【MySQL】MVCC:从核心原理到幻读解决方案
【MySQL】MVCC:从核心原理到幻读解决方案
- MVCC
- undo log
- ReadView
- (1)read view 包含 4 个关键字段
- (2)可见性判断规则
- 隔离级别
- 1. 当前读 vs 快照读
- (1)快照读:普通 select,读版本链的旧版本
- (2)当前读:加锁的读 / 写,读数据的最新版本
- 2. 四种隔离级别的实现逻辑
- (1)读未提交(Read Uncommitted)
- (2)读已提交(Read Committed)
- (3)可重复读(Repeatable Read)
- (4)串行化(Serializable)
- 幻读
- 1. 常规场景:快照读 + 间隙锁
- (1)快照读:看不到新增数据,自然无幻读
- (2)当前读:加间隙锁,阻止其他事务新增
- 2. 极端场景:先快照读,再当前读
- 反例 1:查不到数据,插入却失败
- 反例 2:查不到数据,却能修改
- 3. 极端幻读的解决方案:强制当前读,提前加锁
信不信?花几分钟时间,你就能彻底搞懂 MVCC(多版本并发控制)。其实要吃透 MVCC,关键就是搞懂这几个核心问题:MVCC 是什么?用来解决什么问题?怎么实现的?四种隔离级别如何依托 MVCC 实现?当前读和快照读有啥区别?可重复读隔离级别下,怎么避免幻读?如果避不开,有哪些反例?极端幻读场景又该怎么处理?
从并发事务的痛点说起。假设数据库里一张表存了大量数据,同时有很多事务在访问或修改这些数据 —— 这种并发场景下,很容易出现脏读、不可重复读、幻读这三大问题。要解决这些问题,就得靠隔离级别和 MVCC 的配合。
MVCC
MVCC 指的是多版本并发控制,是通过版本链和 ReadView 机制来实现的。
MVCC通过维护数据的多个版本,让不同事务在并发访问时,能读到符合自己隔离级别的数据版本,从而避免脏读、不可重复读,同时尽可能提高并发性能。
比如:
-
要解决 “脏读”(读到其他事务未提交的数据):就让事务只读 “已提交的版本”;
-
要解决 “不可重复读”(同一事务内多次读同一数据,结果不一样):就让事务每次都读 “同一个版本”。
undo log
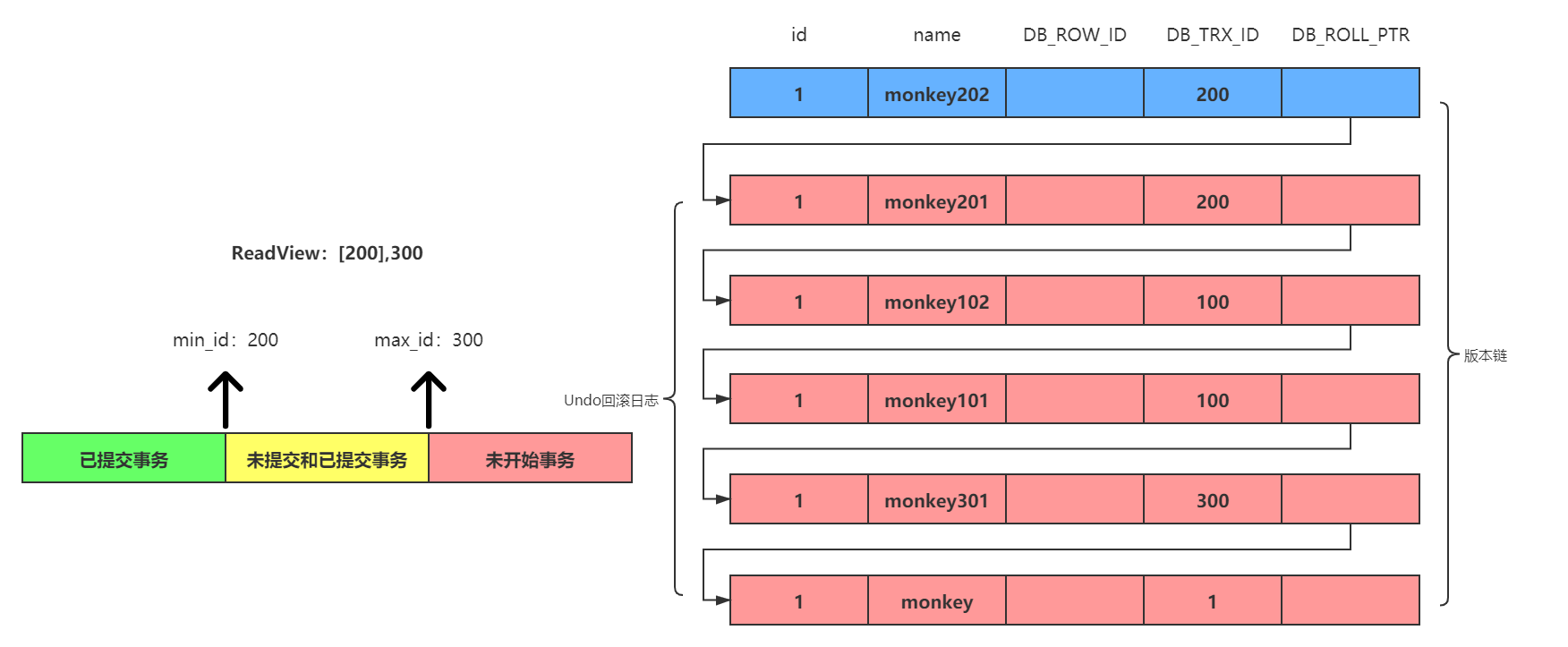
- 每条记录包含两个隐藏列:最近修改的事务 ID 和指向 Undo Log 的指针,用于构成版本链。
- 每次更新数据时,会生成一个新的数据版本,并将旧版本的数据保存到 Undo Log 中。
- 每次读取数据时,会生成一个 ReadView,用于判断哪个版本的数据对当前事务可见。
举个例子:事务 1(ID=10)把user表中id=1的age从 20 改成 25,事务 2(ID=20)又把这个age改成 30。最终的版本链会是这样:
当前数据(age=30): DB_TRX_ID=20,DB_ROLL_PTR→undo log2(age=25)
undo log2(age=25):DB_TRX_ID=10,DB_ROLL_PTR→undo log1(age=20)
undo log1(age=20):DB_TRX_ID=null(初始数据),DB_ROLL_PTR=null
如果事务想读旧版本,顺着DB_ROLL_PTR往下找就行。
ReadView
有了版本链,问题来了:事务查询时,怎么知道该读哪个版本?比如事务 3(ID=30)查id=1的数据,该读 age=30、25 还是 20?
这时候就需要read view(读视图)—— 它相当于一个 “过滤规则”,记录了当前事务启动时,数据库中 “活跃且未提交的事务 ID”,通过对比数据版本的DB_TRX_ID和 read view 的规则,就能判断该版本是否可见。
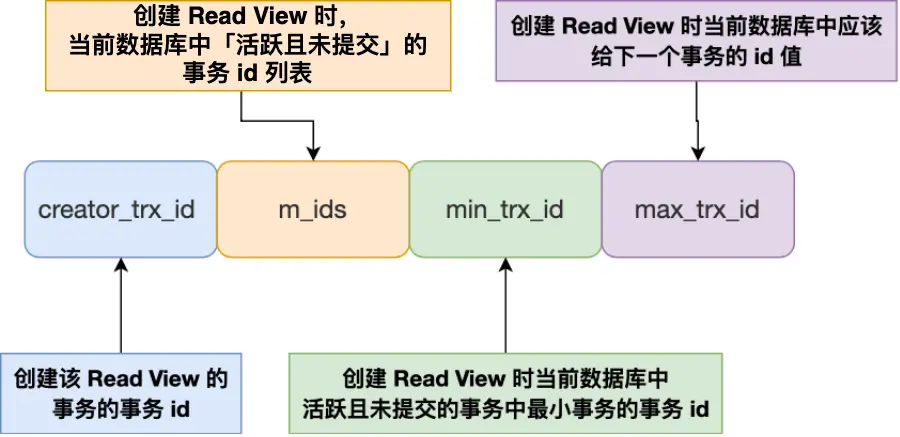
(1)read view 包含 4 个关键字段
-
creator_trx_id:创建这个 read view 的 “当前事务 ID”;
-
m_ids:创建 read view 时,数据库中 “活跃且未提交的所有事务 ID”(比如此时有事务 15、25 没提交,m_ids=[15,25]);
-
min_trx_id:m_ids 中的 “最小事务 ID”(比如 15);
-
max_trx_id:创建 read view 时,数据库 “下一个要分配的事务 ID”(比如当前最大事务 ID 是 25,max_trx_id 就是 26)。
(2)可见性判断规则
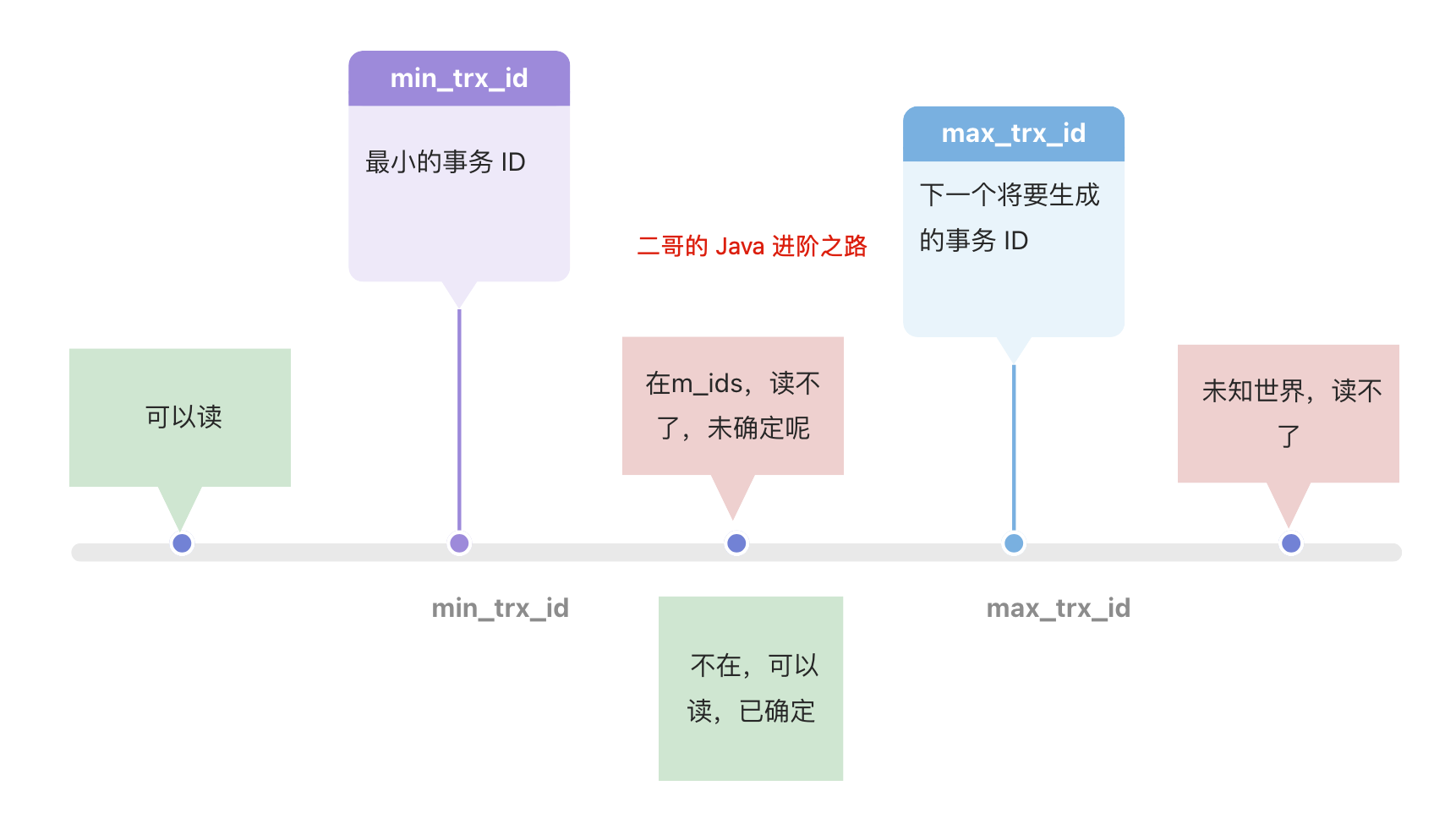
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
-
如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
-
如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
-
如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
-
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
ReadView 主要用来处理隔离级别为**“可重复读"和"读已提交”**的情况。因为在这两个隔离级别下,事务在读取数据时,需要保证读取到的数据是一致的,即读取到的数据是在事务开始时的一个快照。
隔离级别
1. 当前读 vs 快照读
(1)快照读:普通 select,读版本链的旧版本
快照读就是我们平时执行的普通 select 语句(比如select * from user where id=1),它的特点是:
-
不加锁,靠 MVCC 读 undo log 版本链中的旧版本;
-
核心优势是 “高并发”,适合只需要查询数据、不需要修改的场景。
(2)当前读:加锁的读 / 写,读数据的最新版本
当前读是指 “必须读数据最新版本” 的操作,这些操作会加锁,防止其他事务修改,包括:
-
加排他锁的读:select … for update;
-
加共享锁的读:select … in share mode;
-
所有写操作:insert、update、delete(写之前必须先读最新版本,判断是否符合条件)。
当前读的特点是:
-
加锁(行锁或间隙锁),会阻塞其他事务的写操作;
-
不读版本链,直接读数据的最新版本,确保 “写操作基于最新数据”。
比如你执行update user set age=30 where id=1,MySQL 会先 “当前读” id=1 的最新数据,确认存在后再修改 —— 如果此时有其他事务改了 id=1 的数据,会被当前读的锁阻塞。
2. 四种隔离级别的实现逻辑
(1)读未提交(Read Uncommitted)
读未提交是最低的隔离级别,它的逻辑很 “简单粗暴”:直接读数据的最新版本,不管修改该版本的事务是否提交。比如事务 A 改了数据但没提交,事务 B 就能直接读到这个 “脏数据”—— 所以它根本不需要 MVCC 的版本链和 read view,天然就是读未提交。
(2)读已提交(Read Committed)
读已提交的核心要求是 “只能读已提交的数据”,它靠 MVCC 实现的逻辑是:每次执行 select 语句(快照读)时,都会重新生成一个 read view。
举个例子:
-
事务 1(ID=10)改了id=1的 age 为 25,没提交;
-
事务 2(ID=20)第一次 select:生成 read view1,m_ids=[10],此时 trx_id=10 在 m_ids 中,所以读不到事务 1 的修改,只能读旧版本 age=20;
-
事务 1 提交后,事务 2 第二次 select:生成 read view2,m_ids 为空(事务 1 已提交),此时 trx_id=10 < min_trx_id(比如 21),所以能读到 age=25。
这就是读已提交:每次读都用新的 read view,能看到 “最新已提交的版本”,避免了脏读,但无法避免 “不可重复读”(同一事务内两次读结果不同)。
(3)可重复读(Repeatable Read)
可重复读是 MySQL 的默认隔离级别,核心要求是 “同一事务内多次读同一数据,结果一致”,它的实现逻辑是:只在事务第一次执行 select(快照读)时生成 read view,后续所有 select 都复用这个 read view。
还是刚才的例子:
-
事务 2(ID=20)第一次 select:生成 read view1,m_ids=[10],读 age=20;
-
事务 1 提交后,事务 2 第二次 select:复用 read view1,此时 trx_id=10 仍在 m_ids 中(read view1 没更新),所以还是读 age=20。
这样就实现了 “可重复读”:不管其他事务是否提交,同一事务内都用同一个 read view,读的始终是 “第一次看到的版本”,避免了脏读和不可重复读。
(4)串行化(Serializable)
串行化是最高隔离级别,它的逻辑最简单:所有事务串行执行,读写都加锁(读加共享锁,写加排他锁),完全禁止并发。比如事务 A 读数据时,事务 B 不能改;事务 A 改数据时,事务 B 不能读 —— 这种方式能避免所有并发问题,但性能极差,实际业务中很少用。
幻读
幻读是指 “同一事务内,两次执行相同的查询,结果集的行数不一样”(比如第一次查有 10 条数据,第二次查有 11 条,多了一条其他事务新增的)。
可重复读是 MySQL 的默认隔离级别,它能解决脏读和不可重复读,但幻读问题该怎么处理?咱们从 “常规解决方式” 和 “极端场景应对” 两方面说。
1. 常规场景:快照读 + 间隙锁
可重复读通过 “快照读避免新增可见” 和 “当前读加间隙锁阻止新增”,解决了大部分幻读问题:
(1)快照读:看不到新增数据,自然无幻读
普通 select(快照读)靠 MVCC 读旧版本,在可重复读隔离级别下,复用第一次生成的 read view—— 不管其他事务新增 / 删除了多少数据,当前事务都看不到,结果集行数始终不变,自然不会出现幻读。
比如事务 A 第一次查id>100的数据有 5 条,事务 B 新增了 1 条id=101的数据并提交,事务 A 再查id>100的数据,还是 5 条(快照读看不到新增的 1 条),避免了幻读。
(2)当前读:加间隙锁,阻止其他事务新增
执行select … for update、insert、update、delete 等当前读操作时,MySQL 会加 “间隙锁”(属于行锁的一种),锁住 “数据之间的间隙”,阻止其他事务插入数据,从而避免幻读。
举个例子:执行select * from user where id>100 for update(当前读):
-
MySQL 会先锁住 “id=100” 这条数据(如果存在),阻止其他事务修改;
-
再锁住 “100 到正无穷” 的间隙,阻止其他事务插入 id>100 的数据;
-
这样一来,当前事务后续再查 id>100 的数据,行数不会变,避免了幻读。
2. 极端场景:先快照读,再当前读
可惜,“快照读 + 间隙锁” 不能解决所有幻读问题 —— 当事务内 “先快照读,再当前读” 时,还是会出现幻读,咱们看两个典型反例:
反例 1:查不到数据,插入却失败
-
事务 A(可重复读隔离级别):执行select * from user where id=1(快照读),结果为空(表中没有 id=1 的数据);
-
事务 B:执行insert into user(id, name) values(1, ‘AA’),提交;
-
事务 A:再次执行select * from user where id=1(快照读),还是为空(复用第一次的 read view,看不到事务 B 的新增);
-
事务 A:尝试执行insert into user(id, name) values(1, ‘AA’),却报错 “主键冲突”—— 这就是幻读:明明快照读不到,却插不进去,因为当前读(insert 前的检查)看到了事务 B 的新增。
反例 2:查不到数据,却能修改
-
事务 A:select * from user where name=‘AA’(快照读),结果为空;
-
事务 B:insert into user(name) values(‘AA’),提交;
-
事务 A:再次select * from user where name=‘AA’(快照读),仍为空;
-
事务 A:执行update user set age=20 where name=‘AA’,却提示 “1 row affected”(修改成功);
-
事务 A:再查select * from user where name=‘AA’,就能看到 age=20 的数据 —— 这更诡异:快照读不到,却能修改,修改后又能读到,本质也是 “先快照读,再当前读” 导致的幻读。
3. 极端幻读的解决方案:强制当前读,提前加锁
要解决这种极端幻读,核心思路是:在事务开始时,就用当前读(加锁)代替快照读,提前锁住间隙,阻止其他事务新增 / 删除数据。
具体做法有两种:
-
方案 1:用 select … for update 提前加锁:事务一开始就执行select * from user where id=1 for update(当前读),此时会锁住 id=1 的间隙,事务 B 无法插入 id=1 的数据,后续插入就不会冲突;
-
方案 2:给表加表锁:如果需要操作全表数据,可执行lock table user write(加表级排他锁),阻止其他事务对表进行任何写操作(insert/delete/update),但这种方式性能较差,适合数据量小的场景。
核心原则就是:如果事务内需要 “先查后写”,且不允许出现幻读,就不要用普通的快照读,而是直接用当前读加锁,提前阻断其他事务的写操作。