【编译原理笔记】1.2 The Structure of Compiler
龙书中1.2节的标题是:The Structure of a Compiler。
其核心主题是编译器如何通过分析(Analysis)和综合(Synthesis)两个阶段将源代码转换为目标代码,并简要介绍了各子阶段的功能,关于编译器的各子阶段的详细介绍放在了后面章节中。
一、编译器的两阶段核心框架
1.1 分析阶段(Analysis)
任务:将源代码分解为语法和语义单元,生成中间表示(Intermediate Representation, IR)。
关键步骤:
词法分析(Lexical Analysis):将字符流转换为词法单元(Tokens)(如 if 、 = 、 id )。
语法分析(Syntax Analysis):根据语法规则构建语法树(Parse Tree)。
语义分析(Semantic Analysis):检查类型一致性、作用域规则等。
1.2 综合阶段(Synthesis)
任务:从中间表示生成目标代码,可能包含优化。
关键步骤:
中间代码生成(Intermediate Code Generation):生成与机器无关的抽象代码(如三地址码)。
代码优化:提升性能(如删除冗余计算)。
目标代码生成:转换为特定机器的汇编或机器码。
二、编译器各主要子阶段
编译器各主要子阶段包括:
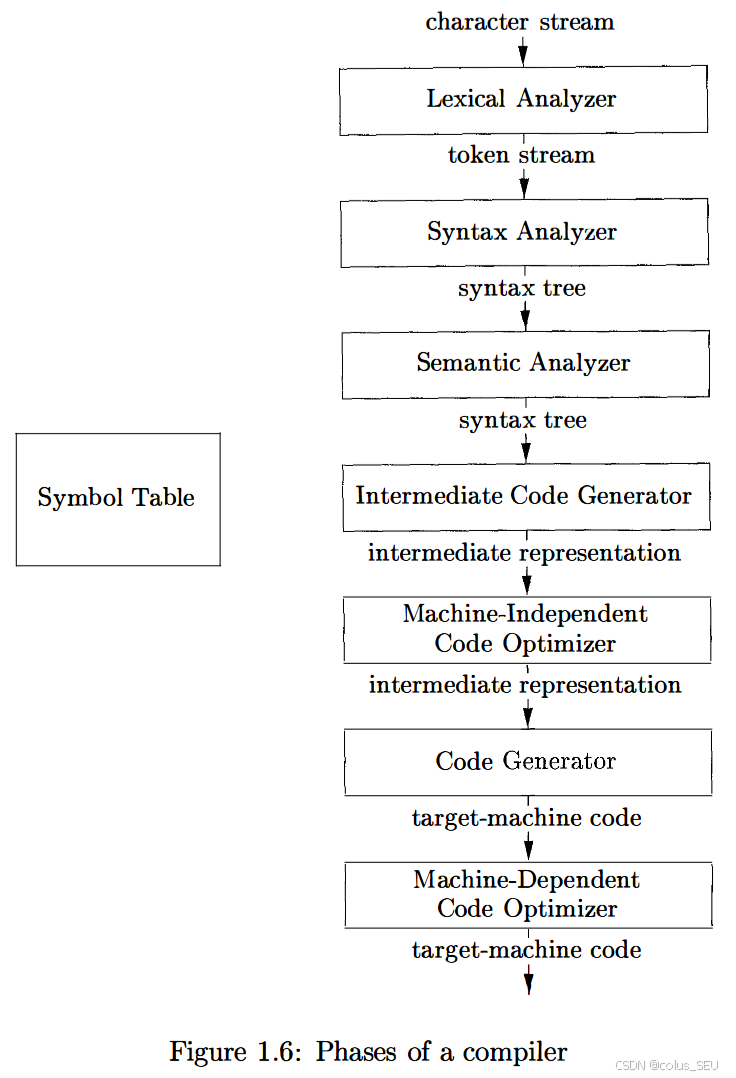
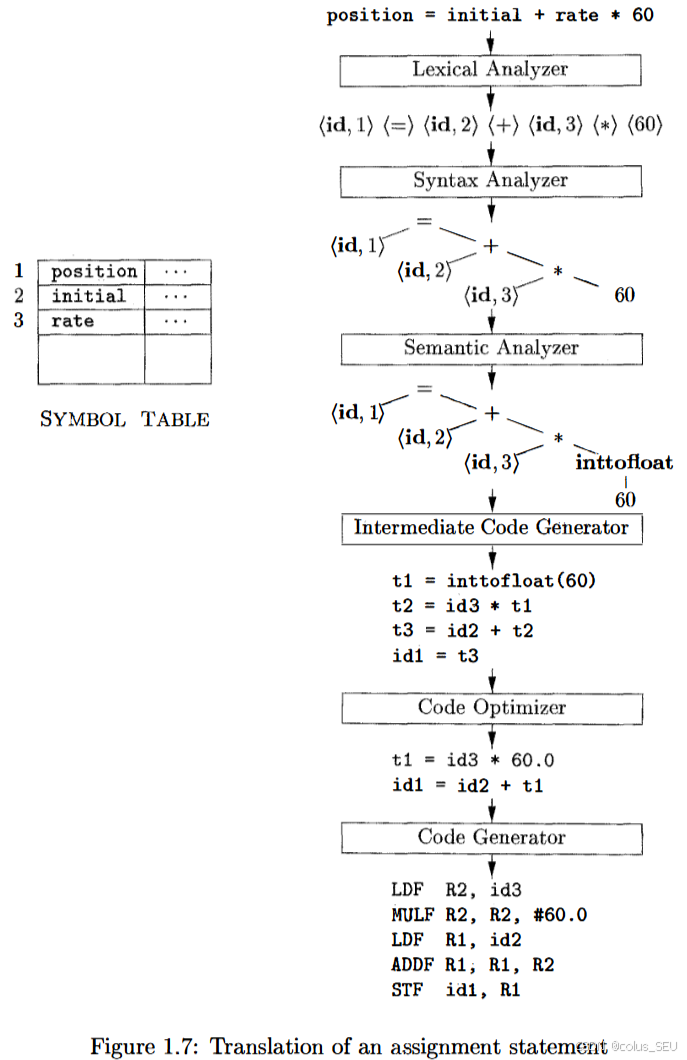
接下来我们对主要子阶段进行简要介绍,以下例子将贯穿整个介绍过程:
2.1 Lexical Analysis
2.1.1 词法分析的核心作用
scanner:词法分析器(有时也认为:scanner = preprocessor[书中1.1节将到的预处理器] + 词法分析器)
输入:源代码字符流(如 position = initial + rate * 60 )
输出:Token序列(如 ⟨id,1⟩ ⟨=⟩ ⟨id,2⟩ ⟨+⟩ ⟨id,3⟩ ⟨*⟩ ⟨60⟩ )
核心任务:
分组字符:将连续字符组合为有意义的词素(Lexeme)。
过滤无关内容:跳过空格、注释、换行等非逻辑字符。
符号表管理:记录标识符信息(名称、类型、内存位置等)。
文档引用(第6页):
“The lexical analyzer reads the input characters and groups them into lexemes, producing tokens passed to the parser.”
2.1.2 Token的结构与生成
Token格式: ⟨token_name, attribute_value⟩
token_name :语法分析使用的抽象符号(如 id 表示标识符)。
token-name is an abstract symbol that is used during syntax analysis
attribute_value :符号表指针或字面值(如 id 指向符号表中 position 的条目)。
attribute-value points to an entry in the symbol table for this token
示例:
| 源代码词素 | Token输出 | 说明 |
|---|---|---|
| position | ⟨id,1⟩ | 符号表索引1指向 position |
| = | ⟨=⟩ | 无属性值 |
| 60 | ⟨60⟩ | 直接存储字面值 |
关键点:
运算符/关键字通常无属性值(如 ⟨+⟩ )。
标识符和常量需关联符号表或存储值。
2.1.3 总结
核心价值:将字符流转换为有意义的Token流,为语法分析提供结构化输入。
技术要点:
正则表达式定义词素规则
有限自动机实现高效匹配
符号表管理标识符生命周期
文档关联:
第3章详解正则表达式与自动机理论。
第2.6节提供词法分析器完整代码实例。
2.2 Syntax Analysis
2.2.1 语法分析的核心作用
Parser(语法分析器)
输入:词法分析生成的 Token序列(如 ⟨id,1⟩ ⟨=⟩ ⟨id,2⟩ ⟨+ ⟩ ⟨id,3⟩ ⟨*⟩ ⟨60⟩ )
输出:语法树(Parse Tree) 或 抽象语法树(AST)
The parser reads the stream of tokens generated by the scanner, and groups the tokens into sentential forms represented as a syntax tree by the construction laws of the programming language.
核心任务:
验证结构合法性:检查Token序列是否符合语言的语法规则(如括号匹配、运算符位置)。
构建层次结构:将线性Token流转换为树形结构,反映代码的嵌套关系。
错误恢复:检测并报告语法错误(如缺少分号),尝试恢复解析。
文档引用(第8页):
“The parser uses the first components of the tokens to create a tree-like intermediate representation that depicts the grammatical structure.”
2.2.2 总结:
语法分析是编译器的核心阶段,连接词法分析与语义分析。
树形结构(Parse Tree/AST)是后续阶段的基础数据结构。
错误恢复能力直接影响用户体验(如IDE的实时错误提示)。
文档关联:
第4章详解各类解析算法(LL/LR)。
第2.5节提供递归下降解析器的完整实现。
2.3 Semantic Analysis
2.3.1 语义分析的核心作用
输入:语法分析生成的 语法树(AST)
输出:带语义标注的语法树 或 中间表示(IR)
Uses the syntax tree and the information in the symbol table to check the source program for semantic consistency with the language definition. It also gathers type information and saves it in either the syntax tree or the symbol table.
核心任务:
验证语义合法性:检查程序是否符合语言定义(如类型匹配、作用域规则)。
补充语义信息:为语法树节点添加类型、符号表引用等属性。
隐式转换处理:自动插入类型转换节点(如 int → float )。
文档引用(第8页):
“The semantic ana**lyzer uses the syntax tree and symbol table to check for semantic consistency with the language definition.”
2.3.2 语义分析的关键任务
2.3.2.1 类型检查(Type Checking)
规则验证:
运算符操作数类型匹配(如 a + b 需 a 和 b 为数值类型)。
函数调用实参与形参类型一致。
文档示例(第9页):
float position, initial, rate; position = initial + rate * 60; // 60需隐式转换为float
语义分析插入转换节点: rate * inttofloat (60) 。
2.3.2.2 作用域分析(Scope Analysis)
符号表管理:
块作用域(如 { int x; } 中 x 仅内部可见)。
嵌套作用域查找(优先当前作用域,逐步向外)。
文档示例(第90页):
{ int x; { float x; } } // 内层x覆盖外层 2.3.2.3 声明与使用匹配
变量先声明后使用:未声明变量报错(如 undeclared variab le 'y' )。
唯一性检查:禁止重复声明(如 int x; float x; )。
2.3.2.4 控制流检查
循环/条件语句合法性:
break 必须在循环内。
return 类型匹配函数声明。
文档关联:
第6章详解类型系统和符号表实现。
第2.3节提供属性文法的完整案例。
2.4 Intermediate Code Generation
中间代码生成的核心作用
输入:语义分析后的 带标注语法树 或 抽象语法树(AST)
输出:与机器无关的中间表示(IR)(如三地址码、P-代码、DAG)
核心任务:
桥梁作用:隔离前端(语言相关)与后端(机器相关),提升可移植性。
优化基础:为后续机器无关优化提供结构化表示。
简化目标代码生成:通过规范化降低后端复杂度。
文档引用(第9页):
“Intermediate code should be easy to produce and easy to translate into the target machine.”
文档关联:
第6章详解三地址码生成算法。
第8章讨论中间代码优化技术。
2.5 Code Optimization
代码优化的核心目标
输入:中间表示(如三地址码、AST)
输出:更高效的中间代码或目标代码
优化目标:
性能提升:减少执行时间(如CPU周期、内存访问)。
资源节省:降低内存占用、功耗或代码体积。
保持语义:确保优化前后程序行为一致。
文档引用(第10页):
“The optimizer attempts to improve the intermediate code so that better target code results.”
文档关联:
第9章:数据流分析与全局优化。
第10章:指令级并行优化。
2.6 Code Generation
代码生成的核心任务
2.6.1 指令选择(Instruction Selection)
目标:将中间代码的操作映射到目标机器的具体指令。
2.6.2 寄存器分配(Register Allocation)
目标:将频繁使用的变量分配到有限的CPU寄存器,减少内存访问。
算法:图着色(Graph Coloring)是经典方法。
2.6.3 指令调度(Instruction Scheduling)
目标:重排指令以避免流水线停顿(Pipeline Stall)。
关联章节:
第8章:代码生成基础(指令选择、寄存器分配)。
第9章:机器无关优化(为代码生成提供高效中间表示)。
第10章:指令级并行优化(调度、流水线)。
总结
代码生成是将编译器前端、中端的成果转化为可执行代码的最后一步,需平衡 效率(指令速度)、空间(代码大小)和 可维护性(调试信息)。现代编译器(如GCC、LLVM)通过多阶段协作(指令选择 → 寄存器分配 → 调度 → 窥孔优化)生成高质量机器码。