Redis Set 类型全解析
文章目录
- 1.引言
- 2.Set 类型的核心特性
- 3.Set 类型核心命令
- 3.1 元素添加与查询:sadd、smembers、sismember
- sadd
- smembers
- sismember
- 3.2 元素删除与随机操作:spop、srandmember、srem
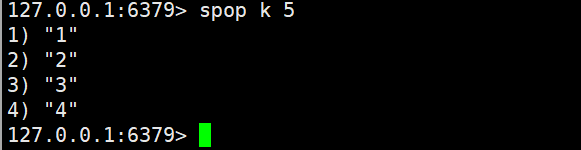
- spop
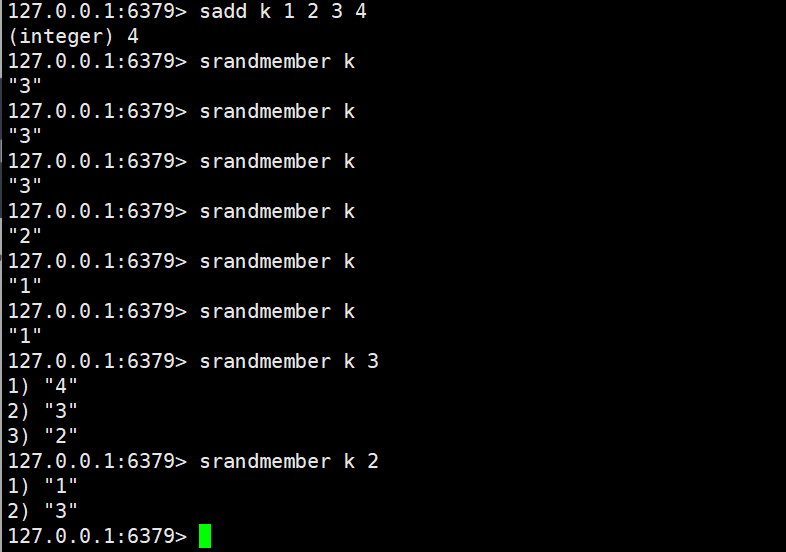
- srandmember
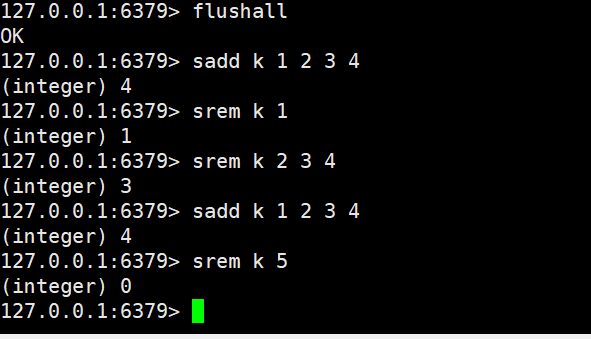
- srem
- 3.3 元素移动:smove
- 3.4 集合间关系计算:sinter、sinterstore、sunion、sunionstore、sdiff、sdiffstore
- sinter
- sinterstore
- sunion
- sunionstore
- sdiff
- sdiffstore
- 3.5 命令小结
- 4. Set 类型的底层编码
- 与其他语言 Set 的底层差异
- 5.应用场景
- 5.1 使用Set来保存用户的 ”标签“
- 5.2 使用Set来计算用户间的共同好友~
- 5.3 使用Set统计 UV
- 5.4 随机筛选(抽奖、随机推荐)
- 5.5 业务场景
- 6.小结
1.引言
在 Redis 常用数据类型中,Set(集合)以 “无序性” 和 “元素唯一性” 为核心特征,完美适配 “去重存储”“关系计算”“随机筛选” 等场景。从用户标签管理到共同好友计算,从 UV 统计到随机抽奖,Set 凭借简洁的命令体系和高效的底层实现,成为分布式系统中处理 “不重复数据” 的关键工具。本文将从核心特性出发,逐条拆解命令、解析编码优化,再结合实际业务场景说明应用逻辑,帮你吃透 Set 类型的所有关键知识点。
2.Set 类型的核心特性
- 元素唯一性:Set 中不会存在重复元素,即使重复添加(如sadd set1 a a),最终也只会保留 1 个(类似数学中的 “集合” 概念);
- 元素无序性:元素插入顺序与存储顺序无关,无法通过下标访问(区别于 List 的 “有序”),也不会按值排序(区别于 Sorted Set 的 “排序有序”);
- 元素类型限制:Set 中的每个元素均为 String 类型,若需存储结构化数据(如用户信息),需先序列化为 JSON 字符串(如"{user_id:1001, name:‘zhangsan’}")。
3.Set 类型核心命令
3.1 元素添加与查询:sadd、smembers、sismember
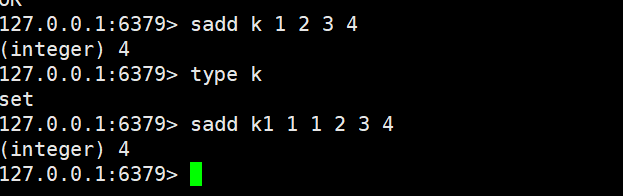
sadd
sadd key member [member ...]
- 功能:向 Set 中添加 1 个或多个元素;若元素已存在,会自动忽略(保证唯一性);若 Key 不存在,会先创建空 Set 再添加。
- 时间复杂度:O (K)(K 为添加的元素个数,单个元素添加为 O (1))
- 返回值:成功添加的元素个数(已存在的元素不计入)。
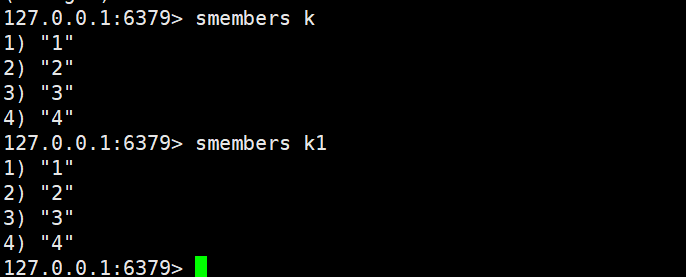
smembers
smembers key
- 功能:获取 Set 中的所有元素(无序返回,每次执行结果的顺序可能不同)。
- 时间复杂度:O (N)(N 为 Set 中的元素总数,需遍历所有元素)
- 返回值:Set 中的所有元素列表(Key 不存在时返回空列表)。
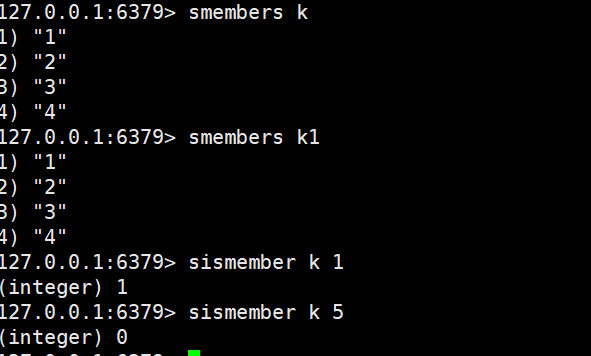
sismember
sismember key member
- 功能:判断指定元素是否在 Set 中(类似 “存在性检查”)。
- 时间复杂度:O (1)(底层基于哈希表,直接通过元素哈希定位)。
- 返回值:1表示元素存在,0表示元素不存在或 Key 不存在。
3.2 元素删除与随机操作:spop、srandmember、srem
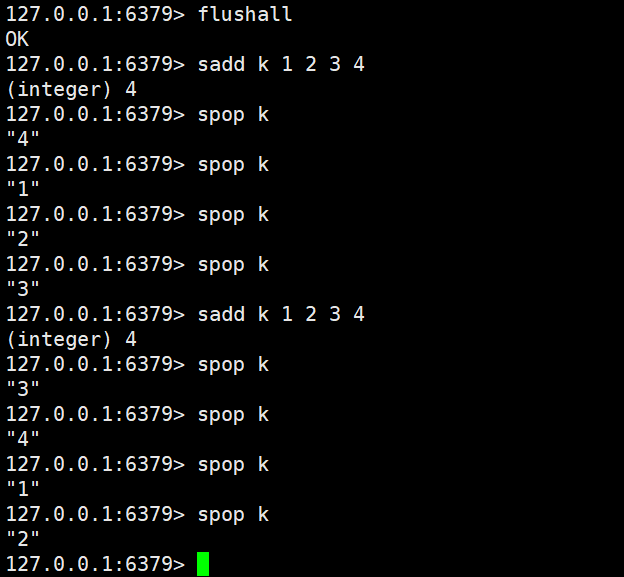
spop
spop key [count]
- 功能:从 Set 中随机删除1 个或count个元素(因 Set 无序,“随机” 即任意选择);若 Key 不存在或 Set 为空,返回nil。
- 时间复杂度:O (count)(单个元素删除为 O (1))
- 返回值:删除的元素列表(删除 1 个时返回单个值,删除多个时返回列表)。
srandmember
srandmember key [count]
- 功能:从 Set 中随机获取1 个或count个元素(不删除元素);若count为正数,返回的元素不重复;若count为负数,返回的元素可能重复(绝对值为获取个数)。
- 时间复杂度:O(count)。
- 返回值:获取的元素列表(Key 不存在或 Set 为空时返回空列表)。
srem
srem key member [member ...]
- 功能:从 Set 中删除 1 个或多个指定元素(非随机,需明确指定元素);若元素不存在,会自动忽略。
- 时间复杂度:O (K)(K 为删除的元素个数,单个元素删除为 O (1))。
- 返回值:成功删除的元素个数(不存在的元素不计入)。
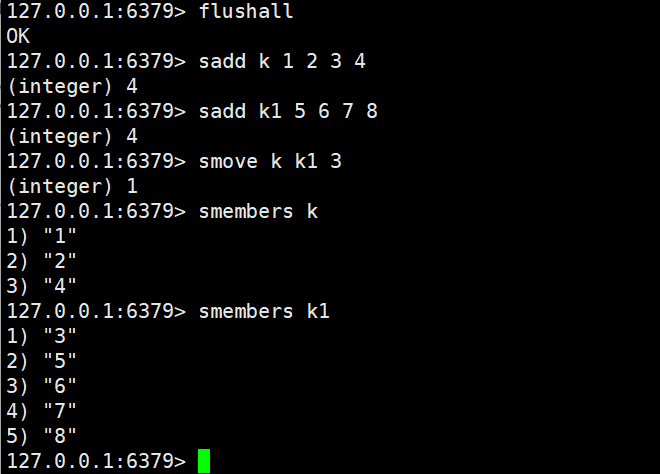
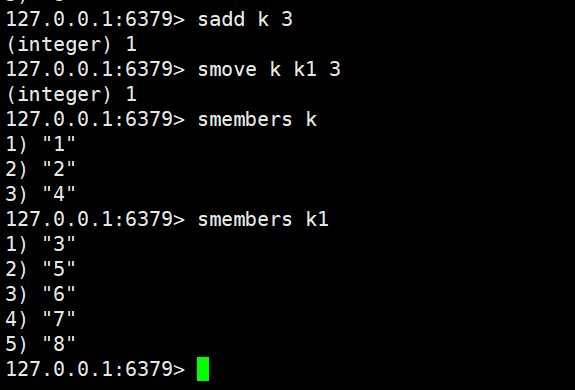
3.3 元素移动:smove
smove source destination member
- 功能:将sourceSet 中的指定元素member移动到destinationSet 中;若source中无该元素,或destination中已存在该元素,移动失败。
- 时间复杂度:O (1)(两个 Set 的操作均为哈希表定位)。
- 返回值:1表示移动成功,0表示移动失败(元素不存在或已重复)。
3.4 集合间关系计算:sinter、sinterstore、sunion、sunionstore、sdiff、sdiffstore
这类命令用于计算多个 Set 之间的 “交集”“并集”“差集”,是 Set 类型的核心价值所在,广泛用于 “共同好友”“标签匹配” 等场景。
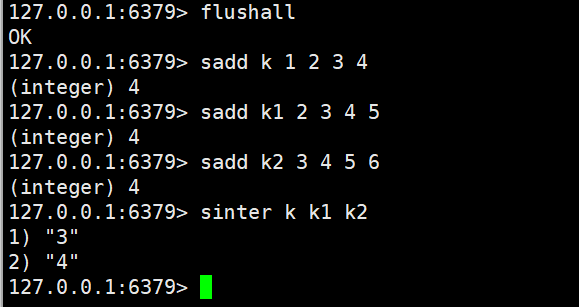
sinter
sinter key [key ...](交集)
- 功能:计算所有输入 Set 的 “交集”—— 仅保留 “在所有 Set 中都存在” 的元素。
- 时间复杂度:O (N*M)(N 为最小 Set 的元素个数,M 为 Set 的个数)。
- 返回值:交集元素列表(无交集或 Key 不存在时返回空列表)
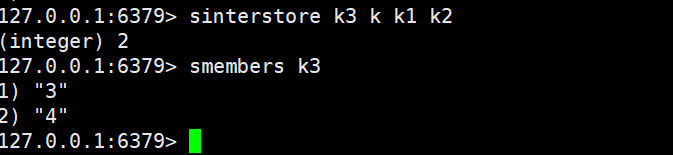
sinterstore
sinterstore destination key [key ...](交集存储)
- 功能:与sinter逻辑一致,计算所有 Set 的交集,但不直接返回结果,而是将交集存储到destinationSet 中;若destination已存在,会先清空原有元素。
- 时间复杂度:O(N*M)。
- 返回值:交集的元素个数(无交集时返回 0)。
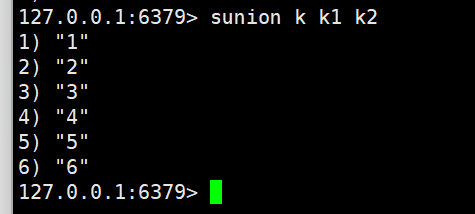
sunion
sunion key [key ...](并集)
- 功能:计算所有输入 Set 的 “并集”—— 保留 “在任意一个 Set 中存在” 的元素(自动去重)。
- 时间复杂度:O (N)(N 为所有 Set 的元素总数之和)。
- 返回值:并集元素列表(Key 不存在时视为空 Set)。
sunionstore
sunionstore destination key [key ...](并集存储)
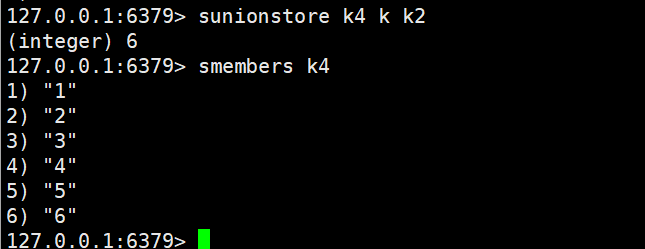
sdiff
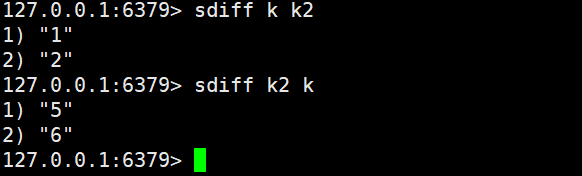
sdiff key [key ...](差集)
- 功能:计算 “第一个 Set 与后续所有 Set” 的 “差集”—— 保留 “仅在第一个 Set 中存在,且在后续 Set 中均不存在” 的元素。
- 时间复杂度:O (N)(N 为所有 Set 的元素总数之和)。
- 返回值:差集元素列表(Key 不存在时视为空 Set)。
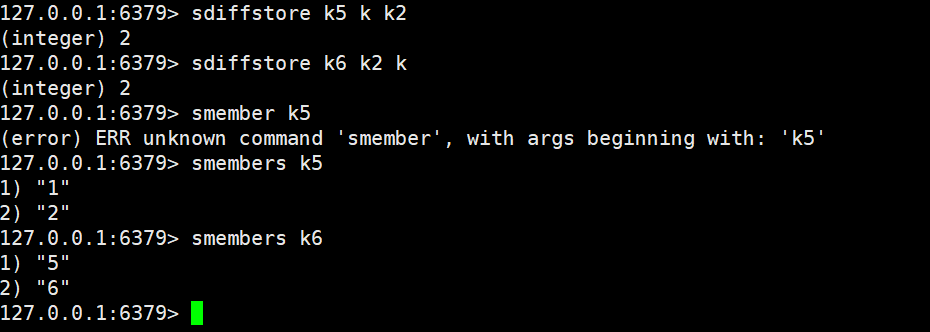
sdiffstore
sdiffstore destination key [key ...](差集存储)
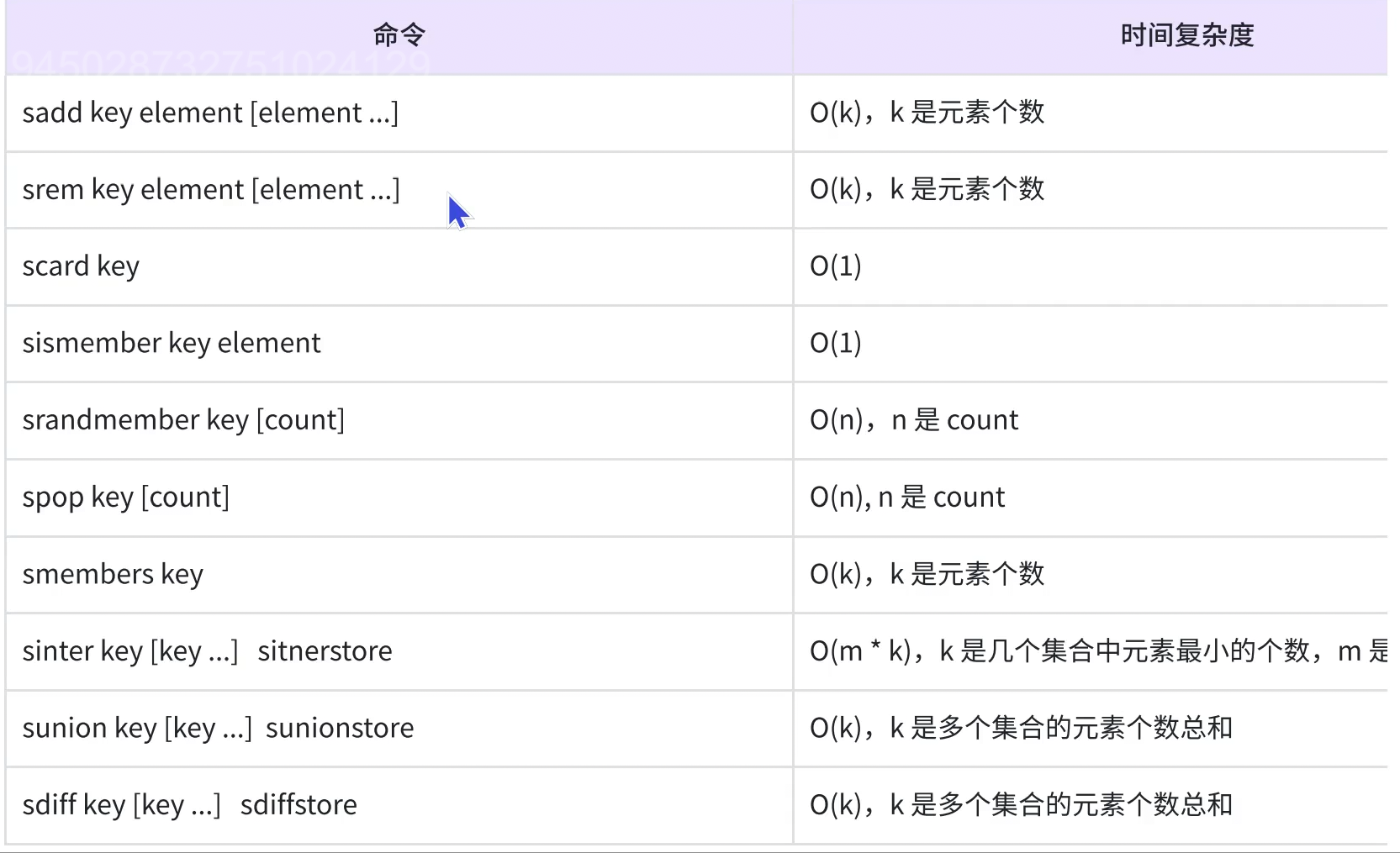
3.5 命令小结
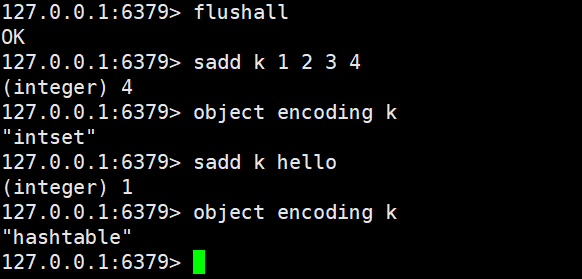
4. Set 类型的底层编码
intset(整数集合) 为了节省空间,做出的特定优化
当元素均为整数,并且元素个数不多的时候
hashtable(哈希表)
Redis 为 Set 设计了两种底层编码,根据 “元素类型” 和 “元素数量” 自动切换,核心目标是 “小数据省内存,大数据保性能”,与 String、List 的编码优化逻辑一致。
与其他语言 Set 的底层差异
- C++ std::set:底层基于红黑树,核心特性是 “有序(按值排序)+ 去重”,适合需要排序的场景,但增删查时间复杂度为 O(logN);
- Java HashSet:底层基于哈希表(数组 + 链表 / 红黑树),特性是 “无序 + 去重”,增删查时间复杂度为 O (1),与 Redis Set 的hashtable编码逻辑类似;
- Java TreeSet:底层基于红黑树,特性是 “有序(按自然顺序或自定义排序)+ 去重”,类似 C++ std::set。
5.应用场景
5.1 使用Set来保存用户的 ”标签“
比如 用户画像
根据你平时的点击,评论,分享,观看时长…等,分析你的特征,再投其所好~~
根据收集到的用户特征,转换成“标签” —》简短的字符串—》保存到set中。
5.2 使用Set来计算用户间的共同好友~
基于集合求交集
QQ:把共同好友多的人相互推荐
5.3 使用Set统计 UV
基于 去重 ~
一个互联网产品,如何衡量用户量,用户规模?
主要两个指标:
1.PV page view 用户每次访问该服务器都会产生一个pv
2.UV user view 每个用户访问服务器,产生一个uv,但是同一个用户多次访问,uv不会增加
uv需要按照用户进行去重,去重过程可以使用set来实现。
5.4 随机筛选(抽奖、随机推荐)
Set 的spop和srandmember命令支持 “随机操作”,适合 “随机抽奖”“随机推荐内容” 等场景 —— 无需额外维护随机数逻辑,Redis 直接提供高效的随机筛选能力。
5.5 业务场景
Set 类型的核心价值在于 “去重” 和 “关系计算”,选择是否用 Set,需判断业务需求是否符合以下特征:
- 需求 1:“数据不能重复”(如 UV 统计、用户标签)——Set 的元素唯一性天然满足;
- 需求 2:“需计算多个数据集的交集 / 并集 / 差集”(如共同好友、标签匹配)——Set 的sinter、sunion等命令高效支持;
- 需求 3:“需随机筛选数据”(如抽奖、随机推荐)——Set 的spop、srandmember命令无需额外开发。
6.小结
Redis Set 类型的核心价值可归纳为 “简洁高效的去重与关系计算工具”—— 它用极简的命令体系,解决了 “不重复数据存储”“多数据集关系分析”“随机筛选” 等高频业务需求,且底层编码优化保证了内存与性能的平衡。
使用 Set 类型时,需牢记三个关键建议:
- 控制 Set 大小:单个 Set 的元素个数建议不超过 10 万,超过后采用 “分桶存储”(如 UV 统计分桶),避免内存占用过高;
- 优先用scard替代smembers:统计元素个数时,scard是 O (1) 高效命令,smembers是 O (N)命令(需遍历所有元素),数据量大时避免用smembers;
- 大规模去重选HyperLogLog:若 UV、PV 等去重统计的精度要求不高(允许 0.81%左右的误差),优先用HyperLogLog(pfadd/pfcount命令),大幅节省内存。