大模型训练流程及GPU内存解析(110)
训练流程简概
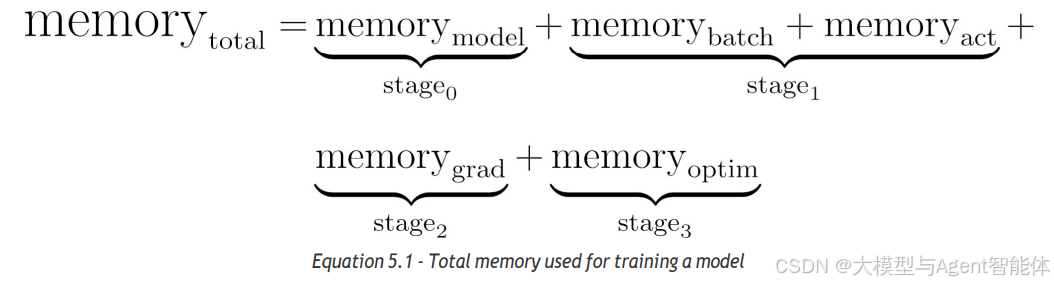
训练一个模型需经历以下基本阶段:
- 阶段0:加载模型。
- 阶段1:加载一个小批量数据(mini-batch),执行前向传播(forward pass)以生成预测结果。
- 阶段2:计算梯度(通过反向传播,即PyTorch中的backward()方法实现)。
- 阶段3:使用优化器更新参数,常用优化器为Adam及其变体。
- 阶段4:将梯度重置为零。
- 阶段5:循环重复(回到阶段1)。
需要注意的是,随着训练流程逐阶段推进,对内存的需求会逐渐增加;但阶段4和阶段5不需要额外内存。
在训练小型模型且 GPU 内存充足时,情况自然一切顺利。但如果要从零开始训练大型模型,第 3 阶段就会成为关键环节:Adam 优化器可能会占用大量内存空间,因为它需要跟踪每个可训练参数的梯度运行统计信息(均值和方差),以便动态调整学习率。如果你遇到了 OOM(内存不足,out-of-memory)错误,通常就是在这个阶段发生的。

“参数越多,麻烦越多。”
如果Adam优化器是问题所在,我们能对其进行改进吗?事实证明,答案是肯定的。还记得当初我们觉得模型