大模型原理与实践:第三章-预训练语言模型详解_第1部分-Encoder-only(BERT、RoBERTa、ALBERT)
预训练语言模型详解
总目录
-
第一章 NLP基础概念完整指南
- 第1部分-概念和发展历史
- 第2部分-各种任务(实体识别、关系抽取、文本摘要、机器翻译、自动问答)
- 第3部分-文本表示(词向量、语言模型、ELMo)
-
第二章 Transformer 架构原理
- 第1部分-注意力机制
- 第2部分Encoder-Decoder架构
- 第3部分-完整Transformer模型)
-
第三章 预训练语言模型
- 第1部分-Encoder-only(BERT、RoBERTa、ALBERT)
- 第2部分-Encoder-Decoder-T5
- 第3部分-Decoder-Only(GPT、LLama、GLM)
-
第四章 大语言模型
- 第1部分-待写
-
第五章 动手搭建大模型
- 第1部分-待写
-
第六章 大模型训练实践
- 第1部分-待写
-
第七章 大模型应用
- 第1部分-待写
目录
-
引言
-
Encoder-only 预训练语言模型
- 2.1 BERT模型
- 2.1.1 思想沿承
- 2.1.2 模型架构——Encoder Only
- 2.1.3 预训练任务——MLM + NSP
- 2.1.4 下游任务微调
- 2.2 RoBERTa模型
- 2.2.1 优化一:去掉NSP预训练任务
- 2.2.2 优化二:更大规模的预训练数据和预训练步长
- 2.2.3 优化三:更大的BPE词表
- 2.3 ALBERT模型
- 2.3.1 优化一:Embedding参数分解
- 2.3.2 优化二:跨层参数共享
- 2.3.3 优化三:SOP预训练任务
- 2.1 BERT模型
引言
在前一章中,我们详细探讨了为自然语言处理(NLP)领域带来革命性变化的注意力机制,以及基于此机制构建的Transformer模型。Transformer的出现标志着NLP模型发展的一个重要里程碑。正如我们所学,Transformer主要由Encoder(编码器)和Decoder(解码器)两部分构成,这两个组件各有独特的结构和输入输出特性。
针对Encoder和Decoder的不同特点,结合ELMo提出的预训练思路,研究者们开始探索对Transformer进行优化的多种方向。例如:
- Google选择仅使用Encoder层,通过堆叠多层Encoder并提出掩码语言模型(Masked Language Model, MLM)预训练任务,打造了在自然语言理解(Natural Language Understanding, NLU)任务上表现卓越的BERT模型
- OpenAI则选择了Decoder层,采用传统的语言模型(Language Model, LM)任务,通过不断扩大模型参数和预训练语料规模,开发了在自然语言生成(Natural Language Generation, NLG)任务上优势明显的GPT系列模型,这也成为了当今大型语言模型(LLM)的基础架构
- 此外,还有同时保留Encoder和Decoder的方案,如Google发布的T5模型,构建了完整的预训练Transformer架构
本章将按照Encoder-Only、Encoder-Decoder、Decoder-Only的顺序,系统介绍Transformer时代的各个主流预训练模型。我们将深入剖析三种核心模型架构、每种架构选择的预训练任务及其独特优势,这些内容也构成了目前所有主流LLM的理论基础。
Encoder-only 预训练语言模型
BERT模型
BERT(Bidirectional Encoder Representations from Transformers,基于Transformer的双向编码器表示)是Google团队于2018年发布的里程碑式预训练语言模型。该模型在论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中首次提出,在包括GLUE、MultiNLI等七个自然语言处理评测任务上实现了当时的最优性能(State Of The Art, SOTA)。
自BERT推出以来,"预训练+微调"的范式成为NLP任务的主流方法。BERT不仅自身在不断迭代优化,还催生了MacBERT、BART等一系列基于BERT改进的模型。可以说,BERT是NLP发展的阶段性成果,标志着预训练模型统治地位的确立。直到大型语言模型(LLM)时代的到来,NLP领域的主导地位才从BERT系模型逐渐转移。即使在LLM时代,要深入理解LLM与NLP,BERT仍然是不可绕过的重要一环。
思想沿承
BERT统一了多种核心思想,主要包括:
- Transformer架构:如第二章所述,2017年发表的《Attention is All You Need》论文提出了完全基于注意力机制、摒弃RNN和LSTM结构的Transformer模型,带来了全新的模型架构。BERT沿承了Transformer的思想,在其基础上进行优化,通过堆叠Encoder结构并扩大模型参数,打造了在NLU任务上表现卓越的模型架构。
- 预训练+微调范式:同样在2018年,ELMo模型的诞生标志着预训练+微调范式的确立。ELMo基于双向LSTM架构,在大规模训练数据上使用语言模型进行预训练,再针对下游任务进行微调,展现出更优越的性能。BERT采用了该范式,并通过调整为Transformer架构、引入更适合文本理解的MLM预训练任务,将预训练-微调范式推向高潮。
模型架构—Encoder Only
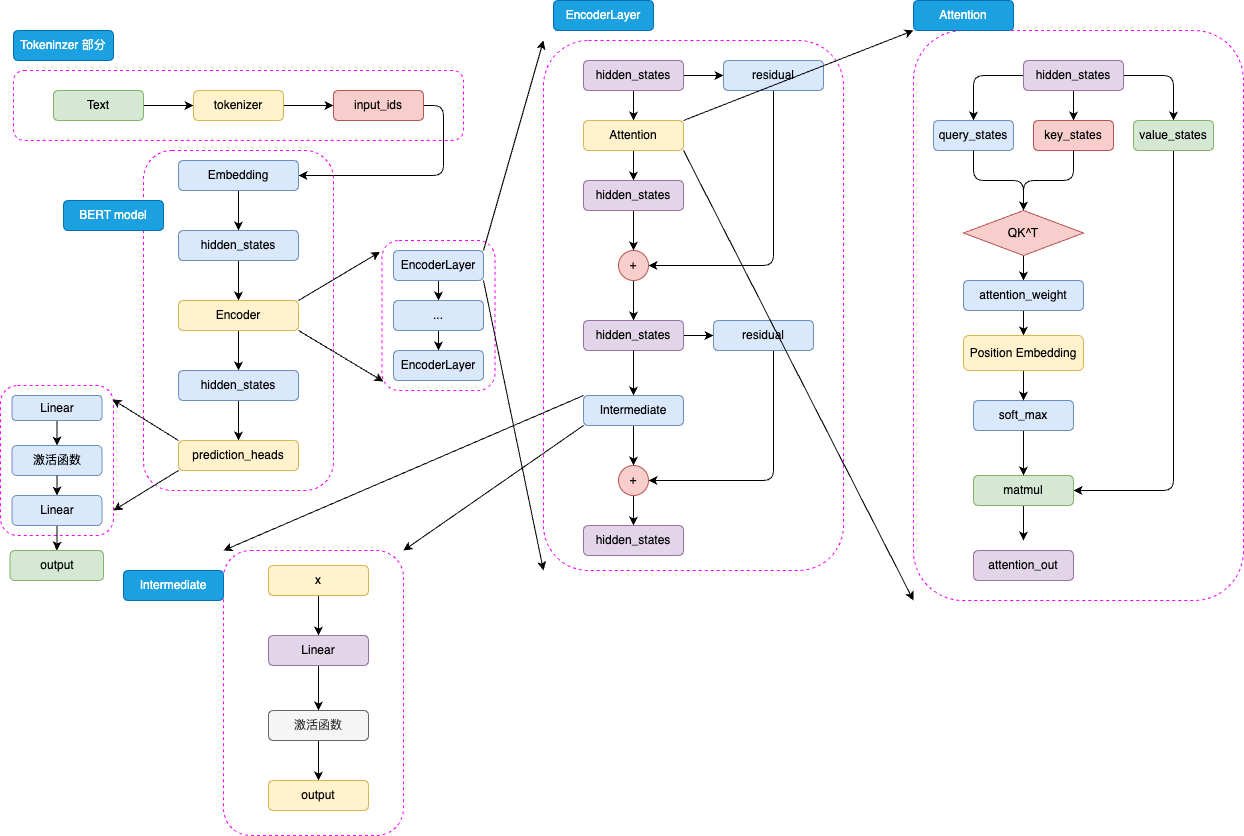
BERT的模型架构由Transformer的Encoder部分堆叠而成。其主要结构包括三个核心组件:
整体架构:
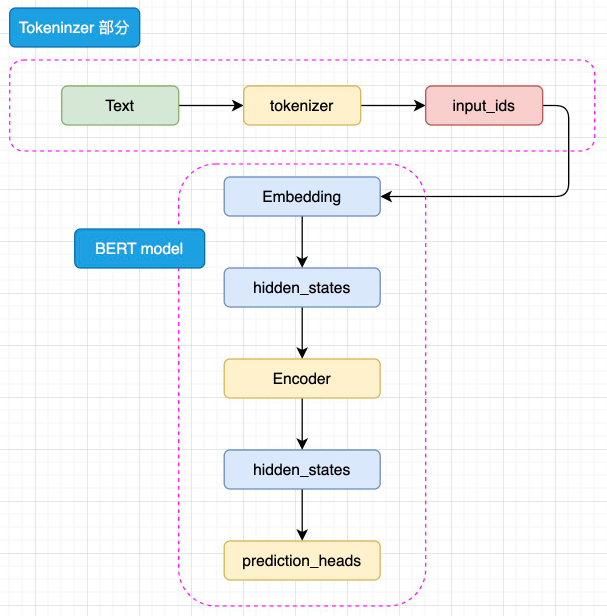
- Embedding层:将输入的token转换为高维向量表示
- Encoder块:由N层Encoder Layer堆叠而成
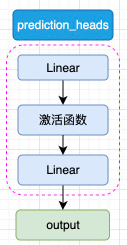
- Prediction Heads:分类头,用于将隐藏状态映射到任务的输出空间
BERT有两个标准版本:
- BERT-base:12层Encoder Layer,768维隐藏层,总参数量110M
- BERT-large:24层Encoder Layer,1024维隐藏层,总参数量340M
处理流程:
# 伪代码示例:BERT的前向传播过程
def bert_forward(text):# 1. 分词和编码input_ids = tokenizer(text) # 将文本转换为token IDs# 2. Embedding层token_embeddings = embedding_layer(input_ids) # token嵌入position_embeddings = position_embedding_layer(input_ids) # 位置编码hidden_states = token_embeddings + position_embeddings# 3. 通过N层Encoder Layerfor encoder_layer in encoder_layers:hidden_states = encoder_layer(hidden_states)# 4. Prediction headslogits = prediction_heads(hidden_states) # 输出分类概率return logits
Encoder Layer结构:
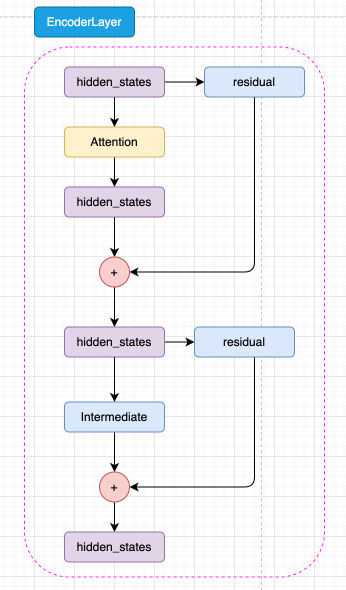
每一层Encoder Layer包含以下组件:
class EncoderLayer:def forward(self, hidden_states):# 1. 多头自注意力机制attention_output = multi_head_attention(query=hidden_states,key=hidden_states,value=hidden_states)# 2. 残差连接和LayerNormhidden_states = layer_norm(hidden_states + attention_output)# 3. 前馈神经网络 (Intermediate层)intermediate_output = feed_forward(hidden_states)# 4. 再次残差连接和LayerNormhidden_states = layer_norm(hidden_states + intermediate_output)return hidden_states
关键技术细节:
- 分词方法:BERT采用WordPiece作为分词方法,这是一种基于统计的子词切分算法。其核心思想是将单词拆解为子词单元,例如"playing"可能被切分为[“play”, “##ing”]。
- 激活函数:BERT使用GELU(Gaussian Error Linear Unit,高斯误差线性单元)激活函数;
GELU的核心思路是将随机正则的思想引入激活函数,通过输入自身的概率分布来决定是否保留该神经元。
- 位置编码:改进版BERT将相对位置编码融合在注意力机制中,将位置编码视为可训练的权重参数。这种方法能够拟合更丰富的相对位置信息,但也增加了模型参数,且无法处理超过训练长度的输入(BERT的最大上下文长度为512个token)。
预训练任务—MLM + NSP
BERT的重大创新在于提出了两个新的预训练任务:
1. 掩码语言模型(Masked Language Model, MLM)
MLM模拟"完形填空"的过程,在文本序列中随机遮蔽部分token,然后要求模型根据未被遮蔽的token预测被遮蔽的token。
示例:
输入:I <MASK> you because you are <MASK>
输出:<MASK> → love; <MASK> → wonderful
MLM的改进策略:
为解决预训练和微调不一致的问题,BERT采用了以下策略:
- 随机选择15%的token进行处理
- 其中80%被替换为
- 10%被替换为随机token
- 10%保持不变
def mask_tokens(tokens, mask_prob=0.15):"""对输入tokens进行掩码处理"""masked_tokens = tokens.copy()labels = tokens.copy()for i in range(len(tokens)):if random.random() < mask_prob:prob = random.random()if prob < 0.8:# 80%的概率替换为[MASK]masked_tokens[i] = '[MASK]'elif prob < 0.9:# 10%的概率替换为随机tokenmasked_tokens[i] = random.choice(vocab)# 10%的概率保持不变else:# 未被选中的token,标签设为-100(不计算损失)labels[i] = -100return masked_tokens, labels
2. 下一句预测(Next Sentence Prediction, NSP)
NSP任务用于训练模型理解句子间的关系,判断两个句子是否为连续的上下文。
示例:
正样本:
Sentence A: I love you.
Sentence B: Because you are wonderful.
标签: 1(连续上下文)负样本:
Sentence A: I love you.
Sentence B: Because today's dinner is so nice.
标签: 0(非连续上下文)
预训练规模:
BERT的预训练使用了:
- 800M的BooksCorpus语料
- 2500M的英文维基百科语料
- 总计约3.3B token
- 90%的数据使用128的上下文长度训练
- 10%的数据使用512的上下文长度训练
- Batch size为256,训练1M步(40个Epoch)
- BERT-base使用16块TPU训练4天
- BERT-large使用64块TPU训练4天
下游任务微调
BERT确立了预训练-微调的两阶段思想,即在海量无监督语料上预训练获得通用的文本理解能力,再在特定下游任务上进行微调。
关键设计:
-
特殊token [CLS]:在每个输入序列首部添加[CLS] token,其对应的特征向量代表整个句子的语义表征
-
微调策略:
- 文本分类任务:直接修改prediction_heads的分类头
- 序列标注任务:集成多层隐含层向量后输出标注结果
- 文本生成任务:取Encoder输出直接解码
# 微调示例:文本分类任务
class BERTForClassification:def __init__(self, bert_model, num_classes):self.bert = bert_modelself.classifier = nn.Linear(bert_model.hidden_size, num_classes)def forward(self, input_ids, attention_mask):# 获取BERT的输出outputs = self.bert(input_ids, attention_mask=attention_mask)# 取[CLS] token的隐藏状态cls_hidden_state = outputs[0][:, 0, :]# 通过分类器得到logitslogits = self.classifier(cls_hidden_state)return logits
BERT一经提出,直接在11个NLP任务上取得SOTA效果,成为NLU方向当之无愧的霸主。直到LLM时代,BERT仍在许多标注数据丰富的NLU任务上保持最优效果。
RoBERTa模型
RoBERTa(Robustly Optimized BERT Approach)是Facebook于2023年7月发布的BERT优化版本。RoBERTa的核心思想是:BERT使用的13GB预训练数据是否已经让模型充分拟合?如果使用更多预训练语料、优化预训练任务和训练超参数,是否可以进一步提升模型性能?
优化一:去掉NSP预训练任务
有学者质疑NSP任务过于简单,无法显著提升下游任务性能,甚至可能带来负面效果。RoBERTa设置了四组对比实验:
- 段落构建的MLM + NSP:BERT原始设置,输入为一对片段
- 文档对构建的MLM + NSP:输入为一对句子,通过增大batch保持token数量相同
- 跨越文档的MLM:去掉NSP,输入为从一个或多个文档中连续采样的完整句子
- 单文档的MLM:去掉NSP,限制输入只能从一个文档中采样
实验结果表明,后两组显著优于前两组,且单文档的MLM在下游任务微调时性能最佳。因此,RoBERTa在预训练中去掉了NSP,只使用MLM任务。
动态遮蔽策略:
RoBERTa将Mask操作从数据处理阶段移至训练阶段,实现动态遮蔽,使每个Epoch的训练数据Mask位置都不同。
class DynamicMaskingDataset:"""动态遮蔽数据集"""def __getitem__(self, index):text = self.texts[index]tokens = self.tokenizer(text)# 每次获取样本时动态进行掩码masked_tokens, labels = self.mask_tokens(tokens)return {'input_ids': masked_tokens,'labels': labels}
优化二:更大规模的预训练数据和预训练步长
RoBERTa使用了更大规模的预训练数据:
- BookCorpus(BERT使用)
- 英文维基百科(BERT使用)
- CC-NEWS(CommonCrawl新闻领域英文部分)
- OPENWEBTEXT(英文网页)
- STORIES(CommonCrawl故事风格子集)
- 总计160GB数据,是BERT的10倍
训练策略优化:
- 更大的Batch Size:从256增加到8K,既提高优化速度,也提升最终性能
- 更长的训练步长:训练500K步(约66个Epoch)
- 固定序列长度:全部使用512长度训练,不再采用BERT的渐进式策略
# 训练配置对比
bert_config = {'batch_size': 256,'max_length': [128, 512], # 先用128训练,再用512'training_steps': 1000000,'total_tokens': '3.3B'
}roberta_config = {'batch_size': 8192,'max_length': 512, # 全程使用512'training_steps': 500000,'total_tokens': '160GB (约50B+)'
}
计算资源:训练一个RoBERTa,Meta使用了1024块V100(32GB显存)训练1天。
优化三:更大的BPE词表
RoBERTa采用BPE(Byte Pair Encoding,字节对编码)作为Tokenizer的编码策略,并将词表大小从BERT的30K扩大到50K。
BPE编码原理:
BPE以子词对作为分词单位。例如:
- “Hello World” → [“Hel”, “lo”, “Wor”, “ld”]
- 对于中文"我"(UTF-8编码为"E68891")→ [“E68”, “891”]
class BPETokenizer:"""BPE分词器示例"""def __init__(self, vocab_size=50000):self.vocab_size = vocab_sizeself.vocab = {}def train(self, corpus):"""训练BPE词表"""# 1. 初始化:每个字符作为一个tokenvocab = self.get_initial_vocab(corpus)# 2. 迭代合并最频繁的字符对while len(vocab) < self.vocab_size:# 找到最频繁的字符对most_frequent_pair = self.find_most_frequent_pair(corpus, vocab)# 合并该字符对vocab[most_frequent_pair] = len(vocab)# 更新语料corpus = self.merge_pair(corpus, most_frequent_pair)self.vocab = vocab
通过上述三方面优化,RoBERTa成功刷新了多个下游任务的SOTA,证明了更大规模预训练的重要意义,这也为LLM的诞生奠定了基础。
ALBERT模型
ALBERT(A Lite BERT)由Google于2020年提出,从降低模型参数、保持模型能力的角度对BERT进行优化。通过优化模型结构和改进NSP任务,ALBERT以更小的参数量实现了超越BERT的性能。
优化一:Embedding参数分解
BERT的Embedding层参数矩阵维度为V×HV \times H V×H(词表大小 × 隐藏层维度)。对于BERT-large,这相当于30K × 1024 = 30M参数。当隐藏层维度增加到2048时,Embedding参数会膨胀到61M。
ALBERT的解决方案:
将Embedding层的输出维度与隐藏层维度解耦,在Embedding层后添加一个线性变换矩阵。
参数量对比:
- BERT: V×HV \times HV×H
- ALBERT: V×E+E×HV \times E + E \times HV×E+E×H(当 E≪HE \ll HE≪H 时,参数量显著减少)
其中:
- VVV 表示词汇表大小(Vocabulary size)
- HHH 表示隐藏层维度(Hidden size)
- EEE 表示Embedding维度(Embedding size)
class FactorizedEmbedding:"""分解的Embedding层"""def __init__(self, vocab_size, embedding_size, hidden_size):# 第一步:从vocab_size映射到较小的embedding_sizeself.word_embeddings = nn.Embedding(vocab_size, embedding_size)# 第二步:从embedding_size映射到hidden_sizeself.projection = nn.Linear(embedding_size, hidden_size)def forward(self, input_ids):# 词嵌入embeddings = self.word_embeddings(input_ids) # [batch, seq_len, embedding_size]# 投影到隐藏层维度hidden_states = self.projection(embeddings) # [batch, seq_len, hidden_size]return hidden_states# 参数量计算示例
vocab_size = 30000
hidden_size = 1024
embedding_size = 128# BERT的Embedding参数量
bert_params = vocab_size * hidden_size # 30,720,000# ALBERT的Embedding参数量
albert_params = vocab_size * embedding_size + embedding_size * hidden_size
# 3,840,000 + 131,072 = 3,971,072print(f"参数减少: {(1 - albert_params/bert_params)*100:.1f}%") # 减少约87%
优化二:跨层参数共享
ALBERT发现各Encoder层的参数呈现高度一致性,因此提出让所有Encoder层共享参数。
实现方式:
class ALBERTEncoder:"""ALBERT的Encoder:所有层共享参数"""def __init__(self, hidden_size, num_layers=24):# 只初始化一个EncoderLayerself.shared_layer = EncoderLayer(hidden_size)self.num_layers = num_layersdef forward(self, hidden_states):# 虽然只有一层参数,但仍进行num_layers次计算for _ in range(self.num_layers):hidden_states = self.shared_layer(hidden_states)return hidden_states
效果对比:
模型层数隐藏层维度参数量
BERT-large241024334M
ALBERT-xlarge24204859M
ALBERT-xlarge虽然参数量仅为BERT-large的18%,但效果更优。
局限性:虽然参数量大幅减少,但训练和推理速度并未显著提升,因为仍需进行24次Encoder Layer计算。这也是ALBERT最终未能完全取代BERT的重要原因。
优化三:SOP预训练任务
ALBERT提出了句子顺序预测(Sentence Order Prediction, SOP)任务来替代NSP。
NSP vs SOP:
NSP任务:
正样本: [Sent A: "I love you."] [Sent B: "Because you are wonderful."]
负样本: [Sent A: "I love you."] [Sent B: "Today's dinner is nice."]
问题: 负样本来自不同文档,过于简单SOP任务:
正样本: [Sent A: "I love you."] [Sent B: "Because you are wonderful."]
负样本: [Sent A: "Because you are wonderful."] [Sent B: "I love you."]
优势: 模型需要理解句子间的顺序关系,难度更高
def create_sop_training_sample(sentence_a, sentence_b):"""创建SOP训练样本"""if random.random() < 0.5:# 50%概率:正样本(保持原顺序)return {'sentence_a': sentence_a,'sentence_b': sentence_b,'label': 1}else:# 50%概率:负样本(交换顺序)return {'sentence_a': sentence_b,'sentence_b': sentence_a,'label': 0}
实验证明:MLM + SOP > 仅MLM > MLM + NSP,SOP确实能显著提升模型效果。
通过上述三点优化,ALBERT成功以更小的参数实现了更强的性能,其"更宽模型"的思路为后续研究提供了重要参考价值。