【Linux】库的制作与原理(2)
1. 目标文件
在 Windows 中,IDE 会封装编译和链接步骤,一键构建虽便捷,但遇到链接错误时易束手无策;而在 Linux 下,我们可通过 gcc 深入操作这两个过程,理解其原理能更好掌握动静态库的使用。
首先回顾编译:它是将源代码翻译成 CPU 可直接运行的机器代码的过程。比如有两个源文件 hello.c 和 code.c,hello.c 中调用了 code.c 里定义的 run 函数,此时用 gcc -c hello.c 和 gcc -c code.c 分别编译这两个文件,会生成 hello.o 和 code.o 两个后缀为 .o 的文件,这就是目标文件。
目标文件有两个关键特点:一是修改单个源文件时,只需单独编译对应的目标文件,无需重新编译整个工程,能节省时间;二是它是 ELF 格式的二进制文件,可通过 file 目标文件名.o 命令查看(如 file hello.o 会显示其为 64 位 ELF 可重定位文件),这种格式是对二进制代码的封装,为后续链接成可执行文件或库文件做准备。
2. ELF文件
要掌握编译与链接的细节,必须了解 ELF 文件—— 它是 Linux 系统中多种关键文件的统一格式,也是连接源代码、目标文件与最终程序 / 库的核心桥梁。
2.1 ELF 文件的四种常见类型
ELF 并非单一文件格式,而是涵盖了四类功能不同的文件,覆盖了程序从编译到运行的全流程:
- 可重定位文件(Relocatable File):即我们熟悉的
xxx.o目标文件,包含代码和数据,需与其他目标文件链接后,才能生成可执行文件或动态库。 - 可执行文件(Executable File):直接能运行的程序(如编译生成的
a.out或自定义命名的可执行文件),加载到内存后即可被 CPU 执行。 - 共享目标文件(Shared Object File):即动态库
xxx.so,可在程序运行时被动态加载,供多个程序共享使用,减少内存占用。 - 内核转储(Core Dumps):当程序异常崩溃时生成的文件,保存了进程崩溃时的执行上下文(如内存数据、寄存器状态),用于后续调试定位问题。
2.2 ELF 文件的四大核心组成部分
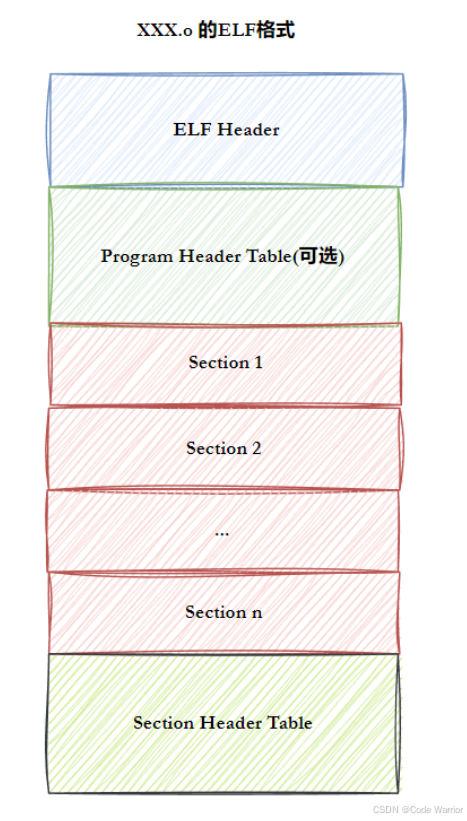
所有 ELF 文件都遵循统一的结构,由四部分组成,各部分分工明确,确保文件能被系统正确解析:
- ELF 头(ELF Header):位于文件最开头,是 ELF 文件的 “身份卡”—— 描述文件类型(如目标文件 / 可执行文件)、架构(如 x86-64)、大小端模式等关键信息,同时提供指针,定位文件其他部分(如程序头表、节头表)的位置。
- 程序头表(Program Header Table):为 “加载器” 服务,记录文件中所有 “段(Segments)” 的信息(如段的起始地址、大小、权限)。段是内存加载的基本单位,加载器通过这张表,将 ELF 文件中的数据和代码映射到内存的对应区域。
- 节头表(Section Header Table):为 “链接器” 服务,记录文件中所有 “节(Sections)” 的信息(如节的名称、类型、大小、偏移)。节是文件存储的基本单位,链接器通过这张表,找到需要合并或重定位的代码、数据等内容。
- 节(Section):ELF 文件的最小数据单元,不同类型的节存储不同用途的数据,常见核心节包括:
- .text 节(代码节):存放编译后的机器指令,是程序执行的核心部分,权限为 “只读可执行”。
- .data 节(数据节):存放已初始化的全局变量和局部静态变量(如
int a = 10;),权限为 “可读可写”。 - 此外还有
.bss节(存放未初始化的全局 / 静态变量,仅占表项不占文件空间)、.rodata节(存放只读常量,如字符串字面量)等。
2.3 查看 ELF 文件的关键工具:size 命令
通过 size 命令可快速查看 ELF 文件中核心节(.text、.data、.bss)的大小,帮助了解程序的代码和数据占用情况。例如查看可执行文件 code:
bash
$ size codetext data bss dec hex filename3312 636 4 3952 f70 code
text:.text 节大小(机器指令占用空间);data:.data 节大小(已初始化数据占用空间);bss:.bss 节大小(未初始化数据的 “占位大小”);dec/hex:text+data+bss的总和(十进制 / 十六进制)。
3. ELF 从形成到加载轮廓
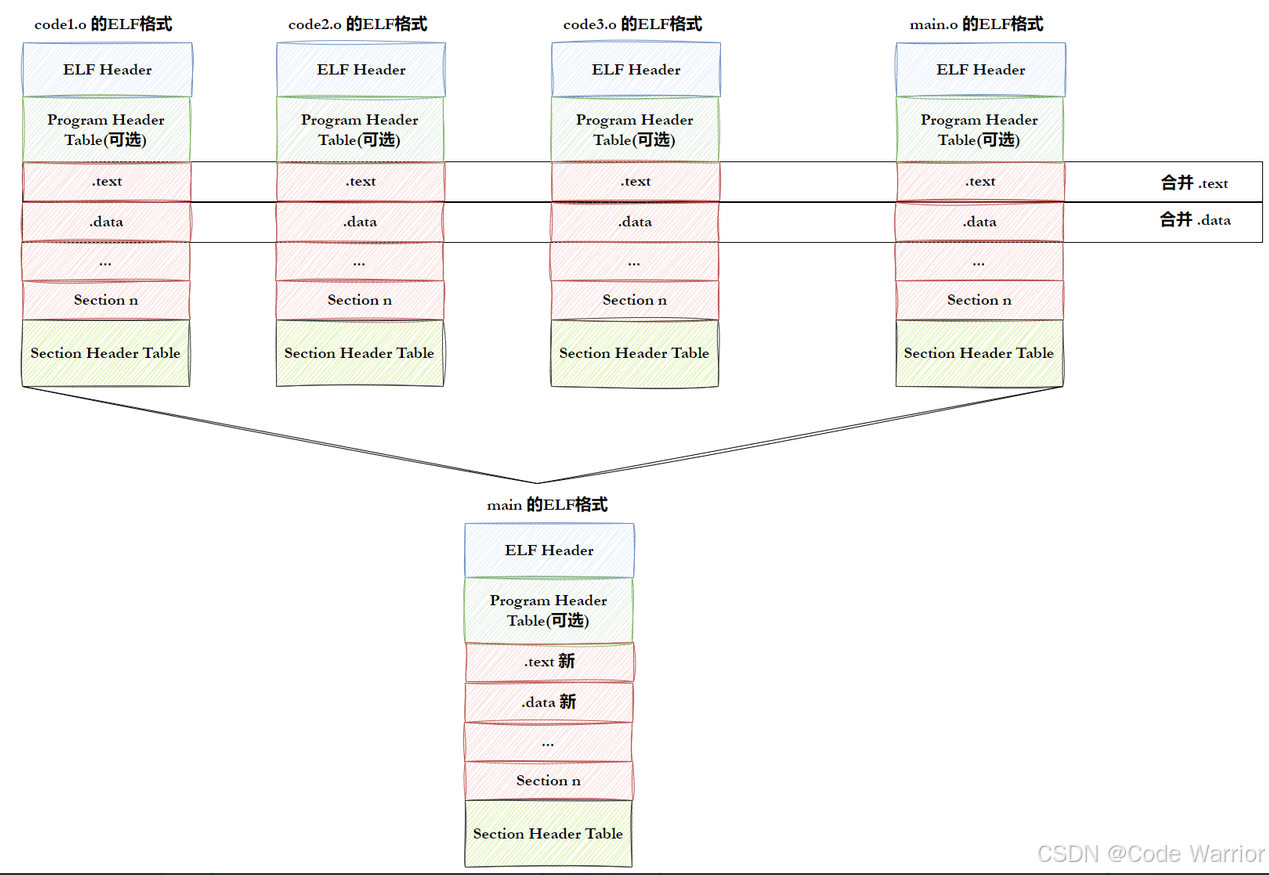
3.1 ELF 形成可执行文件的过程
- step-1:生成基础 ELF 文件将多份 C/C++ 源代码,通过编译(如
gcc -c)翻译为.o目标文件(可重定位 ELF),同时准备好所需的动静态库(同样属于 ELF 格式)。 - step-2:合并目标文件的节(Section)链接阶段会将多份
.o文件中的节进行整合(如多个.text节、.data节分别合并),同时融入动静态库的相关代码与数据,最终生成可执行 ELF 文件。注意:实际合并不仅是简单拼接,还包含符号解析、重定位等操作,涉及库的合并逻辑此处暂不深入。
3.2 ELF 可执行文件的加载过程
- 节(Section)合并为段(Segment)ELF 可执行文件包含多种功能不同的节(如
.text、.data、.rodata),加载到内存时,操作系统会按 “相同属性”(如只读、可写、可执行,或需加载时申请空间)将这些节合并成段。例如,.text(可执行)与.rodata(只读)会合并为 “只读可执行段”,.data与.bss(均为可读写)会合并为 “可读写段”。 - 合并规则的来源节如何合并成段的规则,在 ELF 生成时已确定,具体记录在 程序头表(Program header table) 中,操作系统加载时会依据该表完成合并与内存映射。
3.3 查看 ELF 节与段的工具
- 查看节(Section):执行
readelf -S a.out,可列出所有节的名称、类型、地址、偏移等信息(示例中a.out含 31 个节,如.interp、.dynsym、.text等)。 - 查看段(Segment):执行
readelf -l a.out,可查看所有段的类型、偏移、虚拟地址、权限及 “节到段的映射关系”(如 Segment 02 对应.text、.rodata等多个节)。
3.4 为何要将节合并为段?
- 减少内存碎片,提升效率内存以 “页(如 4KB)” 为基本管理单位,若单个节很小(如
.init仅 512 字节),单独加载会浪费内存。合并后多个小节能共享一个内存页(如 4097 字节的.text+ 512 字节的.init合并后仅需 2 个页,而非 3 个)。 - 统一权限管理按属性合并后,操作系统可对整个段设置统一权限(如 “只读可执行”“可读写”),简化内存权限控制,提升安全性。
3.5 ELF 的两大视图:链接视图与执行视图
ELF 通过 “双视图” 适配不同场景,核心是 节头表 与 程序头表 的分工:
| 视图类型 | 对应表 | 作用场景 | 核心用途 |
|---|---|---|---|
| 链接视图 | 节头表(Section Header Table) | 编译链接阶段 | 按 “功能模块” 细分 ELF(如代码、数据、符号表),供链接器合并目标文件、解析符号 |
| 执行视图 | 程序头表(Program Header Table) | 运行加载阶段 | 按 “内存属性” 划分 ELF(如段的权限、地址),供操作系统加载程序到内存 |
简言之:链接视图管 “怎么合并目标文件”,执行视图管 “怎么加载到内存”。
3.6 补充:ELF 头(ELF Header)
通过 readelf -h 文件名 可查看 ELF 头信息,它是 ELF 文件的 “总目录”,记录文件类型(如可重定位 / 可执行)、架构(如 x86-64)、大小端、节头表 / 程序头表的起始位置等关键信息,用于定位 ELF 的其他部分。
- 示例:目标文件
hello.o的 ELF 头中,程序头表条目数为 0(无需加载);可执行文件a.out的 ELF 头中,有明确的程序入口地址和程序头表信息。
注意:需理解 ELF 各区域与文件偏移量的对应关系,这是解析 ELF 结构的关键。
4. 理解链接与加载
4.1 静态链接
静态链接的核心是将多个目标文件(.o)及依赖的静态库中的 .o 文件整合为一个独立的可执行文件,关键步骤包括目标文件合并与地址重定位,解决模块间的符号依赖(如函数调用、全局变量引用)。
4.1.1 静态链接的本质:.o 文件的整合
无论是用户编译生成的自定义 .o 文件(如 code.o、hello.o),还是静态库(如 libxxx.a)中封装的 .o 文件,静态链接的本质都是将这些分散的 .o 文件 “拼接”,最终生成一个无外部依赖、可独立运行的可执行文件。
示例操作:从 .o 到可执行文件
通过以下命令可直观演示静态链接的完整流程:
bash
# 1. 编译源文件生成 .o 目标文件(仅编译,不链接,生成机器码但未解决符号依赖)
$ gcc -c code.c hello.c # 输出:code.o(1672字节)、hello.o(1744字节)
# 2. 链接所有 .o 文件,生成可执行文件 main.exe
$ gcc *.o -o main.exe # 输出:main.exe(16752字节,带执行权限 rwxrwxr-x)
文件状态变化如下表所示:
| 文件类型 | 操作前文件 | 操作后文件 |
|---|---|---|
| 源文件 | code.c、hello.c | 保留(未修改) |
| 目标文件 | 无 | code.o、hello.o |
| 可执行文件 | 无 | main.exe(可直接运行) |
4.1.2 未链接的 .o 文件:符号未解析与地址暂缺
编译阶段仅处理单个源文件,无法获取其他文件或库中函数的地址,因此生成的 .o 文件存在两个核心问题:符号未解析和函数调用地址暂缺,需在链接阶段解决。
1. 反汇编查看:函数地址暂缺
通过 objdump -d 文件名 反汇编 .o 文件的代码段(.text),会发现函数调用指令(callq)的目标地址被设为 00 00 00 00(暂缺状态)。
- 反汇编
code.o(含run函数,调用printf):$ objdump -d code.o code.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <run>:0: f3 0f 1e fa endbr644: 55 push %rbp5: 48 89 e5 mov %rsp,%rbp8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f <run+0xf>f: e8 00 00 00 00 callq 14 <run+0x14> # 地址暂为 00 00 00 00(printf)14: 90 nop15: 5d pop %rbp16: c3 retq - 反汇编
hello.o(含main函数,调用printf和run):$ objdump -d hello.o ... 0000000000000000 <main>:...f: e8 00 00 00 00 callq 14 <main+0x14> # 地址暂缺(printf)19: e8 00 00 00 00 callq 1e <main+0x1e> # 地址暂缺(run) ...
原因:编译时编译器仅 “看到” 单个源文件,无法知道 printf(C 库函数)或 run(其他文件函数)的实际地址,因此暂时用 0 填充,等待链接器修正。
2. 符号表查看:未定义符号(UND)
通过 readelf -s 文件名 查看 .o 文件的符号表,未定义的符号会被标记为 UND(undefined),表示该符号在当前 .o 文件中未实现,需从其他模块引用。
code.o的符号表(printf对应puts,未定义):$ readelf -s code.o Symbol table '.symtab' contains 13 entries:Num: Value Size Type Bind Vis Ndx Name...10: 0000000000000000 23 FUNC GLOBAL DEFAULT 1 run # 已定义(当前文件)12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts # 未定义(C库)hello.o的符号表(printf和run均未定义):$ readelf -s hello.o Symbol table '.symtab' contains 14 entries:...10: 0000000000000000 37 FUNC GLOBAL DEFAULT 1 main # 已定义(当前文件)12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts # 未定义(C库)13: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run # 未定义(code.o)
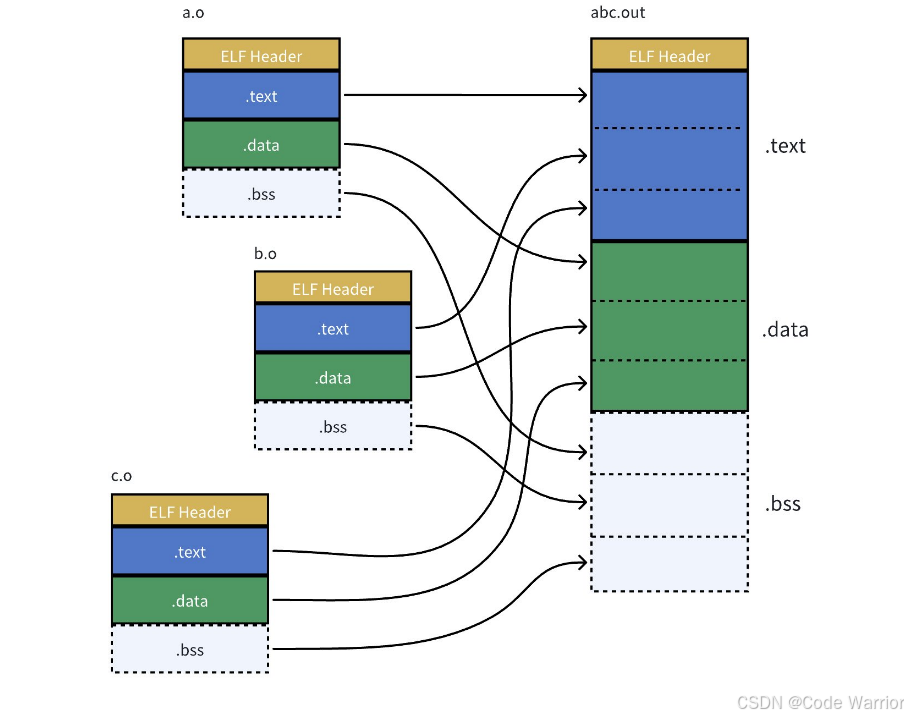
4.1.3 链接阶段:合并 .o 与地址重定位
链接器(如 ld)通过以下两步,将分散的 .o 文件转化为可执行文件:
1. 合并 .o 的段(Section)
将所有 .o 文件的相同功能段(如代码段 .text、数据段 .data、只读数据段 .rodata)合并为可执行文件的统一段,实现代码和数据的 “集中管理”。
例如,code.o 的 .text 段(含 run 函数)和 hello.o 的 .text 段(含 main 函数)会合并为 main.exe 的 .text 段。通过 readelf -S main.exe 可查看合并后的段列表:
$ readelf -S main.exe
Section Headers:[Nr] Name Type Address Offset...[16] .text PROGBITS 0000000000001060 00001060 # 合并后的代码段...
2. 修正函数地址(重定位)
链接器根据符号表,找到未定义符号(如 run、puts)的实际地址,修正 .text 段中暂缺的 callq 地址(这一过程称为 “重定位”)。
通过 objdump -d main.exe 反汇编可执行文件,可见地址已被修正:
main函数中调用run的地址从00 00 00 00改为1149(run函数的实际地址):$ objdump -d main.exe ... 0000000000001160 <main>:...1179: e8 cb ff ff ff callq 1149 <run> # 地址已修正为 1149 ... 0000000000001149 <run>: # run 函数的实际虚拟地址...1158: e8 f3 fe ff ff callq 1050 <puts@plt> # puts 地址(依赖动态库,暂用PLT) ...- 符号表中
run已标记为 “已定义”,地址明确:bash
$ readelf -s main.exe Symbol table '.symtab' contains 67 entries:...52: 0000000000001149 23 FUNC GLOBAL DEFAULT 16 run # 已定义,地址114963: 0000000000001160 37 FUNC GLOBAL DEFAULT 16 main # 已定义,地址1160 ...
4.1.4 静态链接的总结
静态链接的核心是 “合并段” 与 “修正地址”:
- 合并段:将多个
.o的相同功能段整合,形成可执行文件的统一代码段、数据段,实现模块间的 “物理整合”; - 修正地址:通过符号表解析未定义符号,重定位函数调用地址,确保程序运行时能正确跳转。
优缺点:
- 优点:可执行文件无外部依赖,可独立运行;加载速度快(无运行时链接步骤);
- 缺点:文件体积大(嵌入静态库代码);内存占用高(多个程序依赖同一静态库时,各存一份副本);库更新需重新编译链接。
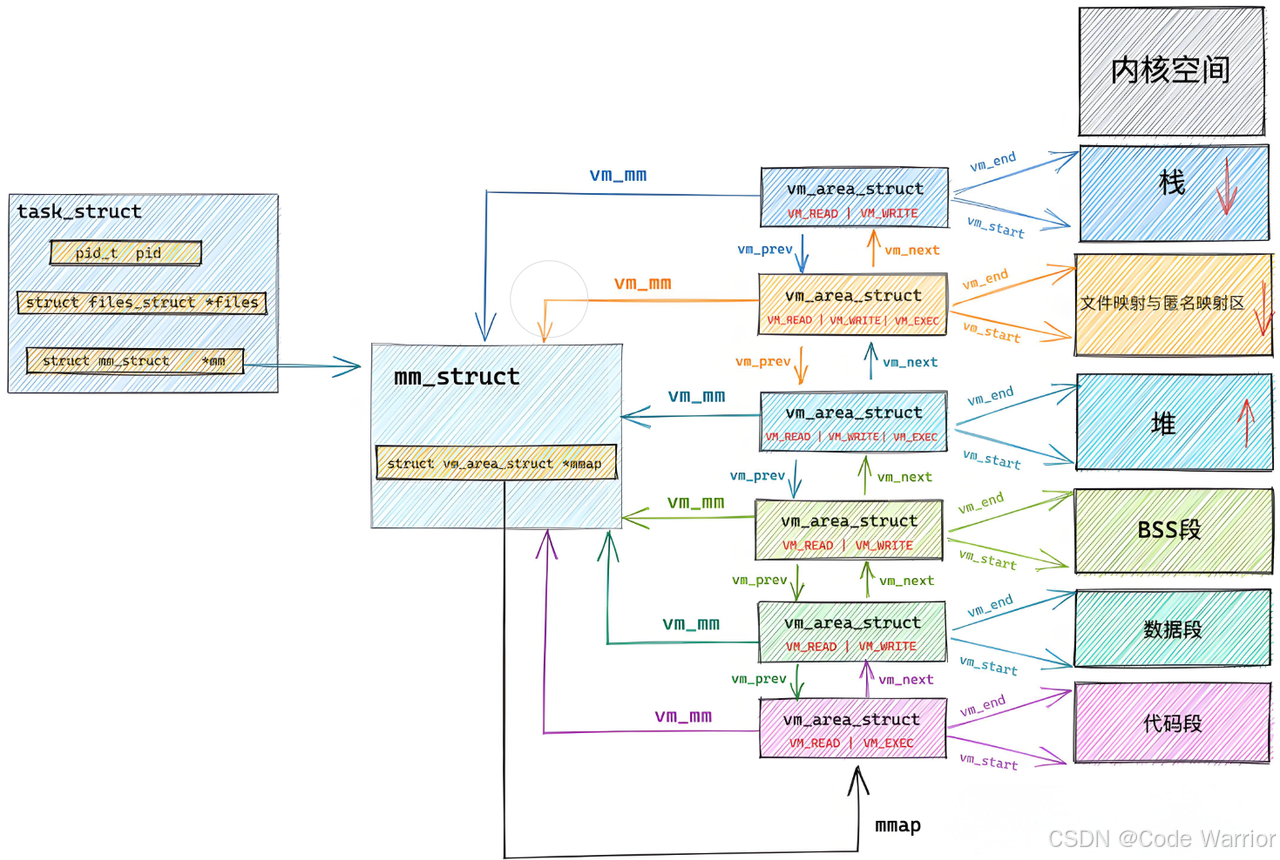
4.2 ELF 加载与进程地址空间
ELF 可执行文件在运行前需被加载到内存,加载过程依赖虚拟地址机制,并与进程的地址空间结构(mm_struct、vm_area_struct)深度绑定。
4.2.1 虚拟地址(逻辑地址):加载前已存在
关键问题 1:ELF 未加载时是否有地址?
答案:是。现代计算机采用 “平坦内存模式”,要求编译器在编译阶段就对 ELF 的代码段、数据段进行统一编址(即虚拟地址)。这些地址并非物理内存地址,而是基于 “起始地址为 0” 的逻辑偏移量,仅在加载时映射到物理内存。
例如,main.exe 的 main 函数在未加载时,虚拟地址已被编译为 0000000000001160(可通过 objdump -d main.exe 查看),这一地址在加载时会被映射到进程虚拟地址空间的代码区。
关键问题 2:进程地址空间结构的初始化数据来源?
答案:来自 ELF 的程序头表(Program Header Table)。ELF 的程序头表记录了每个 “段”(Segment,由多个功能段 Section 合并而成)的虚拟地址范围、大小、权限(读 / 写 / 执行)和文件偏移量,操作系统加载时会:
- 解析程序头表,获取各 Segment 的信息;
- 为进程创建
mm_struct(地址空间描述符,管理整个进程的虚拟地址范围); - 为每个 Segment 创建
vm_area_struct(内存区域描述符,记录单个 Segment 的虚拟地址范围、权限); - 建立虚拟地址到物理内存的页表映射,确保指令执行时能正确访问内存。
结论:虚拟地址机制是 “编译器编址 + 操作系统映射” 的协同结果,二者缺一不可。
4.2.2 重新理解进程虚拟地址空间
ELF 编译完成后,会在其头部(ELF Header)的 Entry 字段记录程序入口地址(即进程启动后第一个执行的指令地址)。通过 readelf -h main.exe 可查看:
$ readelf -h main.exe
ELF Header:...Entry point address: 0x1060 # 程序入口地址(_start 函数的虚拟地址)...
- 进程启动时,操作系统会将 CPU 的程序计数器(PC)设置为
0x1060,从_start函数(由 C 运行时库提供)开始执行; _start函数负责初始化堆栈、调用动态链接器(若为动态链接),最终调用main函数,将控制权交给用户代码;- ELF 的各 Segment 会被加载到虚拟地址空间的固定区域:代码段(
.text)加载到低地址的代码区,数据段(.data/.bss)加载到高地址的数据区,确保代码只读、数据可写的权限隔离。
4.3 动态链接与动态库加载
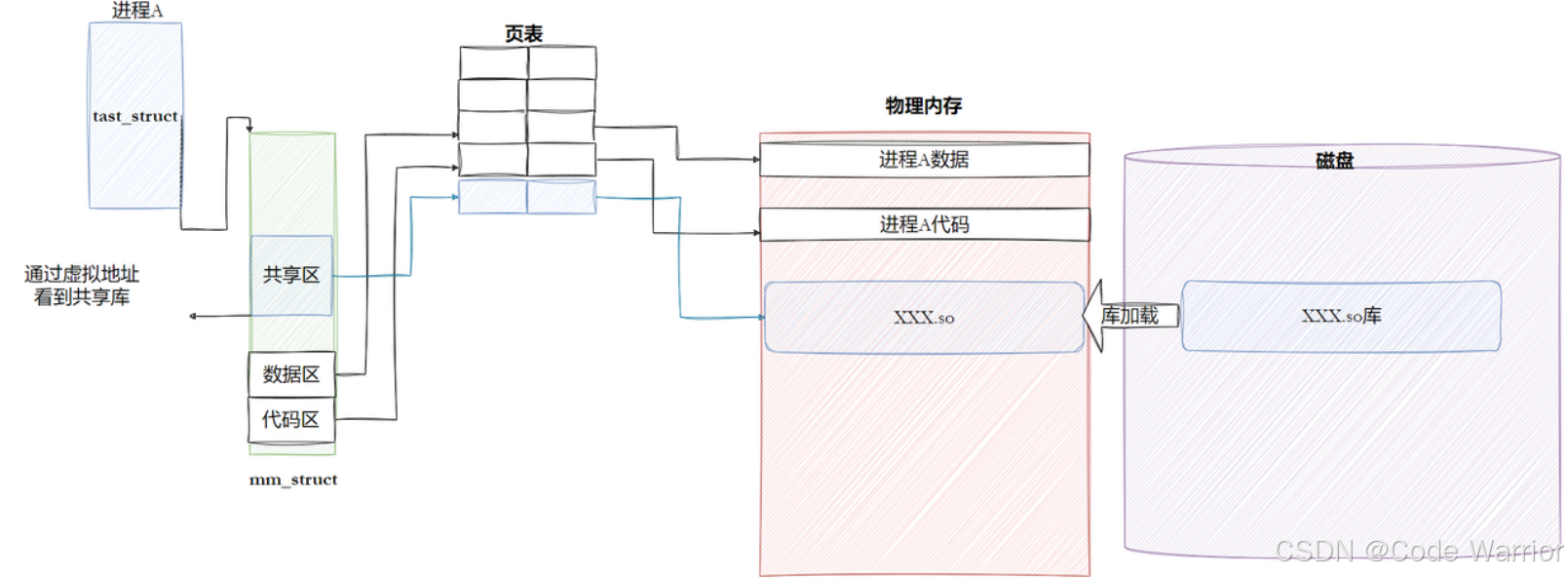
动态链接将 “链接过程” 推迟到程序运行时,不将库代码嵌入可执行文件,而是在加载时动态加载依赖的动态库(如 libc.so.6),实现库的 “跨进程共享”,大幅减少文件体积和内存占用。
4.3.1 动态链接的核心:延迟链接与库共享
1. 动态库的依赖查看
通过 ldd 命令可查看可执行文件依赖的动态库,例如 main.exe 依赖 C 标准动态库 libc.so.6:
$ ldd main.exelinux-vdso.so.1 => (0x00007ffefd43f000) # 内核提供的虚拟动态库libc.so.6 => /lib64/libc.so.6 (0x00007f533380b000) # C标准动态库/lib64/ld-linux-x86-64.so.2 (0x00007f5333bd9000) # 动态链接器
2. 动态链接 vs 静态链接(核心差异)
| 特性 | 静态链接 | 动态链接 |
|---|---|---|
| 文件体积 | 大(嵌入完整库代码) | 小(仅记录库依赖路径) |
| 内存占用 | 高(多进程各存一份库副本) | 低(库在内存中仅存一份,多进程共享) |
| 库更新 | 需重新编译链接可执行文件 | 直接替换动态库,无需修改可执行文件 |
| 启动速度 | 快(无运行时链接步骤) | 慢(需加载库、解析符号、重定位) |
| 依赖关系 | 无外部依赖 | 依赖动态库,缺失库会导致启动失败 |
4.3.2 动态链接的关键机制
1. 动态链接器(ld-linux.so)
动态链接的核心是动态链接器(如 ld-linux-x86-64.so.2),它是一个特殊的动态库,由操作系统启动,负责:
- 解析可执行文件的动态库依赖列表(从 ELF 的
.dynamic段获取); - 搜索动态库(优先从
LD_LIBRARY_PATH环境变量、/etc/ld.so.conf配置路径搜索); - 将动态库加载到进程虚拟地址空间(地址随机分配,避免内存冲突);
- 符号解析与地址重定位(修正可执行文件对库函数的调用地址)。
2. 程序启动流程:从 _start 到 main(动态链接版)
动态链接的程序启动流程比静态链接多了 “动态库加载” 步骤,完整流程如下:
- 加载可执行文件:操作系统将 ELF 加载到虚拟地址空间,读取程序头表;
- 启动动态链接器:操作系统将 PC 指向动态链接器的入口,移交控制权;
- 加载动态库:动态链接器解析依赖,加载
libc.so等动态库到内存; - 符号解析与重定位:通过
GOT/PLT机制,修正可执行文件对库函数的调用地址; - 初始化 C 运行时库:调用
__libc_start_main,初始化堆栈、信号处理、线程库; - 调用
main函数:将控制权交给用户代码,程序正式执行; - 程序退出:
main返回后,调用_exit函数,释放内存、终止进程。
4.3.3 地址无关代码(PIC)与 GOT/PLT 机制
动态库需支持 “加载到任意虚拟地址仍能运行”,核心是地址无关代码(Position-Independent Code, PIC),而实现 PIC 的关键是 GOT(全局偏移量表)和 PLT