【目标检测2025】
yolo2026
https://www.ultralytics.com/yolo
https://docs.ultralytics.com/zh/models/yolo26/#overview
https://github.com/ultralytics/ultralytics/blob/main/docs/en/models/yolo26.md
动机
YOLO26旨在为边缘和低功耗设备提供一种实时物体检测解决方案。它通过简化模型架构,消除不必要的复杂性,并集成有针对性的创新技术,以实现更快、更轻、更易部署的模型。
方法
架构简化:YOLO26采用原生端到端模型设计,无需非最大抑制(NMS)即可直接生成预测结果,简化了推理过程。
部署效率:端到端设计减少了整个处理流程的阶段,降低了延迟,并简化了不同环境下的部署。
训练创新:引入了MuSGD优化器,结合SGD和Muon,灵感来自Moonshot AI的Kimi K2,提高了训练稳定性和收敛速度。
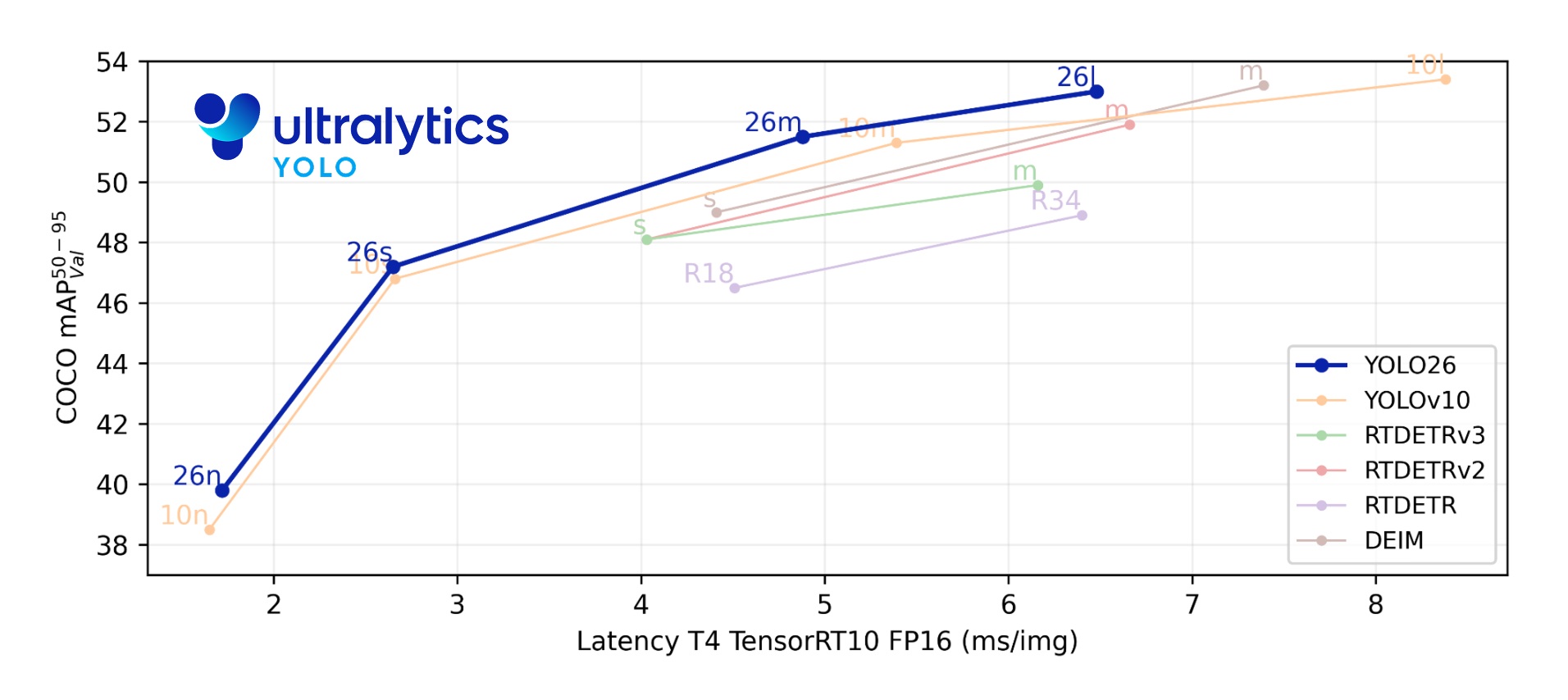
性能优化:通过移除DFL模块、采用ProgLoss + STAL损失函数,以及针对CPU推理的优化,YOLO26在CPU上的运行速度提高了43%。
实验
文档中提到YOLO26的性能数据为早期预览,最终数据和可下载权重将在训练完成后发布。目前,YOLO26在COCO数据集上使用80个预训练类进行训练,但具体的实验结果和基准测试尚未公布。
结论
YOLO26通过其创新的架构设计和优化策略,在小型物体检测精度、部署效率和CPU推理速度上实现了显著提升。它被认为是迄今为止在资源有限环境中最实用、最易部署的YOLO模型之一。然而,由于模型仍在开发中,具体的性能指标和实验结论尚未最终确定。

DINOv3
https://ai.meta.com/dinov3/
动机 (Motivation)
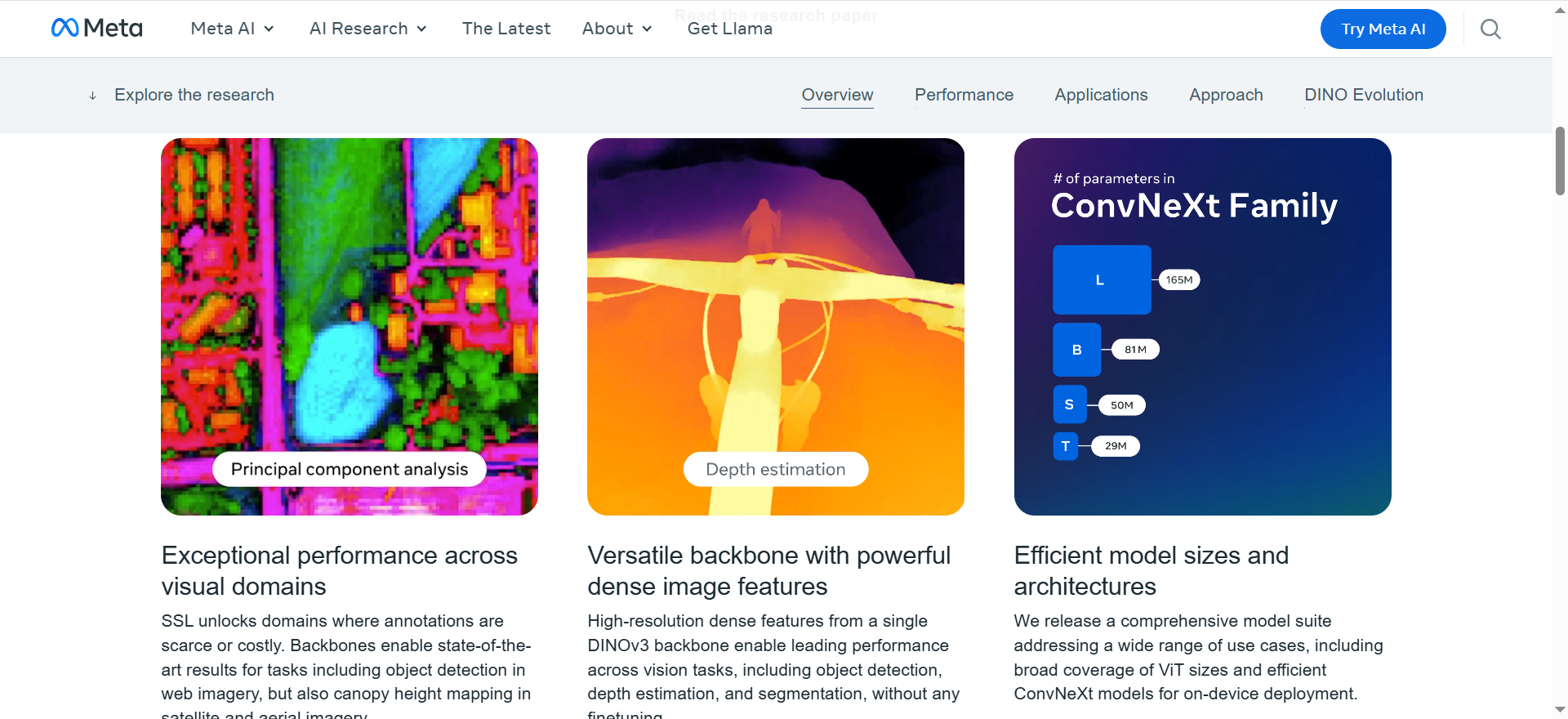
自监督学习的潜力与挑战:自监督学习(SSL)有望消除对人工数据标注的需求,使模型能够轻松扩展到大规模数据集和更大的架构。然而,传统的SSL方法在扩展到大型模型和长时间训练时,会遇到密集特征(即空间分辨率较高的特征图)质量退化的问题,这限制了其在需要精确定位信息的下游任务(如目标检测、语义分割)中的应用。
通用视觉基础模型的需求:领域需要一个能够跨任务和领域、无需微调即可提供卓越性能的通用视觉编码器。现有的SSL模型在密集特征表示方面存在不足,无法完全满足这一需求。
方法 (Method)
DINOv3 的核心技术创新围绕三个关键方面:
大规模数据与模型协同扩展:
数据策略:采用三重数据策划策略,包括聚类策划(clustering curation)、检索策划(retrieval curation)和标准数据集的混合,以确保训练数据的多样性和质量。
模型架构:使用包含高达70亿参数的Vision Transformer (ViT) 架构,实现模型规模的显著扩展。
Gram锚定(Gram Anchoring)技术:
问题:在长时间训练过程中,密集特征图的质量会退化,导致空间定位能力丧失。
解决方案:引入Gram锚定技术,通过约束patch特征间的Gram矩阵相似性结构,保持特征的空间结构信息,从而有效解决密集特征退化问题,使模型在保持全局语义理解能力的同时,维持精确的空间定位能力。
多阶段训练策略:
基础自监督训练:首先进行基础的自监督预训练。
Gram锚定细化:在训练过程中引入Gram锚定,以细化特征表示。
高分辨率适应:进行高分辨率图像的适应训练,以提升模型在高分辨率场景下的性能。
知识蒸馏:最后通过知识蒸馏进一步优化模型,产生真正通用的视觉编码器。
实验 (Experiments)
论文在多种视觉任务上评估了DINOv3的性能,包括图像分类、目标检测、语义分割和深度估计等。实验结果表明:
无需微调的最优性能:DINOv3在无需任务特定微调的情况下,在多种任务上均达到了最先进的性能,显著超越了以往的自监督和弱监督基础模型,甚至超过了一些使用额外监督信号的方法(如掩码标注先验)。
高质量的密集特征:DINOv3能够产生高质量的密集特征,这些特征在空间上具有丰富的细节,能够精确捕捉物体边界、纹理细节和空间关系。
高分辨率特征支持:模型支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景。
结论 (Conclusion)
DINOv3是一个突破性的自监督视觉基础模型,通过大规模数据与模型协同扩展、Gram锚定技术和多阶段训练策略,成功解决了传统SSL在规模化时的稳定性问题和密集特征退化问题。该模型能够产生高质量的密集特征,在无需微调的情况下,在多种视觉任务上达到最先进的性能,为计算机视觉领域树立了新的技术标杆。此外,研究团队还分享了DINOv3系列模型,旨在为不同资源和部署场景提供可扩展的解决方案,推动视觉基础模型的广泛应用。