神经网络中优化器的作用
优化器(Optimizer)在深度学习和大模型训练中起着核心作用,它是连接“模型预测误差”与“参数更新”的桥梁。简单来说:
✅ 优化器的作用是:根据损失函数的梯度,自动调整模型的参数(如权重和偏置),使模型逐步学会从输入到输出的正确映射。
一、为什么需要优化器?
在训练神经网络时,我们的目标是:
最小化损失函数 L(θ),其中 θ 是模型的所有可学习参数。
但模型一开始是“随机初始化”的,预测结果很差 → 损失很大。
我们无法手动去调每一个参数,因此需要一个自动化机制来一步步改进模型 —— 这就是优化器。
二、优化器的核心任务
| 任务 | 说明 |
|---|---|
| 🔍 计算梯度 | 利用反向传播(Backpropagation)计算损失对每个参数的偏导数 |
| 🧮 更新参数 | 根据梯度和其他信息(如历史梯度、动量等),决定如何更新参数: |
其中 ηη 是学习率(learning rate),控制步长。
三、常见优化器及其作用原理
1. SGD(随机梯度下降)
![]()
- gt:当前批次的梯度
✅ 优点:简单、计算快
❌ 缺点:容易震荡、收敛慢、易陷入局部极小
2. SGD + 动量(Momentum)
引入“动量”模拟物理中的惯性:
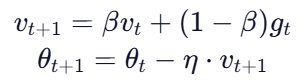
- v:速度(累积历史梯度)
- β:动量系数(通常 0.9)
✅ 作用:
- 加快收敛
- 减少震荡
- 帮助跳出局部极小
3. Adam(最常用)
结合了 动量(Momentum) 和 自适应学习率(RMSProp)
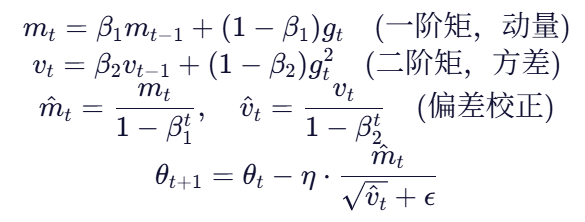
✅ 优势:
- 自适应调整每个参数的学习率(重要参数更新小,不重要更新大)
- 收敛快、稳定性好
- 在大多数任务中表现优异(如 BERT、GPT 训练都用 Adam)
四、优化器的“作用”总结
| 角度 | 说明 |
|---|---|
| 🎯 目标导向 | 最小化损失函数,提升模型性能 |
| ⚙️ 参数更新机制 | 提供一套规则,告诉模型“往哪个方向走、走多远” |
| 🛠️ 加速训练 | 如 Adam、RMSProp 可加快收敛速度 |
| 🧱 稳定训练 | 防止梯度爆炸/消失,避免震荡 |
| 🌐 支持大规模模型 | 能处理数十亿参数的更新(如 LLaMA、ChatGPT) |
五、实际应用中的选择建议
| 场景 | 推荐优化器 |
|---|---|
| 一般深度学习任务(CNN、RNN) | Adam |
| 大模型预训练(如 BERT、GPT) | AdamW(Adam + 权重衰减修正) |
| 精细微调 | SGD with Momentum(泛化更好) |
| 快速实验 | Adam(收敛快) |
💡 AdamW 是目前大模型最常用的优化器,它修正了 Adam 中权重衰减的实现方式,更适合 Transformer 架构。
六、代码示例(PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim# 定义模型
model = nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6)# 使用 AdamW 优化器
optimizer = optim.AdamW(model.parameters(), lr=5e-5, weight_decay=1e-4)# 训练循环
for input, target in dataloader:optimizer.zero_grad()output = model(input)loss = nn.CrossEntropyLoss()(output, target)loss.backward() # 反向传播,计算梯度optimizer.step() # 优化器更新参数✅ 总结一句话:
优化器是深度学习的“导航系统”——它根据损失的梯度,智能地调整模型参数,引导模型一步步走向最优解。
没有优化器,神经网络就无法“学习”。