人工智能发展史 — 物理学诺奖之 Hinton 玻尔兹曼机模型
目录
文章目录
- 目录
- 1983 年:玻尔兹曼机
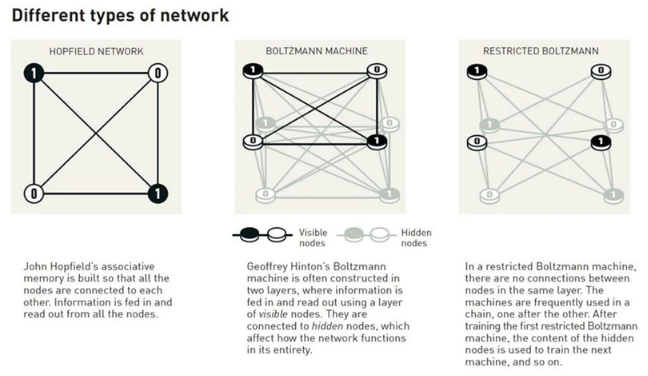
- 霍普菲尔德网络 v.s. 玻尔兹曼机
- 从统计物理学说起:玻尔兹曼分布
- 基于能源的模型
- 吉布斯采样
- 玻尔兹曼机
- 隐藏层和随机性
- 能量函数
- 自学习
- 1985 年,受限玻尔兹曼机
- 能量函数
- CD 学习算法
- 1986 年,多层感知机
- 反向传播学习算法
- 逻辑回归函数 Sigmoid
1983 年:玻尔兹曼机
2024 年的诺贝尔物理学奖颁发给了 John Hopfield 和 Geoffrey Hinton,以表彰他们在实现机器学习的人工神经网络方面的基础性发现与发明。他们分别在 1982 年和 1983 年提出的霍普菲尔德网络和玻尔兹曼机这两种人工神经网络数据模型。
在得知得奖的第一时间,Hinton 本人表示 “没想到会发生这样的事情“。后来,在接受《纽约某报》的采访时,Hinton 表示:Hopfield 网络及其进一步发展(玻尔兹曼机)均依托于物理学成果。Hopfield 网络使用能量函数,而玻尔兹曼机则遵循统计物理学的思想。换句话说,神经网络发展在该阶段中确实很大程度依赖于物理学领域的思想。但实际上,用于构建如今常见的 AI 模型的是另一种不同的技术,这就跟物理学关系不大了。
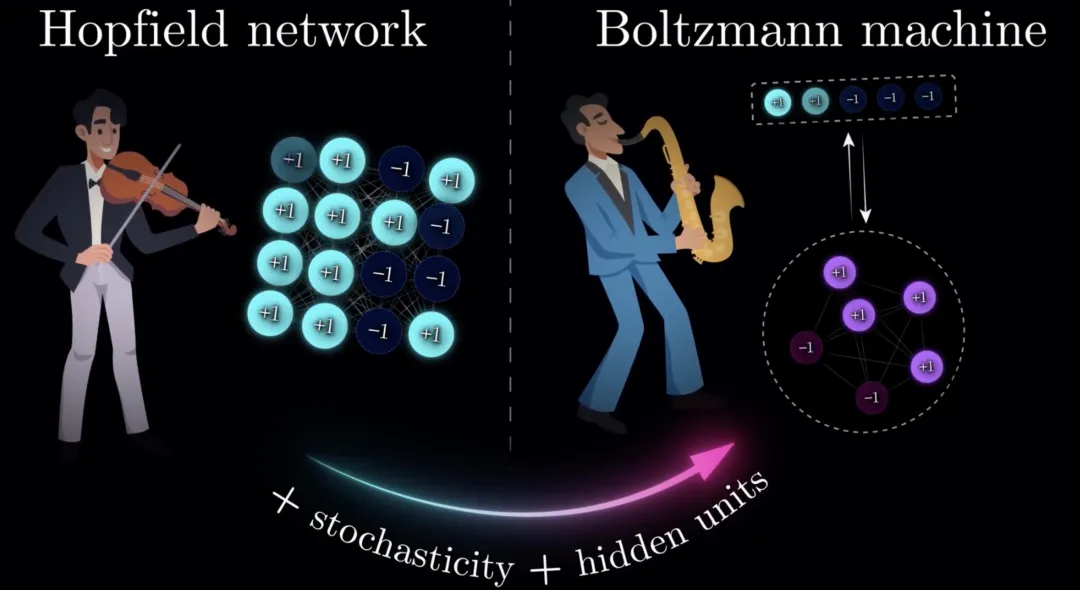
霍普菲尔德网络 v.s. 玻尔兹曼机
在 1980 年代和 1990 年代,研究人员认识到神经网络可以近似复杂的概率分布 —— 但训练它们非常困难。 玻尔兹曼机是一个开创性的提议,它利用统计力学中的概念(如能量状态和热平衡)来描述网络如何学习观测变量和隐藏变量的联合分布。后来,受限玻尔兹曼机用更易于处理的架构完善了这些想法,激发了深度信念网络 (DBN) 和整个早期深度学习研究浪潮。
- 霍普菲尔德网络:解决了 “记忆” 如何在一个神经网络中稳健而灵活地存储,即使有些变化,神经网络也能 “想起来” 或者 “认出来”。
例如:使用霍普菲尔德网络来存储字母图像后,在一定噪声下,网络也可以 “认出” 已经存储的字母; - 玻尔兹曼机:也称为 “随机霍普菲尔德网络”,在普菲尔德网络的基础上,玻尔兹曼机借鉴的物理热力学系统中的能量跃迁机制,让神经网络拥有了 “创造性”,可以探索那些没见过的模式,从而变得更加灵活聪明,是今天生成式模型的奠基者。
简而言之,霍普菲尔德网络像是在如实的演奏一首已经记住了的曲子,而玻尔兹曼机则更像是爵士乐的即兴演奏,是对记忆的 “创造性复现”。
从统计物理学说起:玻尔兹曼分布
19 世纪中叶,欧洲进入了第二次工业革命,大规模使用蒸汽机和内燃机技术革新动力来源。然而,当时的人们仍不清楚热能是如何从物质中产生并驱动机器的。以至于当时的发动机做功效率只不到 5%。直到 “热力学” 的诞生 —— 一门关于热平衡现象和如何设计高效热机的科学理论。
其中,热力第二定律指的是:热量可以自发地从温度高的物体传递到温度低的物体,但不可能自发地从温度低的物体传递到温度高的物体。即:孤立系统会自发地朝着热力学平衡的方向(熵最大化的状态)演化,最终退化为完全无序状态,因而又称为 “熵增定律”。
“熵” 概念最早由德国物理学家克劳修斯提出,他在宏观的层面用熵来描述系统能量变化与温度的关系。而路德维希·玻尔兹曼则是在微观的、分子的层面进行了描述。在分子和原子无法被显微技术观测到的年代,宏观现象的连续性和分子原子运动的离散性这两大流派之间产生了巨大的认知冲突。而玻尔兹曼坚信这个世界的物理现象背后的本质是由实际存在的分子原子运动所导致的。
玻尔兹曼所处的年代是统计学发展的重要时期。统计学主要的研究方法是记录大量可重复事物或者现象的数据,并利用这些数据来挖掘背后的规律,继而对具体的规律做出预测和判断。这为微观粒子互相作用力研究提供了新的思路,即:不关注天文数字量级的粒子之间的具体相互作用,而是只关注它们所有可能状态背后的整体规律。也就是说,这种方法强调通过统计手段来分析大量粒子的整体状态背后的规律,而不是追踪每个粒子的单独运动。
玻尔兹曼正是基于统计思维对微观的分子原子开展研究。他假设在没有外部作用情况下,微观状态的数量是有限的,并且所有的微观状态发生的概率都是一样的。这个通常被称为等概率原理。举例来说,等概率原理:在台球桌上开球之后,所有球在不受摩擦和外部作用力的条件下相互碰撞运动。这时,当用高速摄影机拍下某个瞬间,它们处在任何一种可能的位置和运动状态的组合,都是等可能出现的。同时,在微观状态等概率原理的条件下,每个台球的运动状态所蕴含的能量则很可能是不一样的,或高能或低能。
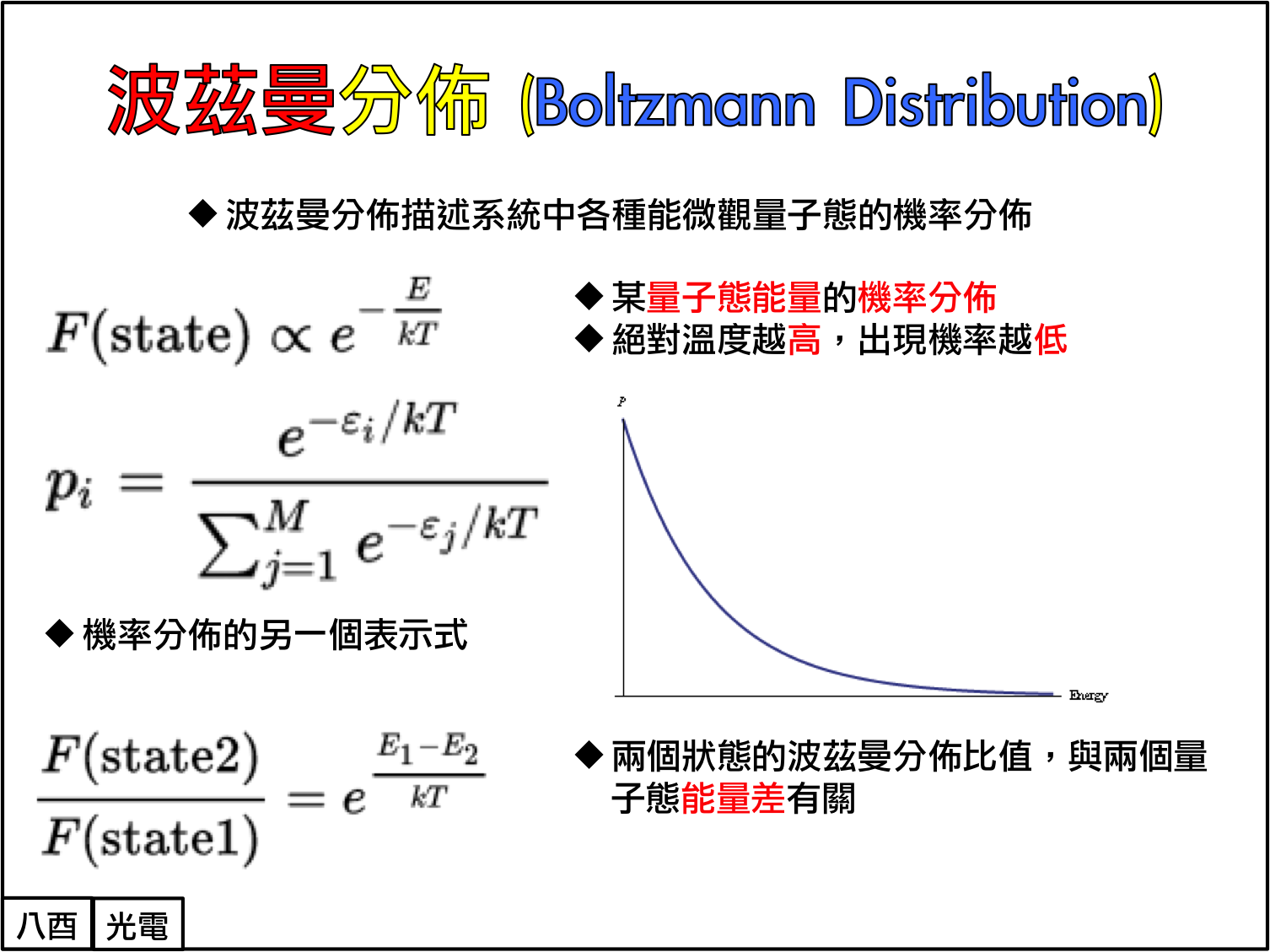
玻尔兹曼发现:当一个孤立的系统处于热平衡状态时,那些具有较高能量的微观状态出现的可能性相对较小,而较低能量的微观状态出现的可能性则相对较高。并提出了玻尔兹曼分布,统计物理学领域最伟大的成果之一。
玻尔兹曼分布,用于描述微观粒子处于特定状态下的概率,是关于状态能量 E(x) 与系统温度 T 的函数。一个粒子处于状态 α 的概率 P(α) 是关于状态能量 E(x) 与系统温度 T 的函数。
如下图,根据 p(x) 的表达式,在温度 T 比较低的时候,最低能量的状态有着显著(指数)大于其它状态的出现概率。此时观测这个系统,我们最大可能看到它低能量的状态。而当温度 T 很高时,这种状态之间出现概率的差距就逐渐被拉平。
基于能源的模型
基于能量的模型 (EBM) 通过将每个可能的配置 x 与能量值 E(x) 相关联来定义数据的概率分布。较低的能量状态对应于更可能的配置,而较高的能量状态对应于不太可能的配置。从形式上讲,基于能量的模型通常使用玻尔兹曼分布:
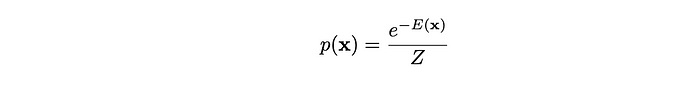
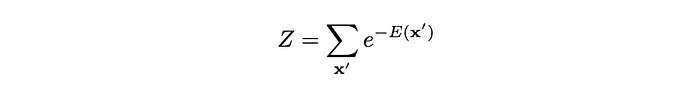
- E(x) 是一个能量函数,通常由神经网络或一些参数函数定义。
- Z 是配分函数(或归一化常数),确保 P(x) 在所有可能的 x 上求和(或积分)为 1。
EBM 公式的关键思想是:当我们可以以可学习的方式来定义和参数化 E(x),那么我们可以通过调整参数的方式来模拟复杂分布,从而使得实际数据配置能耗较低。
值得注意的是,此处 “能量” 的概念是从霍普菲尔德网络从继承而来,而霍普菲尔德网络又是从物理学中借来的。所以玻尔兹曼机的源点依旧是物理学。即:在热力学系统中,在给定温度下,能量较低的状态呈指数级增加。将这个类比转化为机器学习,状态是数据向量,系统会尝试学习一个能量函数,该函数对于要建模的数据来说是最小的。
吉布斯采样
在玻尔兹曼机中,配分函数 Z 通常很难计算,所以采用了另一种方法来将节点的状态值概率趋近于玻尔兹曼分布。即:玻尔兹曼机联合概率分布 P(x) 一般通过马尔科夫链蒙特卡洛方法(MCMC 方法)来做近似计算,采用基于吉布斯采样的样本生成方法来训练。
吉布斯采样,会随机选择一个变量 Xi,然后根据其全条件概率 P(Xi|X-i) 来设置其状态值,即以 P(Xi=1|X-i) 的概率将变量 Xi 设为 1,否则为 0。在固定的温度 T 下,运行足够时间后,玻尔兹曼机会达到热平衡状态。此时,任何全局状态的概率都服从玻尔兹曼分布 P(x),只和系统的能量有关,和初始状态无关。
玻尔兹曼机
霍普菲尔德模型发表不久,卡内基-梅隆大学的 Hinton T. Sejnowski 等人就提出了一个随机性推广 —— 基于统计物理的玻尔兹曼概率分布(系统不同状态的能量决定概率)开发了玻尔兹曼机。
玻尔兹曼机保留了霍普菲尔德能量最小化的核心思想,通过能量函数 E(x) 定义概率分布,能量越低,配置的可能性越高。同时,为了解决霍普菲尔德模型所具有的 “易陷入局部极小值” 和 “存储容量有限且易发生模式混淆” 等局限性,玻尔兹曼机引入了 2 个关键创新:
- 通过引入隐藏层和随机性,从而能够处理更复杂的概率分布。
- 通过引入模拟退火(AIS,Annealed Importance Sampling)等算法,从而能够在学习过程中避免陷入局部最优,从而更好地捕捉到数据的抽象结构和表征。
玻尔兹曼机可以解决 2 类问题:
- 搜索问题:当给定变量之间的连接权重时,需要找到一组二值向量,使得整个网络的能量最低。
- 学习问题:当给定变量的多组观测值时,学习网络的最优权重。
在学习问题领域,玻尔兹曼机是一种无监督学习的随机神经网络,可用于特征提取、降维。
- 无监督模型:一种机器学习模型,它用于 “从未标记的数据中” 学习数据的结构和分布。无监督学习的主要任务包括聚类、降维等。常见的无监督学习算法有 K 均值聚类、主成分分析等。
- 有监督模型:是一种机器学习模型,它 “使用标记的数据集” 进行训练。在有监督学习中,模型通过学习输入和输出之间的映射关系来进行预测或分类。常见的有监督学习算法有线性回归、逻辑回归、支持向量机等。
玻尔兹曼机着重模式的分布,而不是单个模式,因此能够在数据中寻找特征。机器训练时,哺以运行时可能出现的例子。因此机器可以对图像进行分类,或者产生与训练所用例子同一类的图像。
隐藏层和随机性
玻尔兹曼机(Boltzman Machine)是一个随机动力系统,每个变量的状态都以一定的概率受到其他变量的影响。玻尔兹曼机中,随机向量 x 的联合概率,也就是节点的状态值,是满足玻尔兹曼分布的。
玻尔兹曼机可以用概率无向图模型来描述,一个具有 K 个节点的玻尔兹曼机满足以下性质:
- 二值化:每个节点的状态值只有 0 和 1。
- 两类节点:一类是可观察的节点,有 N 个;另一类是不可观察的节点,即隐藏节点,有 K-N 个。
- 全连接:节点之间是全连接的,即每个节点都和其他节点连接。
- 对称性:每两个变量之间的互相影响是对称的。这里的对称和上面无向其实是一个概念,就是已知 A 点的状态值,那么求 B 的状态值,和已知 B 的状态值,求 A 的状态值的影响是相等的。
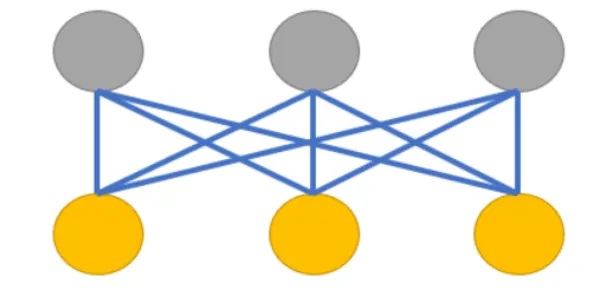
下图就是一个有 6 个节点的玻尔兹曼机。其中有 3 个可观察的节点,已经标了黄色,还有 3 个不可观测的节点,即隐藏节点,已经标了灰色。
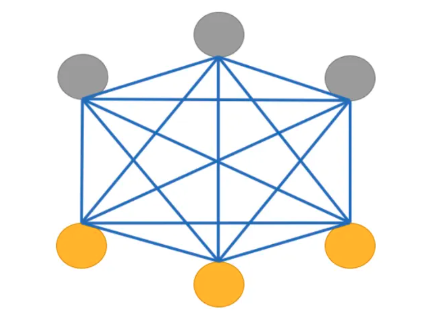
训练时,信息提供给可见节点,但隐藏节点也对能量函数有贡献,因此便于代表更一般的概率分布。在一定规则下,各节点的状态值不断更新,网络整体性质最终确定,虽然各节点的取值还在变化。各种位形出现的概率由玻尔兹曼概率分布决定。
可见,玻尔兹曼机是生成模型的一个早期例子。
能量函数
玻尔兹曼机是一个具有可见和隐藏单元的完全连接网络。每个单元都可以被认为是一个二进制神经元(打开或关闭)。所有单位的配置(可见 + 隐藏)的模型能量函数通常如下所示:
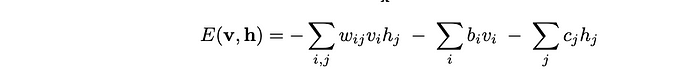
- v 是可见单位,h 是隐藏单位。
- w_ij 是连接可见单位 i 和隐藏单位 j 的权重。
- b_i 和 c_j 分别是可见和隐藏单元的偏差。
自学习
为了拟合玻尔兹曼机,我们的目标是调整权重 w_ij、偏置量 b_i 和 c_j ,以便分布 p(v) 对观测数据 v 施加高概率。对数似然的梯度涉及需要从数据分布(easy) 和模型分布(hard) 中采样的项。在实践中,MCMC 方法(如吉布斯采样)可用于近似这些预期,但对于完全连接的波尔茨曼机而言,这是出了名的慢。
因此,玻尔兹曼机在理论上具有优雅性,但事实证明很难在实际任务中扩展。
1985 年,受限玻尔兹曼机
玻尔兹曼机由完全连接的网络组成,包括可见单元和隐藏单元,但玻尔兹曼机的配分函数计算复杂性非常高,这使得模型无法严格计算一个数据的概率值和似然度。
因此,Geoffrey Hinton 等人在 1985 年发表论文《A learning algorithm for boltzmann machines》,提出了受限玻尔兹曼机(RBM),通过限制隐藏单元之间和可见单元之间的连接,简化了玻尔兹曼机的架构,即:隐藏单元本身之间没有连接,可见单元本身之间也没有连接。相反,连接仅在可见层和隐藏层之间运行(即二分结构)。
受限玻尔兹曼机有层的概念。它有 2 层,其网络架构如下:
- 一层称为显层,用于观测和输入;
- 另一层称为隐藏层,用于提取特征。
受限玻尔兹曼机相比玻尔兹曼机,层间的节点还是采用了对称的全连接的方式连接,但是层内的节点相互独立,相互不受影响。因为层内节点相互独立,那么由 Bayes 条件独立定理,受限玻尔兹曼机可以并行地对所有的显层变量或隐藏层变量同时进行采样,从而更快达到热平衡。
RMB 架构的优势:
- 更容易采样 :由于没有隐藏到隐藏的连接,一旦修复了可见层,每个隐藏的单元在条件上都独立于其他单元(反之亦然)。这大大简化了 Gibbs 采样步骤。
- 高效训练 :使用 CD 算法比 MCMC 方法快非常多。
由于 RBM 具有架构简单、预训练高效、可解释性强等优势,所有在实际应用中交波尔茨曼机用得更多,应用场景包括降维与特征学习、协同过滤(如电影推荐)、深度置信网络(DBN)预训练,以及图像和数据建模等。但 RBM 的局限性在于连接限制、局部最优问题和扩展性挑战。
能量函数

由于受限玻尔兹曼机变成了分层的结构,所以受限玻尔兹曼机的能量函数变成了由 3 部分组成:
- 一个是显层节点偏置乘以显层随机可观测变量部分;
- 一个是连接权重与显层随机可观测变量和隐层随机可观测变量相乘部分;
- 一个是隐层节点偏置乘以隐层随机可观测变量偏置部分。
CD 学习算法
由于受限玻尔兹曼机的特殊结构,Hinton 在 2000 年初提出了一种比吉布斯采样更加有效的学习算法,即对比散度学习算法,又称为 CD 学习算法。CD 算法是 RBM 训练的关键突破,显著减少了训练时间。
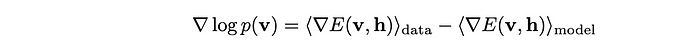
CD 算法在吉布斯采样的基础上作出的一点改进,即在处理玻尔兹曼机时,运行无穷次的吉布斯采样改进为运行 K 次即可。以前处理玻尔兹曼机时,吉布斯采样是一直对这个玻尔兹曼机处理,直到这个玻尔兹曼机收敛。Hinton提出,在受限玻尔兹曼机中,不需要等到受限玻尔兹曼机完全收敛,只需要 K 步吉布斯采样。所以 CD 算法又称 K 步吉布斯采样法。
1986 年,多层感知机
1974 年,哈佛大学的保罗·沃博斯在其博士论文中首次提出了误差反向传播(BP,back propagation)算法的雏形。但最初受限于算力未受重视。
1986 年,Geoffrey Hinton 与 David Rumelhart 和 Ronald Williams 发表了一篇开创性的论文《Parallel Distributed Processing(并行分布式处理)》,证明了可以使用误差的 BP(Back Propagation,反向传播)学习算法来训练具有一层或多层隐藏层的前馈网络,即:多层感知机(MLP)。
- 采用 Sigmoid 进行非线性映射,有效解决了非线性分类和训练的问题。这种引入了非线性激活函数的多层感知机,解决了之前单层感知机仅能拟合线性函数的问题。该算法具有很强的函数复现能力,但容易陷入局部最优解并且随着网络层数的增加训练的难度也越来越大。
- 采用 BP 算法,解决了多层感知机训练中的关键问题。它通过有效地计算误差的导数来逐步调整网络中的权重,使得多层感知机的训练变得可行。
Rumelhart、Hinton 和 Williams 提出了多层感知机(MLP)与反向传播(BP)训练相结合的理念,解决了单层感知器无法进行非线性分类的问题,开启了神经网络的第二次热潮。从简单的前馈神经网络到后来的 CNN(卷积神经网络)、RNN(循环神经网络)、再到 Transformer 以及大语言模型,都离不开这个反向传播算法。
反向传播学习算法
BP 算法的核心思想是通过链式求导法则来计算梯度,即:计算神经网络预测输出与实际输出之间的误差的导数(梯度)来调整权重和偏置,以期逐步减少误差,使网络的输出更接近实际输出。最终使人工神经网络具备 “万能近似” 的能力。
通过链式法则计算损失函数对网络权重的梯度,逐层反向传播误差信号,解决多层网络训练难题。数学表达式为:

深度学习的训练过程本质上就是找到一组参数,使神经网络模型无限逼近我们所期望的输入输出映射,其中神经网络通过损失函数判断自己预测是否准确。
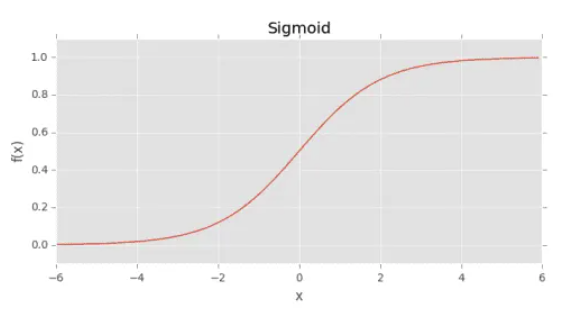
逻辑回归函数 Sigmoid
1958 年,大卫·考克斯提出了逻辑回归模型,这是一种广义的线性分类模型,数据公式与感知机模型相似,但使用了的是 Sigmoid 激活函数来替代阶跃函数进行分类,其目的是最大化线性分类的准确性。逻辑回归模型在分类问题中广泛应用,尤其是二分类问题。
尽管逻辑回归的名字中包含 “回归”,但它实际上是一种用于解决二分类问题的模型。逻辑回归通过引入一个逻辑函数(Sigmoid 函数)将线性回归的 y 输出转换为一个 p 概率值,从而实现对二分类问题的预测。
逻辑回归模型是在线性回归模型的基础之上,通过引入 Sigmoid 函数计算出 y=0 或 y=1 时的 p 概率(将线性组合的结果转换为概率值),继而扩展了线性回归模型的作用,使其可以用于处理二分类任务。
逻辑回归模型的基本形式为:
P(y=1)=11+e−(β0+β1x1+β2x2+⋯+βnxn)
其中,P(y=1) 是目标变量为1的概率,x1, x2, …, xn 是输入变量,β0, β1, β2, …, βn 是参数。逻辑回归的主要目标是找到最佳的参数,使得概率 P(y=1) 最大化,这通常通过最大化对数似然函数来实现。
感知机模型使用线性 sign 激活函数存在 2 大缺陷:
- sign 函数只能处理线性可分的数据(如与门、或门)。但在面对异或(XOR)等线性不可分问题时,单层感知机无法找到有效的分类超平面。例如,异或问题的输入点在二维空间中无法用一条直线分隔,导致模型失效。
- sign 函数在反向传播中几乎无法提供有效的梯度信息(导数接近 0),导致无法通过梯度下降优化参数。例如,符号函数的输出为离散值(1 或 -1),其导数在大部分区域为零,无法更新权重。
为此在多层感知机模型中引入了 Sigmoid 函数来替换 sign 函数:
- 引入了非线性能力,支持非线性激活。Sigmoid 函数将输入映射到 (0, 1) 区间,为模型引入非线性。这使得多层感知机(MLP)能够通过叠加隐藏层学习复杂的数据模式,例如异或问题的螺旋形决策边界。
- 引入了梯度传播的可行性。Sigmoid 函数是连续且平滑的,其导数可通过自身表示,便于计算梯度。例如,在反向传播中,梯度可通过链式法则逐层传递,避免了 sign 激活函数的梯度消失问题。
尽管 Sigmoid 函数解决了感知机 sign 函数的部分问题,但其自身也存在缺陷:
- 梯度消失:当输入值极大或极小时,Sigmoid 的导数趋近于 0,导致深层网络训练困难。
- 输出非零中心化:Sigmoid 的输出均值不为 0,可能影响权重更新的方向。
- 计算复杂度高:涉及指数运算,影响训练速度。
因此,后续研究中出现了 ReLU、Tanh 等替代方案。例如:
- ReLU:在正区间保留梯度,计算高效,缓解梯度消失。
- Tanh:输出零中心化,梯度范围更大,适合隐藏层。
多层感知机模型引入 Sigmoid 函数的核心意义在于:
- 解决线性不可分问题:通过非线性激活增强模型表达能力;
- 支持梯度下降优化:提供可导的梯度信号;
- 概率化输出:适配分类任务的概率需求。
sigmoid 激活函数为神经元引入了非线性特性,使得神经网络能够学习和表示更复杂的函数。
Sigmoid 函数的数学公式如下:
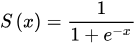
其对 x 的导数可以用自身表示:
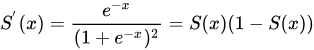
Sigmoid 函数的图形如 S 曲线: