CompletableFuture原理与实践----商品信息查询接口优化---信息组装
0 背景
随着针对商品信息描述的增加,商品信息页面的查询也越来越臃肿,导致界面查询时间耗费极大。作为商品展示的重要信息来源,所有对商品的查询均会流入商品中心。商品中心会调度各种对商品中心提供的功能接口,并且对各个下游服务获取数据进行聚合,具有鲜明的I/O密集型特点。在当前访问量大的情况下,使用同步加载方式的弊端逐渐显现,因此我们开始考虑将同步加载改为并行加载的可行性。
1 为何需要并行加载
商品信息查询业务典型的I/O密集型(I/O Bound)服务。
- 服务端必须一次返回商品卡片所有内容,服务端必须一次性返回商品的所有信息,包含商品主信息、价格、店铺、单位、采购价格、渠道价格、单位转换比、图片等要从十多个表中获取数据。
- 查询页面并无缓存,多个用户查询可导致前端和数据库的频繁交互。
为了保证用户体验,保证接口的高性能,并行从获取数据就成为必然。
2 并行加载的实现方式
并行从下游获取数据,从IO模型上来讲分为同步模型和异步模型。
2.1 同步模型
从各个服务获取数据最常见的是同步调用,如下图所示:
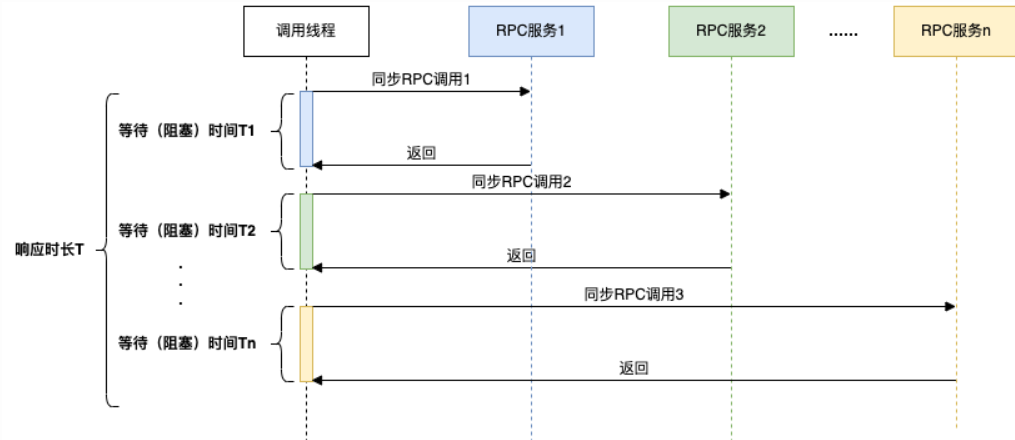
在同步调用的场景下,接口耗时长、性能差,接口响应时长T > T1+T2+T3+……+Tn,这时为了缩短接口的响应时间,一般会使用线程池的方式并行获取数据,商品信息的组装正是使用了这种方式。
这种方式由于以下两个原因,导致资源利用率比较低:
- CPU资源大量浪费在阻塞等待上,导致CPU资源利用率低。在Java 8之前,一般会通过回调的方式来减少阻塞,但是大量使用回调,又引发臭名昭著的回调地狱问题,导致代码可读性和可维护性大大降低。
同步执行为什么会有上下文切换?
在阻塞期间,CPU资源会被争抢:由于大量线程处于 “阻塞→就绪→运行” 的频繁切换中(比如线程等待 I/O 完成后从阻塞态唤醒,抢占 CPU 时间片),上下文切换的频率会显著升高 —— 而每次上下文切换都需要消耗 CPU 资源(保存 / 恢复线程状态、更新内核调度数据结构等),最终导致宝贵的 CPU 资源被浪费在 “切换” 上,而非 “实际业务计算”(如数据聚合)。
当线程数量超过 CPU 核心数时,操作系统会采用时间片轮转调度算法(每个线程分配一个 “时间片”,比如 10ms):
- 当线程 A 的时间片用完,或线程 A 因 I/O 阻塞主动放弃 CPU 时,操作系统会暂停线程 A,将其状态从 “运行态” 转为 “就绪态”(或阻塞态);
- 同时,从 “就绪态” 线程中选择线程 B,恢复其之前的执行状态(如寄存器值、程序计数器位置等),让其进入 “运行态” 占用 CPU。
这个 “暂停线程 A→保存线程 A 状态→恢复线程 B 状态→执行线程 B” 的过程,就是上下文切换。
回调—用方发起请求后,不原地等待结果,而是直接返回去执行其他任务(比如处理下一个请求、计算其他数据),彻底摆脱 “阻塞等待”。
回调地狱—当业务逻辑需要多个依赖(比如 “获取订单→获取商品→获取配送信息”,后一步依赖前一步的结果)时,回调会嵌套多层,导致代码可读性、可维护性急剧下降 —— 这就是前文提到的 “回调地狱”
- 为了增加并发度,会引入更多额外的线程池,随着CPU调度线程数的增加,会导致更严重的资源争用,宝贵的CPU资源被损耗在上下文切换上,而且线程本身也会占用系统资源,且不能无限增加。
通过引入CompletableFuture(下文简称CF)对业务流程进行编排,降低依赖之间的阻塞。本文主要讲述CompletableFuture的使用和原理。这也是为什么后来会出现CompletableFuture—— 它通过thenApply/thenCompose等方法,将嵌套的回调 “平铺化”,解决了回调地狱问题
2.2 为什么会选择CompletableFuture?
| Future | CompletableFuture | RxJava | Reactor | |
|---|---|---|---|---|
| Composable(可组合) | ❌ | ✔️ | ✔️ | ✔️ |
| Asynchronous(异步) | ✔️ | ✔️ | ✔️ | ✔️ |
| Operator fusion(操作融合) | ❌ | ❌ | ✔️ | ✔️ |
| Lazy(延迟执行) | ❌ | ❌ | ✔️ | ✔️ |
| Backpressure(回压) | ❌ | ❌ | ✔️ | ✔️ |
- 可组合:可以将多个依赖操作通过不同的方式进行编排,例如CompletableFuture提供thenCompose、thenCombine等各种then开头的方法,这些方法就是对“可组合”特性的支持。
- 操作融合:将数据流中使用的多个操作符以某种方式结合起来,进而降低开销(时间、内存)。
- 延迟执行:操作不会立即执行,当收到明确指示时操作才会触发。例如Reactor只有当有订阅者订阅时,才会触发操作。
- 回压:某些异步阶段的处理速度跟不上,直接失败会导致大量数据的丢失,对业务来说是不能接受的,这时需要反馈上游生产者降低调用量。
RxJava与Reactor显然更加强大,它们提供了更多的函数调用方式,支持更多特性,但同时也带来了更大的学习成本。而本次整合最需要的特性就是“异步”、“可组合”,综合考虑后,选择了学习成本相对较低的CompletableFuture。
3 CompletableFuture使用与原理
CompletableFuture的实现如下:
ExecutorService executor = Executors.newFixedThreadPool(5);
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println("执行step 1");return "step1 result";
}, executor);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {System.out.println("执行step 2");return "step2 result";
});
cf1.thenCombine(cf2, (result1, result2) -> {System.out.println(result1 + " , " + result2);System.out.println("执行step 3");return "step3 result";
}).thenAccept(result3 -> System.out.println(result3));
3.1 CompletableFuture的使用
一个CompletableFuture的完成会触发另外一系列依赖它的CompletableFuture的执行:
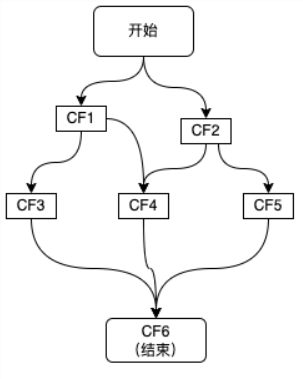
如上图所示,这里描绘的是一个业务接口的流程,其中包括CF1\CF2\CF3\CF4\CF5共5个步骤,并描绘了这些步骤之间的依赖关系,每个步骤可以是一次RPC调用、一次数据库操作或者是一次本地方法调用等,在使用CompletableFuture进行异步化编程时,图中的每个步骤都会产生一个CompletableFuture对象,最终结果也会用一个CompletableFuture来进行表示。
根据CompletableFuture依赖数量,可以分为以下几类:零依赖、一元依赖、二元依赖和多元依赖。
3.1.1 零依赖:CompletableFuture的创建
我们先看下如何不依赖其他CompletableFuture来创建新的CompletableFuture:
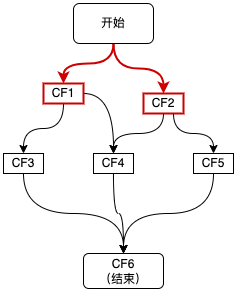
图6 零依赖
如上图红色链路所示,接口接收到请求后,首先发起两个异步调用CF1、CF2,主要有三种方式:
ExecutorService executor = Executors.newFixedThreadPool(5);
//1、使用runAsync或supplyAsync发起异步调用
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {return "result1";
}, executor);
//2、CompletableFuture.completedFuture()直接创建一个已完成状态的CompletableFuture
CompletableFuture<String> cf2 = CompletableFuture.completedFuture("result2");
//3、先初始化一个未完成的CompletableFuture,然后通过complete()、completeExceptionally(),完成该CompletableFuture
CompletableFuture<String> cf = new CompletableFuture<>();
cf.complete("success");
3.1.2 一元依赖:依赖一个CF
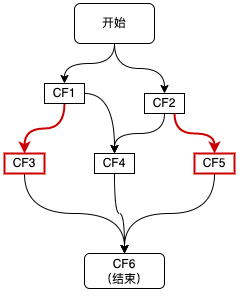
图7 一元依赖
如上图红色链路所示,CF3,CF5分别依赖于CF1和CF2,这种对于单个CompletableFuture的依赖可以通过thenApply、thenAccept、thenCompose等方法来实现,代码如下所示:
CompletableFuture<String> cf3 = cf1.thenApply(result1 -> {//result1为CF1的结果//......return "result3";
});
CompletableFuture<String> cf5 = cf2.thenApply(result2 -> {//result2为CF2的结果//......return "result5";
});
3.1.3 二元依赖:依赖两个CF
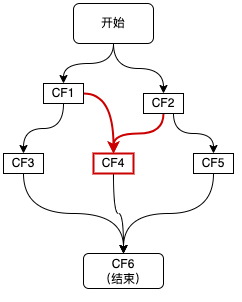
图8 二元依赖
如上图红色链路所示,CF4同时依赖于两个CF1和CF2,这种二元依赖可以通过thenCombine等回调来实现,如下代码所示:
CompletableFuture<String> cf4 = cf1.thenCombine(cf2, (result1, result2) -> {//result1和result2分别为cf1和cf2的结果return "result4";
});
3.1.4 多元依赖:依赖多个CF
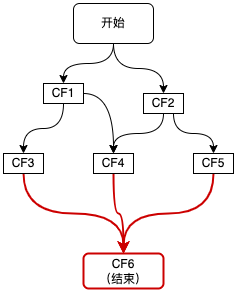
图9 多元依赖
如上图红色链路所示,整个流程的结束依赖于三个步骤CF3、CF4、CF5,这种多元依赖可以通过allOf或anyOf方法来实现,区别是当需要多个依赖全部完成时使用allOf,当多个依赖中的任意一个完成即可时使用anyOf,如下代码所示:
CompletableFuture<Void> cf6 = CompletableFuture.allOf(cf3, cf4, cf5);
CompletableFuture<String> result = cf6.thenApply(v -> {//这里的join并不会阻塞,因为传给thenApply的函数是在CF3、CF4、CF5全部完成时,才会执行 。result3 = cf3.join();result4 = cf4.join();result5 = cf5.join();//根据result3、result4、result5组装最终result;return "result";
});
3.2 CompletableFuture原理
CompletableFuture中包含两个字段:result和stack。result用于存储当前CF的结果,stack(Completion)表示当前CF完成后需要触发的依赖动作(Dependency Actions),去触发依赖它的CF的计算,依赖动作可以有多个(表示有多个依赖它的CF),以栈(Treiber stack)的形式存储,stack表示栈顶元素。
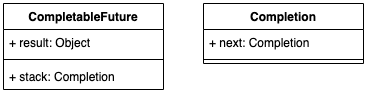
图10 CF基本结构