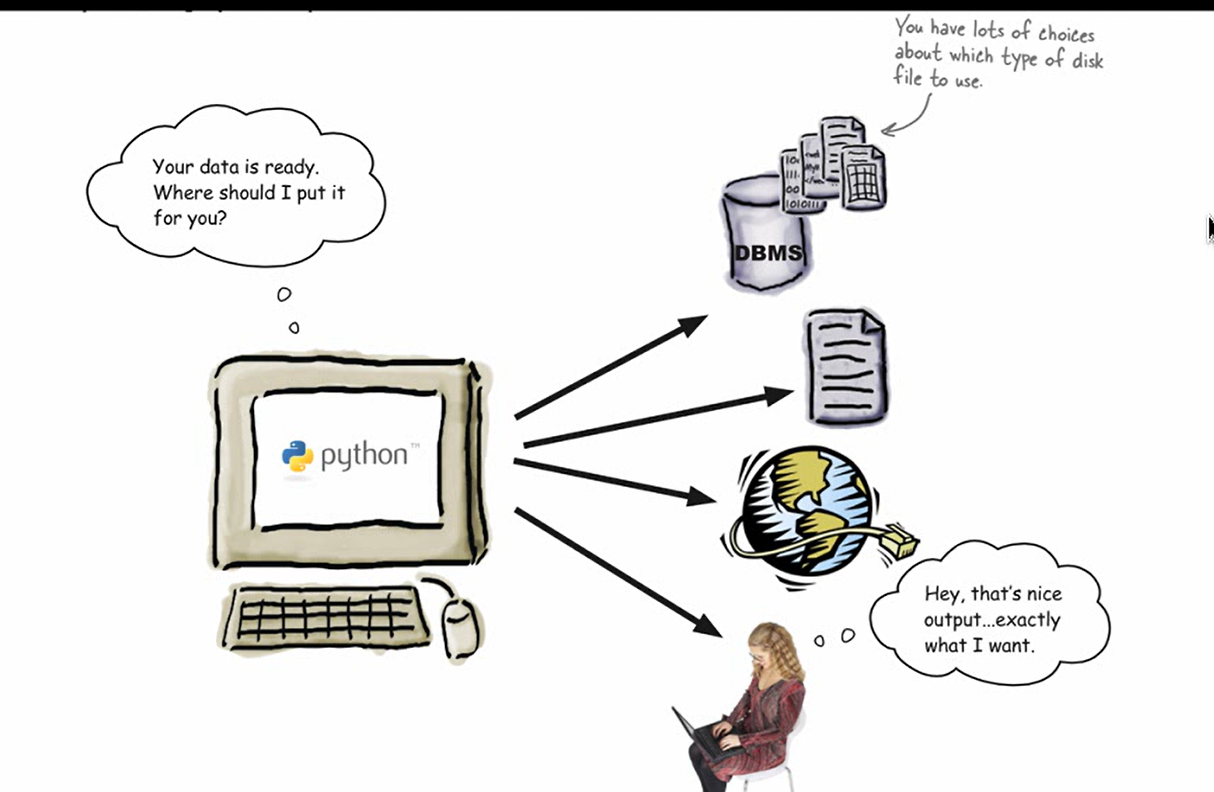
一、持久存储
通常情况我们所输出的数据会打印到控制栏中,有时也会保存到文件中,但我们对于所需要持久保存的数据就需要从磁盘管理方面来入手
有关异常抛出处理存储练习(保存到列表)
针对列表中的脏数据进行处理,然后进行排序
### demo1 将内容分隔后保存到列表中man=[]
other=[]
try:data=open('sketch.txt')for line in data:try:role,spoken=line.split(':')if role == 'Man':man.append(spoken)elif role =='Other Man':other.append(spoken)other.append(spoken)except ValueError:passdata.close()
except IOError:print('The data file is missing')
print(man)
print(other)### demo2 将处理写入后的列表数据,保存到文件中
man=[]
other=[]
try:data=open('sketch.txt')for line in data:try:role,spoken=line.split(':')if role == 'Man':man.append(spoken)elif role =='Other Man':other.append(spoken)other.append(spoken)except ValueError:passdata.close()
except IOError:print('The data file is missing')try:man_file=open('man_data.txt','wt')other_file=open('other_data.txt','wt')# man_file.write(str(man))# other_file.write(str(other_file))print(man,file=man_file)print(other,file=other_file)man_file.close()other_file.close()
except IOError:print('File error')使用finally扩展try:
这里通过finally无论最终数据是否正常写入,都可以正常关闭文件
try:man_file=open('man_data.txt','wt')other_file=open('other_data.txt','wt')# man_file.write(str(man))# other_file.write(str(other_file))print(man,file=man_file)print(other,file=other_file)
except IOError:print('File error')
finally:man_file.close()other_file.close()查看出现报错异常不终止程序
## method1 异常处理
try:data=open('missing.txt')print(data.readline())
except IOError as err:print('File error'+str(err)) ###File error[Errno 2] No such file or directory: 'missing.txt'
finally:if 'data' in locals():data.close()### method2 异常合并
try:with open('man_data.txt','w') as man_file,open('other_data.txt','w') as other_man_file:print(man,file=man_file)print(other,file=other_man_file)
except IOError:print('File error')接下来优化我们之前print_lol函数(当选择打印即进行打印,而选择保存到文件中自行保存到文件中)
### nester部分的函数模块
import sys
def print_lol(the_list,level,fn=sys.stdout):for each_item in the_list:if isinstance(each_item, list):print_lol(each_item, level,fn)else:for tab_shop in range(level):print("\t", end="",file=fn)print(each_item)### 异常抛出函数对接print_lol作为APItry:with open('man_data.txt','w') as man_file,open('other_data.txt','w') as other_man_file:print_lol(man,file=man_file)print_lol(other,file=other_man_file)
except IOError:print('File error')修改setup.py文件
## 初始化py环境
python setup.py sdist
python .\setup.py install
python .\nester.py ### 处理setup.py
from distutils.core import setupsetup(name='nester',version='1.1.0',py_modules=['nester'],author='jfedu',author_email='ce@jfedu.net',url='http://www.jfedu',description='A simple printer of nested lists'
)### 使用print_lol函数表示这部分内容
try:with open('man_data.txt','w') as man_file,open('other_data.txt','w') as other_man_file:nester.print_lol(man,0)nester.print_lol(other,0)nester.print_lol(man,0,man_file)nester.print_lol(other, 0,other_man_file)
except IOError:print('File error')
完成print_lol升级之后参数效果如下
Pickle使用和用法
数据源保存到磁盘中

数据源从磁盘中导出至数据源

pickle通常使用dump保存,使用load进行恢复
import pickle
man=[]
other=[]
try:data=open('sketch.txt')for line in data:try:role,spoken=line.split(':')if role == 'Man':man.append(spoken)elif role =='Other Man':other.append(spoken)other.append(spoken)except ValueError:passdata.close()
except IOError:print('The data file is missing')### 将文件进行备份
try:with open('man_data.txt','wb') as man_file,open('other_data.txt','wb') as other_man_file:pickle.dump(man,man_file) ### 使用pickle处理导入pickle.dump(other,other_man_file) ### 使用pickle处理导入
except IOError:print('File error')
except pickle.PickleError as perr:print('pickle error'+str(perr))### 将文件进行恢复
try:with open('man_data.txt','rb') as man_file,open('other_data.txt','rb') as other_man_file:new_man=pickle.load(man_file) ### 使用pickle处理导入new_other_man=pickle.load(other_man_file) ### 使用pickle处理导入
except IOError:print('File error')
except pickle.PickleError as perr:print('pickle error'+str(perr))
print(new_man[0])
print(new_other_man[0])二、推导数据
数据清洗
对数据进行预处理---->数据清洗--->目标数据
# coding=utf-8### 有关清理数据的函数(数据清洗)
def santize(time_string):if '-' in time_string:spliter='-'elif ':' in time_string:spliter=':'else:return time_stringminutes,seconds=time_string.split(spliter)return(minutes+'.'+seconds)#### 数据预处理 ####
with open('james.txt') as jaf:data = jaf.readline()
james=data.strip().split(',') ### 方法串链with open('julie.txt') as juf:data = juf.readline()
julie=data.strip().split(',')with open('mikey.txt') as mif:data = mif.readline()
mikey=data.strip().split(',')with open('sarah.txt') as saf:data = saf.readline()
sarah=data.strip().split(',')"""
['2-34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
['2:22', '3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38']
['2:58', '2.58', '2:39', '2-25', '2-55', '2:54', '2.18', '2:55', '2:55']
"""# print(james)
# print(julie)
# print(mikey)
# print(sarah)## 排序方式(原地,降序)
# data =[6,3,4,1,1,5]
# print(data)
# data2=sorted(data)
# print(data2)
# print(sorted(james))
# print(sorted(julie))
# print(sorted(mikey))
# print(sorted(sarah))"""
['2-34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
['2:22', '3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38']
['2:58', '2.58', '2:39', '2-25', '2-55', '2:54', '2.18', '2:55', '2:55']
['2-22', '2-34', '2.34', '2.45', '2:01', '2:01', '3.01', '3:10', '3:21']
['2-23', '2.11', '2.59', '2:11', '2:23', '3-10', '3-21', '3.21', '3:10']
['2.49', '2:22', '2:38', '3.01', '3.02', '3.02', '3:01', '3:02', '3:22']
['2-25', '2-55', '2.18', '2.58', '2:39', '2:54', '2:55', '2:55', '2:58']"""clean_james=[]
clean_julies=[]
clean_mikey=[]
clean_sarch=[]#### 迭代数据的处理
for each_t in james:clean_james.append(santize(each_t))for each_t in julie:clean_julies.append(santize(each_t))for each_t in mikey:clean_mikey.append(santize(each_t))for each_t in sarah:clean_sarch.append(santize(each_t))#
# print(sorted(clean_james))
# print(sorted(clean_julies))
# print(sorted(clean_mikey))
# print(sorted(clean_sarch))## 优化添加后的数据print(sorted(santize(t) for t in clean_james))
print(sorted(santize(t) for t in clean_julies))
print(sorted(santize(t) for t in clean_mikey))
print(sorted(santize(t) for t in clean_sarch))"""
['2.01', '2.01', '2.22', '2.34', '2.34', '2.45', '3.01', '3.10', '3.21']
['2.11', '2.11', '2.23', '2.23', '2.59', '3.10', '3.10', '3.21', '3.21']
['2.22', '2.38', '2.49', '3.01', '3.01', '3.02', '3.02', '3.02', '3.22']
['2.18', '2.25', '2.39', '2.54', '2.55', '2.55', '2.55', '2.58', '2.58']
"""数据预处理的代码可以进行如下优化
def get_coach_data(filename):try:with open(filename) as f:data = f.readline()return data.strip().split(',')except IOError as error:print('File error:'+str(error))return (None)
james=get_coach_data('james.txt')
sarah=get_coach_data('sarah.txt')
julie=get_coach_data('julie.txt')
mikey=get_coach_data('mikey.txt')列表切片
迭代删除重复项

james=sorted(sorted([santize(t) for t in clean_james])) ### reverse=true,逆序排序
uniq_james=[]
for each_t in james:if each_t not in uniq_james:uniq_james.append(each_t)
print(uniq_james)用集合删除重复项
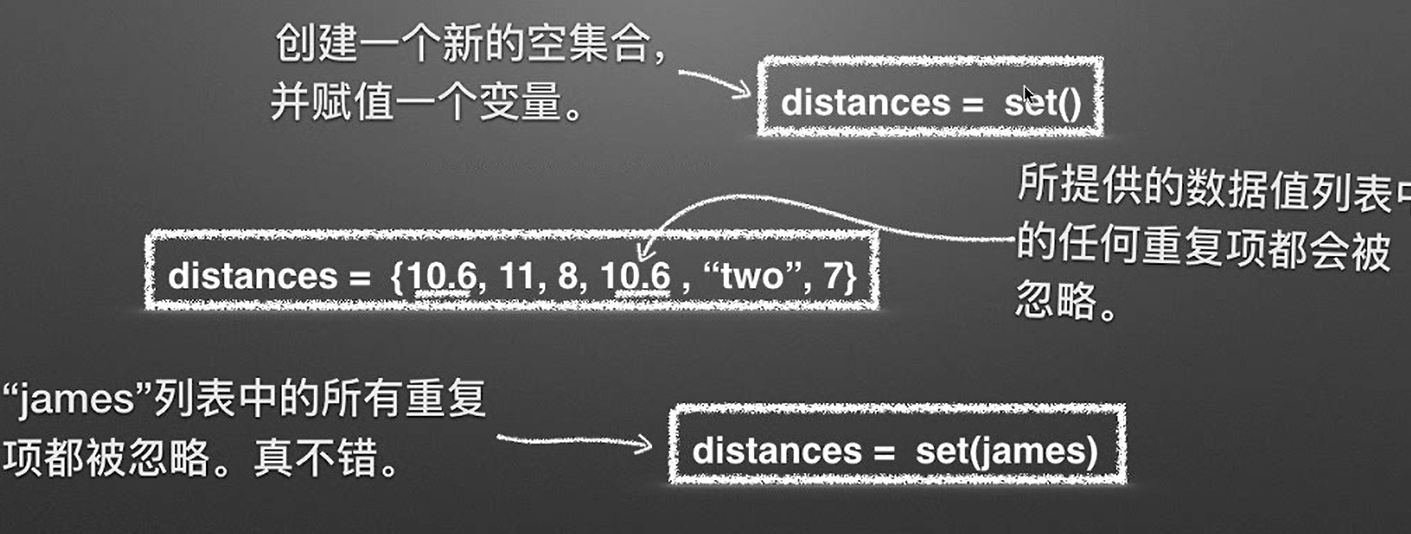
print(sorted(set([santize(t) for t in clean_james]))[0:3])
print(sorted(set([santize(t) for t in clean_julies]))[0:3])
print(sorted(set([santize(t) for t in clean_mikey)])[0:3])
print(sorted(set([santize(t) for t in clean_sarch]))[0:3])三、作业

### 参考1while count<3:user_passowrd=input('请输入密码:')if user_passowrd!=password:count+=1print('密码错误!请重试3次')continueprint('密码正确')break
else:print('重试了3次,退出')### 参考2
i=0
try:with open('secret','rt') as contain:while True:contain.seek(0)sec=input('please input secret:')line=contain.readline()if i==3:print('you input agin greater than 3 lines')breakelse:if line==sec:print('right login to succcess!!!!')breakelse:print('please agin you have {} chance'.format(3-i))i+=1
except IOError as error:print('error'+error)### 参考3
count=0
def get_password(filename):try:with open('password.txt') as f:return f.readline().strip()except Exception as e:raise ewhile count<3:user_passowrd=input('请输入密码:')passwd=get_password('password.txt')if user_passowrd!=passwd:count+=1print('密码错误!请重试3次')continueprint('密码正确')break
else:print('重试了3次,退出')