【完整源码+数据集+部署教程】鹿角图像分割系统: yolov8-seg-C2f-DCNV2-Dynamic
背景意义
研究背景与意义
随着计算机视觉技术的快速发展,图像分割在各个领域中的应用日益广泛,尤其是在生物学和生态学研究中,图像分割技术为物种识别、行为分析和环境监测提供了重要的支持。鹿角作为鹿类动物的重要特征,不仅在生态学研究中具有重要的生物学意义,同时也是动物行为学、遗传学及保护生物学等领域研究的关键对象。准确地识别和分割鹿角图像,对于研究鹿类的生长发育、种群动态以及生态环境变化等方面具有重要的现实意义。
本研究旨在基于改进的YOLOv8模型,构建一个高效的鹿角图像分割系统。YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而受到广泛关注,尤其是YOLOv8在处理复杂场景和小目标检测方面表现出色。然而,传统的YOLO模型在实例分割任务中仍存在一定的局限性,尤其是在细粒度特征提取和边界精确度方面。因此,针对鹿角图像的特性,对YOLOv8进行改进,以提高其在实例分割任务中的表现,具有重要的理论和实践价值。
本研究所使用的数据集包含1400张图像,涵盖24个类别,涉及不同类型的鹿角。这一数据集的丰富性为模型的训练和验证提供了坚实的基础。通过对这些图像进行实例分割,可以有效地提取出鹿角的形状、大小及其与背景的关系,为后续的分析提供数据支持。此外,数据集中包含的多样化类别使得模型能够学习到不同鹿角的特征,从而提高其在实际应用中的泛化能力。
在生态保护和生物多样性维护的背景下,鹿类作为重要的生态指示物种,其生存状态直接反映了生态系统的健康状况。通过精确的鹿角图像分割,可以为生态学家提供更为详实的数据支持,帮助他们更好地理解鹿类的生长规律、繁殖行为及其与环境的相互作用。这不仅有助于科学研究的深入开展,也为制定有效的保护措施提供了重要依据。
综上所述,基于改进YOLOv8的鹿角图像分割系统的研究,不仅具有重要的学术价值,也为生态保护和生物多样性研究提供了新的技术手段。通过提高鹿角图像分割的准确性和效率,本研究将为相关领域的研究者提供更加可靠的数据支持,推动鹿类生态学及相关研究的进一步发展。
图片效果
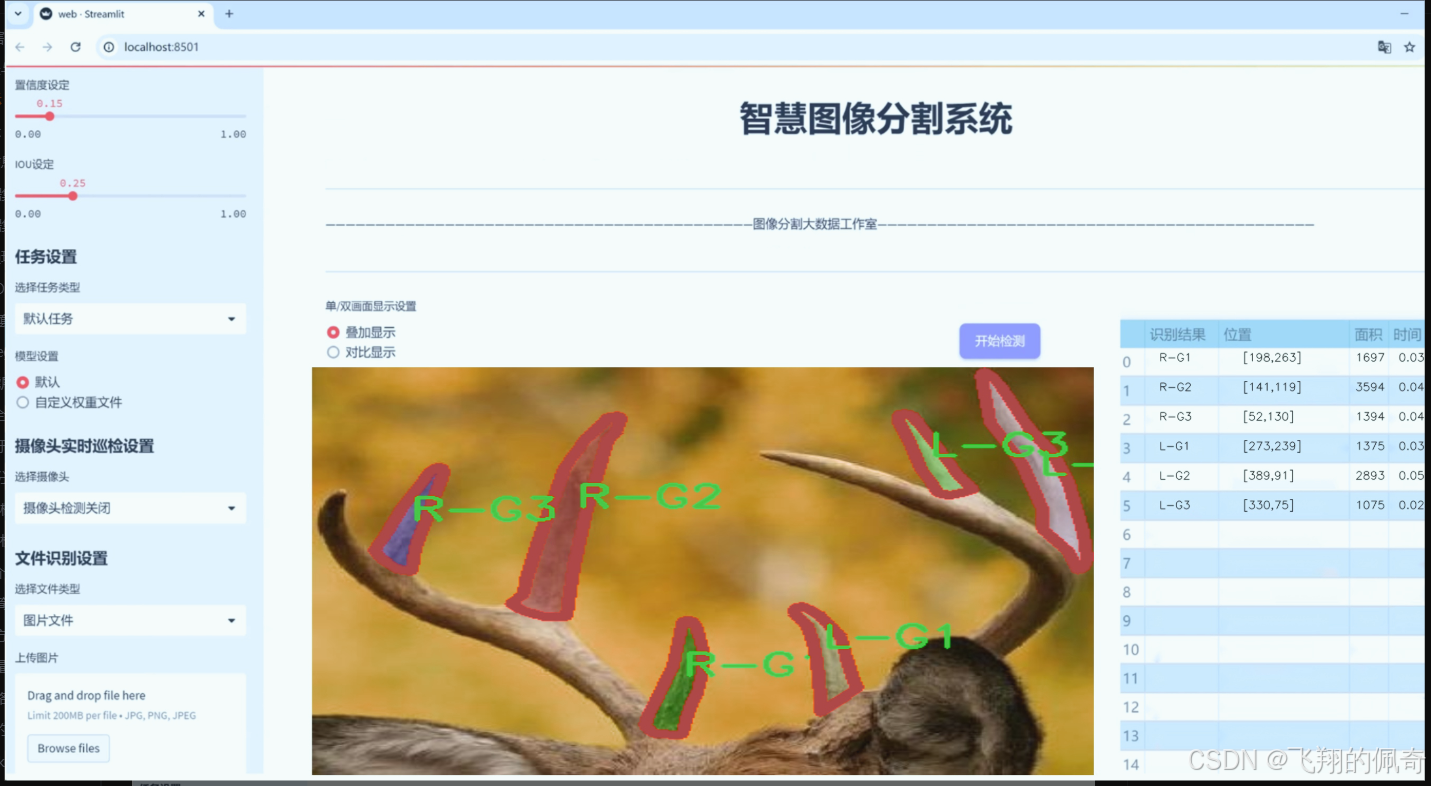
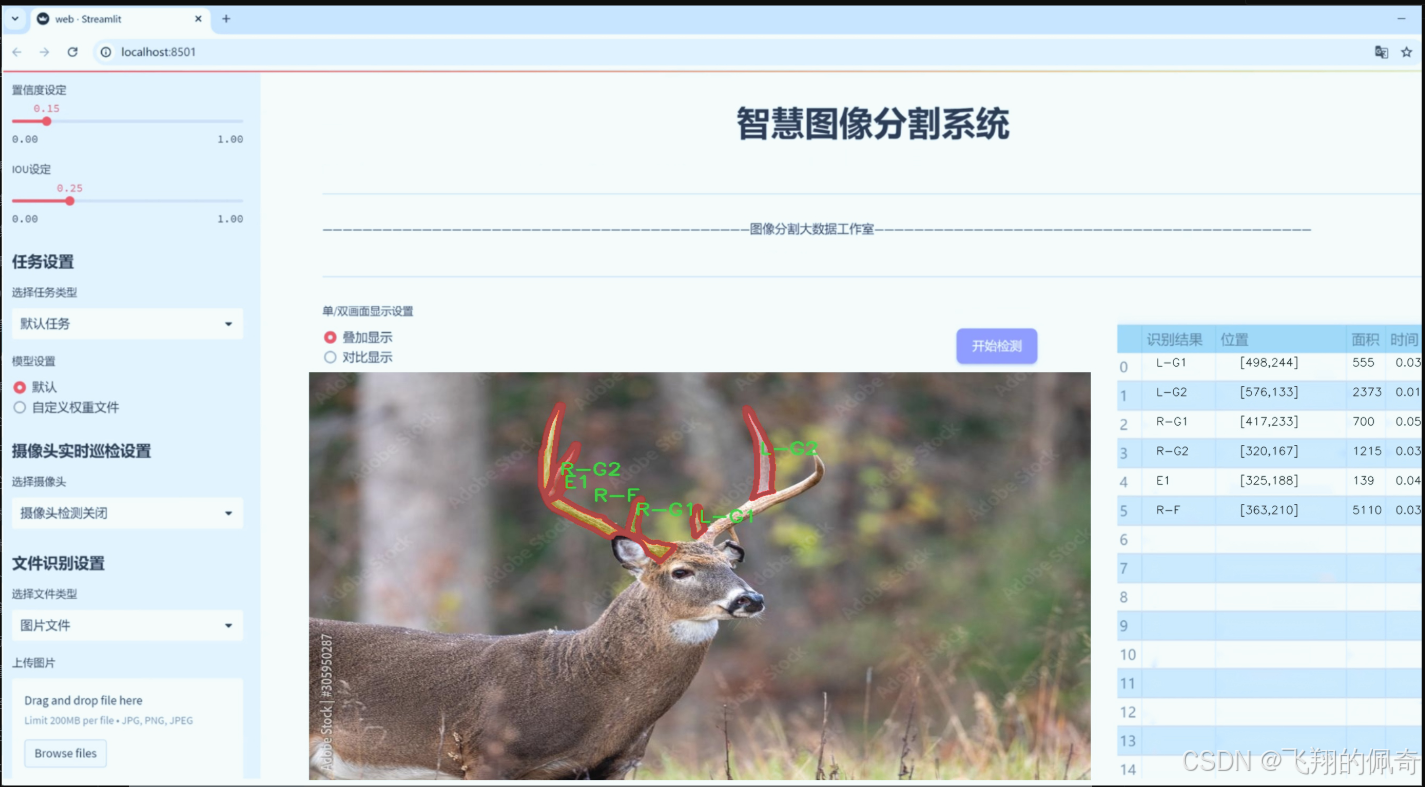
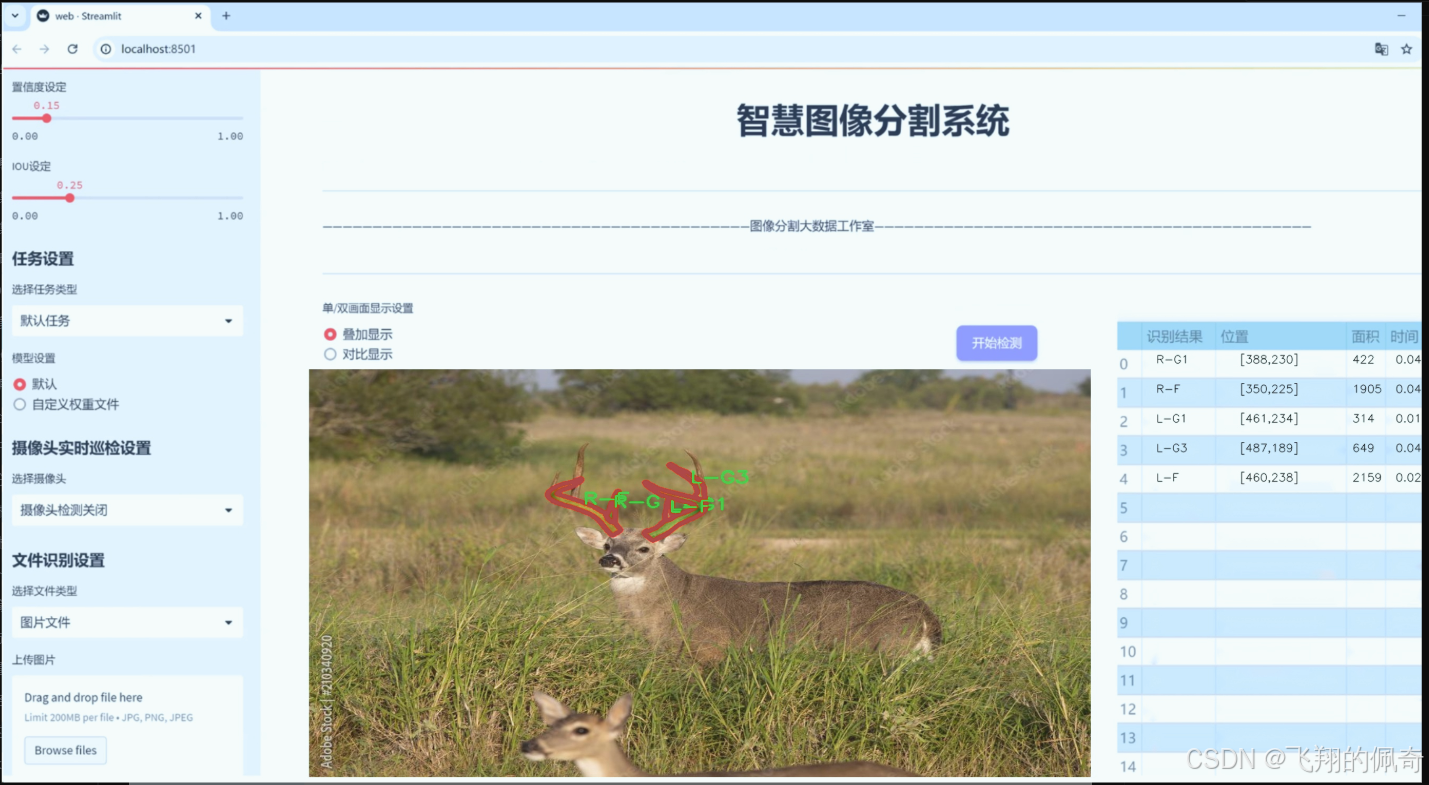
数据集信息
数据集信息展示
在本研究中,我们使用了名为“Antler_detection”的数据集,以训练和改进YOLOv8-seg模型在鹿角图像分割任务中的表现。该数据集专门设计用于处理鹿角的多样性,涵盖了24个不同的类别,旨在为模型提供丰富的训练样本,以提高其在实际应用中的准确性和鲁棒性。
“Antler_detection”数据集的类别数量为24,具体类别包括:E-1、E1、E2、E3、E4、L-E1、L-F、L-G1、L-G2、L-G3、L-G4、L-G5、L-G6、L-R、R-E1、R-F、R-G1、R-G2、R-G3、R-G4、R-G5、R-G6、R-G7和R-R。这些类别不仅反映了鹿角的不同形态和结构特征,还考虑了鹿角在不同生长阶段和不同种类中的变化。这种多样性使得数据集在训练过程中能够涵盖广泛的场景和条件,从而增强模型的泛化能力。
数据集中的每个类别都代表了特定的鹿角特征,例如,E类可能代表了某种特定的鹿种或生长阶段的鹿角,而L类和R类则可能对应于左侧和右侧的鹿角,进一步细分为不同的形态和特征。这种细致的分类方式不仅为模型提供了丰富的标注信息,也为后续的图像分割任务奠定了坚实的基础。
在数据集的构建过程中,研究团队对每个类别的样本进行了精心挑选和标注,确保每个类别的样本在数量和质量上都能满足训练需求。数据集中的图像来源于多个不同的环境和条件,涵盖了自然栖息地、人工饲养场所等多种场景,确保了数据的多样性和代表性。这种多样化的图像来源使得模型在面对不同背景和光照条件时,能够保持较高的分割精度。
为了进一步提升YOLOv8-seg模型的性能,数据集还包含了丰富的图像标注信息,包括每个类别的边界框和分割掩码。这些标注信息为模型的训练提供了必要的监督信号,使其能够在训练过程中学习到不同类别的特征和分布,从而在实际应用中实现高效的图像分割。
总之,“Antler_detection”数据集为改进YOLOv8-seg的鹿角图像分割系统提供了一个强大的基础。通过对24个类别的细致划分和丰富的样本选择,该数据集不仅增强了模型的训练效果,也为未来的研究和应用提供了宝贵的数据支持。随着模型的不断优化和数据集的进一步扩展,我们期待在鹿角图像分割领域取得更为显著的进展。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
def adjust_bboxes_to_image_border(boxes, image_shape, threshold=20):
“”"
调整边界框,使其在一定阈值内贴合图像边界。
参数:boxes (torch.Tensor): 边界框坐标,形状为 (n, 4)image_shape (tuple): 图像的高度和宽度,形状为 (height, width)threshold (int): 像素阈值,默认值为 20返回:adjusted_boxes (torch.Tensor): 调整后的边界框
"""# 获取图像的高度和宽度
h, w = image_shape# 调整边界框,使其在阈值内贴合图像边界
boxes[boxes[:, 0] < threshold, 0] = 0 # 将左上角 x 坐标调整为 0
boxes[boxes[:, 1] < threshold, 1] = 0 # 将左上角 y 坐标调整为 0
boxes[boxes[:, 2] > w - threshold, 2] = w # 将右下角 x 坐标调整为图像宽度
boxes[boxes[:, 3] > h - threshold, 3] = h # 将右下角 y 坐标调整为图像高度
return boxes
def bbox_iou(box1, boxes, iou_thres=0.9, image_shape=(640, 640), raw_output=False):
“”"
计算一个边界框与其他边界框的交并比 (IoU)。
参数:box1 (torch.Tensor): 单个边界框的坐标,形状为 (4, )boxes (torch.Tensor): 一组边界框的坐标,形状为 (n, 4)iou_thres (float): IoU 阈值,默认值为 0.9image_shape (tuple): 图像的高度和宽度,形状为 (height, width)raw_output (bool): 如果为 True,则返回原始 IoU 值而不是索引返回:high_iou_indices (torch.Tensor): IoU 大于阈值的边界框索引
"""
# 调整边界框,使其在图像边界内
boxes = adjust_bboxes_to_image_border(boxes, image_shape)# 计算交集的坐标
x1 = torch.max(box1[0], boxes[:, 0]) # 交集左上角 x 坐标
y1 = torch.max(box1[1], boxes[:, 1]) # 交集左上角 y 坐标
x2 = torch.min(box1[2], boxes[:, 2]) # 交集右下角 x 坐标
y2 = torch.min(box1[3], boxes[:, 3]) # 交集右下角 y 坐标# 计算交集的面积
intersection = (x2 - x1).clamp(0) * (y2 - y1).clamp(0)# 计算两个边界框的面积
box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) # box1 的面积
box2_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1]) # boxes 的面积# 计算并集的面积
union = box1_area + box2_area - intersection# 计算 IoU
iou = intersection / union # IoU 值,形状为 (n, )if raw_output:return 0 if iou.numel() == 0 else iou # 如果需要原始 IoU 值,直接返回# 返回 IoU 大于阈值的边界框索引
return torch.nonzero(iou > iou_thres).flatten()
代码说明:
adjust_bboxes_to_image_border 函数:
该函数用于调整边界框的位置,使其在图像的边界内。如果边界框的某个边距离图像边界小于指定的阈值,则将该边界框的坐标调整到图像边界上。
bbox_iou 函数:
该函数计算一个边界框与一组边界框之间的交并比 (IoU)。首先调用 adjust_bboxes_to_image_border 函数调整边界框,然后计算交集、并集及最终的 IoU 值。如果 raw_output 为 True,则返回原始的 IoU 值;否则,返回 IoU 大于指定阈值的边界框的索引。
这个程序文件主要包含两个函数,分别用于调整边界框的位置和计算边界框之间的交并比(IoU)。
第一个函数 adjust_bboxes_to_image_border 的作用是将给定的边界框调整到图像的边界内,确保它们不会超出图像的范围。函数接收三个参数:boxes 是一个形状为 (n, 4) 的张量,表示 n 个边界框,每个边界框由四个坐标值(x1, y1, x2, y2)表示;image_shape 是一个元组,包含图像的高度和宽度;threshold 是一个整数,表示距离图像边界的阈值。函数首先获取图像的高度和宽度,然后根据阈值调整边界框的位置。如果边界框的左上角(x1, y1)距离图像边界小于阈值,则将其调整为 0;如果右下角(x2, y2)超出图像边界,则将其调整为图像的宽度或高度。最后,返回调整后的边界框。
第二个函数 bbox_iou 用于计算一个边界框与一组其他边界框之间的交并比。该函数接受多个参数:box1 是一个形状为 (4,) 的张量,表示待计算的边界框;boxes 是一个形状为 (n, 4) 的张量,表示 n 个其他边界框;iou_thres 是一个浮点数,表示 IoU 的阈值;image_shape 是图像的高度和宽度;raw_output 是一个布尔值,指示是否返回原始的 IoU 值。函数首先调用 adjust_bboxes_to_image_border 来确保所有边界框都在图像边界内。接着,计算两个边界框的交集区域的坐标,并根据这些坐标计算交集的面积。然后,计算每个边界框的面积,并根据交集和并集的面积计算 IoU。最后,如果 raw_output 为真,则返回 IoU 值;否则,返回与 box1 的 IoU 大于阈值的边界框的索引。
整体来看,这个文件提供了处理边界框的基本工具,适用于目标检测等计算机视觉任务。
11.4 ultralytics\nn\modules_init_.py
以下是代码中最核心的部分,并附上详细的中文注释:
导入Ultralytics YOLO模块所需的各个组件
from .block import * # 导入自定义的基本模块(如块结构)
from .conv import * # 导入卷积层模块
from .head import * # 导入模型头部模块(通常用于输出层)
from .transformer import * # 导入变换器模块(可能用于特征变换或处理)
详细注释:
from .block import *:从当前包中导入所有的block模块。block模块通常包含构建神经网络所需的基本构件,比如残差块、激活函数等。
from .conv import *:从当前包中导入所有的conv模块。conv模块主要定义卷积层,卷积层是卷积神经网络(CNN)的核心组成部分,用于提取输入数据的特征。
from .head import *:从当前包中导入所有的head模块。head模块通常包含模型的输出层,负责将特征图转换为最终的预测结果,比如分类或检测框。
from .transformer import *:从当前包中导入所有的transformer模块。transformer模块可能用于实现特征变换、数据增强或其他处理步骤,以提高模型的性能。
这些导入语句为构建YOLO模型的各个部分提供了必要的功能模块,使得后续的模型定义和训练过程能够顺利进行。
这个程序文件是Ultralytics YOLO项目中的一个模块初始化文件,文件名为__init__.py,它的主要作用是定义和导入该模块下的所有子模块,以便在使用时能够方便地访问这些功能。
文件开头包含了一段注释,说明了该模块的版权信息(AGPL-3.0许可证)以及模块的用途。接着,注释中提供了一个示例,展示了如何使用该模块中的功能。示例代码中,首先从ultralytics.nn.modules导入所有内容,然后导入了PyTorch库和操作系统库。接下来,创建了一个形状为(1, 128, 40, 40)的张量x,并实例化了一个卷积层m,其输入和输出通道均为128。随后,代码使用torch.onnx.export将该卷积层导出为ONNX格式,并使用onnxsim工具对导出的模型进行优化,最后打开生成的ONNX文件。
在文件的最后部分,使用了相对导入的方式,将该模块下的多个子模块(如block、conv、head和transformer)导入到当前命名空间中。这意味着在其他地方使用from ultralytics.nn.modules import *时,可以直接使用这些子模块中的类和函数,而无需单独导入每一个子模块。
总体来说,这个文件的设计使得Ultralytics YOLO的模块结构更加清晰和易于使用,方便开发者进行模型的构建和实验。
11.5 ultralytics\engine_init_.py
Ultralytics YOLO 🚀, AGPL-3.0 license
这段代码是Ultralytics YOLO模型的开源实现,遵循AGPL-3.0许可证。
YOLO(You Only Look Once)是一种实时目标检测算法,能够在单次前向传播中同时进行目标分类和定位。
Ultralytics是YOLO的一个实现版本,提供了高效的训练和推理功能。
代码的核心部分通常包括模型的定义、训练过程、推理过程等,但由于提供的代码片段非常简短,无法直接提取具体实现。
下面是一个简化的YOLO模型结构示例,供参考:
class YOLO:
def init(self, model_config):
# 初始化YOLO模型,加载模型配置
self.model_config = model_config
self.load_model()
def load_model(self):# 加载模型权重和结构passdef predict(self, image):# 对输入图像进行目标检测# 返回检测到的目标及其位置passdef train(self, dataset):# 训练模型,使用提供的数据集pass
以上是YOLO模型的核心结构,具体实现会根据需求有所不同。
注释说明:
模型初始化:在__init__方法中,接收模型配置并调用加载模型的方法。
加载模型:load_model方法负责加载模型的权重和结构,这通常是YOLO实现中的重要步骤。
预测方法:predict方法用于对输入图像进行目标检测,返回检测结果。
训练方法:train方法用于训练模型,接受一个数据集作为输入。
这段代码展示了YOLO模型的基本框架,具体的实现细节和算法逻辑会在实际代码中更为复杂。
这个程序文件是Ultralytics YOLO(You Only Look Once)项目的一部分,使用AGPL-3.0许可证进行发布。Ultralytics YOLO是一个流行的目标检测算法,广泛应用于计算机视觉领域。文件的开头注释部分简单地标明了项目的名称和许可证类型。
在这个文件中,通常会包含一些初始化代码,可能会导入必要的模块和类,设置包的元数据,或者定义一些全局变量和函数。由于文件名为__init__.py,这意味着它是一个包的初始化文件,Python会在导入该包时执行这个文件中的代码。
具体的实现细节可能包括定义YOLO模型的相关类、加载预训练模型、设置训练和推理的参数等。这些功能可以帮助用户快速开始使用YOLO进行目标检测任务。
总的来说,这个文件是Ultralytics YOLO项目的重要组成部分,负责初始化包的环境和功能,为后续的模型训练和推理提供支持。
12.系统整体结构(节选)
Ultralytics YOLO 项目的整体功能和构架概括
Ultralytics YOLO 是一个高效的目标检测框架,旨在提供易于使用的接口和强大的功能,以支持训练和推理任务。该项目采用了模块化的设计,使得各个功能可以独立开发和维护。整体架构包括模型定义、训练引擎、验证工具、实用程序等多个部分,能够满足从数据处理到模型评估的完整工作流。
模型模块:定义了各种YOLO模型的结构,包括NAS(Neural Architecture Search)和FastSAM(Fast Segment Anything Model)等。
训练引擎:负责模型的训练过程,包括数据加载、损失计算、优化器设置等。
验证工具:提供验证和评估模型性能的功能,确保模型在测试集上的表现。
实用程序:包含一些辅助功能,如分布式训练支持、边界框处理等。
文件功能整理表
文件路径 功能描述
ultralytics/utils/dist.py 处理分布式训练相关的功能,包括查找可用网络端口、生成DDP文件和命令、清理临时文件等。
ultralytics/models/nas/val.py 定义了 NASValidator 类,用于处理YOLO NAS模型的验证,执行非极大值抑制(NMS)以生成最终检测结果。
ultralytics/models/fastsam/utils.py 提供边界框处理的工具,包括调整边界框位置和计算边界框之间的交并比(IoU)。
ultralytics/nn/modules/init.py 初始化模块,导入子模块以便于使用,可能包含模型构建和导出功能的示例。
ultralytics/engine/init.py 初始化引擎模块,设置训练和推理的环境,可能包含模型训练和评估的相关功能。
通过这种模块化的设计,Ultralytics YOLO项目能够高效地支持各种目标检测任务,并为开发者提供灵活的使用方式。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻