[论文阅读] 人工智能 + 软件工程 | AFD——用“值流分析+LLM”破解C程序指针分析精度难题,26倍提升堆对象建模效率!
AFD——用“值流分析+LLM”破解C程序指针分析精度难题,26倍提升堆对象建模效率!
一、论文信息
- 论文原标题:AFD: Automatic Allocation Function Detection with Value-Flow Analysis and Large Language Models
- 论文链接:https://arxiv.org/pdf/2509.22530
二、一段话总结
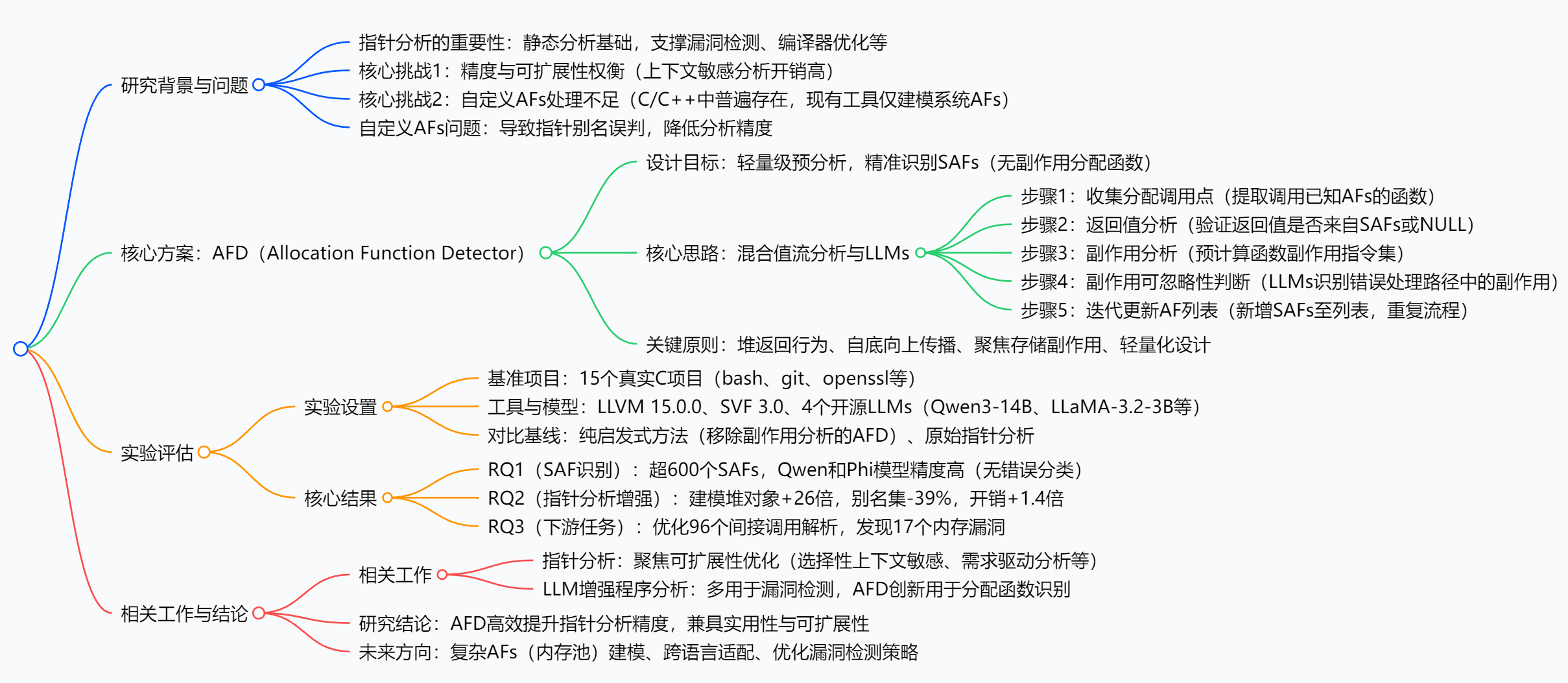
本文提出AFD(Allocation Function Detector),一种结合“值流分析”与“大语言模型(LLMs)”的轻量级技术,专门解决C/C++程序中“自定义分配函数(AFs)未被识别”导致的指针分析精度不足问题。它先通过值流分析筛选无副作用的简单分配函数(SAFs),再用LLMs判断含潜在副作用的函数是否属于“错误处理路径中的可忽略副作用”,最终在15个真实C项目(如bash、git、openssl)上验证:AFD识别出超600个自定义AFs,使指针分析的建模堆对象数量提升26倍、别名集大小减少39%,仅增加1.4倍运行时开销,还助力发现17个未检测到的内存漏洞,显著优化了下游静态分析任务效果。
三、思维导图
四、研究背景:指针分析的“自定义AFs痛点”,到底难在哪?
要理解AFD的价值,得先搞懂“指针分析”在程序开发中的角色——它就像静态分析的“眼睛”,能跟踪代码中指针的指向关系,支撑漏洞检测(比如内存泄漏、双重释放)、编译器优化(比如删除冗余代码)等关键任务。但这双“眼睛”长期存在一个“视力盲区”:自定义分配函数(AFs)。
在C/C++开发中,程序员很少直接用系统自带的malloc(系统AF),更爱封装自定义AF——比如xmalloc(bash中常用),它会在malloc基础上增加“内存分配失败时的错误提示”“初始化内存为0”等逻辑。这些自定义AF本质上还是“分配内存并返回指针”,但现有指针分析工具只认识malloc,会把所有xmalloc调用返回的指针视为“指向同一个抽象对象”——这就像把所有“长得像苹果的水果(红富士、嘎啦果、阿克苏)都当成同一个品种”,直接导致指针别名误判:明明是不同xmalloc分配的独立内存,工具却认为它们是“同一个指针的别名”,后续漏洞检测自然会漏判或误判。
举个真实案例:bash源码中,xmalloc被调用了755次,而直接调用malloc仅42次。按现有工具的逻辑,这755次xmalloc返回的指针都会被归为“同一别名”,如果其中有一处内存未释放,工具根本分不清是哪次xmalloc出了问题,更别提精准定位漏洞了。
除了“自定义AFs识别难”,指针分析还面临“精度与效率的矛盾”:要提升精度,就得用“上下文敏感分析”(比如跟踪每个函数调用的上下文),但这种方法在大规模项目中开销极高——1-call-site敏感分析的开销是上下文不敏感的10-15倍,Java项目中2-object敏感甚至超100倍。如果再加上“识别自定义AFs”的复杂分析,效率只会更差。
简单说,行业急需一种技术:既能精准识别自定义AFs,又不能让分析开销“暴涨”——这就是AFD诞生的背景。
五、创新点:AFD的“两大突破”,解决了传统方法的哪些死结?
AFD之所以能在实验中表现出色,核心在于它跳出了传统“纯静态分析”或“纯启发式”的局限,有两个关键创新:
-
“值流分析+LLM”混合架构,破解“副作用误判”难题
传统方法要么“一刀切”:把含任何副作用(比如修改全局变量、调用其他函数)的函数都排除在“自定义AFs”之外,导致大量合法AFs被漏判;要么用复杂静态分析判断副作用,却因开销太高无法落地。AFD的解法很巧妙:先用值流分析筛选“完全无副作用”的基础SAFs,再对“含潜在副作用”的函数,让LLM判断“副作用是否仅存在于错误处理路径”(比如“内存分配失败时打印错误日志”,这种副作用不影响内存分配核心逻辑,属于可忽略范畴)。LLM的语义理解能力,刚好补上了静态分析“不会区分副作用场景”的短板。 -
轻量化设计,平衡“精度”与“效率”
AFD定位是“指针分析的预分析步骤”,所以从设计之初就拒绝“重计算”:①值流分析只跟踪“指针流向返回值”和“返回值来源”,不做全程序复杂分析;②副作用分析只关注“非局部内存存储”和“free调用”,忽略无关操作(比如局部变量赋值、加载操作);③LLM查询用“零样本提示+5次投票”,既保证准确率,又避免反复调用的延迟。最终实现“提升26倍堆对象建模率”的同时,仅增加1.4倍开销,远低于上下文敏感分析的10-15倍。
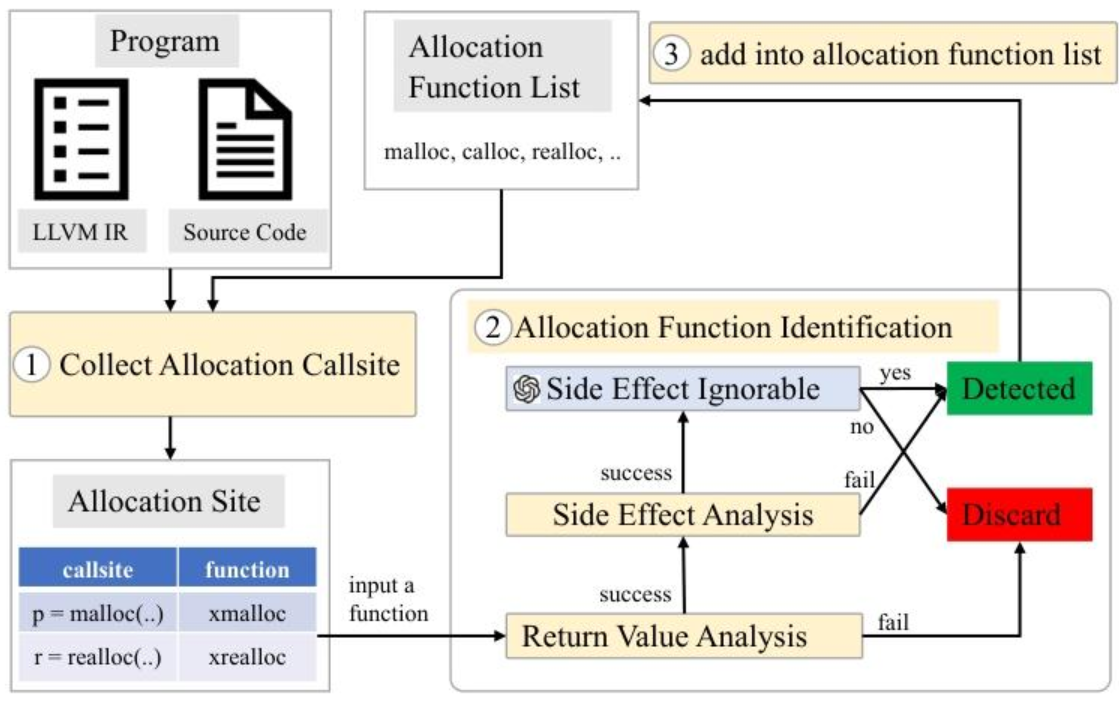
六、研究方法:AFD的“五步工作流”,从“识别AFs”到“增强指针分析”
AFD的核心逻辑可以拆解为5个步骤,环环相扣,最终实现“自动识别自定义SAFs”并赋能指针分析:
步骤1:收集“潜在分配函数调用点”(CSet)
先从代码中找出“调用已知AFs”的函数——初始“已知AFs”是系统AFs(如malloc),后续会迭代加入新识别的SAFs。这里要注意:如果是间接调用(比如函数指针调用),会先用Kelp工具解析调用目标,只有“所有目标都是SAFs”的间接调用,才会纳入CSet。
步骤2:返回值分析,筛选“基础SAFs”
对CSet中的每个函数,用 intra-procedural 值流跟踪验证两个条件:①函数内所有SAF调用的结果,最终都流向“函数返回值”(没有被中间变量转移所有权);②函数所有返回路径的返回值,要么来自SAF调用,要么是NULL(确保返回的一定是“分配的内存指针”或“空指针”)。满足这两个条件的函数,进入下一步。
步骤3:副作用分析,标记“潜在问题函数”
预计算函数的“副作用指令集(SI)”——如果函数包含“修改非局部内存”或“调用含副作用函数”的指令,SI就非空,说明该函数可能含副作用。如果SI为空,直接判定为SAFs;如果SI非空,进入下一步。
步骤4:LLM判断,区分“可忽略副作用”
给LLM输入“函数代码+副作用指令位置”,用提示模板(比如“请判断以下函数的副作用是否仅存在于错误处理路径,且不影响内存分配核心逻辑?”)让LLM做零样本判断。如果LLM判定“副作用可忽略”,则该函数纳入SAFs;否则排除。实验中Qwen3-14B和Phi-4-ReasoningPlus的判断准确率最高,能做到“零错误分类”。
步骤5:迭代更新,扩大“AFs列表”(AFL)
把新识别的SAFs加入AFL,然后回到步骤1,用“更新后的AFL”重新收集调用点——因为有些函数可能调用了“新识别的SAFs”,之前未被纳入CSet。重复步骤1-4,直到AFL不再新增SAFs,迭代停止。
关键原则支撑:4条“红线”确保识别精准
为了避免误判,AFD还定了4条设计原则:
- P1:仅关注“堆返回行为”——排除返回栈对象、参数对象的函数;
- P2:自底向上传播——沿调用图从“底层函数”往“上层函数”识别,支持SAF嵌套(比如
xmalloc被xmalloc_array调用,两者都能被识别); - P3:聚焦“存储副作用”——只关注影响内存状态的操作,忽略无关操作;
- P4:轻量化优先——能靠简单规则判断的,绝不引入复杂计算。
七、实验方法与主要成果:15个真实项目验证,AFD到底有多强?
实验设置:用“真实项目+多基线”验证效果
- 实验对象:15个主流C项目,覆盖命令行工具(bash-5.2)、版本控制(git-2.47.0)、加密库(openssl-3.4.0)等,代码量从几万行到上百万行不等,确保结果有代表性。
- 工具与模型:基于LLVM 15.0.0和SVF 3.0实现AFD,LLM选用4个开源模型(Qwen3-14B、LLaMA-3.2-3B、Phi-4-ReasoningPlus、DeepSeek-R1-0528-Qwen3-8B),本地用vLLM部署,减少调用延迟。
- 对比基线:①纯启发式方法(移除LLM模块的AFD);②原始指针分析(上下文不敏感Andersen算法);③启发式增强分析(纯启发式+原始指针分析)。
- 核心指标:SAF识别数量、堆对象扩展率(ER,建模堆对象数量提升倍数)、别名集减少率(ARR,指针别名误判程度)、运行时开销、下游任务效果(间接调用解析数、漏洞检测TP/FP数)。
主要成果:用数据说话,AFD的3大核心价值
1. SAF识别:超600个自定义AFs被“唤醒”,LLM助力精准不漏判
| 方法 | 平均SAF识别数量(15个项目) | 最高精度模型(无错误分类) | 纯启发式漏判率 |
|---|---|---|---|
| AFD(Qwen3-14B) | 40+(总计超600) | Qwen3-14B、Phi-4-ReasoningPlus | 约70%(如bash中纯启发式仅识别3个,Qwen识别65个) |
| 纯启发式方法 | 12+ | -(无模型,漏判严重) | - |
2. 指针分析增强:26倍堆对象建模率,39%别名集减少,效率碾压传统方法
| 策略 | 堆对象扩展率(ER) | 别名集减少率(ARR) | 运行时开销(相对原始分析) |
|---|---|---|---|
| AFD(Qwen3-14B) | 26.4倍 | 38.7% | 1.4倍 |
| AFD(Phi-4) | 26.2倍 | 39.3% | 1.38倍 |
| 纯启发式增强分析 | 9.0倍 | 26.7% | 1.2倍 |
| 原始指针分析 | 1倍(基准) | 0%(基准) | 1倍(基准) |
3. 下游任务:优化间接调用解析,发现17个遗漏内存漏洞
- 间接调用解析:15个项目共2066个间接调用,AFD帮助优化96个,平均每个优化调用的“目标函数数量”从98.9降至57.6(比如原本工具认为一个函数指针可能调用2个函数,优化后能精准定位到1个)。
- 内存漏洞检测:将AFD集成到Saber(SVF的漏洞检测器)后,结果如下:
漏洞类型 减少假阳性(FP) 新增真阳性(TP,即新发现漏洞) 新增假阳性(FP) 内存泄漏 241个 13个 444个 双重释放 30个 4个 66个 新增的假阳性主要源于Saber自身的“路径敏感性不足”(65%),而非AFD的问题——AFD的核心贡献是“多发现17个真实漏洞”,这在工业界是极具价值的突破。
八、关键问题:问答拆解AFD的核心逻辑
问题1:AFD为什么要区分“错误处理路径的副作用”?这种区分对识别自定义AFs有什么用?
答:因为很多自定义AFs会在“内存分配失败”时添加副作用(比如打印错误日志、终止程序),但这些副作用不影响“分配内存并返回指针”的核心逻辑,属于“可忽略副作用”——如果不区分,传统方法会把这类函数误判为“非AFs”,导致大量漏判。比如bash中的xmalloc,当malloc失败时会调用fatal函数打印错误信息,这个“调用fatal”就是错误处理路径的副作用。AFD通过LLM识别出这种场景,就能把xmalloc正确归为“自定义AFs”,而传统方法会因“含调用fatal的副作用”将其排除,最终漏判755次xmalloc调用中的大部分。
问题2:相比直接用LLM识别所有自定义AFs,AFD先用值流分析筛选“无副作用SAFs”,再让LLM处理“含副作用函数”,这种分步策略有什么优势?
答:主要有两个优势:①降低LLM调用成本——值流分析能快速筛选出“完全无副作用”的基础SAFs,这些函数无需LLM判断,减少了LLM的调用次数和延迟(尤其在大规模项目中,值流分析筛选后,需要LLM处理的函数仅占10%-20%);②提升LLM判断准确率——值流分析已经排除了“返回值不来自AFs”“返回值被转移所有权”等明显非AFs的函数,LLM只需聚焦“副作用是否可忽略”这一个问题,避免了“让LLM判断全量函数”导致的语义混淆(比如LLM不会把“返回栈对象的函数”误判为AFs)。实验中Qwen3-14B的“零错误分类”,就得益于这种“值流分析先筛选,LLM再精判”的分步策略。
问题3:AFD仅增加1.4倍运行时开销,却能提升26倍堆对象建模率,这种“高效提升”是怎么实现的?
答:关键在于AFD的“轻量化设计”:①值流分析只做“最小必要跟踪”——仅关注“SAF调用结果→返回值”的流向和“返回值来源”,不做全程序值流分析,计算量小;②副作用分析只聚焦“关键操作”——忽略局部变量赋值、加载操作等无关副作用,仅判断“非局部内存存储”和“free调用”,减少无效计算;③LLM调用优化——用“零样本提示”避免训练成本,用“5次投票”平衡准确率和调用次数,且只对“含副作用函数”调用LLM,而非全量函数。这些设计让AFD的计算量远低于“上下文敏感分析”,最终实现“1.4倍开销换26倍精度提升”的高效平衡。
问题4:AFD发现的17个新内存漏洞,为什么原始指针分析没检测到?这些漏洞有什么共性?
答:原始指针分析没检测到,核心原因是“自定义AFs未被识别,导致值流跟踪断裂”——原始分析把所有自定义AFs返回的指针视为“同一抽象对象”,无法区分“