再谈线程同步——读写锁与屏障
引言
核心问题仍然是当多个线程共享同一进程的内存空间(即共享全局数据、堆数据等)时,如果它们同时读写同一份数据,且操作不是原子性的,就会导致数据的不一致性、逻辑错误或程序崩溃。这就是竞态条件。其中原子操作,指一个操作要么完全执行,要么完全不执行,中间不会被打断。像 i++ 这样的操作看似一行代码,但实际上对应了多条机器指令(读、增、写),因此不是原子操作。线程同步的目的就是为了协调多个线程对共享资源的访问,确保在任意时刻,临界区(访问共享资源的代码段)最多只有一个线程在执行,从而避免竞态条件。
读写锁
互斥锁是排他的,但有时共享资源的读取操作远多于写入操作,读写锁提供了更高的并行性。读写锁也被称为"共享-独占锁"。它针对"读多写少"的场景进行了优化,提高了并发性能。
读模式(共享):多个线程可以同时持有读锁,只要没有线程持有写锁。
写模式(独占):只有一个线程可以持有写锁,并且在此期间,任何其他线程都不能持有读锁或写锁。锁的优先级策略:不同的实现可能有不同的策略来处理读锁和写锁请求的竞争:
读优先:允许读锁插队,可能导致写线程饥饿(长时间等待)。
写优先:一旦有写锁请求,后续的读锁请求必须等待,防止写线程饥饿。
默认策略:通常取决于具体实现,POSIX 标准允许实现自定义策略。(适合的场景:读多写少的场景,如配置信息、缓存等)
#include <pthread.h>
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;// 初始化读写锁int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr);int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);// 销毁读写锁int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);// 获取读锁int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);// 获取写锁int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);// 解锁(读锁和写锁都用这个解锁)int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
//尝试获取读锁,如果无法立即获取(例如锁已被写者持有),则返回错误 EBUSY,而不是阻塞。int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
//尝试获取写锁,如果无法立即获取,则返回错误 EBUSY,而不是阻塞。 int pthread_rwlock_timedrdlock(pthread_rwlock_t *rwlock, const struct timespec *abstime);
//在指定的绝对时间 abstime 之前尝试获取读锁,超时则返回 ETIMEDOUT。 int pthread_rwlock_timedwrlock(pthread_rwlock_t *rwlock, const struct timespec *abstime);
//在指定的绝对时间 abstime 之前尝试获取写锁,超时则返回 ETIMEDOUT。宏初始化的读写锁不需要调用 pthread_rwlock_destroy()(但调用通常也无害)
用于静态地初始化一个读写锁。它在编译时期完成初始化,使用默认属性。适用于全局或静态读写锁。
注意点:
同一个线程可以多次获取读锁,但必须有相同次数的解锁操作。
如果线程已经持有写锁,再尝试获取读锁的行为是未定义的,可能导致死锁。
写锁是独占的。一旦某个线程持有写锁,其他所有线程(无论是读还是写)都无法获得锁,直到该写锁被释放。如果线程已经持有读锁,再尝试获取写锁的行为是未定义的,通常会导致死锁。线程必须先释放所有读锁,才能申请写锁。 必须由锁的持有者线程来调用解锁。
解锁操作会唤醒正在等待该锁的其他线程(可能是读线程或写线程,取决于系统调度策略)。
用例
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>// 配置结构体
struct config {int value;char name[100];
};
// 全局配置实例和读写锁
struct config global_cfg;
pthread_rwlock_t cfg_rwlock;// 读线程函数 - 多个读线程可以同时执行
void* reader_thread(void* arg) {int thread_id = *(int*)arg;free(arg); // 释放动态分配的参数内存for (int i = 0; i < 5; i++) {// 获取读锁pthread_rwlock_rdlock(&cfg_rwlock);// 安全地读取 global_cfgprintf("Reader %d: Config value=%d, name=%s\n", thread_id, global_cfg.value, global_cfg.name);// 释放读锁pthread_rwlock_unlock(&cfg_rwlock);// 休眠一段时间,模拟读取操作耗时usleep(100000); // 100ms}return NULL;
}// 写线程函数 - 写线程是独占的
void* writer_thread(void* arg) {int thread_id = *(int*)arg;free(arg); // 释放动态分配的参数内存for (int i = 0; i < 3; i++) {// 获取写锁pthread_rwlock_wrlock(&cfg_rwlock);// 安全地修改 global_cfgglobal_cfg.value++;snprintf(global_cfg.name, sizeof(global_cfg.name), "Config_v%d", global_cfg.value);printf("Writer %d: Updated config value to %d, name to %s\n", thread_id, global_cfg.value, global_cfg.name);// 释放写锁pthread_rwlock_unlock(&cfg_rwlock);// 休眠一段时间,模拟写入操作耗时usleep(200000); // 200ms}return NULL;
}int main() {const int num_readers = 5;const int num_writers = 2;pthread_t readers[num_readers];pthread_t writers[num_writers];// 初始化配置global_cfg.value = 0;strcpy(global_cfg.name, "InitialConfig");// 初始化读写锁if (pthread_rwlock_init(&cfg_rwlock, NULL) != 0) {perror("Failed to initialize rwlock");return EXIT_FAILURE;}printf("Starting with initial config: value=%d, name=%s\n\n", global_cfg.value, global_cfg.name);// 创建读线程for (int i = 0; i < num_readers; i++) {int* thread_id = malloc(sizeof(int));*thread_id = i + 1;if (pthread_create(&readers[i], NULL, reader_thread, thread_id) != 0) {perror("Failed to create reader thread");free(thread_id);}}// 创建写线程for (int i = 0; i < num_writers; i++) {int* thread_id = malloc(sizeof(int));*thread_id = i + 1;if (pthread_create(&writers[i], NULL, writer_thread, thread_id) != 0) {perror("Failed to create writer thread");free(thread_id);}}// 等待所有读线程完成for (int i = 0; i < num_readers; i++) {pthread_join(readers[i], NULL);}// 等待所有写线程完成for (int i = 0; i < num_writers; i++) {pthread_join(writers[i], NULL);}printf("\nFinal config: value=%d, name=%s\n", global_cfg.value, global_cfg.name);// 销毁读写锁pthread_rwlock_destroy(&cfg_rwlock);return 0;
}(当写线程持有锁时,所有后来的读线程和写线程都会被阻塞,直到写线程释放锁。这可以防止写线程“饿死”。 写线程饥饿:如果一直有读锁被持有,写线程可能会一直无法获取写锁而“饿死”。某些实现提供了偏向写线程的读写锁或公平的策略来避免此问题。)
屏障
屏障允许多个线程在某个点同步等待,直到所有参与线程都到达这个点后,才能继续执行。即设置一个屏障点和一个计数 N。每个线程到达屏障点时都会阻塞。当第 N 个线程到达后,所有被阻塞的线程才会被同时唤醒,继续执行。就像现实中多人约好到一个地点集合,所有人都到齐后,再一起出发。
并行计算:将一个大任务分解成多个子任务由不同线程并行计算,最后需要汇总所有结果。
多轮次的计算,每轮开始前需要等待所有线程完成上一轮。
#include <pthread.h>pthread_barrier_t barrier =PTHREAD_BARRIER_INITIALIZER(count);// 初始化屏障,count 指定需要等待的线程数
int pthread_barrier_init(pthread_barrier_t *barrier, const pthread_barrierattr_t *attr, unsigned int count);int pthread_barrier_destroy(pthread_barrier_t *barrier);// 销毁屏障int pthread_barrier_wait(pthread_barrier_t *barrier);// 线程到达屏障点并等待 返回值:0 表示所有线程已到达,PTHREAD_BARRIER_SERIAL_THREAD 表示其中一个被选中的线程注意点:
屏障一旦初始化,所需的线程数 (count) 就固定了,不能动态更改。如果需要在进程间共享屏障,可以通过属性设置 PTHREAD_PROCESS_SHARED,但这需要将屏障放在共享内存中。
线程选择:哪个线程会收到 PTHREAD_BARRIER_SERIAL_THREAD 是不确定的,由实现决定。通常是最后一个到达屏障的线程。
可重复使用:屏障是可重用的。一旦所有线程到达屏障并被释放,屏障会自动重置,可以再次使用。
不可取消:如果线程在等待屏障时被取消,屏障可能会处于不一致状态,影响其他线程。
屏障状态:当所有线程到达后,屏障的状态会变为"已触发",所有等待线程会被释放,然后屏障自动重置为初始状态,等待下一轮使用。
用例
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>#define NUM_THREADS 4
pthread_barrier_t barrier;void* thread_function(void* arg) {long thread_id = (long)arg;printf("Thread %ld: Starting phase 1\n", thread_id);sleep(1 + thread_id); // 模拟不同长度的工作时间printf("Thread %ld: Reached barrier\n", thread_id);int result = pthread_barrier_wait(&barrier);if (result == PTHREAD_BARRIER_SERIAL_THREAD) {printf("Thread %ld: I'm the serial thread! Performing serial work...\n", thread_id);// 这里可以执行一些只需要一个线程完成的工作(如数据整合)} else if (result == 0) {printf("Thread %ld: Passed barrier\n", thread_id);}// 所有线程继续执行第二阶段工作printf("Thread %ld: Starting phase 2\n", thread_id);return NULL;
}int main() {pthread_t threads[NUM_THREADS];// 初始化屏障,等待 NUM_THREADS 个线程if (pthread_barrier_init(&barrier, NULL, NUM_THREADS) != 0) {perror("Failed to initialize barrier");return EXIT_FAILURE;}// 创建线程for (long i = 0; i < NUM_THREADS; i++) {if (pthread_create(&threads[i], NULL, thread_function, (void*)i) != 0) {perror("Failed to create thread");return EXIT_FAILURE;}}// 等待所有线程完成for (int i = 0; i < NUM_THREADS; i++) {pthread_join(threads[i], NULL);}// 销毁屏障pthread_barrier_destroy(&barrier);printf("All threads completed.\n");return 0;
}( 初始化时指定的count必须正确,通常等于需要使用该屏障的线程数。 pthread_barrier_wait函数返回PTHREAD_BARRIER_SERIAL_THREAD的线程可以执行一些特殊的串行工作(如数据汇总)。 屏障一旦被突破(所有线程都到达后),会自动重置,可以重复使用。)
自旋锁
自旋锁的主要作用是实现对共享资源的互斥访问。它与互斥锁类似,都是为了保护临界区,确保同一时间只有一个线程可以访问共享资源。自旋锁是一种忙等待(busy-waiting) 的锁机制。它的核心原理是:当一个线程尝试获取一个已经被其他线程持有的自旋锁时,它不会立即进入睡眠状态(即不会发生上下文切换),而是会在一个紧凑的循环中不断地尝试获取锁,直到成功为止。
核心区别在于:当锁已被占用时,线程的行为不同。
互斥锁:线程会进入睡眠状态,让出 CPU,等待被唤醒。
自旋锁:线程会在一个循环中忙等待,不断地检查锁是否被释放,期间不让出 CPU。
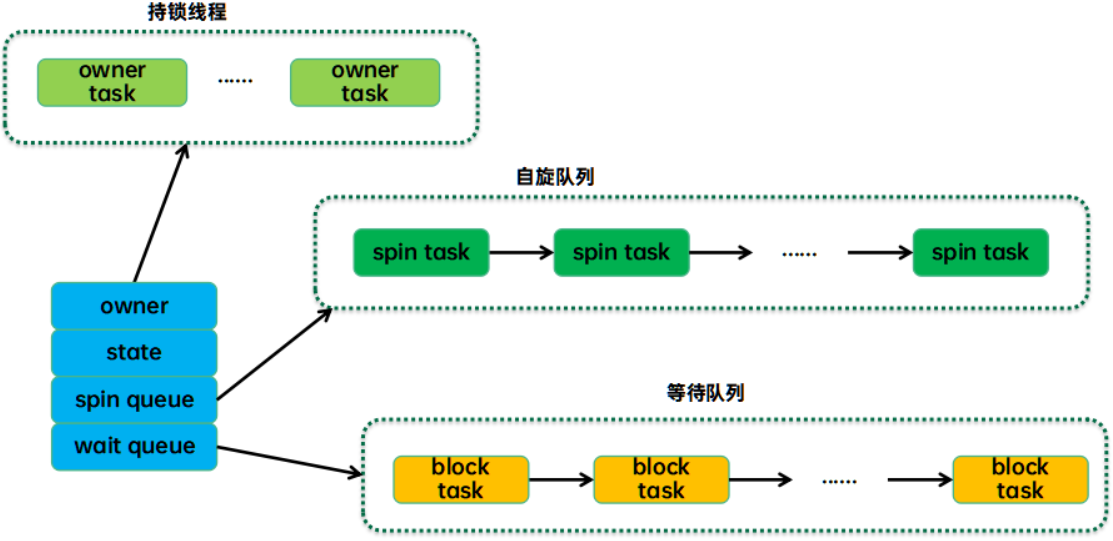
其使用需要非常小心,仅在特定场景下能发挥优势:
• 极短的临界区:需要保护的代码段(临界区)执行速度非常快,通常只有几条指令,预计等待锁的时间极短(甚至短于线程上下文切换的开销)。
• 多核系统:在单核CPU上,自旋锁通常没有意义(除非配合中断禁用)。因为如果线程A在自旋等待锁,而锁被线程B持有,但在单核上线程B无法运行来释放锁,这就导致了死锁。多核系统上,持有锁的线程可能在另一个核上运行并很快释放锁。
• 不允许睡眠的上下文:例如在内核编程的中断处理程序(ISR)中,或者在一些实时操作系统中,线程是不允许睡眠的,此时自旋锁是唯一的选择。
• 低延迟要求:对于一些对延迟极其敏感的应用,为了避免上下文切换带来的不可预测的延迟,可能会使用自旋锁。
(只有在多核系统上,且你能确信锁被持有的时间非常非常短的时候,才考虑使用自旋锁。)
#include <pthread.h> pthread_spinlock_t spinlock = PTHREAD_SPINLOCK_INITIALIZER;int pthread_spin_lock(pthread_spinlock_t *lock); // 获取自旋锁 int pthread_spin_trylock(pthread_spinlock_t *lock); // 尝试获取自旋锁(非阻塞) int pthread_spin_unlock(pthread_spinlock_t *lock); // 释放自旋锁 int pthread_spin_init(pthread_spinlock_t *lock, int pshared); // 初始化自旋锁 int pthread_spin_destroy(pthread_spinlock_t *lock); // 销毁自旋锁 对于进程间共享的自旋锁,必须将其放置在共享内存区域中。
用例
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>#define NUM_THREADS 5
pthread_spinlock_t spinlock;
int shared_counter = 0;void* thread_func(void* arg) {long thread_id = (long)arg;// 尝试获取自旋锁if (pthread_spin_trylock(&spinlock) == 0) {printf("Thread %ld acquired the lock\n", thread_id);// 临界区shared_counter++;printf("Thread %ld: shared_counter = %d\n", thread_id, shared_counter);// 释放锁pthread_spin_unlock(&spinlock);printf("Thread %ld released the lock\n", thread_id);} else {printf("Thread %ld: lock is busy, doing other work...\n", thread_id);// 执行不需要锁的操作}return NULL;
}int main() {pthread_t threads[NUM_THREADS];// 初始化自旋锁if (pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE) != 0) {perror("Failed to initialize spinlock");return EXIT_FAILURE;}// 创建线程for (long i = 0; i < NUM_THREADS; i++) {if (pthread_create(&threads[i], NULL, thread_func, (void*)i) != 0) {perror("Failed to create thread");return EXIT_FAILURE;}}// 等待所有线程完成for (int i = 0; i < NUM_THREADS; i++) {pthread_join(threads[i], NULL);}printf("Final value of shared_counter: %d\n", shared_counter);// 销毁自旋锁pthread_spin_destroy(&spinlock);return EXIT_SUCCESS;
}线程同步手段的选取:
先看是否需要等待某个条件:如果需要(如“队列不为空”),首选 互斥锁 + 条件变量。
再看数据访问模式:如果主要是读取,偶尔写入,且对性能要求高,考虑 读写锁。
然后看是否需要控制并发量:如果需要限制同时访问的线程数,用 信号量。
最后看是否需要所有线程同步进度:
如果需要所有线程完成一个阶段再进入下一个,用 屏障。
对于最简单的独占访问,直接用 互斥锁。