[论文阅读] AI + 软件工程 | 从“事后补救”到“实时防控”,SemGuard重塑LLM代码生成质量
从“事后补救”到“实时防控”,SemGuard重塑LLM代码生成质量
论文信息
- 论文原标题:SemGuard: Real-Time Semantic Evaluator for Correcting LLM-Generated Code
- 论文链接:https://arxiv.org/pdf/2509.24507
- 发表情况: Accepted by the 40th IEEE/ACM Automated Software Engineering Conference (ASE 2025)
一段话总结
SemGuard是一种嵌入LLM解码器的语义评估驱动框架,通过实时行级语义监督纠正LLM生成代码中占比超60%的语义错误;研究者为训练其核心语义评估器,构建了首个含细粒度标注的SemDiff数据集(标记正确与错误代码的精确偏离行),该框架无需执行程序或依赖测试用例即可检测部分代码偏差、回滚错误行并引导重生成。实验表明,SemGuard在4个基准测试中表现优异:在SemDiff上较ROCODE降低19.86%语义错误率,在LiveCodeBench(CodeLlama-7B)上提升48.92% Pass@1,且具备跨模型(StarCoder2-7B、DeepSeekCoder-6.7B等)和跨语言(Python、Java) 通用性,同时较ROCODE减少31%生成token与60%耗时。
思维导图

研究背景
想象一下:你让LLM写一段“计算用户购物车总价”的代码,它生成的语法完全正确,但把“满100减20”写成了“满200减10”——这种**“语法对、逻辑错”的语义错误**,正是当前LLM代码生成的“老大难”。
据论文数据,这类语义错误占LLM生成代码错误的60%以上,比语法错误更隐蔽、更影响功能。但现有解决方案却像“马后炮”:比如SOTA方案ROCODE,要等代码完整生成后,再跑测试用例检测错误,不仅延迟高,还可能执行未验证代码带来安全风险;更麻烦的是,它靠“预测不确定性(熵值)”定位错误行,常常把正确代码也一起删掉,白白浪费计算资源。
就像批改作业,老师先让学生写完一整篇再检查,既耗时又难揪出“第一步错在哪”——SemGuard要做的,就是变成“实时监工”,在学生写每一行时就判断逻辑对不对,从源头减少错误。
创新点
- 首次实现“实时行级语义监督”:无需等代码写完,生成每行后立即评估语义正确性,把错误拦截在“萌芽阶段”,解决传统方案“事后补救”的痛点。
- 首个细粒度语义偏离数据集:SemDiff填补了“片段级语义评估训练数据”的空白,精准标记“哪一行开始出错”,让评估器能学懂“语义偏差的根源”。
- 低成本高通用:不依赖大模型或复杂测试环境,轻量评估器+简单惩罚机制,就能适配6种主流LLM、2种编程语言,落地门槛低。
- 精度与效率双优:在提升代码正确率的同时,比ROCODE少生成31%的token、节省60%时间,兼顾“好用”和“快用”。
研究方法和思路
论文的核心思路是“先造数据,再搭框架”,分两大步骤落地:
步骤1:构建SemDiff数据集(给评估器“喂料”)
要让模型学会“判断代码行是否语义正确”,首先得有标注清晰的数据。研究者从CodeNet(含1400万代码提交)中筛选出“长得像但逻辑不同”的代码对:
- 筛选条件:Jaccard相似度>0.9(确保只有语义差异,没有语法/风格干扰,比如“a=1”和“a=2”的差异);
- 标注方法:
- 若仅1行不同,直接标这行为“语义偏离行”;
- 若多行不同,用DeepSeek-V3 LLM定位“首个导致逻辑错误的行”(比如循环条件写错是首错行,后续计算错是连锁反应);
- 最终得到Python版123,522条、Java版107,816条标注数据。
步骤2:设计SemGuard框架(让纠错“实时跑起来”)
框架分“训练”和“推理”两阶段,像给LLM装了一个“语义刹车系统”:
- 训练阶段:用SemDiff数据训练轻量语义评估器(选DeepSeekCoder-1.3B,平衡精度和速度),任务是二分类——输入部分代码片段,输出“语义正确(1)”或“错误(0)”,用二元交叉熵(BCE)损失优化。
- 推理阶段:LLM生成代码时,每写完一行就触发评估器:
- 若评估器置信度>0.5(语义正确),继续生成下一行;
- 若置信度≤0.5(语义错误),回滚到错误行,对该行首个非缩进token施加0.8倍惩罚(降低重复生成错误的概率),最多重试3次,选置信度最高的版本继续。
主要成果和贡献
核心成果(用数据说话)
| 研究问题 | 对比对象 | 关键结论 |
|---|---|---|
| 性能对比 | ROCODE(SOTA) | SemDiff测试集上,DeepSeekCoder-6.7B的Pass@1达38.06%,超ROCODE 2.23个百分点,语义错误率降19.86% |
| 跨模型适配 | 6个LLM(3B-7B) | 7B模型提升最显著,DeepSeekCoder-6.7B较基础版+25.69% Pass@1 |
| 跨语言能力 | Java(SemDiff-Java) | 无需调优,DeepSeekCoder-6.7B Pass@1从33.58%升至42.53%(+25.09%) |
| 效率对比 | ROCODE | 生成token数少31%,耗时少60%,成本降低近半 |
实际价值
- 开发者提效:减少人工排查语义bug的时间,尤其适合快速迭代的项目;
- 企业降本:轻量框架+低资源消耗,无需为纠错部署大模型集群;
- 生态完善:开源的SemDiff数据集(假设地址)为语义纠错研究提供基础数据。
3. 详细总结
1. 研究背景与核心问题
- LLM生成代码的关键缺陷:语义错误占比超60%(基于DeepSeek-Coder-6.7B、QwenCoder-7B在MBPP和LiveCodeBench的实验数据),此类错误可正常编译但功能偏离需求,现有工具(编译器、静态分析、单元测试)因缺乏语义感知难以检测。
- 现有SOTA方案(ROCODE)的两大不足:
- 后生成语义检测:需生成完整程序并执行测试用例后验证语义正确性,导致错误识别延迟,且执行未验证代码存在安全风险。
- 回溯点定位不准:依赖熵启发式(反映预测不确定性)定位错误源,而非语义偏差的因果关系,易丢弃大量正确代码,增加计算开销。
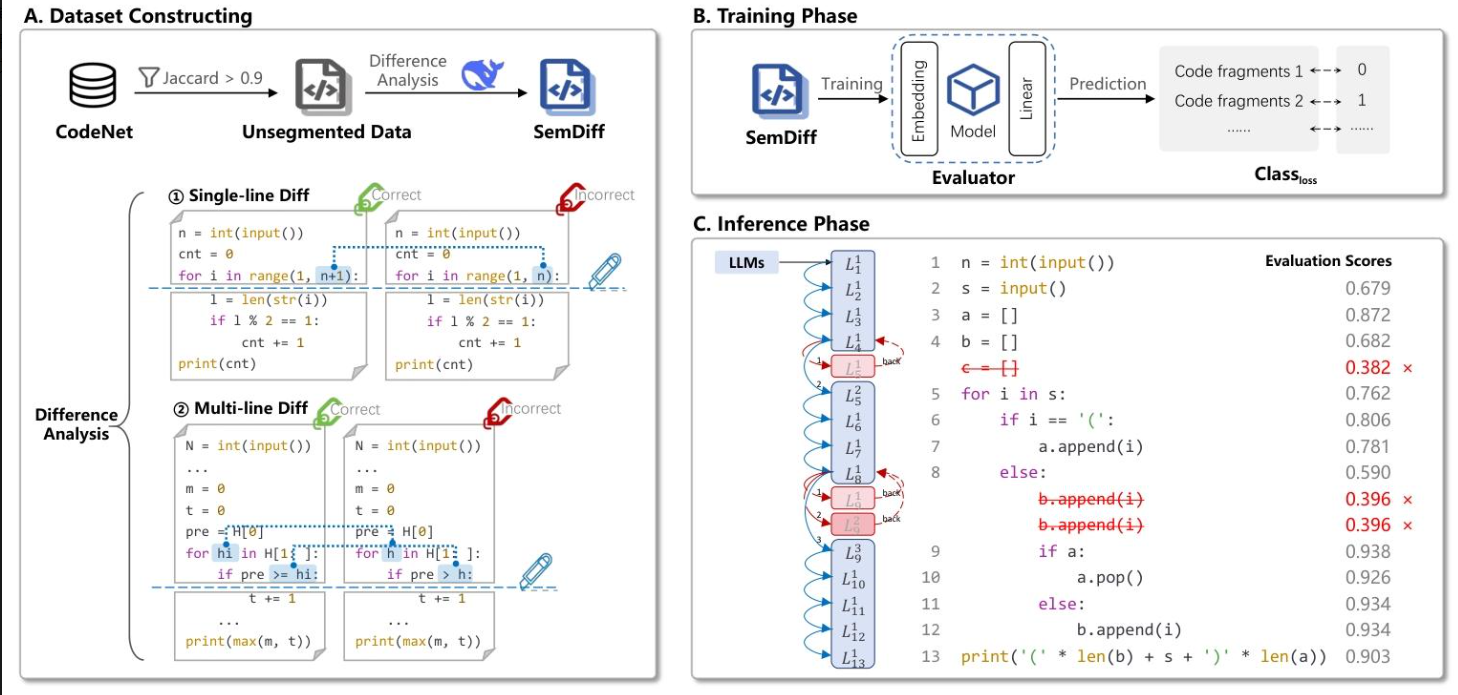
2. 核心方案:SemDiff数据集与SemGuard框架
2.1 SemDiff数据集(首个细粒度语义偏离标注数据集)
- 构建目标:为片段级语义评估器提供训练数据,标记正确与错误代码的精确语义偏离行。
- 构建流程:
- 数据来源:从CodeNet(含1400万代码提交、50+编程语言)筛选样本。
- 样本筛选:保留“正确代码-语义错误代码”对,要求Jaccard相似度>0.9(确保代码差异最小,聚焦语义偏差而非语法/风格差异)。
- 标注方法:
- 单行文差异(差异行数|D|=1):直接标记差异行为语义偏离行。
- 多行文差异(|D|>1):借助DeepSeek-V3 LLM,通过引导提示(见表1)定位首个语义偏离行,提升标注精度。
- 数据规模(表1):
数据集版本 任务数 训练样本数 验证样本数 测试样本数 总计 SemDiff(Python) 998 114,098 5,784 3,640 123,522 SemDiff-Java - 99,882 4,262 3,672 107,816
2.2 SemGuard框架(语义评估驱动的实时纠错系统)
- 核心目标:在LLM解码过程中嵌入语义评估,实现实时行级语义监督,无需执行程序或依赖测试用例。
- 三阶段架构:
- 数据集构建:生成SemDiff的行级语义偏离对。
- 评估器训练:
- 基础模型:选择轻量LLM(如DeepSeekCoder-1.3B),平衡精度与 latency。
- 任务类型:二分类(判断输入的部分代码片段语义正确/错误)。
- 损失函数:二元交叉熵(BCE),公式为L=−1k∑i=1k(yilogpi+(1−yi)log(1−pi))\mathcal{L}=-\frac{1}{k} \sum_{i=1}^{k}\left(y_{i} log p_{i}+\left(1-y_{i}\right) log \left(1-p_{i}\right)\right)L=−k1∑i=1k(yilogpi+(1−yi)log(1−pi))(yiy_iyi为标签,pip_ipi为预测概率)。
- 推理阶段:
- 实时监测:LLM生成代码时,每行生成后将当前前缀输入评估器,获取置信度sts_tst(st>0.5s_t>0.5st>0.5接受,否则判定为语义偏差)。
- 错误处理:回滚至错误行,对首行非缩进token施加惩罚(λ=0.8),最多采样3次,选择置信度最高的版本继续生成,避免重复错误。
3. 实验设计
3.1 研究问题(RQ1-RQ6)
- RQ1:SemGuard与基线方法的性能对比。
- RQ2:SemGuard在不同LLM上的适配性。
- RQ3:SemGuard在未见过基准数据集上的可迁移性。
- RQ4:SemGuard在Java语言上的跨语言性能。
- RQ5:SemGuard各组件(评估器能力、回溯策略)的贡献。
- RQ6:SemGuard的成本与效率。
3.2 实验对象
- 数据集:SemDiff(Python)、SemDiff-Java、MBPP(500测试任务)、LiveCodeBench(2024.7-2025.4任务,避免数据污染)。
- 基础LLM:6个开源模型,覆盖不同规模与家族:
- DeepSeekCoder(1.3B、6.7B)
- QwenCoder(3B、7B)
- StarCoder2(3B、7B)
- CodeLlama-7B
- 基线方法:
- Temperature Sampling(T=0.8,控制随机性)。
- Sampling + Filtering(生成多样本后筛选通过测试的代码)。
- ROCODE(现有SOTA,基于程序分析与迭代回溯)。
3.3 实验设置
- 生成模型:所有模型采用LoRA微调(r=8,α=32,dropout=0.1),5个epoch,学习率2e-5,确保基线稳定。
- 评估器模型:CodeT5-770M(小模型)、DeepSeekCoder-1.3B(大模型),15个epoch,学习率6e-5,批大小50。
- 评估指标:Pass@1(单轮生成正确率),每个实验运行3次取平均,确保结果可靠。
4. 实验结果与分析
4.1 RQ1:与基线方法对比(SemDiff测试集)
| 方法 | DeepSeekCoder-6.7B Pass@1 | QwenCoder-7B Pass@1 |
|---|---|---|
| Temperature Sampling | 30.28% | 30.83% |
| Sampling + Filtering | 33.33% | 34.17% |
| ROCODE | 35.83% | 37.50% |
| SemGuard-Random | 33.33% | 34.16% |
| SemGuard-Penalty | 38.06% | 38.34% |
- 结论:SemGuard-Penalty性能最优,较ROCODE降低19.86%语义错误率,且无需执行程序/测试用例。
4.2 RQ2:跨模型性能(SemDiff测试集)
| 模型 | Temperature Sampling | ROCODE | SemGuard-Random | SemGuard-Penalty | 相对提升(vs Temp.) |
|---|---|---|---|---|---|
| DeepSeekCoder-6.7B | 30.28% | 35.83% | 33.33% | 38.06% | +25.69% |
| QwenCoder-3B | 22.22% | 23.33% | 23.34% | 26.11% | +17.51% |
| QwenCoder-7B | 30.83% | 37.50% | 34.16% | 38.34% | +24.36% |
| StarCoder2-3B | 16.11% | 18.33% | 17.50% | 19.44% | +20.67% |
| StarCoder2-7B | 21.11% | 23.05% | 22.78% | 25.83% | +22.36% |
| CodeLlama-7B | 15.28% | 17.77% | 15.78% | 18.05% | +18.13% |
- 结论:7B模型提升更显著,说明评估器精度与基础模型能力越强,SemGuard效果越好。
4.3 RQ3:可迁移性(MBPP、LiveCodeBench)
- MBPP(简单任务):SemGuard-Penalty在所有模型上优于基线,StarCoder2-7B的Pass@1从44.27%(Temp.)升至49.20%,提升约5个百分点。
- LiveCodeBench(复杂任务):
- DeepSeekCoder-6.7B的Pass@1从7.68%(Temp.)升至10.04%(+30.7%)。
- CodeLlama-7B上ROCODE略优(8.73% vs 8.28%),但SemGuard-Penalty在3/4模型上仍为最优,验证复杂场景下的可靠性。
4.4 RQ4:跨语言性能(SemDiff-Java)
| 模型 | Temperature Sampling | SemGuard-Random | SemGuard-Penalty | 相对提升(vs Temp.) |
|---|---|---|---|---|
| DeepSeekCoder-6.7B | 33.58% | 36.32% | 42.53% | +25.09% |
| QwenCoder-7B | 33.94% | 37.39% | 40.94% | +20.63% |
| StarCoder2-7B | 30.30% | 31.71% | 34.90% | +15.18% |
| CodeLlama-7B | 22.08% | 23.95% | 26.43% | +19.70% |
- 结论:无需语言特定调优,SemGuard在Java上仍有效,验证跨语言通用性。
4.5 RQ5:消融实验(DeepSeekCoder-6.7B,SemDiff)
| 评估器 | 回溯策略 | Pass@1 | 关键结论 |
|---|---|---|---|
| CodeT5-770M | SemGuard-Random | 27.50% | 小模型评估器能力不足 |
| CodeT5-770M | SemGuard-Penalty | 28.33% | 惩罚策略有一定提升 |
| CodeT5-770M | Full-Restart Backtracking | 32.97% | 全重启浪费正确代码 |
| CodeT5-770M | Exponentially-Decaying Penalty | 35.00% | 粗粒度惩罚效果有限 |
| DeepSeek-1.3B | SemGuard-Random | 33.33% | 评估器精度是核心 |
| DeepSeek-1.3B | SemGuard-Penalty | 38.06% | 高精度评估器+行级惩罚最优 |
- 结论:评估器能力决定基础性能,行级token惩罚进一步放大优势。
4.6 RQ6:成本与效率(DeepSeekCoder-6.7B,SemDiff)
| 方法 | Pass@1 | 生成token数 | 耗时(s) | 关键优势 |
|---|---|---|---|---|
| Temperature Sampling | 30.28% | 110.4 | 6.12 | 成本最低,但精度差 |
| Sampling + Filtering | 33.33% | 230.6 | 8.38 | 精度提升有限,成本高 |
| ROCODE | 35.83% | 253.8 | 32.50 | 精度中等,耗时最长 |
| SemGuard-Random | 33.33% | 172.6 | 13.44 | 成本低于ROCODE,精度待提升 |
| SemGuard-Penalty | 38.06% | 175.6 | 12.98 | 精度最高,较ROCODE少31% tokens、快60% |
- 结论:SemGuard实现精度与成本的最优平衡,适合实际落地。
5. 研究局限与未来工作
- 局限:
- 非局部逻辑处理弱:难以检测跨函数、跨文件的语义偏差。
- 上下文敏感性:长提示时语义信号稀释,短片段时上下文不足。
- 假阳性问题:虽FPR≤0.40(低于ROCODE的>0.50),但仍存在不必要的回滚。
- 未来工作:
- 扩展至多文件/框架场景,支持复杂项目开发。
- 探索生成器与评估器的联合训练,降低假阳性与推理延迟。
6. 核心贡献
- 技术创新:提出SemGuard框架,首次实现LLM解码过程中的实时行级语义监督,无需执行程序/测试用例。
- 数据支撑:构建SemDiff数据集,为片段级语义评估器提供首个细粒度标注数据,开源供研究使用。
- 通用性验证:在4个基准、6个LLM、2种语言上验证有效性,证明跨模型、跨语言的广泛适配性。
4. 关键问题
问题1(侧重“技术创新与痛点解决”):SemGuard相比现有SOTA方案(如ROCODE),在技术路径上有哪些核心突破,如何针对性解决了现有方案的关键痛点?
答案:SemGuard的核心突破在于**“实时语义介入”与“精准语义定位”** 的技术路径,针对性解决ROCODE的两大关键痛点:1. 解决ROCODE“后生成检测”的延迟与安全痛点:SemGuard将轻量语义评估器嵌入LLM解码器,每行代码生成后立即检测语义偏差,无需等待完整程序生成与测试执行,避免错误传播与未验证代码执行的安全风险;2. 解决ROCODE“回溯点不准”的效率痛点:ROCODE依赖反映预测不确定性的“熵值”定位错误,而SemGuard基于SemDiff数据集训练的评估器可精准识别“首个语义偏离行”,减少正确代码丢弃;此外,SemGuard引入token惩罚机制(λ=0.8,最多3次采样),避免重复生成相同错误,进一步提升重生成效率。实验数据显示,SemGuard较ROCODE降低19.86%语义错误率,同时减少31%生成token与60%耗时,实现“精度-效率”双提升。
问题2(侧重“数据集设计与价值”):SemDiff数据集的构建为何强调“细粒度语义偏离标注”与“最小差异代码对”,这两个设计特点对SemGuard评估器的训练有何关键作用?
答案:SemDiff的两大设计特点是为解决“片段级语义评估器训练”的核心难点,作用如下:1. “最小差异代码对”(Jaccard相似度>0.9)的设计价值:筛选出仅存在语义偏差、语法/风格高度一致的代码对,排除无关差异(如变量名、缩进)对评估器的干扰,确保评估器学习的是“语义正确性”而非表面特征;2. “细粒度语义偏离标注”的设计价值:精确标记“首个语义偏离行”,使数据集可拆分为“正确前缀-错误前缀-偏离行”的片段结构,直接满足评估器“判断部分代码是否语义正确”的训练需求——若标注粒度粗(如仅标记错误代码整体),评估器无法学习“哪一行开始出现语义偏差”,也就无法支撑SemGuard的实时行级监督。正是这两个设计,使SemGuard的评估器能在缺乏完整程序上下文的情况下,精准判断部分代码的语义正确性,为实时介入提供核心能力。
问题3(侧重“实际落地价值”):SemGuard在跨模型、跨语言场景下的性能表现如何,这些特性对其在工业界的实际落地有何重要意义?
答案:SemGuard在跨模型、跨语言场景下表现出优异的通用性,关键数据与落地意义如下:1. 跨模型表现:在6个不同规模(3B-7B)、不同家族的LLM上均有效,7B模型提升更显著(如DeepSeekCoder-6.7B Pass@1提升25.69%,QwenCoder-7B提升24.36%),说明其不依赖特定模型架构,可适配企业现有LLM技术栈,降低落地时的模型选型限制;2. 跨语言表现:在Java的SemDiff-Java数据集上,DeepSeekCoder-6.7B的Pass@1从33.58%升至42.53%(+25.09%),且无需语言特定调优,可覆盖Python(数据科学)、Java(企业级开发)等主流开发场景,满足多语言项目需求;3. 落地意义:工业界开发场景中,企业常使用不同模型(如小模型用于快速生成、大模型用于复杂任务)、涉及多语言开发,SemGuard的跨模型/跨语言特性使其可无缝集成至现有工作流,同时其低成本(较ROCODE少31% tokens、60%耗时)与高精度(LiveCodeBench上Pass@1提升48.92%)的优势,能在提升代码质量的同时降低开发成本,具备极高的实际应用价值。
总结
SemGuard通过“数据+框架”双创新,解决了LLM代码生成中语义错误难实时纠错的核心问题。其构建的SemDiff数据集填补了细粒度语义标注的空白,而实时行级监督框架则实现了“精度-效率-通用性”的平衡。虽然目前对跨文件逻辑错误处理较弱,但已为LLM代码生成的“可控性”提供了新范式,未来联合训练生成器与评估器后,有望进一步提升纠错能力,推动AI辅助编程向“更高质量、更低成本”迈进。