复旦华为提出首个空间理解和生成统一框架UniUGG,支持参考图像和任意视图变换的 3D 场景生成和空间视觉问答 (VQA) 任务。
复旦大学与华为诺亚方舟实验室携手,提出首个用于空间理解和生成的统一框架 UniUGG。该框架功能强大,不仅能支持空间级视觉问答(VQA),还可生成几何一致的 3D 场景;给定参考图像时,能创造性生成 3D 变体并精准描述。在性能方面,UniUGG 在空间理解和生成任务上均超越基准水平。此外,经特殊调整的视觉编码器在下游任务中也有出色表现,展现出强大的应用潜力。

给定参考图像和相对视图变换,UniUGG 可以生成相应的 3D 场景。 以下是参考视图的点图。
3D 生成比较
UniUGG 准确捕捉输入视图变换,并利用参考图像“想象”新视图下的细粒度空间结构,并输出正确的字幕。

3D 场景生成和字幕
给定一个参考图像,我们随机采样合理的相对视图变换,并让 UniUGG 生成相应的 3D 场景,并进一步为生成的 3D 场景添加字幕。

空间理解
UniUGG 可以捕捉细粒度的空间关系并支持空间视觉问答 (VQA) 任务。

问题:这些是视频的帧。这个房间里有多少个天花板灯?
回答:视频显示,房间里共有 2 盏吊灯。
相关链接
论文: https://arxiv.org/abs/2508.11952
项目: https://fudan-zvg.github.io/UniUGG
论文介绍

UniUGG:通过几何语义编码实现统一的 3D 理解和生成
尽管近期的统一架构在图像理解和生成方面取得了令人瞩目的进展,但 3D 任务的集成仍然充满挑战,且在很大程度上尚未得到探索。本文介绍了 UniUGG,这是第一个统一的 3D 模态理解和生成框架。
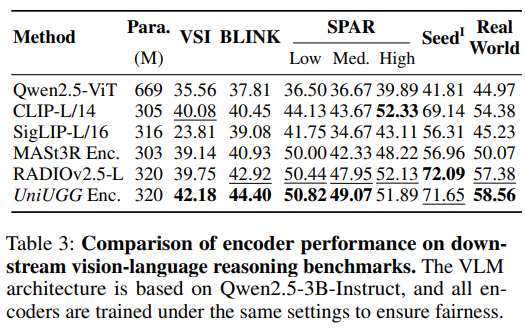
该统一框架采用 LLM 来理解和解码句子和 3D 表征。其核心是提出了一个空间解码器,利用潜在扩散模型来生成高质量的 3D 表征。这使得基于参考图像和任意视图变换的 3D 场景生成和想象成为可能,同时仍然支持空间视觉问答 (VQA) 任务。此外,我们提出了一种几何语义学习策略来预训练视觉编码器。该设计联合捕捉输入的语义和几何线索,增强了空间理解和生成。大量的实验结果证明了我们的方法在视觉表征、空间理解和 3D 生成方面的优越性。
方法概述

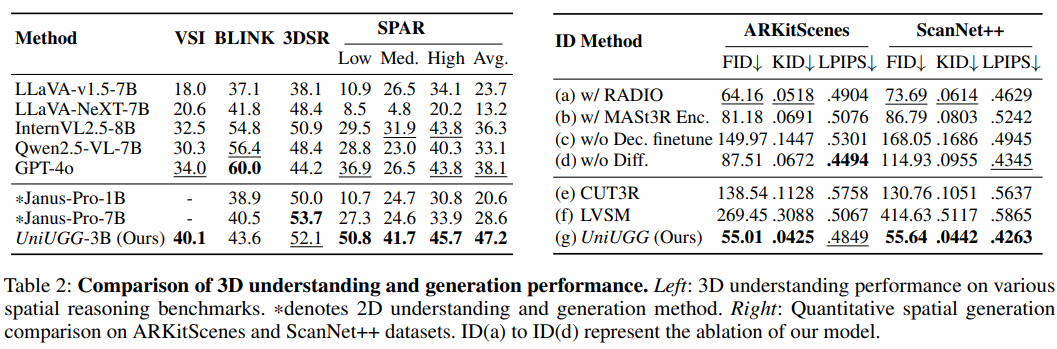
UniUGG 概览 这是首个用于空间理解和生成的统一框架。(A) UniUGG 支持空间级 VQA,并可生成几何一致的 3D 场景。(B) 给定参考图像,它可以创造性地生成 3D 变体并准确描述它们。(C) UniUGG 在空间理解和生成方面均超越基准,我们经过特殊调整的视觉编码器在下游任务中表现出色。
实验结果

定性 3D 生成比较。UniUGG 能够准确捕捉输入视图变换,并利用参考图像在新视图下“想象”细粒度的空间结构,最终输出正确的字幕。相比之下,基线方法仅能生成粗糙且模糊的几何结构。

结论
UniUGG 是首个用于空间生成和理解的统一框架,能够进行空间级 VQA 和生成 3D 场景。论文提出了一种几何语义学习策略来预训练视觉编码器,增强其空间建模能力。这显著提升了我们统一框架的生成和理解能力,并在下游任务中取得了优异的性能。此外论文设计了 Spatial-VAE 来实现 3D 生成,并连接空间解码器进行微调,以确保更清晰的 3D 场景解码。广泛的评估证明了 UniUGG 能够有效处理 3D 生成和空间 VQA 任务。未来的工作将扩展 3D 生成功能,使其不再局限于点云,并融入编辑功能。