isolcpusnohz_full
Ref:
CPU 隔离:简介-阿里云开发者社区
CPU 隔离:Full Dynticks 深探-阿里云开发者社区
CPU 隔离:Nohz_full-阿里云开发者社区
CPU 隔离:管理和权衡-阿里云开发者社区
CPU 隔离:实践-阿里云开发者社区
Kconfig中的说明:
config CPU_ISOLATION
bool "CPU isolation"
depends on SMP || COMPILE_TEST
default y
help
Make sure that CPUs running critical tasks are not disturbed by
any source of "noise" such as unbound workqueues, timers, kthreads...
Unbound jobs get offloaded to housekeeping CPUs. This is driven by
the "isolcpus=" boot parameter.
Say Y if unsure.
HouseKeeping Flags
enum hk_flags {
HK_FLAG_TIMER = 1,
HK_FLAG_RCU = (1 << 1),
HK_FLAG_MISC = (1 << 2),
HK_FLAG_SCHED = (1 << 3),
HK_FLAG_TICK = (1 << 4),
HK_FLAG_DOMAIN = (1 << 5),
HK_FLAG_WQ = (1 << 6),
};
简介
操作系统内核的核心是管理硬件资源,并为用户态业务提供好服务。除非用户主动申请内核服务支持,某些用户在执行业务时,并不希望被内核打断(影响其连续性、缓存布局等)。比如,一些CPU计算型任务或者用户态IO任务(如DPDK),希望内核尽可能少的打断用户态业务执行。
但是内核作为硬件资源的管理者和服务的提供者,其有一些必须要做的事情,比如页面回收、进程调度、定时器、中断等。这些,被称为“内核噪声”!对于某些专有的用户态业务来说,如何减少内核噪声的干扰,是尤为重要的。
NoHZ
CONFIG_NO_HZ_IDLE (https: //lwn.net/Articles/223185/) 内核选项带来了一种在CPU空闲时(没有任务要执行时),停止周期性中断的机制。CONFIG_NO_HZ_FULL内核选项,则是另一种CPU隔离技术。内核可以通过bootargs中传入“nohz_full=”来配置需要隔离的cpu。cpu-list 参数格式请参考:https://www.kernel.org/doc/html/latest/admin-guide/kernel-parameters.html#cpu-lists。
例如,假设您有 8 个 CPU,希望隔离 CPU 4、5、6、7:
nohz_full=4-7
当一个 CPU 包含在 nohz_full 引导参数的 CPU 列表中,内核会试图从那个 CPU 中排除尽可能多的内核干扰,这主要包含以下几个方面。
定时器中断
满足以下条件时,定时器可以停止:
- 在一个 CPU 上运行的任务无法被抢占。
这又包含几种场景:
1)CFS调度器场景(SCHED_OTHER、SCHED_BATCH),只能有一个任务,不然就需要调度切换;
2)实时调度器场景(SCHED_RR),最高优先级的任务只能有一个,否则也需要调度切换;
3)实时调度器场景(SCHED_FIFO),始终满足这一条件
- 任务不使用定时器事件,如 posix-cpu-timers、 perf event等。
残余的 1 Hz Tick(每秒钟中断)仍然存在,目的是为了维护调度程序内部统计。它以前在隔离的 CPU 上执行,但现在,这个事件使用一个unbound wq被挂载到 nohz_full 范围之外的 CPU运行。这样,我们的预期的任务可以在这个CPU 上 100%无 Tick 运行。
定时器回调
unbound的定时器回调的执行被移动到 nohz_full 范围之外的任何 CPU。与此同时,被固定的定时器 Tick 不能转移到其他地方。我们稍后会探讨如何处理。
工作队列和其他内核线程
与定时器回调类似,未绑定的内核工作队列和 kthread 被移动到 nohz_full 范围之外的任何 CPU。但是,被固定的工作队列和 kthread 不能移动到其他地方。我们稍后会探讨如何处理。
RCU静默状态
当 RCU 写者程序发布更新并将回调加入排队时,它必须等待所有 CPU 报告新的“RCU 静默状态”。实际上,rcu_read_lock() 和 rcu_read_unlock()之间的任何代码(或任何不可抢占的代码)都是“RCU 读端临界区”;其他剩下的都是“RCU 静默状态”。
要追踪静默状态,RCU 依赖 Tick 并检查它中断了哪个上下文。如果中断了不在 rcu_read_lock()/rcu_read_unlock()对保护的代码片段(不在RCU读临界区),则它报告静止状态。如果中断了用户空间,它也被认为是静默状态,因为用户空间是不能使用内核 RCU 子系统。
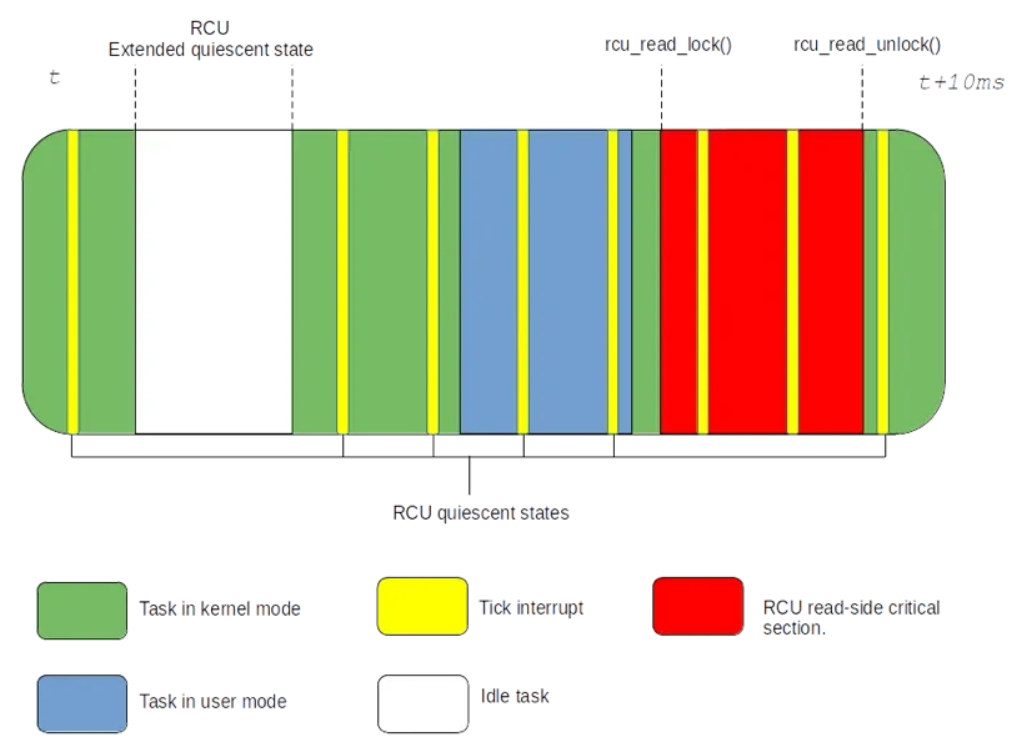
上图还说明了 tick-deprived idle 任务如何从特殊处理方式中再次受益。空闲 CPU 不是主动报告静默状态,而是通过进入“RCU extended静默状态”而被动报告。它在进入和退出空闲状态时递增一个具有完整内存屏障的原子变量。然后,等待所有 CPU 报告静默状态的 RCU 最终会扫描未响应的 CPU,以找出扩展的静默状态,并代表这些 CPU 报告静默状态。这种模式之所以有效,是因为我们知道空闲上下文不使用 RCU。我们知道用户空间也不使用RCU,因此,当运行非空闲任务的时候停止 Tick 时,这种被动报告方案可以扩展到用户空间中:
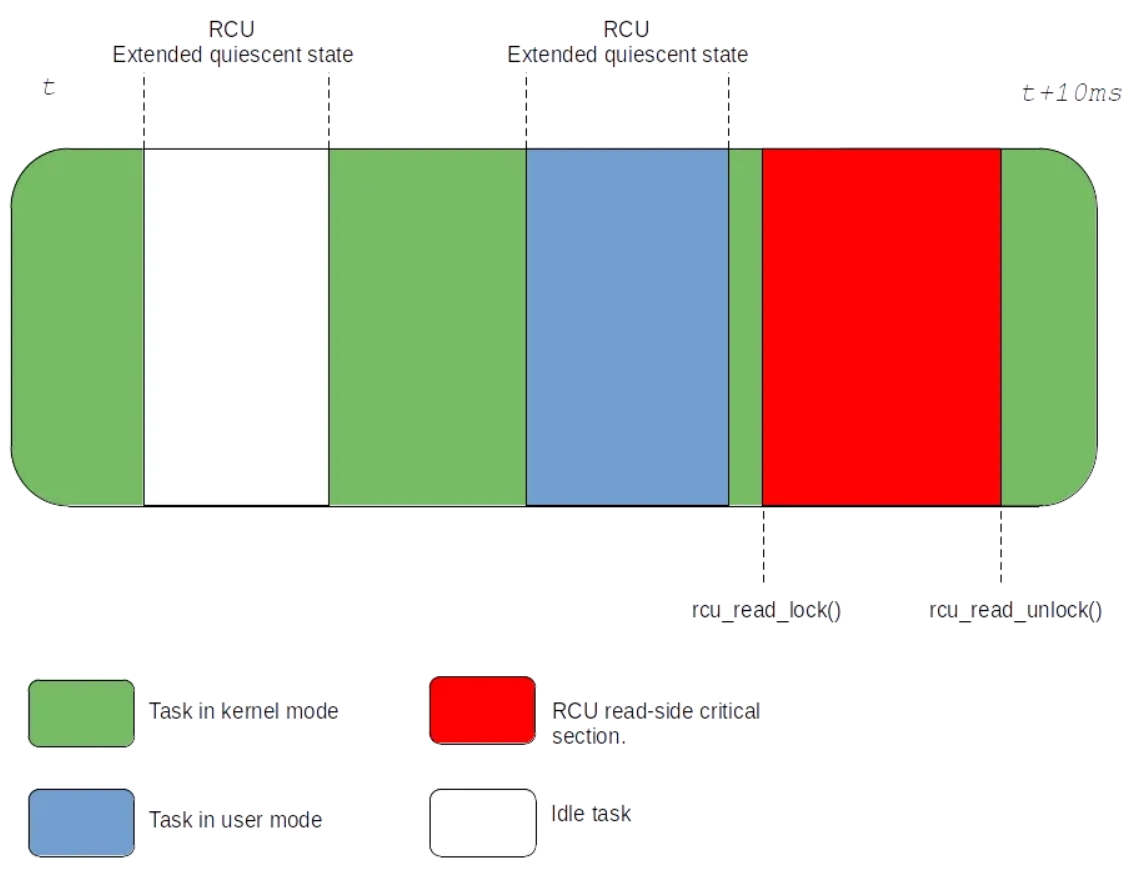
由于 CPU 很少在内核中花费太多时间(隔离出来的任务一般都长期运行在用户态),因此,上述提议将取代基于 Tick 的静默状态报告。RCU 扩展的静默状态要么在会出现短暂的延迟(短暂的内核代码路径),要么就持续很长时间。
这同样有一个问题:为什么不在 Tick 运行时也采用这种模式?
因为这将在每个用户态/内核态往返过程中产生一个代价高昂的原子操作,并且会有一个完整的内存屏障。此外,报告静默状态的责任最终由其他 CPU 承担。
因此,大部分 RCU 处理任务都被转移到隔离范围外的 CPU 上。CPU 设置为 nohz_full ,则默认就在RCU的NOCB 模式(CONFIG_RCU_NOCB_CPU=y)下运行,这也意味着在这些 CPU 上排队的 RCU 回调,被转移到了非隔离的 CPU 上运行的unbound kthreads 中执行。不需要传递“rcu_nocbs=” 内核参数,因为这在传递“nohz_full=” 参数时自动处理。
CPU 也不需要通过 Tick 来主动报告静默状态,因为它在返回到用户空间时,就进入了RCU的扩展静默状态。
Cputime 记账
将 CPU 切换到 full dynticks cputime 记账,这样它就不再依赖周期性事件。
当在 procfs 文件系统中检查指定进程的 stat 文件时,可以检索多个上下文的 cputime 统计信息,例如线程在用户空间、内核空间、客户机等中花费的时间。
这些数字由调度程序 cputime 记账功能来维护。 Tick 会触发并检查它中断了哪个上下文。如果中断了用户上下文,则一个 jiffy(两次 Tick 之间的时间)将计入用户时间。如果中断了内核上下文,则 jiffy 将被计入内核时间。这种行为如下图所示:
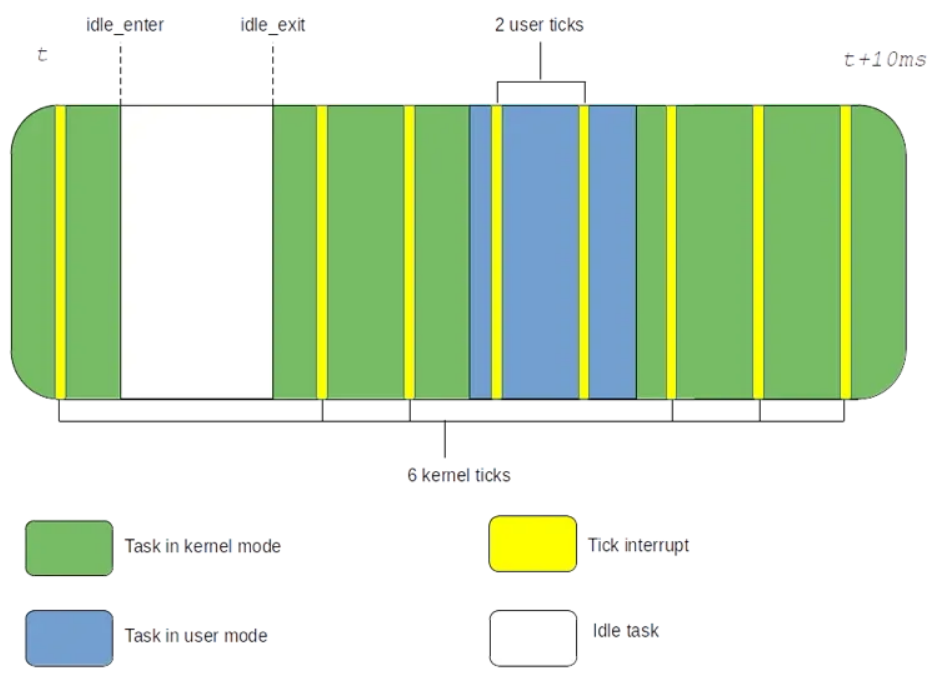
在上例中,我们记录了 2 次用户 Tick 和 6 次内核 Tick。对于 1000 Hz 的 Tick,一个 jiffy 等于 1 毫秒。因此,用户时间记录为 2ms,内核时间记录为 6ms。Tick 频率越高,cputime 越精确。
现在检查一下idle记账。这种方式不同,因为空闲时间内没有 Tick,因此,我们所能做的就是计算退出空闲状态和进入空闲状态的时间戳之间的差。
为了能够在运行非空闲任务并且 Tick 停止时对用户和内核 CPU 使用时间进行记账,我们必须将空闲记账逻辑扩展到用户/内核记账中。如下所示:
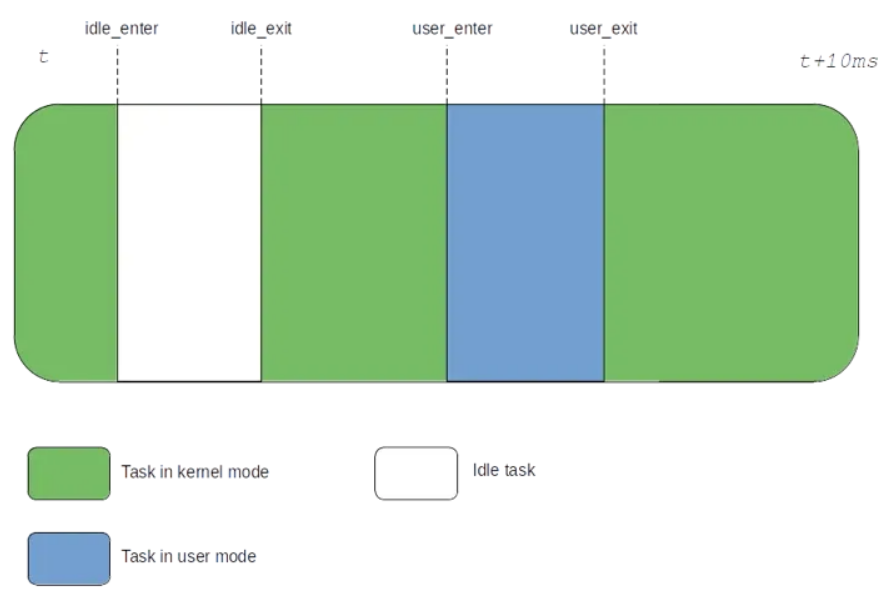
在这里,内核时间可以通过用户进入和退出内核态之间的差,当然,要排除idle时间。用户时间是用户进入和退出用户态之间的差,它的计算非常简单,甚至比基于 Tick 的记账更加精确。
但这带来了一个问题:为什么不在 Tick 运行时也使用这种解决方案呢?
因为每次在我们跨越用户/内核边界时,需要读取精确的但可能很慢的硬件时钟。通用工作负载遇到这种情况的频率会非常多(系统调用多),从而产生性能损失。因此,这种无tick的记账,适合于很少进行内核和用户空间切换的工作负载。
其他
除了上述小节描述的内核做的工作,用户还需考虑其他一些细节:
1、用户任务的cpu绑定
如果您想运行一个不被干扰的任务,一定不希望其他线程或进程与其共享 CPU。full dynticks 最终只在单个任务中运行,因此,需要:
1)将每个隔离任务绑定到 nohz_full 范围内的一个 CPU。每个 CPU 必须只有一个隔离任务。
2)将其他所有任务映射到 nohz_full 范围之外。
2、IRQ的cpu绑定
硬件 IRQ(除定时器和其他特定的中断之外)可能会在任何 CPU 上运行,并打乱您的隔离集。产生的干扰可能不仅仅是占用 CPU 时间和破坏 CPU 缓存的中断,IRQ 可能会在 CPU 上启动进一步的异步工作:softirq、计时器、工作队列等。因此,将 IRQ 映射射到 nohz_full 范围之外的 CPU 通常是一个好想法。这种映射可以通过文件来设置:
/proc/irq/$IRQ/smp_affinity
$IRQ 是向量号,更多细节可见内核文档:https://www.kernel.org/doc/Documentation/IRQ-affinity.txt
管理和权衡
管理
正常的配置下,每个 CPU 都要承担一些周期性的内核工作,例如更新调度程序的内部统计数据或计时等。nohz_full 配置会以隐含方式移除 nohz_full 集合内cpu的内核工作。
也就是说,如果您有 8 个 CPU,并隔离 CPU 1、2、3、4、5、6、7:
nohz_full=1-7
则 CPU 0 将单独承担内核管理工作。这些工作涉及:
- 未绑定timer回调执行
- 未绑定wq执行
- 未绑定 kthreads 执行
- 计时更新(jiffies 和 gettimeofday())
- RCU 缓冲期跟踪
- 代替隔离的 CPU 进行 RCU 回调执行
- 代替隔离的 CPU 执行 1Hz 残余的计时器 Tick
- 还可能承担一些额外的工作:绑定的硬件 IRQ、隔离cpu应用之外的用户态任务
尽管这些工作通常可由一个 CPU 代替其他 7 个 CPU 处理,但随着 CPU 数量的增加,同时,随着内存和缓存的进一步分区,内核管理任务可能也需要分区处理。通常情况下,为每个 NUMA 节点配置一个管理 CPU 是一种不错的方法。如以下配置所示:
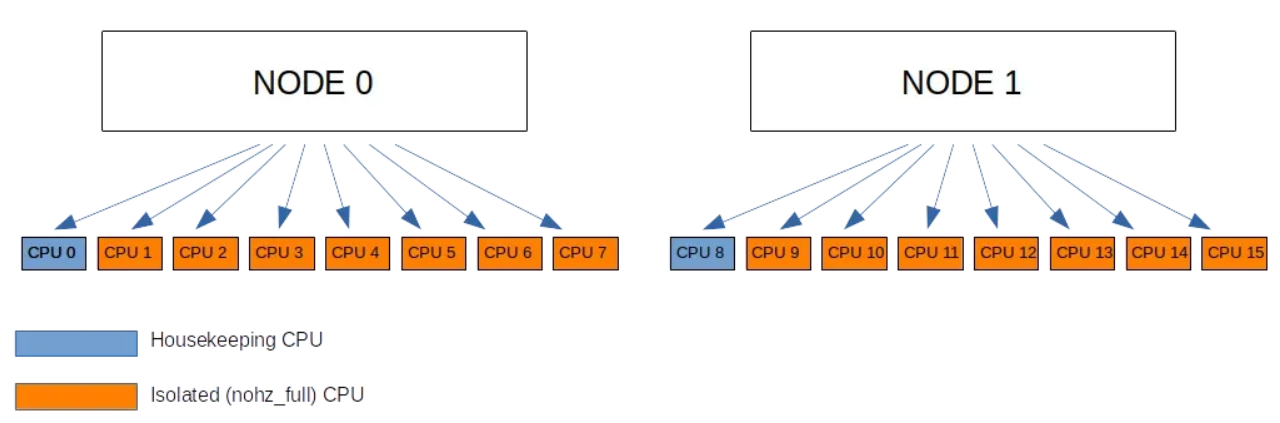
由于 CPU 0 - 7 属于节点 0,CPU 8 - 15 属于节点 1,默认设置如下所示:
nohz_full=1-7,9-15
在测试阶段,建议通过 top/htop 等工具检查和监控管理程序的活动,以确保它们没有超负荷。例如,如果以上设置显示 CPU 0 或 CPU 8 的负荷为 100%,则可能需要添加更多的管理 CPU,尽管这种情况更有可能使用更多的节点来处理。
同样需要注意的是,对内核的访问(例如系统调用或内存故障)可能会产生更多的内核管理活动,并导致 CPU 承担更多负载。通常不建议从隔离的 CPU 中请求内核服务。
在任何情况下,内核都有工作需要处理,这不能忽略。如果所有 CPU 都被传递到“nohz_full=” 内核参数,则 CPU 0 将从隔离集合内清理出来,并为其单独分配内核管理工作,可能会输出如下消息:
NO_HZ: Clearing 0 from nohz_full range for timekeeping
因此,要注意的是:被隔离的 CPU 之所以获得无抖动的特性,是因为其他 CPU 承担了更多工作,而至少一个 CPU 需要为这些工作做出牺牲。
内核进入/退出的开销
完全的 dynticks 模式增加了内核进入和退出的大量开销。这些是由于:
- 系统调用
- 异常(页面错误、陷阱等)
- 中断
这些开销首先是由于 RCU 跟踪和排序造成的。这项工作通常由周期性计时器中断来处理。现在,我们已经摒弃了这种方法,最终需要使用代价高昂的完全排序后的原子操作,来计算通过内核边界的往返次数。
这些开销的第二部分来自记录CPU运行时间(cputime记账)。同样,内核必须使用内核边界上的探测器来计算任务在内核和用户空间中执行所花费的时间,因为周期性的中断不再执行这项工作。尽管记录 CPU 运行时间使用的排序比 RCU 跟踪要弱,但仍有一些处理会增加总体开销。
我们之前曾经说过,IRQ 与内核管理密切相关。使用 mlock() 可以防止页面错误(https://man7.org/linux/man-pages/man2/mlockall.2.html)。之后,用户需要减少系统调用,这就形成了一条硬性规则:full dynticks 不适合基于内核的 I/O 型工作负载。相反,其更适合于:
- CPU 计算型的工作负载。涉及大量 CPU 处理和最少的基于内核的 I/O 的操作(依赖内核驱动程序处理系统调用和中断)。
- 对于内核不参与的 I/O 类型的工作负载,即基于 DPDK 等用户空间驱动程序的 I/O (https://www.dpdk.org/)。
实践
内核配置要求
CONFIG_NO_HZ_FULL=y
CONFIG_CPUSETS=y
CONFIG_TRACING=y
第一条为在运行一个任务时停止 Tick 提供支持。第二条使任务绑定设置更容易。第三个选项支持对 CPU 隔离进行调试的跟踪能力。
引导要求
使用“nohz_full=” 引导参数,可以在运行单个任务时关闭计时器 Tick,并且大多数非内核负载也会迁移到隔离范围之外的 CPU。由于计划隔离第 8 个 CPU,我们需要通过以下信息引导内核:
nohz_full=7
CPU 编号从 0 开始,所以第 8 个 CPU 的编号为 7。此外,无需设置“rcu_nocbs=” 引导参数,如示例中通常显示的那样,nohz_full 可自动调节该参数。
任务绑定
有多种方法可以在隔离的任务和系统其余部分之间划分 CPU,首选方法是使用 cpuset 。对于有特殊需求的人,还有其他解决方案可用。
Cpuset
一旦内核启动,为了确保无关任务不会干扰 CPU 7,我们创建两个 cpusets 分区。名为“isolated” 的目录包含我们隔离的 CPU,它将来会运行隔离任务。另一个名为“housekeeping” 的目录承担常规负载。我们强制禁用“isolation” 分区的负载平衡,以确保任何任务都不能迁移进/出 CPU 7,除非手工移动。
cd /sys/fs/cgroup/cpuset
mkdir housekeeping
mkdir isolated
echo 0-6 > housekeeping/cpuset.cpus
echo 0 > housekeeping/cpuset.mems
echo 7 > isolated/cpuset.cpus
echo 0 > isolated/cpuset.mems
echo 0 > cpuset.sched_load_balance
echo 0 > isolated/cpuset.sched_load_balance
while read P
do
echo $P > /sys/fs/cgroup/cpuset/housekeeping/cgroup.procs 2>&1
done < /sys/fs/cgroup/cpuset/cgroup.procs
对 housekeeping/cgroup.procs 的一些写入操作可能会失败,因为内核线程 pid 无法移出根 cpuset 分区。然而,未绑定的内核线程会自动强制绑定 nohz_full 范围之外的 CPU,因此可以安全地忽略这些故障。
Isolcpus
您还可以使用“isolcpus=” 内核引导参数实现与以上 cpuset 设置相同的设置。但我们不建议使用这种解决方案,因为以后无法在运行时更改隔离配置。因此,尽管“isolcpus” 仍在使用,但一般“不推荐”。对于尚未支持 cpusets/cgroups 的专用或嵌入式内核,它可能仍然可用。
Taskset, sched_setaffinity(), …
从底层来讲,还可以使用 taskset(https://man7.org/linux/man-pages/man1/taskset.1.html) 等工具或者依赖 sched_setaffinity() (https://man7.org/linux/man-pages/man2/sched_setaffinity.2.html) 这样的 API,将每个任务绑定到所需的 CPU 集合。在不支持 cpuset 的系统中,其优点是允许在运行时更改绑定关系,这与“isolcpus” 不同;缺点是它需要更精细的工作。
IRQ 绑定
我们已经进行了任务绑定,但是硬件中断仍然可以在隔离的 CPU 上触发,并干扰其独占负载。所幸,我们可以通过 procfs (https://www.kernel.org/doc/html/latest/core-api/irq/irq-affinity.html) 提供的接口安排在内核管理集上触发这些中断:
### Migrate irqs to CPU 0-6 (exclude CPU 7)
for I in $(ls /proc/irq)
do
if [[ -d "/proc/irq/$I" ]]
then
echo "Affining vector $I to CPUs 0-6"
echo 0-6 > /proc/irq/$I/smp_affinity_list
fi
done
您可能会在其中一个中断向量上遇到 I/O 错误,例如 x86-64 机器上的数字 0,因为这是每个 CPU 上的计时器向量表,由于其本地性的特质,无法将其移开。然而,这个问题大可放心忽略,因为“nohz_full” 就是专门为解决这个问题而设计的。
实际测试
现在,大部分内务管理工作负载应在 CPU 0-6 上运行。CPU 7 将在无干扰的情况下运行用户空间代码。我们用启动器做一个无意义的循环。
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
// Move the current task to the isolated cgroup (bind to CPU 7)
int fd = open("/sys/fs/cgroup/cpuset/isolated/cgroup.procs", O_WRONLY);
if (fd < 0) {
perror("Can't open cpuset file...\n");
return 0;
}
write(fd, "0\n", 2);
close(fd);
// Run an endless dummy loop until the launcher kills us
while (1);
return 0;
}
将该代码包写在名为“user_loop.c” 的文件中,并编译:
$ gcc user_loop.c -o user_loop
Launch脚本
除了在隔离的 CPU 7 上运行无意义的循环 10 秒之外,launch脚本的作用是跟踪可能对敏感工作负载有潜在干扰的事件。
# !/bin/bash
TRACING=/sys/kernel/debug/tracing/
# Make sure tracing is off for now
echo 0 > $TRACING/tracing_on
# Flush previous traces
echo > $TRACING/trace
# Record disturbance from other tasks
echo 1 > $TRACING/events/sched/sched_switch/enable
# Record disturbance from interrupts
echo 1 > $TRACING/events/irq_vectors/enable
# Now we can start tracing
echo 1 > $TRACING/tracing_o
# Run the dummy user_loop for 10 seconds on CPU 7
./user_loop &
# $!:表示最后一个后台进程的进程 ID(PID)
USER_LOOP_PID=$!
sleep 10
kill $USER_LOOP_PID
# Disable tracing and save traces from CPU 7 in a file
echo 0 > $TRACING/tracing_on
cat $TRACING/per_cpu/cpu7/trace > trace.7
上述代码可以写入名为“launch” 的文件中,该文件与“user_loop” 位于相同的目录中。
这里跟踪到两个有意思的底层事件:
调度程序上下文切换:报告任何抢占“user_loop” 的任务。这包括工作队列和内核线程。
IRQ 向量:报告任何(大多数)中断“user_loop” 的 IRQ,这包括计时器中断。