IEEE论文爬取(关键字搜索)

书接上回,在上篇文章中:
IEEE关键字搜索结果爬取![]() https://mp.csdn.net/mp_blog/creation/editor/152328482 通过抓包分析,我们获取到了关键字搜索结果中论文的题目以及Adobe PDF阅读器链接。那么本文我们就在此基础上,针对获取到的链接内的PDF内容进行爬取。
https://mp.csdn.net/mp_blog/creation/editor/152328482 通过抓包分析,我们获取到了关键字搜索结果中论文的题目以及Adobe PDF阅读器链接。那么本文我们就在此基础上,针对获取到的链接内的PDF内容进行爬取。
抓包分析
首先运行上篇文章中的完整代码,得到指定关键字查询结果的一些论文标题与下载链接:
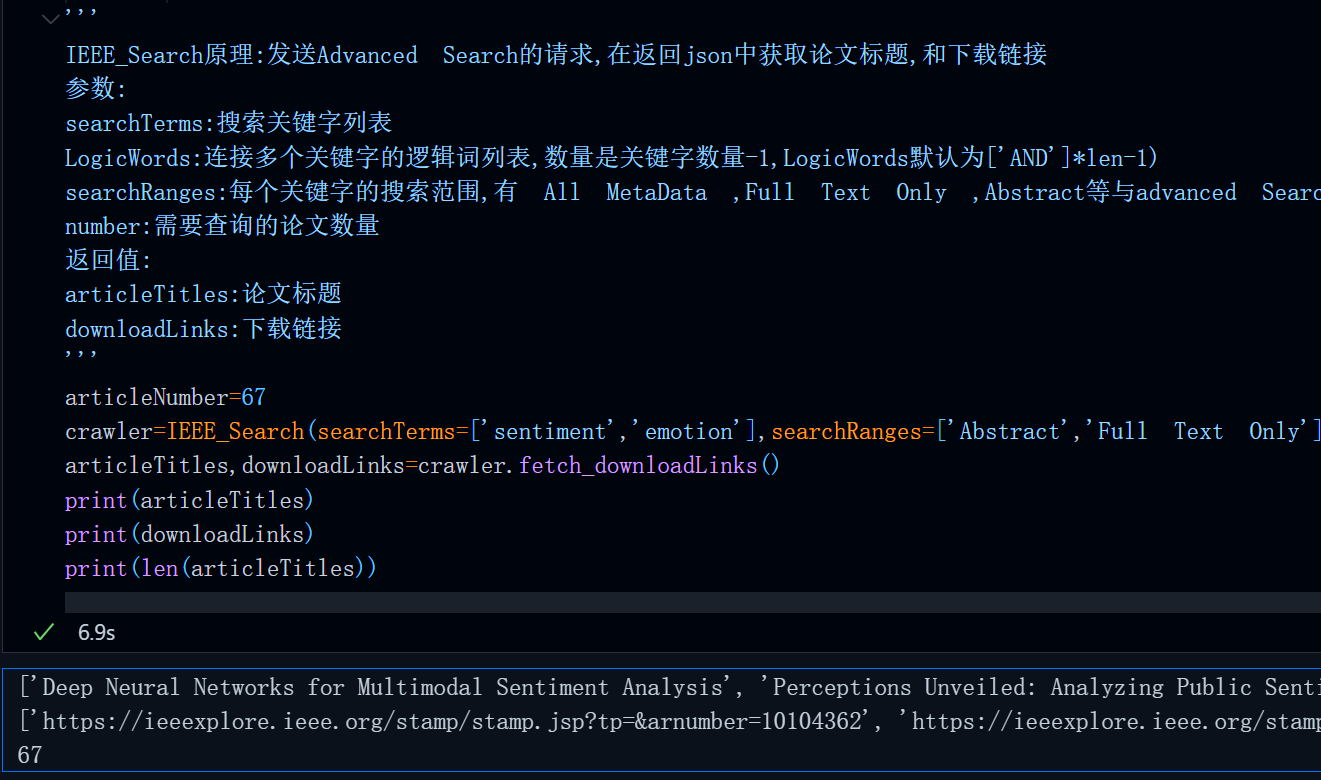
复制任意一个链接,在浏览器中打开:
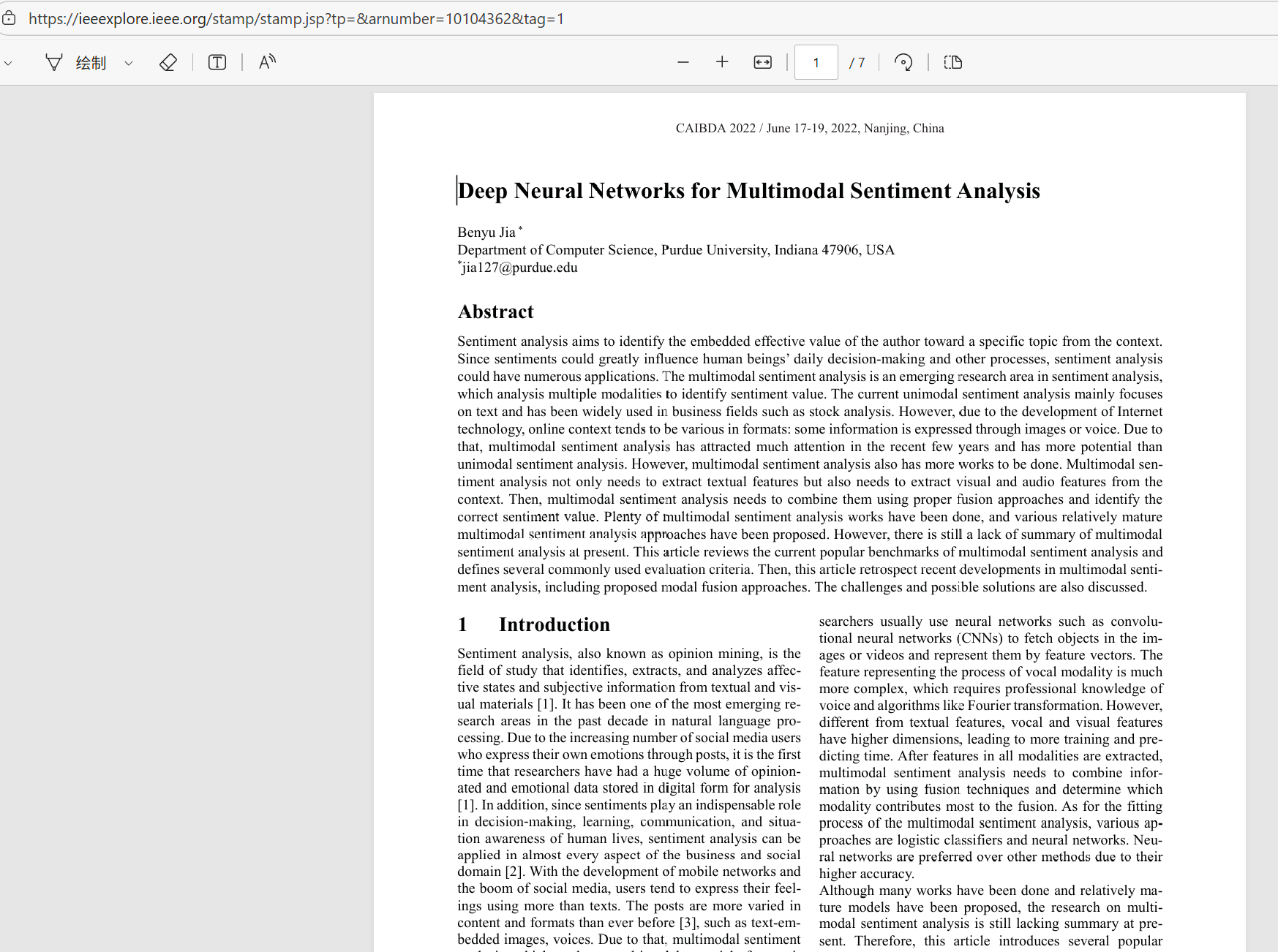
明显这是一个Adobe PDF阅读器界面,这样的阅读器界面中必然会有一个