反爬虫机制深度解析:从基础防御到高级对抗的完整技术实战

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
作为一名长期奋战在网络安全一线的技术专家,我见证了爬虫与反爬虫技术之间永不停息的"猫鼠游戏"。在这个数据为王的时代,网站数据的安全防护已成为企业生存发展的生命线。从早期的简单IP限制到如今基于深度学习的智能识别,反爬虫技术已经发展成为一个复杂而精密的系统工程。本文将带领大家深入探索反爬虫技术的完整技术栈,从最基础的请求频率控制到基于行为分析的智能识别系统,通过详实的代码示例和架构设计,构建一个全方位的防护体系。我们将一起剖析各种反爬虫策略的技术原理,探讨如何在保护数据安全的同时确保正常用户的访问体验,并展望未来反爬虫技术的发展趋势。这不仅仅是一次技术分享,更是一场关于数据安全与开放平衡的深度思考。
1. 反爬虫技术概述
1.1 爬虫与反爬虫的博弈演进
在互联网发展的早期阶段,爬虫技术主要用于搜索引擎的数据抓取,而反爬虫措施相对简单。随着大数据时代的到来,爬虫技术被广泛应用于商业数据采集、价格监控、舆情分析等领域,这促使反爬虫技术不断升级演进。
爬虫技术的发展阶段:
- 第一代:基于HTTP请求的简单爬虫
- 第二代:模拟浏览器行为的动态爬虫
- 第三代:分布式智能爬虫系统
- 第四代:基于AI的语义理解爬虫
反爬虫技术的对应演进:
- 基础防御:IP限制、User-Agent检测
- 中级防御:验证码、请求频率控制
- 高级防御:行为分析、指纹识别
- 智能防御:机器学习、深度学习识别
1.2 反爬虫技术分类体系
class AntiCrawlerTaxonomy:"""反爬虫技术分类体系"""def __init__(self):self.defense_levels = {"基础层": ["IP限制", "User-Agent检测", "Referer验证"],"应用层": ["验证码", "频率限制", "请求参数验证"],"行为层": ["鼠标轨迹分析", "点击模式识别", "浏览行为监控"],"智能层": ["机器学习模型", "深度学习识别", "异常检测算法"]}def get_defense_strategy(self, threat_level):"""根据威胁等级推荐防御策略"""strategies = {"低": ["基础层防御"],"中": ["基础层+应用层防御"],"高": ["基础层+应用层+行为层防御"],"极高": ["全栈智能防御体系"]}return strategies.get(threat_level, ["基础层防御"])
关键代码解析:
defense_levels定义了四个层次的防御体系get_defense_strategy方法根据威胁等级推荐相应的防御组合- 这种分层设计确保了防御策略的可扩展性和针对性
2. 基础防御机制
2.1 IP地址限制与频率控制
IP地址限制是最基础也是最有效的反爬虫手段之一。通过监控单个IP的请求频率,可以有效识别和阻止恶意爬虫。
import time
from collections import defaultdictclass IPRateLimiter:"""IP频率限制器"""def __init__(self, max_requests=100, time_window=3600):self.max_requests = max_requestsself.time_window = time_windowself.ip_requests = defaultdict(list)def is_allowed(self, ip_address):"""检查IP是否允许访问"""current_time = time.time()# 清理过期记录self._clean_old_requests(current_time)# 获取该IP的请求记录requests = self.ip_requests[ip_address]if len(requests) >= self.max_requests:return False# 记录本次请求requests.append(current_time)return Truedef _clean_old_requests(self, current_time):"""清理超过时间窗口的请求记录"""cutoff_time = current_time - self.time_windowfor ip in list(self.ip_requests.keys()):# 保留时间窗口内的记录self.ip_requests[ip] = [req_time for req_time in self.ip_requests[ip] if req_time > cutoff_time]# 如果记录为空,删除该IPif not self.ip_requests[ip]:del self.ip_requests[ip]
2.2 User-Agent检测与验证
User-Agent检测是识别爬虫的另一个重要手段。合法的浏览器都有特定的User-Agent格式,而爬虫往往使用简化的或伪造的User-Agent。
import reclass UserAgentValidator:"""User-Agent验证器"""def __init__(self):# 合法的浏览器User-Agent模式self.valid_browser_patterns = [r'Mozilla/5\.0.*Chrome/\d+', # Chrome浏览器r'Mozilla/5\.0.*Firefox/\d+', # Firefox浏览器r'Mozilla/5\.0.*Safari/\d+', # Safari浏览器r'Mozilla/5\.0.*Edge/\d+', # Edge浏览器]# 已知的爬虫User-Agentself.known_crawlers = {'python-requests', 'scrapy', 'beautifulsoup','curl', 'wget', 'java', 'go-http-client'}def is_valid_browser(self, user_agent: str) -> bool:"""检查是否为合法浏览器"""if not user_agent:return False# 检查是否为已知爬虫if any(crawler in user_agent.lower() for crawler in self.known_crawlers):return False# 检查是否符合浏览器模式for pattern in self.valid_browser_patterns:if re.search(pattern, user_agent):return Truereturn False
图1:反爬虫防御架构流程图
3. 中级防御技术
3.1 验证码技术实现
验证码是阻止自动化爬虫的有效手段,现代验证码技术已经发展到包含多种复杂形式。
import random
import string
from PIL import Image, ImageDraw, ImageFont
import io
import base64class CaptchaGenerator:"""验证码生成器"""def __init__(self, width=200, height=80, length=6):self.width = widthself.height = heightself.length = lengthself.font_size = 36def generate_text_captcha(self) -> tuple:"""生成文本验证码"""# 生成随机字符characters = string.ascii_letters + string.digitscaptcha_text = ''.join(random.choice(characters) for _ in range(self.length))# 创建图像image = Image.new('RGB', (self.width, self.height), color='white')draw = ImageDraw.Draw(image)try:font = ImageFont.truetype('arial.ttf', self.font_size)except:font = ImageFont.load_default()# 绘制干扰线for _ in range(8):x1 = random.randint(0, self.width)y1 = random.randint(0, self.height)x2 = random.randint(0, self.width)y2 = random.randint(0, self.height)draw.line([x1, y1, x2, y2], fill=self._random_color(), width=2)# 转换为base64buffered = io.BytesIO()image.save(buffered, format="PNG")img_str = base64.b64encode(buffered.getvalue()).decode()return captcha_text, f"data:image/png;base64,{img_str}"def _random_color(self):"""生成随机颜色"""return (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
3.2 请求参数签名验证
请求参数签名可以有效防止参数篡改和重放攻击。
import hashlib
import hmac
import timeclass RequestSigner:"""请求签名验证器"""def __init__(self, secret_key: str):self.secret_key = secret_key.encode()def generate_signature(self, params: dict, timestamp: int = None) -> str:"""生成请求签名"""if timestamp is None:timestamp = int(time.time())# 排序参数并构建签名字符串sorted_params = sorted(params.items())param_string = '&'.join(f"{k}={v}" for k, v in sorted_params)sign_string = f"{timestamp}{param_string}"# 使用HMAC-SHA256生成签名signature = hmac.new(self.secret_key,sign_string.encode('utf-8'),hashlib.sha256).hexdigest()return signature
图2:验证码验证时序图
4. 高级行为分析技术
4.1 鼠标轨迹与行为分析
通过分析用户的鼠标移动轨迹、点击模式等行为特征,可以区分人类用户和自动化脚本。
import numpy as np
from dataclasses import dataclass@dataclass
class MouseEvent:x: floaty: floattimestamp: floatevent_type: str # 'move', 'click', 'scroll'class BehaviorAnalyzer:"""用户行为分析器"""def analyze_mouse_trajectory(self, events: list) -> dict:"""分析鼠标轨迹特征"""if len(events) < 10:return {"confidence": 0.5, "risk_level": "medium"}features = self._extract_features(events)return self._evaluate_behavior(features)def _extract_features(self, events: list) -> dict:"""提取行为特征"""move_events = [e for e in events if e.event_type == 'move']# 计算移动速度特征speeds = self._calculate_speeds(move_events)features = {'speed_mean': np.mean(speeds) if speeds else 0,'speed_std': np.std(speeds) if speeds else 0,'movement_variability': self._calculate_variability(move_events)}return featuresdef _calculate_speeds(self, events: list) -> list:"""计算移动速度"""speeds = []for i in range(1, len(events)):dx = events[i].x - events[i-1].xdy = events[i].y - events[i-1].ydt = events[i].timestamp - events[i-1].timestampif dt > 0:distance = np.sqrt(dx**2 + dy**2)speed = distance / dtspeeds.append(speed)return speeds
4.2 浏览器指纹识别
浏览器指纹识别通过收集浏览器的各种特征来唯一标识用户设备。
import hashlib
import jsonclass BrowserFingerprinter:"""浏览器指纹识别器"""def __init__(self):self.fingerprint_components = ['user_agent', 'screen_resolution', 'timezone','language', 'platform', 'hardware_concurrency']def generate_fingerprint(self, browser_data: dict) -> str:"""生成浏览器指纹"""fingerprint_data = {}for component in self.fingerprint_components:value = browser_data.get(component, 'unknown')fingerprint_data[component] = str(value)# 排序以确保一致性sorted_data = json.dumps(fingerprint_data, sort_keys=True)# 生成MD5哈希作为指纹fingerprint = hashlib.md5(sorted_data.encode()).hexdigest()return fingerprint
图3:反爬虫技术对比象限图
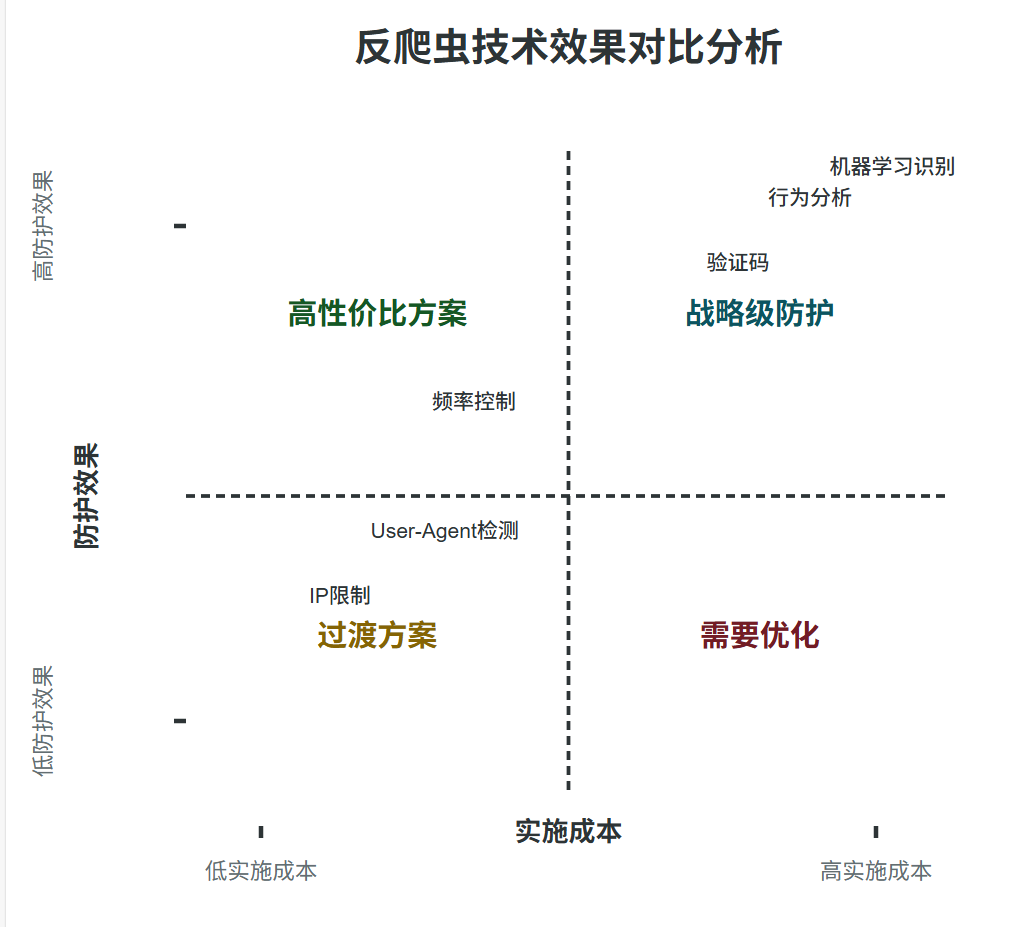
5. 智能防御系统
5.1 基于机器学习的爬虫检测
使用机器学习算法对用户行为进行分类,自动识别爬虫行为。
from sklearn.ensemble import RandomForestClassifier
import pandas as pdclass MLSpiderDetector:"""基于机器学习的爬虫检测器"""def __init__(self):self.model = Noneself.feature_columns = ['request_frequency', 'session_duration', 'page_depth','click_regularity', 'mouse_speed_variance']def extract_features(self, user_session_data: dict) -> pd.DataFrame:"""从会话数据中提取特征"""features = {}# 请求频率特征features['request_frequency'] = self._calculate_request_frequency(user_session_data.get('requests', []))# 会话时长特征features['session_duration'] = self._calculate_session_duration(user_session_data.get('session_start'),user_session_data.get('session_end'))return pd.DataFrame([features])def train_model(self, training_data: pd.DataFrame, labels: pd.Series):"""训练检测模型"""self.model = RandomForestClassifier(n_estimators=100,max_depth=10,random_state=42)self.model.fit(training_data[self.feature_columns], labels)return self.model
图4:智能反爬虫系统架构图
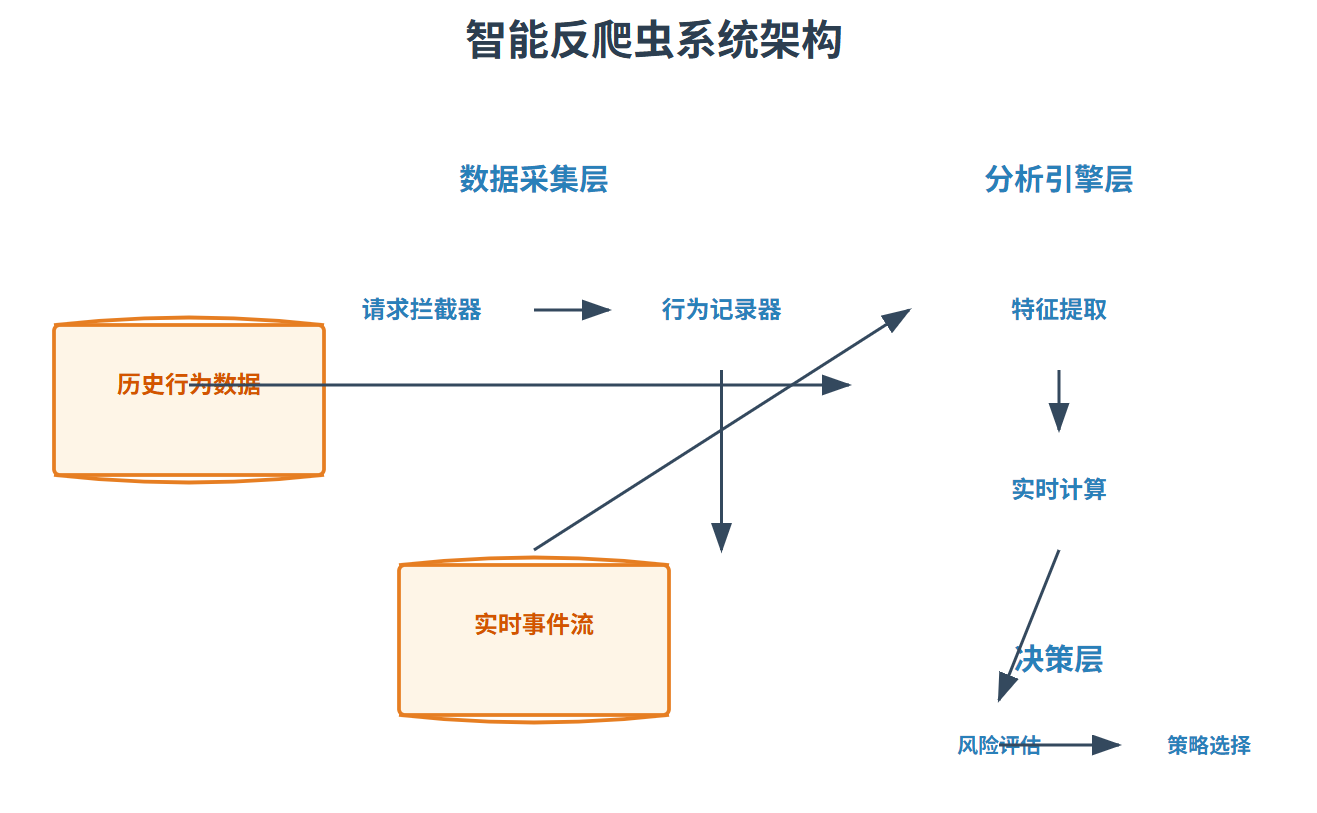
6. 技术对比与最佳实践
6.1 反爬虫技术对比分析
为了帮助开发者选择合适的技术方案,我们对比了不同反爬虫技术的效果和成本:
| 技术类型 | 防护效果 | 实施成本 | 用户体验影响 | 适用场景 |
|---|---|---|---|---|
| IP限制 | ★★☆☆☆ | ★☆☆☆☆ | 低 | 基础防护、小型网站 |
| User-Agent检测 | ★★☆☆☆ | ★☆☆☆☆ | 低 | 基础防护、简单爬虫识别 |
| 频率控制 | ★★★☆☆ | ★★☆☆☆ | 中 | API防护、资源保护 |
| 验证码 | ★★★★☆ | ★★★☆☆ | 高 | 关键操作、敏感数据 |
| 行为分析 | ★★★★☆ | ★★★★☆ | 中 | 高级防护、精准识别 |
| 机器学习识别 | ★★★★★ | ★★★★★ | 低 | 企业级、智能防护 |
评分说明:
- ★★★★★:效果最好/成本最高
- ★☆☆☆☆:效果最差/成本最低
6.2 防御策略选择公式
基于风险评估的防御策略选择可以通过以下公式进行量化:
防御等级 = α × 数据价值 + β × 攻击频率 + γ × 业务敏感性
其中:
- α = 0.4(数据价值权重)
- β = 0.3(攻击频率权重)
- γ = 0.3(业务敏感性权重)
防御策略映射表:
| 防御等级区间 | 推荐策略 | 技术组合 |
|---|---|---|
| 0-0.3 | 基础防御 | IP限制 + User-Agent检测 |
| 0.3-0.6 | 中级防御 | 频率控制 + 简单验证码 |
| 0.6-0.8 | 高级防御 | 行为分析 + 智能验证码 |
| 0.8-1.0 | 企业级防御 | 机器学习 + 全栈防护 |
7. 实战案例与性能优化
7.1 电商网站反爬虫实战
以电商网站价格监控爬虫防护为例,展示完整的防御实现:
class ECommerceAntiCrawler:"""电商网站反爬虫系统"""def __init__(self):self.rate_limiter = IPRateLimiter(max_requests=50, time_window=300)self.validator = UserAgentValidator()self.behavior_analyzer = BehaviorAnalyzer()self.ml_detector = MLSpiderDetector()def handle_product_request(self, request_data):"""处理商品信息请求"""ip = request_data.get('ip')user_agent = request_data.get('user_agent')behavior_data = request_data.get('behavior', {})# 第一层:基础防御if not self.rate_limiter.is_allowed(ip):return self._rate_limit_response()if not self.validator.is_valid_browser(user_agent):return self._suspicious_agent_response()# 第二层:行为分析behavior_result = self.behavior_analyzer.analyze_mouse_trajectory(behavior_data.get('mouse_events', []))if behavior_result['risk_level'] == 'high':return self._captcha_challenge()# 第三层:机器学习检测features = self.ml_detector.extract_features(request_data)prediction, confidence = self.ml_detector.predict(features)if prediction == 'crawler' and confidence > 0.8:return self._block_request()# 正常请求处理return self._successful_response(request_data)
7.2 性能优化策略
反爬虫系统需要在高并发场景下保持良好性能:
import asyncio
from concurrent.futures import ThreadPoolExecutorclass OptimizedAntiCrawler:"""性能优化的反爬虫系统"""def __init__(self, max_workers=10):self.executor = ThreadPoolExecutor(max_workers=max_workers)self.cache = {} # 使用缓存减少重复计算async def async_check(self, request_data):"""异步检查请求"""# 并行执行多个检查任务tasks = [self._check_ip_rate(request_data),self._check_user_agent(request_data),self._check_behavior(request_data)]results = await asyncio.gather(*tasks, return_exceptions=True)return self._combine_results(results)async def _check_ip_rate(self, request_data):"""异步检查IP频率"""loop = asyncio.get_event_loop()return await loop.run_in_executor(self.executor, self.rate_limiter.is_allowed, request_data['ip'])def _combine_results(self, results):"""合并检查结果"""# 实现结果合并逻辑pass
8. 行业引用与最佳实践
安全箴言: “在网络安全领域,没有绝对的安全,只有相对的安全。真正的防护不在于构建无法逾越的城墙,而在于建立快速响应和持续演进的防御体系。” — 网络安全专家原则
8.1 反爬虫设计原则
根据多年的实战经验,我总结出以下反爬虫系统设计原则:
-
分层防御原则
- 建立多层次、纵深防御体系
- 每层都有独立的检测和防护能力
- 避免单点故障,确保系统鲁棒性
-
用户体验平衡原则
- 防护强度与用户体验需要平衡
- 对正常用户影响最小化
- 对恶意爬虫精准打击
-
持续演进原则
- 爬虫技术在不断进化,防御系统也需要持续更新
- 建立反馈机制,根据攻击模式调整策略
- 定期评估和优化防御效果
-
合规合法原则
- 确保反爬虫措施符合相关法律法规
- 尊重用户隐私,避免过度收集数据
- 明确服务条款,建立合法的防护依据
9. 未来发展趋势
9.1 技术演进方向
反爬虫技术正在向更加智能化和自动化的方向发展:
-
AI驱动的智能识别
- 基于深度学习的异常检测
- 自然语言处理识别语义爬虫
- 图像识别技术应对OCR爬虫
-
区块链技术的应用
- 分布式信任机制
- 不可篡改的行为记录
- 去中心化的身份验证
-
边缘计算集成
- 就近计算减少延迟
- 分布式防护节点
- 智能流量调度
9.2 面临的挑战
未来反爬虫技术发展面临的主要挑战:
- 隐私保护与数据收集的平衡
- 跨国法律合规性问题
- AI对抗技术的兴起
- 性能与准确性的权衡
10. 总结
回顾这场持续的技术博弈,我深刻体会到反爬虫技术的复杂性和重要性。从最初简单的IP限制到如今基于AI的智能识别,反爬虫技术已经发展成为一门综合性的技术学科。在这个过程中,我见证了无数次的攻防对抗,也积累了宝贵的实战经验。
作为技术从业者,我们需要认识到反爬虫不仅仅是技术问题,更是涉及用户体验、商业利益和法律合规的综合性挑战。一个优秀的反爬虫系统应该在保护数据安全的同时,最大限度地减少对正常用户的影响,这需要我们在技术实现和策略选择上做出精细的平衡。
未来的反爬虫技术将更加注重智能化和自适应能力。随着AI技术的发展,我们可以期待更加精准的识别算法和更加高效的防护策略。但同时,爬虫技术也在不断进化,这场"猫鼠游戏"将会持续下去。作为技术守护者,我们需要保持学习的态度,不断更新我们的技术栈和防护理念。
在二进制世界的星河中,每一次技术突破都是我们对未知领域的探索。反爬虫技术作为网络安全的重要组成部分,将继续在数据保护的前沿发挥关键作用。让我们携手前行,用代码构筑更加安全可靠的数字世界。
参考链接
- OWASP Anti-Crawler Techniques
- Google reCAPTCHA最佳实践
- 反爬虫技术白皮书 - 腾讯安全
- 机器学习在网络安全中的应用
- Web应用防火墙技术解析
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!