【完整源码+数据集+部署教程】棉花产量预测分割系统: yolov8-seg-bifpn
背景意义
研究背景与意义
随着全球人口的不断增长,粮食安全问题日益突出,农业生产的效率和可持续性成为各国政府和科研机构关注的重点。在众多农作物中,棉花作为重要的经济作物,不仅是纺织工业的基础原料,也是农民收入的重要来源。因此,提升棉花的产量和质量,优化种植管理策略,对于促进农业可持续发展、保障农民生计、推动地方经济发展具有重要意义。然而,传统的棉花产量预测方法往往依赖于经验和历史数据,难以适应快速变化的气候条件和市场需求。因此,基于先进的计算机视觉技术,尤其是深度学习方法的棉花产量预测分割系统的研究显得尤为重要。
近年来,YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而受到广泛关注。YOLOv8作为该系列的最新版本,进一步提升了检测精度和速度,具有较强的应用潜力。通过对YOLOv8进行改进,结合实例分割技术,可以实现对棉花生长状态的精准识别与分析,从而为棉花产量的预测提供更为可靠的数据支持。该研究旨在构建一个基于改进YOLOv8的棉花产量预测分割系统,利用1500张图像的数据集,涵盖了棉花的不同生长阶段和环境条件,进行深入的模型训练与验证。
本研究的意义在于,首先,通过引入深度学习技术,能够实现对棉花生长状态的自动化监测与分析,减少人工干预,提高工作效率。其次,改进YOLOv8模型的应用,不仅能够提升棉花目标检测的精度,还能通过实例分割技术,实现对棉花与其他植物或杂草的有效区分,为精准农业提供数据支持。此外,研究中所使用的1500张图像数据集,涵盖了三类主要类别(棉花、杂草和土壤),为模型的训练提供了丰富的样本,有助于提高模型的泛化能力和适应性。
通过建立这一系统,研究将为棉花种植者提供科学的决策依据,帮助他们更好地把握棉花的生长周期,优化施肥、灌溉和病虫害防治等管理措施,从而提高棉花的产量和质量。同时,该系统的成功应用也将为其他农作物的产量预测提供借鉴,推动农业智能化的发展。
综上所述,基于改进YOLOv8的棉花产量预测分割系统的研究,不仅具有重要的理论价值,还有着广泛的实际应用前景。通过深度学习技术的引入,能够为棉花种植提供更加科学、精准的管理方案,助力农业的可持续发展。
图片效果
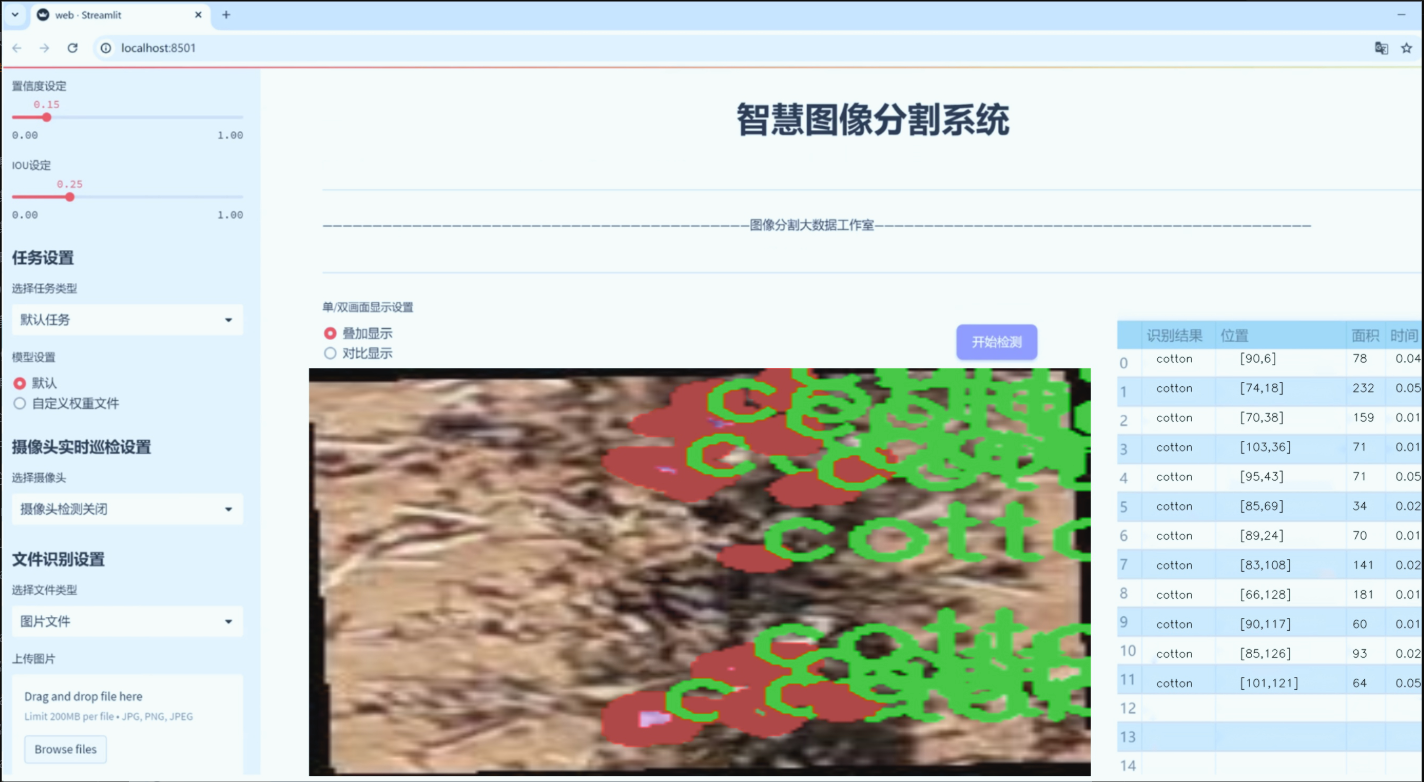
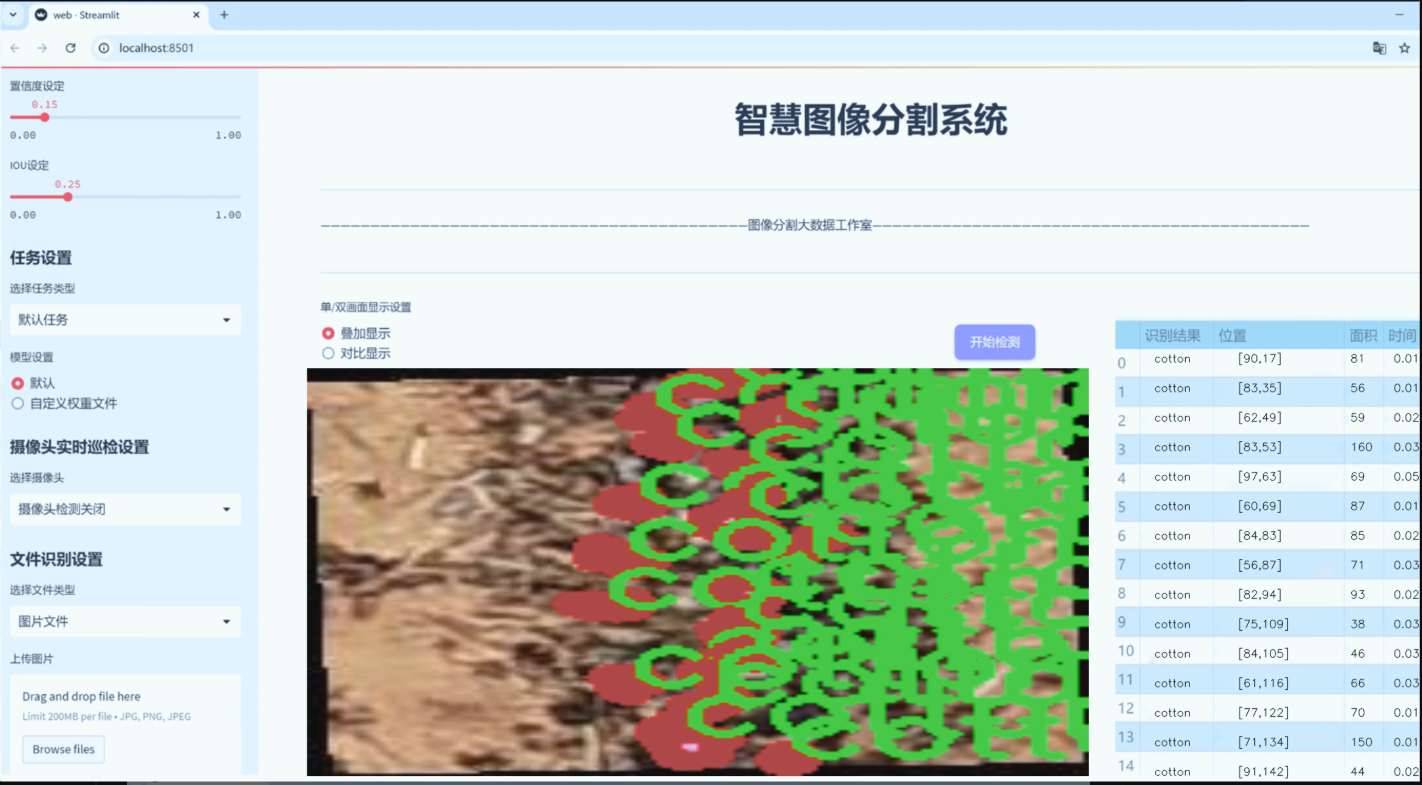
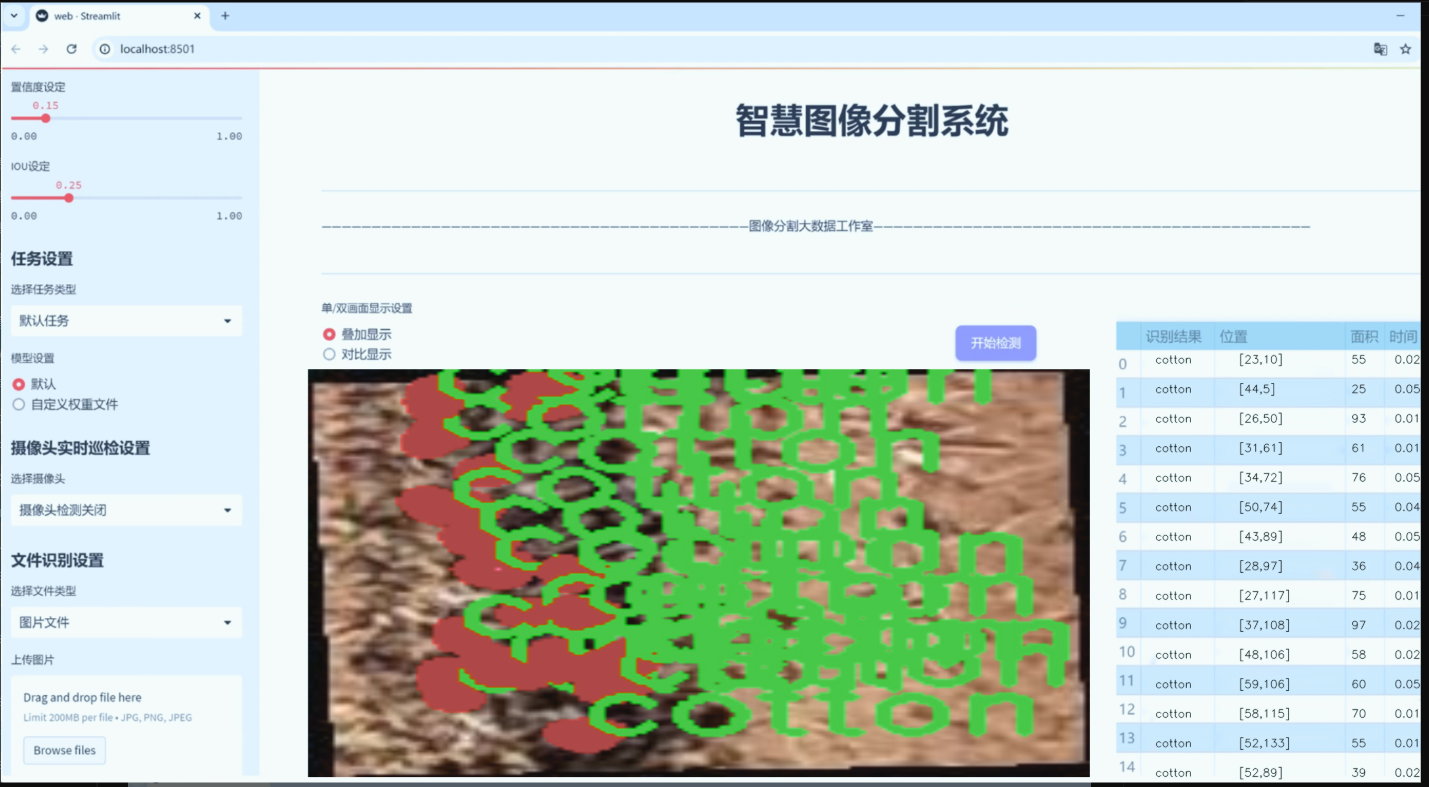
数据集信息
数据集信息展示
在现代农业生产中,棉花作为一种重要的经济作物,其产量的准确预测对于农民的决策和农业管理具有重要意义。为了实现这一目标,我们构建了一个名为“cotton_yield_prediction”的数据集,旨在为改进YOLOv8-seg的棉花产量预测分割系统提供高质量的训练数据。该数据集包含了丰富的图像数据和标注信息,能够有效支持深度学习模型在棉花产量预测中的应用。
“cotton_yield_prediction”数据集的类别数量为3,具体类别包括“cotton”(棉花)、“f”(病害)和“s”(土壤)。这些类别的选择不仅反映了棉花生长过程中可能影响产量的关键因素,也为模型的训练提供了多样化的样本。棉花(cotton)作为主要类别,涵盖了不同生长阶段的棉花植株图像,能够帮助模型学习到棉花的生长特征和形态变化。病害(f)类别则专注于棉花植株上常见的病虫害图像,这些病害对棉花的生长和最终产量有着直接的影响。通过对病害的识别,模型能够更好地评估其对棉花产量的潜在威胁。土壤(s)类别则包含了不同土壤条件下的图像,土壤的质量和类型是影响棉花生长的重要环境因素,能够为模型提供更全面的背景信息。
该数据集的构建过程注重数据的多样性和代表性,确保所收集的图像涵盖了不同的生长环境、气候条件和管理实践。我们从多个棉花种植区域收集了大量的图像数据,确保数据集的广泛性和适用性。此外,为了提高数据集的质量,我们对图像进行了严格的标注,确保每一张图像都能准确反映其对应的类别。这种高质量的标注不仅提高了模型的训练效果,也为后续的模型评估提供了可靠的基准。
在数据集的使用过程中,研究人员可以通过对“cotton_yield_prediction”数据集的分析,深入了解棉花生长的动态变化及其与环境因素之间的关系。通过将该数据集与YOLOv8-seg模型相结合,研究人员能够实现对棉花产量的精准预测,并通过分割技术识别出不同类别的区域,从而为农民提供科学的种植建议和管理策略。
总之,“cotton_yield_prediction”数据集不仅为棉花产量预测提供了重要的基础数据支持,也为农业智能化发展奠定了坚实的基础。随着深度学习技术的不断进步,该数据集的应用前景广阔,未来将为棉花种植的精准管理和可持续发展提供更多的可能性。通过对数据集的深入研究,我们期待能够推动棉花生产的智能化进程,提高农业生产效率,最终实现更高的经济效益和环境效益。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import time
import pandas as pd
from ultralytics import YOLO
from ultralytics.utils import select_device, check_yolo
def benchmark(model=‘yolov8n.pt’, imgsz=160, device=‘cpu’, verbose=False):
“”"
对YOLO模型进行基准测试,评估不同格式的速度和准确性。
参数:model (str): 模型文件的路径,默认为'yolov8n.pt'。imgsz (int): 用于基准测试的图像大小,默认为160。device (str): 运行基准测试的设备,可以是'cpu'或'cuda',默认为'cpu'。verbose (bool): 如果为True,将输出详细的基准测试信息,默认为False。返回:df (pandas.DataFrame): 包含每种格式的基准测试结果的数据框,包括文件大小、指标和推理时间。
"""pd.options.display.max_columns = 10 # 设置显示的最大列数
pd.options.display.width = 120 # 设置显示的宽度
device = select_device(device, verbose=False) # 选择设备
model = YOLO(model) # 加载YOLO模型results = [] # 存储结果的列表
start_time = time.time() # 记录开始时间# 遍历不同的导出格式
for i, (name, format, suffix, cpu, gpu) in export_formats().iterrows():emoji, filename = '❌', None # 默认导出状态为失败try:# 检查设备支持情况if 'cpu' in device.type:assert cpu, 'CPU不支持此推理'if 'cuda' in device.type:assert gpu, 'GPU不支持此推理'# 导出模型if format == '-':filename = model.ckpt_path or model.cfg # PyTorch格式else:filename = model.export(imgsz=imgsz, format=format, device=device, verbose=False)assert suffix in str(filename), '导出失败'emoji = '✅' # 导出成功# 进行推理model.predict('bus.jpg', imgsz=imgsz, device=device) # 使用示例图像进行推理# 验证模型results_dict = model.val(data='coco8.yaml', batch=1, imgsz=imgsz, device=device)metric, speed = results_dict.results_dict['mAP'], results_dict.speed['inference']results.append([name, emoji, round(file_size(filename), 1), round(metric, 4), round(speed, 2)])except Exception as e:if verbose:print(f'基准测试失败: {name}: {e}')results.append([name, emoji, None, None, None]) # 记录失败的结果# 打印结果
check_yolo(device=device) # 打印系统信息
df = pd.DataFrame(results, columns=['格式', '状态', '大小 (MB)', '指标', '推理时间 (ms/im)'])# 输出基准测试的总结信息
print(f'\n基准测试完成,结果如下:\n{df}\n')
return df
代码核心部分解释:
导入必要的库:导入了时间、Pandas、YOLO模型以及一些工具函数。
benchmark函数:该函数用于对YOLO模型进行基准测试,评估不同格式的速度和准确性。
参数:
model:指定要测试的模型文件路径。
imgsz:指定输入图像的大小。
device:指定运行测试的设备(CPU或GPU)。
verbose:控制是否输出详细信息。
返回值:返回一个包含测试结果的Pandas DataFrame。
设备选择:使用select_device函数选择合适的设备。
导出模型:根据不同的格式导出模型,并进行推理测试。
结果记录:将每种格式的测试结果记录到results列表中。
打印结果:最终将结果以DataFrame的形式打印出来。
这个简化的代码片段保留了基准测试的核心逻辑,并提供了必要的注释以帮助理解。
这个程序文件 benchmarks.py 是 Ultralytics YOLO(You Only Look Once)模型的一个基准测试工具,主要用于评估不同格式的 YOLO 模型在速度和准确性方面的表现。文件中包含了两个主要的类和一些辅助函数。
首先,文件开头部分提供了如何使用这个基准测试工具的示例,包括如何导入相关模块和调用 ProfileModels 和 benchmark 函数。ProfileModels 类用于对不同模型进行性能分析,而 benchmark 函数则用于对特定模型进行基准测试。
benchmark 函数的参数包括模型路径、数据集、图像大小、是否使用半精度或整型精度、设备类型(CPU 或 GPU)以及是否显示详细信息。该函数会返回一个包含基准测试结果的 pandas DataFrame,结果包括每种格式的文件大小、性能指标和推理时间。
在函数内部,首先设置了 pandas 的显示选项,然后选择运行设备。接着,如果模型是字符串或路径类型,则将其加载为 YOLO 模型。随后,程序遍历不同的导出格式,尝试导出模型并进行推理,记录每种格式的性能指标。对于每种格式,程序会进行异常处理,以确保在发生错误时能够输出相应的警告信息。
ProfileModels 类则专注于对不同模型进行性能分析。它的构造函数接受模型路径、定时运行次数、预热运行次数、最小运行时间、图像大小等参数。该类的方法 profile 会获取模型文件,导出 ONNX 和 TensorRT 格式的模型,并对其进行基准测试,最后输出结果。
在 ProfileModels 类中,get_files 方法用于获取指定路径下的模型文件,get_onnx_model_info 方法用于获取 ONNX 模型的信息,iterative_sigma_clipping 方法用于对数据进行迭代的 sigma 剪切,以去除异常值。profile_tensorrt_model 和 profile_onnx_model 方法分别用于对 TensorRT 和 ONNX 模型进行基准测试,计算其平均运行时间和标准差。
最后,generate_table_row 和 generate_results_dict 方法用于生成格式化的输出,便于在控制台打印和记录基准测试结果。print_table 方法则负责将结果以表格形式输出,方便用户查看不同模型的性能对比。
总体而言,这个文件为 YOLO 模型的性能评估提供了一个全面的工具,用户可以通过简单的调用来获取不同模型在多种格式下的速度和准确性数据。
11.5 ultralytics\models\fastsam\utils.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
def adjust_bboxes_to_image_border(boxes, image_shape, threshold=20):
“”"
调整边界框,使其在距离图像边界一定阈值内时贴近边界。
参数:boxes (torch.Tensor): 边界框的坐标,形状为 (n, 4)image_shape (tuple): 图像的高度和宽度,形状为 (height, width)threshold (int): 像素阈值返回:adjusted_boxes (torch.Tensor): 调整后的边界框
"""# 获取图像的高度和宽度
h, w = image_shape# 调整边界框的坐标
boxes[boxes[:, 0] < threshold, 0] = 0 # 将左上角 x 坐标调整为 0
boxes[boxes[:, 1] < threshold, 1] = 0 # 将左上角 y 坐标调整为 0
boxes[boxes[:, 2] > w - threshold, 2] = w # 将右下角 x 坐标调整为图像宽度
boxes[boxes[:, 3] > h - threshold, 3] = h # 将右下角 y 坐标调整为图像高度
return boxes
def bbox_iou(box1, boxes, iou_thres=0.9, image_shape=(640, 640), raw_output=False):
“”"
计算一个边界框与一组其他边界框的交并比(IoU)。
参数:box1 (torch.Tensor): 单个边界框的坐标,形状为 (4, )boxes (torch.Tensor): 一组边界框的坐标,形状为 (n, 4)iou_thres (float): IoU 阈值image_shape (tuple): 图像的高度和宽度,形状为 (height, width)raw_output (bool): 如果为 True,则返回原始 IoU 值而不是索引返回:high_iou_indices (torch.Tensor): IoU 大于阈值的边界框索引
"""
# 调整边界框,使其贴近图像边界
boxes = adjust_bboxes_to_image_border(boxes, image_shape)# 计算交集的坐标
x1 = torch.max(box1[0], boxes[:, 0]) # 交集左上角 x 坐标
y1 = torch.max(box1[1], boxes[:, 1]) # 交集左上角 y 坐标
x2 = torch.min(box1[2], boxes[:, 2]) # 交集右下角 x 坐标
y2 = torch.min(box1[3], boxes[:, 3]) # 交集右下角 y 坐标# 计算交集的面积
intersection = (x2 - x1).clamp(0) * (y2 - y1).clamp(0)# 计算两个边界框的面积
box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) # box1 的面积
box2_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1]) # boxes 的面积# 计算并集的面积
union = box1_area + box2_area - intersection# 计算 IoU
iou = intersection / union # IoU 的形状为 (n, )if raw_output:return 0 if iou.numel() == 0 else iou # 如果需要原始 IoU 值,直接返回# 返回 IoU 大于阈值的边界框索引
return torch.nonzero(iou > iou_thres).flatten()
代码核心部分说明:
adjust_bboxes_to_image_border 函数:该函数用于调整边界框的位置,使其在距离图像边界一定阈值内时,自动贴近边界,确保边界框不会超出图像的范围。
bbox_iou 函数:该函数计算一个边界框与一组其他边界框的交并比(IoU),并返回与给定边界框有较高重叠度的边界框的索引。通过调整边界框位置,计算交集和并集的面积,最终得出 IoU 值。
这个程序文件包含了两个主要的函数,分别用于调整边界框和计算边界框之间的交并比(IoU)。首先,adjust_bboxes_to_image_border函数的作用是将给定的边界框调整到图像的边界内,如果这些边界框的某一边距离图像边界小于指定的阈值(默认为20像素),则将其调整到图像的边界上。该函数接收三个参数:boxes是一个形状为(n, 4)的张量,表示n个边界框的坐标;image_shape是一个元组,包含图像的高度和宽度;threshold是一个整数,表示调整的阈值。函数内部首先获取图像的高度和宽度,然后根据阈值调整边界框的坐标,最后返回调整后的边界框。
接下来的bbox_iou函数用于计算一个边界框与一组其他边界框之间的交并比。该函数接收五个参数:box1是一个形状为(4,)的张量,表示要计算的边界框;boxes是一个形状为(n, 4)的张量,表示其他边界框;iou_thres是一个浮点数,表示IoU的阈值;image_shape是图像的高度和宽度;raw_output是一个布尔值,指示是否返回原始的IoU值。函数首先调用adjust_bboxes_to_image_border来确保所有边界框都在图像边界内。然后,通过计算交集的坐标,得到交集的面积,接着计算两个边界框的面积以及它们的并集面积,最后计算IoU值。如果raw_output为真,则返回IoU值;否则,返回与IoU大于阈值的边界框的索引。
整体来看,这个文件提供了处理边界框的基本工具,适用于目标检测等计算机视觉任务。通过这些函数,可以有效地调整边界框并评估它们之间的重叠程度。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是一个基于Ultralytics YOLO模型的目标检测和姿态估计框架,包含多个模块,旨在提供高效的模型训练、推理和性能评估功能。程序的结构设计清晰,主要分为以下几个部分:
姿态预测模块 (predict.py): 负责对输入图像进行姿态估计,处理模型的输出并进行后处理,返回关键点和边界框信息。
超参数调优模块 (tuner.py): 提供了一种系统化的方法来优化YOLO模型的超参数,通过进化算法寻找最佳配置,以提高模型性能。
检测头模块 (head.py): 定义了不同类型的检测头,负责处理模型的输出,生成预测的边界框和类别概率,支持多种检测任务。
基准测试模块 (benchmarks.py): 提供了评估模型性能的工具,能够对不同格式的YOLO模型进行速度和准确性测试,输出基准测试结果。
实用工具模块 (utils.py): 包含处理边界框的基本工具,提供边界框调整和交并比计算的功能,适用于目标检测任务。
文件功能整理表
文件路径 功能描述
ultralytics/models/yolo/pose/predict.py 实现姿态预测,处理模型输出,进行后处理,返回关键点和边界框信息。
ultralytics/engine/tuner.py 提供超参数调优功能,通过进化算法优化YOLO模型的超参数配置,以提升模型性能。
ultralytics/nn/extra_modules/head.py 定义不同类型的检测头,处理模型输出,生成预测的边界框和类别概率,支持多种检测任务。
ultralytics/utils/benchmarks.py 提供基准测试工具,评估不同格式YOLO模型的速度和准确性,输出基准测试结果。
ultralytics/models/fastsam/utils.py 提供边界框处理工具,包括边界框调整和交并比计算,适用于目标检测任务。
整体来看,这些模块相互协作,形成了一个功能全面的目标检测和姿态估计框架,支持从模型训练到推理和性能评估的整个流程。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻