《Span-based Localizing Network for Natural Language Video Localization》
一、跨度 QA 框架(Span-based QA Framework)
1. 核心定义
跨度 QA 框架是一种原本用于文本问答任务的技术框架,核心目标是从给定的文本 “段落”(Context)中,定位与文本 “问题”(Question)语义匹配的连续文本片段(答案跨度,Answer Span),通过预测该跨度的起止边界完成问答。在本文中,作者将该框架适配到自然语言视频定位(NLVL)任务:把未剪辑视频视为 “文本段落”,视频的视觉特征序列类比文本的词嵌入序列;把待定位的视频目标时刻视为 “答案跨度”,从而将 NLVL 转化为 “从视频中定位与文本查询匹配的时刻跨度” 问题。
2. 本文中的适配实现(以 VSLBase 为例)
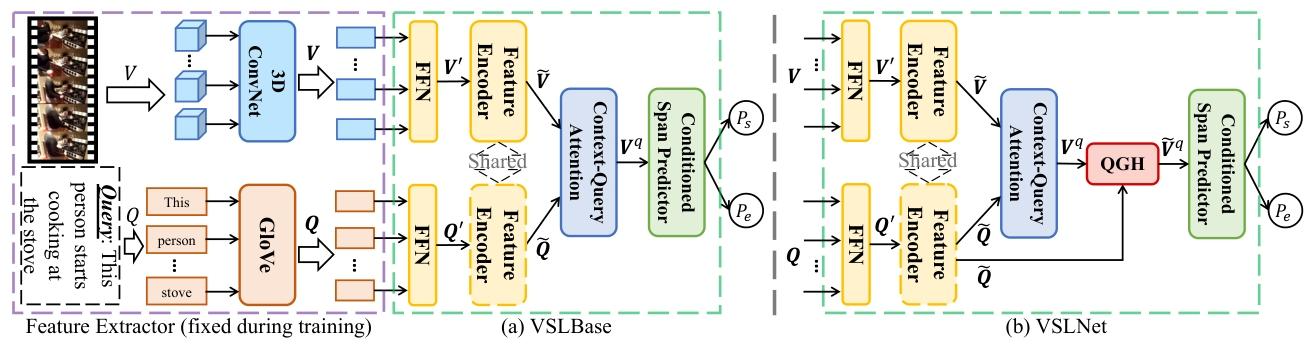
作为标准跨度 QA 框架在 NLVL 的适配版本,VSLBase 包含三大核心模块,实现 “视频 - 查询交互→边界预测” 的完整流程:
- 特征编码:将视频视觉特征(3D ConvNet 提取)与查询词嵌入(GloVe 初始化)投影到同一维度,通过共享参数的编码器(卷积 + 多头注意力)生成统一特征表示;
- 上下文 - 查询注意力(CQA):计算视频与查询特征的相似度,捕捉跨模态交互,生成 “查询感知的视频特征”,为后续边界预测提供语义关联依据;
- 条件跨度预测器:用两个堆叠的单向 LSTM(端边界依赖始边界)预测目标时刻的起止边界,通过交叉熵损失优化预测精度。
二、QGH(Query-Guided Highlighting,查询引导高亮)
1. 核心定义
QGH 是本文为解决 “传统跨度 QA 与 NLVL 的模态差异” 而提出的关键策略,核心思路是:基于文本查询的语义,在视频特征序列中 “高亮” 出可能包含目标时刻的区域(前景),引导模型仅在该区域内搜索目标时刻,从而适配视频与文本的本质差异。
2. 设计目的:解决两大模态差异
传统跨度 QA(文本)与 NLVL(视频 - 文本)存在两大核心差异,QGH 通过 “区域高亮” 针对性解决:
- 差异 1:连续性与因果性:视频是连续的(相邻帧变化小、事件存在因果邻接性),文本是非连续的(相邻词语义可能无关)——QGH 将目标时刻扩展为 “目标时刻 + 相邻上下文” 的前景区域,提供更多连续上下文信息,辅助定位;
- 差异 2:感知敏感度:人对视频帧的小偏移不敏感,但文本中 1-2 个词的差异会改变语义 ——QGH 缩小模型的搜索空间(从全视频到高亮区域),帮助模型聚焦视频帧的细微差异,提升边界预测精度。
Query-Guided Highlighting(QGH,查询引导高亮)详解
一、QGH 的设计目的
QGH 是 VSLNet 中为解决传统文本跨度 QA 与 NLVL 任务核心差异而提出的关键策略。这两类任务的核心差异(文档引言中提及)包括:
- 模态连续性差异:视频具有连续性(相邻帧变化小、事件存在因果邻接性),而文本具有非连续性(相邻词语义可能无关);
- 感知敏感度差异:人对视频帧的小偏移不敏感,但文本中 1-2 个词的差异会显著改变语义。QGH 通过 “高亮视频中与查询相关的区域”,针对性缓解上述差异,引导模型高效定位目标时刻。
二、QGH 的核心定义与前景扩展逻辑
1. 前景与背景划分
QGH 将视频特征序列划分为 “前景” 与 “背景”:
- 前景:与文本查询语义对齐的 “目标时刻” 及其相邻上下文(图 3 所示)。其中,目标时刻的真实起止边界为\(a^s\)(始)和\(a^e\)(端),长度为\(L = a^e - a^s\);
- 背景:视频中除前景外的其余区域(与查询语义无关的部分)。
2. 前景扩展机制
为覆盖目标时刻的关联上下文(适配视频连续性特点),QGH 通过超参数\(\alpha\) 控制前景扩展比例:将前景边界从\([a^s, a^e]\)扩展为\([a^s - \alpha L, a^e + \alpha L]\)。扩展后的前景既能提供目标时刻的额外关联信息,又能避免引入过多无关背景噪声(后续实验显示\(\alpha=0.05\sim0.2\)时性能最优)。
三、QGH 的实现流程(结合图 4 与公式)
QGH 本质是一个二分类模块:预测每个视频特征属于 “前景” 的置信度(高亮分数),并基于该分数优化视频特征表示。具体流程如下:
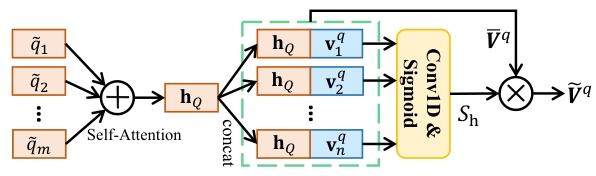
1. 步骤 1:生成查询的句子级表示\(h_Q\)
首先对编码后的查询特征\(\tilde{Q}\)(由 VSLBase 的特征编码器生成)进行处理:通过自注意力机制(Bahdanau et al., 2015)将查询的词级特征聚合为句子级表示\(h_Q\),捕捉查询的整体语义(如 “用工具逐个取下螺母” 的完整含义),为后续 “判断视频特征是否与查询相关” 提供依据。
2. 步骤 2:拼接查询语义与视频特征
将句子级表示\(h_Q\)与 “查询感知的视频特征\(V^q\)”(VSLBase 中上下文 - 查询注意力模块的输出)的每个特征向量拼接,得到新的特征序列\(\overline{V}^q\):\(\overline{V}^q = [\overline{v}_1^q, \overline{v}_2^q, ..., \overline{v}_n^q]\),其中\(\overline{v}_i^q = [v_i^q; h_Q]\)(\(v_i^q\)是\(V^q\)的第i个特征,分号表示向量拼接)。该操作让每个视频特征都融入查询的整体语义,为后续 “高亮与查询相关的视频区域” 奠定基础。
3. 步骤 3:计算高亮分数\(S_h\)
通过 1D 卷积层与 Sigmoid 激活函数,对\(\overline{V}^q\)进行处理,输出每个视频特征属于前景的置信度(高亮分数):\(S_h = \sigma\left(Conv1D\left(\overline{V}^q\right)\right)\)其中,\(\sigma\)表示 Sigmoid 激活函数(将输出映射到\([0,1]\)区间,1 表示 “完全属于前景”,0 表示 “完全属于背景”),\(S_h \in \mathbb{R}^n\)(n为视频特征总数,即\(S_h\)的每个元素对应一个视频特征的前景置信度)。
4. 步骤 4:生成高亮视频特征\(\tilde{V}^q\)
用高亮分数\(S_h\)对\(\overline{V}^q\)进行元素 - wise 加权,突出前景区域的特征重要性,抑制背景区域干扰:\(\tilde{V}^q = S_h \cdot \overline{V}^q \quad(6)\)该高亮特征\(\tilde{V}^q\)将替代 VSLBase 中的\(V^q\),用于后续条件跨度预测器的边界分数计算(即公式 3 中的\(v_t^q\)替换为\(\tilde{v}_t^q\))。
四、QGH 的损失函数与训练方式
1. QGH 的二分类损失\(\mathcal{L}_{QGH}\)
为优化 QGH 对前景 / 背景的分类精度,定义交叉熵损失(\(f_{CE}\)),衡量预测的高亮分数\(S_h\)与真实前景标签\(Y_h\)的差异:\(\mathcal{L}_{QGH}=f_{CE}\left(S_h, Y_h\right) \quad(7)\)其中,\(Y_h\)是视频特征的真实前景标签序列(0-1 序列):若第i个视频特征属于前景,\(Y_{h,i}=1\);否则\(Y_{h,i}=0\)。
2. VSLNet 的总损失与端到端训练
VSLNet 将 QGH 的损失与 VSLBase 的跨度预测损失(\(\mathcal{L}_{span}\))结合,形成总损失,通过端到端方式训练:\(\mathcal{L}=\mathcal{L}_{span }+\mathcal{L}_{QGH}\)这种联合训练确保 QGH 的 “高亮逻辑” 与后续 “边界预测逻辑” 协同优化,最终提升 NLVL 任务的定位精度。
编辑分享
QGH 并非单纯 “增大前景上下文”,而是基于查询语义,通过 “前景扩展 + 查询引导高亮 + 损失优化” 的组合逻辑,让模型聚焦与查询相关的视频区域,进而适配 NLVL 与文本 QA 的模态差异。
具体结合文档内容来看:
“增大前景上下文” 是 QGH 的手段之一:文档明确提到,QGH 将与查询对齐的目标时刻(原始前景)扩展,通过超参数 α 控制扩展比例,覆盖其 “前后文内容”(antecedent and consequent video contents),目的是适配视频的连续性特点(相邻帧变化小、事件有因果邻接性),这与你提到的 “增大前景的上下文” 一致,是解决 “视频 - 文本连续性差异” 的关键动作。
QGH 更核心的是 “查询引导的前景定位与特征增强”:文档指出,QGH 是 “基于查询语义的高亮策略”—— 首先通过自注意力将查询特征编码为句子级表示\(h_Q\)(捕捉查询整体语义),再将\(h_Q\)与视频特征拼接,通过 1D 卷积和 Sigmoid 生成 “高亮分数\(S_h\)”(预测每个视频特征属于前景的置信度),最终用\(S_h\)对视频特征加权,得到 “高亮特征\(\tilde{V}^q\)”。这一步的核心是让 “前景扩展” 的区域与查询语义强关联,避免无差别增大上下文(若仅增大上下文而无查询引导,可能引入无关背景噪声),对应解决 “视频 - 文本感知敏感度差异”(引导模型聚焦前景内的细微差异)。