交叉熵损失函数和负对数似然损失函数 KL散度
交叉熵损失函数和负对数似然损失函数
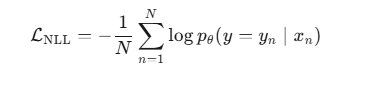
负对数似然损失函数
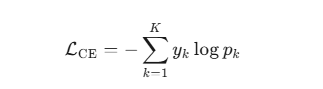
交叉熵损失函数
在分类问题,llm训练预测下一个token的任务上,只有正确位置为1,N=1,所以最终体现的数学形式一致。因此二者相等
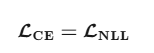
区别
他们的区别就是出发点和来源不同,交叉熵损失函数来自概率论的知识
信息量-》信息熵-》交叉熵
- 信息量:概率越低的事件发生时所含的信息量越大
- 信息熵:衡量某个事件发生的期望值,也是最优编码的编码长度 (每个字符的出现概率相等)
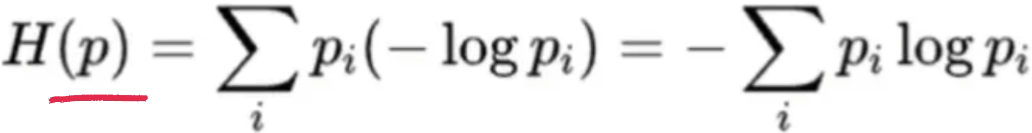
- 交叉熵:非最优的编码长度,就叫交叉熵,在p的分布下,使用q来编码的期望编码长度,也代表了用q来代表p分布所要付出的代价
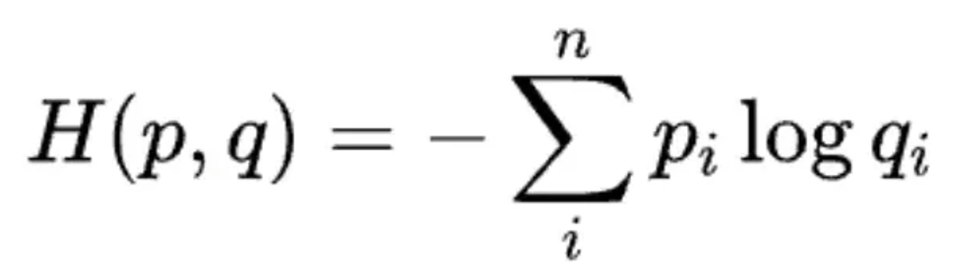
负对数似然损失函数
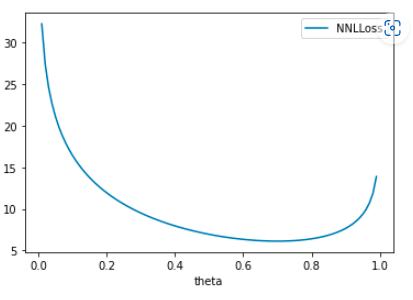
负对数似然损失函数的目标是找到到达目标的最佳参数是什么,举个例子,一个不规则的硬币,你不知道他正面与负面的概率是多少,那你就要通过数据来推这个参数(概率),下图是负对数似然损失函数的的图像,可以可以得到在0.7左右的损失是最小的,因此可以得到为正个概率是0.7
KL散度
KL散度就是交叉熵-信息熵,代表了用q来表示p的时候损失的信息量,衡量的是差异
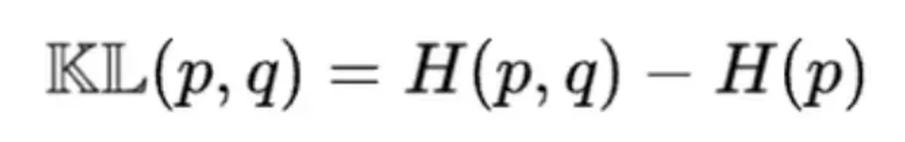
为什么不适用KL散度作为损失函数
首先KL散度不符合距离的三原则
- 1.非负性与同一性
d(x,y) ≥ 0,且 d(x,y)=0 ⇔ x=y
(距离不能是负数,且只有到自己才为零) - 2.对称性
d(x,y) = d(y,x)
(A到B多远,B到A就多远) - 3.三角不等式
d(x,z) ≤ d(x,y)+d(y,z)
(绕路不会更近)
KL散度不对称,用q来代表p和用p来代表q的差异是不相等的,KL散度是一种差异,而不是距离,差异会随着数据线性增大或减小,导致梯度爆炸或者消失,因而影响模型的训练效率
为什么softmax之后经常接交叉熵损失
首先交叉熵损失接收的输入是概率,利用softmax把模型输出转化为概率,其次softmax和交叉熵损失的组合,他们的导数形式非常简单,有利于模型的训练和加速
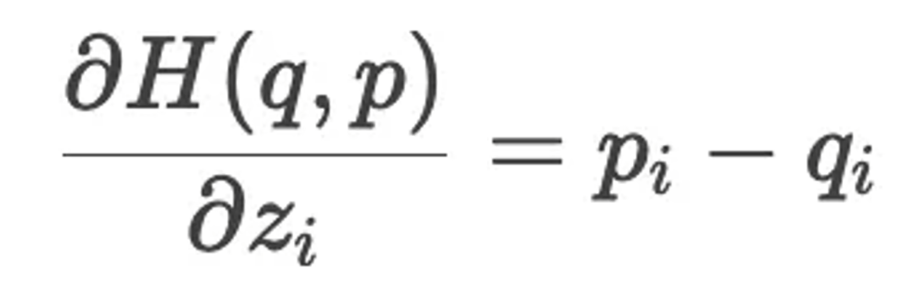
也就是预测标签分布与真实标签分布的差
KL散度在loss中的形式
在PPO中,KL散度是提前在奖励中的,先把KL散度减去,最终是作为label让模型学习的
在GRPO中,KL散度是在损失函数中作为正则化项来让模型不要偏离原模型太远
在DPO中,通过数学的方式约掉了KL散度,所以在π_new/π_old这里隐含了KL散度
KL散度不计算梯度,与上述的KL散度不作为损失函数的原因相同,所以不矛盾