Linux开发工具(一)
目录
1.Linux开发工具
2 命令模式:
2.1 光标如何到第一行,如何到最后一行(光标的上下运动)
2.2 光标的左右移动:
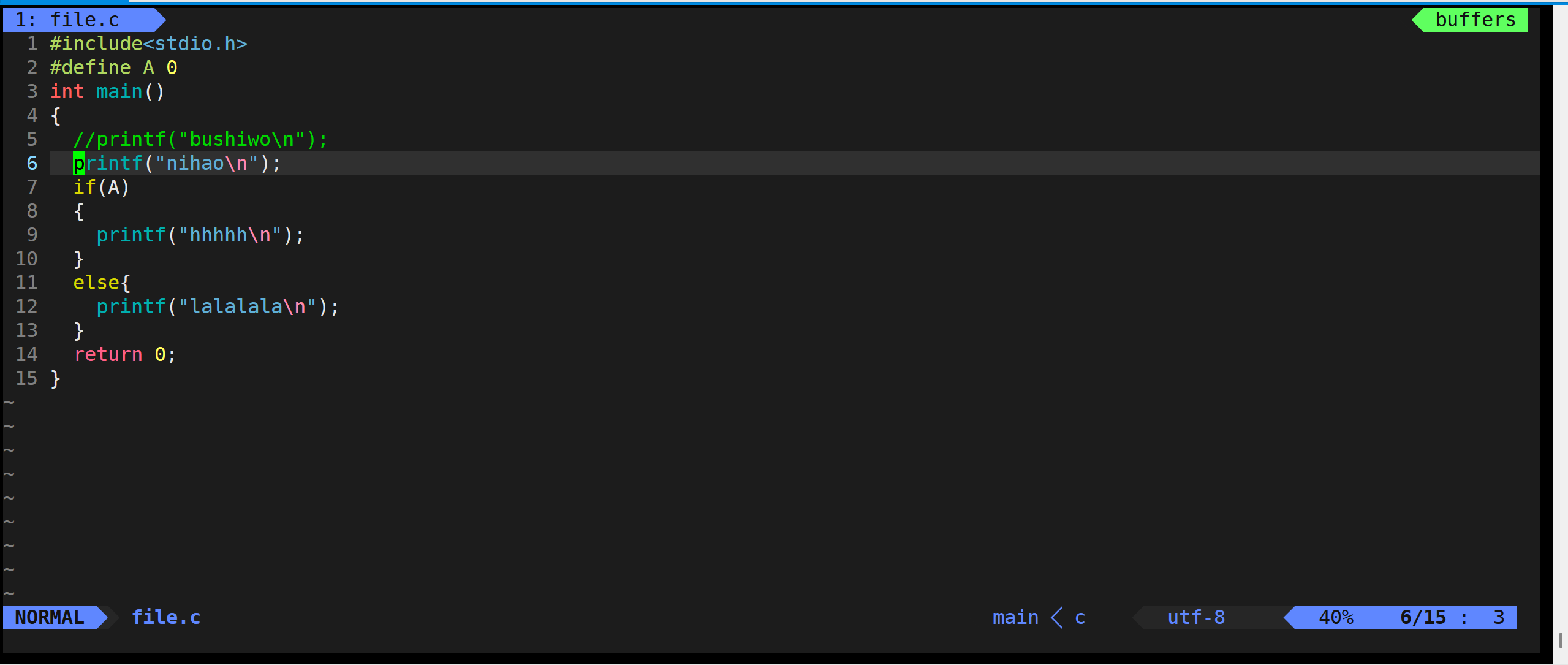
2.3 光标的上下左右运动:
2.4 更快的移动:
2.5 对文本的修改:
2.5.1 复制:
2.5.2 删除:
2.5.3 撤销与反撤销
2.5.4 大小写转换
2.5.5 替换:
2.5.6 批量注释:
3 底行模式
1.底行模式的文件权限
2 临时文件
3 按照关键词搜索
4 集体替换
5 分屏操作
4 简单vim配置
编译器gcc/g++
1.程序的执行过程
1.1 预处理
1.2 编译
1.3 汇编:
1.4 链接
1.Linux开发工具
Linux下的开发工具都是独立的,那么,咱们通常说要完成一个项目,肯定是需要经过很多的步骤的。其中就包括很多开发工具的使用,今天咱们就来介绍几个开发工具。
写代码-也就是咱们常说的编辑器(vim),这个只是用来写代码。并且,在终端下进行写代码的工具。
编译代码-gcc(g++)。
调试-gdb,cgdb
构建工具-Makefile,make,cmake,git
那么接下来,咱们先来介绍一下vim编辑器吧。
vim的多模式都是围绕着命令展开的。在window下,你可以输入abcd1234,也可以输入ctrl+c,ctrl+v,这两个叫做快捷键。那么在Linux中也叫做命令。那么命令可以增加你的编辑效率。因为命令背后是子自动化以及批量化。
且命令越多,效率也就越高。
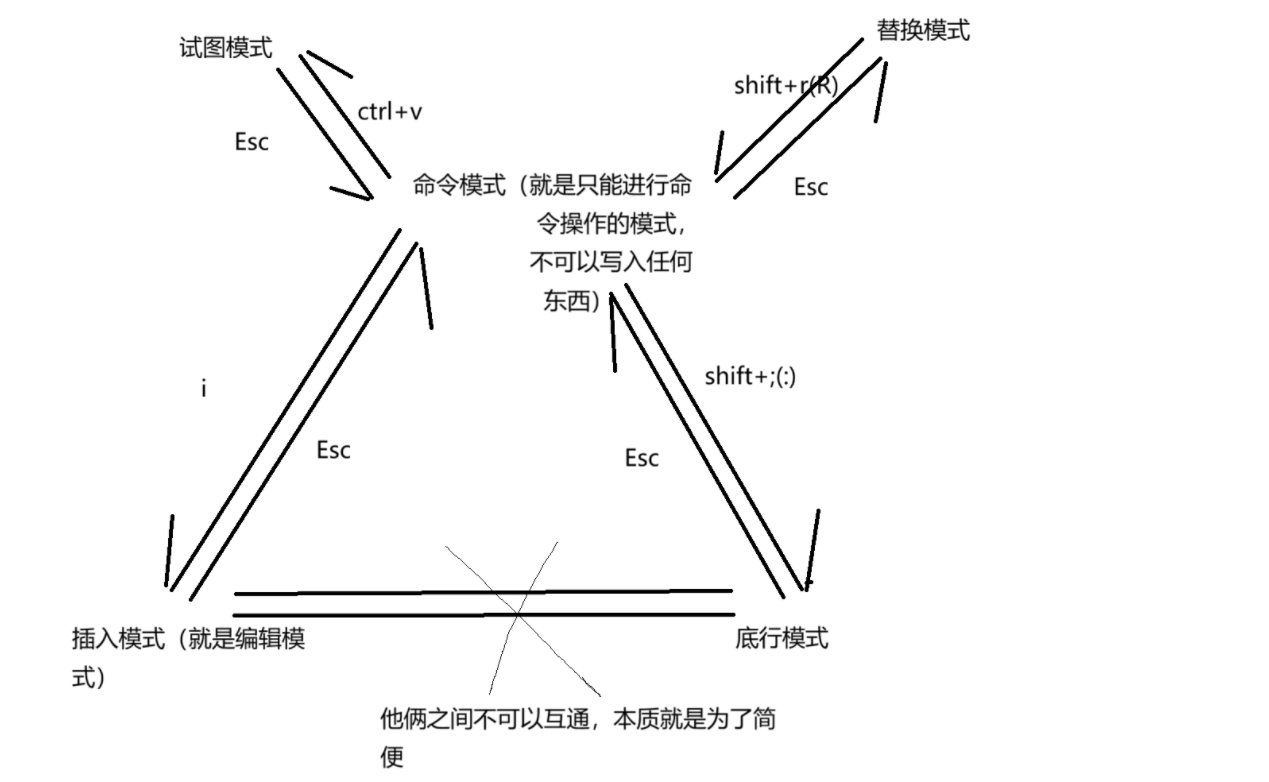
先给大家看vim编辑器的五个模式。接下来我会为大家一一的进行解析的。
那么咱们退出vim编辑器,有两种方法:
1.进入底行模式,输入w(保存)+q(退出)
2.在命令模式下直接shift+zz(ZZ)
并且任何模式想回到命令模式,直接Esc即可。
先说一下:
在底行模式下:set nu:调出行号
set nonu:去掉行号
在LInux下,你退出vim的时候,光标在第几行,那么你再次进入vim的时候,光标还是在第几行。
2 命令模式:
2.1 光标如何到第一行,如何到最后一行(光标的上下运动)
shift+g(G):光标从第一行到最后一行。
gg:回到文本的开始
n+shift+g:定位到任意一行(n为任意数字)。例如5+shift+g即为定位到第五行


2.2 光标的左右移动:
shift+4($),光标移动到当前行的行尾。
shift+6(^):光标移动到当前行的行头。
这俩也被称作锚点。
2.3 光标的上下左右运动:
咱们知道,平常咱们看文本的时候,想让你那个闪烁的竖杠,移动,只有按住你的上键,下键,左键,以及右键。那么今天咱们来介绍四个键:
H,J,K,L
这四个键,分别对应左移,下移,上移,右移动。
H,L很好理解,就是一个最左边,一个最右边。那么j可以理解为jump:跳,也就是朝下跳。
K:king,国王,国王都是高高在上的吧。所以说,k就是上移。
那么为什么vim上已经有了上下左右移动键,为什么话要有这个hjkl呢?其实在很早的时候,老式的键盘上是没有这个上下左右键的。其次呢,就是这个快呀。
2.4 更快的移动:
那么咱们hjkl,都是一个一个的移动,那么有没有快速的呢?有!
从左往右:w:按照单词,以单词为单位,从左往右移动。如果遇到的不是单词,比如说特殊符号,那么你就可以一个一个的跳过了。
从右往左:b。也是以单词为单位。
数字+w可以连续跳过数个单词。
数字+b可以连续跳过数个单词。
2.5 对文本的修改:
2.5.1 复制:
那么咱们光标所在的行:yy赋值这一行,然后p就是粘贴到当前行的下一行。数字+p,粘贴“数字”行。并且粘贴不包括当前行。
n+yy:赋值n行。(包括当前行)。
2.5.2 删除:
dd:删除当前行(例如删除前光标在第五行,那么删除之后,光标也会在第五行)
ndd:删除n行,(包括当前行的下面n-1行)
dd其实是剪切,你再按p还是会粘贴上去的。
x:删除光标所在的字符。(你的delete键,是得在插入模式下才可以使用的),这个是从左往右进行删除。(删除光标内的)
shift+x:从右向左进行删除。并且删除的是光标左边的,并不是删除光标内的。
n+x:还是连续删除n个字符。
n+shift+x:连续向左删除n个字符。
2.5.3 撤销与反撤销
u:就是撤销操作。
ctrl+r:就是对你上一步的撤销进行撤销操作。
什么意思呢?就是

u就是撤销,是假如误操作了,导致现在的操作不是我想要的,那么我就可以按u回到过去,回到我没有误操作的那一步。此时的u就在过去。
而ctrl+r就是让在过去的u再回到未来(也就是现在)。就是对u的撤销操作。所以u,你再接着按ctrl+r,就是相当于没动。
所以,再vim编辑器下,完全不需要担心你误操作。
2.5.4 大小写转换
shift+~:大小写的快速转换(例如定义宏)
n+shift+~:快速的将n个进行转换
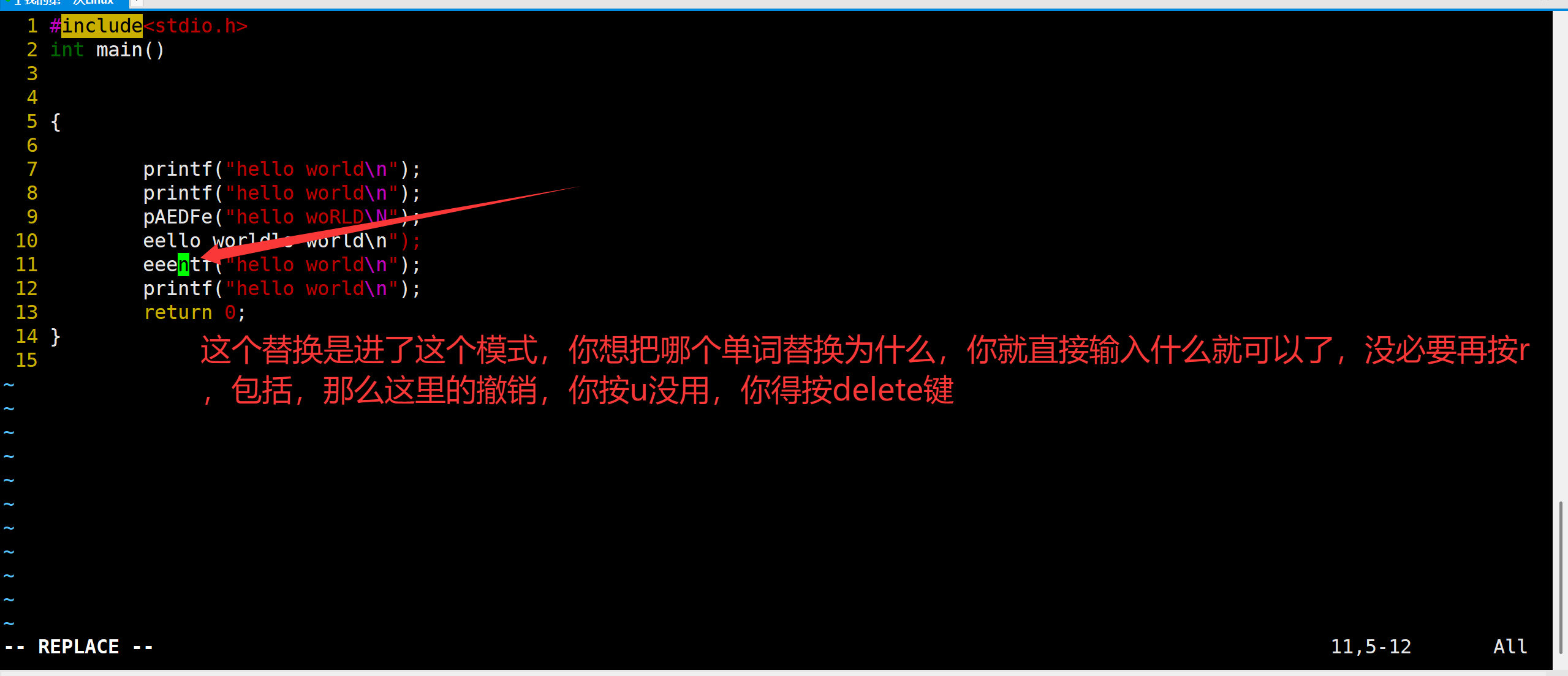
2.5.5 替换:
r:按r,然后再接着按你想要替换的字符,就可以替换为你想替换的那个字符了。
3r+a:连续换成3个a。(从当前光标开始,连着后面的2个字符)
那么讲到了替换,就不得不讲一个东西:那就是替换模式了。上面的模式图大家应该也看到了。替换模式是可以对内容进行自由的替换的。
2.5.6 批量注释:
这个需要用到视图模式:
1.ctrl+v:先进入视图模式
2.之后使用hjkl选中区域。可以使用n+(h,j,k,l)
3.shift+i=I。直接进入插入模式
4.输入//(这个地方其实可以输入任何东西,就是批量进行添加操作)
5.按esc,即可自动批量添加东西。
批量撤销:
1.ctrl+v,进入视图模式
2.选中区域
3.按d,即可批量消除任何东西,包括注释。
那么假如你的操作都完成之后,便会自动回到命令模式。
3 底行模式
1.底行模式的文件权限
假如说你的这个文件,没有读的权限,也就是r。那么你打开这个文件,就是啥都没有(noperm)
如果没有写权限(w),那么你此时想写文件,会发现,无法写入。因为你的insert模式进不去。那么此时只需要在底行模式下进行shift+;(:)+w!即可进行写入了。那么这个时候又有人问了,这个不是强制保存吗?是的,但是呢,这个也可以用来写。你在底行模式下输入这个,你的insert模式1就可以进去了。
之后,q!就是强制退出。


2 临时文件
如果说你正在写着vim文件,那么突然你的vim还没有保存,终端就突然的退出了。那么这个时候,不需要担心,因为你的这个文件内容并不会丢失。因为它会被保存进一个以.swap结尾的临时文件中(临时文件都是以.开头的),可以使用ls -al 来查看。那么你第一次打开这个文件保存并退出后,得删了临时文件。后面才可以正常的进入。

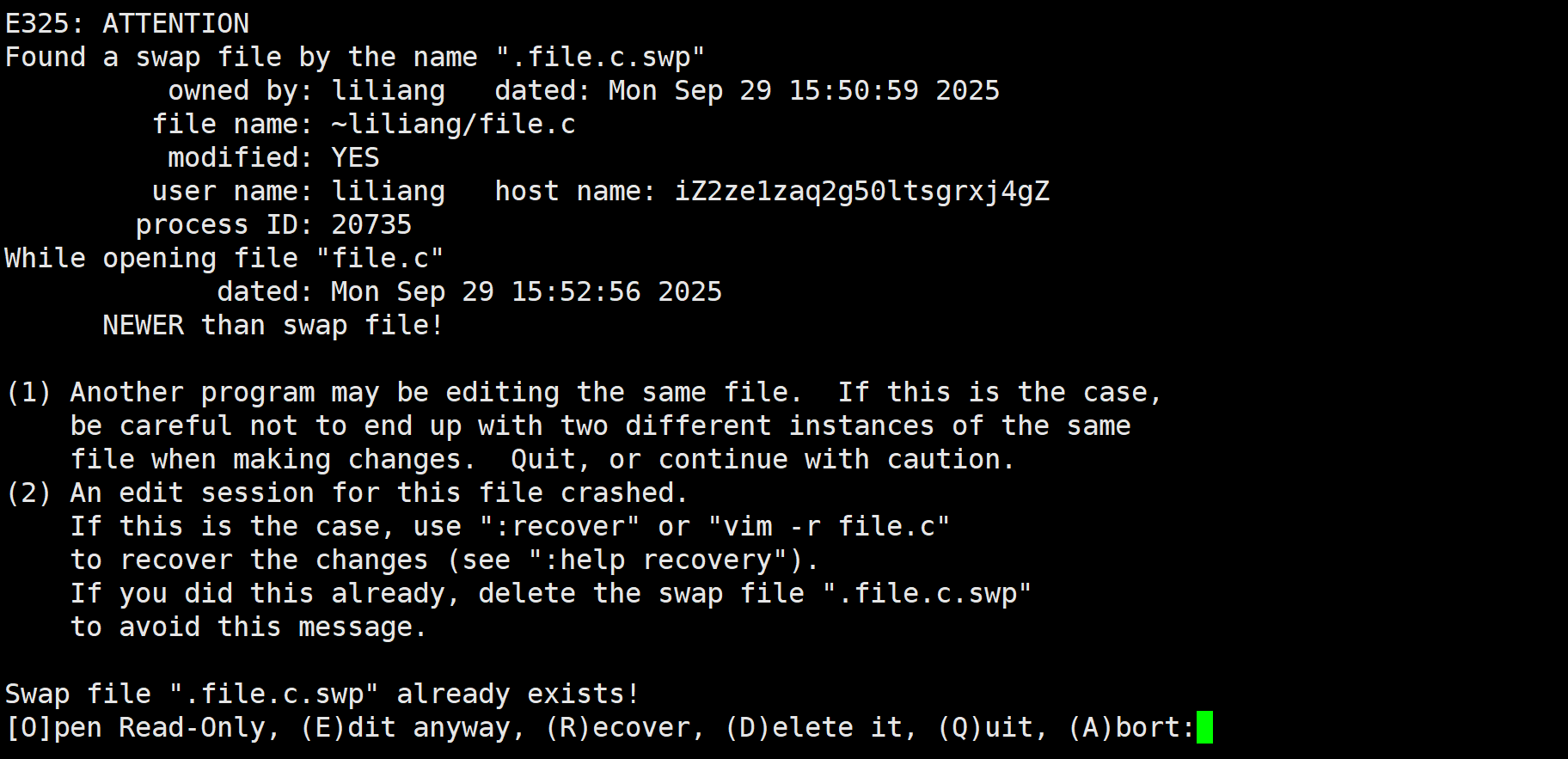
此时就是删了临时文件
那么此时删了临时文件之后,你再次进入文件,就不会有第二张图片的提示了。
3 按照关键词搜索
:/key+n就是/+key关键词,即你要搜索的关键词,之后按回车,找到关键词后,你再按n就可以一个一个的进行搜索了。
:!+指令,就可以在底行模式下进行执行shell指令了。并且不会退出vim编辑器。

4 集体替换
:%s/dst/src/g
将文本的dst全部替换为src。这个%s后面的空格可有可无。
5 分屏操作
:vs就是分屏操作
例如:vs code.h就会分屏出一个code.h文件,所以此时你的屏幕上总共有两个文件,一个是code.h,一个是你自己打开的。那么你想把你自己打开的文件的头文件放到code.h中,直接yy赋值,然后ctrl+ww,换到另外一个文件上(code.h),然后p即可。
那么你写完之后,直接:wq即可。并且分屏退出顺序,是跟你的创建的顺序是相反的。
并且你的电脑上会出现这三个文件。
好,到此为止,5个模式都给大家介绍完了。有人说了,这不才2个模式吗?这2个中间,穿插了视图以及替换模式。至于插入模式,还需要介绍吗?你就正常敲代码就可以了。
4 简单vim配置
vim是系统中的一条基本的指令。对vim的配置其实就是把配置写进home/xx/.vimrc配置文件中。
which vim
/usr/bin/vim
然后启动vim,vim默认会带上家目录下的(.vimrc)这个隐藏文件。读取对应的配置文件
咱们的vim配置其实有很多的。
例如:你要是想让vim有缩进啥的。你就可以在.vimrc中进行配置,同理,你要是想让vim有语法提示啥的,可以下载插件,咱们可以创建一个隐藏目录(.vim),然后把插件放到这个目录下(ls -al)即可查看隐藏目录与文件。
好的,那么到此为止,vim编辑器咱们已经全部的讲完了。那么接下来,我将再带大家来讲解编译器gcc/g++
编译器gcc/g++
那么有人问了,这两者有啥区别呢?其实这两者的选项完全一样。目前用的是gcc。
gcc:c语言编译器,只能用来编译c语言。
g++:是一个c++/c语言编译器。
1.程序的执行过程
那么咱们想把一个c语言文本,编译一下,让他成功的运行,那么咱们只需要
gcc test.c(编译test.c这个文件)只不过这种编译方式,统一会形成a.out的可执行文件。
如果你想自己进行命名。可以gcc test.c -o test
即可,这个test即为重新命名的可执行文件。这个-o的意思就是自己指定名字形成的可执行程序。
那么这种咱们把他叫做一步到位。
咱们知道,一个c语言源文件,你如果想把它编译为可执行文件。必须要经过预处理-编译-汇编-链接。
这四大步骤。
1.1 预处理
预处理又分为头文件展开-去掉注释-宏替换-条件编译(有条件编译才可以进行条件编译,即有#if,#endif这样的)
咱们如果说不想让源文件一步变成可执行程序。想让他执行完预处理这一步就停下来。那么正纳闷可以
gcc -E test.c -o test.i(将test.c文件预处理的结果放到test.i这个文件中)
-E:程序开始翻译,做完对源文件的预处理就停下来。
那么咱们打开test.i文件,就可以看到里面有900多行对吧。那为啥预处理这么多呢?其实,咱们打开vim /usr/include/stdio.h,打开之后,会发现也是900多行,而这个stdio.h头文件就是咱们test.c这个源文件里面所包含的。所以说。其实预处理阶段,会把 /usr/include/stdio.h这个里面的内容拷贝到源文件内部。并且,有的东西该拷贝,有的东西不该拷贝。它自己都知道。这个其实叫做头文件展开。
宏替换,以及去掉注释,很简答,就不介绍了。
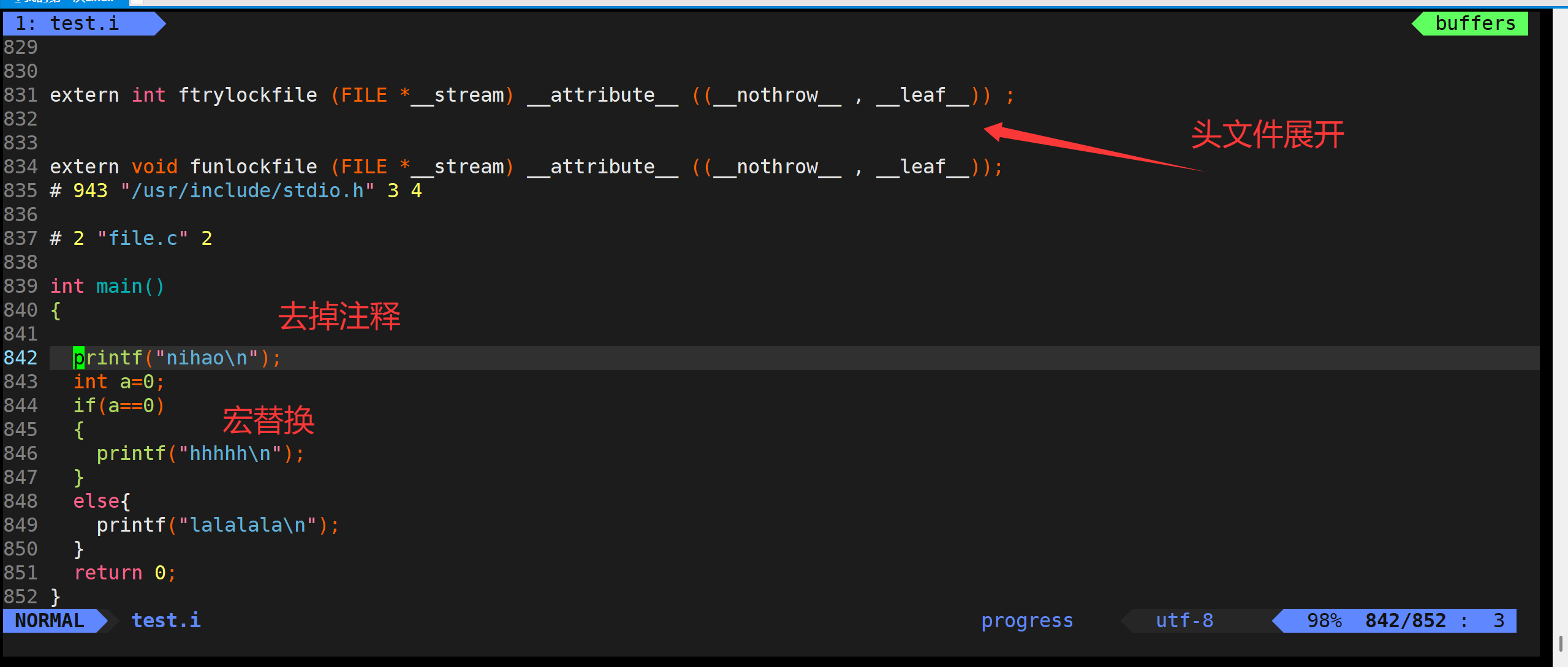
好,咱们接下来,说一下这个条件编译。这个条件编译。(对代码进行裁剪。并且只有gcc能做到)
条件编译存在的根本意义是:在编译前动态地塑造源代码,让同一份源代码能够根据不同条件生成不同的程序版本。
条件编译存在于正式的代码中,决定了哪些代码可以执行,哪些代码不可以执行。条件编译指令可以出现在C/C++代码的任何位置。
例如:
#include <stdio.h>
#define DEBUG 1 // 1=包含调试代码,0=不包含int main() {printf("正式功能\n");#if DEBUG// 这些调试代码只在DEBUG=1时存在printf("[DEBUG] 变量状态: x=%d\n", 42);log_to_file("程序启动");
#endifreturn 0;
}当 DEBUG 为 0 时,#if DEBUG 和 #endif 之间的代码就像从未写过一样。
来看几个条件编译使用的例子:
1. 在函数内部(最常见)
void process_data(int* data, int size) {// 正常的业务逻辑for(int i = 0; i < size; i++) {data[i] *= 2;}// 条件编译的调试代码 #if LOGGING_ENABLEDprintf("数据处理完成,大小: %d\n", size);for(int i = 0; i < size; i++) {printf("data[%d] = %d\n", i, data[i]);} #endif// 更多业务逻辑... }2. 在函数外部(全局范围)
#include <stdio.h>// 根据平台选择不同的头文件 #ifdef _WIN32#include <windows.h>#define PLATFORM "Windows" #elif defined(__linux__)#include <unistd.h>#define PLATFORM "Linux" #else#define PLATFORM "Unknown" #endif// 条件编译定义不同的函数 #if USE_OPTIMIZED_VERSIONvoid algorithm() {// 优化版本实现printf("使用优化算法\n");} #elsevoid algorithm() {// 标准版本实现printf("使用标准算法\n");} #endifint main() {printf("运行在: %s\n", PLATFORM);algorithm();return 0; }3. 在头文件中(防止重复包含)
// math_utils.h #ifndef MATH_UTILS_H #define MATH_UTILS_H#include <math.h>// 头文件内容... double calculate_hypotenuse(double a, double b);#endif // MATH_UTILS_H4. 控制变量声明
#include <stdio.h>// 根据条件选择不同的配置 #define USE_DOUBLE_PRECISION 1#if USE_DOUBLE_PRECISIONtypedef double real;#define REAL_FORMAT "%.6lf" #elsetypedef float real;#define REAL_FORMAT "%.3f" #endifint main() {real number = 3.1415926535;printf("数值: " REAL_FORMAT "\n", number);return 0; }
实际工程中的典型位置
完整的例子:
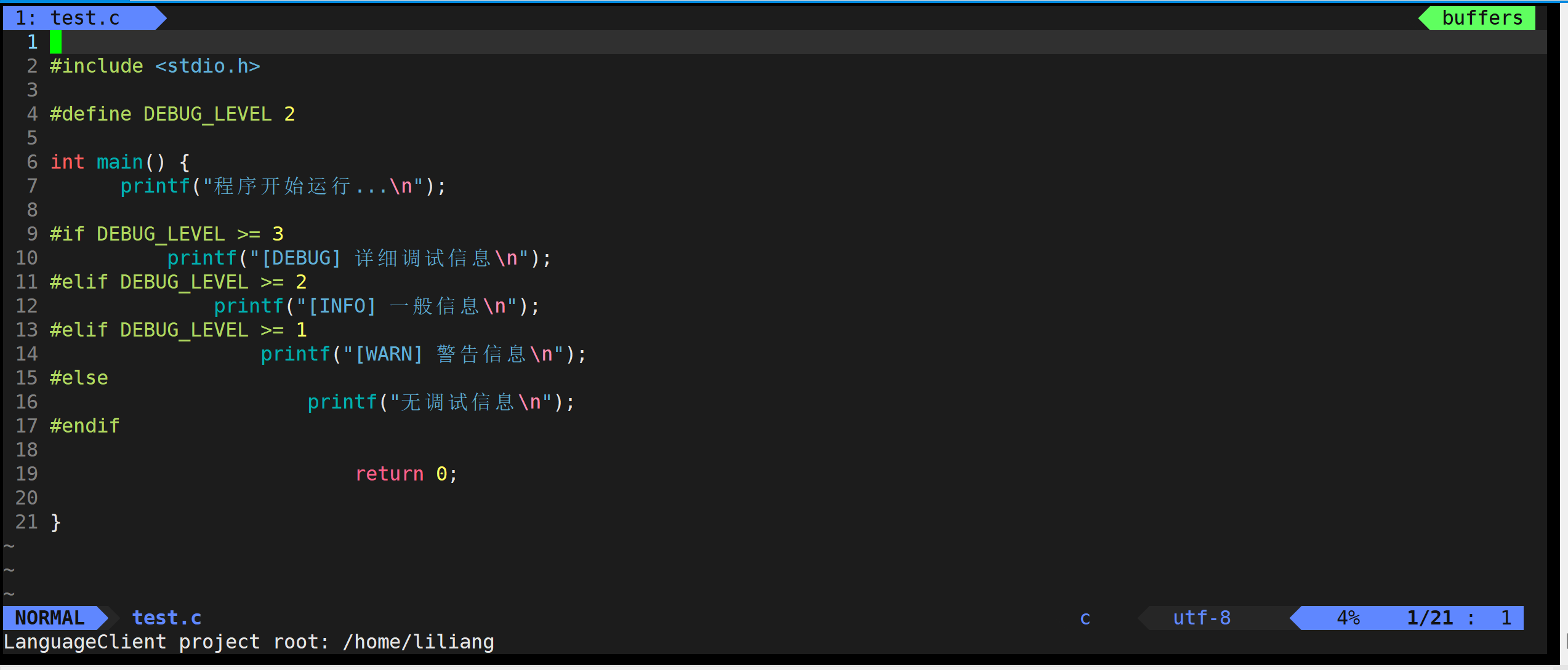
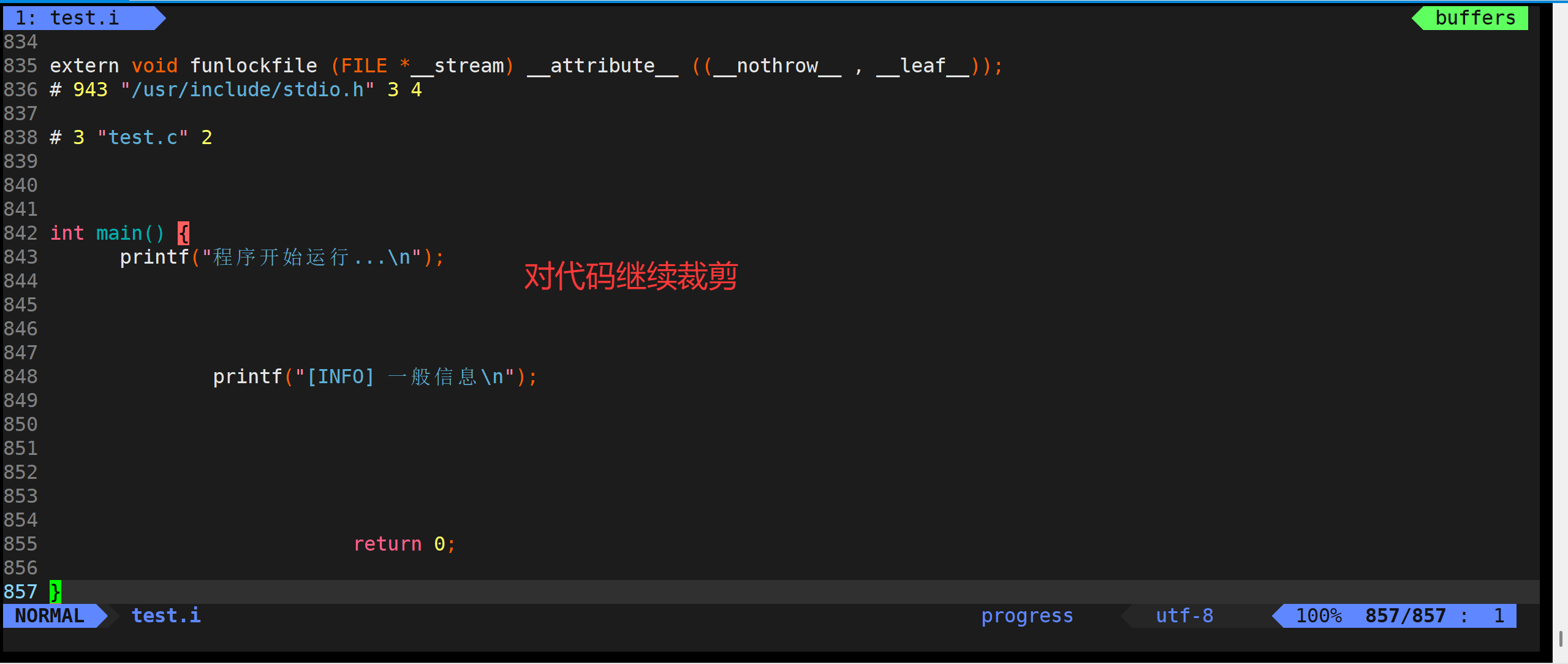
#include <stdio.h>// 1. 在文件开头定义编译选项 #define DEBUG_LEVEL 2 #define PLATFORM_WINDOWS 1 #define FEATURE_LOGGING 1// 2. 根据选项包含不同的头文件 #if PLATFORM_WINDOWS#include <windows.h> #else#include <unistd.h> #endif// 3. 条件编译的函数声明 #ifdef FEATURE_LOGGINGvoid log_message(const char* message); #endif// 4. 主函数中的条件编译 int main() {printf("程序启动\n");// 调试信息 #if DEBUG_LEVEL >= 2printf("[DEBUG] 初始化完成\n"); #endif// 平台特定代码 #if PLATFORM_WINDOWSSleep(1000); // Windows延时 #elsesleep(1); // Linux延时 #endif// 可选功能 #ifdef FEATURE_LOGGINGlog_message("主函数执行中"); #endif// 正常的业务逻辑int result = calculate();printf("结果: %d\n", result);#if DEBUG_LEVEL >= 1printf("[DEBUG] 程序结束\n"); #endifreturn 0; }// 5. 条件编译的函数实现 #ifdef FEATURE_LOGGING void log_message(const char* message) {printf("[LOG] %s\n", message); } #endif
而,咱们比如说,Linux下有免费版本,还有收费版本。那么有一次版本更新,难道说我要把这两个版本都再更新一遍吗?不需要,咱们只需要条件编译一下,比如,用户使用免费版本,那么咱们只需要把收费版本裁掉就可以了。
1.2 编译
编译就是把c语言汇编成为汇编语言
gcc -S(大写)test.i -o test.s
-S:程序开始翻译,从c语言翻译为汇编语言停止即可。
1.3 汇编:
把汇编语言翻译为二进制文件(.0,这个二进制文件叫做可重定位目标二进制文件)。此时的这个文件是不可以执行的。后面会解释。
gcc -c(小写)test.s -o test.o(这个二进制文件打开就是乱码)
test.s 文件
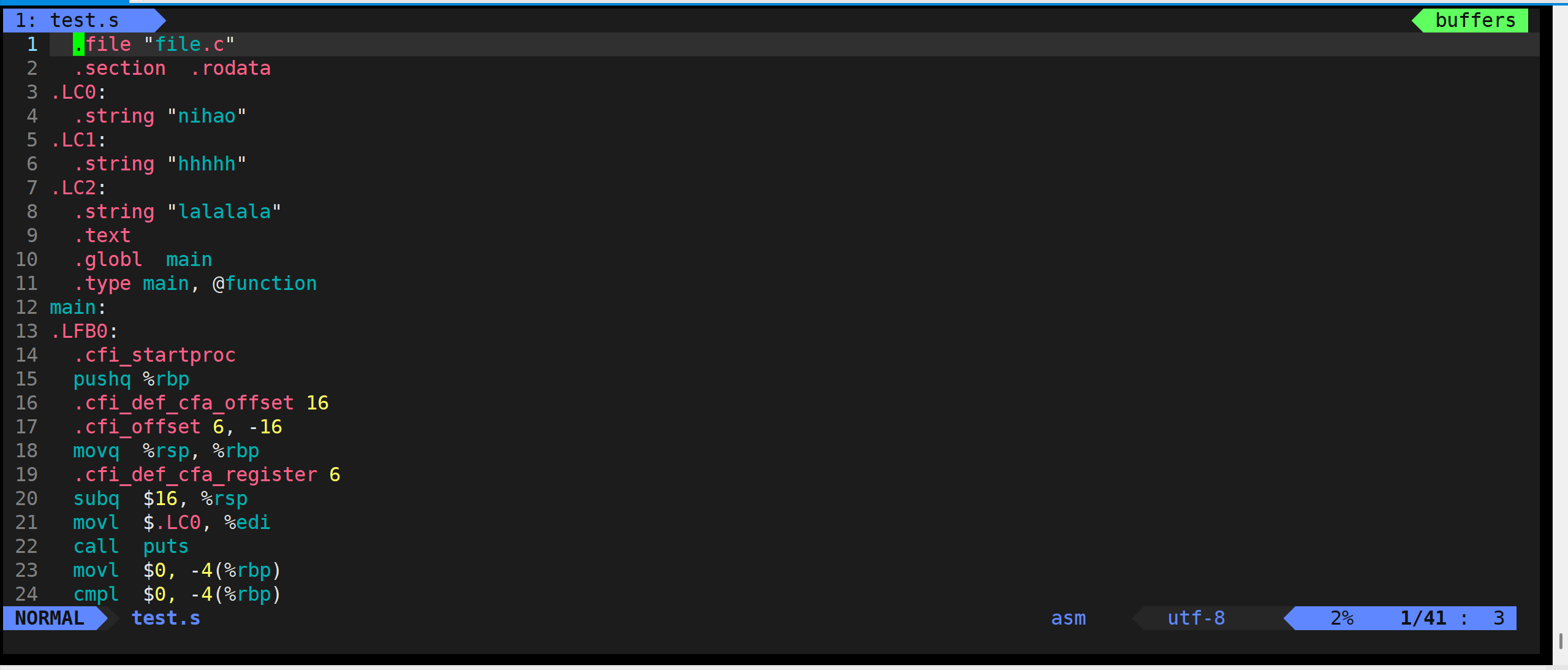
test.o 文件
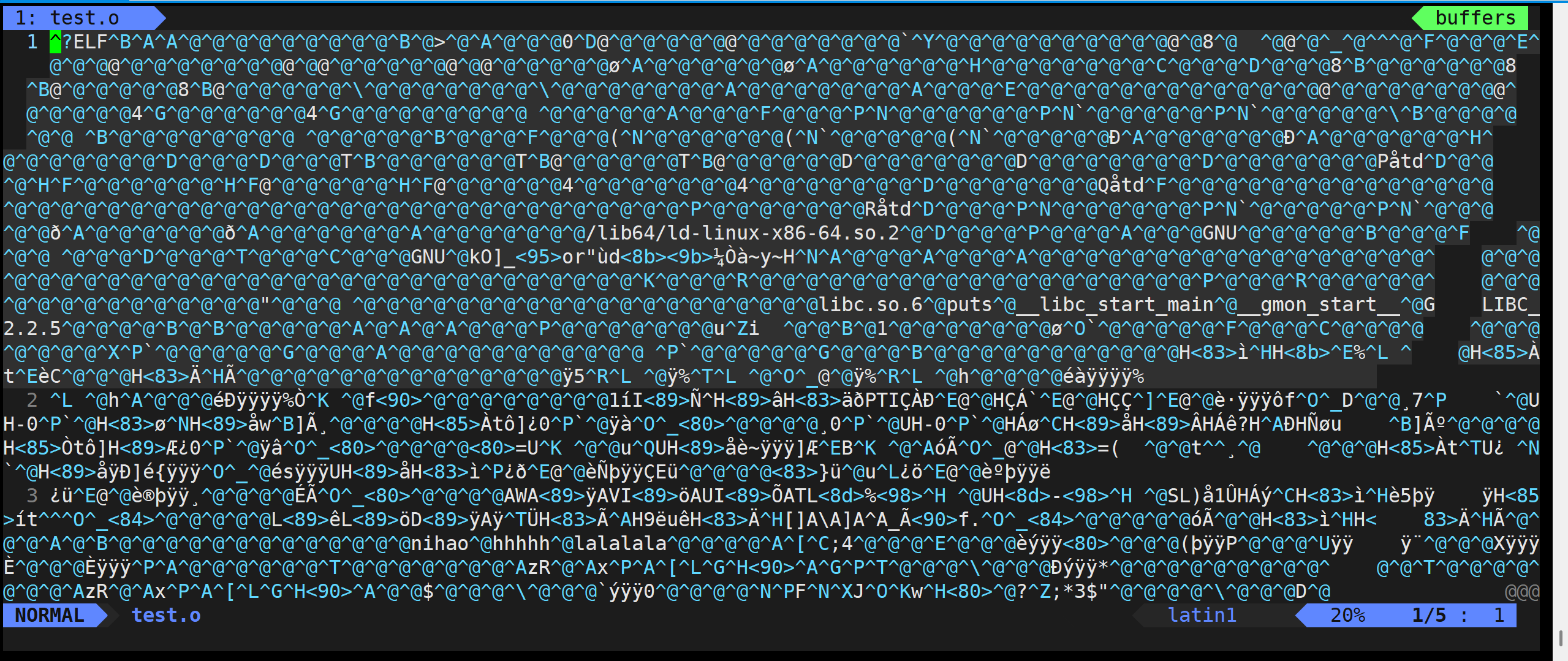
-c:程序开始翻译,当我们把汇编语言翻译为二进制文件就停下来。
1.4 链接
好,那么这个时候,为什么上面的那个.o文件执行不了呢?很简单,就是这个.o文件里面我们用到了库方法,比如printf,但是.o文件里面只有声明,没有定义。所以,咱们需要一个可以连接这个方法库的方法,就叫做链接(咱们只有找到了定义,才可以使用这个库方法)。
gcc code.o -o code
而ldd code 就可以查看运行这个文件所需要的库。
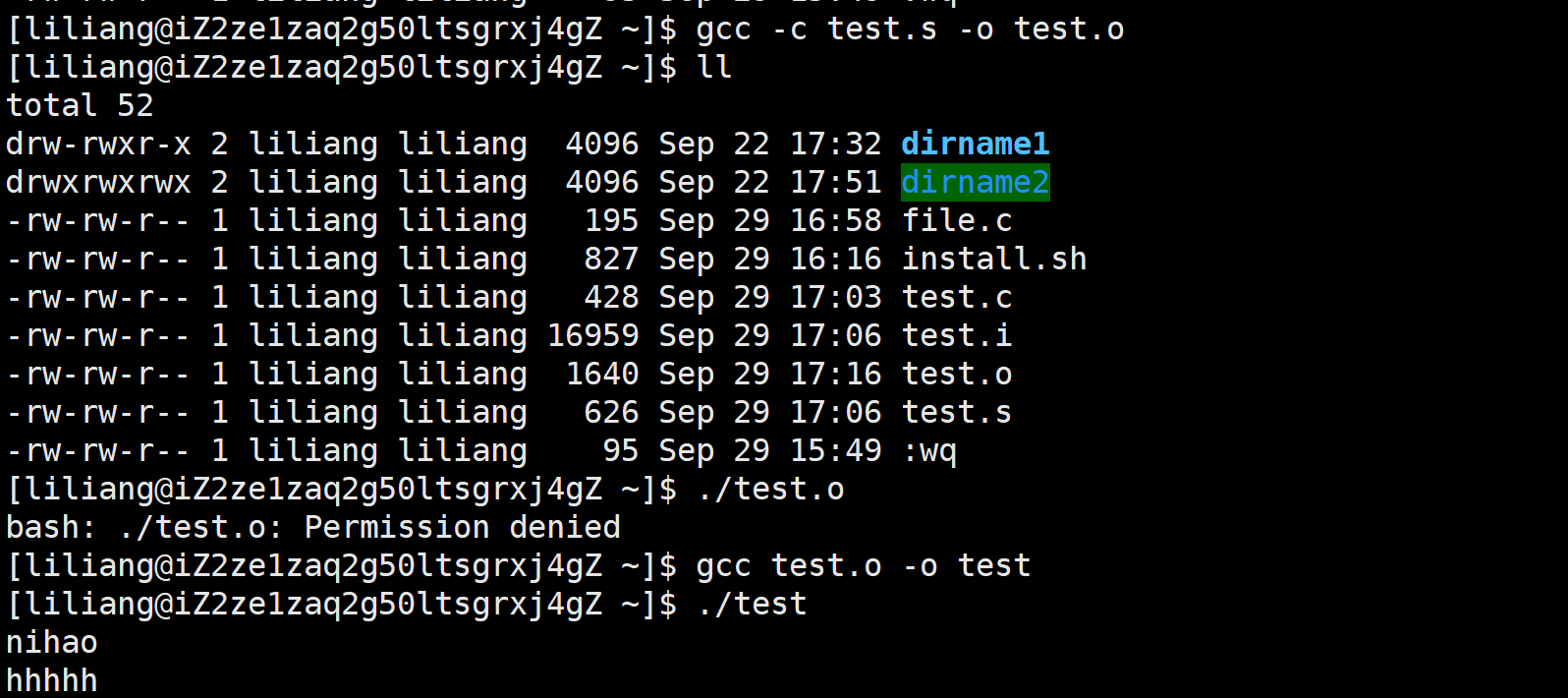

好,那么至此,我成功的引出了库这个概念。
那么下一篇文章,博主再来解释库。
本篇完................